논문 정보
저자:
Lucas Maes*¹, Quentin Le Lidec*², Damien Scieur¹·³, Yann LeCun², Randall Balestriero⁴
1: Mila & Université de Montréal, 2: New York University, 3: Samsung SAIL, 4: Brown University
링크: https://arxiv.org/abs/2603.19312
프로젝트페이지: https://le-wm.github.io/
안녕하세요. 이번 논문 리뷰는 JEPA(Joint Embedding Predictive Architecture) 기반의 World Model인데, 기존 JEPA들이 겪던 representation collapse 문제를 아주 심플하게 해결하면서 end-to-end 학습을 안정적으로 가능하게 만든 LeWorldModel(LeWM) 방법론입니다.
사실 저는 요즘 “DP-WM latent aligned 기반 failure detection으로 reward 시그널을 만들어서 online RL학습으로 policy steering하여 작업성공률 개선하는 연구”를 구체화하려고 WM 쪽 서베이를 열심히 하고 있는데요. 그러다보니 자연스럽게 JEPA 기반 WM들을 많이 보게 되었고, 그 과정에서 DINO-WM이나 PLDM 같은 방법론들의 각각의 한계가 좀 눈에 보이기 시작하던 차에 이 논문을 발견하게 되었습니다.
특히 이 논문이 눈에 띈 이유는, 기존 end-to-end JEPA인 PLDM이 VICReg 기반으로 7개나 되는 loss term을 사용하면서도 학습이 불안정했던 반면, LeWM은 단 2개의 loss term, 1개의 hyperparameter만으로 그걸 능가하는 성능을 보였다는 점이었는데요. 게다가 15M 파라미터에 단일 GPU로 수 시간이면 학습된다니, research 진입장벽 측면에서도 꽤나 매력적이었습니다.
그리고 무엇보다 제 연구 관점에서, LeWM의 VoE(Violation-of-Expectation) 실험이 물리적 perturbation에 대해 높은 surprise를 보인다는 결과가, WM의 prediction error를 failure detection signal로 활용할 수 있는 가능성을 보여주는 것 같아서 흥미로워 리뷰하게 되었습니다.
Introduction
World Model 연구 분야 히스토리
AI 에이전트가 다양한 task와 environment에서 skill을 습득하려면, sensory input으로부터 action의 결과를 예측할 수 있는 World Model(WM)이 필수적입니다. WM은 환경의 dynamics를 학습해서, 실제 환경과 상호작용하지 않고도 imagination space에서 planning과 self-improvement를 가능하게 해주는데요. 특히 offline setting에서 고정된 데이터셋으로부터 synthetic experience를 생성하고 counterfactual action sequence를 평가하는 데 큰 가치를 지닙니다.
WM의 흐름을 크게 나눠보면, 먼저 Generative WM 계열이 있습니다. IRIS, DIAMOND, Δ-IRIS, OASIS, DreamerV4 같은 방법론들이 pixel space에서 직접 미래 observation을 생성하는 action-conditioned generative model로서, Minecraft나 Counter-Strike 같은 게임 환경에서 policy sample efficiency를 높이는 데 성공적이었죠. Genie나 HunyuanWorld처럼 아예 새로운 interactive simulator를 생성하는 방향도 있고요. 다만 이런 generative WM들은 대부분 reward signal을 포함한 데이터셋을 필요로 하고, task-specific한 성격이 강하다는 한계가 있습니다.
한편 JEPA(Joint Embedding Predictive Architecture) 기반 WM은 pixel space에서 직접 reconstruction하는 대신, compact한 latent space에서 미래 state의 embedding을 예측하는 방식인데요. LeCun이 2022년에 제안한 이래, self-supervised representation learning(I-JEPA, V-JEPA, Echo-JEPA 등)과 action-conditioned world modeling 양쪽에서 발전해왔습니다. 이 접근의 장점은 환경의 모든 측면을 모델링하려 하지 않고, 미래 state 예측에 가장 relevant한 feature만을 capture한다는 점이 있다고 합니다.
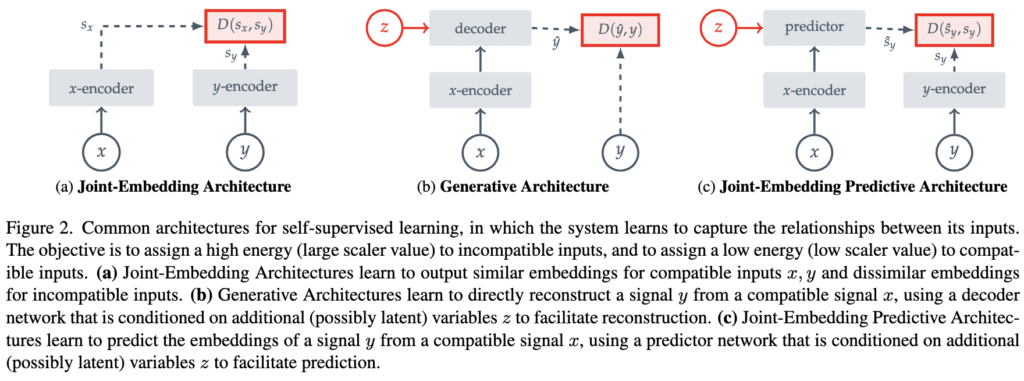
위 figure는 제가 JEPA가 뭔지 이해하려 논문을 레퍼런스를 돌아다니다가, I-JEPA(CVPR 23) 에서 가져온 figure입니다. 해당 논문은 JEPA를 image 단에서 적용한 방법론이었고 이 figure 2 가 그나마 직관적으로 그려져 있어서 기존 아키텍쳐와 JEPA 아키텍쳐의 차이를 보기 쉬운 것 같아 가져왔습니다.
JEPA의 핵심 문제: Representation Collapse
근데, JEPA의 개념적 단순함에도 불구하고, 실제 학습에서는 Representation Collapse라는 치명적인 문제가 있습니다. 모든 입력을 거의 동일한 representation으로 매핑해버리면 temporal prediction objective를 trivially 만족시킬 수 있기 때문인데요. 이걸 막기 위해 기존 방법론들은 다양한 heuristic에 의존해왔습니다:
- EMA + Stop-Gradient: I-JEPA, V-JEPA 등에서 target encoder의 EMA를 사용하고 SG를 적용하는데, 이 방식은 well-defined objective를 minimize하는 것에 해당하지 않는다는 이론적 한계가 있더라.
- Pretrained Encoder Freezing: DINO-WM은 DINOv2를 frozen encoder로 사용해서 collapse를 원천적으로 회피하지만, end-to-end 학습이 불가하고 pretrained encoder의 expressivity에 bound되더라.
- Multi-term Loss: PLDM은 VICReg이라는 ICLR 22년 방법론 기반의 7-term loss로 end-to-end 학습을 시도하지만, 6개의 hyperparameter 튜닝이 필요하고 학습이 불안정하더라.
등 각각의 방법론들마다 다 이런저런 방식이 있었습니다.
저자의 빡침포인트 및 연구 철학 제안
근데 여기서 저자들의 빡침포인트가 생기는 것 같습니다. “왜 JEPA를 end-to-end로 안정적으로 학습시키는 게 이렇게 복잡해야 하는가?”. 기존 end-to-end JEPA인 PLDM은 VICReg에서 파생된 7개의 loss term(prediction, variance, covariance, temporal smoothness, temporal variance, temporal covariance, IDM)을 사용하고, 이 중 6개의 hyperparameter를 환경마다 튜닝해야 한다고 합니다(완벽한 이해까지는 못했지만..굉장히 많은 loss term이 있는데요). 이건 O(n^6)의 search complexity를 야기합니다. 반면 DINO-WM은 안정적이라고 하지만, 124M 이미지로 사전학습된 DINOv2 encoder에 의존하며 end-to-end 학습은 못하게 됩니다.
이에 저자들은 LeWorldModel(LeWM)을 제안하게 됩니다. 핵심 철학은 다음과 같습니다:
- 단 두 개의 loss term만 사용: Next-embedding prediction loss + SIGReg(simple Gaussian regularizer)
- 튜닝할 hyperparameter는 1개뿐 (\lambda, regularization weight)
- Stop-gradient, EMA, pretrained encoder 를 아예 사용하지 않고 완전 end-to-end 학습
- 15M parameter, 단일 GPU에서 수 시간 학습 → research 진입장벽을 낮춤(..이게 엄청난 것 같습니다.)
- Provable anti-collapse guarantee → SIGReg의 Cramér-Wold theorem 기반 이론적 보장
특히 핵심 철학인 것이, collapse 방지를 위해 이것저것 heuristic을 쌓는 대신, latent embedding 분포를 isotropic Gaussian에 맞추도록 강제하는 단 하나의 regularizer만으로 모든 걸 해결하겠다는 것입니다. 이론적으로 Cramér-Wold theorem에 의해 뒷받침되기 때문에, PLDM처럼 이거 왜 되는지 잘 모르겠지만 일단 돌아가니까 쓰자 같은 느낌이 아니라 수학적으로 provable한 anti-collapse guarantee를 제공한다는 점이 인상적이었습니다.
Related Work
관련 연구들을 좀 정리해봤는데, JEPA 기반 World Model 쪽에서 collapse를 다루는 접근이 크게 세 갈래로 나뉘는 것으로 보입니다.
[ICML 2025] DINO-WM: World Models on Pre-trained Visual Features Enable Zero-shot Planning
문제 정의 : JEPA 기반 WM에서 representation collapse를 어떻게 피할 것인가?
접근 방안 : DINOv2라는 대규모 사전학습 vision encoder를 freeze하고, 그 위에 predictor만 학습. Encoder를 건드리지 않으므로 collapse가 원천적으로 발생하지 않음.
근데 단점이 좀 있는데요. 일단 end-to-end 학습이 불가하다 보니 encoder가 task-specific feature를 학습할 수 없고, DINOv2의 pretraining knowledge에 bound됩니다. 그리고 ~200× 더 많은 token으로 encoding하다 보니 planning이 느리더라고요.(LeWM 대비 ~48× 느림) 또한 proprioceptive input 등 추가 modality에 의존하기도 합니다.
[NIPS 2022] PLDM: Predictive Latent Dynamics Models (Joint Embedding Predictive Architectures Focus on Slow Features)
문제 정의 : End-to-end로 JEPA 기반 world model을 학습할 수 있을까?
접근 방안 : VICReg 기반의 variance-invariance-covariance regularization에 temporal regularization term들을 추가하여 end-to-end 학습. 총 7개의 loss term 사용.
\mathcal{L}_{\text{PLDM}} = \mathcal{L}_{\text{pred}} + \alpha\mathcal{L}_{\text{var}} + \beta\mathcal{L}_{\text{cov}} + \gamma\mathcal{L}_{\text{time-sim}} + \zeta\mathcal{L}_{\text{time-var}} + \nu\mathcal{L}_{\text{time-cov}} + \mu\mathcal{L}_{\text{IDM}}End-to-end 학습은 가능하지만, 6개의 hyperparameter를 튜닝해야 하고(O(n^6) search complexity) 학습이 불안정한 게 꽤 치명적입니다. 나중에 밑에서 실험에서 잠깐 나오지만 PLDM의 Training curve를 보면 여러 loss component들이 noisy하고 non-monotonic한 behavior를 보이는데, competing gradients 문제가 심한 것 같습니다. 그리고 collapse에 대한 formal guarantee도 없고요.
[arxiv 2025, Google DM] DreamerV4 / [ICLR 2024 Spotlight] TD-MPC2
문제 정의 : Scalable world model 기반 RL agent
이쪽은 task-specific하게 reward signal과 함께 world model을 학습하는 계열인데, Dreamer는 image reconstruction 기반, TD-MPC는 state-based + reward reconstruction 기반입니다. LeWM 관점에서 보면 task-agnostic한 generic world model 학습에는 부적합한 셈이죠.
방법론 비교 정리
| 특성 | PLDM | DINO-WM | Dreamer | TD-MPC | LeWM |
|---|---|---|---|---|---|
| End-to-End | ✅ | ❌ (Frozen) | ✅ | ✅ | ✅ |
| Task Agnostic | ✅ | ✅ | ❌ | ❌ | ✅ |
| Pixel Based | ✅ | ✅ | ✅ | ❌ (State) | ✅ |
| Reward Free | ✅ | ✅ | ❌ | ❌ | ✅ |
| Reconstruction Free | ✅ | ✅ | ❌ | ❌ | ✅ |
| Hyperparameters | 6개 | – | – | – | 1개 |
| Anti-collapse Guarantee | ❌ | ✅ (trivial) | – | – | ✅ (provable) |
이건 gpt랑 같이 좀 보기 쉽게 따로 정리를 해본건데, LeWM이 기존 방법론들의 장점을 거의 다 가져가면서 단점은 최소화한 위치에 있는 게 보이는데요. 특히 PLDM의 end-to-end 학습 능력 + DINO-WM의 안정성을 동시에 갖추면서, 둘 다 가지지 못한 provable anti-collapse guarantee까지 제공한다는 점이 인상적입니다.
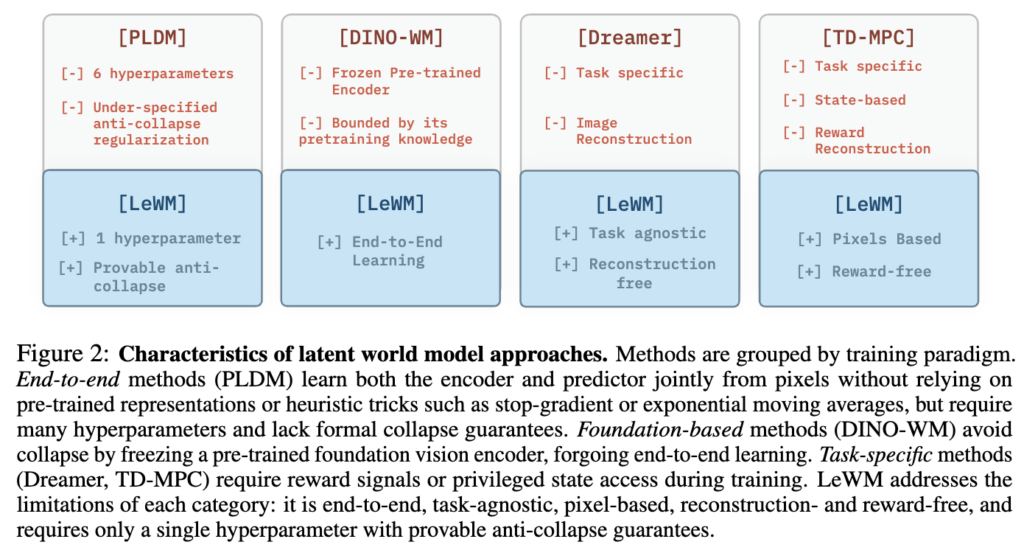
위는 논문에서 가져온 figure입니다.
Methods
Model Architecture
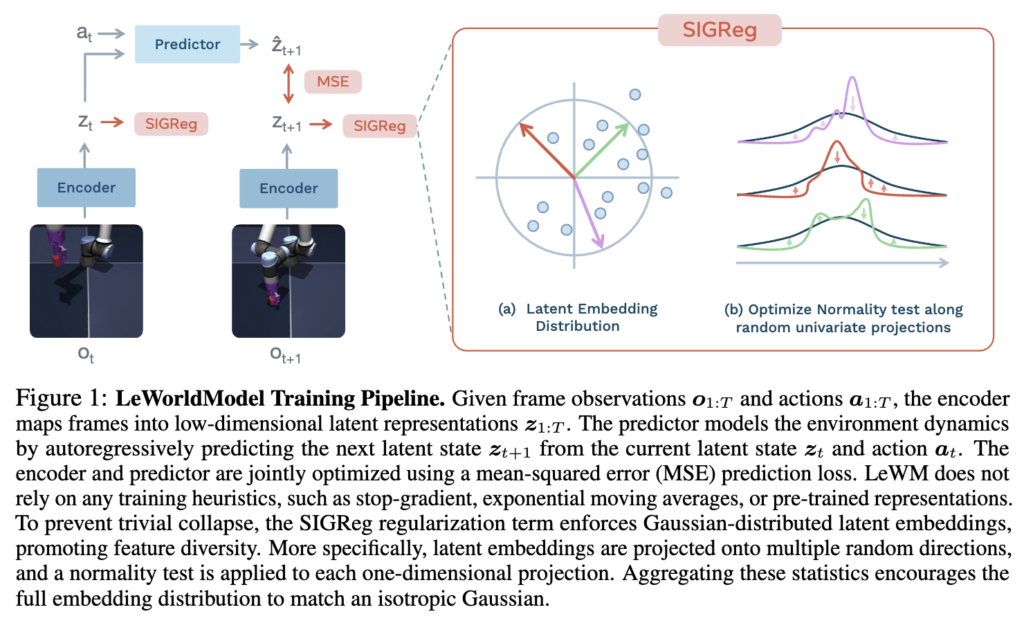
LeWM은 두 개의 핵심 구성요소로 이루어져 있습니다.
1. Encoder:
- ViT-Tiny(~5M parameters, patch size 14, 12 layers, 3 attention heads, hidden dim 192) 기반
- Frame observation o_t를 저차원 latent representation z_t로 매핑
- 마지막 layer의 [CLS] token embedding → 1-layer MLP + Batch Normalization으로 projection
여기서 BN을 사용하는 이유가 좀 재미있는데, ViT 마지막 layer의 LayerNorm이 SIGReg의 anti-collapse objective 최적화를 방해하기 때문이라고 합니다. 이런 디테일이 실제로 학습 안정성에 영향을 크게 주는 것 같습니다.
2. Predictor:
- Transformer(6 layers, 16 attention heads, 10% dropout, ~10M parameters) 기반
- 현재 latent embedding z_t와 action a_t로부터 다음 frame의 latent embedding \hat{z}_{t+1}을 예측
Action은 Adaptive Layer Normalization (AdaLN) 으로 각 layer에 주입되는데, 여기서도 디테일이 있습니다. AdaLN parameter를 zero-init하여 action conditioning이 학습 초반에는 영향을 거의 주지 않다가 점진적으로 영향을 키우는 방식으로 설계했다고 합니다. Causal masking으로 autoregressive 예측을 수행하구요.
이게 끝입니다… 얘네들이 핵심적으로 진짜 가벼운 프레임워크라고 느끼는 게 총 파라미터가 ~15M 정도 라서 단일 GPU에서 몇 시간 안에 학습 가능하게 설계됐다는 게 진짜 놀랍습니다..
Training Objective
LeWM의 이 loss가 이 논문의 핵심인데요. 정말 깔끔합니다. 단 2개의 loss term의 합입니다.
\mathcal{L}_{\text{LeWM}} \triangleq \mathcal{L}_{\text{pred}} + \lambda \cdot \text{SIGReg}(Z)1. Prediction Loss (\mathcal{L}_{\text{pred}}):

예측된 다음 step embedding과 실제 다음 step embedding 간의 MSE입니다. 이걸 통해 encoder가 predictor에게 유용한 representation을 학습하도록 유도하는 거죠.
근데 이 loss만 쓰면 당연히 collapse가 발생합니다. 모든 입력을 상수로 매핑해버리면 prediction loss가 0이 되니까요. 그래서 두 번째 loss가 필요한 것입니다.
2. SIGReg (Sketched-Isotropic-Gaussian Regularizer):
이것이 LeWM의 핵심 contribution이자, collapse를 방지하는 핵심입니다. 아이디어 자체는 꽤 이론적으로 여러가지가 뒤섞여 나오게 되었는데요. 핵심은 고차원에서 직접 normality test를 하는 건 어렵기 때문에 Cramér-Wold theorem라는 개념을 활용하였다고 합니다.
“Cramér-Wold theorem: 모든 1D marginal이 일치하면, 전체 joint distribution도 일치한다.” 라는 건데요.
구체적으로 다음과 같이 흘러간다고 합니다.
- Latent embedding Z를 M개의 random unit-norm direction u^{(m)} \in \mathbb{S}^{d-1}에 projection
- 각 1D projection h^{(m)} = Zu^{(m)}에 대해 Epps-Pulley test statistic T(\cdot) 적용
- 이를 평균해서 SIGReg loss 계산
뭐 이래저래 용어가 처음보는 게 많긴 했는데 좀 정리해서 말하면, 고차원 분포 매칭 문제를 여러 개의 1D normality test 문제로 환원해버리는 건데, 이게 이론적으로 Cramér-Wold 이란 거에 의해 보장되니까 provable anti-collapse를 제공한다는 것이었습니다. PLDM의 VICReg처럼 “variance 키우고 covariance 줄이고 temporal smoothness 유지하고…” 이렇게 여러 방향에서 regularize하는 것보다, “그냥 isotropic Gaussian이 되게 해”라고 걍 조건 하나로 collapse 막고 수학적으로 안정되게 표현하게 만들 수 있다는 증명된 이론이 있더라~ 이게 훨씬 깔끔하고 강력하게 만들 수 있더라~ 가 핵심인 것 같습니다.
기타 implemental 포인트들:
- M = 1024 projections, \lambda = 0.1이 default인데, M은 성능에 거의 영향 없음
- 따라서 실질적으로 튜닝할 hyperparameter는 \lambda 하나뿐
- \lambda \in [0.01, 0.2] 범위에서 80% 이상의 success rate 유지 → bisection search로 O(\log n) 튜닝 가능
- Stop-gradient, EMA 같은 heuristic 이 들어가지 않음.
PLDM이 O(n^6)으로 hyperparameter search 해야 하는 거 대비 O(\log n)이면… 학습 시 optimization이 차원이 다른 효율성이긴 할 것 같습니다.
학습 Pseudo-code

이건 논문에 있던 수도코드 알고리즘인데 보면 코드로 너무나도 쉽게 구현될 수 있다는 점을 어필하는 것 같습니다.
Latent Planning
추론 시에는 학습된 world model의 latent space에서 trajectory optimization을 수행합니다.

- 초기 observation o_1과 goal o_g를 encoder로 embedding → z_1, z_g
- Candidate action sequence를 random 초기화
- Predictor가 autoregressive하게 미래 latent state rollout: \hat{z}_{t+1} = \text{pred}_\phi(\hat{z}_t, a_t)
- Terminal goal-matching cost 최소화:
C(\hat{z}_H) = \|\hat{z}_H - z_g\|_2^2 - Cross-Entropy Method (CEM) 으로 action sequence 최적화(300 candidates, 30 optimization steps, top-30 elites)
- Model Predictive Control (MPC) 전략: horizon 5의 action plan을 실행 후 replan
Planning 속도가 DINO-WM 대비 최대 48× faster(0.98s vs 47s)인데, 이건 ~200× fewer tokens으로 encoding하기 때문입니다. 저희 로보틱스 도메인에서도 planning 속도가 충분히 나온다면 적용가능할 것 같습니다. (개인적으로는 현재 영규형이랑 같이 진행하고 있는 연구의 프레임워크 내에서 실시간 failure filtering을 하는 기반으로 쓸 수도 있지 않을까.. 싶습니다.)
Experiments
실험에선 LeWM을 planning performance, training stability, physical understanding 이렇게 크게 세 축으로 평가합니다. 실험 환경은 2D/3D 포함 아래의 총 4가지를 사용했고요.

1. Planning Performance
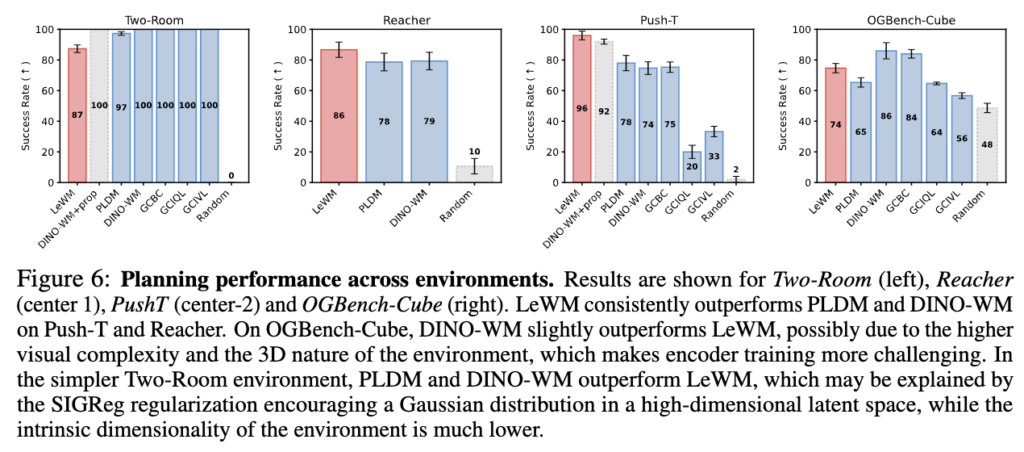
- TwoRoom: LeWM 87% vs PLDM/DINO-WM 100% → 가장 단순한 환경에서 오히려 약함(..?)
- Reacher: LeWM 86% vs PLDM 78% vs DINO-WM 79% → LeWM이 최고 성능
- Push-T: LeWM 96% vs PLDM 78% vs DINO-WM 74% → LeWM이 PLDM을 18% 능가하고, DINO-WM+proprioception까지 넘어섬
- OGBench-Cube: LeWM 74% vs DINO-WM 86% → 3D 환경에서는 DINO-WM이 우세
정리 해봤는데, TwoRoom에서 약한 이유가 좀 흥미로운데요. 데이터의 낮은 diversity와 낮은 intrinsic dimensionality 때문에, 고차원 latent space에서 isotropic Gaussian prior를 맞추기 어려워 less structured representation이 형성될 수 있다고 합니다. 즉 SIGReg가 “모든 걸 Isotropic Gaussian으로 만드셈!”이라고 강제하는 것 같은데, 환경 자체의 complexity가 너무 낮으면 오히려 과도한 regularization이 되는 셈이죠. 이건 살짝 아쉬운 한계점인 것 같습니다.
OGBench-Cube에서도 DINO-WM에 밀리는데, 이건 아마 3D 환경의 visual complexity가 높다 보니 scratch encoder가 DINOv2의 124M 이미지 pretraining 지식을 이기기 어려운 것으로 보입니다
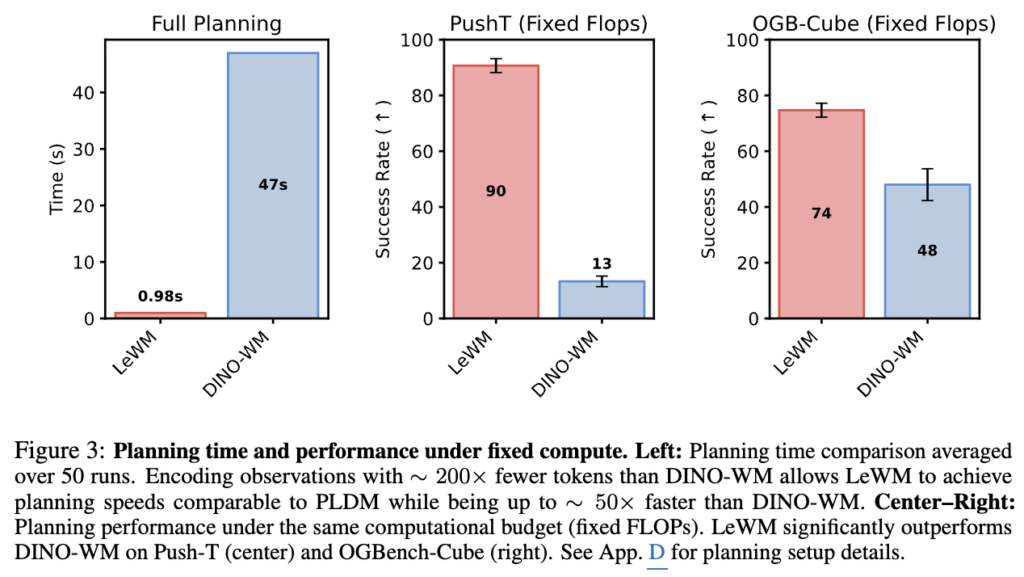
다만 위 figure 3은 저자들이 논문 Introduction 쪽에 넣어버린 figure인데,, 왜 위에 넣었나 처음엔 몰랐다가 full planning을 하면 LeWM은 latency time이 1초도 안되게 빠른 모습에 비해, DINO-WM은 48초인데요.. fixed FLOPs로 비교하면 Push-T는 LeWM 90% vs DINO-WM 13%, OGB-Cube에서는 LeWM 74% vs DINO-WM 48%로 같은 computing 파워면 LeWM이 압도적이긴 하다는 점을 어필하고 싶었던 것 같습니다. 즉 성능 좋은데 쓰기 쉽고 가볍고 빠르다가 핵심인 것 같습니다.
3. Training Stability
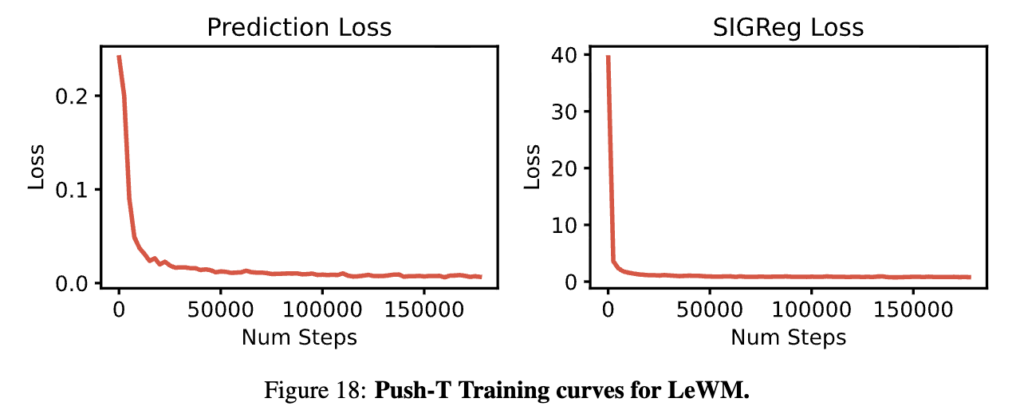
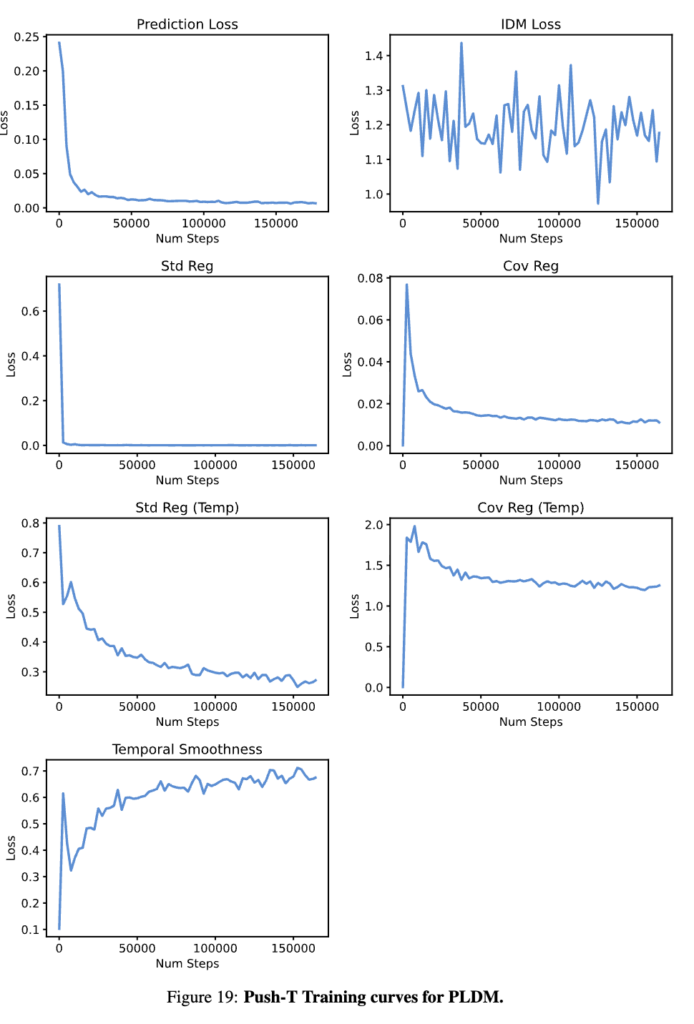
Training curve를 비교해보면 차이가 꽤 극명합니다. LeWM은 Prediction loss가 smooth하게 monotonic 감소하고, SIGReg loss는 초반에 급격히 떨어진 후 plateau되면서 매우 안정적인 경향을 보입니다. 반면 PLDM은 7개 loss term이 noisy하고 non-monotonic을 보여서 competing gradients 문제가 심각한 경향을 보입니다. Training variance도 LeWM 96.0 ± 2.83 vs PLDM 78.0 ± 5.0으로 LeWM이 높은 성능과 낮은 variance를 보입니다.
4. Ablation Studies
여기서 여러 가지 디자인 초이스에 대한 ablation을 보여주는데요.
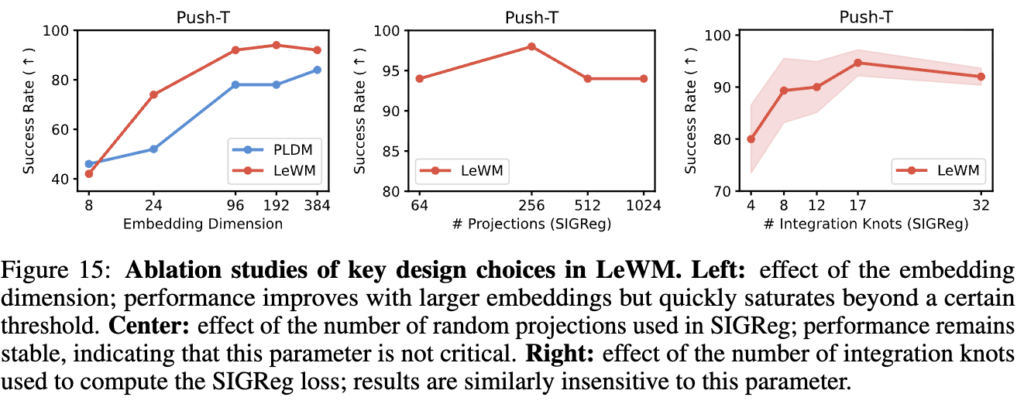
Embedding Dimension: dim이 올라갈 수록 안정적으로 success rate이 올라가는 경향은 기존 방법론들이랑 크게 다르지 않긴한데, 더 급격하게 성능이 올라가는 경향이 생기는 것 같습니다. 근데 너무 차원이 커지면 saturation되는 경향도 있네요. 오히려 가볍게 모델링하는 것이 좋은 것 같습니다.
SIGReg Projections 수 (M): 64에서 1024까지 변화시켜도 성능이 거의 동일합니다. 즉 M은 튜닝할 필요가 없더라.
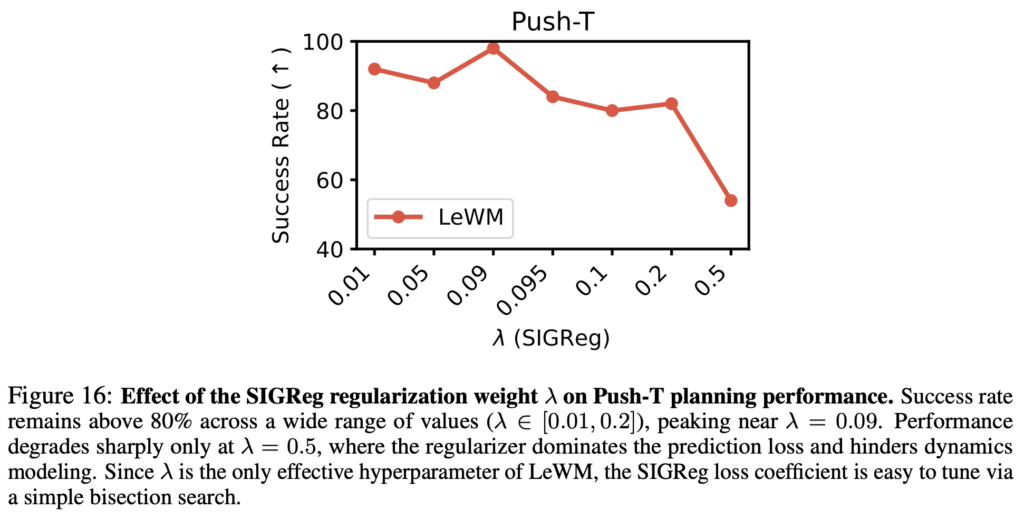
SIGReg Weight (\lambda): [0.01, 0.2] 범위에서 80%+ 유지하고, 0.09 근처에서 peak. \lambda = 0.5에서만 급격히 하락하는데, 이건 regularizer가 prediction loss를 압도해버려서 dynamics modeling이 안되기 때문인 것 같습니다.

Encoder Architecture: ViT vs ResNet-18 모두 competitive(ViT: 96%, ResNet-18: 94%) 한 성능을 보였는데, encoder architecture에 agnostic할 수 있다는 어필인 것 같습니다.

Reconstruction Loss 추가: 오히려 성능 하락(96% → 86%). 이건 좀 인상적인데, JEPA의 reconstruction-free 철학이 실험적으로 정당화되는 모습인 것 같습니다. Decoder를 붙이면 시각적 디테일까지 encode하느라 control에 불필요한 정보까지 latent에 담기게 되는 거 아닐까 싶네요.
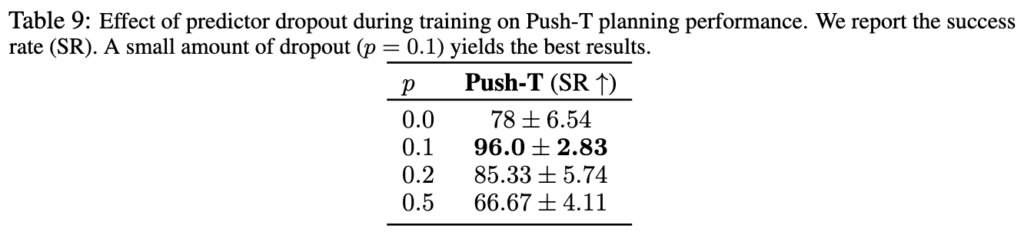
Predictor Dropout: 이건 predictor dropout은 해보니까 0.1이 최적(0.0: 78%, 0.1: 96%, 0.2: 85%, 0.5: 67%)이더라 라는 내용인데. 약간의 dropout이 predictor regularization에 꽤 효과적이네요.
5. Physical Understanding
이 파트가 아무래도 Push-T 기반으로 실험하다보니 제 연구랑 좀 연결지을 수 있지 않을까 생각하게 됐는데요.
Probing Physical Quantities
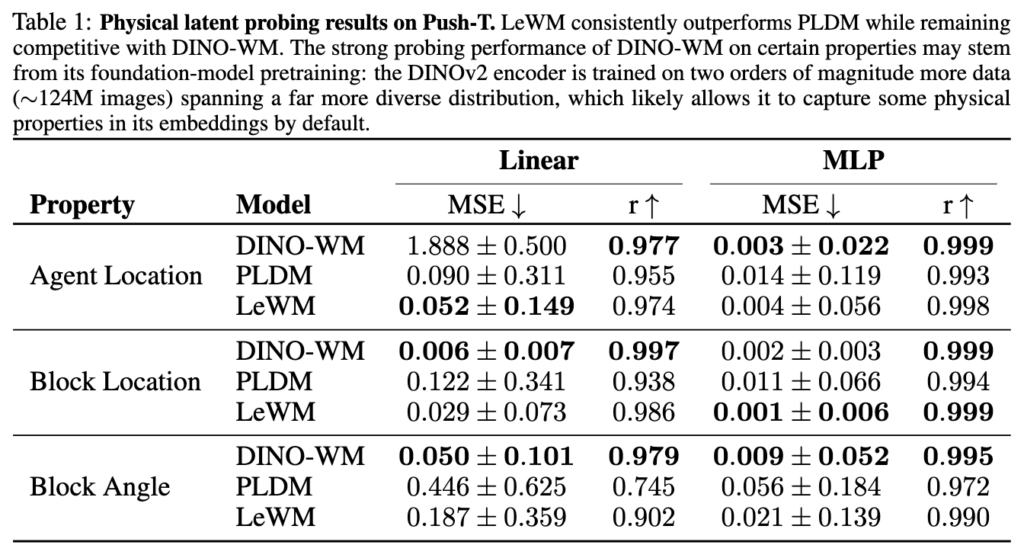
위 테이블은 Latent embedding으로부터 물리적 quantity를 얼마나 잘 복원할 수 있는지 linear/MLP probe로 평가하는 실험입니다. Push-T에서 MLP Probe correlation 결과 LeWM이 PLDM을 consistently 능가하고, DINOv2(124M 이미지로 pretrained)와 비비는 수준입니다. Raw pixels로부터 end-to-end 학습만으로 이 수준의 physical grounding을 달성했다는 게 꽤나 인상적인 결과라고 볼 수 있겠습니다.
Violation-of-Expectation (VoE)
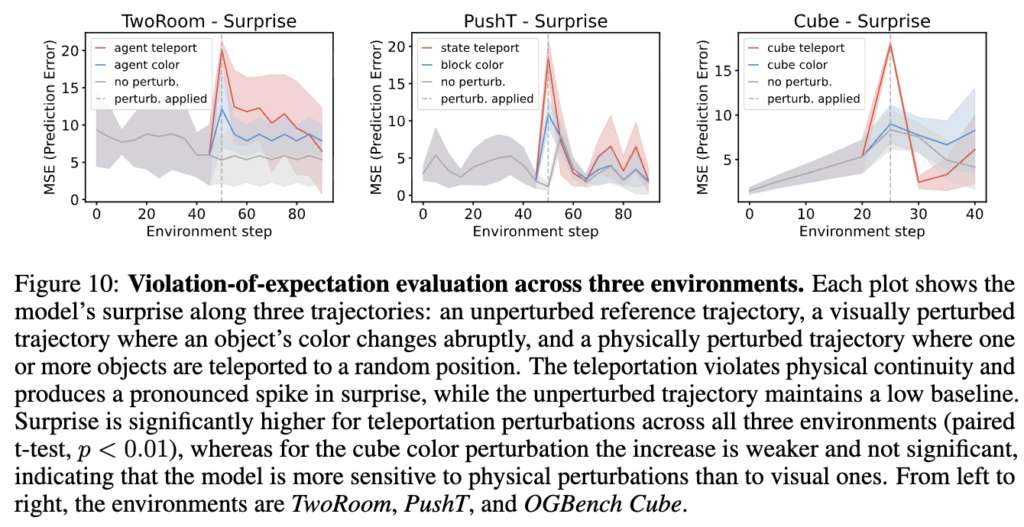
이 실험은 사실 제 연구 관점에서 써먹을 수 있는 거 아닌가 싶어서 좀 인상깊었습니다. 물리적으로 불가능한 event(object teleportation)가 발생했을 때 모델이 얼마나 높은 surprise(prediction error)를 보이는지 평가하는 실험인데요.
그 결과 Physical perturbation (teleportation) 측면에서는 세 환경 모두에서 유의미하게 높은 surprise spike(paired t-test, p < 0.01) 가 보였고, Visual perturbation (color change) 측면에서는 상대적으로 약한 반응, 유의하지 않은 결과가 나왔습니다.
즉, LeWM은 시각적 변화보다 물리적 변화에 더 민감하게 반응한다는 건데, 이게 의미하는 바가 큰 것 같습니다. Latent space가 superficial한 visual feature가 아니라 underlying physics를 capture하고 있다는 것이니까요. 그리고 이건 제가 구상하고 있는 WM의 prediction error를 failure detection signal로 활용하는 접근에서 이 VoE 성능을 나중에 저도 써먹어서 실험적으로 보여줄 수 있는 증거가 될 수도 있겠네요.
참고로 DINO-WM은 OGBench-Cube에서 physical perturbation에 대한 surprise가 유의하지 않았다고 합니다. 반면 LeWM은 세 환경 모두에서 유의한 결과를 보였으니, end-to-end 학습이 physical understanding 측면에서는 오히려 장점이 될 수 있는 건가 라는 생각이 듭니다.
Temporal Latent Path Straightening
이건 저자들의 finding인데요. 학습 과정에서 latent trajectory가 점차 선형적인 경로를 따르는 현상이 “어떤 explicit regularization도 없이 자발적으로 나타났다”고 합니다. 이게 뭔 말이냐면 시간축을 따라 관찰되는 연속 상태들의 변화가 잠재공간에서 linear한 방향으로 이동하도록 표현이 정리된다는 뜻입니다. 즉, 복잡한 실제 움직임이 latent에서는 덜 굽은(더 직선적인) 궤적으로 표현된다는 것인데, 저자들은 이 현상이 아무런 시간적 규제항(temporal smoothness loss) 없이도 자연스럽게 생겼다고 언급합니다.

요 식으로 해당 현상을 측정했다고 하는데요.
재미있는 건, PLDM은 \mathcal{L}_{\text{time-sim}}이라는 explicit temporal smoothness loss를 사용함에도 불구하고 LeWM보다 temporal straightness가 낮다는 점입니다. 저자들의 가설은, LeWM에서의 SIGReg가 각 time step에서 독립적으로 적용되지만 temporal 차원에는 제약을 주지 않기 때문에, encoder가 일종의 temporal collapse 방향으로 successive embedding이 점점 linear path를 따르게 수렴한다는 것인데요. 이게 성능에 해롭지 않고 오히려 도움이 된다는 점이 흥미롭습니다. 저는 개인적으로 embedding이 linear해진다는 표현이 뭔가 원래의 복잡한 차원을 선형적으로 표현하게 된다는 점에서 한편으로는 안 좋은 bias인 게 아닌가 싶은데,, 저자들은 이 implicit bias가 성능에 좋은 영향을 준다고 주장하네요.
Qualitative Experiment
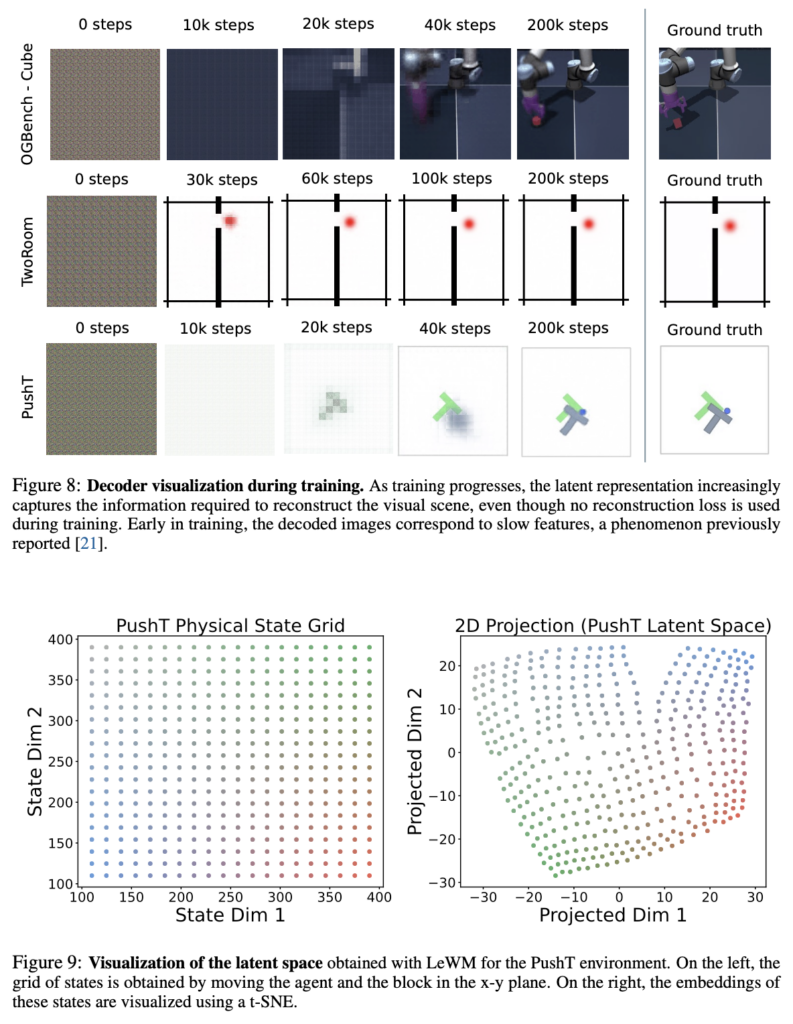
마지막으로 정성적 실험 결과인데요. Figure8 에서 LeWM은 decoder에서 reconstruciton loss를 학습 때 적용하지 않았음에도, GT와 유사한 reconstruction을 decoding할 수 있다는 것이 여기선 가장 핵심 포인트인 것 같습니다. Figure 9에서는 왼쪽은 PushT env의 spatial한 structure를 physical state grid라는 표현으로 보인건데, 이를 LeWM에서의 latent space에서 보면, 오른쪽처럼 나름의 상대적인 거리와 위치 관계를 유지하려는 경향성을 보입니다. 이게 사실 robing Physical Quantities, VoE, Temporal Latent Path Straightening 에 대한 저자들의 설명들이 이 정성적인 결과로도 이어질 수 있게 되는 거 아닌가 싶네요.
근데 개인적으로는 실험 환경이 real world로 넘어갔을 땐 또 어떤 경향성을 보이게 될지 궁금합니다. 사실 여기에 real-world 실험은 딱히 없었거든요.
Limitation
솔직히 최근 본 WM 논문 중 가장 깔끔하다는 느낌을 받은 논문입니다. 복잡한 regularization을 쌓는 것보다 이론적으로 하나의 regularizer를 아주 잘 설계하고 이걸 실험으로 증명해낸다는 것이 매우매우 fancy한 논문이네요. 논문에서의 한계로는 short-horizon planning, offline dataset 의존성, action label 필요, 3D 복잡 환경에서의 성능 한계(특히 rotational quantity 복원) 등이 있지만, 이 한계들은 추후 연구 step들에서 충분히 접근가능한 문제로 보이고, 저자들은 world model을 위한 learning paradigm을 더 가볍고 쉽고 임팩트있게 제시했다는 점에서 의의가 있는 것 같습니다.
제가 구상 중인 “DP-WM latent aligned 기반 failure detection → reward signal → offline RL policy steering” 관점에서 핵심적인 takeaway는 세 가지였는데요. 첫째, VoE 실험에서 물리적 perturbation에 대해 높은 surprise를 보인 결과가 WM prediction error를 failure detection signal로 활용할 수 있는 가능성을 직접 보여줬다는 점. 둘째, 48× faster planning 속도가 online RL loop에서 WM을 reward model로 활용할 때 bottleneck이 되지 않는다는 점. 셋째, LeWM의 short-horizon planning 한계는 오히려 WM이 failure detection/reward signal 제공에만 집중하고 action 생성은 DP에게 맡기는 complementary한 역할 분담 구조를 정당화할 수 있다는 점입니다. 추가로, 이전에 리뷰했던 FOREWARN의 DreamerV3를 LeWM으로 대체하면 end-to-end 학습과 빠른 planning 덕분에 VLM-WM-aligned-in-the-loop 구조를 만약에 사용하게 되더라도 bottleneck도 크게 줄어들 수 있겠다는 생각이 듭니다. 리뷰 마치겠습니다. 감사합니다.
최근에 읽어볼 논문 리스트에 저장 해뒀던 논문인데, 리뷰 작성하셨네요.
정성스러운 리뷰 감사합니다.
히스토리도 간단하게 Motivation, Main Contribution 이렇게 정리해주니깐 이해가 더 잘 되는거 같습니다.
대신 백그라운드는 잘 설명해주셨는데, method 쪽 설명에서는 갑자기 훅 치고 빠지는 느낌이 들어 저같은 WM알못은 이해하기 조금 어려웠던거 같습니다.
collapse를 해결하기 위한 메커니즘으로 SIGReg를 제안한거 같은데, 결국에는 feature들의 분포가 isotropic Gaussian을 따르도록 해주는 regularization 일까요? 이게 논문의 핵심인거 같은데 이 부분 이해가 좀 잘 안되네요.
왜 그렇게 해야하는지 조금만 더 설명이 해주실 수 있으면 좋을 거 같습니다.
그리고 조금 더 궁금한걸 물어보자면, Feature Space에서의 Reconstruction이 완전한 주류가 될 수 있을거라 보시나요?? Pixel의 디테일은 그 과정에서 사라질 수도 있어 장단이 존재하는 거 같습니다.
정말 나이브한 생각이지만 두 흐름을 합치려는 시도는 없을까요?? latent space에서 놓친 부분을 pixel space에서 reward 해주는 느낌..?
안녕하세요 근택님 너무 좋은 질문 감사합니다! 리뷰 작성하며 부족했던 부분을 다시 공부하였습니다.
1. SIGReg는 원래 LeJEPA에서 먼저 나왔는데, 이게 기존 SSL에서 늘 문제였던 embedding collapse를 휴리스틱한 학습 트릭 없이 좀 더 근본적으로 정면으로 해결해보자는 접근이었던 것으로 저는 이해했습니다. 보통은 stop-gradient나 teacher–student, EMA 등의 방법론들이 주로 collapse를 막기 위해 쓰였다고 하는데, SIGReg는 아예 분포 자체에 대해 수학적으로 깊게 고찰한 것 같습니다. 핵심은 학습된 feature 임베딩이 downstream에서 안정적으로 쓰이려면, 특정 방향의 gaussian 형태(anisotropic)로 몰려 있는 것보다 모든 방향으로 골고루 퍼져 있는, 즉 학습할 때 어느 방향으로 보든 gaussian 분포처럼 보이게(isotrapic) 임베딩을 학습해 더 낫다는 가정을 기반으로 학습하면서 임베딩을 그 형태로 계속 제약을 주려는 게 핵심입니다.
그걸 이제 Cramér–Wold theorem 라는 수학적 이론을 바탕으로 고차원 분포를 그대로 보지 않고, 여러 랜덤한 방향으로 잘라서 1D로 만든 다음 그 분포들이 엄청 여러 개면, 원래의 고차원 분포를 모사할 수 있게 만들 수 있지 않겠냐가 핵심이었고. 그래서 매 step마다 랜덤 방향 몇 개 뽑아서 projection하고, 그 결과가 Gaussian처럼 생겼는지를 계속 확인하는데, 방향을 계속 바꿔가면서 반복하면 원래의 전체 feature space를 충분히 커버하지 않겠냐 라는 가정을 만들어나간 것 같습니다. (1d 로 슬라이싱을 1024, 2048 쯤으로 한 실험이 있었습니다.)
그래서 결국 LeJEPA에서 말하길 각 1D 분포가 Gaussian이랑 얼마나 비슷한지는 Epps–Pulley test 기반 통계 가설 검증 이론을 기반으로 정량화한다고 하구요. 이 1D 분포들의 Epps–Pulley 평균을 그대로 loss로 쓰는 것 같은데, 저자들 왈 미분가능하고 평균취하는 방식이라 gpu에도 gradient 쪼개서 잘 올릴수도 있고, 등등 학습효율적인 이점이 있다고 합니다. 그래서 LeJEPA에서 이미 백본에 대해 안정적으로 학습을 보였기에, 이걸 world model에선 미래 임베딩 예측의 정보량 분산(미래 예측의 다양성, 혹은 exploration 효과?)을 최대한 가져가려는 경향을 만들어서 LeWM에서도 학습 효율이랑 성능이 같이 좋아진 것으로 이해해주시면 될 것 같습니다!
2. 결국 근택님의 말씀처럼 JEPA 기반의 feature space reconstruction은 픽셀의 디테일이 사라질 수도 있다는 내용에 저도 공감하긴 합니다. 근데 저 개인적으로는 WM에서는 어느정도 주류? 혹은 탄탄한 기반이 될 수도 있을 것이라고 생각이 들었습니다. 결국 WM은 latent embedding이 가지게 될 미래 예측 표현에 대해 기대하는 부분이 환경 dynamics 예측, 행동과 관련된 물리적 예측이 중점이고, pixel레벨의 reconstruction은 그동안 WM에서 꽤나 큰 학습 overhead였던 것으로 보이기에 LeJEPA 에 pixel-wise recon이 효율적으로 통합될 수 있는 방법론이 만약 없다면, 당분간은 주류일 수 있을 것 같습니다.
3. 위랑 연결지어서,, 그래서 저도 뭔가 또 새로운 방법론이 생겨나거나, 아니면 이미 나왔는데 제가 모르는 것일 수도 있겠단 생각이 들었습니다.(근데 아직 서치해본 적은 없습니다.) latent feature space에서의 임베딩은 SIGReg기반으로 최대한 latent 자체가 둥글둥글 다양한 표현을 학습하게 만드는 게 중요한 것 같고, 여기서 부족한 pixel-wise detail representation들은 단순 pixel-wise recon loss를 추가해주는 것이 아니라, pre-trained된 latent 임베딩 인코더에 대해 최대한 그 원래 latent 임베딩은 catastrophic forgetting을 줄이고 recon loss 가지고 steering 해주듯이 post-training을 해주는 것이 괜찮은 방향이지 않을까…. 하는 막연한 생각이 드네요.. 혹은 전체 pixel-wise recon을 하면 배경의 영향도 많이 받을 테니,, 이미지 내 object-centric한 patch만 따로 loss 먹여주는 건 어떨지 싶기도 합니다.. (뇌피셜입니다.)
안녕하세요 재찬님 자세한 리뷰 감사합니다
LeJEPA가 로봇 분야에 바로 적용되고 좋은 결과를 내는걸 보니까 정말 신기했습니다.
특히 의미적인 부분을 정말 잘 잡아내는 DINO보다 스크래치로 학습시킨 LeWM가
VoE지표를 통해 underlying physics를 더 잘 잡아내는게 신기했네요.
궁금한 점은 SIGReg의 anti-collapse objective 최적화를 방해하기 때문에 ViT 마지막 레이어에 layernorm이 아닌 batchnorm을 사용한다고 하였습니다. 왜 마지막 레이어만 layernorm이 방해가 되는지 저자가 자세히 설명하게 있나 궁금합니다.
안녕하세요 정우님, 좋은 질문 감사합니다!
제가 이해했을 땐 논문에서는 ViT의 마지막 레이어에 Layer Norm을 적용하는 것은, SIGReg 에서의 핵심 기법이 될 수 있는 1D 투영 기반의 gaussian 가설 검증 통계량 연산이 최적화가 잘 안 되어, [CLS] 출력을 1-layer MLP로 다시 투영하고 그 투영층에 BatchNorm을 두는 것이라고 이해했습니다. 이게 뭔말이냐면, layerNorm이 때려지면 해당 학습샘플 내부에서만 표준화되는 형태가 되는데에 반해, BatchNorm을 때리면 서로 다른 학습샘플들이 배치 단에서 보이는 분포 차이(전체 분산 형태 혹은 특정 1d 투영축에서의 분산의 형태)가 정규화되어 반영이 되고, SIGReg의 핵심은 이런 배치 단위 분포 변화를 1D 투영의 어느축에서 보든 isotropic gaussian 형태로 정규화하고 싶다. -> 그래야 latent embedding이 isotropic 이 될거다. 가 목적이니까 로 이해했습니다.
좋은 리뷰 감사합니다
figure6 실험 결과에 대해 추가 질문이 있습니다
LeWM의 경우 complexity가 낮거나 너무 높은경우가 아닌 평균적인 수준에서 특히 우수한 성능을 보이는것같은데, 학습 데이터와 유사한 복잡도를 의미하나요? 학습 데이터 도메인에 가볍고 빠르게 높은 정확도를 도달하는 학습법으로 이해하면 되는지 궁금합니다.
둘째로는 table7의 decoder loss 관련하여 구조적으로만 유사하게 하거나 metric learning loss를 적용하는등 시각적 디테일을 일부 무시할 수 있는 loss를 적용하려는 시도나 언급이 있었나요? 저자들의 분석이 작성해주신것과 같다면 이러한 확장을 고려할 수 있을것같아 여쭤봅니다
감사합니다
안녕하세요 유진님, 좋은 질문 감사합니다!
1. Figure 6, complexity관련
네, 맞는 방향으로 이해하신 것 같습니다. 논문에서도 언급하길 너무 단순한 환경(TwoRoom)에서는 데이터에 내재된 차원 자체가 낮아서 SIGReg의 isotropic Gaussian 강제가 오히려 과도한 regularization이 되고, 너무 복잡한 3D 환경(OGBench-Cube)에서는 LeWM의 scratch encoder(~5M)가 DINOv2(124M)의 사전지식을 이기기 어려운 한계가 있다고 합니다. 결국 유진님이 말씀해주신 것처럼 해당 학습데이터 도메인에 가볍고 빠르게 latent 표현력을 임베딩하고, 이런 latent 와 MPC solver 기반으로 하면 planning 성공률도 충분히 높더라라는 설계라고 봐주시면 될 것 같습니다.
2. Table 7, decoder loss 확장 가능성?
논문 내에서 이런 확장에 대한 언급은 따로 없었습니다. 다만 관련 연구를 찾아보니, [arXiv 2603]“Is the reconstruction loss culprit? An attempt to outperform JEPA” 라는 논문에서 reconstruction이 왜 해로운지를 분석하고, pixel 내 predictable한 component만 선택적으로 recon하는 gated predictive autoencoder라는 걸 제안해서 JEPA대비 괜찮더라를 보인 논문이 있긴 합니다. 근데 이게 살짝 toy setting 느낌의 실험인 것 같아서 일반화적인 내용인지는 아직은 잘 모르겠습니다. 유진님이 말씀하신 것처럼 perceptual loss나 SSIM, metric learning loss 등으로 불필요한 시각적 디테일은 살짝 무시하게 하면서 구조적 정보만 보존하는 방향은 JEPA 기반 world model 기반 연구에서는 아직까지는 명시적으로 시도한 논문을 찾지 못했습니다. [NIPS 2025 Spotlight]”Joint-Embedding vs Reconstruction: Provable Benefits of Latent Space Prediction” 라는 논문도 찾아봤는데, 이건 recon loss가 JEPA엔 안좋다 에 대해서 고차원 irrelevant features에 끌려가기 때문이라고 이론적으로 증명한 논문이고 이거 기반으로 LeWM도 JEPA에 recon은 안좋다를 주장한 것 같아서,,, 만약 유진님이 말씀하신 것처럼 irrelevant한 시각적 detail 자체를 걸러내게 유도하는 좀 디테일한 selective recon은 충분히 설득력 있어보이고 해당 실험을 진행하는 것도 유의미할 수도 있을 것 같습니다! 확장 아이디어 제안 감사합니다!
안녕하세요 재찬님 좋은 리뷰감사합니다.
리뷰해주신 논문과는 관련이 살짝 없을 수 있는데 궁금한게 생겨서 여쭤봅니다. JEPA 의 representation collapse 문제들중에 Pretrained weigth를 사용하면 생기는 “expressivity에 bound되더라”라고 말씀 설명주셨는데 어떤건지 설명 해주시면 감사하겠습니다. 저도 간단하게 JEPA에 대해서 읽어봤는데 pretrained encoder의 능력을 사용하면 해소될 수 있는 문제들이있는데 문제정의와 벗어나서 사용을 안한건가? 이런생각도 들고 해결 할 요소들이 VFM의 weight들 같다는 생각이 들었는데 bound된다는 현상은 어떤걸까요 ?
답변주시면 감사합니다^^.
안녕하세요 우진님, 좋은 질문 감사합니다! 구두로도 간략하게 말씀드리긴 했지만, 표현 상 이해하기에 어려우셨을 부분이 있을 것 같아 저도 자료를 다시 한번 찾아보고 답글 정리해드립니다.
먼저 제가 리뷰에서 “pretrained encoder의 expressivity에 bound된다”는 표현을 조금 짧게 써서 정보가 부족해서 충분히 이해하기에 부족했던 표현이었던 것 같습니다.
여기서 bound는 정량적인 어떤 상한이 있다기보다, pretrained dinov2 encoder를 freeze하면 downstream world model이 사용할 수 있는 정보의 종류가 pretrained encoder의 feature space의 범주에 고정된다는 의미로 이해해주시면 될 것 같습니다.
예를 들어 DINO-WM에서는 obs를 frozen dinov2 encoder로 latent embedding한 뒤, predictor가 현재 embedding과 action으로 다음 latent embedding을 예측합니다. 이 방식은 encoder가 학습 중 변하지 않으므로 representation collapse를 안정적으로 피할 수 있고, dinov2의 풍부한 visual prior도 바로 활용할 수 있다는 큰 장점이 있긴 합니다.
반대로 task 수행에 중요한 미세한 접촉 상태, 작은 자세 차이, 동역학 관련 변화 등이 dinov2 feature에서 충분히 구분되지 않는다면, 뒤의 predictor는 이미 embedding 과정에서 사라진 정보를 다시 복원하기는 좀 어렵습니다. 즉, pretrained encoder의 표현력이 부족하다는 의미보다는 현재 task의 dynamics에 맞게 무엇을 강조하고 버릴지를 encoder가 새롭게 학습하기가 어려울 수도 있다는건데,
말씀해주신 것처럼 VFM weight는 실제로 매우 유용한 해결 요소라고 생각합니다. 논문에서도 시각적으로 복잡한 OGBench-Cube나 일부 dynamic·rotational quantity에서는 DINO-WM이 더 좋은 결과를 보였습니다. 따라서 pretrained encoder가 항상 불리하다는 표현은 틀린표현이 되는 것 같고, 정확히는 풍부한 general visual prior와 task-specific adaptation 사이의 trade-off가 생길 것 같다. 가 결론인 것 같습니다.
LeWM은 pretrained encoder를 freeze하지 않고도 scratch level로도 raw pixel에서 encoder와 predictor를 end-to-end로 학습하면서 collapse를 막을 수 있는가가 논문의 핵심이라고 생각합니다. task-specific하고 compact한 표현을 학습하고, dinov2보다 훨씬 적은 token인데도 충분히 빠르게 planning할 수 있다는 점을 보이려 한 것으로 이해했습니다.
개인적으로는 말씀하신 방향처럼 VFM weight으로 encoder 초기화한 뒤 SIGReg를 적용하며 end-to-end fine-tuning하거나, 일부 layer·adapter만 학습하는 hybrid 방식도 충분히 의미 있어 보입니다. 다만 encoder를 unfreeze하면 prediction loss의 trivial collapse 가능성이 다시 생기므로 SIGReg 같은 anti-collapse 제약은 여전히 필요할 것 같습니다. 이 hybrid 방향은 해당 논문에서는 직접 실험하지 않았습니다.
질문 덕분에 제가 애매하게 썼던 표현을 다시 생각해보고 정리할 수 있었네요. 감사합니다!