오늘은 생성형 모델인 LLM을 임베딩 모델로 변환하는 것과 관련된 페이퍼를 리뷰해보겠습니다.

Venue: Arxiv 2024
Authors: Yixuan Tang, Yi Yang
Affiliation: The Hong Kong University of Science and Technology
Title: Pooling And Attention: What Are Effective Designs For LLM-Based Embedding Models?
0. Background
최근 E5, VLM2Vec, VLM2Vec-V2 같은 논문들을 리뷰하면서 반복적으로 보게 되는 흐름이 있습니다. 바로 기존 LLM을 단순한 generation model로만 사용하는 것이 아니라, retrieval에 사용할 수 있는 embedding model로 바꾸려는 시도입니다. 다시말해, 기존 임베딩 모델에는 CLIP 같은 계열을 활용했다면, 이젠 그러지 말고 LLM 을 임베딩 모델의 백본으로 활용하자는 것이죠.
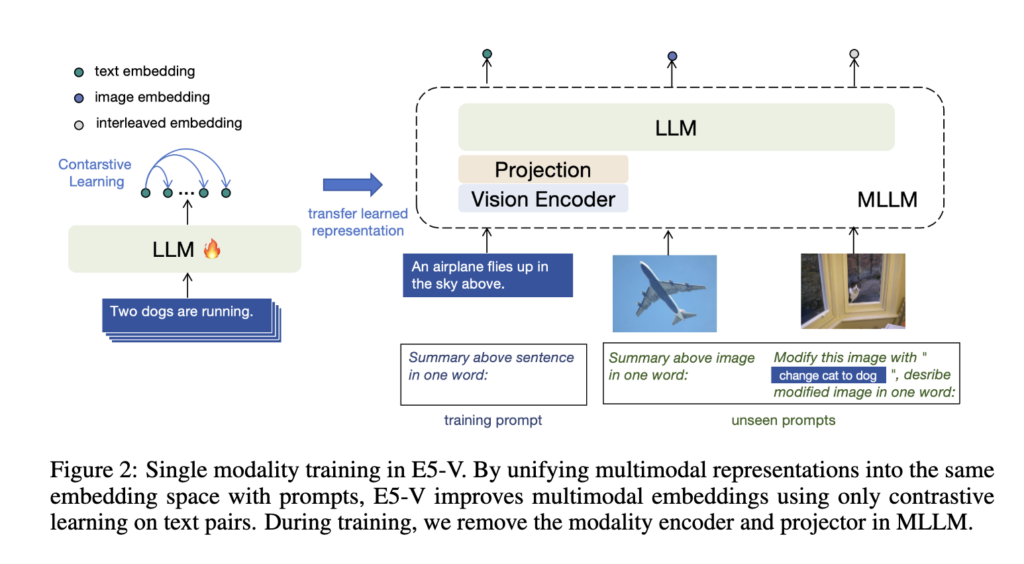
기존 LLM을 embedding model로 활용하기 위해서는, 결국 LLM 내부의 hidden state 중 어떤 representation을 최종 feature로 사용할지가 중요합니다.
아시다시피, LLM은 입력 sequence를 처리하면서 각 token마다 hidden state를 생성하죠? 이 LLM을 임베딩 모델(즉, retrieval)을 위한 feature를 사용하려면 LLM의 여러 hidden state 중 하나를 선택하거나 pooling하여 하나의 embedding vector로 만들어야 합니다.
기존 연구에서는 보통 입력 마지막에 EOS token을 붙이고, 마지막 layer에서 나온 EOS token의 hidden state를 문장 전체를 대표하는 embedding으로 활용하곤 했습니다. 이후 이 embedding을 contrastive learning으로 학습하여, 의미적으로 가까운 query-document pair는 가깝게, 관련 없는 pair는 멀어지도록 embedding space를 조정하는 방식이죠.
이걸 읽으셨다면 다들 의문이 들 것 같습니다. 어떤 hidden state를 embedding으로 쓰는 지에 따라서 성능이 천차만별이겠구나! 라는 점에서요
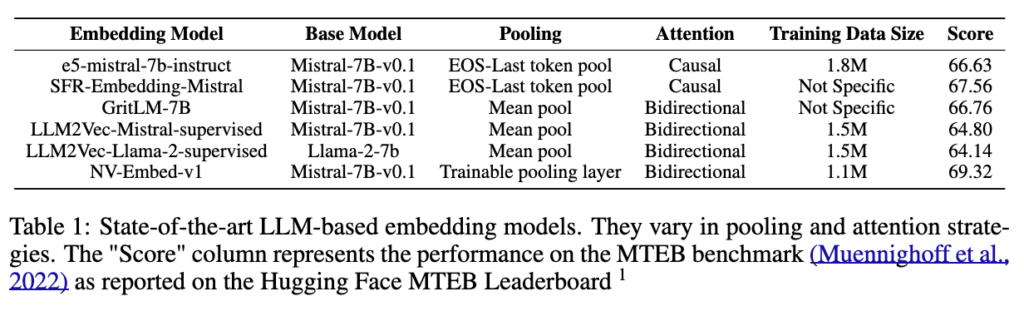
실제로 기존 연구에서도 feature를 뽑는 방법이 다양했습니다. E5-mistral은 EOS-last token pooling과 causal attention을 사용하고, LLM2Vec은 mean pooling과 bidirectional attention을 사용하며, NV-Embed는 trainable pooling layer와 bidirectional attention을 사용합니다. 즉, 모두 LLM을 embedding model로 바꾸려는 시도이지만, pooling과 attention 설계는 모두 다릅니다.
문제는 기존 모델들이 base model, training data, 학습 설정까지 모두 다르기 때문에, 성능 차이가 정말 pooling 때문인지, attention 때문인지, 아니면 데이터 때문인지 알기 어렵다는 점입니다. 그래서 지금 리뷰하는 논문에서 집중한 문제는 다음과 같습니디:
LLM-based embedding model에서 pooling과 attention은 실제로 얼마나 중요한가?
1. Introduction
본 논문은 LLM을 embedding model로 사용할 때 필요한 두 가지 설계 요소에 집중합니다. 하나는 pooling strategy이고, 다른 하나는 attention strategy입니다.
Pooling은 LLM의 hidden state에서 최종 embedding vector를 어떻게 뽑을지에 대한 문제입니다. 마지막 EOS token을 사용할 수도 있고, 전체 token을 평균낼 수도 있으며, 별도의 trainable pooling layer를 붙일 수도 있습니다. Attention은 LLM의 causal attention을 그대로 유지할지, 아니면 embedding task에 맞게 bidirectional attention으로 바꿀지에 대한 문제입니다.
여기서 저자들이 주목한 첫 번째 문제는, 대부분의 embedding model이 마지막 layer의 hidden state에 의존한다는 점입니다. 하지만 LLM의 각 layer가 정말 같은 정보를 담고 있을까요?
이 질문을 확인하기 위해 저자들은 먼저 layer별 hidden state를 분석하였습니다.

상단 그림 1은 서로 다른 layer의 EOS token hidden state 사이의 correlation을 시각화한 것입니다. 그림을 보면 인접한 layer끼리는 correlation이 높지만, 멀리 떨어진 layer들은 correlation이 낮습니다. 즉, LLM의 각 layer가 단순히 같은 정보를 반복해서 담고 있는 것이 아니라, layer마다 서로 다른 정보를 담고 있을 가능성이 있다는 것이죠.
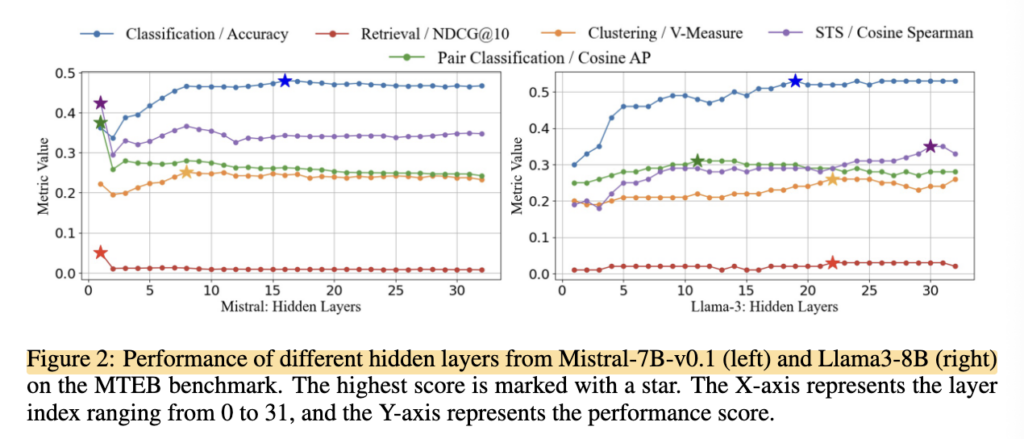
상단 그림 2는 각 layer 임베딩을 사용한 성능 측정 결과입니다. 각 layer의 hidden state를 embedding으로 사용해 MTEB 성능을 측정했을 때, 마지막 layer가 항상 가장 좋은 성능을 보이지 않았습니다. Mistral에서는 앞쪽 layer가 더 좋은 경우가 있었고, Llama3에서는 중간 layer가 더 효과적인 경우도 있었죠
이 두 가지 실험 결과를 바탕으로 저자가 내린 결론은, 기존처럼 마지막 layer 하나만 뽑아서 embedding으로 쓰는 방식이 생각보다 최선이 아닐 수 있다는 것입니다.
그래서 저자들은 Multi-Layers Trainable Pooling이라는 새로운 pooling 방식을 제안하였습니다. 핵심은 마지막 layer만 사용하는 것이 아니라, 모든 layer의 hidden state를 함께 활용하는 것이죠. 바로 method 섹션에서 그 과정에 대해 설명드리겠습니다.
3. Method
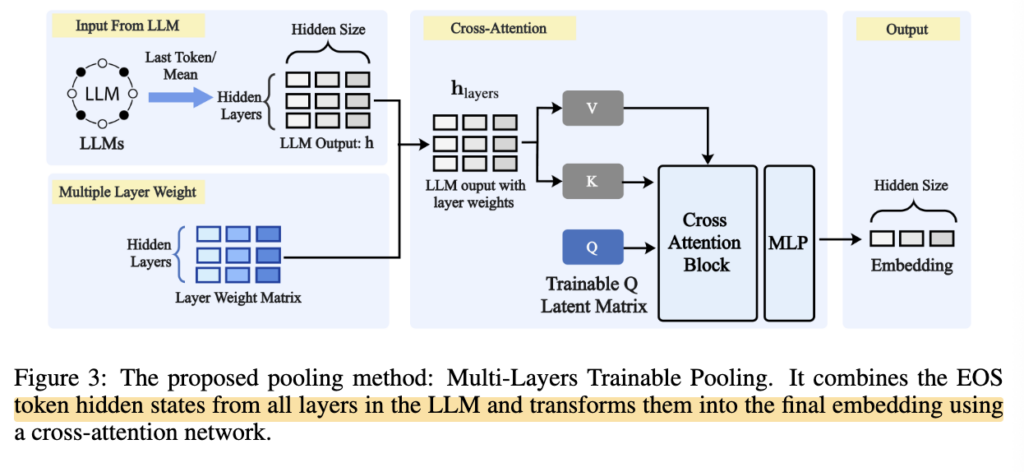
그럼 이제 그림 3을 조금 더 구체적으로 살펴보겠습니다. 바로 저자들이 제안한 Multi-Layers Trainable Pooling을 나타낸 것인데요. 이는 크게 세 단계로 구분할 수 있습니다. 첫 번째는 LLM의 여러 layer에서 hidden state를 가져오는 것이고, 두 번째는 layer별 중요도를 학습하는 것이며, 마지막은 cross-attention을 통해 이 정보들을 하나의 embedding으로 합치는 것입니다.
2.1 Input: Hidden States Across All Layers
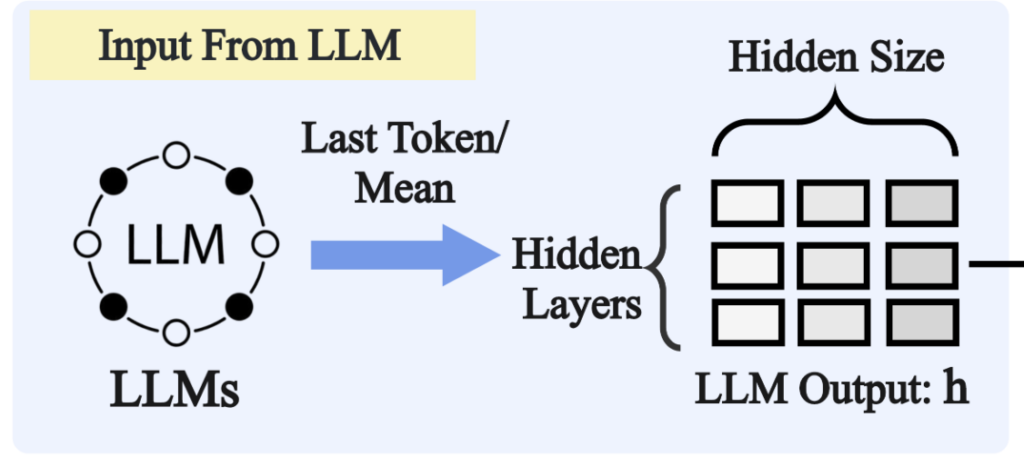
먼저 기존 pooling 방식과 가장 큰 차이는 입력으로 사용하는 hidden state의 범위입니다. 기존 EOS-last token pooling은 마지막 layer의 EOS token hidden state만 사용했습니다.
반면 저자들의 Multi-Layers Trainable Pooling은 마지막 layer만 사용하지 않고, LLM의 모든 layer에서 hidden state를 가져왔습니다.
여기서 attention 방식에 따라 입력을 가져오는 방식이 조금 달라지는데요. causal attention을 사용하는 경우에는 EOS token hidden state를 layer별로 가져오고, bidirectional attention을 사용하는 경우에는 각 layer에서 token 방향으로 평균을 내어 사용합니다.
왜냐하면, causal attention에서는 앞쪽 token이 뒤쪽 정보를 볼 수 없기 때문에, 전체 sequence 정보를 모으기 위해 EOS token을 사용하는 것이 자연스럽고, bidirectional attention에서는 모든 token이 서로를 볼 수 있으므로 mean pooling을 사용했다고 합니다.
2.2 Layer Weight Matrix
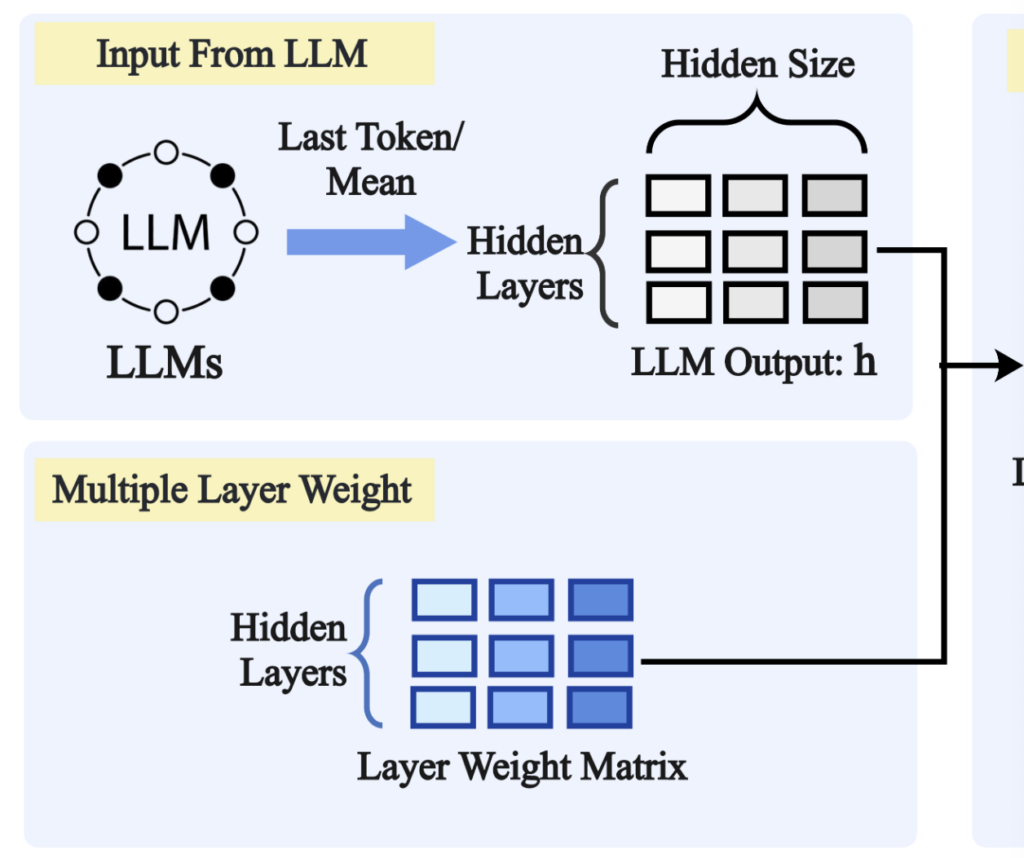
다음으로 저자들은 layer별 중요도를 학습하기 위해 trainable layer weight matrix를 추가합니다. 모든 layer의 hidden state를 가져온다고 해서, 모든 layer가 최종 embedding에 똑같이 중요하다고 보기는 어렵기 때문입니다.
2.3 Cross-Attention Network
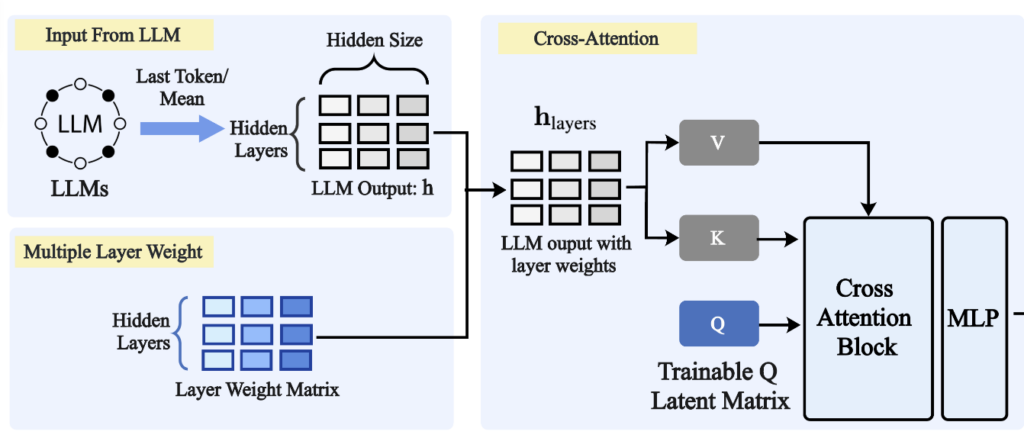
이후 layer weight가 반영된 hidden state들은 cross-attention network로 전달됩니다. 그림 3에서 가장 중요한 부분이 바로 이 cross-attention block입니다.
여기서 hidden state들은 key와 value로 변환되고, 별도의 trainable query matrix가 이 key-value 정보에 attention을 수행합니다. 쉽게 말하면, 여러 layer에 흩어져 있는 정보 중 최종 embedding을 만들 때 필요한 정보를 query가 선택적으로 가져오는 구조라고 볼 수 있습니다.
이 방식은 단순 pooling과 차이가 있습니다. 평균 pooling은 모든 정보를 동일한 방식으로 섞어버리지만, cross-attention은 어떤 layer의 어떤 정보가 더 중요한지를 학습하면서 조합할 수 있습니다.
마지막으로 cross-attention의 출력은 MLP를 거쳐 최종 fixed-size embedding vector로 변환됩니다. 이렇게 만들어진 embedding은 기존 방식과 동일하게 query-document similarity 계산에 사용되는 것입니다.
3. Experiments
그럼 이제 저자들이 제안한 Multi-Layers Trainable Pooling이 실제로 효과가 있었는지 살펴보겠습니다.
3.1 implementaion
기존 연구들은 서로 다른 base model, 서로 다른 training data, 서로 다른 setting을 사용했기 때문에 pooling과 attention의 효과만 따로 비교하기 어려웠습니다. 그래서 본 논문에서는 동일한 base LLM과 동일한 training data를 사용하고, pooling과 attention 조합만 바꿔가며 비교합니다.
저자들은 Mistral-7B를 기본 모델로 사용하고, 총 5가지 조합을 실험했습니다.

평가는 MTEB benchmark에서 진행되었고, STS, Classification, Retrieval, Clustering을 중심으로 결과를 비교합니다. 또한 단순히 평균 점수만 비교한 것이 아니라, Wilcoxon Signed Rank Test를 사용해 통계적으로 유의미한 차이인지도 함께 확인했습니다.
3.2 Pooling Strategy
먼저 Table 2는 pooling strategy에 따른 성능 차이를 보여줍니다.
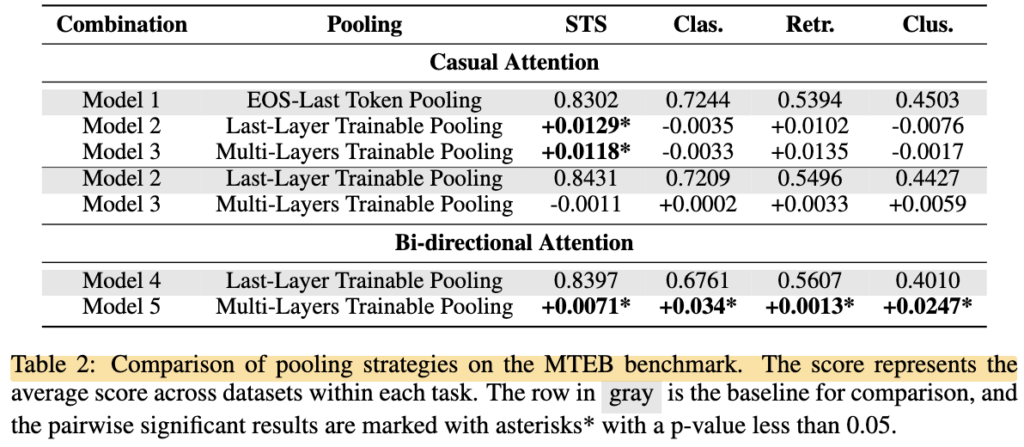
여기서 저자가 비교하고 싶었던 것은 “EOS token 하나만 쓰는 것보다, trainable pooling을 쓰는 것이 정말 더 좋은가?” 였던 것 같습니다.
결과를 보면 causal attention을 사용하는 경우, trainable pooling은 STS task에서는 유의미한 성능 향상을 보였습니다. 하지만 classification, retrieval, clustering에서는 뚜렷한 개선이 나타나지 않았습니다. 즉, trainable pooling을 붙인다고 해서 모든 task에서 무조건 좋아지는 것은 아니었습니다.
반면 bidirectional attention을 사용하는 경우에는 조금 결과가 달랐는데, 이때는 Multi-Layers Trainable Pooling이 Last-Layer Trainable Pooling보다 STS, Classification, Retrieval, Clustering 모두에서 더 좋은 성능을 보였습니다.
이 결과를 보면 Multi-Layers Pooling 자체는 확실히 가능성이 있지만, 그 효과는 attention 방식과 함께 봐야 한다는 것을 알 수 있습니다. 다시말해, 단순히 multi-layer를 쓰면 좋다 라기보다는, bidirectional attention과 결합되었을 때 더 잘 작동하는 것으로 보입니다.
3.3 Attention Strategy
다음으로 Table 3은 attention strategy의 영향에 대한 비교 실험입니다.
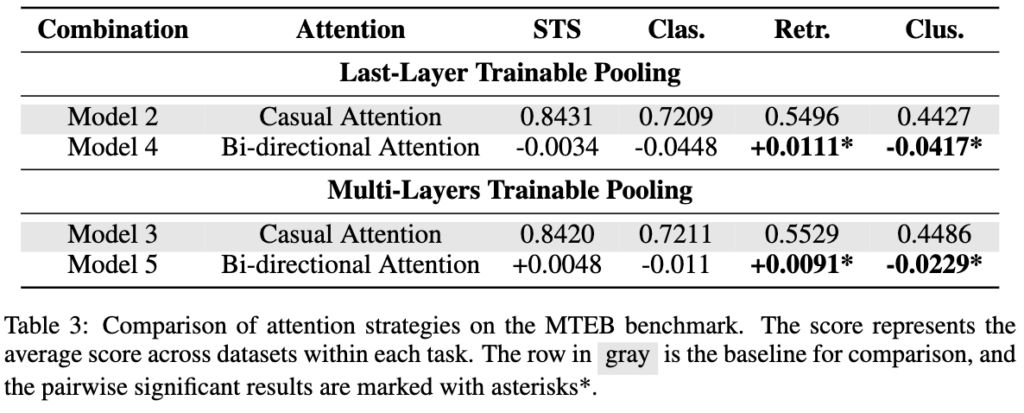
LLM의 causal attention을 그대로 두는 것이 좋을지, 아니면 bidirectional attention으로 바꾸는 것이 좋을지를 확인해보고자 한 것인데요.
결과를 보면 bidirectional attention은 retrieval task에서 일관되게 성능을 높였습니다. 이는 query와 document의 의미적 관련성을 비교해야 하는 retrieval에서는, 입력 전체를 양방향으로 보는 것이 도움이 된다는 의미로 해석할 수 있을 것 같습니다.
하지만 clustering에서는 오히려 성능이 떨어졌습니다. 저자들은 bidirectional attention이 더 많은 context를 볼 수 있게 해주지만, clustering처럼 데이터 자체의 구조를 나눠야 하는 task에서는 불필요한 noise가 될 수도 있다고 설명합니다.
3.4 Overall Comparison
마지막으로 Table 4는 다섯 가지 모델 조합을 한 번에 비교한 결과입니다.
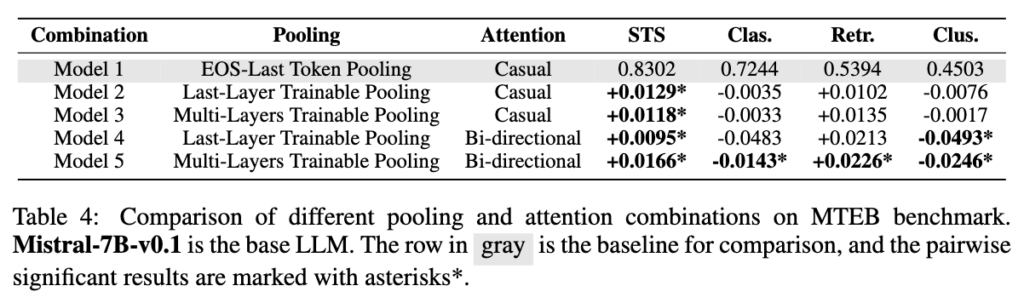
가장 좋은 조합은 task마다 달랐습니다. STS와 Retrieval에서는 Model 5, 즉 Multi-Layers Trainable Pooling + Bidirectional Attention 조합이 가장 좋은 성능을 보였습니다. 특히 retrieval에서는 기존에 많이 사용되는 EOS-last token pooling + causal attention 대비 유의미한 향상을 보였습니다.
하지만 classification과 clustering에서는 이야기가 달라집니다. Model 5가 항상 좋은 것은 아니었고, 오히려 causal attention을 사용하는 단순한 구조가 더 나은 경우도 있었습니다.
정리하면, retrieval이나 semantic similarity처럼 두 입력 간의 의미적 관련성을 비교하는 task에서는 bidirectional attention과 multi-layer pooling이 효과적이었습니다. 반면 classification이나 clustering처럼 입력 자체의 category나 구조를 구분하는 task에서는 더 복잡한 pooling과 attention이 항상 이득을 주지는 않았습니다.
3.5 Robustness Check
저자들은 추가적으로 Qwen2-0.5B를 사용한 실험도 진행했습니다. 이는 작은 LLM에서도 같은 경향이 나타나는지 확인하기 위한 실험입니다.
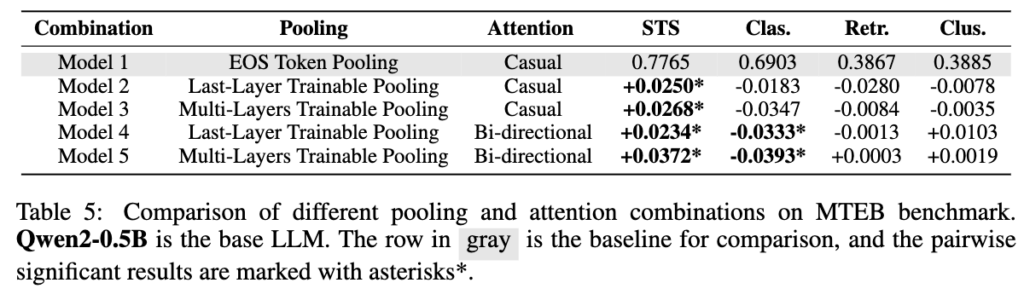
Table 5를 보면 전체 성능은 Mistral-7B보다 낮았습니다. 이는 base LLM의 capacity 차이 때문으로 볼 수 있습니다. 하지만 큰 흐름은 비슷했습니다. Multi-Layers Trainable Pooling + Bidirectional Attention은 STS에서는 좋은 성능을 보였지만, classification에서는 오히려 성능이 떨어졌습니다.
또한 작은 모델에서는 복잡한 pooling이나 bidirectional attention이 항상 의미 있는 성능 향상으로 이어지지는 않았습니다. 이 결과는 embedding model 설계에서 모델 크기 역시 중요한 변수라는 점을 보여줍니다.
결국 이 논문의 실험은 단순히 제안하는 방법이 좋다 라기 보다는, 오히려 pooling, attention, task, base model size가 서로 얽혀 있고, 어떤 목적의 embedding model을 만들 것인지에 따라 설계를 다르게 선택해야 한다는 점을 보여준 것 같습니다.
4. Conclusion
이 논문의 결론은, LLM-based embedding model에서 pooling과 attention 설계는 중요하지만, 모든 task에 통하는 정답은 없다는 것입니다. STS나 Retrieval처럼 두 입력 간의 의미적 유사성을 비교하는 task에서는 Multi-Layers Trainable Pooling과 Bidirectional Attention 조합이 효과적이었지만, Classification이나 Clustering에서는 오히려 단순한 causal attention 기반 구조가 더 나은 경우도 있었습니다.
개인적으로 이 논문은 E5, LLM2Vec, NV-Embed처럼 LLM을 embedding model로 바꾸려는 흐름을 이해하는 데 꽤 유용한 논문이라고 느꼈습니다. 특히 기존 연구들이 서로 다른 backbone, data, training setting을 사용해 pooling과 attention의 효과를 분리해서 보기 어려웠는데, 이 논문은 동일한 조건에서 이를 비교했다는 점이 의미가 있지 않나 싶네요.
다만 이 논문이 ICLR 2025에 reject이 되었는데 그 이유도 어느 정도 이해가 되긴 합니다. 제안한 Multi-Layers Trainable Pooling이 방법론적으로 아주 새롭다기보다는 기존 trainable pooling을 multi-layer로 확장한 것일 뿐이고, 또한 성능 향상도 Retrieval과 STS에 집중되어 있고, Classification과 Clustering에서는 오히려 하락하는 경우가 있어 “범용적인 embedding 설계법”으로 주장할 수 없는 그 모호함 때문 같습니다. 그럼 리뷰 마치겠습니다.
안녕하세요 주영님 리뷰 감사합니다.
재미있는 논문을 소개해주셨는데요, 단순히 디코더를 제거하는것이 아니라 레이어별 정보를 잘 정합하는 것이 신기했습니다.
본 접근법이 다양한 모델에서 공통적으로 적용할 수 있는지 궁금합니다.
감사합니다
댓글 감사합니다.
질문 주신 부분이 제가 Conclusion에서 어느 정도 다룬 내용과 연결되는 것 같습니다.
논문에서 Mistral-7B뿐 아니라 Qwen2-0.5B에서도 추가 실험을 진행해서, 제안한 pooling/attention 설계가 특정 모델에만 국한된 것은 아니라는 걸 확인하긴 했습니다
그치만 두 모델 모두 텍스트 LLM 기반이고, 실험 범위도 MTEB 중심이기 때문에 다양한 LLM/VLM/MLLM에 공통적으로 적용 가능하다고 일반화하기에는 아직 부족해 보입니다.
안녕하세요 주영님, 좋은 리뷰 감사합니다. LLM 내부 hidden state에 대한 인사이트를 얻을 수 있었던 논문이었던 것 같습니다. 질문 몇 개가 있는데,
1) 해당 task를 잘 몰라서 드리는 질문인데, embedding task에서 bidirectional attention을 주로 사용하는 이유가 무엇인가요?
2) 논문에서 제안한 Multi Layer Trainable Pooling 방식은 이전 EOS token 가져오던 방식에 비해서 연산 비용이 크게 증가할 것으로 보이는데, Table 2를 보면 성능 향상 폭이 0.01대 인 것으로 보아 증가한 연산량 대비 성능 향상 폭은 아쉬운 것 같습니다. 그런 상황에서, 논문에서 이러한 연산 비용 증가를 정당화할 만한 주장이나 실험 등을 제시했는지 궁금합니다.
안녕하세요 좋은 질문 감사합니다.
Q1. bidirectional attention을 주로 사용하는 이유?
-> embedding task에서는 입력 전체의 의미를 하나의 벡터로 잘 압축하는 것이 중요해서 bidirectional attention을 자주 사용한다고 합니다.
특히 causal attention은 앞쪽 token이 뒤쪽 token을 볼 수 없기 때문에, 각 token representation이 전체 문맥을 충분히 반영하지 못할 수 있죠. 반면 bidirectional attention은 모든 token이 서로를 참고할 수 있어서 문장 전체의 의미를 더 균형 있게 반영한 embedding을 만들기 쉽습니다.
Q2. 논문 향상 폭이 크지 않은데, 이에 대응하는 연산 비용 등 다른 장점이 있는가?
-> 저도 이 부분은 논문의 아쉬운 점이라고 생각했습니다. (Reject된 이유도 그 때문이 아닐까 싶구요)
논문에서는 Multi-Layers Trainable Pooling이 여러 layer의 정보를 활용해 retrieval/STS 성능을 높일 수 있다는 점은 보여주긴 하지만, 그로 인해 증가하는 연산량이나 메모리 비용을 정량적으로 분석하지는 않았습니다. 따라서 이 논문은 성능을 조금이라도 더 끌어올려야 하는 retrieval/STS 상황에서 검토할 수 있는 선택지 정도로 보는 게 맞지 않을까 싶네요