안녕하세요 최인하입니다. 이번에는 Robot data quality에 관련된 논문을 리뷰해보겠습니다. Internet-scale의 데이터셋에 대해서 Supervised learning을 진행하여 여타 모델들은 지속적인 성능 향상을 이뤄냈습니다. 이처럼 더 많은 데이터가 더 높은 성능으로 연결된다는 관찰 덕분인지 robot domain에서도 모방학습을 통한 policy의 성능 향상을 위하여 데이터를 많이 수집하게 되었습니다. 이러한 흐름속에서 양보다 질, 질보다는 양이라는 질문을 할 수 있을 것 같은데요. 이 논문은 Quality over Quantity 즉 양보다는 질에 집중한 논문입니다. 기껏 어렵게 많은 시간을 투자해서 teleoperation을 통해 모방학습 데이터를 모았다고 해도 Quality가 좋지 않아 모델의 성능이 안좋으면 안되겠죠. 따라서 논문에서는 action과 state간의 Mutual informaion을 추정하여 데이터의 퀄리티를 측정합니다. 그렇게 측정된 데이터를 curation을 진행하여 모델을 학습시켰을 때 성능이 10% 이상 향상되었다고 하네요. 차근차근 설명해보겠습니다.
Start
논문에서는 DROID dataset으로 학습한 OpenVLA model이 오히려 성능 저하를 보인 모습을 언급하며 시작합니다. 여기서 DROID dataset이란 7만 6천개의 다양한 에피소드를 가지고 있는 로보틱스 분야에서 크고 다양한 데이터셋입니다. 이런 데이터를 모으는데 12개월이 걸렸다는데 실제 model을 학습시켰을 때 성능이 저하된다면 가슴아프겠죠. 논문에서는 이를 방지하기 위해서 다음과 같은 방식으로 데이터의 퀄리티를 측정합니다.
- Mutual Information: 한 변수의 주변 엔트로피와(논문에서는 action을 변수로 사용했습니다.) 다른 변수의 conditional 엔트로피간의 차이를 추정합니다. 뒤에서 더 자세히 설명하겠지만 이를 이용해서 imitation learning의 데이터 퀄리티를 측정합니다.
- Demlnf: 논문에서는 Delmlnf(Demonstration Information Estimation)을 제안합니다. Demlnf는 VAE를 이용하여 action과 state간 구조화된 저차원 representation을 학습하고, K-NN에 기반한 Mutual Information을 사용하여 state-action chunk pairs의 퀄리티를 추정한다고 합니다. 논문에서는 이러한 방식이 로보틱스 분야에서 흔히 사용되 50~300개 정도의 데이터에 더 안정적이라는 것을 발견했다고 합니다.
Preliminaries
Preliminaries는 Demonstration curation 부분을 설명해보겠습니다. 간단하게 말하면 BC에서 demonstration curation이란 주어진 task에서 가장 높은 성능을 얻을 수 있는 policy를 학습시키기 위한 expert policy를 어떻게 형성할 것인가?에 대한 문제입니다.
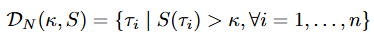
tau라고 읽는게 맞는지 모르겠는데 tau는 에피소드의 state, action pairs 라고 생각하시면 됩니다. 논문에서는 위의 식에서 S를 구하는 것이 목적입니다. 즉 D(demonstration data)가 주어졌을 때 각각의 에피소드의 퀄리티를 측정할 수 있는 S가 있다면 좋은 퀄리티의 data만 학습에 사용할 수 있지 않을까?의 문제입니다. 여기서 k는 quality threshold입니다.
MUTUAL INFORMATION AS A QUALITY METRIC
Mutual information이 어떻게 demo data의 quality metric이 되었을까요?
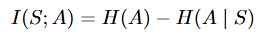
BC는 expert data를 label로 state로 부터 어떤 action을 해야 되는지를 나타내는 policy를 학습합니다. 따라서 action과 state를 mutual information으로 나타내면 위와 같은 식이 되는데요. 논문에서는 위의 식을 사용하여 두가지 조건으로 데이터의 퀄리티를 평가합니다.
- Maximizing Marginal Action Entropy
- Minimizing Conditional Action Entropy
왜 이 두가지가 로봇 데이터의 퀄리티를 평가할 수 있는지 설명해보겠습니다.
Minimizing Conditional Action Entropy
- Ease of fit: 쉽게 생각해서 어떠한 state에서 action의 값이 정해져있을 수록 즉 같은 state에 대한 action의 엔트로피가 낮을 수록 BC는 분포를 학습하기 용이해집니다.
- Multimodality: 엔트로피가 낮은 분포는 종종 적은 수의 peak를 보이는데, 낮은 수의 peak일 수록 forward KL과 reverse KL이 유사한 모습을 보이기 때문에 데이터의 퀄리티를 측정함에 있어서 논문에서 제시하는 방식이 실제 BC에서 최적화 하려고 하는 방식과 비슷해지기 때문입니다.
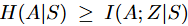
- Privileged Information: 데이터를 수집할 때 expert가 로봇 시야에 없는 즉 카메라에 잡히지 않는 곳에서 데이터를 수집하면 학습되는 policy가 이를 학습하기 매우 어렵겠죠. 따라서 로봇이 관측하지 못하는 Z인 state를 고려하면 위와 같은 식이 나오게 됩니다. 따라서 conditional action entropy를 최소화 하게 되면 관측되지 않은 요인이 데이터에 미치는 영향을 최소화 할 수 있습니다.
Maximizing Marginal Action Entropy
이 부분에서는 처음에는 의아했었는데 새로운 insight를 가져갈 수 있었던 것 같습니다. 논문에서는 H(A) 값을 고려하지 않으면 H(A | S) 는 상수 값을 갖는 분포가 되어서 state와는 무관하게 항상 같은 action만 취하게 될 수 있다고 합니다. 따라서 action entropy는 이러한 상황에서 학습된 policy가 action을 예측할 때 더욱 state를 고려하게 된다고 합니다.
Method
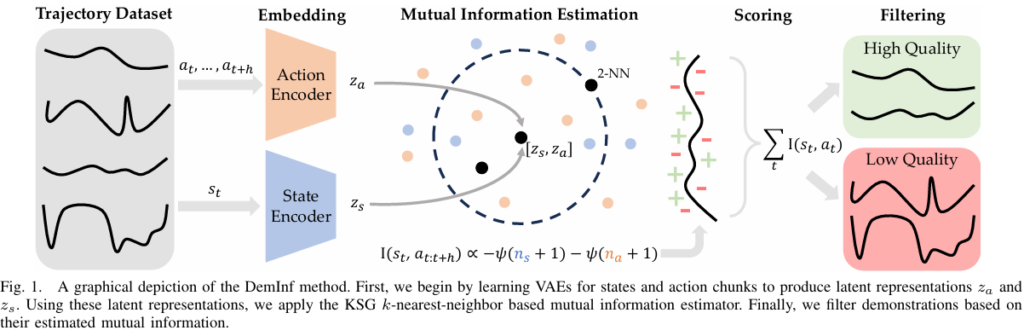
논문에서는 data curation을 위해서 개별 demonstration을 측정하는데 집중한다고 합니다. 따라서 개별 episode가 dataset 전체의 mutual information에 어떤 영향을 미치는지 확인한다고 하네요.
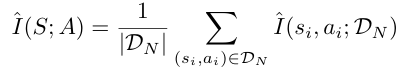
위에서 언급한 Demonstration information estimation (이하 Demlnf)는 k-NN에 기반하여 mutual information을 추정한다고 했는데요. k-nn 방식은 차원의 Curse of Dimensionality 때문에 로보틱스 데이터 처럼 높은 차원의 데이터에는 거리 개념이 무의미 해져 적합하지 않을 수 있습니다. 따라서 논문에서는 별도의 VAE를 학습시켜 state와 action을 임베딩하여 표현합니다. 해당 변수를 충분히 표현할만한 최대한 작은 latent dimension을 선택했다고 하네요.
state와 action의 latent representation이 주어지면 k-nn 기반 estimator를 이용하여 개별 action-state pair가 전체 데이터셋의 mutual information에 얼마나 기여하는지 추정할 수 있습니다. 어떤 데이터 주변의 확률 밀도가 높다면 그 데이터 주변에 많은 sample들이 있을 것이고 k-nn 거리는 작을 것입니다. 반대는 k-nn이 크겠죠. 이러한 확률 밀도를 이용하여 엔트로피를 추정하고, 이를 mutual information으로 확장한다고 합니다.
위의 그림을 보면서 식을 보시면 이해하기가 더욱 쉬우실 것이라고 생각합니다.
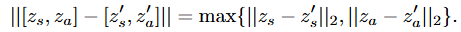
우선 action과 state의 latent space에서 k-nn 거리를 위와 같이 정의합니다.
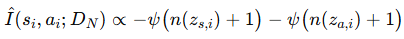
그리고 di-gamma 함수를 통해 확률 분포의 엔트로피를 추정한다고 합니다.(이 수학적인 부분은 따로 공부가 필요할 것 같습니다.) 이때 n(state), n(action)은 밑의 식과 같이 정의된다고 합니다.
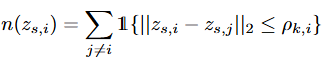
이렇게 mutual information의 추정값들의 집합이 주어지면 위에서 언급한 목표인 각 에피소드에 대한 score function S를 정의할 수 있습니다.
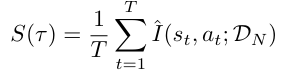
논문에서는 에피소드의 점수 S로 데이터를 필터링합니. 이 때 전체 데이터 셋에 대하여 state – action pair가 mutual information에 기여하는 정도를 추정하면서도 필터링은 개별로 진행하지 않는다고 합니다. 개별로 진행하게 되면 즉 timestep 별로 진행하게 되면 오히려 데이터가 노이즈 해질 수도 있고, 중요한 부분을 놓칠 수도 있다고 합니다. 여기서 중요한 부분이란 그리퍼가 물체와 상호작용하는 부분 즉 물체를 잡는 부분 등을 말합니다.
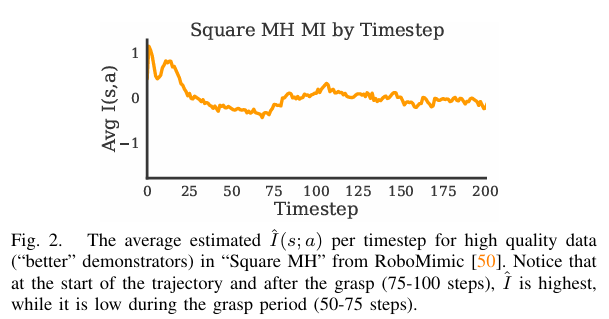
위의 그림에서 볼 수 있듯이 그리퍼가 물체를 닫는 부분에서 mutual information의 값은 낮아지는 모습을 볼 수 있습니다. 왜냐하면 위에서 mutual information의 식을 생각해보면 그리퍼를 닫는 부분에서는 엔트로피 값이 매우 낮아질 것입니다. 특정 행동을 무조건해야 되니까요. 따라서 timestep으로 필터링을 진행하게 되면 이처럼 mutual information은 낮지만 task에 있어서 매우 중요한 부분을 필터링 할 위험이 있다고 합니다.
Experiment
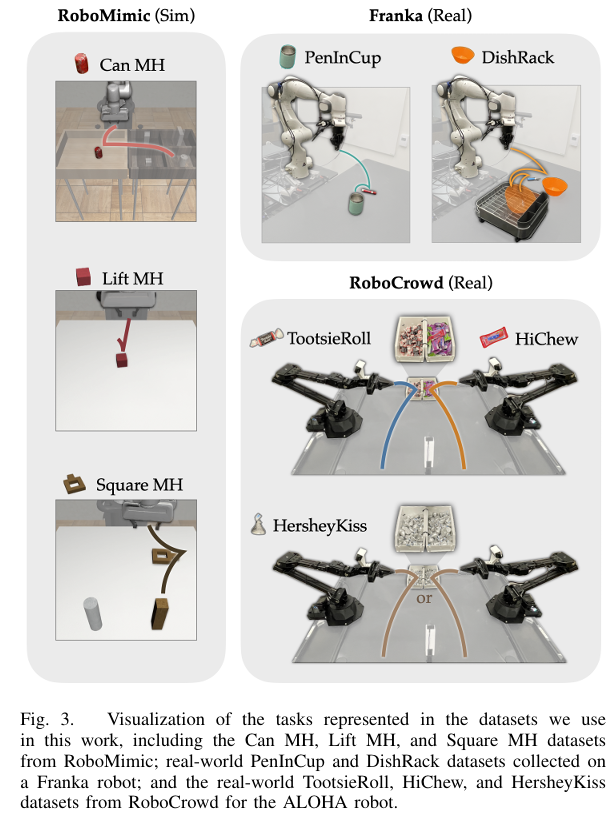
실험 세팅은 위의 그림과 같습니다. 특히 human expert가 quality label을 제공한 데이터를 사용하여 평가하였다고 하네요.
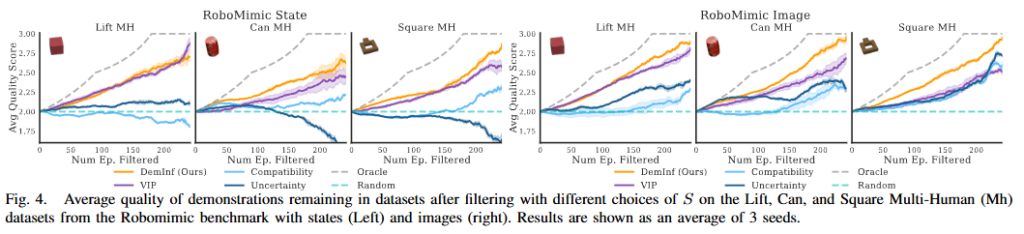
첫번째 평가는 Demlnf가 얼마나 data curation을 잘 수행하는가?입니다. 회색 점선이 이상적인 data curation 결과입니다. noise가 더 많은 image 기반에서 논문에서 제시하는 Demlnf 방식이 더욱 높은 성능을 보이는 것을 볼 수 있습니다.
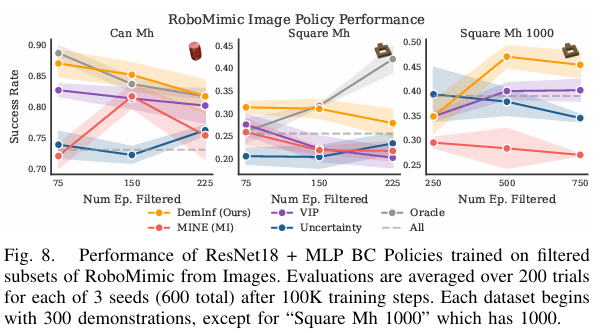
실제로 필터링한 데이터로 BC policy를 학습시켜 결과를 확인하였는데요 논문에서 제시한 Demlnf 방식으로 필터링 된 데이터셋으로 학습한 policy 가 우수한 성능을 보이는 것을 확인할 수 있었습니다.
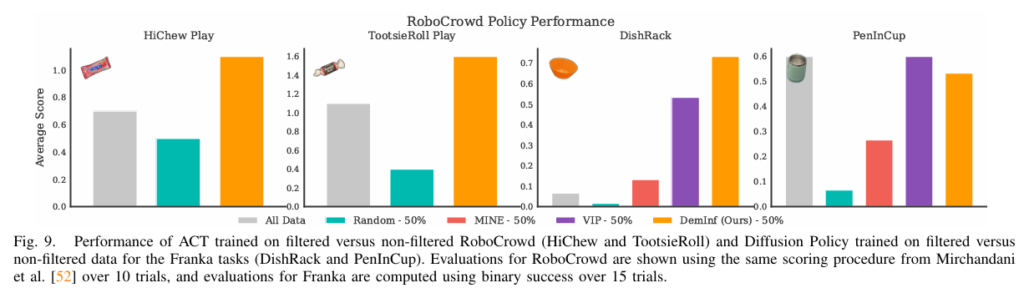
또한 실제로 데이터를 취득하여 학습하였을 경우에도 성공률이 높은 것을 볼 수 있었습니다. 이 때 논문에서는 데이터를 취득할 때 일부로 50% 정도 노이즈한 데이터를 취득했다고 하네요.
오늘 리뷰를 진행한 논문은 데이터의 양보다는 질에 집중한 논문이라고 생각이듭니다. 하지만 multi-task의 부재, task의 실패한 에피소드, 에피소드를 지움으로서 발생하는 분포의 변화 등을 다루지 않았다는 것에 대한 아쉬움이 있네요. 감사합니다
인하님 좋은 리뷰 감사합니다.
해당 논문이 policy를 학습하는 데 있어, 도움이 되는 데이터를 선별하기 위해 mutual inforamtion을 활용하는 논문이라 이해하였습니다.
리뷰에서, ‘Privileged Information’에 대한 설명 중, 로봇이 관측하지 못하는 Z인 state는 H(A|S) ≥I(A;Z|S)와 같은 식이 나온다고 하셨는데, 해당 식이 잘 이해가 되지 않습니다. H와 I가 각각 무엇을 의미하며, 카메라에 보이지 않는 state가 어떤 경향을 보인다는 것인 지 설명 부탁드립니다.
또한, 해당 논문이 모든 데이터에 대하여 수학적으로 계산하여 평가하는 것으로 이해하였는데, DROID와 같이 대규모 데이터의 경우 이러한 curation 과정이 굉장히 오래 걸릴 것 같다는 생각이 듭니다. 이에 대한 언급은 따로 없나요?
마지막으로, 실험 그래프에서 회색 점선이 이상적인 data curation 결과라 하셨는데, 그래프에 보면 ‘Oracle’이라 되어있는데, 사람이 데이터를 보고 선택한 결과일까요? 이때 해당 논문에서 정의한 기준을 따르는 것인지도 궁금합니다.
감사합니다.
안녕하세요 승현님! 좋은 질문 감사합니다.
첫번째 수식에 대해서 설명해보겠습니다.
우선 H는 엔트로피입니다. 따라서 H(A|S)는 state가 주어졌을 때 robot이 취할 수 있는 action 값의 엔트로피입니다. I 는 mutual information입니다. 따라서 I(A; Z|S)의 의미는 state가 주어졌을 때 관측하지 못하는 Z가 robot action에 얼마나 영향을 미치는가를 의미합니다. 따라서 논문에서는 H(A|S) ≥I(A;Z|S)의 의미는 state간 action 엔트로피 값을 최소화 한다면 I(A; Z|S)의 값도 같이 줄어든다를 의미하고 있습니다. 풀어서 설명하면 state가 주어졌을 때 action에 대한 불확실성이 줄어들면 관측할 수 없는 상황에서의 action에 대한 mutual information의 값도 줄어든다고 말할 수 있을 것 같습니다.
두번째 질문에 대해서는 시간에 대한 정량적인 언급은 없었지만, 논문에서 제시하는 K-NN 방식이 데이터셋의 규모가 커질 수록 time cost가 크게 증가한다고 하였습니다. 따라서 논문에서는 배치 단위로 쪼개어 계산한다고 하며, future work에서 large dataset에 대한 검증을 염두해 두는 것 처럼 보였습니다!
세번째 질문에 대해서는 논문엣허는 사람 전문가가 이미 매겨둔 quality label로 직접 데이터를 정렬해서 고르는 경우를 oracle로 명칭합니다! 또한 기준에 대해서도 질문해주셨는데, Robomimic 과 RoboCrowd 데이터 셋 같은 경우에는 데이터 셋 자체에서 quality를 제공한다고 합니다!
안녕하세요 인하님, 좋은 리뷰 감사합니다.
사실 알고보면 데이터셋 집합이라는 것도 따지고 보면 확률통계적으로 설명될 수 있기에, mutual information이라는 확률,통계,정보이론 관점에서의 접근을 적용해서 data curation을 위한 filtering 기준을 만들어냈다는 점이 신선하네요.
사실 수식에 대한 설명이 생략된 부분이 있는 것 같아서,, 이해는 완벽히 하지 못해서 조금 더 하이레벨의 질문이 몇가지 있는데요.
1. time step으로 filtering 하지 않는다는 의미에 대해 이해를 해보려 했는데, 한 에피소드의 데이터에 대해 전체 time step이 0~1이라고 하면 이 중 특정 time step의 시퀀스 0.1~0.3을 필터링해서 잘라내는 게 혹여라도 그 쪽에 gripper 동작 하는 과정이 있을 수 있으니까 안 좋으니 하면 안된다인거죠?
2. 그렇다면 time step filtering이 아니면 그냥 에피소드 통째로를 기준으로 filtering을 하고 curation한다는 건가요?
3. 사실 VAE 기반 encoder 로 latent space로 임베딩해서 거기서 knn기반 거리 값을 활용하는 것까지는 일단 distance값에 불과한 것 같고, 여기에 di-gamma 함수? 를 적용하면서 mutual information과 관련된 확률적 성질이 가미되어 수치화될 수 있다는 것으로 이해했는데, 그럼 이 di-gamma 함수.. 실험에서 비교하는 베이스라인 방법론들(MI, VIP, Uncertainty)과 비교했을 때 어떤 수학적 의미 차이를 가지나요..?
안녕하세요 재찬님 좋은 질문 감사합니다!
1. 맞습니다. 좀 더 풀어서 설명해보면 time step 기준으로 필터링을 진행하게 되면 MI가 낮은 부분 즉 그리퍼가 닫히는 물체를 grasping 하는 부분이 curation 되기 때문에 오히려 노이즈한 데이터가 될 수 있다고 합니다.
2. 넵 맞습니다.
3. K-NN 의 거리 값을 이용하는 것은 맞지만 더욱 더 구체적으로 말하면 밀도를 이용한다고 생각하시면 될 것 같습니다. 이 부분은 너무 수학적인 디테일이 있어서 여기다가 제가 다 풀어서 작성해도 솔직히 설명이 부족할 것 같아서 Kozachenko–Leonenko estimator 찾아보시면 될 것 같습니다.
3번쨰 질문은 저도 수식적으로 공부해보겠습니다. 감사합니다
안녕하세요, 인하님. 좋은 리뷰 감사합니다.
Mutual Information으로 데이터 품질을 판단하는 방식이 흥미로웠습니다.
그런데 어떤 구간은 action이 거의 정해져 있어서(MI가 낮게 나올 수 있는 구간) 오히려 중요한 데이터일 수도 있을 것 같은데, 이런 경우에도 잘 반영이 되는지 논문에 제시되어 있는지 궁금합니다.
감사합니나.
안녕하세요 기현님 좋은 질문 감사합니다~
그 부분을 저자들은 중요하게 생각하였습니다! 예를 들어보면 robot EE 가 object를 grasping 하는 상황에서는 매우 중요한 데이터이지만 state에 따른 action 값이 정해져있어서 MI 값이 낮게 나오겠죠. 따라서 저자들은 에피소드 기준으로 MI의 평균을 평가합니다. timestep 기준으로 평가하게 되면 이러한 중요한 부분이 전부 curation 되어서 오히려 노이즈한 데이터가 될 수 있다고 하네요!