안녕하세요, 이번에 리뷰할 논문은 Google Deepmind에서 2023년에 발표한 NIPS spotlight 논문입니다. 현재 저희 팀 과제에 투입되기 위한 팔로우업 중에 읽게 된 논문으로, detection 데이터셋이 제한적인 상황에서 어떻게 Web scale의 데이터 양으로 스케일을 키워 detection task 모델을 사전 학습 시킬 지에 중점을 두고 있습니다.
Introduction
Open Vocabulary Object Detection(OVOD)는 CLIP 같은 사전학습된 VLM의 발전과 함께 빠르게 발전했지만, 사용한 가능한 detection dataset의 양이 (CLIP에 사용된 방대양 한의 Web scale 이미지-텍스트 쌍 데이터에 비해) 상대적으로 적다는 문제가 있었습니다. Detection 데이터셋 양이 적다보니, detection task에 맞게 finetuning할 경우 모델이 해당 데이터셋의 정답 클래스에만 과적합되어 기존 CLIP이 가지고 있던 ‘분포 변화에 강인한 표현’을 잃게 됩니다. 그래서 open vocabulary object detector를 통해 (박스)라벨링이 되지 않은 이미지에 대해 박스와 클래스를 예측한 뒤(pseudo-labeling), 이 예측값을 weak supervision으로 사용하는 “Self-training” 연구가 진행되었습니다.
Web scale의 이미지-텍스트 쌍으로 pseudo-labeling을 진행했을 때 weak supervision으로 학습시킬 수 있는 데이터셋의 양을 큰 폭으로 키울 수 있을 것으로 기대되었습니다. 하지만 기존 self-training 방법론 중 웹 이미지-텍스트 쌍의 텍스트 캡션의 명사만 골라서 pseudo-labeling에 사용하거나 detector가 예측한 박스 중 가장 큰 박스를 텍스트 캡션과 연결시키는 heuristic한 방법은 고품질의 pseudo annotation을 만들어내기 어려웠고, 텍스트 캡션과 예측된 박스를 정확하게 정렬하기 위한 모델 아키텍처나 grounding loss를 복잡하게 설계하는 방법은 데이터셋 크기를 기하급수적으로 늘리는 데 실패했습니다.
저자들은 detection task에 대한 weak supervision을 최적화하기 위한 세 가지 핵심 요소를 라벨 공간 선택, pseudo-annotation 필터링, 그리고 학습 효율성을 정의했습니다. 기존 self training 방법론들과 달리, 최소한의 전처리/필터링 사용 및 이미지-텍스트 쌍의 텍스트 캡션의 N-grams를 pseudo-labeling용 detector(annotator)의 입력으로 넣는 사전학습 방법론인 OWL-ST와, 주어진 연산량 내에서 훈련 때 사용하는 학습 데이터량을 늘리기 위해 학습 효율성을 최적화시킨 모델 아키텍처 OWLv2를 제안합니다. (참고로 OWL-ST, OWLv2 네이밍을 붙인 이유는 base model로 OWL-ViT라는 Open World Localization 모델을 사용했기 때문입니다.)
OWL-ST를 적용한 OWLv2 모델은 pseudo annotation 데이터를 2.3B로 스케일업 했을 때 제로샷 성능(eval on LVIS_rare)이 이전 SOTA 대비 36% 상승한 AP를 기록했습니다. 또한 In the wilds 라는 Out of distribution 데이터셋으로 평가했을 때 fine-tuned 성능과 zero shot 성능 간의 trade-off를 확인했으며, 스케일링 실험을 통해 무한하게 존재하는 웹 이미지-텍스트 쌍(Weak supervision)을 활용하는 자기 지도 학습이 향후 OVOD를 더 발전시킬 잠재력을 가지고 있다고 분석했습니다.
Method
OWL-ST는 아래 세 가지 단계로 진행됩니다.
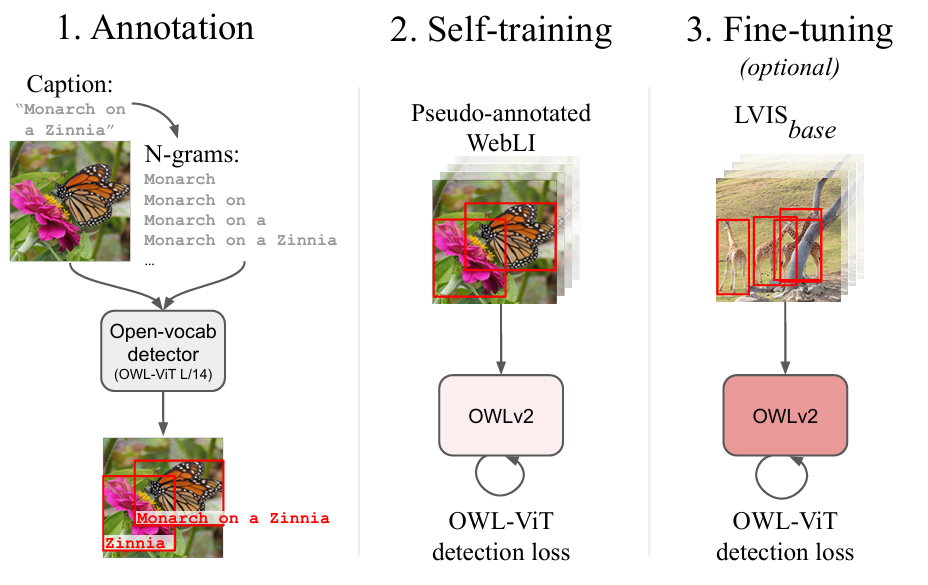
- Open Vocabulary Detector(OWL-ViT)를 사용해서 Web scale image-text pairs의 바운딩 박스를 예측하고 텍스트 캡션과 align해서 pseudo annotation을 진행합니다.
- 위 annotation을 가지고 새 detector를 self-train 시킵니다.
- (Option) human annotated dataset으로 fine-tuning 시킵니다.
또한 저자들은 human annotation이 거의 없는 상황에서도 강하고 scalable한 open vocab 성능을 달성할 수 있도록, 본 self training의 세 가지 핵심 요소인 라벨 공간, pseudo annotation 필터링, 학습 효율성을 최적화하고자 했습니다.
Generating Web-Scale Open-Vocabulary Object Annotations
Pseudo labeling을 위한 source dataset으로는 WebLI가 사용되었습니다. WebLI 데이터셋은 10B 개의 이미지와 대체 텍스트(alt-text) 쌍으로 구성되었습니다. Annotator로는 CLIP-L/14기반 OWL-ViT가 사용됩니다. 이미지가 주어지면, OWL-ViT는 class-agnostic하게 박스를 예측한 뒤, text query 목록을 주면 각 박스의 객체들과 각각의 단어의 유사도를 비교해서 박스와 텍스트를 매칭하게 됩니다. 여기서 이 text query 목록을 어떻게 입력할 것이냐 == 라벨 공간을 어떻게 할당할 것인지에 대해 두 가지 방법이 제시되었습니다.
- Human-curated label space
현존하는 4개의 detection 데이터셋이 가지고 있는 모든 클래스 이름을 모은 뒤 중복 제거 등의 작업을 거쳐 2520개의 common한 카테고리를 가진 라벨 공간을 만들었습니다. 결국 이 라벨 공간이 텍스트 쿼리로서 annotator에 입력되면, annotator는 각 박스마다 2520개의 카테고리 중 유사도 점수가 가장 높은 클래스를 라벨링합니다. - Machine-generated label space
기존 weak supervision 연구에서 사용한 방법은 텍스트 캡션에서 명사 또는 핵심 개념만 파싱해서 사용하는 것인데, 쿼리의 다양성을 줄여 편향을 일으킬 수 있다는 문제점이 있었습니다. 그러한 편향을 최소화하기 위해 저자들은 텍스트 캡션의 N-grams를 10-grams까지 추출했습니다. 예를 들어, 텍스트 캡션이 “This is a sentence”였다면 1-grams는 this,is,a,sentence, 2-grams는 this is, is a, a sentence, … 이며 그렇게 10-grams까지 추출하고 추출된 모든 item을 annotator에 입력할 텍스트 쿼리 목록으로 사용합니다. 이후 라벨링 작업은 human-curated label space와 동일하게 진행됩니다.

각 라벨 공간을 적용했을 때에 대한 비교 실험은 Experiment 파트에서 설명드리겠습니다.
Self-training at Scale
Pseudo annotation을 생성한 뒤에는 self training을 진행합니다. 전반적인 학습 과정 자체는 베이스 모델은 OWL-ViT와 유사하게 진행됩니다. 같은 loss를 사용하고, contrastive learning의 효과를 극대화하기 위해 다른 이미지 샘플의 텍스트 쿼리를 랜덤하게 가져와서 “pseudo-negatives”로 사용합니다. annotator가 박스와 텍스트 쿼리를 매칭할 때 기존의 N-grams에 pseudo-negative를 추가해 오답과의 차이를 명확하게 학습하는 셈입니다.
Classification 같은 image-level task에서 1B 이상의 이미지 샘플로 사전학습했을 때 하위 테스크의 성능이 향상된다는 점에 착안해서, 저자들은 비슷한 scaling law를 detection self-training에 적용하고자 비슷한 학습 연산량 내에서 모델이 보는 이미지 수를 늘리기 위한 학습 효율화 방안을 탐구했습니다.
Mosaics

고정된 입력 해상도 내에서 모델이 보는 이미지 수를 늘리기 위해 먼저 원본 이미지들을 모아 ‘모자이크’처럼 하나의 샘플로 재구성했습니다. n x n grid의 각 칸에 각기 다른 이미지들을 넣고 빈 공간은 0으로 padding시킵니다. Web 상 이미지들은 이미지 중간 즈음에 객체가 큼지막하게 위치한 경우가 많아, 작은 객체가 이미지 내 여기 저기에 흩어져 있는 일반 detection dataset보다 해상도와 복잡도가 낮은데 모자이크화를 통해 평균적인 객체 크기를 줄이고 작은 객체 검출 성능을 향상시키도록 했습니다. 그리드 크기는 1×1,2×2, …, 6×6 크기의 모자이크를 동일 비율로 구성하여 학습 시 샘플 하나를 볼 때마다 평균적으로 13.2개의 원본 이미지를 보는 효과를 유도했습니다.
Token Dropping

Vision Encoder 내에서 이미지는 ‘순서 없는 토큰 시퀀스’로 표현되기 때문에 저자들은 모델 파라미터 변경 없이 쓸모 없는 토큰을 버릴 수 있다고 생각했습니다. 따라서 입력 샘플의 패치들 중 픽셀 분산이 낮은 하위 50%를 버리도록 구성했습니다. 픽셀 분산이 낮은 패치는 보통 배경 또는 모자이크 내 패딩 영역과 같이 객체 탐지에 큰 영향을 주지 않는 패치이기 때문에 버려도 상관이 없다고 하며, inference 때에는 token dropping을 수행하지 않습니다.
Instance Selection
OWL-ViT의 매커니즘에 대한 이해가 일부 필요한 파트입니다. OWL-ViT에서는 vision encoder를 통과한 output token sequence의 각각의 토큰마다 박스 및 클래스 분류 예측을 수행합니다. 만약 이미지 패치가 196개였다면, 1차적인 class-box prediction 쌍이 196개 생성되는 셈입니다. OWL-v2의 디폴트 입력 사이즈가 1008×1008이고 패치 사이즈가 14×14이기 때문에 5184개의 패치 토큰이 생성되는데, 한 샘플 내 객체 개수가 5000개를 넘어가는 경우는 드물기에 모든 패치가 클래스-박스 예측을 수행하는 것 자체가 비효율적이라고 볼 수 있습니다. 저자들은 여기서 “Objectness head”를 도입했습니다. 각 패치 토큰이 ‘객체를 담고 있을 확률’을 계산해서 그 확률이 높은 패치들만 남고 박스-클래스 예측 연산을 이어가도록 설계한 방식입니다.
Output token이 Objectness head를 거치면 objectness score가 출력되는데, 이 점수는 해당 토큰이 미래에 class head를 통과했을 때 나올 classification score를 의미합니다. 이 objectness score가 높은 순으로 또 10%의 토큰만 남기고 이 토큰들로만 박스-클래스 예측를 수행하며, 이때 실제로 class head를 통과한 실제 classification score를 objectness score에 대한 supervision으로 사용합니다. Inference 때는 역시 모든 토큰을 유지합니다.
Fine-tuning
Self training 만으로도 충분히 좋은 성능을 보여주는 것이 확인되었지만, human annotated dataset으로 fine-tuning을 진행했을 때 더 좋은 성과를 얻을 수 있다고 주장합니다. 하지만 Open Vocabulary Model을 fine tuning시키는 것은 fine-tuned 성능과 zero shot 성능 사이의 trade-off를 고려해야 합니다.
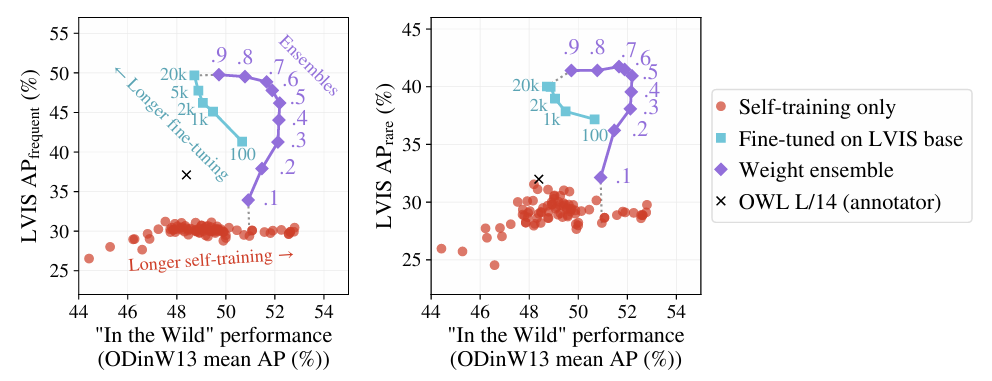
LVIS AP_rare : zero shot performance
In the Wild : OOD performance
실험 세팅은 self-train only(red dot), LVIS_base dataset으로 fine tuning했을 때(light blue line), 그리고 weight ensembling 적용 시 (purple line) 이며, 기타 LVIS AP_frequent는 LVIS의 test set 중 common class로만 구성되어 fine tuned 성능을, LVIS AP_rare는 학습 때 보지 않은 ID zero shot 성능, In the wild는 OOD zero shot 성능을 나타냅니다. Finetuned 성능인 하늘색 선을 주목해 보면, fine tuning을 더 길게 할수록 fine tuned 성능이 오르는 반면 OOD 성능은 하락한다는 것이 확인됩니다. 저자들은 이 trade-off를 fine tuning 전후의 가중치를 평균해서 적용하는 weight ensembling을 도입해서 간단하게 해결했습니다. 또 주목할 점은 zero shot 성능(LVIS_rare) 역시 fine tuned 성능처럼 fine tuning이 진행됨에 따라 상승했다는 점입니다. 저자들은 LVIS_rare의 클래스 구성이 ‘heron’,’mallard’,’puffin'(새 종류)처럼 LVIS_frequent에서의 ‘bird’, 즉 common class와 의미적, 시각적으로 연결되어 있기 때문이라고 분석했습니다. 따라서 LVIS_rare 평가를 통한 zero shot 성능은 좁은 의미의 open vocab 성능이며, OOD 평가와 달리 fine tuning이 기존의 일반화 능력을 해친다는 점을 드러내지 못한다고 합니다.
Experiments
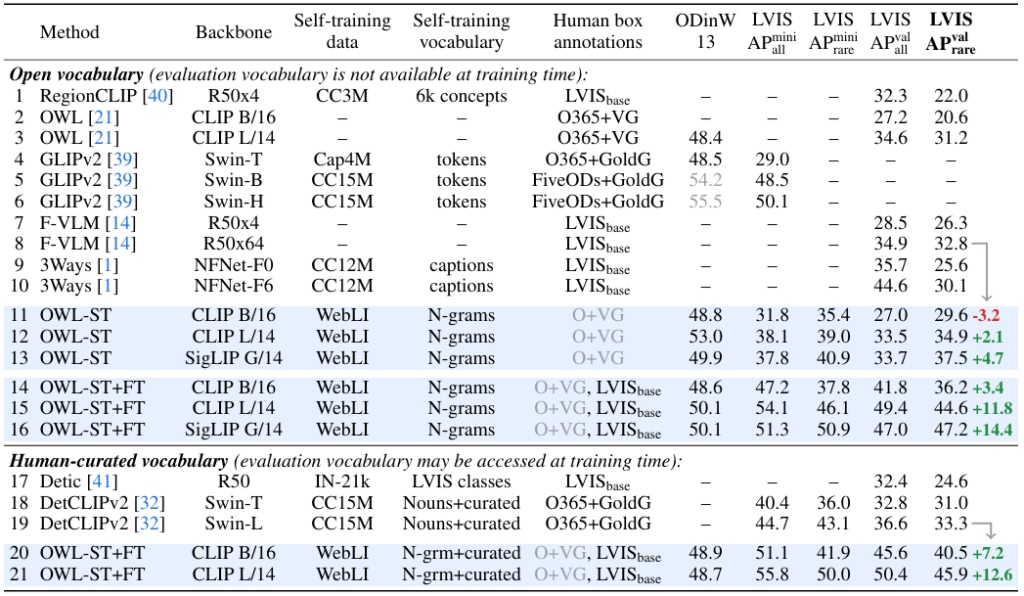
- OWL-ST : self-train only, without fine tuning
- OWL-ST+FT : with fine tuning
- LVIS AP_all : seen, fine-tuned performance
- LVIS AP_rare : zero shot performance
이전 self-training 연구와의 비교를 통해, 본 논문에서 제안한 사전학습법인 OWL-ST만 적용해도 좋은 성능을 보여주었으며, fine tuning했을 때 추가적인 성능 향상을 확인했습니다. 주목할 점은 zero shot 성능이 seen/fine tuned 성능보다 더 높았다는 점인데(ex. Exp 11 – 27.0 | 29.6), LVIS_rare처럼 흔치 않은 객체가 포함된 이미지-텍스트 쌍은 실제로 그 이미지 속 개체를 정확히 지칭하고 있을 가능성이 높은 반면 ‘man’,’car’ 같은 흔한 단어들은 실제 이미지 내용과 무관하게 텍스트에 남발되는 경우가 많다고 분석합니다.
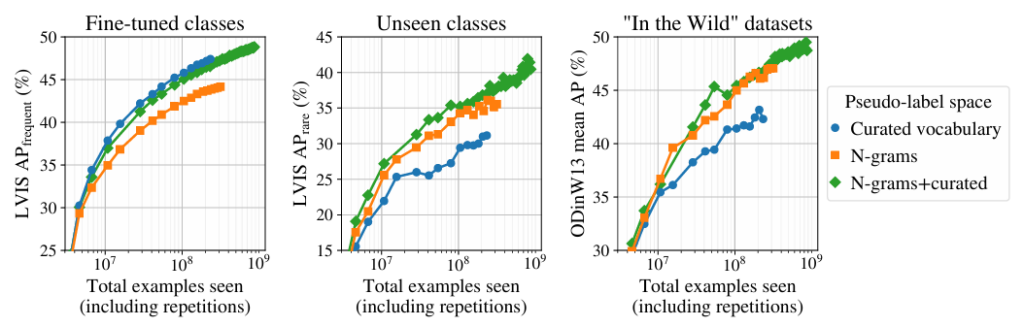
Human-curated label space와 Machine-generated label space(N-grams) 비교 실험입니다. 학습을 계속 진행함에 따라, Curated Vocab(blue)의 fine-tuned 성능은 좋아지는 반면, zero shot 성능은 훅 떨어지는 경향성을 보입니다. 반대로 N-grams(orange)는 비록 fine-tuned 성능은 상대적으로 애매한 반면 일관되게 높은 zero shot 성능을 보여주고 있어, Open Vocabulary Generalization이라는 목표에 대해선 N-grams label space를 선택하는 것이 효과적이었습니다.
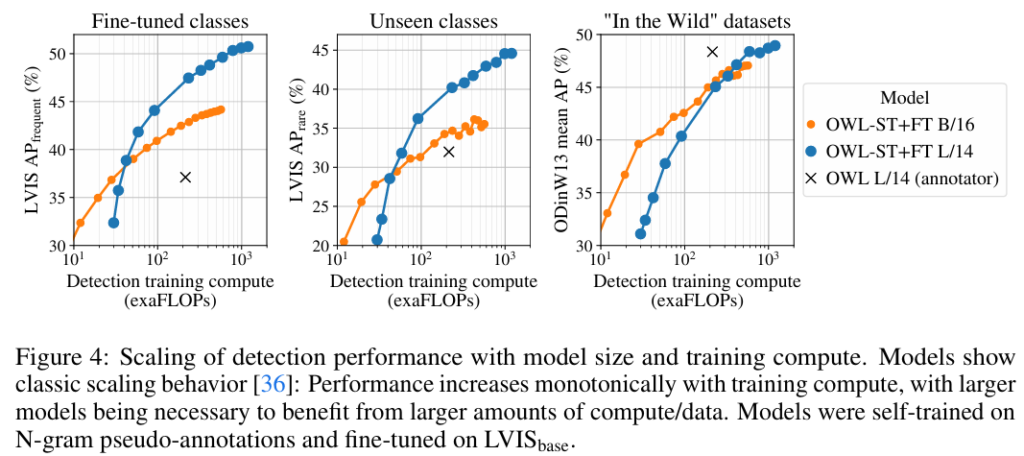
classification에서처럼, detection task에서도 scaling law가 적용된다는 것을 보여주는 실험입니다. 우선 annotator로 쓰였던 일반 OWL-ViT모델과 OWL-ST+FT를 비교했을 때 비슷한 성능을 보여주기 위해 필요한 연산량이 OWL-ST에서 훨씬 적었다는 점에서 본 self training 방식의 효율성을 입증했습니다. 또 연산량을 늘림에 따라 모델의 성능이 오르고, 더 큰 사이즈의 모델에 더 유리하게 작용된다는 점에서 Scaling law가 detection에도 적용된다는 것을 확인했습니다. 왼쪽에서 3번째 그래프인 OOD 성능표를 확인했을 때, distribution shift 때의 성능을 높이기 위해서는 큰 모델(L/14)의 성능이 작은 모델(B/16)의 성능을 앞서기 위해 필요한 연산 자원이 증가하므로,가성비를 고려했을 때 큰 모델을 짧게 학습시키는 것보다 작은 모델을 길게 학습시키는 것이 낫다는 결론에 도달했습니다.
Conclusion
OWLv2는 Web scale 이미지-텍스트 쌍을 활용한 데이터셋 스케일업으로 self-training되었으며, 사람의 직접적인 라벨링 없이도 성능을 끌어올릴 수 있음을 증명했습니다. Detection task에도 Scaling law가 적용된다는 것을 확인했지만 결국 그만큼 많은 데이터를 감당해낼 만한 연산 비용 역시 기하급수적으로 증가하기 때문에 데이터 scaling이외에 또다른 방법이 필요하다고 합니다. 또한 결과적으로 fine tuning 시 OOD 성능은 하락하는 trade-off가 여전히 존재한다는 것이 limitation입니다.
안녕하세요 재윤님 좋은 리뷰 감사합니다.
N-grams를 10-grams까지 쓰는 게 label space를 넓히는 데는 좋아 보이는데 그럼 그만큼 이상한 phrase도 꽤 많이 들어갈것 같다는 생각이 드는데 이런 noise는 데이터 스케일로 어느정도 커버된다고 보면 되는건지 아님 결국 필터링이 꽤 중요할지 궁금합니다!
안녕하세요 찬미님, 좋은 질문 감사합니다.
논문에서는 그러한 노이즈를 다루기 위해 1차적으로 “An image~”,”~.jpg” 등 노이즈가 될 만한 단어가 섞인 경우 필터링했으며, 10-grams로 이상한 phrase가 많이 생성되더라도 pseudo-labeling 과정에서 VLM이 unlabeled object에 대해 10-grams로 만든 라벨 중 가장 적절한 라벨을 할당하기 때문에 충분히 커버되었다고 본 것 같습니다.
안녕하세요 재윤님. 좋은 리뷰 감사합니다.
SigLIP2 논문을 읽는 중 OWL-V2를 사용해, annotation을 하는 방식이 사용된다는 것을 보고 OWL-V2에 대해 궁금한 점이 생긴 차에, 재윤님의 리뷰가 있어 보게 되었습니다.
읽던 중 질문이 생겨 댓글 남깁니다.
Web-scale 수준으로 데이터를 scaling 하기 위해 OWL-VIT 모델을 통해 pseudo-labeling을 수행한다는 점이 인상이 깊었고, SigLIP2 에서도 이러한 방식이 동일하게 사용되었습니다. 다만 궁금한 점은, OWL-VIT에서 생성한 잘못된 labeling에 대한 처리는 어떻게 이루어 졌는지 궁금합니다. 혹시 이 부분이 Objectness heads에서 확률이 높은 박스만 남기는 부분에서 처리가 되는 것인가요?
두번째는 간단한 질문으로, OOD와 fine-tuning간의 tradeoff가 생기는 이유가 무엇인지 간략하게 설명 부탁드립니다!!
감사합니다.
안녕하세요 희승님, 좋은 질문 감사합니다.
1. 우선 objectness heads에서 confidence가 높은 박스만 남기는 부분은 연산 효율성을 높이기 위함인데, 기존의 패치 토큰마다 박스 및 클래스 예측을 수행하는 설계는 수천 개의 패치 토큰 중 진짜로 객체가 존재하는 토큰이 몇 개 수준에 불과하다는 점에서 비효율적이기 때문에 thresholding으로 연산할 대상을 줄이기 위한 목적이었다고 보시면 될 것 같습니다. 잘못된 라벨링은 무의미한 텍스트를 1차적으로 걸러내는 과정, 다른 이미지의 캡션을 랜덤하게 가져와서 오답으로 제공하여 정답과 노이즈 간 차이를 구분하도록 학습시키는 pseudo negatives 활용 등으로 필터링하며, 애초에 웹 상의 이미지와 그에 매칭된 대체 텍스트(alt text)를 활용해서 pseudo labeling을 하기 때문에 관련 없는 annotation이 부여될 가능성은 적습니다.
2. CLIP이나 OWL-ViT같은 사전 학습 모델은 방대한 양의 데이터로 사전학습되어 일반화 능력이 좋다는 특징, 곧 OOD 환경에서도 강건하다는 장점이 있는데, 사전학습 때 사용된 데이터셋에 비해 훨씬 작은 downstream task의 데이터셋으로 fine-tuning을 하게 되면 fine tuning용 데이터셋에 fit하도록 가중치를 조정하는 과정에서 기존 사전학습된 일반화 능력이 옅어지게 됩니다. 그렇기 떄문에 fine-tuning을 하게 되면 새로 학습된 데이터셋에 대한 성능은 높아지지만 다른 OOD 데이터셋으로 평가했을 때의 성능은 떨어지는 trade-off가 발생합니다.