안녕하세요. 오늘은 HybridVLA에 대해서 소개드리겠습니다. VLA를 많이 알아보고 있는 편임에도 불구하고 계속 새로운 모델이 나오고 있는데, 검색을 하면서 발견하여서 어떤 부분이 다를까? diffusion과 autoregressive? 내용에 끌리게 되어서 이 분야에 대해서 좀 더 견문을 넓히고, 제가 VLA 방향 중에서도 아직 어떤 분야에 흥미가 있는지 정확하게 파악을 못한 것 같아서 이 분야에 대해서 좀 더 알아보고 방향을 확실하게 정하기 위해 읽어보게 되었습니다. 그러면 재밌게 읽어주시고 궁금한 점은 질문으로 お願いします~

- Conference: ICRL 2026
- Authors: Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, Chengkai Hou, Mengdi Zhao, KC alex Zhou, Pheng-Ann Heng, Shanghang Zhang
- Affiliation: Peking University; Beijing Academy of Artificial Intelligence (BAAI); CUHK
- Title: HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
1. Introduction
최근 로봇 액션 부분을 보면 Autoregressive 방식과 Diffusion 방식을 볼 수 있습니다. 기존 Autoregressive 기반 VLA(RT-2, OpenVLA 등)는 VLM이 원래 잘하던 next-token prediction을 그대로 로봇 action 예측에 가져옵니다. 그래서 언어 지시를 이해하고 장면의 의미를 파악하는 능력은 좋은 편입니다. 쉽게 말하면 “지금 이 상황에서 로봇이 무엇을 해야 하는가”를 문맥적으로 판단하는 능력이 좋다고 설명할 수 있습니다. 다만 로봇 action은 본질적으로 연속값이기 때문에 이를 discrete bin으로 양자화해서 토큰처럼 다루면 action의 연속성이 깨질 수 있습니다. 로봇 제어에서는 미세한 위치 차이나 회전 차이가 현실 세계에서 큰 변화를 가져오기 때문에 이러한 점에 대해서 신중히 고려해야 된다고 생각됩니다.
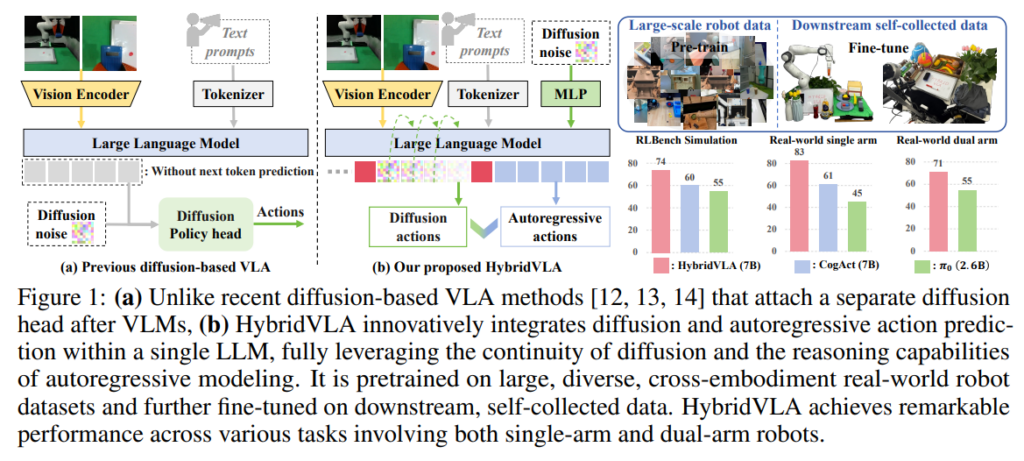
반대로 Diffusion 기반 VLA(π0, CogACT 등)는 연속적인 action을 직접 다루는 데 강점이 있습니다. 노이즈가 섞인 action을 점점 복원해 가면서 최종 action을 예측하기 때문에 더 부드럽고 정밀한 제어가 가능합니다. 그런데 기존 Diffusion 기반 VLA들은 보통 VLM 뒤에 diffusion head를 따로 붙이는 형태를 사용합니다. 즉, VLM이 뽑아준 feature를 diffusion head가 받아서 action을 예측하는 구조입니다. 이런 방식은 연속적인 액션은 잘 살리지만, LLM이 가진 토큰 단위의 reasoning 능력을 action 생성 과정 전체에 충분히 활용하지 못한다는 한계가 있습니다. 즉 LLM을 좋은 feature 추출기로 사용하고 순간순간 생각해서 동작하는 정도로만 쓰는 느낌이 강합니다.
그래서 이 논문에서 저자들은 HybridVLA를 제안합니다. 이름 그대로 diffusion과 autoregression을 하나의 LLM 내부에서 함께 다룬다는 내용입니다. 해당 논문에서 중요한 점은 단순히 한쪽 head 더 붙였다가 아니라, diffusion denoising 과정 자체를 다음 토큰을 예측하는 흐름에 넣을려고 한 점입니다. 저자들은 이 두 방식이 서로 충돌만 하는 것이 아니라 오히려 상호 보완적이라고 주장하면서 결과적으로 어떤 task에서는 diffusion이 더 잘하고, 어떤 task에서는 autoregression이 더 잘하기 때문에, 이를 같이 쓰면 더 robust한 manipulation이 가능하다는 것입니다.
2. HybridVLA Method
HybridVLA의 backbone은 pretrained VLM입니다. 7B 버전은 Prismatic VLM을 기반으로 vision encoder로 DINOv2와 SigLIP 조합을 활용하며, language backbone으로는 LLaMA-2 7B를 사용합니다. 2.7B 버전은 더 작은 구성으로 Phi-2를 사용하고 vision encoder로는 CLIP만 씁니다. 사진에서 볼 수 있듯이 처음부터 전부 새로 학습이 아니라, 이미 인터넷 규모 데이터에서 잘 학습된 vision-language backbone 위에 robot action generation 능력을 얹기 때문에 vision encoder는 freeze 하여 사용합니다.
이미지 입력은 vision encoder를 거쳐 visual token으로 변환됩니다. 7B 버전의 경우 DINOv2에서 f_d \in \mathbb{R}^{B \times N_v \times 1024}, SigLIP에서 f_s \in \mathbb{R}^{B \times N_v \times 1152}를 추출하고, 이를 채널 차원으로 이어 붙여 f_v \in \mathbb{R}^{B \times N_v \times 2176}을 만들어 LLM 임베딩 공간으로 projection합니다. 멀티뷰 이미지를 사용하는 경우에는 shared vision encoder로 각각 특징을 추출하고 token 차원으로 이어 붙입니다.
robot state는 별도의 learnable MLP를 통해 LLM embedding space 안으로 직접 projection합니다. f_r \in \mathbb{R}^{B \times 1 \times 4096} 이 부분은 robot state를 discrete token처럼 억지로 바꿔서 언어 쿼리에 합치는 대신 연속값 그대로 embedding 공간으로 보내는 것이 diffusion 쪽의 continuous action prediction과 더 잘 맞기 때문입니다. 저자들도 discrete state token이 연속 action 예측에 부정적인 영향을 줄 수 있다고 보고 있습니다.
2.1 HybridVLA Architecture
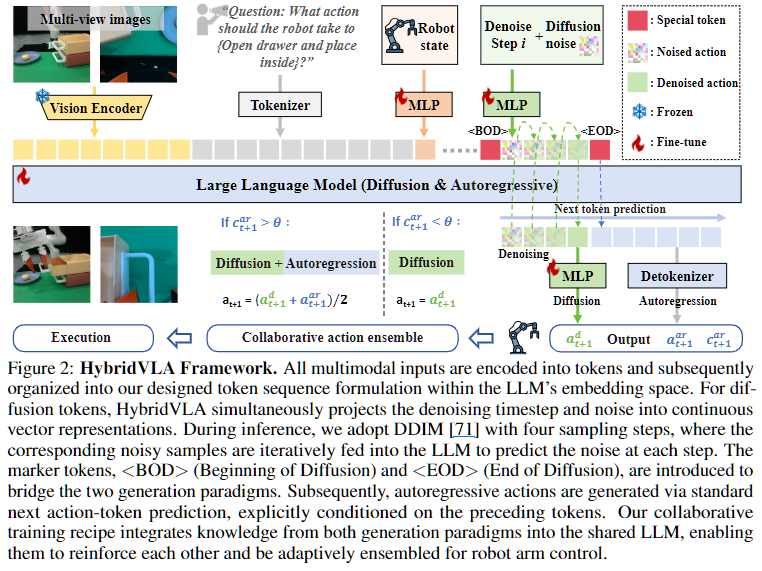
HybridVLA는 diffusion token과 autoregressive token을 한 시퀀스 안에 같이 배치합니다. 그런데 그냥 막 섞는 것이 아니라, BOD(Beginning of Diffusion)와 EOD(End of Diffusion)라는 special token을 두어 diffusion 구간의 시작과 끝을 명확히 표시합니다. diffusion에서 사용하는 timestep 정보와 noisy action 역시 MLP를 통해 continuous vector로 embedding되어 LLM에 들어갑니다. 그 뒤에 autoregressive action token들이 이어집니다. 즉 하나의 시퀀스 안에 visual tokens, language tokens, robot state token, BOD diffusion 구간 EOD, autoregressive action token 같은 흐름을 만들어 둔 것입니다.
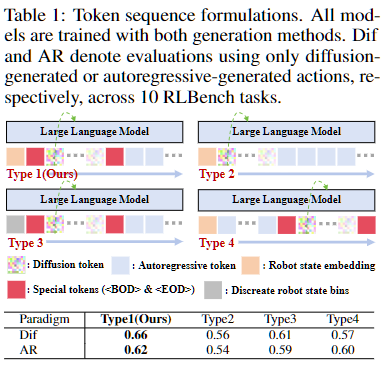
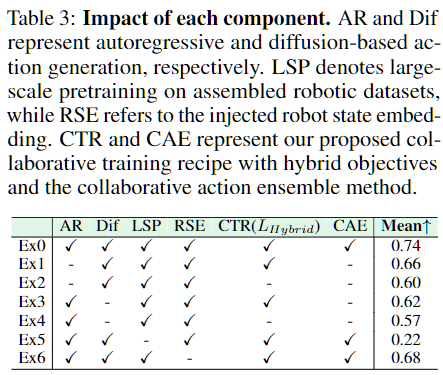
해당 순서가 중요한 이유는 autoregressive는 학습 시 정답 action token도 같이 보게 되기 때문입니다. 만약 autoregressive token을 앞에 두고 diffusion을 뒤에 두면(아래 사진의 Type 4), diffusion이 학습 때 정답 action 정보를 간접적으로 엿보게 되는 GT leakage 문제가 생길 수 있습니다. 실제로 Type 4는 Dif 성능(0.57)이 Type 1(0.66)보다 눈에 띄게 낮아 이 문제가 diffusion 예측에 직접적인 영향을 준다는 것을 확인할 수 있습니다. 또한 Type 2처럼 BOD, EOD special token 없이 diffusion token을 그대로 배치하면, diffusion token이 이후의 masked discrete token을 직접 예측하려는 혼란이 생겨 역시 성능이 떨어집니다(Dif 0.56). 결국 Type 1처럼 diffusion token을 special token으로 감싸고 앞에 배치하는 것이 diffusion-only, autoregressive-only 평가 모두에서 가장 좋은 결과를 냈습니다.
2.2 Collaborative Training Recipe
diffusion과 autoregression을 한 모델 안에 다 넣는다고 하면 오히려 불안정하거나 성능이 떨어질 가능성이 크기 때문에 저자들은 이를 위한 collaborative training recipe를 제안하고, 이는 크게 hybrid objective와 structured training stage 두 가지로 구성됩니다.
Hybrid Objectives
diffusion과 autoregression을 동시에 학습하기 위해 두 손실 함수를 결합합니다. Diffusion 부분에서는 모델이 예측한 노이즈 \epsilon_\pi와 실제 노이즈 \epsilon 사이의 MSE를 최소화합니다.
\mathcal{L}_{dif} = \mathbb{E}_{a,i,c}||\epsilon - \epsilon_\pi(a^i_t, i, c)||^2여기서 a^i_t는 i번째 step의 noisy action이고, c는 conditioning 정보입니다. 안정적인 로봇 팔 동작을 위해 classifier-free guidance는 사용하지 않습니다.
Autoregressive 부분에서는 이산 출력을 감독하기 위해 Cross-Entropy Loss \mathcal{L}_{ce}를 사용합니다. 최종 hybrid loss는 두 손실을 합친 것입니다.
\mathcal{L}_{hybrid} = \mathcal{L}_{dif} + \mathcal{L}_{ce}\mathcal{L}_{dif}와 \mathcal{L}_{ce}가 공유된 LLM backbone에 동시에 gradient를 주기 때문에, LLM이 diffusion의 연속표현도 흡수하고 autoregression이 가진 의미적인 추론표현도 동시에 흡수할 수 있습니다. 말 그대로 두 방식이 shared backbone 안에서 서로 배우는 구조입니다. 논문에서는 이를 mutual reinforcement라고 표현하는데, 쉽게 말하면 diffusion은 autoregression으로부터 문맥적 의미 이해를 얻고, autoregression은 diffusion으로부터 연속적 action 표현의 감각을 얻는 느낌으로 보시면 될 것 같습니다.
Structured Training Stage
학습은 두 단계로 진행됩니다. 먼저 Open X-Embodiment, DROID, RoboMind 등 35개 대규모 로봇 데이터셋(총 760K trajectory, 33M frame)에서 5 epoch pretraining을 수행하고, 이후 downstream simulation/real-world self-collected 데이터로 fine-tuning합니다. 논문에서도 large-scale robot pretraining의 중요성을 강조하고 있고, 단순히 VLM pretrained weight만 가져오는 것으로는 부족하고 로봇 데이터에 대한 대규모 사전 학습이 있어야 실제 manipulation 성능이 안정적으로 나온다고 보고 있습니다. 실험 결과에서 pretraining 없이 학습한 경우 성공률이 0.22까지 감소하면서 이를 설명해주고 있습니다.
2.3 Collaborative Action Ensemble
Autoregressive Action Generation
Autoregressive 쪽은 EOD 이후부터 시작되는 일반적인 next-token prediction 형태이지만, 기존 OpenVLA 같은 모델과 완전히 같은 것은 아닙니다. HybridVLA의 autoregressive generation은 앞쪽에서 diffusion이 만들어 낸 continuous latent representation을 문맥으로 생각하고 받아들인 상태에서 action token을 생성합니다.
autoregressive branch는 원래 문맥 이해에는 강하지만 미세한 연속 제어 감각은 약할 수 있어 diffusion이 앞단에서 continuous action latent를 만들어 주면, autoregressive generation도 좀 더 action-like한 정보를 활용할 수 있게 됩니다. 결론적으로 HybridVLA는 diffusion이 잘 되기만 하는 모델이 아니라, autoreg branch도 강하게 만들어주는 구조입니다.
Diffusion actions
HybridVLA에서 diffusion action은 LLM 내부에서 denoising을 반복하면서 생성됩니다. 추론 시에는 DDIM을 사용하며, 각 step마다 noisy sample을 LLM에 다시 넣어 noise prediction을 수행합니다. 즉 feature 한 번 뽑고 끝이 아니라, denoising step 자체가 LLM의 next-token style context processing 안으로 들어와 있다는 점이 기존 diffusion-based VLA와 차별점이라고 하고 있습니다.
해당 논문에서 실험하기로는 denoising step 수를 대폭 줄였다고 합니다. 일반적으로 diffusion은 step이 많아야 품질이 좋다고 알려져 있는데, 이 논문에서는 4 step만으로도 성능 저하 없이 충분한 manipulation이 가능했다고 합니다. diffusion의 정밀성이 크게 떨어지지 않으면서도 추론 속도도 올리는 이점이 있다고 보입니다.
추론 속도를 더 높이기 위해 KV cache도 함께 활용합니다. 첫 번째 denoising step에서 조건 정보를 처리한 key와 value를 저장해 두고, 이후 step에서는 timestep과 noise 정보만 넣어 반복되는 연산을 줄이는 방식을 사용합니다. KV cache는 기존 autoregressive 모델에서 자주 쓰이는데, 저자들은 이를 diffusion action generation에도 적용한 사례라고 말하고 있고, 실험에서 KV cache 유무에 따라 추론 속도가 9.4 Hz에서 5.0 Hz로 크게 차이가 났습니다.
Ensembled actions
이 논문에서는 추론 시 두 action을 어떻게 합치는지에 대해서도 두 가지 현상을 관찰한 후 서술합니다. 첫째로는 task 유형에 따라 두 방식의 성능이 다릅니다. diffusion은 Phone on base, Close laptop lid처럼 정밀한 조작이 중요한 task에 강하고, autoregression은 Water plants, Frame off hanger처럼 장면 의미를 이해해야 하는 task에 강합니다. 두번째로는 autoregressive token의 평균 confidence가 action 품질의 신뢰할 만한 지표가 되어 성공한 샘플의 80% 이상에서 이 값이 0.96을 초과했다고 합니다.
이를 바탕으로 threshold \theta = 0.96을 설정하고 Figure 2의 내용을 기반으로 ensemble 방식을 결정합니다. 이를 통해 confidence가 충분히 높을 때는 두 action의 평균을 사용하고, 그렇지 않을 때는 diffusion action만 사용합니다. 해당 방식은 단순 ensemble이 아니라 autoreg branch의 자기 확신을 활용했습니다. 결과적으로 HybridVLA는 diffusion과 autoregression을 둘 다 예측한 뒤, 상황에 따라 둘을 합쳐서 더 강하게 쓸지 아니면 안전하게 diffusion만 쓸지를 결정하는 구조라고 설명드릴 수 있을 것 같습니다. 실험에서 threshold 값에 따른 민감도도 확인했는데, 0.94 미만이면 신뢰도 낮은 autoregressive action까지 사용하게 되어 성능이 떨어지고, 0.98 이상이면 앙상블이 diffusion 단독과 유사해져 결과적으로 0.96이 최적임을 수치로 확인했다고 합니다.
4. Experiments
Simulation: RLBench
RLBench 벤치마크에서 Franka Panda 로봇을 이용해 Close box, Close Laptop, Toilet seat down 등 10가지 테이블탑 태스크를 평가했습니다. 각 태스크당 100개 궤적으로 학습하고, 최신 epoch 체크포인트에서 20번 rollout으로 평가했습니다.
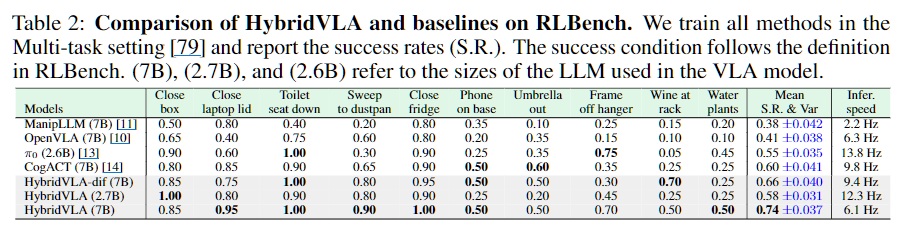
HybridVLA(7B)는 10개 태스크 평균 성공률 74%를 달성해, Autoregressive SOTA인 OpenVLA 대비 33%, Diffusion SOTA인 CogACT 대비 14% 향상된 결과를 보였습니다. 특히 HybridVLA-dif(7B)도 CogACT, π0 대비 각각 6%, 11% 향상되어, 기존 diffusion head 방식과 달리 LLM의 사전 학습 지식을 diffusion에도 충분히 활용할 수 있음을 입증합니다. 추론 속도 면에서도 4 step DDIM과 KV cache 덕분에 HybridVLA-dif(7B)는 9.4 Hz를 달성해 실시간 제어에 충분한 속도를 보입니다.
Ablation Study
Real-World Experiment
Franka Research 3 단일 팔 로봇과 AgileX 양팔 로봇으로 각각 5가지 태스크를 수행했습니다.
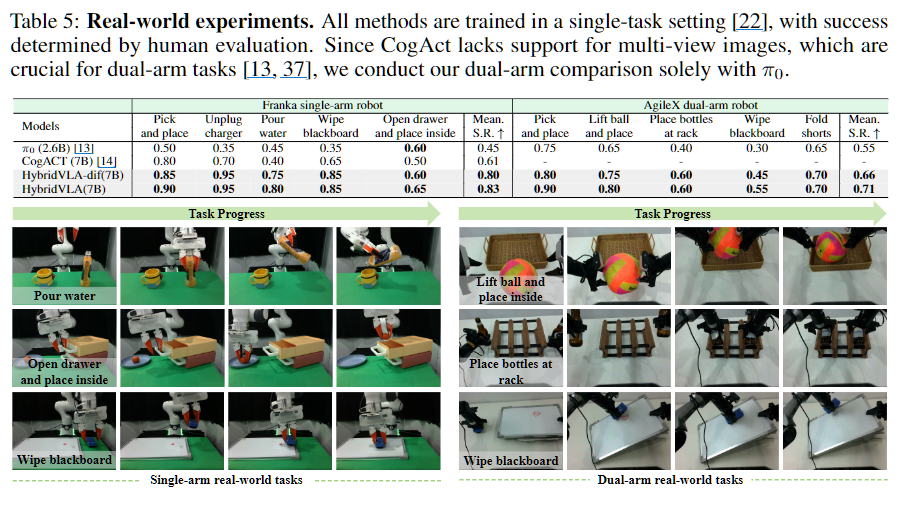
단일 팔 태스크에서 HybridVLA(7B)는 평균 성공률 83%를 달성해 CogACT(61%) 대비 22%, π0(45%) 대비 38% 향상을 보였습니다. 특히 Pour water 태스크에서는 기존 SOTA 대비 35% 향상이 두드러지며, 정밀한 회전 제어가 필요한 task에서의 강점을 잘 보여줍니다. 양팔 태스크에서도 π0 대비 16% 향상된 71% 평균 성공률을 달성했습니다.
Generalization Experiment
unseen 조작 객체, 배경, 높이, 조명 조건 4가지 상황에서의 일반화 성능을 평가했다고 합니다.

모든 시나리오에서 HybridVLA는 CogACT, π0 대비 성능 하락 폭이 가장 작았습니다. 특히 객체 시나리오에서 CogACT가 43% 하락할 때 HybridVLA는 33% 하락에 그쳤는데, Diffusion을 next-token prediction에 통합함으로써 Autoregressive의 객체 수준 의미 추론 능력이 보존된 결과로 보입니다.
5. Conclusion and Limitation
HybridVLA의 한 가지 한계는 추론 속도가 Autoregressive 생성 속도에 제약을 받는다는 점입니다. 여기서 저자들은 학습에서는 두 방식을 함께 쓰되, 추론에서는 Diffusion만 사용하는 HybridVLA-dif 변형을 제공해 9.4 Hz를 달성했습니다.
실제 실험에서는 세 가지 주요 실패 유형도 관찰된다고 합니다. 첫번째로 Pour water나 Place bottle at rack처럼 다단계 회전 동작에서 오차가 누적되는 회전 예측 편차 문제, 두번째로는 로봇의 자유도 한계를 초과하는 포즈를 예측하는 자유도 제한 초과 문제, 마지막으로는 한 팔의 동작이 물체 상태를 바꾸면 다른 팔의 예측이 무효화되는 양팔 협응 실패 문제입니다.
결과적으로 보면 뭔가 두마리 토끼를 다 잡기 위해서 이러한 모델 구조를 만든 것 같다는 생각이 듭니다. 근데 어떤 동작에서는 diffusion만 쓰는 것이 잘 먹고 어떤 동작에서는 autoregressive와 같이 쓰는 것이 더 잘 먹는다고 하는데, 이러한 점이 어떻게 모델에 긍정적인 영향을 준 것인지, VA지만 기존에 autoregressive로 동작을 수행해는 ACT 같은 경우에는 어떻게 되는건지 의문이 들었습니다. 그리고 최근에는 diffusion에서 시작하는 flow 기반이 많은데, 이런 것은 과연 동작에 대한 흐름 이해를 diffusion에 비해서 잘하는 것 같은데 이런 것으로 상쇄가 되는지 좀 찾아봐야 될 것 같습니다.
리뷰 끝까지 봐주셔서 감사합니다.
