안녕하세요 이번에 들고온 논문도 VLM 에서의 token pruning 논문입니다. 개인연구를 진행하면서 해당 분야에 논문들이 쏟아져나오고 있어서 생각보다 쉽지 않은 것 같습니다.
그럼 리뷰 시작하겠습니다.
Abstract
토큰 프루닝 논문들을 리뷰해오면서 매번 언급하는 내용이지만, 해당 분야는 여러가지를 목표로 합니다. VLM이 visual 정보와 textual 정보를 동시에 다루면서 visual 정보를 tokenize하는과정에서 생기는 redundant한 토큰들을 줄이는 것, 줄이면서 불필요한 토큰 소모량을 줄이고, inference 속도를 빠르게하며 동시에 원본 성능과 비슷한 성능을 내는것을 목표로 하는 task로 이해할 수 있습니다.
기존 방법들은 attention-based pruning이나 similarity-based 의 pruning을 진행해왔는데, 앞의 attention 관련 방법들은 비슷한 정보가 중복되어 채택될 가능성이 있고, 뒤의 similarity 방식은 질문과 관련없는 token들이 선택된다는 한계가 있었습니다. 저자는 최초로 conditional similarity를 정의하여 이미지 정보가 텍스트와 관련있는 정보만 남게 하고, token pruning 방법론을 Determinantal point process (DPP) 로 reformulate하여 선택된 token들의 subset이 조건부 다양성을 최대화하게끔 하는 방식으로 구현했다고 합니다.
뒤의 내용은 Abstract에 넣을만한 SOTA달성 및 LLaVA에서 FLOPs나 latency관련된 내용입니다.
Introduction
Token pruning 방법론들이 Video 를 타겟으로하는 논문도 분명히 있고 여러 모달리티를 사용하는 논문도 있지만, 제일 핫하고 지금 많이 작성되고있는 분야는 image 쪽 벤치마크를 10개정도 메인으로 가져가고, 비디오쪽 벤치마크를 3개정도 넣는 분야인 것 같습니다.
물론 이렇게 image를 메인으로 타겟하더라도 image의 token redundancy가 분명히 텍스트에 비해 높기 때문에, 충분히 납득이되고, 비디오를 연구하기에는 GPU 자원이 힘들수도 있을거라 생각합니다.
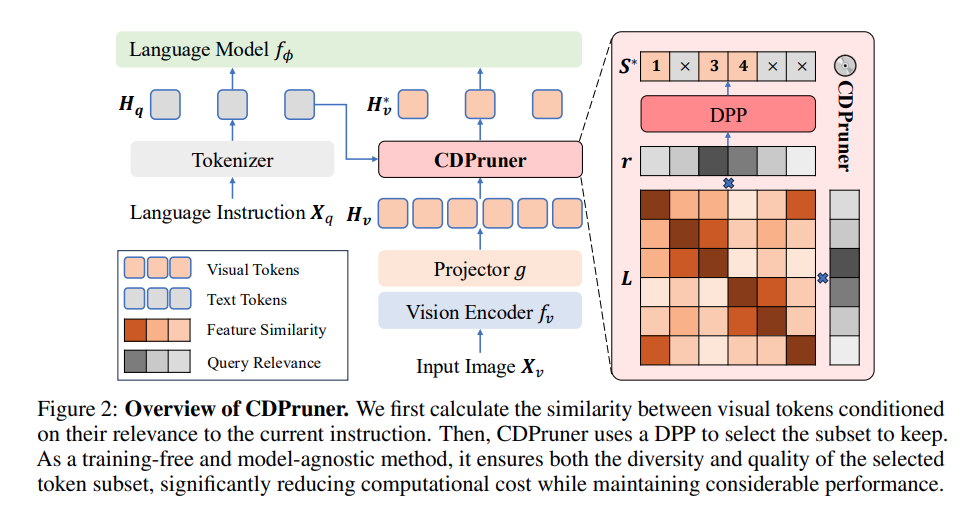
저자는 기존의 MLLM의 visual token pruning 방법론들이 크게 2가지로 연구되어 왔다고 하는데 첫번째는 high attention scores를 중요하게 보는 방법론들, 그리고 두번째는 redundant 한 부분을 feature similarity를 활용하여 지우는 연구라고 합니다. 기존의 attention-based 방법론들은 visual token들의 정보만 활용하기 때문에 비슷한 정보들이 많이 살아남는다고 주장하고, similairy-based와 앞의 attention score 기반의 방식들 모두 텍스트를 고려하지 못한다는 문제를 가진다고 주장하며 아래의 Figure를 설명합니다.

이러한 문제점들을 해결하기 위해서 저자는 CDPruner를 제안하는데, 선택된 token들로 하여금 conditional diversity를 최대화하는 방향으로 구현되었다고 합니다. 저자가 말하는 conditional diversity는
- feature similarity
- instruction relevance
두가지로 구성되어있으며, 구체적으로는 visual tokens들의 pairwise한 similarity를 계산하고 input instruction의 relevance에 의해 visual token들이 선택된다고 합니다. 저자의 방법론은 attention을 참조하지 않으므로 기존 token pruning 논문들에서 주장하는 attention shift문제도 피하면서, 동시에 flash attention과도 호환이 잘 된다고 합니다.
Visual token reduction
앞서 Introduction에서 설명한 것보다 조금 더 구체적으로 Related works에서 Token reduction계열 설명을 진행합니다.
먼저 vision-text pre-fusion 방식이 존재했었는데, 이는 아예 encoder 구조를 바꾸어 visual token을 줄이거나, image와 text를 미리 결합해서 representation을 압축하는 방식으로 모델 구조를 수정하는 방법론들은 추가 학습이 필요하기에, 계산 비용이 커지고 번거롭다는 문제가 있었습니다.
그래서 최근에는 저자의 계열과 마찬가지로 inference 과정에서 불필요한 visual token을 제거하는 token pruning 방식을 연구해왔고, 이는 크게 3가지로 나뉠 수 있다고 합니다.
- language model 내부의 text-visual attention을 이용하는 방식으로 text token이 어떤 visual token을 많이 보는지를 기준으로 중요도를 판단하는 방법입니다. 이는 위에서 언급했듯이 Attention shift 문제 때문에 실제로 중요한 token을 제대로 잡지 못하는 경우가 있고, attention scrore 자체를 필요로 하기 때문에 Flashattention과 같은 효율적인 구현과 호환이 안되는 문제가 있다고 합니다. 제가 이전에 리뷰한 VisPruner가 증명한 거의 6페이지정도 되는 내용을 3줄로 요약한 상황입니다.
- 두번째는 language model에 들어가기전에 visual token을 줄이는 방식으로 이 경우 attention 문제는 피할 수 있지만, 대신 특정 visual encoder 구조에 의존하게 된다고 합니다. 예를 들면 patch구조나 feature 형태를 가정하고 token을 합치거나 줄이기 때문에, 다른 MLLM에 그대로 적용하기 어렵다고 하고 기존의 visionzip이나 prumerge+ 등이 여기에 해당한다고 합니다. (ViT등과 같은 모델은 출력이 patch구조를 보존하지만, 다른 encoder를 사용하는 Qwen-VL2.5 와 같은 방법론들은 다른 형태의 모델 출력을 사용하므로 호환되지 않는점을 지적하는 것입니다.)
- 세번째는 visual token간의 feature similarity를 이용해서 중복된 token을 제거하는 방식으로 이건 encoder 구조에 덜 의존하고 비교적 일반적으로 적용 가능하다는 장점이 있지만, text와의 관계를 전혀 고려하지 않기 때문에, 실제 질문과 관련 없는 token을 남기거나 중요한 token을 제거하는 문제가 생길 수 있다고 합니다.
Determinantal point process.
이 섹션은 DPP가 무엇인지 설명하는 부분입니다.
원래는 물리에서 나온 개념인 fermion이라는 입자가 같은 상태를 공유할 수 없다는 성질에서 출발합니다. 직관적으로 이것을 비슷한 것들이 서로 모이지 않으려는 성질 즉 “anti-bunching” 이라고 불리는 성질이 생기는데, 이걸 다양성으로 해석할 수 있다고 합니다.
이러한 개념이 이후 머신러닝쪽으로 넘어오면서, 여러 개의 후보 중에서 서로 비슷한 것들만 고르는 게 아니라, 서로 다른 것을 고르게 선택하는 문제에 쓰이게 되고, 이는 서로 다른 다양한 subset을 고르는 방법으로 사용됩니다.
기존에도 다양성을 최대화하는 문제로 Max-Min Diversity Problem(MMDP) 와 같은 접근이 있었는데, 이건 극단적인 케이스에 치우치는 경향이 있다고 합니다. 예를 들면 서로 가장 먼 것들만 고르는 식이라 전체적으로 균형잡힌 선택이 안될 수 있고 반면 DPP는 행렬식 기반으로 전체 집합의 다양성을 동시에 고려학 ㅣ때문에 더 균형 잡힌 subset을 선택하는 경향이 있다고 합니다.
기존 DPP는 기본적으로 feature similarity만을 기준으로 동작되어 서로 비슷한 sample은 같이 선택될 확률이 낮고, 서로 다른 sample이 같이 선택될 확률이 높아지는데 저자는 더 나아가서, 단순히 token간의 similarity를 보는 게 아니라, 사용자 instruction과의 관련성까지 같이 고려하여 “서로 다른 token”을 고르는 것에서 “질문과 관련있는 token 중에서 서로 다른 것” 을 고르도록 확장했다고 생각하면 됩니다.
Method
3.1 Visual token pruning
이 부분은 문제 정의로 기본적으로 MLLM이 vision encoder, projector, llm 으로 구성되며, visual token이 H_v로 변환되고 해당 visual token 수 n이 text token보다 훨씬 많으므로 visual token을 일부만 남겨 모델 출력이 최대한 유지되로록 하는것을 수식화한 부분입니다.
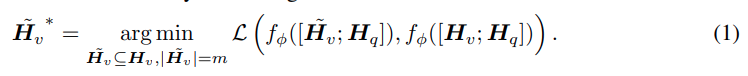
즉 token을 줄였을때와 원래 결과의 차이를 최소화하는 수식이라 이해하면 됩니다.
3.2 DPP with token similarity
해당 구절은 서로 다른 token들을 고르게하는 것이며 DPP는 P(S) ∝ det(L_s)를 최대화하는 subset을 고르는 구조입니다. 여기서 kernel L은 아래의 수식과 같은데 단순 cosine sim으로 이해하면 됩니다. 즉 token 끼리의 similarity로 구성됩니다.
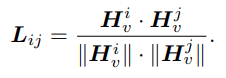
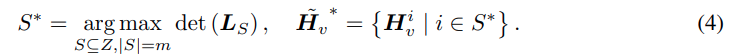
여기서 determinant가 크면 서로 다른 token임을 이해하면 됩니다.
3.3 Instruction relevance
앞에서는 token끼리의 similarity만 봤기 때문에 아직 textual한 정보가 들어가지 않았습니다. 그래서 relevance를 추가해주는 구절이고, 각 token에 대해 visual token 과 instruction (query) similarity를 구하게 됩니다.
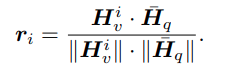
위의 Figure2를 보면 language instruction X_q 가 tokenizer를 타고나와 $H_q$ 로 변환되어 sim 계산에 사용되는데, 이는 LLM tokenizer로 보이지만 LLaVA1.5 기준으로는 CLIP의 text tokenizer를 사용하고 없다면 LLM embedding을 평균내어 사용했다고 합니다. 즉 앞에서 visual patch들의 sim 을 계산하는 3.2절은 LLM 의 projector까지 통과한 feature단에서 sim 을 계산하고, relevance관련은 LLaVA기준에서는 CLIP을 통과환 visual patch와 textual 정보의 sim을 통해 text와 관련있는 patch가 어디있는지 text축으로 평균내어 relevance정보를 구하는 것으로 확인했습니다.
3.4 CDPruner
이제 위의 두 과정을 합쳐 기존 Kernel L을 아래와 같이 바꿉니다.

이게 의미하는 부분은 similarity에 relevance weighting을 씌우는 것으로 diagonal 부분은 figure2 부분에서 relevance가 양옆 축으로 곱해지는 것으로 이해하면 좋을 것 같습니다. (patch의 sim matrix의 ij 방향 및 ji 방향을 모두 고려)
약간 사담으로 깃헙 코드상 LLaVA1.5 기준으로 저자의 해당 relevance를 계산하는 부분에는 -가 붙어있어 실제로 text와 patch가 관련없는 부분만을 선택하는 것으로 확인됩니다. 해당 부분을 지적하는 issue 에 대해서는 LLaVA에서 사용하는 CLIP 이 그러한 특성을 보여 LLaVA에서만 그렇게 구현했다고 언급되어있고 논문에는 그러한 것을 밝히지는 않았습니다.
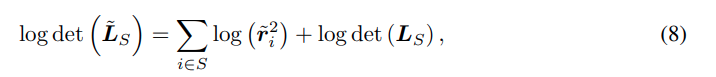
그리고 해당 수식을 통해 relevance(중요도) 와 similarity(다양성) 을 모두 고려하게 되고 이는 중요하면서도 서로 다른 token을 고르게 된다고 합니다. 저자의 subset selection과정에서 greedy DPP를 사용하여 latency가 매우 작게하였다고 합니다.

위의 Figure는 저자가 relevance score를 “is there a {object} in the iamge?” 라는 프롬프트를 주었을때로 시각화해본 것입니다. 실제 object스러운 것들이 잘 mapping되고있는 것 같습니다.
Experiments
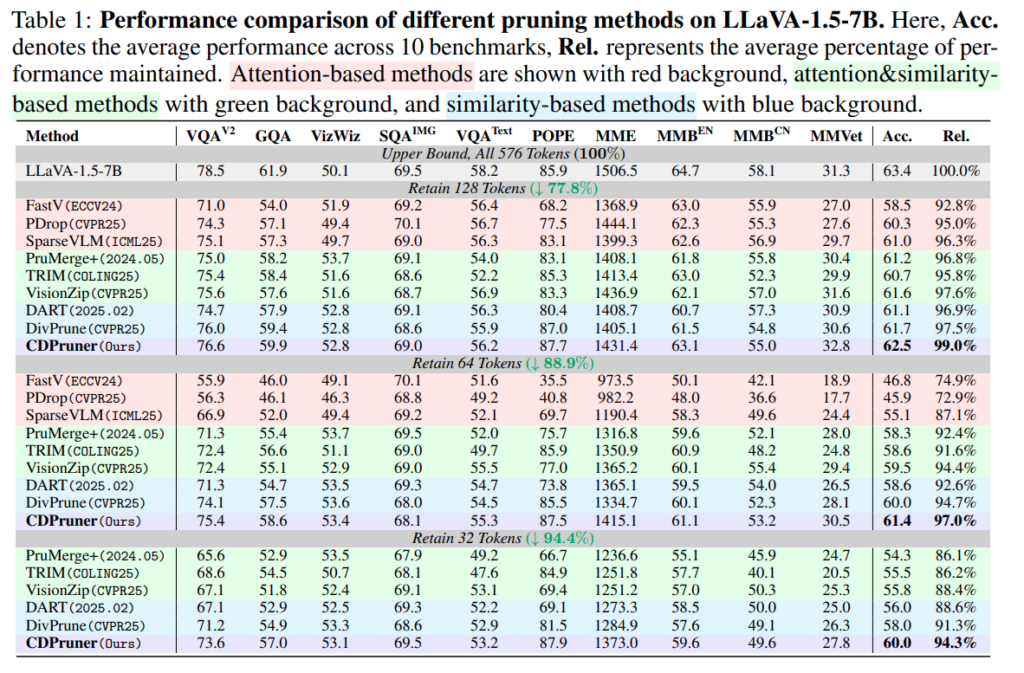
저자는 기존의 방식들을 attention based와 attention&similarity 기반 그리고 similarity기반으로 나누었고 저자의 색만 다르게 표시해서 보여주고 있습니다. (해당 저자논문 github 이슈를 보면 FastV 방법론이 다른 논문들과 성능이 다르게 리포팅되어있다고 하는데, 저자의 실험세팅에서 재현실험을 한 것인지 관련내용에 대한 답변이 없네요..) 여기서 저자는 빨간색으로 색칠된 attention 관련 실험들이 64개 token 실험부터는 25%이상 성능 drop 이 나는 것을 주목합니다. 32token을 남긴 부분에서는 POPE 벤치마크에서는 오히려 성능이 올랐는데 이는 pruning이 hallucination을 줄일 수도 있다는 주장으로 언급하고 있습니다.
또한 VizWiz에서 성능이 크게 달라지지 않는 것은 질문이 “이게 무엇인가?” 와 같은 형태라 text relevance가 크게 의미가 없어서 그럴 것이라 추측한다고 합니다.
별 차이가 없어보일 수 있지만 해당 연구를 진행하고 있어서 비슷한 시기에 나온 논문들보다 훨씬 높은 성능이 나오는 것으로 보입니다…특히 128tokens 을 retain하는 섹션에선 전체성능에서 평균 99%성능 보존이 되는게 인상적입니다.
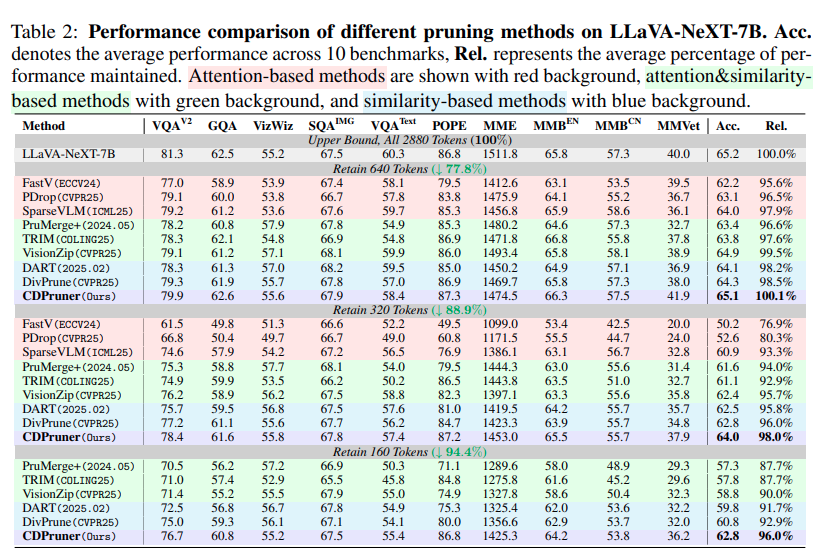
해당 Table은 고화질의 이미지를 넣는 LLaVA-NEXT 에서의 성능으로 해당 Table에서도 가장 높은 성능을 보이고 있습니다. 고화질일수록 token redundancy가 증가하여 이전 Table1보다 성능이 더 높게 나온다는 점을확인할 수 있습니다.
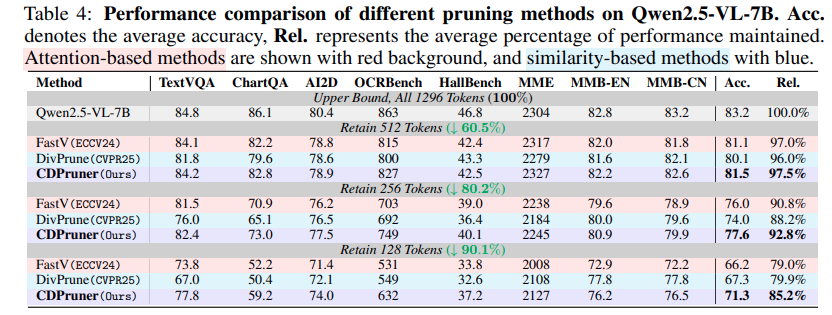
Qwen2.5-VL 의 결과는 dynamic resolution의 케이스인데, 저자의 방법론이 encoder를 바꿔도 잘 동작함을 볼 수 있습니다.
위의 실험 결과들로 저자는 attention 기반은 attention shift에 영향을 많이 받는다는 것을 보여주고, similarity만 보면 부족하며 relevance를 챙겨야하는점, 그리고 저자의 CDPruner가 relevance와 diversity를 모두 잘 챙긴다는 것을 정량적으로 증명한 것 같습니다.
Efficiency analysis
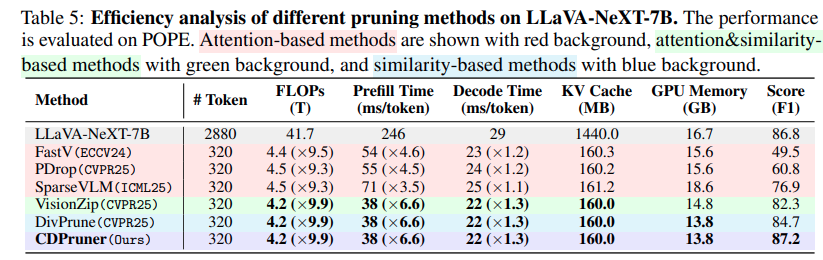
이 섹션에서는 CDPruner가 얼마나 효율적인지를 보여주는 것으로 FLOPs, CUDA latency, KV cache, GPU memory순으로 보여줍니다. POPE dataset이 데이터셋의 질문 길이가 비슷하여 사용했고 FLOPs가 거의 10배정도 줄어드는 것을 확인할 수 있습니다. 실제 실행 시간 기준으로 prefill 단계에서는 약 6.6배, decode 단계에서는 약 1.3배정도 빨라집니다. 또한 단순히 속도만 빨라지는 것이 아니라 KV cache크기나 GPU 메모리 사용량도 줄어드는 것을 확인할 수 있고 이는 inference시 필요한 전체 자원이 줄어드는 것으로 이해할 수 있습니다.
Conclusion
제가 앞서 리뷰한 Training-free visual token pruning 방법론들중 성능이 제일 높으면서 동시에 간단하면서 납득이 되는 논문이라 생각합니다. 단순히 token 간 유사도를 넘어서서 instruction 기반의 conditional similairty를 정의하여 이를 기반으로 token 선택 문제를 DPP로써 재정의한 논문입니다. 앞선 논문들이 기존 한계들을 잘 분석해주었어서 Related work로 짧고 굵게 잘 언급한 것 같고, 포지셔닝도 굉장히 잘 선택한 것 같습니다.
감사합니다.
리뷰 잘 읽었습니다 두 가지 궁금한 점이 있어 댓글 남갸두겠습니다.
1. instruction relevance를 실제로 어떤 feature 공간에서 계산하는건가요? 리뷰를 보면 token-token similarity는 projector 이후 visual token에서 계산하고, relevance는 LLaVA 기준으로 CLIP 쪽 표현을 쓴다고 이해됐는데, 그러면 두 점수가 서로 다른 표현 공간에서 만들어지는 게 아닐까 해서요.
2. relevance score에 음수 부호가 붙는 LLaVA 구현 부분 관련해서… 리뷰에서 이게 코드상 확인됐다고 하셨는데, 그렇다면 실제 LLaVA에서는 ‘질문과 관련 있는 토큰‘이 아니라 반대로 ‘덜 관련 있는 토큰‘을 남기는 방향이 아닌가요…? 이 부분을 어떻게 이해히먄 좋을까요?
안녕하세요 주영님 좋은 답글 감사합니다.
1번 내용은 제가 코드를 보고 어디쪽에서 계산하는지를 확인해본 것인데, 서로 다른 표현 공간에서 만들어지지만 projector를 타고나온 이미지의 similarity계산을 통해 패치간의 관계 matrix를 만들어내고, CLIP 을 통과한 visual patch와 text token들에 대한 relevance는 패치단위의 weight들만 만들어놓는 형태라 다른곳에서 계산해도 크게 문제는 없는 것 같습니다.
2번 내용에 대해서는 우선 깃헙 이슈내용을 복사해드리자면 다음과 같습니다.
“Yes, as you said, this phenomenon is quite interesting. As described in previous work such as ECLIP, the cosine similarity between image patches and text embeddings in CLIP is often counterintuitive. Therefore, when computing query relevance, we take the invertion of the similarity score. This approach can also be found in TRIM. It is worth noting that we have only observed this phenomenon in CLIP, so this adjustment is only applied in LLaVA.”
ECLIP에서도 비슷한 주장을 했었고 TRIM 논문코드에서도 동일하게 – similarity를 사용하는 것으로 확인했습니다.
CLIP이 patch level의 cosine sim이 텍스트와 높아지도록 학습된 것은 아니고, global 한 image-text alginment를 배우도록 학습되어서 실제 patch레벨의 attention을 뜯어보면 전체 특징을 나타내는 CLS-like의 배경 성분이 크게 반응할 가능성이 높다고 생각합니다. ECLIP 논문을 읽어본 것은 아니라 실제 해당 논문 저자가 뭐라고 주장했을지는 모르겟네요
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
최종적으로 LLM에 들어가는 visual token 수가 줄어 FLOPs나 KV cache 측면에서는 이득이 있지만, pruning 전에는 유사도 계산이나 greedy dpp과정이 필요할 것같은데 이때 오버헤드가 논문에 언급되어있다면 어느정도인지 궁금합니다. (dpp기반 subset selection 계산비용) 고해상도를 처리해야하는 환경에서 pruning 모듈 자체가 무거워 질 수 있지 않을까라는 생각이 단순히 들어서 댓글 듭립니다 감사합니다.
안녕하세요 우현님 좋은 답글 감사하니다.
오버헤드 자체가 논문에 언급되어있지는 않습니다. 아마 우현님 생각대로 썩 좋지는 않을 것 같다고 판단되는데, 저도 개인연구를 진행하고 있는 입장에서 이러한 latency 관점에서의 computational overhead를 하나의 contribution으로 가져갈까 고민중에 있습니다.
pruning이 KV cache 관점에서의 이득도 분명 존재하지만 여러 환경에서의 latency가 중요한거도 맞기에 올바른 지적을 해주신 것 같습니다.