안녕하세요 이번에 들고온 논문도 VLM 에서의 token pruning 논문입니다.
해당 논문은 25년도까지의 pruning 논문들이 ViT의 [CLS] 토큰이나 llm decoder 단에서의 visual-text attention 정보에 어느정도 의존하는 것을 넘어서 다른계열의 방법론을 제안했습니다.
그럼 리뷰 시작하겠습니다.
Abstract
기존 연구들이 보통 [CLS] attention 이나 text-vision cross-attention을 이용해서 중요하지 않은 visual token을 제거하는 방식을 사용해왔습니다. 실제로 이런 방식들이 어느 정도 성능은 잘 나오긴 하는데, 논문에서는 두 가지 한계를 지적합니다. 하나는 positional bias 문제이고, 다른 하나는 FlashAttention같은 효율적인 attention 커널과 호환이 안된다는 점입니다. 즉, 실제로 빠르게 돌리려고 하면 오히려 구조적으로 맞지 않는다는 문제가 있습니다.
그래서 이 논문은 아예 attention 기반 접근에서 벗어나서, visual token compression을 정보 관점에서 다시 보겠다는 방향을 취합니다. 제가 성능쪽 이야기는 Abstract에서 거의 다루지 않는데, 해당 저자의 방법론을 사용하면 video 쪽 도메인에서는 87.5% token을 드랍했을떄 오히려 성능이 오르는 경향을 보여준다고 하네요..(물론 토큰수 드랍이나 데이터셋은 어느정도 체리핔 했을 가능성이 있긴 합니다.)
Introduction
최근 VLMs 들에서 자주 언급되는, image token의 redundancy 를 언급하며 고해상도 이미지나, 비디오 도메인에서는 token pruning이 필수적임을 간단하게 언급하며 시작합니다.
기존 VLM token pruning 논문들은 대부분 LLaVA의 이미지 인코더인 ViT의 [CLS] 및 patch token들과의 attention score 기반의 pruning을 진행하거나, Decoder 단에서의 Text-Visual attention을 사용하여 중요도 기반의 pruning을 진행합니다. 저자는 그중 특히 Decoder 단에서의 attention weights 들을 사용하는 방법론들은 Flash attention을 사용하지 못함에 주목합니다. pruning이 efficient라는 어떠한 도메인에 묶이는 방법론들임에도 불구하고, 정작 Flash attention을 사용하지 못한다는 점이 아이러니 하다는 것을 지적하는 것입니다. ( decoder 단에서의 text-visual attention을 이용하면 Flash attention 을 사용하지 못하는 이유는 Flash attention이 attention weights를 중간에 꺼내볼 수 없기 때문입니다.)
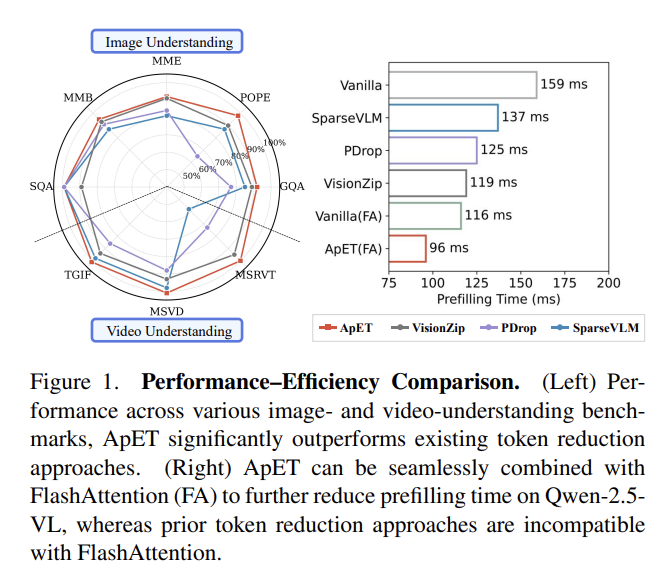
Figure 1의 좌측은 최근 방법론들과의 성능 비교라고 보면 되고, 우측은 위에서 언급한 FA(Flash attention)을 사용하는 것보다도 기존 방법론들이 더 느리고, 저자의 방법론은 FA 까지 적용하면 더 빨라지는 것을 보여주는 것입니다.
제가 알기로 VisionZip 논문은 vision encoder 단에서의 attention weight를 사용하기 때문에 Flash attention을 사용할 수 있는 것으로 알고있는데.. 논문을 읽거나 코드를 봐본건 아니라 정확하진 않습니다. 그리고 저자의 논문이 언제부터 아카이브였는지는 모르겠으나 25년도의 SOTA 방법론들이 꽤나 많이 리포팅에서 빠져있네요
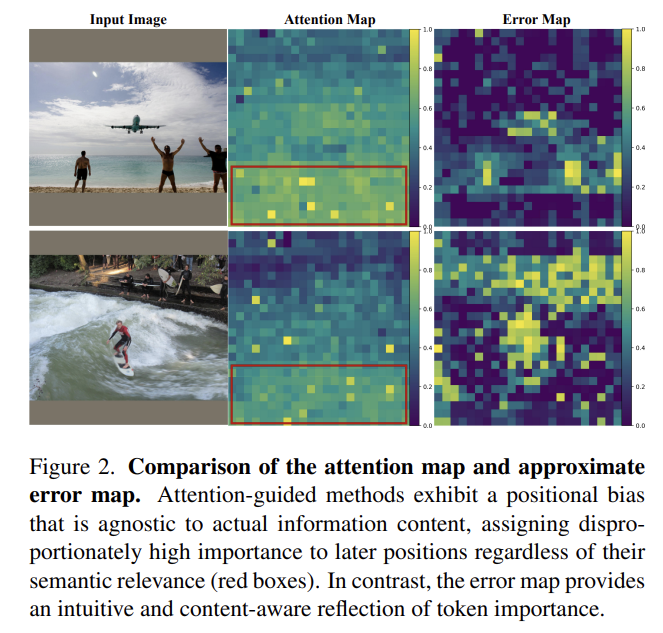
해당 Figure는 기존 Attention based 의 방법론들이 겪었던, Attention shift를 보여주는 예시입니다. 제가 이전 Token pruning 논문들에서도 다뤘지만, LLM decoder 단에서는 RoPE 에 의한 Atention shift문제가 존재합니다. 따라서 해당 figure 의 attention map 에서 보이듯 semantic relevance가 없어보이는, 이미지의 하단부에 위치한 attention 치우침 현상이 생기게 됩니다. 자세한 이유는
제 이전 논문 리뷰의 내용 및 댓글을 확인해주시면 이해하기 편할 것 같습니다. 우측 Error Map은 저자가 제안하는 방법론은 대조적으로 semantic relevance를 보여준다고 하네요.
앞서 지적한 문제들을 해결하기 위해, 이 논문에서는 ApET라는 방법론을 제안합니다.
핵심 아이디어는 생각보다 단순한데 각 visual token을 다른 일부 token들로 선형적으로 재구성해보고, 이때 발생하는 reconstruction error를 이용해서 해당 token이 얼마나 중요한지를 판단하겠다는 것입니다.
구체적으로 보면, 먼저 전체 token 중 일부를 선택해서 basis처럼 사용하고, 이걸로 나머지 token들을 선형결합으로 근사합니다. 그 다음 각 token이 얼마나 잘 근사되는지를 보는데, 이때 reconstruction error가 작으면 그 token은 다른 token들로 충분히 표현이 가능하다는 의미이기 때문에 정보량이 적다고 보고 제거 대상이 됩니다. 반대로 error 가 크면 다른 token들로 대체하기 어렵다는 뜻이기 때문에 정보량이 크다고 보고 유지하는 방식입니다.
결국 이 논문이 말하는 핵심은 token의 중요도를 attention 같은 외부 신호로 판단하는 것이 아니라, 그 token 자체가 가지는 “재구성 난이도”, 즉 approximation error로 판단하겠다는 것입니다. 이게 저자들이 말하는 intrinsic information이라는 개념입니다.
저자는 contribution을 다음과 같이 언급합니다.
- VLM 에서 visual token의 중요도를 정보-이론 관점에서 분석하고, approximation error를 통해 각 token 이 가지는 정보량을 정량화할 수 있다는 새로운 관점을 제시합니다. 이를 통해 attention이나 다른 외부 신호 없이도 token 중요도를 평가할 수 있다는 점을 보여줍니다.
- 이러한 분석을 기반으로 ApET라는 toekn compression 방법을 제안하고 해당 방식은 위에 언급한 positional bias 문제를 제거하면서도 기존 효율적인 연산 구조(Flash attention)와 호환됩니다.
- 마지막으로 여러 벤치마크에서 높은 성능을 유지하면서도 token 수를 크게 줄일 수 있음을 보였다고 합니다.
Method
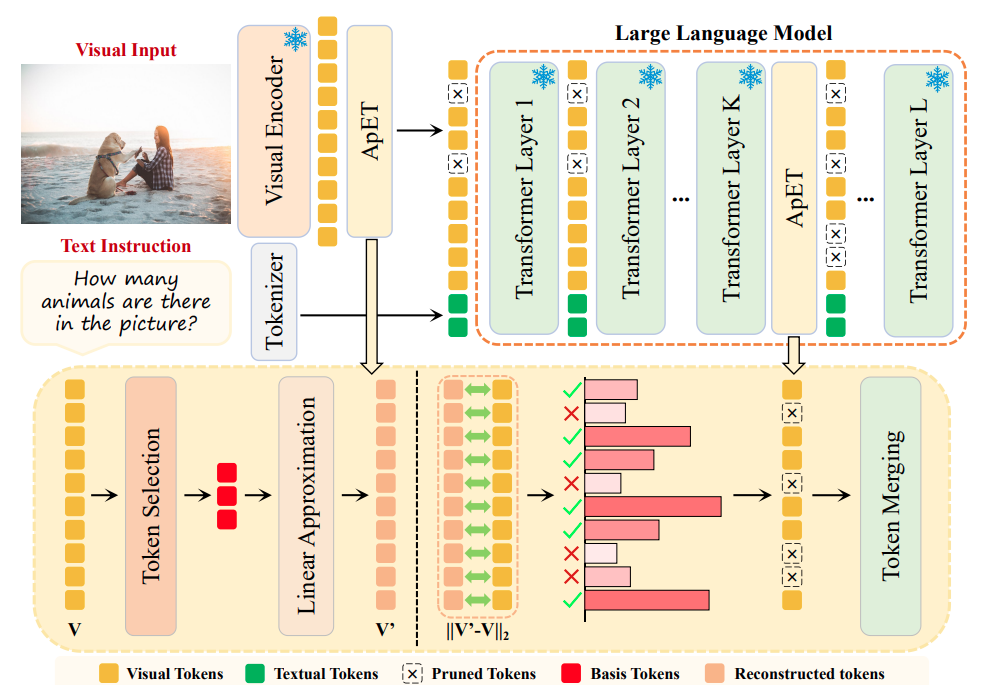
대부분의 VLMs 들은 3가지 구성요소로 되어있습니다. visual encoder와 feature projector 그리고 LLM decoder 순서로 이미지를 처리합니다. 물론 text도 기존 로직과 같게 tokenize 되어서 LLM 에 같이 들어가게 됩니다.
구체적으로 전체 Visual token 집합 V가 있을때, 이를 일부 subset S로 줄이되, 원래 정보는 최대한 유지하는 것을 목표로 합니다. 이를 mutual information I(V;S) 최대화 문제로 정의합니다.
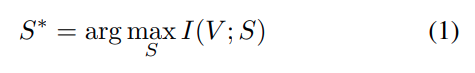
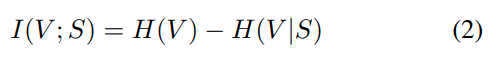
여기서 mutual information은 위의 수식(2)로 정의되는데, H(V) 는 원래 토큰들의 entropy이고 H(V|S) 는 subset S 를 보고 난 뒤에도 남아있는 불확실성입니다. 따라서 저자의 (1)번식은 결국 H(V)는 입력이 주어지면 고정되는 값이므로, H(V|S) 를 최소화하는 문제로 정의되고, 즉 선택된 token S로 전체 V를 얼마나 잘 설명할 수 있는지로 생각하면 됩니다.
문제는 이걸 직접 계산하는 게 불가능하다는 점입니다. 실제로는 p(V,S) 같은 분포를 알아야 entropy를 계산할 수 있는데, 이걸 현실적으로는 구할 수 없고, 저자는 reconstruction error로 바꿔서 근사합니다.
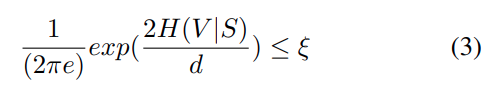
따라서 Reconstruction error를 줄이면 H(V|S) 도 줄어들게 되고 결론적으로 reconstruction error를 줄이는 것이 정보 손실을 최소화하게됩니다.
다만 저자는 별도의 reconstruction 모델을 사용하는 것은 아니고, 단순하게 linear approximation으로 근사해서 추정하게 됩니다. 일부 token을 basis로 선택하고 나머지 toekn을 이걸로 선형 결합해서 근사합니다.
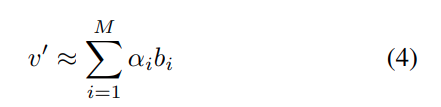
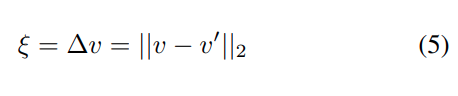
여기서 b_i 는 basis token이고, \alpha_i 는 계수입니다.
즉 error 가 작으면 다른 token으로 표현이 가능하여 중요도가 낮고, error 가 크면 대체 불가능하여 중요도가 높다고 생각합니다.
저자는 전체 과정을 3가지로 요약하는데
- Token selection 에서는 전체 token 중에서 일부 token을 basis로 선택하는 과정이고, FPS (가장 멀리 떨어진 샘플 선택) DPC (density 기반) random 3가지를 비교하게 됩니다.
- Approximation-Error 계산은 위의 수식으로 진행합니다.
- Token merging 과정은 importance가 가장 낮은 toekn을 제거하는데, 그냥 버리지 않고 가장 비슷한 token과 merge 합니다.
Experiments
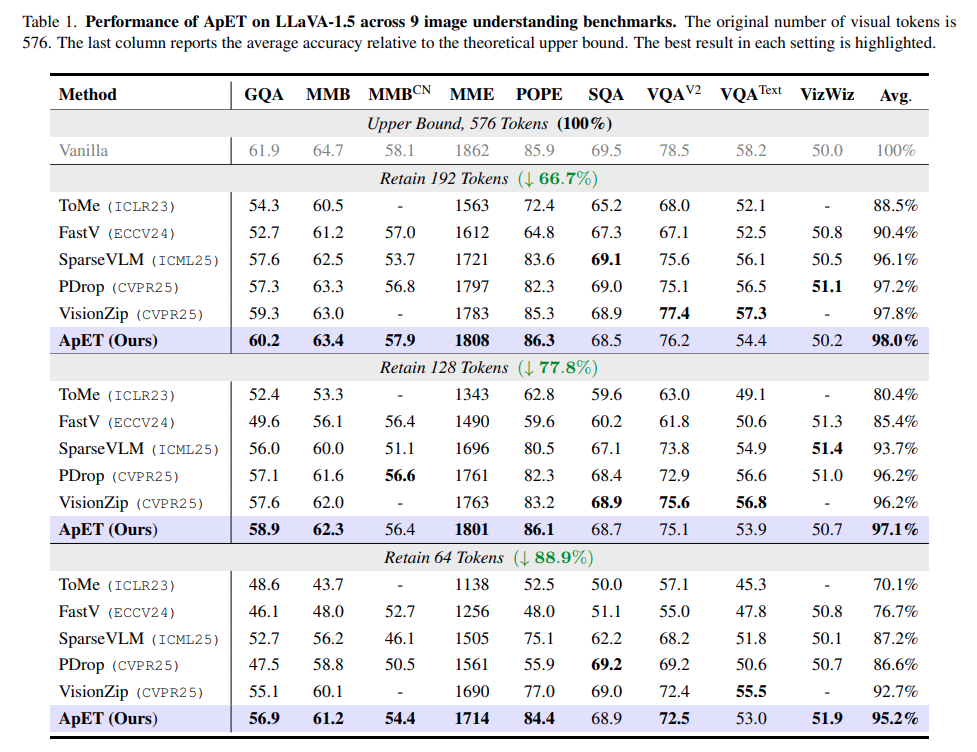
우선 LLaVA-1.5 7B 메인 성능으로, 기존 SOTA 방법론들을 전부 제친 성능입니다. 다만 25 ICCV 논문을 포함하여 리포팅 했다면 SOTA일지는 불분명하네요.
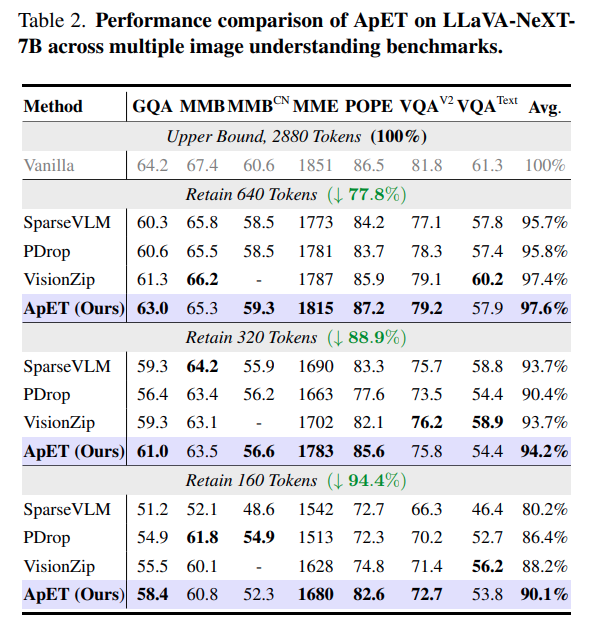
아래는 LLaVA-NeXT 7B의 성능으로 똑같이 SOTA인 모습입니다. 고해상도 이미지를 다루는 만큼 들어가는 visual token 수가 많음을 알 수 있습니다.
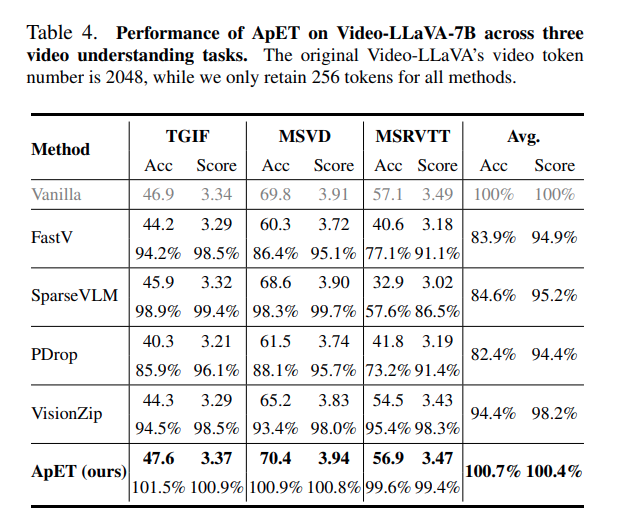
해당 Table은 Video-LLaVA 7B 성능으로 저자의 방법론만 pruning을 적용하더라도 MSRVTT 데이터셋을 제외하고는 성능이 오르는 모습을 보여줍니다.
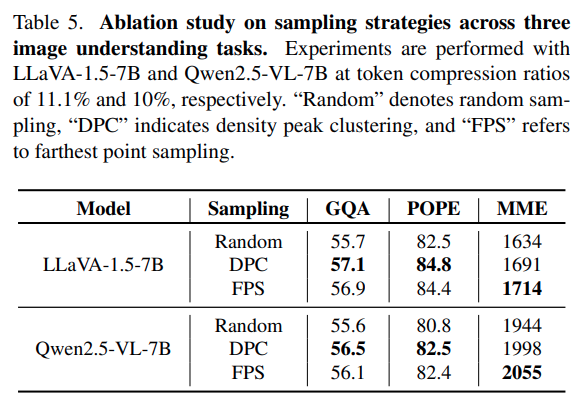
해당 Table은 LLaVA나 Qwen 의 백본에서 앞서 언급한 DPC, FPS 및 Random 성능을 보여주는 것으로 FPS 방식으로 가장 먼 곳의 basis token을 고르는 것이 가장 성능이 좋았음을 보여줍니다. 논문을 써야하는 입장에서 해당 Table이 다른 방법론들과의 성능 비교를 하지는 않지만, 본인이 SOTA인 dataset들만 리포팅한 것을 알 수 있습니다. 1컬럼으로 Table을 넣어야하는 위치에서 적절한 ablation 실험은 저였어도 SOTA인 데이터셋을 넣을 것 같네요.

기존 방법론들과 저자의 방법론의 selected 된 token을 시각화한 장면입니다.
Conclusion
기존 방법론들이 CLS 토큰이나 attention weight을 사용하는 반면, 그럼으로써 생기는 문제점 2가지를 언급하며 attention-free 기반의 방법론을 제안한게 인상적입니다. 저도 현재 attention score를 사용하지 않고 pruning을 하는 방법을 생각중인데, 같은 계열의 방법론이 될 것 같고, 저자의 방법론도 간단하고 성능이 낮지 않아 좋은 학회에 붙었네요. 아직 appendix가 나오지 않아서 추가적인 정보를 얻지는 못해 아쉽습니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
이런 LLM계열의 token pruning은 vision encoder 쪽 pruning과는 목적이 조금 다른지 궁금합니다.
아니면 결국 비슷하게 효율성을 위한 접근인데 메모리나 latency 같은 효율 지표를 상대적으로 덜 리포팅하는 편인지도 궁금합니다. 해당 분야에 대해서 잘 모르기도 하고 리뷰에 리포팅된 성능에 관련 지표가 없어서 궁금해서 질문드립니다. 감사합니다.
안녕하세요 우현님 좋은답글 감사합니다.
vision encoder 쪽의 pruning을 말하는거라면 vision encoder에 따라 다르겠지만.. 웬만하면 모델 학습이 추가적으로 필요해서 training free 계열이랑은 좀 다른 것 같습니다. 아니면 질문의 의도가 혹시 vision encoder를 타고 나온 후 pruning하는 방법론을 얘기한거라면 위의 논문도 같은 계열에서 pruning을 할 수 있습니다.
그리고 latency관련 지표를 보통 하나씩 리포팅하긴하는데, main contribution으로 가져가냐 아니냐의 차이로 논문 어디에 구성할지는 저자 마음인 것 같습니다. 저자의 figure 1도 결국 latency와 관련된 내용이고 appendix에도 추가적인 내용이 존재합니다.
감사합니다.