Intro
최근 단안 깊이 추정(Monocular Depth Estimation, MDE)은 깊이 파운데이션 모델(depth foundation model)의 발전에 힘입어 좋은 모습을 보여주고 있습니다. 그러나 이러한 모델들은 여전히 한계가 있는데 주로 정적인 이미지를 대상으로 설계되었기 때문에 비디오에서는 깜빡임(flickering)과 모션 블러(motion blur) 현상이 종종 발생합니다. 이러한 한계는 시간적으로 일관된 깊이 정보가 요구되는 로보틱스, 증강현실, 그리고 고급 비디오 편집 분야에서의 활용을 제한하는 등 문제로 남습니다.
이러한 문제를 해결하고자 Video Depth Estimation을 잘 수행하려는 연구가 등장하였는데, Test Time Adaptation 방식으로 DFM의 output값에 정교한 기하학적 제약을 넣어 조정하는 방식을 취하거나 learning 방식으로 접근한 연구 등이 있습니다. TTA 방식은 추론 과정에서 추가적으로 adaptation을 하다보니 추론 시간에 부정적인 영향을 끼쳐 대부분 학습 기반 방식으로 접근하는데, 이러한 학습 방식들도 시간 일관성에 대한 규제를 주기 위해서 optical flow나 camera pose 같은 추가 정보에 매우 의존적이다보니 해당 정보들의 noise가 같이 반영되는 문제가 발생한다고 하네요.
다른 방식으로는 사전 학습된 비디오 디퓨전 모델을 video-to-depth 예측 모델로 재설계하는 방식도 있는데, 이들의 정확도는 좋긴 하다만 연산량이 너무 많기도 하고 기존에 공개된 DFM 구조를 활용하지도 못하며, 다룰 수 있는 비디오의 길이도 제한적인 단점이 있다고 합니다.
결과적으로, 저자들의 목적은 기존에 공개된 DFM의 일반화 성능은 그대로 활용하면서 해당 모델들의 단점인 temporal stability를 좋게 만든다는 점입니다.
Method
아래 그림은 저자들의 overall framework를 의미합니다. Encoder는 DepthAnythingV2의 ViT 모델을 그대로 활용하고 있으며, 앞서 언급드린 것처럼 DFM의 일반화 성능을 그대로 활용하기 위해서 백본을 freeze해둔 상태입니다.
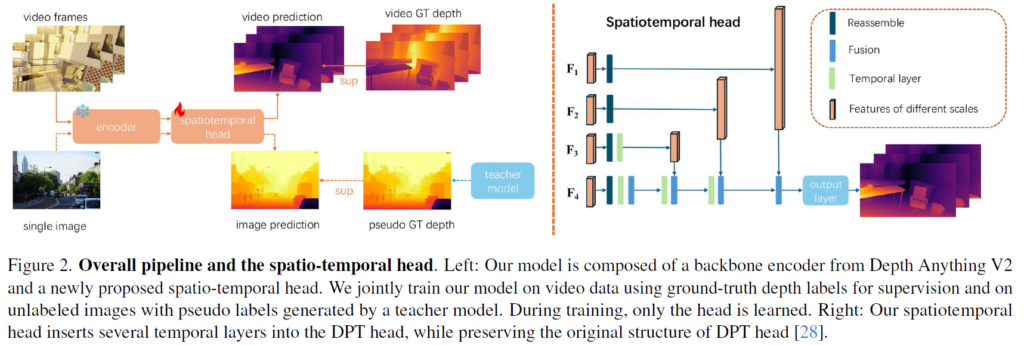
그리고 뒷단에 spatiotemporal head의 경우에는 Dense prediction transformer (DPT)의 decoder 구조에 temporal layer를 추가하였습니다. DPT의 decoder는 DepthAnythingV2 모델에서도 사용하던 모델 구조로 ViT backbone에 대해 pixel-level prediction을 수행하기 위해 제안된 디코더 아키텍처입니다.
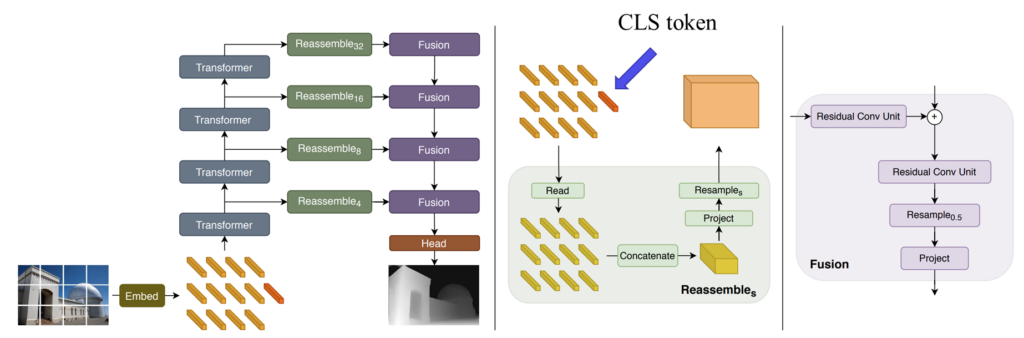
위에는 DPT의 모델 구조를 나타내고 있는데 reassemble 구조는 ViT의 CLS token을 나머지 visual token에게 concat을 할지, 혹은 element-wise summation을 할지 등에 대한 구조입니다. 그리고 Fusion 모듈은 pixel-level prediction 관점에서 U-net architecture처럼 Encoder의 feature map을 decoder에게 전달해주는 과정과, resnet의 residual convolution block 그리고 2x interpolation 과정으로 구성되어있습니다.
그림 2를 다시 살펴보시면 Reassemble 모듈과 Fusion 모듈 사이에 temporal layer라는 것이 존재하는데 이게 기존 DepthAnything V2에는 없던 VideoDepthAnything model에만 추가된 모듈입니다. 해당 모듈에서 비디오의 시간축에 대한 특징 관계를 고려하고 있습니다. temporal layer의 구조는 매우 단순한데 그냥 transformer의 self-attention 정도로 구성이 되어있습니다.

비디오를 N개의 프레임(이미지)로 구성되었다고 할 때, 저자들은 학습 또는 추론 과정에서 좌측 같은 형태로 데이터의 shape을 만들어 Encoder에 입력으로 사용합니다. 이는 Encoder가 image-level depth estimation 모델에 입력으로 사용되는 것이기 때문에 encoder 내부에는 temporal 축을 이해하지 않고 그냥 개별 프레임마다 특징을 추출하는 것으로 이해하시면 됩니다.
Decoder 역시 DPT decoder가 image-level depth estimation을 수행하는 것이다보니 reassemble module과 fusion module에서는 좌측과 같이 (BxN) x C x H x W의 이미지 형태 tensor를 처리하지만, Temporal layer에서는 프레임간의 temporal relation을 모델링해야 하기에 우측처럼 spatial axis인 H와 W가 배치축과 함께 묶이고 N길이의 프레임 축에 대해서 attention 연산을 진행하게 됩니다.
마지막으로, 저자들은 빠른 추론 시간을 위해서 temporal layer를 해상도가 상대적으로 낮은 F_{4}, F_{3}, F_{2} 부분에 대해서만 진행하였습니다. 각각은 원본 입력 해상도 대비 1/32, 1/16, 1/8의 해상도를 지니고 있습니다.
Optical Flow based Warping (OWM)
다음은 모델의 학습에 대해서 알아보겠습니다. 우선 기존의 Video depth estimation 연구들은 예측된 깊이 맵들의 temporal consistency를 학습에 반영하기 위해 아래 수식과 같은 규제화를 추가하였다고 합니다.
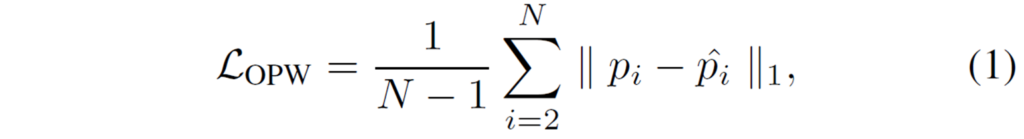
하지만 수식1과 같은 규제 방식은 사실 실제 데이터에서 위배되는 경우가 많습니다. 실제로는 인접한 프레임 사이에서 대응되는 픽셀들이 서로 같은 depth 값을 지니지 않는다는 뜻으로, 아래 그림 예시 살펴보시면 실제 카메라가 정적이지 않고 동적으로 움직이면서 정적인 영역을 촬영할 경우 빨간색 대응점들처럼 시간에 따라 거리 값이 달라지는 경우가 존재합니다. 물론 초록색 대응관계처럼 카메라와 피사체가 모두 동일한 속도로 움직이는 경우에는 시간축이 다르더라도 같은 깊이 값을 가질 수 있는 것이죠.

정리하면, 기존의 논문들이 자주 활용하던 대응관계에 대한 깊이 값이 같도록 하는 규제는 이를 위배하는 경우가 많이 있어 실제로는 비디오 깊이 추정 모델에게 부정적인 영향을 끼치게 됩니다. 그래서 저자들은 이러한 문제를 해결하고자 아래 수식의 규제화로 바꾸어보았습니다.
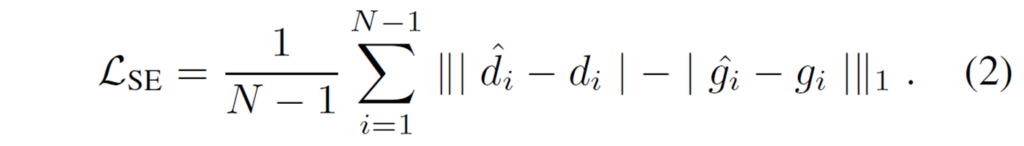
d는 모델의 예측값을, g는 GT depth를 의미합니다. hat이 있는 경우는 수식1과 마찬가지로 인접한 프레임 사이에서 d와 g의 대응관계인 픽셀의 depth value를 나타냅니다. 수식2의 차이점은 GT depth가 i+1과 i번째 픽셀 대응관계에서 depth 변화가 발생했다면 모델의 예측값 d도 이와 동일한 수준의 depth 변화가 발생해야한다는 점입니다. 이러한 변화를 학습하는 방식은 정적인 대상이든 동적인 대상이든 상관없이 모델이 항상 시간축에 대하여 자연스러운 일관성을 학습할 수 있도록 합니다.
다만 수식2도 여전히 한계점이 존재했는데 이는 바로 optical flow를 통하여 pixel correspondence를 계산해야만 한다는 점입니다. 저자들은 학습 과정에서 사전학습된 optical flow 모델을 필요로 한다는 점이 비용적인 측면에서의 한계도 있고, 또 optical flow 값 자체가 부정확할 수도 있을 거라고 판단하였습니다. 따라서 저자들은 인접한 프레임의 동일 좌표에서의 변화를 학습시키는 방식을 최종적으로 제안합니다.
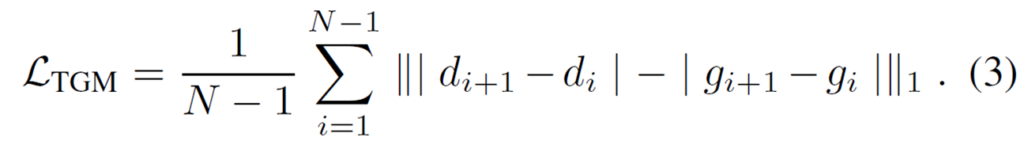
보시면 수식3이 수식2와 거의 동일한데 차이는 수식2에서는 d_{i+1}, g_{i+1} 을 optical flow를 통해 올바른 대응관계가 형성된 픽셀들만을 학습시켰다면 이번에는 그런 것 없이 동일 좌표 위치에서의 pixel들에 대해서 얼만큼의 depth가 변화하였는지를 학습하는 방식을 사용했습니다. 즉 i번째 이미지와 i+1번째 이미지에서 5,5 픽셀 좌표에 해당하는 두 depth 값이 어떻게 변화하였는지를 학습하는 것이죠.
이 방식은 optical flow와 같은 correspondence label이 없이 모델을 학습시킬 수 있다는 이점이 있습니다. 다만 비디오가 어떻게 변화하는지 모르는 상황에서 occlusion, 객체의 테두리 또는 심한 dynamic 상황에서 i번째 프레임과 i+1번째 프레임 사이의 depth 오차가 심하게 차이가 나는 경우가 발생할 수 있습니다. 저자들은 이처럼 변화량의 차이가 너무 크거나 부정확하여 모델이 학습이 어려워할 것을 대비하여 GT depth의 변화 차이가 아래와 같이 0.05보다 작은 경우에 대해서만 학습에 사용하였다고 합니다.
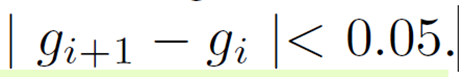
Inference Strategy for Long Videos
다음은 비디오 깊이를 추정하는 방식에 대해 소개드리겠습니다. 비디오의 길이가 짧은지 적당한지, 혹은 엄청 긴지 모르는 상황에서도 최대한 전체 비디오 내에서 예측되는 깊이의 스케일이 일관성 있도록 하는 것은 매우 어려운? 일이라고 합니다. 이전의 비디오 깊이 추정 방식들은 한번에 처리할 수 있는 프레임 수가 N개라고 하였을 때 N개의 프레임들에 대해서만 깊이를 추정하여 이러한 비디오 클립들을 단순히 이어붙였거나, 혹은 이 비디오 클립들 사이에서 대표 스케일 값을 뽑아 정규화를 해주는 식으로 접근했습니다.
하지만 단순히 이어붙이는 방식은 개별 비디오 클립마다 서로 상이한 깊이 분포를 추론하는 바람에 일관성이 상당히 떨어졌으며, 클립들 사이에서 스케일을 조정해주는 방식도 비디오가 점점 길어서 클립의 개수가 늘어날수록 그 일관성이 크게 떨어졌다고 합니다.
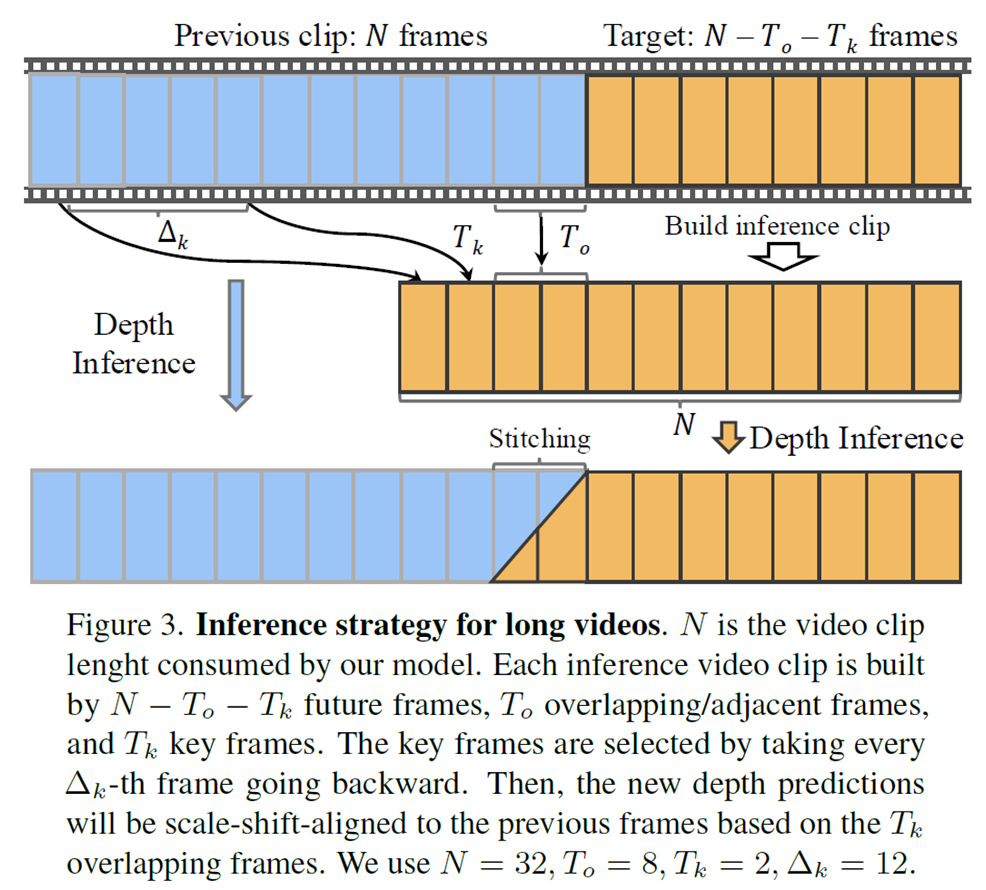
그래서 저자들은 어떠한 길이의 비디오가 들어오더라도 일관성 있는 깊이를 추론할 수 있는 방식을 소개하는데 이는 위의 그림3과 같습니다. 우선 파란색이 모델이 한번에 처리할 수 있는 이전 비디오 클립이라고 한다면, 저자들이 새로 처리해야하는 주황색 길이의 클립에 대하여 추론을 한다고 하였을 때, 이전 클립에서의 주요 frame feature를 함께 가져옵니다. 이를 key frame T_{k}라고 명칭하며, 해당 key frame은 항상 전체 비디오의 1번째 feature에서 시작하여 일정 간격마다 샘플링되어 함께 활용됩니다.
그리고 중간에 overlap frame T_{o}가 존재하는데, 이는 이전 클립과 현재 클립 사이의 매우 인접한 프레임들이기 때문에 이들 프레임도 함께 추가하여 깊이 추론에 활용하고 있습니다.
마지막으로 이렇게 추론한 두 인접한 클립의 깊이 결과값을 단순히 concat하여 이어붙이는 것이 아니라 stitching 과정을 통해 자연스럽게? 붙이게 되는데, 이는 아래 논문 글에서 볼 수 있듯이, overlapping frame에 해당하는 depth 값을 이전과 이후의 scale interpolation 과정을 통해 업데이트를 한다고 합니다.
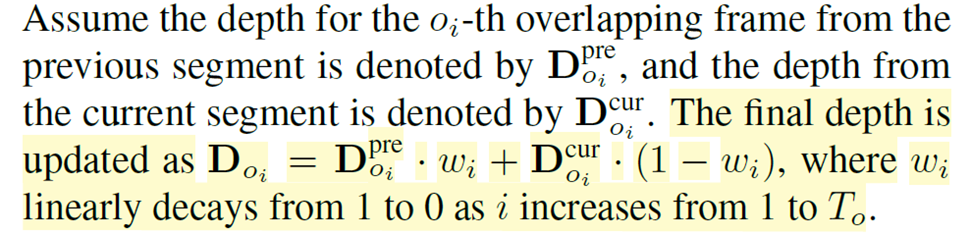
Experiments
그럼 실험 결과 살펴보고 리뷰 마무리 짓도록 하겠습니다. 우선 평가 메트릭부터 간단하게 소개드리자면 평가 지표는 아래와 같습니다.

여기서 AbsRel과 delta1 성능은 기존 monocular depth estimation에서 매우 많이 활용되는 방식으로, Absrel은 상대적인 에러 값을 나타내어 낮을수록 좋은 것이며, delta1은 몇개의 깊이 값이 일정 임계치 미만으로 들어왔는지를 측정하는 유효한 깊이의 비율을 책정하는 방식이라 값이 높을수록 좋은 것입니다.
그리고 Video Depth estimation에서 가장 중요한 temporal consistency를 측정하는 방식으로 TAE 방식의 평가를 진행한다고 하는데, 이는 i번째에서 측정한 depth를 projection matrix를 통해 i+1로 warping시킨 뒤 그와 대응되는 depth의 오차를 계산하는 방식과 그의 역방식으로 구성되어 있습니다. 여기서도 Absrel을 사용한다는 점에서 TAE 역시 낮게 나올수록 모델이 정확하구나라고 생각하시면 됩니다.
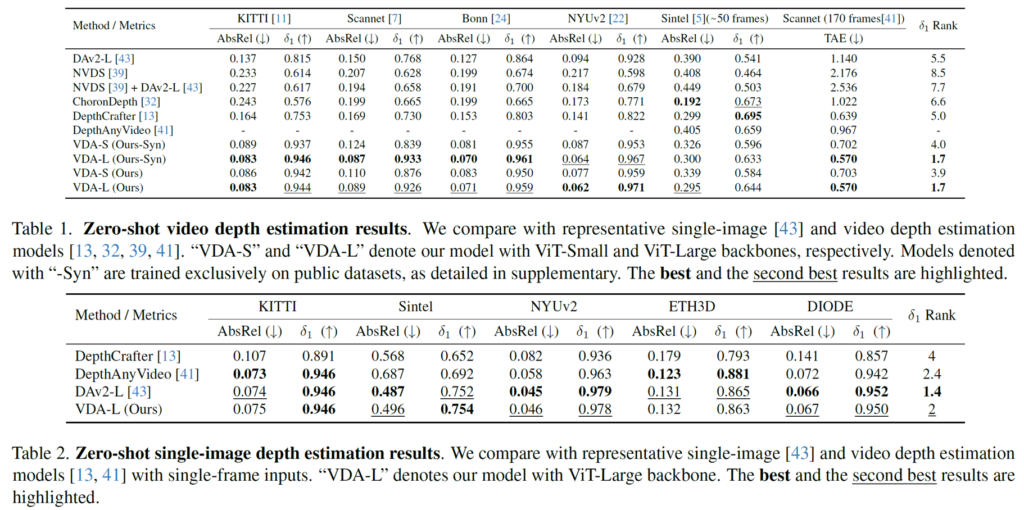
표1은 video depth에 대한 성능을 나타낸 것이고 표2는 single image에 대한 depth 결과값을 나타낸 것입니다. 표1부터 살펴보면 제일 우측에 delta rank라는 것을 볼 수 있는데 5개의 벤치마크에서 저자들의 모델이 가장 등수가 높은 것을 볼 수 있습니다. 이는 평균적으로 delta 값이 가장 높았다는 것을 의미하고, TAE 역시도 저자들의 모델이 0.570으로 가장 낮은 에러값을 보여주어 temporal consistency가 높음을 의미합니다.
또한 저자들의 모델이 비록 Video Depth를 목적으로 한 것이나 single image depth estimation에서도 video depth estimation 모델들 중에서 평균 delta 값이 가장 높은 것을 확인할 수 있습니다. 이는 DAv2의 backbone을 freeze하여 최소한의 구조적 변경만으로 모델을 학습한 것이기 때문에 단일 이미지에 대해서도 깊이 추정 능력이 보존됨을 의미합니다.
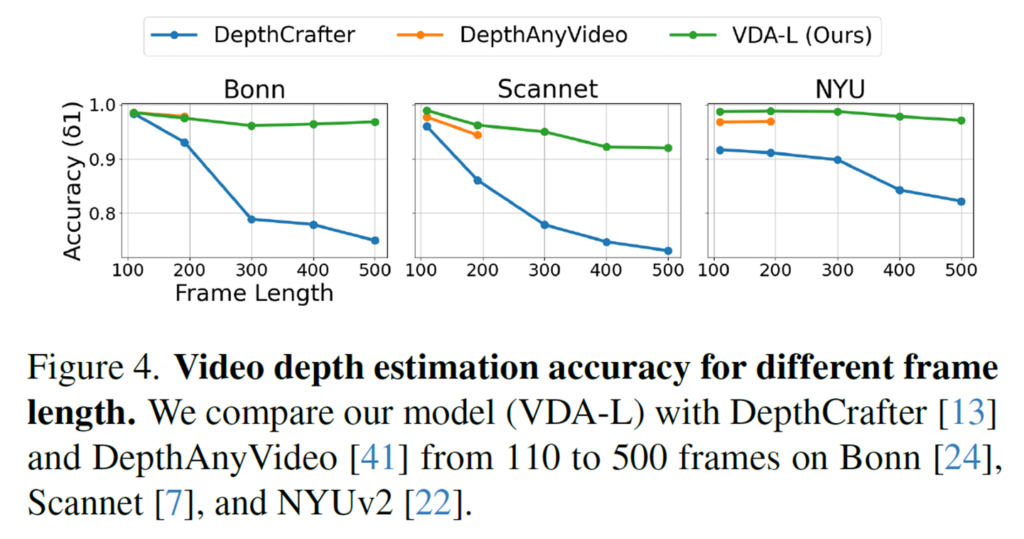
위 그림은 처리하는 비디오의 길이에 따라서 모델의 깊이 추정 성능이 어떻게 나오는지에 대한 결과입니다. 기존의 비디오 깊이 추정 모델의 경우에는 한번에 처리할 수 있는 프레임수가 각각 110과 190정도인데, DepthAnyVideo는 190 이상에 대해서는 처리가 불가능하여 추론 결과가 190프레임까지만 있는 것을 확인할 수 있고, DepthCrafter의 경우에는 110 이상에 대해서도 공개 코드를 기반으로 저자들이 평가했다고 합니다.
결과에 대해서 분석하자면 3개의 모델 모두 한번에 처리할 수 있는 길이까지는 모두 비슷한 수준의 깊이 추정 결과값을 보여주지만, VideoDA를 제외하고는 자신이 처리할 수 있는 길이 이상의 비디오에 대해 깊이를 추론하려고 할 때 성능이 크게 하락하는 것을 볼 수 있습니다. 반면 저자들의 방법론은 임의의 비디오 길이에 대해서 추론을 하기 위한 key frame, overlap frame 그리고 스티칭 방식등을 통해 최소한의 하락으로 유효한 깊이를 추론하는 모습입니다.
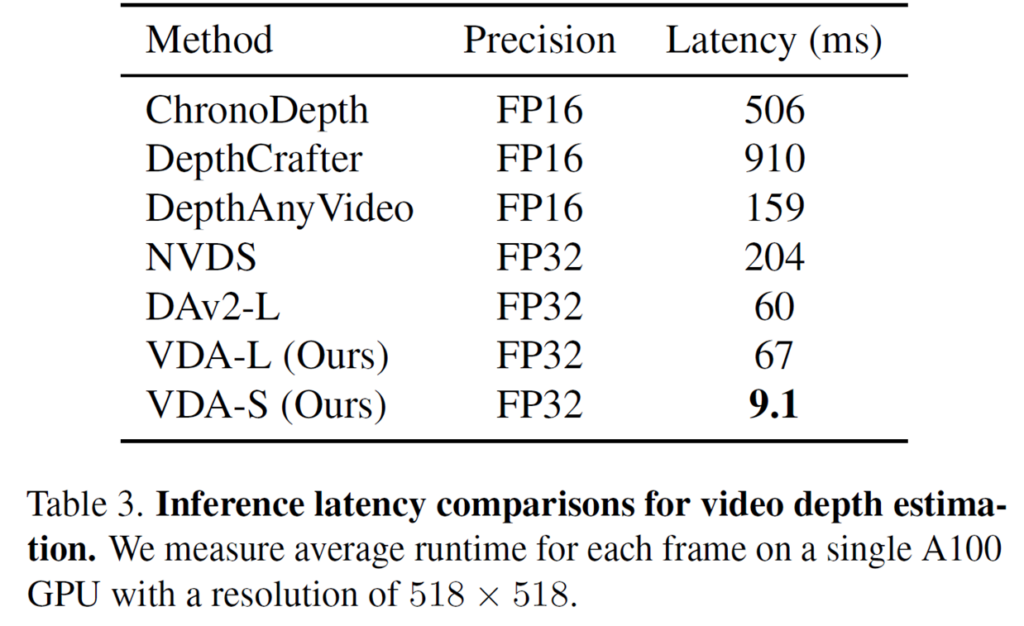
다음은 추론 속도에 대한 부분인데, 모델의 사이즈가 small인 경우에는 프레임 하나를 처리하는데 있어 9.1ms 밖에 걸리지 않으며, Large model의 경우에는 67ms 정도 소모됩니다. precision이 FP32인데 이정도 속도인 것을 보면 FP16으로 추론하면 실시간 추론도 가능하지 않을까 생각이 듭니다. 그리고 다른 video depth estimation 모델보다 훨씬 빠르다는 점에서도 상당히 큰 이점이 있다고 생각합니다.
Ablation
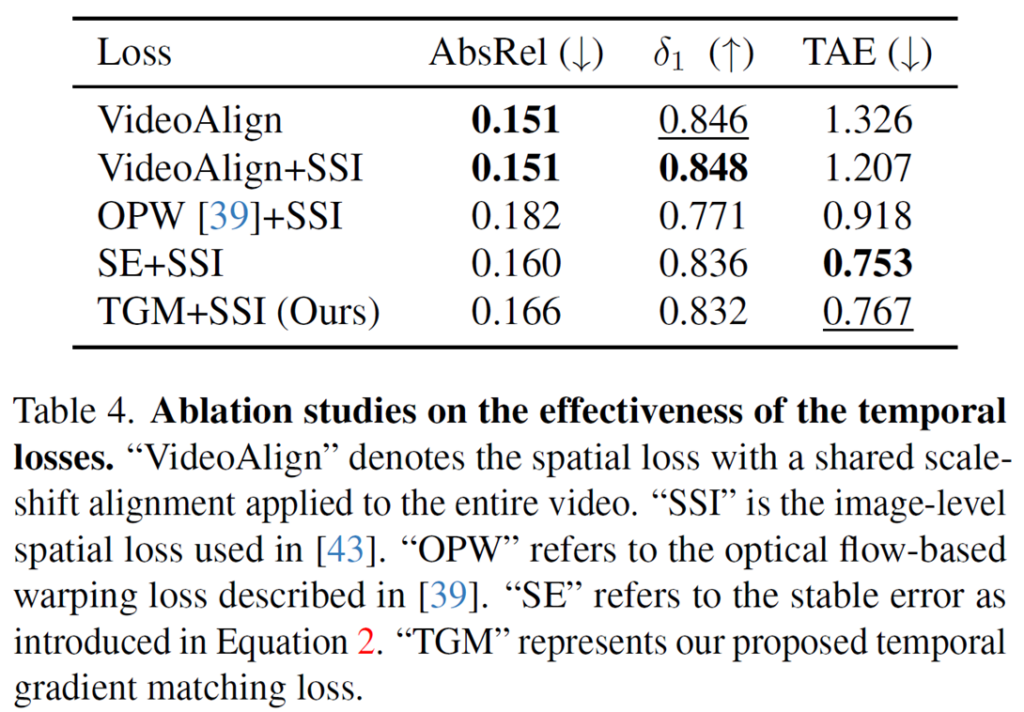
다음은 ablation study입니다. VideoAlign이라는 방법론에서 제안하는 학습 방식은 단일 영상에 대해서 더 높은 성능을 보여주지만, 전체 비디오에 대해 동일한 scale과 shift 값으로 정합을 하는 방식이라서 temporal consistency에 대한 TAE 성능이 제일 낮은 것을 확인할 수 있습니다.
그리고 이전 연구에서 자주 활용한 optical flow warping 방식의 loss는 temporal consistency가 소폭 좋아지긴 했습니다만 해당 loss에 위배되는 지역들로 인해 depth 정확도에 대한 conflict가 발생하여 개별 이미지들에 대한 깊이 정확도가 떨어지는 모습입니다.
반면 저자들이 제안하는 GT depth의 변화 차이를 학습하는 방식을 적용할 경우 단일 이미지에 대한 깊이 추정 성능도 보전되면서 temporal consistency도 크게 좋아지는 것을 볼 수 있습니다. 여기서 SE 방식이 가장 좋은 성능을 보여주고 있지만, SE는 optical flow와 같은 pixel-level corresponding label이 있어야만 학습이 가능한 반면, 저자들의 TGM은 그러한 label 없이도 유사한 성능을 보여주었다는 점에 의미가 있어 보입니다.
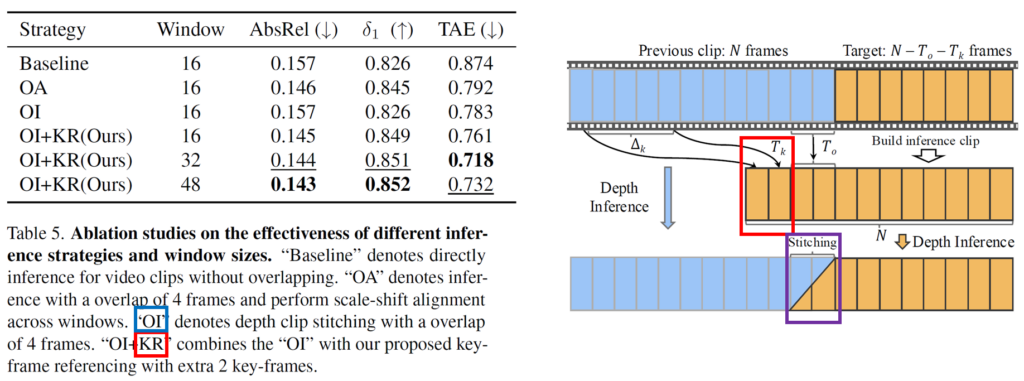
그리고 깊이 추론에서 overlapping frame과 key frame의 역할 그리고 stitching에 대한 ablation study입니다. 결론부터 말씀드리면 overlapping frame과 stitching 방식이 temporal consistency 관점에서 더 좋다는 것을 확인할 수 있으며, key frame을 추가할 경우 깊이의 정확도도 크게 보완되는 것을 확인할 수 있습니다.