안녕하세요, 이번주는 작은 모델임에도 불구하고 대용량 학습 데이터로 학습한 큰 모델 대비 강인하고 성능 좋은 모델을 다룬 연구에 대해서 리뷰해보려고 합니다. 얼마 전 VLA-Adapter라는 연구도 강력하지만 작은 VLA로 인정을 받았었는데, 비슷한 연구가 등장했습니다. 단순히 작은 모델인데 좋다를 넘어서 어떻게 학습시켰는지, 어떤 요소가 이러한 결과를 만들어냈는지가 중요한 연구인 것 같습니다. 리뷰 시작하겠습니다.
Introduction

Vision-Language-Action 모델은 이미지로 환경을 보고, 자연어 명령을 이해하며, 로봇이 실행할 action을 생성하는 모델입니다. 최근 VLA는 로봇 조작의 중요한 연구 방향이 되었지만 기존 VLA들은 아직 세 가지 중요한 한계를 가진다고 합니다. 첫 번째는 일반 VLM의 pre-trained knowledge가 로봇 조작 도메인과 잘 맞지 않는다는 점입니다. 웹 이미지와 텍스트로 학습된 VLM은 물체를 설명하거나 질문에 답하는 데는 강하지만, “잡아야 할 물체”, “놓아야 할 위치”, “왼쪽/오른쪽/위/아래와 같은 공간 관계”, “어느 부분이 조작 가능한가”와 같은 embodied manipulation 지식에는 약할 수밖에 없습니다. 이렇기 때문에 각종 embodied ai용 데이터셋과 벤치마크들이 등장하는것 아닐까 싶습니다. 두 번째는 multi-view spatial consistency가 부족하다는 점입니다. 실제 로봇 조작에서는 base camera와 wrist camera가 동시에 사용될 수 있는데, 기존 모델은 두 시점에서 같은 조작 대상을 일관되게 이해하는 능력이 부족합니다. 세 번째는 action을 생성하기 전에 high level task-relevant knowledge를 명시적으로 예측하지 않는다는 점입니다. 즉, 모델이 어떤 대상을 보고 action을 만들었는지 해석하기 어렵고, 불필요한 시각 정보에 흔들릴 가능성이 높습니다.
저자들의 철학은 이런 문제점을 해결하는데 있어서 모델 크기만 키우는 방향이 아니라, action learning에 필요한 표현을 더 정교하게 만들고, 그 표현을 action head에 효과적으로 연결하는 방향이 필요하다고 합니다. 위 사진이 논문의 main figure인데, 실제로 1.22B의 작은 규모임에도 불구하고 LIBERO와 real world 평가에서 OpenVLA-OFT를 넘기는 성능을 보이기도 했습니다. 저자들이 제안한 접근 방식은 크게 다섯 가지 요소로 구성됩니다. 먼저, 저자들은 공개 데이터와 시뮬레이터에서 필터링 한 240만 개 규모의 vision-language 학습 데이터셋을 구축했습니다. 이 데이터셋은 일반적인 시각 질의응답, 공간적 grounding, affordance 학습, embodied reasoning 데이터로 구성돼있고, VLM이 로봇 조작 상황에서 필요한 공간 이해와 조작 가능성 판단 능력을 갖추도록 설계되었다고 합니다. 또 wrist camera와 base camera에서 관측되는 조작 대상을 일관되게 semantic segmentation하기 위해 학습 가능한 special token을 도입했습니다. Special token은 모델이 여러 시점에서 같은 조작 대상을 안정적으로 인식하도록 돕고, 결과적으로 로봇이 어떤 물체나 영역에 집중해야 하는지를 명확하게 집중할 수 있게 만들었다고 합니다. 또한 저자들은 Spatial Forcing과 유사한 아이디어에서 영감을 받아 feed-forward geometry foundation model을 활용해 wrist view와 base view에서 얻은 multi-view geometry 정보를 학습해 공간 인식 능력을 강화했다고 합니다. 마지막으로, 저자들은 action query가 VLM의 마지막 layer에서 나온 visual feature, 앞서 도입한 special token, 그리고 기타 조작 관련 정보를 cross-attention 방식으로 통합하도록 설계했습니다.
Related Works
Related works는 VLA foundation model, spatial-aware VLA, goal-aware VLA, perception-action bridging 키워드로 정리할 수 있습니다. 초기에는 RT-1이나 Octo처럼 로봇 demonstration data를 기반으로 transformer policy를 학습하는 방식이 주류였습니다. 이후 RT-2는 VLM을 web-scale vision-language data와 robot trajectory에 함께 fine-tuning하면서 VLM 지식을 로봇 제어로 전이하려 했고, OpenVLA는 대규모 robot dataset으로 pre-training된 open-source VLA 모델을 제시했습니다. Pi 0와 Pi 0.5는 flow matching decoder를 통해 복잡한 action generation을 다루었고, GR00T N1이나 OpenHelix와 같은 모델들은 fast/slow system 관점의 dual-system VLA를 제시하기도 하며 계속 발전된 모델들이 등장했습니다.
하지만 저자들이 보기에 VLA에서 여전히 부족한 부분은 “공간을 어떻게 이해할 것인가”와 “목표 대상을 어떻게 붙잡을 것인가”였다고 합니다. SpatialVLA, PointVLA, GeoVLA, BridgeVLA 같은 연구들은 3D positional encoding, point embedding, point cloud projection 등을 통해 VLA의 공간 이해를 강화하려 했지만 추가 modality나 external foundation model을 inference 때 요구할 수 있고, 이는 실제 로봇에서 latency를 증가시킬 수 있다는 한계가 있었습니다. 따라서 inference가 아니라 training 단계에서만 사용하여 3D 지식을 model representation에 전이해 효율성을 챙겼습니다.
Goal-aware VLA 관점에서는 DreamVLA, ReconVLA 같은 연구와 연결됩니다. DreamVLA는 dynamic region, depth, semantics 같은 compact world knowledge를 예측하고, ReconVLA는 target region reconstruction을 통해 action attention을 조작 대상 쪽으로 유도합니다. 다만 저자들은 semantic segmentation mask가 gaze reconstruction이나 dynamic region reconstruction보다 조작 대상에 대한 더 직접적이고 세밀한 spatial guidance를 제공한다고 합니다.
마지막으로 perception-action bridging 관점에서 저자들은 자율주행 분야의 learnable query 기반 planning 구조에서 영감을 받았다고 합니다. 자율주행에서는 query가 panoptic segmentation, map, obstacle feature와 같은 perception 정보를 모아 planning network로 전달하는 구조가 자주 사용되는데, 이 아이디어를 로봇 VLA에 가져와 action query가 visual feature, geometry-aware feature, segmentation-aware feature, robot state를 모아 action chunk를 생성하도록 설계했다고 합니다. 기존 VLA가 VLM hidden state를 거의 raw feature처럼 action head에 전달했다면, PokeVLA는 action에 필요한 perception 정보를 구조화해서 전달하려는 시도라고 볼 수 있을 것 같스빈다.
Methods
System Overview
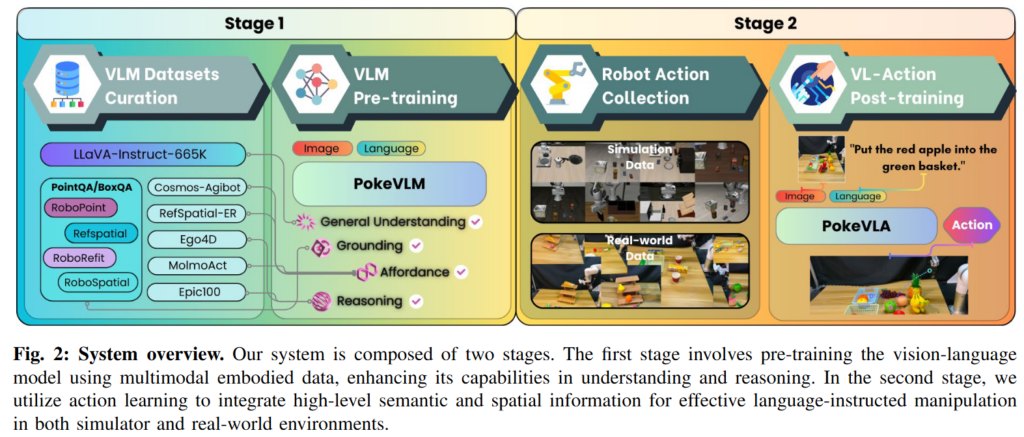
학습은 2stage로 진행됩니다. 먼저 VLM pre-training을 진행합니다. Spatial grounding, affordance, embodied reasoning 지식을 포함한 multimodal embodied dataset으로 PokeVLM을 pre-training했습니다. PokeVLM은 Qwen2.5-0.5B를 사용하고, vision encoder는 DINOv2와 SigLIP을 함께 사용한다고 합니다. SigLIP이 semantic 정보를 담고, DINOv2가 이미지 내에서 spatial perception에 유리하므로 두 encoder를 결합해 semantic과 spatial cue를 모두 얻으려는 설계라고 합니다.
두 번째 단계는 VL-Action post-training입니다. 저자들은 이 때 단순히 image-language feature를 action으로 변환하는 구조로 가져가지 않았다고 합니다. 먼저 base camera와 wrist camera에서 조작 대상을 일관되게 segment하도록 goal-aware segmentation을 학습합니다. 다음으로 VGGT에서 나온 geometric feature와 VLM의 visual hidden state를 정렬하여 VLM 내부 표현이 3D 구조를 담도록 유도합니다. 마지막으로 action query 기반 action head가 visual token, language token, <SEG> token, robot state를 통합해 future action chunk를 예측합니다. 핵심은 조작 대상과 공간 구조를 최대한 학습시키고 그 정보를 action head로 잘 전달하는 구조인 것 같습니다. 아래에서 디테일을 조금 더 다뤄보겠습니다.
Architecture
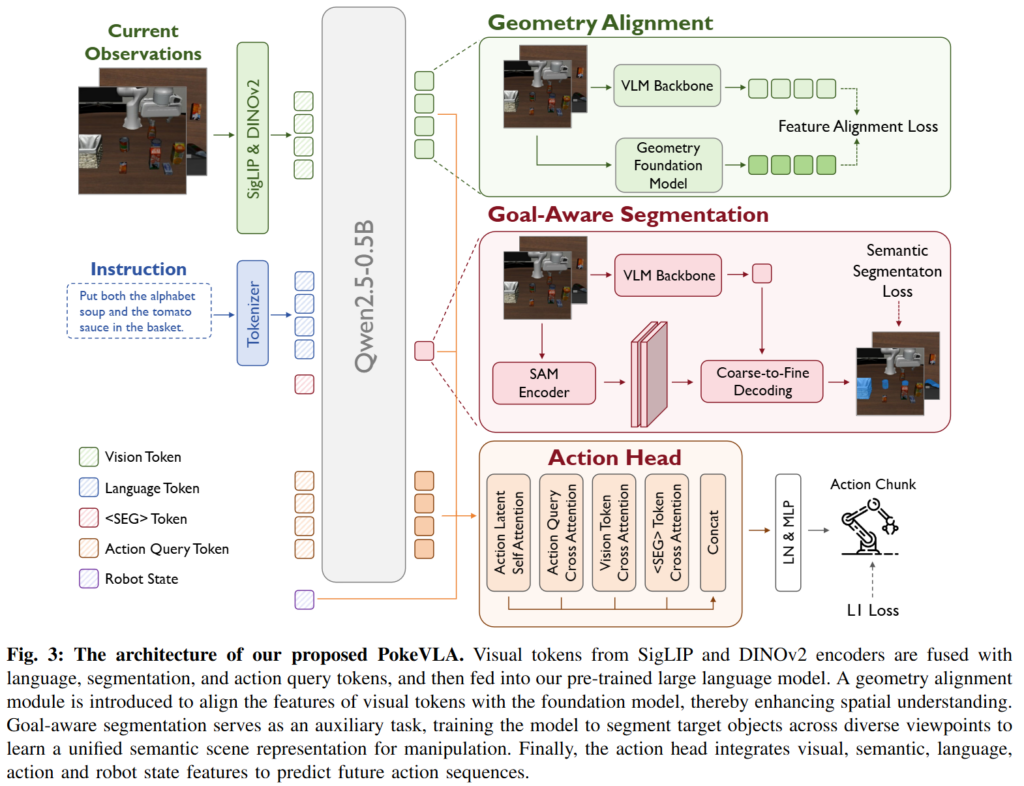
VLM Pre-training
저자들은 PokeVLM을 만들기 위해 2.5M 규모의 embodied multimodal dataset을 구성했습니다. 이 데이터셋은 네 가지 능력을 위해 설계되었습니다. General Understanding에는 LLaVA-Instruct-665K가 사용되어 일반적인 image captioning, object recognition, OCR과 같은 vision-language 능력을 유지하도록 했습니다. Grounding에는 RoboPoint, RefSpatial, RoboRefIt, RoboSpatial이 사용되어 tabletop 환경에서 물체나 공간 영역을 language instruction으로 찾아내는 능력을 강화했다고 합니다. Affordance에는 HOVA의 Ego4D와 Epic100 subset, MolmoAct의 manipulation trace가 사용되어 물체의 조작 가능 지점이나 사람의 1인칭 조작 정보를 학습하도록 했습니다. Reasoning에는 RefSpatial과 Cosmos 기반 embodied reasoning data가 포함되어 공간 관계와 복합 지시문을 추론하는 능력을 보강할 수 있었다고 합니다.
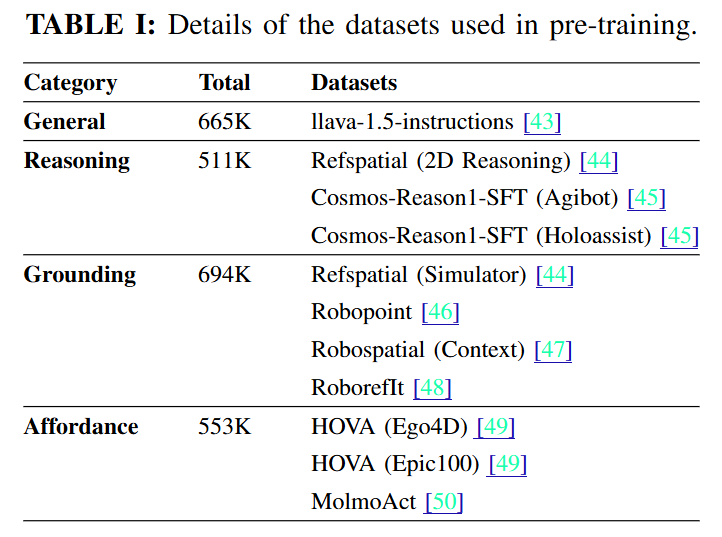
저자들은 단순히 데이터를 많이 모은 것이 아니라, 조작에 필요한 능력을 기준으로 데이터를 분류하고 정제했다는 것이 포인트라고 합니다. 모든 point coordinate를 [0, 1] 범위의 relative coordinate로 정규화했고, 잘못된 annotation을 제거하고, word-level annotation만 있는 embodied dataset은 template과 LLM을 사용해 language description을 풍부하게 만들었다고 합니다. 또한 task balance를 맞추기 위해 sampling을 수행했는데, PokeVLM이 일반 VLM 능력을 잃지 않으면서도 로봇 조작에 필요한 spatial grounding과 affordance prior를 갖게 만든다고 합니다.
PokeVLM 모델의 구조는 Prismatic-VLM 기반이라고 하빈다. Image는 SigLIP과 DINOv2 encoder를 각각 통과하고, 두 feature는 channel dimension으로 concatenate된 뒤 projector를 통해 language model embedding space로 매핑됩니다. 이후 multimodal pair에 대해 next-token prediction 방식으로 end-to-end training이 이루어집니다.
VL-Action Post-training
PokeVLA의 action training은 OpenVLA-OFT의 효율적인 action decoding 철학을 기반으로 한다고 합니다. OpenVLA-OFT는 multi-view image, robot state, language instruction을 embedding으로 변환해 language model에 넣고, empty action embedding과 bidirectional attention을 사용해 action을 병렬적으로 decoding합니다. 이를 통해 여러 step의 action을 한 번의 forward pass에서 예측하는 action chunking을 수행하며, continuous action은 MLP를 통해 예측하고 L1 loss로 학습합니다.
여기에 저자들은 기존 방식이 VLM hidden state를 action head에 그대로 넘기기 때문에, action learning에 필요한 high-level semantic guidance가 부족하다고 합니다. 그래서 첫 번째로 goal-aware manipulation module을 도입했습니다. 해당 모듈의 목적은 instruction이 가리키는 조작 대상을 base camera와 wrist camera에서 동시에 segment하는 것애라고 합니다. 이 설계가 action 생성을 위한 중간 reasoning step이고, 이 과정에서 모델이 무엇을 잡아야 하는지를 pixel-level로 알고 action을 만들도록 강제하는 구조라고 합니다. 모듈 학습은 LISA에서 영감을 받은 embedding-as-mask paradigm을 썼다고 합니다. VLM vocabulary에 <SEG>라는 special token을 추가하고, 모델이 이 token을 출력하도록 만든 뒤, 마지막 layer hidden state에서 <SEG> embedding을 추출합니다. 이 embedding은 language instruction, scene context, target object 정보를 모두 포함하는 조작 대상 표현으로 사용됩니다. 이후 SAM image encoder가 base view와 wrist view에서 dense visual feature를 추출하고, <SEG> embedding이 SAM prompt encoder와 mask decoder를 거쳐 multi-view segmentation mask를 생성합니다.
저자들의 학습 포인트에는 coarse-to-fine decoding도 있습니다. Coarse decoder가 먼저 scene 전체의 foreground object와 공간 관계를 큰 틀에서 파악합니다. 이 때의 coarse output은 noise가 있지만, foreground object와 조작 후보 영역을 넓게 잡아내는 역할을 하게 됩니다. Fine-grained decoder는 이 coarse output을 mask prompt로 다시 사용해 실제 manipulation target을 더 정밀하게 segment합니다. 저자들은 coarse stage는 scene-level contextual relationship을 학습하고, fine stage는 <SEG> token과 coarse map을 결합해 target-specific mask를 생성합니다. 이 구조 덕분에 하나의 <SEG> token이 base view와 wrist view를 동시에 다루면서도 cross-view consistent target representation을 만들 수 있습니다.

다음 학습 모듈은 geometry alignment입니다. Goal-aware segmentation은 조작 대상에 대한 cross-view semantic consistency를 주지만, 2D image만으로는 정확한 3D 구조를 충분히 담기 어렵습니다. 저자들은 이 문제를 해결하기 위해 VGGT를 학습 과정에서 사용했습니다. Multi-view image로부터 VGGT feature를 추출하고, VLM의 vision token hidden state를 projection 해서 cosine similarity로 feature alignment loss를 통해 학습했다고 합니다. 마지막은 action head입니다. PokeVLA의 action head는 action latent에 대해 self-attention을 수행한 뒤, action query와 robot state, geometry-enhanced visual hidden state, <SEG> embedding를 각각 cross-attention합니다. 이렇게 되면 Action head가 단순히 VLM의 마지막 hidden state만 받는것이 아니라 3D 구조 정보와, 조작 대상에 대한 semantic focus를 제대로 받을 수 있다고 합니다. 최종적으로 LayerNorm과 MLP를 거쳐 future action chunk가 출력되고, action은 L1 loss로 학습됩니다. 전체 학습 objective는 action loss, segmentation loss, geometry alignment loss의 weighted sum으로 구성됩니다. 저자들은 seg=0.2, geo=0.4 세팅으로 갔다고 합니다
Experiments
VLM Experiments
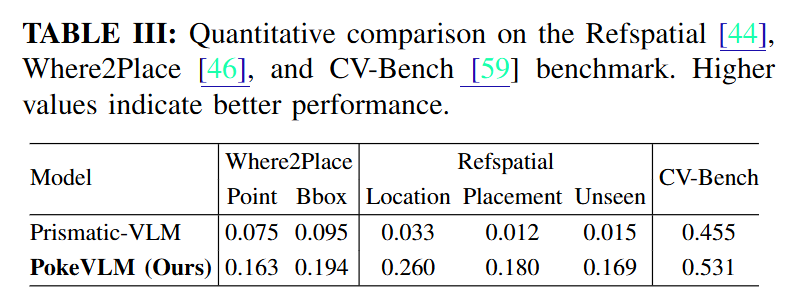
먼저 PokeVLM에 대한 평가를 진행했습니다. 평가는 Where2Place, RefSpatial, CV-Bench에서 진행했다고 합니다. Task에 대한 설명은 아래 Table2와 같습니다.

결과를 보면 Prismatic-VLM baseline에 비해 spatial grounding 성능이 크게 향상되었습니다. 모든 task에서 향상된 모습을 보이는데, 특히 CV-Bench는 general한 벤치마크인데도 불구하고 embodied에 집중한 pre training이 일반적인 이해 능력또한 향상 시켰다는것을 볼 수 있습니다. 정성적인 결과는 아래 Fig 4를 참고하시면 됩니다.

Simulation Experiments
Simulation benchmark는 LIBERO와 LIBERO-Plus를 사용했습니다. LIBERO-Plus는 LIBERO에 camera viewpoint, robot initialization, language instruction, lighting, background texture, sensor noise, object layout의 perturbation을 추가한 benchmark입니다.
LIBERO에서는 total success rate 98.2%를 기록했습니다. OpenVLA, CoT-VLA, WorldVLA, π0, GR00T N1 등등 baseline을 다 이겼습니다. Long suite에서 95.2%를 달성했다는 점은 goal-aware representation이 long-horizon manipulation에서도 의미가 있었던거라고 생각할 수 있을 것 같습니다.
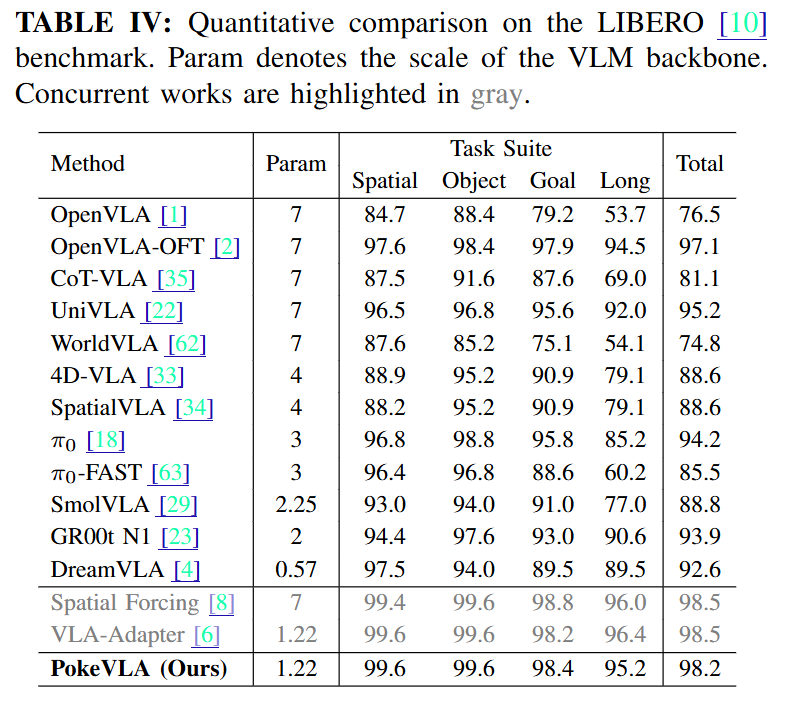
LIBERO-Plus data에서는 total success rate 83.5%를 기록했는데, camera perturbation에서는 98.2%, lighting에서는 99.0%, background에서는 99.3%를 기록했다는 점에서 아직 확정지을 수는 없지만 꽤나 강인한 것 같습니다. Robot initialization perturbation에서도 강한 모습을 보이는 것이 실제로 2D쪽에만 머무르지 않고 3D에 대한 이해가 어느정도는 된 것 같다는 생각도 듭니다.
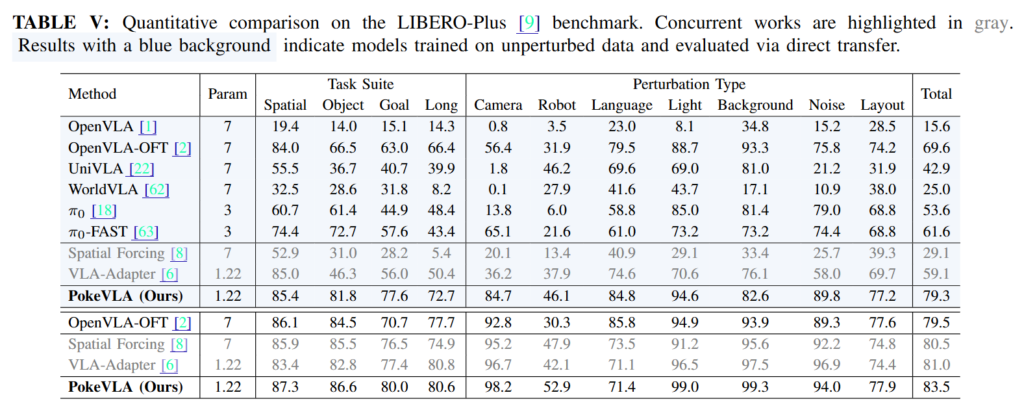
개인적으로 제일 놀라운 결과는 LIBERO 데이터로 학습하고 LIBERO-Plus에서 평가한 결과입니다. 그럼에도 불구하고 camera viewpoint shift에서 84.7%, language perturbation에서 84.8%, sensor noise에서 89.8%를 보여주었는데, 꽤 강력한 결과라고 생각합니다. 물론 큰 모델들과 엄청난 데이터가 가지는 다양한 현실 환경에 대한 강인성은 이 벤치마크가 담지 못 하지만, 모델 아키텍쳐와 학습 구조 설계를 통해서 작은 파라미터의 모델을 가지고도 기존 VLA의 문제를 다룰 수 있다는 것의 가능성을 보인것이 대단한 것 같습니다.
Ablation Study & Deep Analysis
Ablation을 보면 기본 Libero-Plusd에서 각 module이 독립적으로도 도움이 되지만, semantic prior, geometry prior, target focus가 결합될 때 가장 강한 성능을 내는것을 확인할 수 있습니다. Pre-training이 goal suite와 language perturbation에서 강한것을 보면 embodied VLM pre-training이 instruction 이해와 task semantic 이해에 도움이 된느것을 볼 수 있습니다. Geometry alignment를 통해서는 VGGT로부터 학습한 3D scene structure가 물체와 공간에 대한 이해를 도와주는 것을 볼 수 있습니다. Goal-aware segmentation이 lighting, background, noise perturbation에서도 강한데, 조작 대상에 해당하는 region을 직접 segment하도록 학습했기 때문에 배경이나 조명 변화처럼 task와 무관한 visual variation을 자연스럽게 처리할 수 있었다고 합니다. goal-aware segmentation을 통해서도 강건성을 확보할 수 있었다고 합니다.
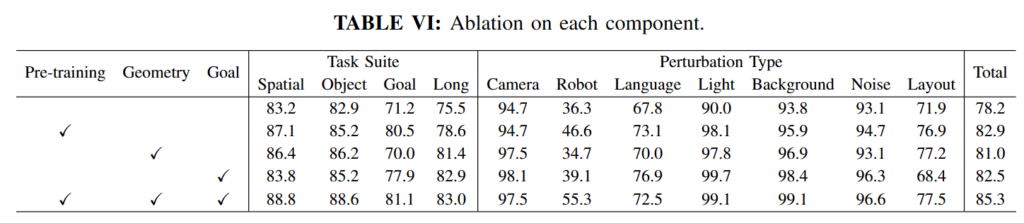
Figure 5를 통해서는 long horizon task를 수행할 때 다른 view의 camera로부터 안정적으로 semantic segmentation이 가능한 것을 볼 수 있습니다. 아래 노란색 블럭으로 instruction이 표기된 figure에서는 아까 method에 넣었었는데 coarse-to-fine의 구조를 확인할 수 있습니다. Figure 7은 다양한 perturbation에도 잘 작동하는 모습을 보여줍니다.

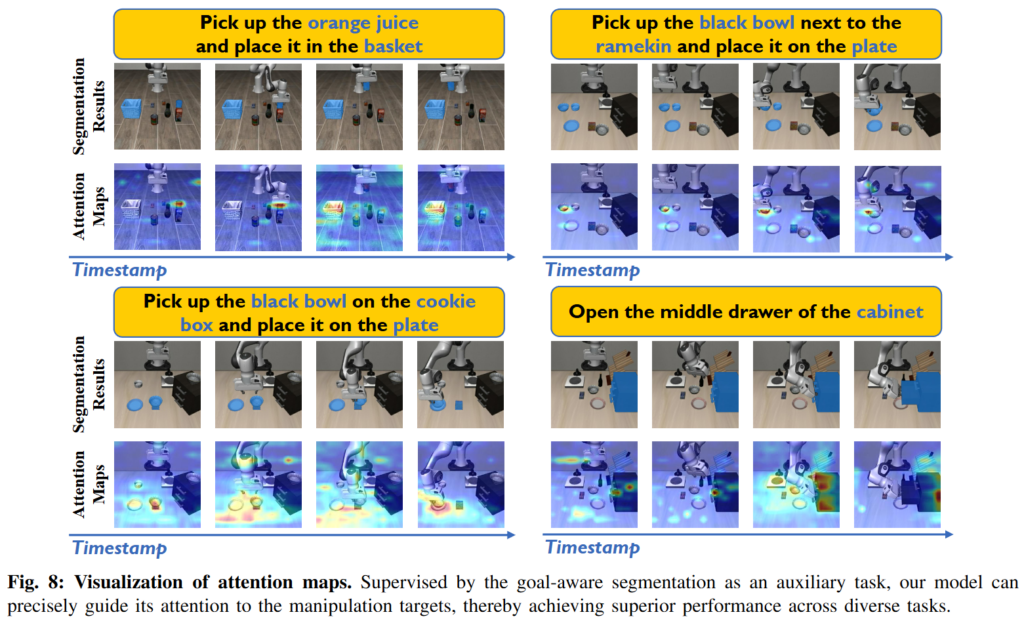
아래 figure 8을 보면 segmentation result 기반으로 Attention을 효과적으로 목표 대상들에게 가이드 할 수 있음을 보여주기도 합니다. 이 결과를 통해서 segmentation이 단순한 auxiliary output이 아니라 action quality에 직접 연결되는 representation learning 구조라는 것을 강조했습니다.
Real World Experiments

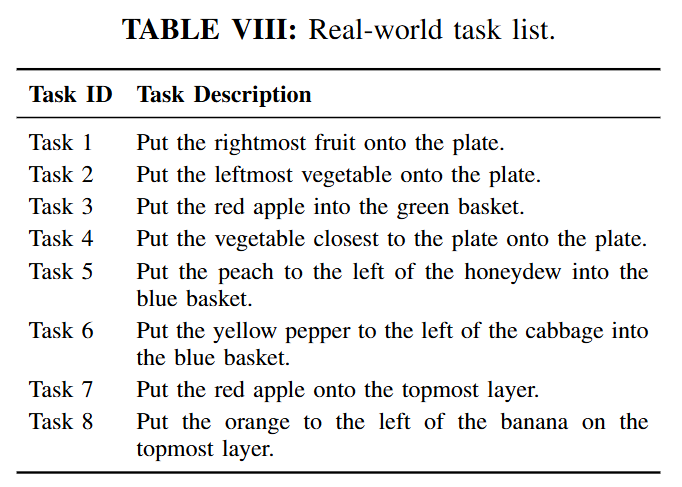
Real world에서는 Xarm7을 사용해 wrist view와 base view(front cam)을 사용했습니다. Task의 경우에는 table 8과 같이 설정됐고 모든 task에 대해서 50개의 데모를 취득했다고 합니다. 데이터는 GELLO teleoperation system을 사용해 수집되었고, 110 × 110 cm wooden tabletop workspace에서 pick-and-place task를 수행했습니다. 데이터에는 총 97개의 objects and containers가 포함되며, 이 중 57개는 seen object, 40개는 unseen object라고 합니다. 데이터 Annotation은 SAM2를 활용해서 사람이 직접 pixel-wise mask를 만들었다고 합니다. 참고로 학습에는 A100 8장을 사용했고, joint space에서 학습되었습니다.

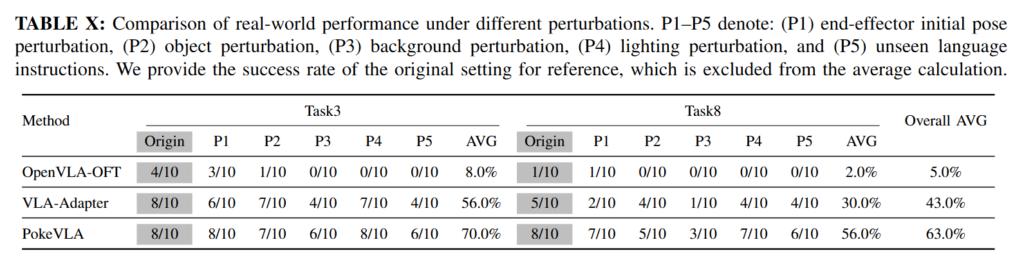
결과를 보면 original setting의 8개 real-world task 평균 성공률 81.25%를 기록했습니다. 이전 연구인 VLA-Adapter는 68.75%, 베이스라인인 OpenVLA-OFT는 20.00%인것에 비해 강한 모습을 보여줬고 공간 관계가 중요한 task에서 강점을 보였다고 합니다. 또한 color reference가 포함된 task에서도 baseline보다 나은 성능을 보였는데, VLM pre-training의 grounding 및 color/semantic understanding, geometry alignment가 실제로 유의미 하다는 것을 보여줄 수 있는 결과인 것 같습니다. 위 Figure 10을 보면 어떤 방해혀과들이 적용됐는지 볼 수 있는데, 해당하는 방해효과들에 대해서도 강건한 모습을 보여주었습니다.
Conclusion
VLA의 성능을 키우기 위해 모델을 무작정 크게 만드는 대신, 조작 대상, 공간 구조, affordance, instruction understanding을 action이 사용할 수 있는 형태로 구조화해서 각각의 학습 방법을 제안하면서 작은 모델의 성능을 끌어올린 연구라고 정리할 수 있는데요, 해당 구조가 OOD task나 Sim2Real에도 어느정도 영향을 미칠 수 있지 않을까 생각해보면서 저는 특히 Sim2Real에서 gap을 무작정 줄이는 것도 방법이지만 도메인 차이가 없는 요소들을 기준으로 학습시키는 방법도 충분히 고려해볼만 하다고 생각합니다. 이렇게 되면 오히려 control이나 dynamics gap이 중요해지지는 않을까 생각해봅니다.
안녕하세요 영규님 좋은 리뷰 감사합니다.
각 쿼리가 future action 의 각 타임스텝에 대응되는 구조인지 아니면 쿼리 하나가 액션 후보 하나를 의미하는 건지가 궁금합니다. 추가로 action 쿼리는 몇개 사용되는지가 궁금합니다. navigation 쪽에도 query-based action generation 연구에서는 각 query가 하나의 action candidate를 의미하고 여러 query 중 가장 적합한 action을 선택하는 방식으로 동작하는 경우가 있었는데 여기서도 비슷한 방식인지가 궁금했습니다. 감사합니다.
안녕하세요 우현님 댓글 감사합니다.
PokeVLA의 action query는 navigation/planning 연구에서처럼 각 query가 하나의 action candidate를 의미하고, 여러 후보 중 최적 action을 선택하는 구조는 아닌 것으로 이해하는 것이 맞는 것 같습니다. 이 논문에서는 action query embedding이 VLM backbone을 거쳐 나온 action-relevant conditioning representation으로 사용되고, 실제 future action sequence는 action head 내부의 action latent a_t가 visual hidden state, token, robot state, action query embedding을 cross-attention으로 참조한 뒤 continuous action chunk로 회귀하는 구조입니다. 최종 action도 여러 후보 중 선택되는 방식이 아니라 ground-truth action chunk와의 L1 loss로 직접 supervise됩니다.