안녕하세요 이번에 들고온 논문도 VLM 에서의 token pruning 논문입니다. 바로 리뷰 시작하겠습니다.
Abstract
MLLMs 의 token pruning 논문들에서 단골로 등장하는 말인 입력 단에서의 visual token개수가 너무 많아 컴퓨팅 코스트가 높다는 문제점을 해결하기 위함이 목적이라고 합니다. 특히 고해상도나 비디오 입력에서 이러한 token compression이 도움이 되죠. 이때까지 나온 방법론들은 isolated pipeline 이거나 textual algnment를 무시해와서 성능이 낮았다고 주장합니다.
저자는 VisionTrim이라는 Training free MLLM acceleration 방법론을 제안하고 2가지의 효과적인 plug and play 모듈인 DVTS (Dominant Vision Token Selection) 과 TGVC( Text-Guided vision Complement) 모듈을 통해 context-aware 하고 textual cues를 기반으로한 token merging 을 가능하게 했다고 합니다. 여러 이미지, 비디오 상황과 모델들을 통해 일반화된 장점을 보여준다고 하네요
여기서 isolated 파이프라인이 뜻하는 점은 LLaVA와 같은 VLM 모델들이 LLM에 이미지 및 텍스트 입력을 넣기 전 Image Encoder나 Text Embeder를 거쳐서 토큰화 시키는데, LLM 입력 전에 reduction을 진행할수도 있고 LLM 안에서도 reduction이 가능한 파이프라인이라는 뜻입니다.
Introduction
우선 VLM 은 다들 아시다싶이, LLM 에 이미지 정보를 어떻게 이해시킬지 연구하며 발전되어왔습니다. MLLM이라 불리는 현재의 멀티모달 LLM 들은 visual signals들을 연속적인 토큰형태로 바꾸어 LLM이 이해할 수 있는 토큰형태로 text와 함께 LLM에 입력으로 들어가게 됩니다.
이러한 성능 향상에도 불구하고 이미지의 입력 토큰양이 텍스트에 비해 과도하게 많기에, 실용적인 deployment에는 문제가 되어 해당 task 가 발전되고 있는 상황입니다.
간단하게 발전동향을 설명드리자면 FasterVLM 과 VisionZip 방법론은 앞서 abstract에서 언급했듯이 vision encoder 타고나온 이미지 정보들과, 텍스트 정보들을 활용하여 LLM decoding 이전에 pruning을 진행합니다. 또한 SparseVLM과 FastV 방법론은 LLM decoding 과정에서 pruning을 진행합니다. 이러한 pruning 위치의 차이점을 저자는 specific한 individual components 에서만 pruning을 진행할 수 있다는 한계정도로 언급합니다.
VScan 방법론은 저자와 마찬가지로 2단계 모두에서 pruning할 수 있지만 visual token을 고를때 text의 정보를 활용하지 않고, PyramidDrop 방법론도 text-agnostic 방법론으로 visual token 들을 선택할때 textual information과 정렬해야할 필요성을 간과한다고 합니다.
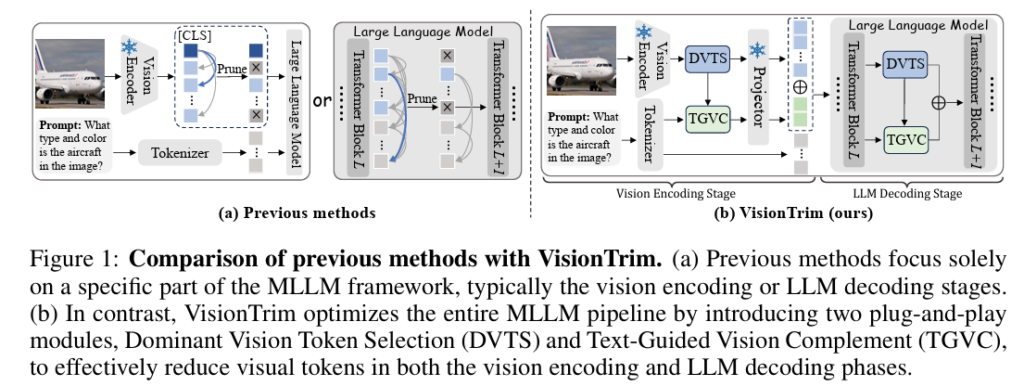
해당 Figure에서 (a)를 살펴보면 앞서 언급한 vision encoding 단계에서의 pruning 과 LLM decoding 단계에서의 pruning 의 차이를 알 수 있고, 저자는 (b) 의 도식도처럼 어느 단계에서나 Plug and Play 방식으로 pruning을 진행할 수 있음을 보여줍니다.
저자는 이러한 문제를 해결하기 위해서 training-free 방식의 MLLM acceleration 방법론인 VisionTrim 을 제안합니다. 저자의 방법론은 두 단계 모든 과정에서 즉 MLLM 의 forward propagation 과정을 모두 고려한다는 이점이 있다고 합니다. 저자의 방법론은 DVTS 와 TGVC 라는 두가지 모듈로 구성되는데, DTVS는 중요한 시각 정보를 전달하는 visual token을 선별하기 위해 global semantics 와 local spatial continuity를 모두 고려하게 되고, global semantic 중요도를 측정하기 위해서는 [CLS] token의 attention score를 활용하는 것에 더해 visual token 들 사이의 feature similarity와 spatial proximity를 동시에 포착하기 위해 Local Token Affinity meassurement, LTAM 알고리즘을 개발했다고 합니다.
두번째로 TGVC 모듈에서는 입력 text instruction과 관련된 pruned visual token들을 clustering 하고 merging 하는 과정에서 textual information을 활용한다고 합니다. 이렇게 얻어진 token들은 이후 DVTS module 내에서 선택된 dominant visual token을 보완하는데 사용하고 visual token reduction 과정에 textual context를 통합하게 되어 저자의 방법론은 시각적인 정보와 텍스트 정보를 implicit하게 alignment할 수 있었다고 합니다.
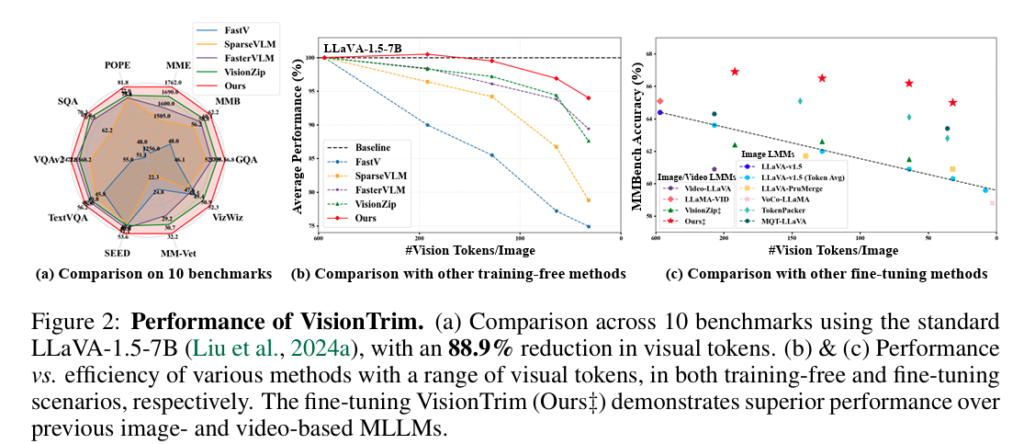
Figure 2에서 보이는 것처럼 저자의 접근법은 다양한 reduction ratio에서 기존 기법들을 일관되게 능가하고, 여러 image-based 및 video-based MLLM 에서 효율성과 정확도 모두 상당한 이점을 제공한다고 합니다.
저자의 연구의 기여도를 요약하면 크게 3가지 입니다.
- Training-free MLLM acceleration을 가능하게 하는 unified vision token compression 프레임워크인 VisionTrim 을 제안, 이는 전체 MLLM pipeline을 최적화함
- DVTS 와 TGVC 라는 두 개의 효과적인 plug-and-play module을 제시하며 이들은 vision encoder와 LLM backbone 의 forward process 를 가속하도록 설계되어 임의의 두 layer 사이에 자연스럽게 통합될 수 있음
- standard 및 high-resolution 설정, imgae-based 및 video-based MLLM을 모두 포함하는 다양한 multimodal bench에서 광범위한 실험을 수행하였고, 그 결과 visionTrim이 SOTA보다 우수하다는 것을 증명함
Method
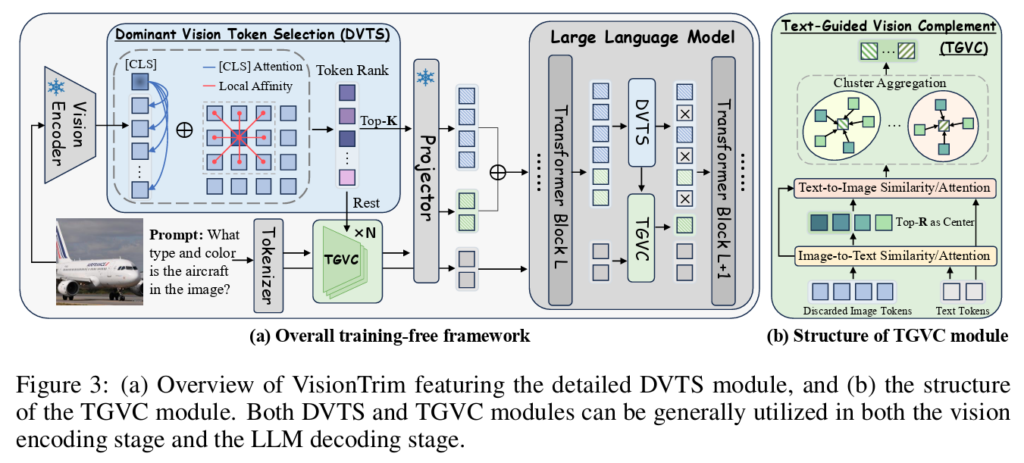
Figure3에 나타난 것처럼 저자의 접근법은 MLLM 의 전체 파이프라인을 포괄적으로 고려하고 vision encoder와 LLM forward procoess를 동시에 가속하는 두 가지 핵심 구성요소로 이루어집니다.
첫번째 구성요소인 DVTS 모듈은 중요한 visual information을 보존하기 위해 token 들을 정교하게 필터링하고 특히 token들이 가지는 global semantics 와 local spatial continuity측면의 중요성에 초점을 둔다고 합니다.
두번째 구성요소인 text-guided vision complement , TGVC 모듈은 textual context를 활용하여, 입력 text instruction과 관련 있는 discarded visiual token들을 clustering 하고 merging하도록 유도한다고 합니다. 이 과정은 중요한 시각적 세부 정보를 통합함으로써 dominant visual token 들을 보완합니다. DVTS와 TGVC는 모두 plug and play 방식으로 vision encoder와 LLM의 임의의 두 layer 사이에 자연스럽게 통합될 수 있다고 합니다.
Dominant Visual Token Selection, DVTS
저자는 visual token compression 과정에서 visual intergrity를 보존하기 위해 새로운 scoring 매커니즘을 도입했다고 합니다. 이 매커니즘은 global semantic significance와 local spatial continuity를 모두 철저히 반영하는데 먼저 [CLS] 토큰이 다른 visual token들에 대해 가지는 attention score를 사용하여 global semantic importance를 평가합니다. 그 다음 Local Token Affinity Measurement, LTAM을 활용해서 dual-kernel method를 사용한 feature similarity와 spatial proximity를 포착하고 이를 통해 local spatial continuity를 보장한다고 합니다.
이러한 상호보완적인 metric들이 이후 adaptive variance-based weighting scheme 을 통해 통합되고, 신뢰할 수 있는 visual token들이 우선적으로 선택된다고 합니다.
Global Semantic Importance
기존 방법들에서 동기를 얻어, [CLS] token 이 모든 image token에 대해 가지는 attention distribution을 global semantic significance를 측정하는 자연스러운 기준으로 사용한다고 합니다. 이는 CLIP 기반의 vision encoder의 마지막에서 두번째 layer, 즉 penultimate layer에서 attn weight를 추출하고 [CLS] token의 attention pattern을 활용한다고 합니다.
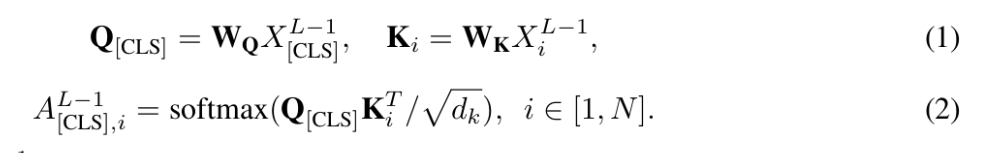
여기서 X는 각각 (L-1)th layer에서의 [CLS] token 과 i번째 visual token의 hidden state를 의미하고, W는 learnable projection Matrix입니다. (여기서 projection은 ViT내부의 MLP 로 생각하면 됩니다.)
그리고 i번째 visual token의 global importance score는 모든 H개의 head에 대한 평균 attn score로 정의됩니다.
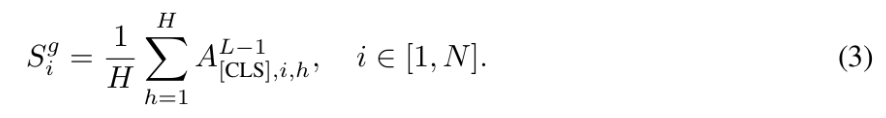
그리고 [CLS] toekn의 attention 매커니즘을 기반으로, 각 visual token이 image의 global semantic representation에 얼마나 기여하는지를 효과적으로 평가합니다. 계산된 global score는 이후 모든 visual token 에 대한 probability distribution이 되도록 normalize 됩니다.
Local Spatial Continuity
기존 연구들에서 영감을 받아 저자는 visual token의 local spatial continuity를 효과적으로 포착하기 위해 LTAM 알고리즘을 도입한다고 합니다.
LTAM은 feature similarity와 positional proximity를 동시에 고려하기 위해 dual kernel affinity 매커니즘을 사용한다고 합니다. 이는 위치 (x,y)에 있는 i번째 token 에 대해 local importance S는 k X k 크기의 local kernel 안에 있는 neighboring token들과의 affinity를 계산함으로써 결정된다고 합니다.
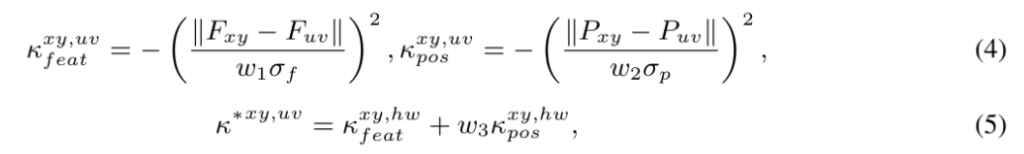
여기서 F_xy와 P_xy 는 각각 위치 (x,y) 에 있는 token의 feature vector와 spatial coordinate를 의미하고 시그마값은 feature difference와 positional difference의 표준편차입니다.
쌍 (h,w) 는 이웃 set N 에서 샘플링되며 w값들은 단순 밸런싱 파라미터들입니다. 즉 위치 (x,y) 에 있는 i번째 token들의 local importance는 모든 이웃 token들에 대한 affinity score를 평균내고 이를 확률 분포로 변환함으로써 계산됩니다.
여기서 각 점수에 음수가 붙어있는 이유는, 거리가 가까울수록 score에 대한 패널티를 적게주기 위함입니다. 거리가 가깝거나 패치가 유사하면 값이 낮아지게 되는데, 거리가 멀면 값이 커지게 되므로 여기에 음수를 붙여 중앙 패치기준 주변패치의 sim이 낮다면 패널티를 많이주게됩니다. 저자의 LTAM을 간단하게 생각해보면 배경패치든 객체패치든 주변과 유사할수록 좋은 점수를 가진다는 것을 알 수 있는데, 이는 앞서 언급한 [CLS]기반의 dominant한 token selection과 더해져 시너지가나는 것 같습니다.
Adaptive Variance-based Weighting
global importance score와 local importance score를 통합하기 위해, 저자는 아래와같은 수식으 사용한다고 합니다.
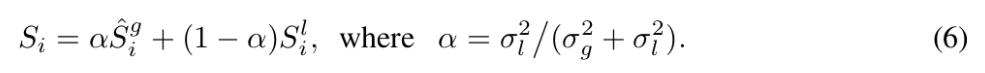
여기서 시그마는 각각 global 과 local importance에 대한 variance를 의미하고, 이 adaptive weighting scheme은 consistency에 기반하여 더 신뢰할 수 있는 signal을 자동으로 우선시하고 robust 한 token selection을 보장한다고 합니다.
최종 importance score는 전체 token set 에서 informative token 상위 K개를 선택하는데에 사용됩니다.
Text-Guided Vision Complement , TGVC
선택된 dominant token 들은 주요 visual information 을 포착하지만, 입력 instruction과의 관련성을 완전히 반영하지 못할 수 있습니다. 이로 인해 Textual information과의 misalignment 가 발생하거나, 중요한 visual element가 손실될 수 있습니다.
저자는 이러한 문제점을 해결하기 위해 Text-Guided Vision Complement, TGVC를 도입하는데 이 모듈은 text instruction 을 활용하여 선택된 dominant vision token을 보완합니다.
저자는 CLIP 의 text encoder를 활용하여 remaining visual token (dominant로 선택되지 않은 버려지는 token) 과 text token 사이의 sim을 계산하고,상위 R개의 token을 clustering center로 식별합니다. 그 다음 이 center들은 remaining visual token들이 R개의 cluster에 할당되게 합니다.각 cluster가 merge되어 text와 가장 관련성이 높은 최종 R개의 visual token을 만들어내고 이를 vision complement token으로 부릅니다.
Clustering centers
dominant token selection 이후 남아잇는 (dominant로 선택되지 않은 버려지는 token) visual token을 text와의 sim 계산에 활용하면

위와 같고, 그 다음 모든 text token에 대한 sim score를 평균내어 token-level importance score를 얻습니다.
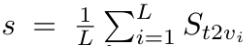
이중 상위 R개의 token 이 clustering center로 선택됩니다. 여기서 clustering center로 선택된 token들은 의미적으로 dominant token에서는 빠졌지만, text instruction과 평균적으로 관련성이 높은 remaining visual token들이라고 이해할 수 있습니다.
Token Assignment
각 remaining token에 대해 저자는 text-guided sim을 사용하여 각 clustering center에 대한 assignment score를 계산합니다.
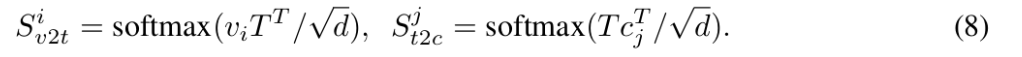
assignment scoer는 위의 S_v2t 와 S_t2c를 곱하여 사용하게되고 각 token은 가장 높은 similarity score를 가지는 clustering center에 할당됩니다. 이 내적을 이해해보자면 우선 center는 남겨진 애들중 text 단어들과 가장 유사하다고 생각되는 patch들 입니다. 그리고 각 남겨진 center가 아닌애들이 text단어들중 어디와 유사한지를 구한 후 각 center와의 내적을 통해 어떤 center와 의미론적으로 비슷한지를 점수화한다고 생각하면 됩니다.
Cluster Aggregation
각 cluster에 들어간 token들을 weighted average로 합치게 됩니다.
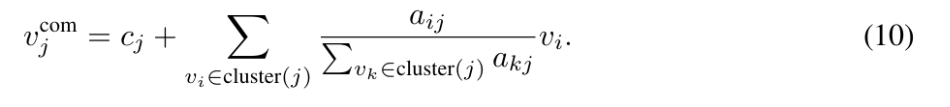
의미는 각 token center는 유지하고 그 center에 배정된 주변 token들을 text-guided score로 가중평균해서 더하게 됩니다. 즉 complement token하나는 단순나 center가 아니라 관련 remaining tokens 들의 weighted aggregation이 됩니다. 이 token들을 나중에 dom 토큰들과 붙이게 됩니다.
Multi-Stage Pruning Strategy
저자의 방법론은 앞서 언급했듯이 LLM decoding stage에서도 동작합니다.
구체적으로 [CLS]토큰을 활용하지 않고 첫 번째 generated token 의 attention distribution을 모든 image token 에 대한 global semantic 정보로 활용한다고 합니다. layer L 에서 다음과같이 계산됩니다.
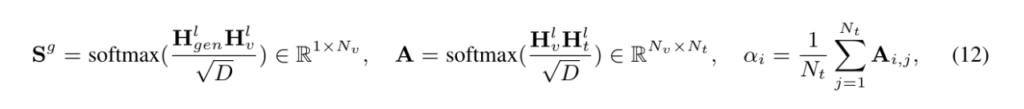
Experiments
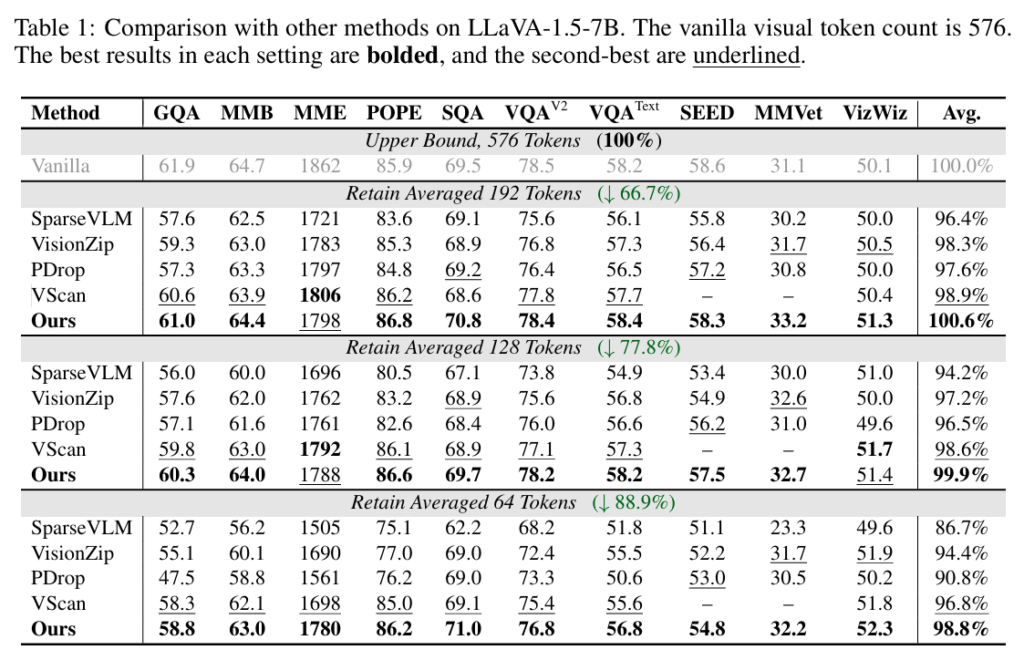
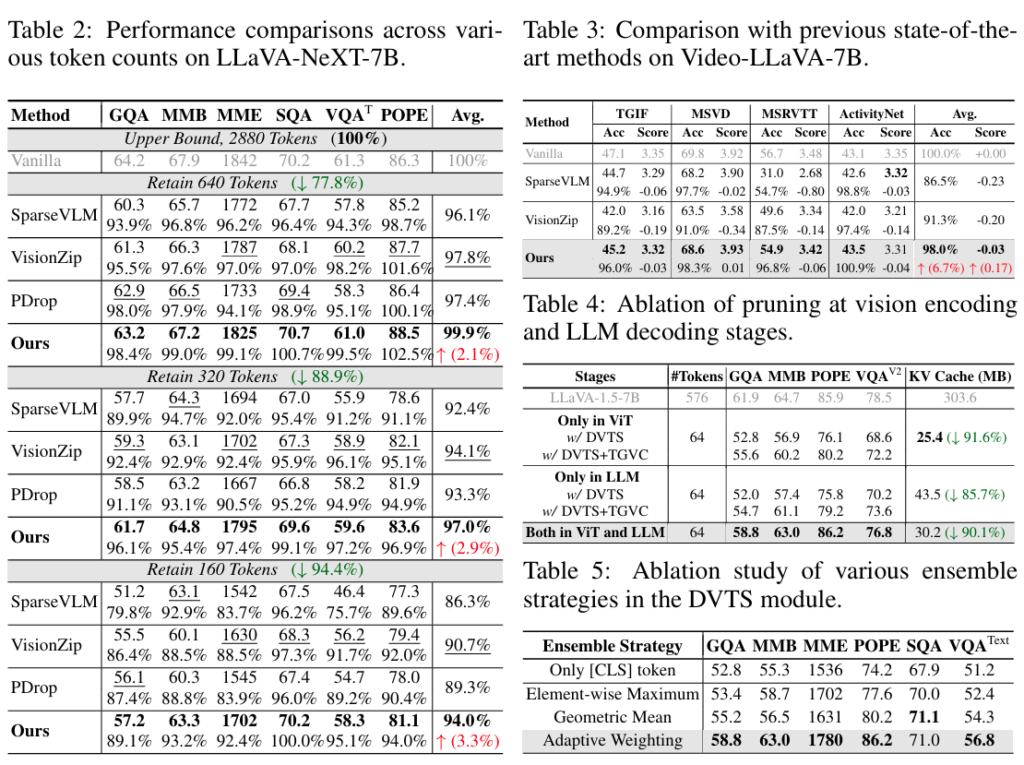
우선 Table 1,2 는 LLaVA-1.5-7B 와 LLaVA-NeXT-7B 로 다른 pruning 논문들에서도 흔히 리포팅하는 메인 테이블입니다. 저자의 방법론이 방법도 복잡해보이고 굉장히 휴리스틱해보이긴 하지만 실제 계산되는 computational cost가 엄청 크지는 않을 것 같아서.. 나중에 비교할때 latency리포팅을 잘 해봐야할 것 같습니다. 성능도 현재까지 읽은 모든 논문중 가장 SOTA인것 같네요. Table 3는 video-LLaVA에서 리포팅한 성능이며 타 논문들과 비슷하게 decoder 계열에서 한개, 보통 VisionZip을 리포팅하는 추세인 것 같습니다.
Table 4가 꽤 제 기준에서는 꽤나 흥미로운데, 저자의 방법론이 ViT에서만 pruning 하는것, 그리고 LLM 에서만 하는것보다 2 stage에서 모두 pruning 하는 것이 성능이 가장 좋음을 확인할 수 있습니다. 성능이 엄청 많이 오르는데.. 지금 제가 실험중인 SOTA 실험 성능들이 저자의 ViT와 LLM 동시 pruning 방법론보다 조금씩 낮은상태라 이후 실험에 있어서 참고해볼만한 Table인 것 같습니다.
저자의 DVTS, TGVC가 휴리스틱함에도 불구하고 저와 마찬가지인 ViT 기반의 pruning 에서는 지금 제 방법론이 성능이 더 높은 것 같네요
그리고 저자의 방법론중 Table 5 에서의 ablation도 꽤나 도움이 되는 정보인데 비슷한 정보를 가지는 patch 토큰들에 대해서 Adaptive weighting 하는 것이 성능향상폭이 큰 것 같습니다.
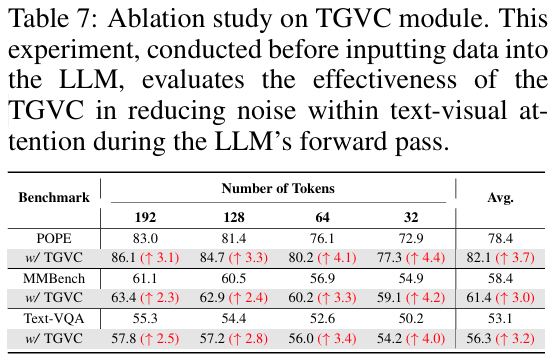
해당 Table은 llm decoding 이전에 TGVC모듈이 얼마나 효과적인지를 3가지 벤치마크에 대해 보여주는 것입니다. compression ratio 가 커질수록 TGVC의 영향력이 커지네요
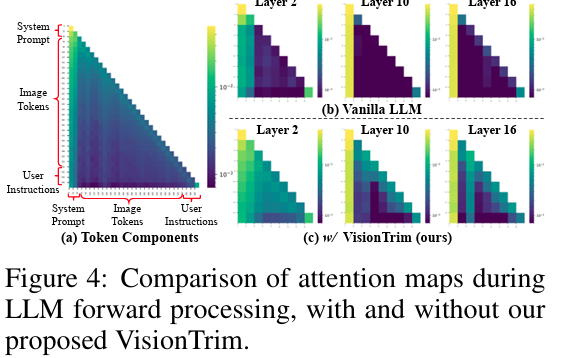
해당 figure는 좀 흥미로운데, 저자의 방법론을 적용하면 LLM forward 과정에서 token 들의 attention 분포가 깔끔하게 바뀌는 것 같습니다. token compression 이후 attention 분포가 더 compact하고 redundancy가 줄었다고 하네요. 뭔가 이전에 제가 알고있던 attention shfit 문제가 완화되는건가 싶습니다..

해당 figure는 저자의 dual attention 와 기존의 [cls] 기반의 시각화 차이를 보여줍니다.

해당 figure는 TGVC모듈을 여러번 적용하면서 어떠한 token 들이 남는지를 보여주는 시각화 입니다. 앞서 cluster aggregation에서의 수식을 T번 적용할 수 있어서 진행하면서 더욱 textual 정보를 담는 토큰만 남게 됩니다.
Efficiency analysis
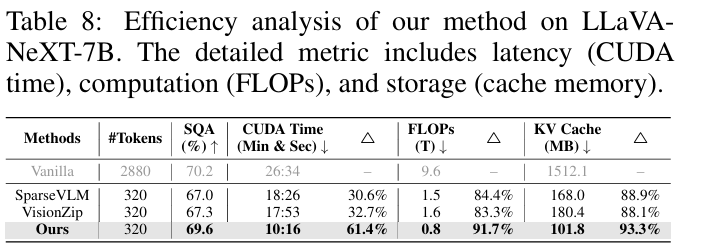
이 섹션에서는 저자의 방법론이 얼마나 효율적인지를 보여주는 것으로 CUDA time, FLOPs, storage memory를 측정했고, SQA는 데이터셋의 성능입니다.
Conclusion
저자의 방법론은 vision encoding stage와 llm decoding stage 모두에서 사용될 수 있는 효과적인 plug and play 방법론입니다. 주장하는 모듈의 접근법도 타당하고 성능이 매우 높아서 이 논문성능 이상의 방법론이 나오기가 쉽지않을 것 같습니다.
저자는 limitation으로 token 88.9% 를 감소하면서 98.8%의 성능을 유지한다는데 완전한 손실이 없는 것이 아니고, 저자는 visual token 의 redundancy를 효과적으로 줄인다면 효율성이나 lossless method 측면에서는 부족하다고 언급합니다.
감사합니다.
안녕하세요 인택님, 좋은 리뷰 감사합니다.
TGVC 모듈은 Dominant Token으로 선택되지 않은 나머지 토큰들을 텍스트와의 유사도 기반으로 클러스터링하고 가중 평균하여 병합한다고 이해했습니다.. 압축률이 높아질수록 이 모듈의 영향이 커진다고 하였는데, 텍스트와 우연히 유사도가 높게 측정된 배경 노이즈나 무관한 패치들이 하나의 토큰으로 압축되면서 오히려 LLM에 잘못된 시각적 Hallucination을 유도할 위험은 없을까요?
안녕하세요 재윤님 좋은 답글 감사합니다.
의문점으로 제시하신 hallucination 문제점이 생길수도 있다고 생각합니다.
모델의 성능과 hallucination이 사실 반비례하지 않을수도 있습니다. hallucination이 커지더라도 모델의 성능이 drop 되지 않을수도 있기에, 그러한 점을 체크하기 위해서는 hallucination 전용 벤치마크등을 찍어봐야 안다고 생각합니다. 다만 다른 방법론들을 읽어보았을때 diversity 기반 방법론은 hallucination이 좀 더 심하다는 연구도 존재하긴 합니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
LTAM은 feature similarity와 spatial proximity를 함께 고려해서 주변 token과 유사한 token을 중요하게 보는 방식으로 설명해주셨는데 단순 궁금증인데 배경처럼 넓고 반복적인 영역도 local continuity가 높게 나올 수 있는 상황인 안생기는 건가요,,? 뭔가 local continuity가 높은 token이 항상 정보량이 높은 token이라고 볼 수 있는지 의문이 들었습니다. 감사합니다.
안녕하세요 우현님 좋은 댓글 감사합니다.
충분히 우려하는 그런 상황이 생길수도 있습니다만, 전체 dataset 에서 아마 일부분일거고, 해당 방법론이 text 를 사용하는 방법론이기에 아마 이미 질문과 어느정도 관련있는 부분이 살아남아서 성능 drop 에 크게 영향을 주는 것 같지는 않습니다.
감사합니다.