안녕하세요. 오늘은 long video understanding 분야의 논문 중 긴 비디오를 무작정 탐색하는 대신 정답 선지에 대한 가설을 먼저 세운 뒤 영상의 증거로 검증하는 방식을 제안한 Think, Then Verify 논문을 리뷰해보겠습니다.
그럼 바로 시작하겠습니다.
Intro
긴 비디오 이해가 어려운 이유를 세가지로 정리합니다.
먼저 dense visual redundancy로 긴 비디오는 비슷한 장면이 계속 반복 되는데 실제로 중요한 정보를 가지는 프레임은 그중 일부 일부라는 점 입니다. 예를들어서 사람이 10분동안 바느질하는 영상이라 치면 비슷한 주방 장면이 계속되겠지만 질문을 푸는 데 필요한 장면은 몇 초가 안될수 있겠죠
두번쨰로는 long-range temporal dependencies입니다. 이건 긴 비디오에서 답을 내기 위해 멀리 떨어져있는 두 시점을 연결해야하는 경우가 많은데, 예를들어서 초반에 누가 물건을 집었고 후반에 그 물건때문에 사건이 벌어졌다면 단순히 현재장면만 보는것이 아니라 멀리 떨어진 시간 관계까지 이해해야 하는 것 입니다.
세번째로는 semantic drift and correlation-driven errors로 이게 저자들이 가장 중요하게 다룬 문제의식인데, 기존의 CoT나 retrieval 기반의 에이전트 들은 여러 단계를 거치며 추론을 진행하죠! 그런데 긴 비디오에서는 그 과정을 진행 하다가 chain이 길어지면 자칫 편향이 생기는등의 의미가 조금씩 틀어질수 있습니다. 이걸 semantic drift라고 합니다. 예를들어서 처음에는 해당 질문에 사람이 옷을 바느질 하는 장면을 확인해야해! 하고 시작했는데 중간에 천을 만지는 장면이나, 작업대에 앉아있는 장면 같은 겉으로만 관련있어 보이는 증거를계속 따라가다 보면 정작 핵심인 실제로 재봉틀을 썼는가를 놓칠수 있습니다. 즉 관련있어 보이는 것과 답을 판별하는 데 필요한 것은 다를수 있다는점 입니다. 그렇기 문에 긴 비디오QA의 핵심은 관련 클립을 찾느것이 아니라 애초에 무엇을 찾아야 하는지를 결정해야 합니다
저자들은 그럼 어떻게 해결하려 했을까요?
아이디어만 먼저 쉽게 살펴보자면 “먼저 찾지말고 먼저 생각하자! 각 선택지가 맞으려면 비디오에서 어떤 사실이 보여야 하는지 가설을 세우자! 그 다음 가설을 검증할 증거를 찾자!!” 라는 흐름입니다. 이 방식을 thinking-before-finding이라고 부릅니다. 즉 기존의 방식이 “찾고나서 생각” 이였다면, 저자들이 제안하는 방식은 생각하고 나서 찾기! 입니다. 바로 요 차이가 이 논문의 해결법의 핵심입니다!
또한 에이전틱 방법론들과의 차이를 직관적으로 살펴보자면 기존의 방법들이 plan→retrieve→re-plan→ retrieve again이였다면 저자들이 제안하는 방식은 hypothesize→derive clue→verify→integrate evidence로 명시적인 가설-검증 루프로 진행이 되는것 입니다
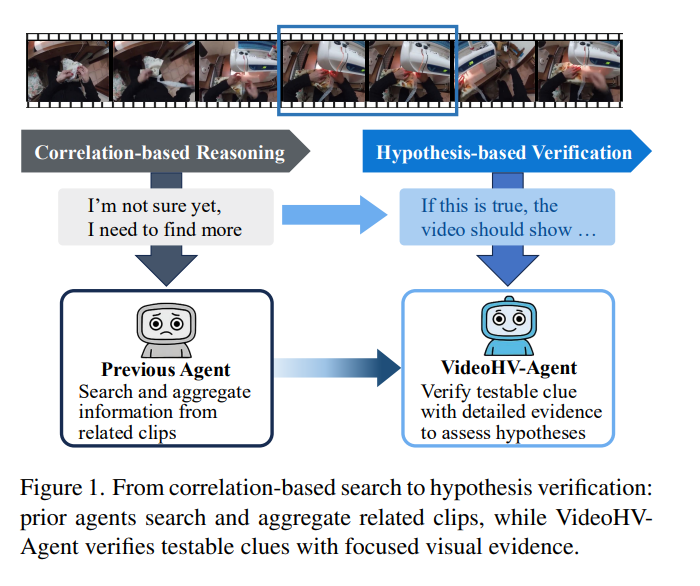
thinking-before-finding이라는 방식으로 해결하기 위해 총 4개의 에이전트를 사용합니다. 각 역할을 직관적으로 정리하자면, 먼저 Thinker는 보기들을 그냥 단순히 답의 후보로 두는게 아니라, 각 보기별로 검증 가능한 가설로 바꿉니다. 이게 무슨 말이냐면 예를들어 보기 중 B가 “그녀는 재봉틀을 사용했다.” 라면 가설은 더 구체적으로 “만약 B가 맞다면 이 비디오에는 재봉틀을 사용해 천을 이어붙이는 장면이 보여야 한다” 가 됩니다. 즉 답을 비디오에서 확인 가능한 주장으로 재작성 하는 역할입니다. 두번째로 Judge의 역할은 Thinker로 나온 가설들을 비교해서 어떤 포인트를 보면 이 가설고 저 가설들을 구분할수 있는지를 뽑아내는 것 입니다. 이게 clue(단서)로 위의 예를 이어 보자면, 재봉틀을 썼는지, 바늘과 실을 손으로 썼는지를 확인해라 같은 식 입니다. 이렇게 Judge는 검증의 초점을 잡아줍니다. 세번째로는 Verifier로 말 그대로 검증자입니다. 여기서 검증은 진짜 비디오를 보면서 앞의 Judge로 나온 clue를 검증하는거겠죠! 여기서가장 중요한 부분인 긴 비디오를 여기저기 냅다 뒤져보는게 아니라 그 clue와 관련된 국소적인 구간을 보고 세밀하게 확인한다는 점 입니다. 이 verifier가 수행하는 “찾기” 자체도 목적없는 검색이 아니라 검증을 위한 검색이 되는 것입니다. 마지막으로는 Answer입니다. 에이전트의 이름처럼 마지막으로 검증된 증거를 모아서 최종 답을 냅니다.이 과정들의 중요한 포인트는 마지막 답이 그냥 LLM의 블랙박스 식의 최종 답이 아닌 무엇을 확인했고, 어떤 증거가 있었고, 그래서 왜 이 답이 맞는지! 라는 형태로 설명 가능하다는 점(interpretability) 입니다.
저자들은 제안하는 이 VideoHV-Agent의 장점을 3가지로 정리합니다. 먼저 enhanced interpretability로 윗 문단에 간단히 설명했듯이, 가설→단서→검증→최종답 의 흐름이 보이기 때문에 왜 이 답이 나왔는지를 더 잘 설명할 수 있습니다. 두번째로는 improved logical soundness로 이 정답 추론의 과정이 냅다 그냥 관련 장면을 많이 모으는 방식이 아니고 답이 맞으려면 무엇이 참이여야 하는지를 먼저 따지기 때문에 논리적으로 아주 탄탄하다고 주장합니다. 세번째로는 lower computational cost로 의외로 비용도 낮다고 합니다. 전체 영상을 냅다 다 훑는 대신 판단에 필요한 국소 구간만을 집중해서 보기 때문이라고 합니다. 종합하자면 결국에 더 정확하과 더 설명 가능하면서 더 효율적이라는 주장입니다.
Method
VideoHV-Agent의 전체 흐름은 크게 3단계로 이루어져있습니다
먼저 query-conditioned summary단계로 거친 수준의 파악을 진행합니다. 샘플링된 프레임들(1fps)에서 텍스트 설명을 얻고 질문에 맞춘 요약을 만드는 것으로 어떤 답딜이 대충 가능해 보이는 지를 빨리 가늠하는 단계입니다.
두번째 단계로는 Thinker + Judge로 먼저 thinker가 각 선택지를 가설로 바꿉니다. 예를들어 선택지가 남자가 사과를 씻었다 라면 가설은 (이 선택지가 맞다면 비디오에서는 남자가 사과를 물에 대고 씻는 장면이 보여야 한다)라는 식 입니다. 그럼 이 가설들의 사이를 구별하는 최소한의 clue(과일을 자른것인지 씻은것인지 확인해라)를 judge가 만듭니다. 그후 Verifier로 이제 실제 비디오에서 clue를 확인합니다. 전체를 다 보는것이 아닌 관련된 소수의 클립만 찾아 세밀하게 캡셔닝 합니다. 그 후 결과를 세가지(VERIFIED(지지), PARTIAL(부분지지), NOT VERIFIED(반박))중 하나로 판단합니다.
마지막 단계로 Answer는 검증된 증거와 요약정보를 합쳐서 최종 답을 도출합니다.
1. Main Framework
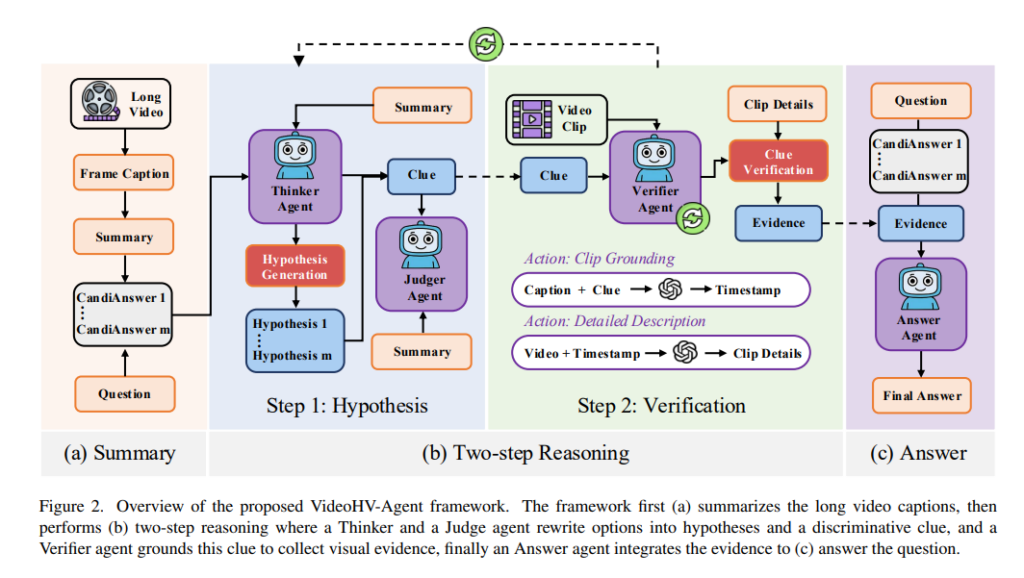
프레임워크는 fig2처럼 크게 context summarization, two-step reasoning, evidence integration의 3단계로 진행이 됩니다.
[ Context Summarization ]
그림의 (a)단계로 비디오에 대해 프레임 캡셔닝을 진행하고 전체를 요약하는 것으로 비디오를 바로 끝까지 깊게 추론하는 것이 아니라 먼저 요약된 전반적인 맥락을 만드는 단계입니다.
먼저 frame-level의 캡션(P_v)을 만듭니다. 그다음 이 많은 캡션들을 그대로 다쓰는게 아니라 질문에 맞게 중요한 내용만 모아서 짧은 요약(P_s)를 만듭니다. 이걸 질문 조건이 반영된 요약(query-conditioned summary)라고 합니다.
[ Two-step Reasoning ]
(b)단계로 앞선 요약을 바탕으로 가설을 세우고 그 가설을 검증합니다. 이 단계에서는 총 3개의 에이전트(Thinker, Judger, Verifier)가 사용됩니다. 이때 two-step reasoning 단계는 비디오QA를 가설–검증(hypothesis–verification)으로 재구성하는 단계로 self-refinement loop를 통해 반복됩니다.
먼저 가설 생성하는 단계인 Hypothesis Generation은 Thinker agent를 통해 각 선지들을 그 선지가 성립하려면 비디오에서 무엇이 있어야 하는지를 명시하는 검증 가능한 가설로 다시씁니다. 예를들어 선지A가 바늘로 실을 연결했다, 선지 B가 재봉틀로 천을 연결했다.라면 thinker는 (A가 맞다면 손바느질 동작이 보여야 한다), (B가 맞다면 재봉틀 위에서 천을 밀어 넣으며 연결하는 장면이 있어야 한다.)와 같은 식으로 검증 할수있는 주장으로 변환하는것 입니다. 이때 가설들은 선지와 1대1로 생성됩니다.
이후 Judger가 가설들 사이의 핵심 차이가 무엇인지 찾습니다. 요 맥락이 좀 중요한 포인트 인데, Thinker가 각 선지에 맞게 가설을 만들고 그걸 하나하나 요약글에서 따로 검증하면 비효율적이기 때문에 이 선지 가설들을 보고 결국 정답을 구분하려면 무엇을 확인해야하는지를 한줄 clue로 압축하는것 입니다. 즉 이 Judger를 통해서 도출되는 것은 검증해야 할 핵심 포인트를 최소화한 질문(clue)입니다.
다음으로 만든 가설들을 검증하는 단계인 Hypothesis Verification로 이제 Verifier가 사용됩니다. 이 Verifier는 앞서 가설 생성단계에서 도출된 clue를 바탕으로 영상에서 딱 필요한 구간(minimal temporal context)만을 찾아봅니다. 예를들어 clue가 (재봉틀을 쓰는지 확인해라)였다면 재봉하는 구간이 있는 짧은 시점만 보는 것 입니다. 그 다음 detailed captioning같은 세밀한 분석 도구를 사용해서 그 구간에서 실제로 무슨일이 일어나는지를 더 자세히 살펴봅니다.
이렇게 clue 기반으로 영상을 살펴본뒤, Verifier는 총 3가지 상태로 결과를 냅니다. 3가지 상태는 아래와 같습니다. 즉, 검증의 결과를 단순히 yes or no로 끝내는 것이 아니라 중간상태(Partiar)를 둬서 불확실성을 다룹니다.
- VERIFIED : 단서가 확인됨
- PARTIAL: 일부만 확인됨, 아직 더 봐야 함
- NOT VERIFIED : 지금 단서나 가설로는 확인이 안 됨
또한 이 단계에서는 한번에 못 맞히면 가설 자체를 다시 다듬는 Self-Refinement Loop단계를 진행합니다.
처음 검증이 실패했다면 specificity enhancement를 통해 가설을 더 구체적이고 검증 가능하게 다시 씁니다. 예를들어 처음 가설이 너무 넓고 모호해서 검증이 잘 안된다면, 이후에는 재봉틀 바늘 아래로 천이 지나가는지처럼 더 구체적으로 확인할 수 있는 형태가 되도록 가설을 다시 정비하는 것입니다. 그러면 그에 맞춰 clue도 다시 업데이트됩니다. 반대로 선지 가설들이 예를들어 A가설이 (손으로 천을 만짐) 이고 B가설도 (손으로 천을 만짐) 처럼 비슷할수도 있겠죠?! 이럴 땐 discriminability enhancement를 통해 가설들의 차이를 더 선명하게 만들도록 선지 가설을 다시써서 의미적 대비를 더 키워줍니다.
즉 이 프레임 워크는 처음 세운 가설과 clue를 절대적인 것으로 두지 않고 검증 실패를 이용해서 가설을 다시 정비하고, 그에 따라 clue도 함께 업데이트하는 것으로 다음 추론을 더 잘 할수 있도록 만드는 구조입니다.
[ Evidence Integration ]
마지막(c)단계로 요약과 검증 증거를 종합해서 정답을 내는 구간입니다. 앞에서 모은 요약정보, 검증결과, 어느 가설이 지지되는지, 어느가설이 반박되는지를 전부 종합해서 reasoning chain을 만듭니다. 예를 들어서 A는 아예 반박됨, B는 일부 비슷하지만 핵심 증거가 없음, C는 지지하는 증거 강하게 나옴 이라면 이런 구조를 설명하면서 C를 고르는 방식 입니다. 이렇게 하는 것으로 LLM의 직감 같은 단순 추론이 아닌 검증된 증거의 결과물이 되도록 하는 것 입니다.
2. Details of Two-step Reasoning

위 알고리즘 처럼 프레임워크를 크게 3단계로 확인해 보았다면, 이번엔 이 프레임워크의 핵심인 fig2의 (b)단계(Two-stage Reasoning)의 디테일을 살펴봅시다. (알고리즘 5~15행)
[ Step 1: Hypothesis ]
보통 객관식 문제를 풀때는 선지 A,B,C중 뭐냐!? 하고 답을 고르는 것 이지만 저자들은 이 문제를 단순히 정답 고르기가 아니라 가설 쓰기 문제로 바꿨습니다. 이 가설과 관련된 부분을 Hypothesis Generation과 Clue Generation로 나누어서 살펴봅시다
먼저 Hypothesis Generation의 구성요소는 크게 3가지로, salient entities,objects(핵심 인물, 물체, 객체) / action,events(무슨 행동, 무슨 사건이 벌어지는지) / temporal,causal constraints(시간 순서,원인-결과 관계) 와 같이 이루어져 있습니다. 즉 좋은 가설은 “재봉틀을 썼다” 이 수준이 아니라 “사람이 천을 재봉틀 바늘아래로 넣고 그 과정에서 손으로 정렬을 맞추는 장면이 보여야한다” 처럼 더 구체적이여야 합니다.
또한 fig3과 알고리즘을 보면 요약을 Thinker에 넣어주는데 이때 Thinker가 요약만 봐도 명백히 아닌 선택지를 먼저 걸러내기도 합니다. 이 말은 모든 선지를 무조건 다 똑같이 다루는게 아니라 summary수준에서 이미 너무 가능성이 낮은 선지라면 초기에 버리도록 하는 것입니다. 이렇게하면 불필요한 verification비용을 줄이거나 괜히 엉뚱가설 때문에 생기는 noise를 줄일수 있겠죠?!
다음으로 Clue Generation는 Judger에서 생성되는것인데, 여기서의 핵심은 minimal observation(최소 관찰 정보) 입니다. 즉 Judger의 역할은 단순 요약이 아니라 이 가설들 사이를 가르려면 최소환 무엇을 확인해야하는가?! 를 찾아내는것 입니다.
그럼 이 clue가 굳이 왜 필요할까요? 저자들은 특히나 긴 비디오에서는 가설을 그냥 하나씩 따로 검증하기위해 각 가설마다 영상을 다시 뒤지기 시작하면 비용이 금방 커지기 때문에 느리고 비효율적이라고 합니다. 그래서 Judger가 서로 겹치는 부분은 버리고 진짜 차이를 만드는 부분만 남겨서 Verifier가 봐야하는 포인트를 좁혀주는 것 입니다.
[ Step 2: Verification ]
그럼 Verifier가 clue를 기반으로 어떻게 VERIFIED/PARTIAL/NOT VERIFIED라는 결과까지 도출되는지를 구체적으로 살펴봅시다. 앞선 단계에서 clue가 넘어오면 이 clue를 실제 영상에서 어느시점에 나오는지를 찾아야겠죠. 따라서 먼저 frame-level의 캡션 P_v를 훑어보면서 그 clue와 가장 잘 맞는 시간구간(temporal window)를 고릅니다. 이때 전체 비디오가 아니라 clue를 판별하는데 필요한 최소 구간만을 선택하는것 입니다.
그럼 이렇게 시간 구간이 선택되고 나면 그 구간에 대해서 raw frames을 다시 봅니다. 요 과정을 논문에서는 Detailed Captioning라고 하는데, 이 raw frames를 디테일하게 다시 보는 이유는 처음 뽑아진 P_v는 거친수준의 캡셔닝으로 결정적인 단서 같은것 들이 빠질수가 있기 때문에 해당 구간에서만 fine-grained captioning을 추가로 진행해주는 것 입니다. 이때 이 detailed captioning은 해당 구간에서 최대 5프레임까지 본다고 합니다.
이렇게 디테일까지 확인하는것으로 clue에 대해서 살펴보고 나면 최종적으로 검증 상태를 냅니다. 검증 상태는 앞서 말한 것 처럼 3개로 구성되어있는데, 먼저 VERIFIED는 증거가 충분하기 떄문에 clue가 확인되었다는 상태로 summary와 함께 최종 답으로 이어집니다. 두번째로 PARTIAL은 일부는 맞는데 아직은 부족하다는 의미로 추가 프레임 추가 관찰이 필요합니다. 따라서 가설이나 clue는 유지한 채로 추가 구간을 더 찾아봅니다. 마지막으로 NOT VERIFIED는 현재 clue자체가 구리거나 이 선지가설 구조로는 잘 검증되지 않는다는 것을 의미합니다. 이 경우에는 단순히 더 찾는다고 해결되는것이 아니기 때문에 hypothesis와 clue를 다시 만들어 주어야 합니다.
Verifier가 검증 상태를 도출하면서 단순히 상태만 결과로 내는게 아니라 어디서 봤는지(timestamps), 무엇을 관찰했는지(entities), 그래서 어떤 추론을 진행했는지(relations)와 같은 근거를 붙이고 이 증거를 조합해서 reasoning trace를 만듭니다. 그래서 이 reasoning trace가 뒤에서 Answer agent가 최종 판단을 할때 쓰이는 근거의 체인이 되는것 입니다.
4. Experiment
1. Main result
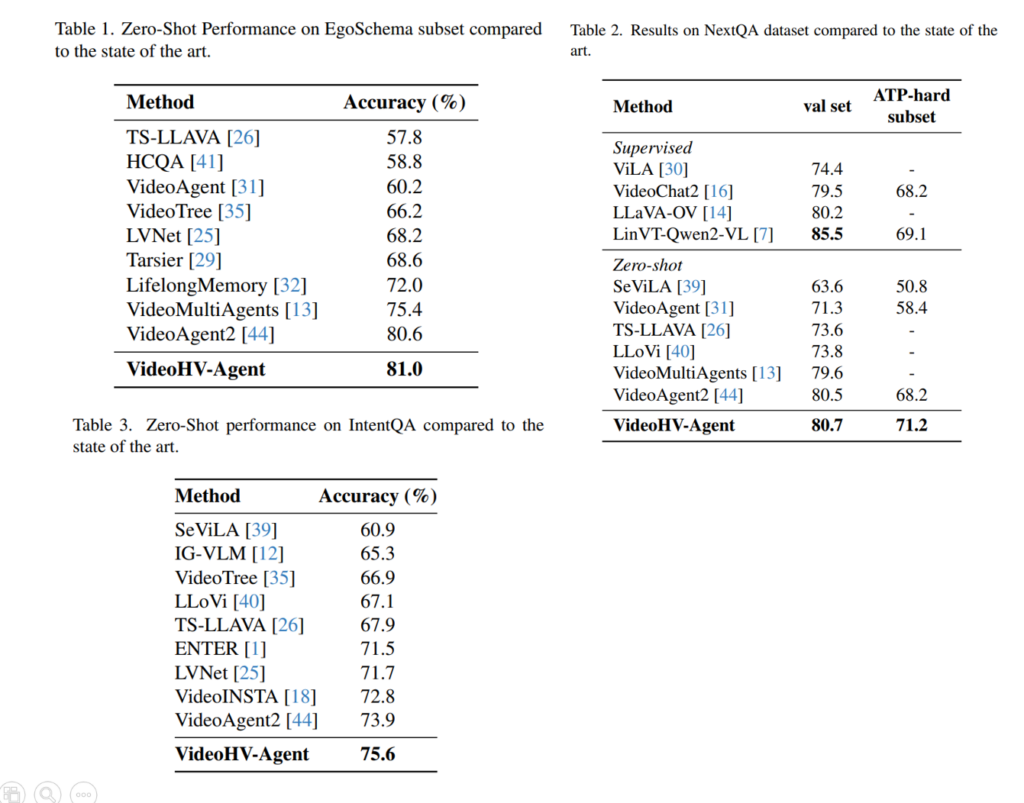
EgoSchema, NextQA, IntentQA 벤치마크에서 다른 방법론들과 실험을 진행했고, 프레임워크에서 있던 4개의 에이전트에 대해 LLM backbone으로 GPT-4o을 사용했습니다. table1,2,3에서 볼 수있듯이 저자들이 제안하는 VideoHV-Agent가 세 벤치마크에서 모두 sota인 것을 확인할수 있습니다. table 2의 NextQA의 ATP-hard subset는 복잡한 추 문제들을 모은 서브셋인데 여기서도 크게 성능이 향상되는것을 확인 할수있습니다.
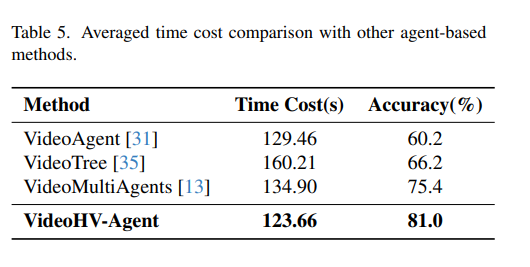
추가로 table5에서 다른 에이전트 기법들과 비교해서 속도 측면에서도 강한것을 확인할수 있는데, 이 부분에 대해서 저자들은 VideoHV-Agent가 기존 agent들처럼 긴 영상을 반복적으로 훑어가지 않고 summary와 clue를 이용해 필요한 구간만 정밀하게 확인하기 때문에 더 정확하면서도 더 빠르다고 합니다.
2. Ablation study
Ablation 실험으로 성능이 단순히 GPT-4o가 세서 나온게 아니라 hypothesis, clue, verification status, refinement loop 같은 구조 덕분인지 확인합니다.
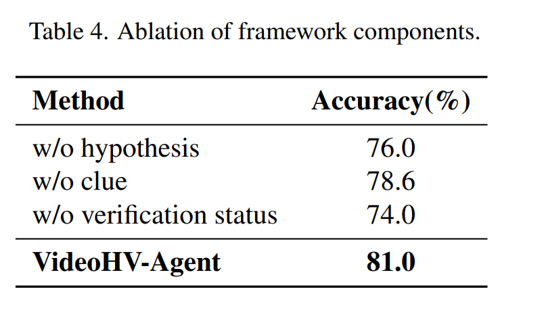
[Without hypothesis generation]
table4에서 먼저 선지 가설 생성을 제거한 실험으로, 이렇게 되면 선지들의 표면적인 차이만 가지고 clue를 만들게 됩니다. 결과적으로 5.0%가 떨어지는 것을 확인할 수있는데, 이 결과로 논문에서 말하는 think then verify 에서 think, 즉 선지를 먼저 검증 가능한 가설로 바꾸는것 자체가 중요하다는 것을 알수 있습니다.
[Without clue generation]
두번로 clue 생성 제거 실험입니다. 가설제거보다는 하락폭이 작은 2.4정도인데, 저자들은 이 이유를 개설 생성은 선지들을 검증가능한 형태로 바꾸는 핵심단계이고 이 clue 생성은 그 가설들 간의 차이를 검증포인트로 압축하는 것이기 때문이라고 합니다. 즉, 선지 가설 생성이 더 큰 뼈대 역할을 하고 clue는 그 뼈대를 실제 검증 방향으로 좁혀 주는 역할이라고 볼수있습니다.
[Without verification status]
마지막으로 verification 상태 제거 실험인데, 7.0정도로 가장 크게 하락한 결과를 보입니다. 이것은 프레임워크상 당연한 결과일텐데, status가 있어야 현재 증거가 충분한지, 모자란지, 가설 자체를 다시 짜야하는지가 정해지기 때문입니다. 없으면 증거가 애매해도, 부족해도 그냥 넘어가면서 인트로에서 저자들이 언급한 semantic drift나 오류 누적이 다시 생기게 될수도있게 되겠죠
[Ablation of the number of loops]
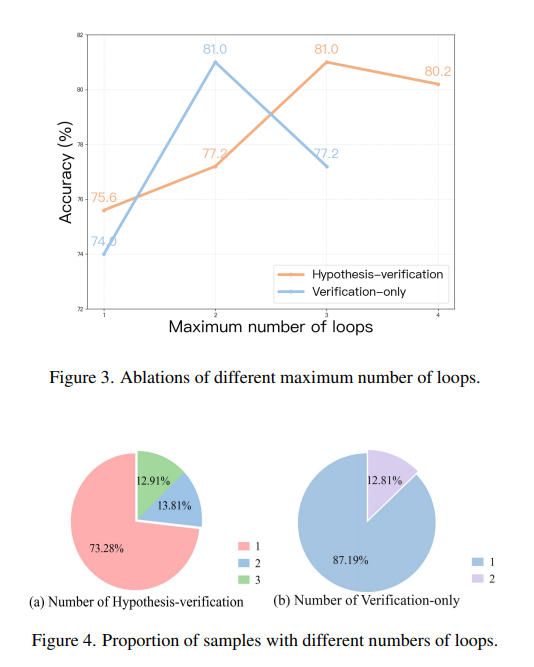
이번에는 fig3,4의 Two-step Reasoning에 대한 루프 실험을 보겠습니다. 앞서 메소드에서 설명한 것처럼 루프는 크게 Hypothesis-verification loop와 Verification-only loop로 두 종류 입니다.
먼저 fig3처럼 최대 루프 수를 늘리면 주황색인 hypothesis-verification은 대체로 올라가서 3회 부근에서 최고점을 찍고 약간 유지되고, 파란색인 verification-only는 초반에 크게 좋아졌다가 이후 다시 내려가는 것을 볼수 있습니다. 저자들은 이 부분에 대해서 VideoHV-Agent가 대체로 한두 번의 반복만으로도 중요한 단서를 효율적으로 잘 찾고, 이후 추가 루프는 꼭 필요한 경우에만 보완적으로 작동한다고 해석합니다. 따라서 반복은 도움이 되기는 하지만 너무 많이 늘리면 성능 향상의 폭 점점 작아지면서 무조건 많이 반복하는것은 좋은것이 아니라고 봅니다 실제로 fig4에서 처럼 대부분의 문제들은 한번의 루프 만으로도 충분한 것을 확인할 수 있습니다.
추가로 정성적인 확인은 아래와 같습니다.

안녕하세요 찬미님 좋은 리뷰 감사합니다.
간단한 질문이 있는데, 검증하는 단계에서 모든 frame을 보지않고 빠르게 해당 부분을 찾기 위해 clue 를 활용하여 캡션에서 가장 잘 매치되는 구간을 찾는 것으로 이해했는데, 그러한 최소구간을 어떻게 찾는건지에 대한 디테일이 있나요? 그것도 그냥 LLM agent로 하여금 캡션을 훑고 clue 기반의 가장 매치되는 frame들을 골라줘 와 같은 형태의 입력이 들어가는건지 궁금합니다.
감사합니다.
안녕하세요 인택님 댓글 감사합니다.
이해 하신 흐름이 맞습니다! 논문 기준으로는 별도의 세밀한 구간 찾는 알고리즘이 따로 있기 보다는 결국 LLM agent에 clue와 frame-level caption을 프롬프트로 넣었을 때 LLM agent가 관련 구간을 고르는 방식에 가깝습니다. 그 다음 그 구간만 다시 자세히 봐서 검증하는 구조입니다!
좋은 리뷰 감사하빈다. 몇 가지 질문이 있어 댓글 남겨두겠습니다
1. summary를 만들 때 1fps로 샘플링된 프레임을 사용한다고 하셨는데, 이 fps는 고정인지, 아니면 비디오 길이에 따라 조정되는지도 궁금합니다.
2. Thinker가 summary를 보고 명백히 아닌 선택지를 초기에 걸러낸다고 하셨는데, 이게 filtering이 heuristic인지, 아니면 LLM이 자연스럽게 판단하도록 유도하는 프롬프트 기반인지 궁금합니다.
안녕하세요 답변 감사합니다!
1. fps는 논문 기준 고정 1fps입니다. 비디오 길이에 따라 조정한다는 내용은 따로 없습니다.
2. 초기 필터링도 휴리스틱이라기 보다는 프롬프트 기반 LLM판단에 가깝습니다. 어펜딕스에 프롬프트가 있는데 해당 부분에 Thinker가 summary를 보고 “확실하게 부적절한 옵션은 hypothesis를 만들지 말라!”는 식으로 지시프롬프트를 받습니다.
안녕하세요 좋은 리뷰 감사합니다.
검증을 통해 증거 영역을 찾는 iteration을 반복하는 알고리즘으로 구성되어있는데, 반복의 횟수는 1회로 이해하면 될까요? Figure3에서는 보통 1, 2회의 반복으로 충분하다고 하나 비교적 짧은 데이터에 대해 실험한 것같습니다. 혹시 video mme나 long video bench 같은 다른 데이터셋에 대한 실험이 부록이나 언급에 있었는지 궁금합니다
감사합니다
안녕하세요 유짐님 댓글 감사합니다
반복은 1회 고정은 아닙니다! 필요하면 추가반복이 가능하고 verification단계에서 evidence를 더 찾는 루프와, 가설과 clue자체를 다시 만드는 루프로 나누어져있습니다.
또한 롱비디오 데이터셋 실험으로는 어펜딕스에 VideoMME-L를 사용해서 성능을 확인한 실험이 있기는 하지만 루프 횟수 자체를 별도로 분석해서 보여주진 않아서 롱비디오에 대해서도 동일하게 1~2회로도 충분한지에 대해서는 단정짓기 어렵다고 생각됩니닷!