이번에 소개해 드릴 논문은 아카이브에 공개된 지 2주 좀 안 된 논문입니다. 정확히는 테크니컬 리포트이고 애플에서 쓴 논문이네요.
Intro
기존 트랜스포머는 문맥(Context)을 파악하는 ‘Self Attention(SA)’과 각 위치의 특징을 업데이트하는 Feed Forward Network(FFN) 구조로 구성되어 있습니다.
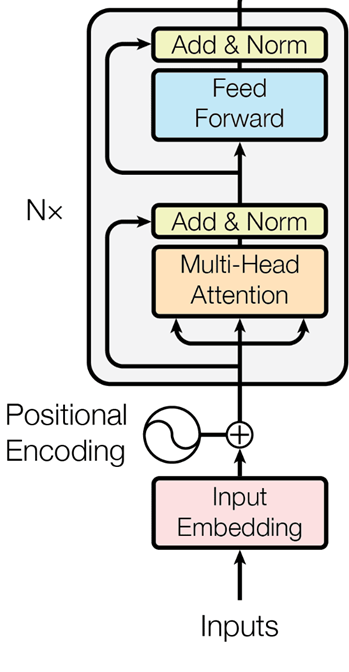
self-attention 과정은 잘 아시겠지만 한번 정리하고 가면, 입력 x에 대하여 각각의 fc layer를 통과해 query, key, value 값을 계산한 뒤 query와 key 값을 내적하고 softmax를 취해서 attention map을 생성합니다.
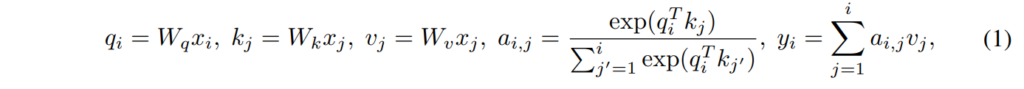
그리고 이렇게 만들어진 attention map이 value 값에 내적합으로 적용됨으로써 attention이 적용된 y값이 생성됩니다. 여기서 저자들은 SA의 출력값이 자기 자신의 value 값과 불필요하게 높은 유사도를 높다는 문제점을 발견하고 이를 어텐션 유사도 편향(attention similarity bias) 문제라고 정의합니다. 쉽게 이야기해서 attention 과정을 거친 y값과 value v값이 코사인 유사도가 높게 계산된다는 점입니다.
저는 처음에 value값에다가 attention map을 적용해서 만들어진 것이 y이니 당연히 y와 v가 유사도가 높은 것이 이상하지는 않겠다고 생각은 했습니다만, 보통 self-attention 연산을 통해서 저희가 바라는 점은 주변 문맥을 잘 파악하는 데 집중해야 하는 것인데 그러지 못하고 자기 자신의 정보들에 집중하고 있다는 의미가 됩니다.
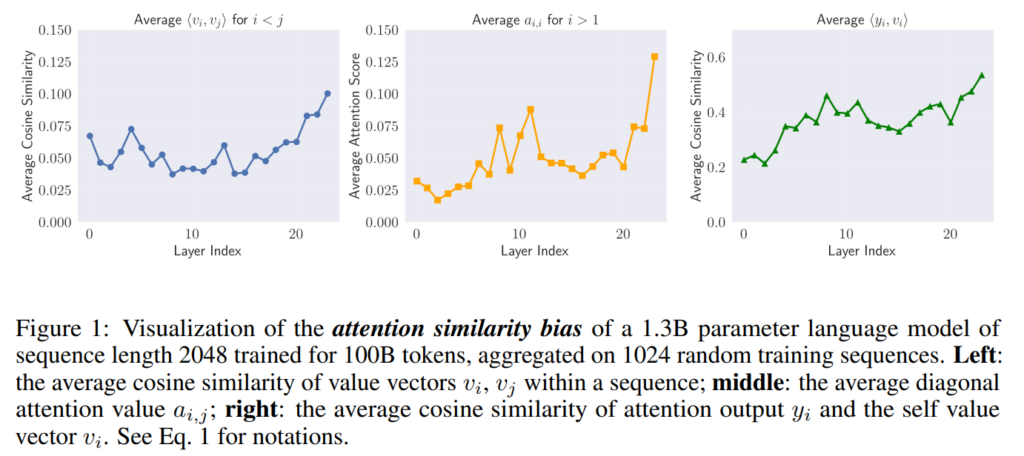
위의 그래프는 저자들이 1.3B LLM 모델에 대해 transformer layer 별로 특징들을 분석한 결과입니다. 가장 좌측 결과는 동일한 head와 sequence 안에서 value vector들에 대한 코사인 유사도를 측정한 것이며, 가운데 결과값은 attention map의 대각성분의 평균 score 값을 나타낸 것입니다. 우측 결과는 y값과 그에 대응되는 위치의 value 값 사이의 코사인 유사도의 평균값을 나타낸 것입니다.
위의 결과에 대해서 저자들은 다음과 같이 분석했는데, 첫째는 value 값과 attention score가 양의 상관관계를 지녔다는 점입니다. 세가지 표가 모두 비슷한 양상을 보여주고 있다는 점이며 둘째로 동일 위치에서의 value와 y 사이의 코사인 유사도가 높다는 점에서 자기 자신에 대한 특징 모델링의 역할을 수행하고 있는 것이 아닌지, FFN과의 역할이 중복되어서 수행되고 있는 것이 아닌지에 대한 우려를 저자들은 표하고 있습니다.
정리하면, 자기 자신에 대한 정보를 잘 파악하고 특징을 모델링하는 부분은 FFN의 역할이지만 그 과정을 SA도 불필요하게 반복하고 있다는 점들이 저자들이 꼽는 문제점에 해당합니다. 결과적으로 문맥을 모델링하는 것과 자기 자신의 특징을 모델링하는 것 사이에 경쟁이 발생해 모델의 효율성과 성능을 갉아먹는다고 저자들은 주장합니다.
Method
그럼 해결 방법에 대해서 알아보겠습니다. 사실 저자들이 제시한 해결책은 상당히 간단합니다. 핵심 아이디어는 SA의 최종 출력값 y에서 ‘자기 자신의 가치 벡터 v의 방향’을 명시적으로 빼버리는 것입니다. 즉, 출력값에 자신의 정보가 섞이지 않도록 직교하게 만듦으로써, 어텐션이 오로지 ‘주변 문맥 정보’만 온전히 담아내도록 강제했습니다.
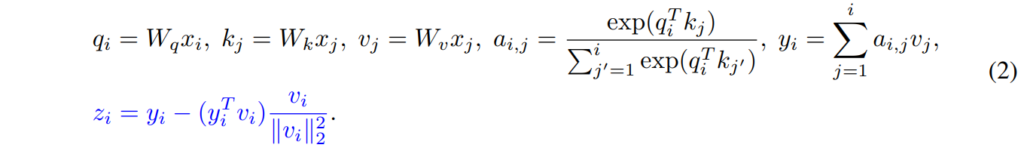
아까 봤던 수식1에서 파란색 내용이 추가된 모습입니다. 저 파란색 과정이 추가되는 것이 저자들이 제안하는 XSA 방법론입니다. 쉽게 생각해서 y와 v가 서로 유사도가 높다면 y 벡터에 대하여 v 방향에 대한 성분들을 제거하자는 것입니다. 너무 간단하죠? 실제 파이토치 코드에서도 매우 간단하게 구현이 되어 있습니다.

저희가 아는 기존의 self-attention 과정을 다 마친 뒤 파란색 코드 부분만 추가하면 됩니다. value 값에 대하여 정규화하여 방향에 대한 정보만 남긴 Vn을 구한 뒤 Y와 내적하여 해당 방향에 대한 Y의 크기 값을 계산합니다. 그리고 다시 Vn 방향값을 곱해준다음에 해당 성분을 Y에 빼주면 끝이죠.
이렇게 그냥 v 방향에 대한 성분을 제거해버리는 방식이 어찌보면 극단적이라는 생각이 들 수도 있습니다. 저자들의 주장대로 attention의 결과값이 y와 value 사이의 연관성이 높은 것이 더 넓은 맥락을 파악해야 하는 관점에서 문제가 될 수도 있지만, 반대로 이 연관성이 높아야만 하는 경우가 있을 수도 있을 텐데 말이죠.
저자들은 이 부분에 대해서 크게 걱정하지는 않는 모습입니다. 설령 attention 연산을 거친 뒤 저자들의 exclusive한 방식을 통해 자기 자신에 대한 정보를 최대한 제거하더라도 결국 기존의 transformer는 attention 처리가 된 output과 input 사이의 residual connection을 수행하기 때문에 자기 자신에 대한 정보가 여전히 살아있다는 것입니다. 그리고 그 이후에 FFN을 태워서 또 모델링을 하니 역할의 중복을 최소화하고 SA가 주변들과의 관계를 더 집중할 수 있도록 도와주겠다는 것이죠.
Experiments
저자들은 Vision과 같은 다른 모달리티는 다루지 않고, text 모달리티만을 실험에서 고려합니다. 실험에 사용한 모델의 구조는 각각 아래 3가지 버전으로 세부사항은 표를 참고하시면 좋을 듯 합니다.
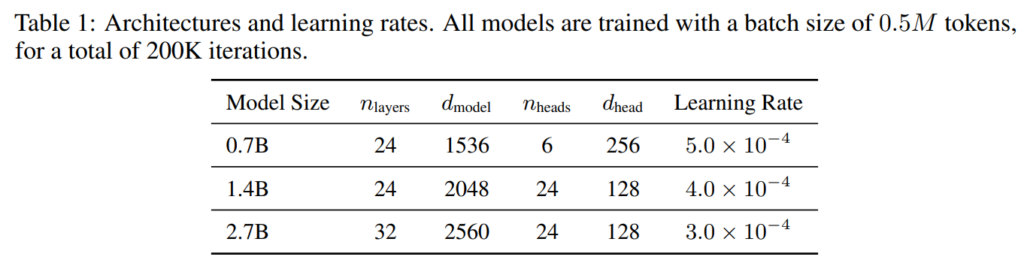
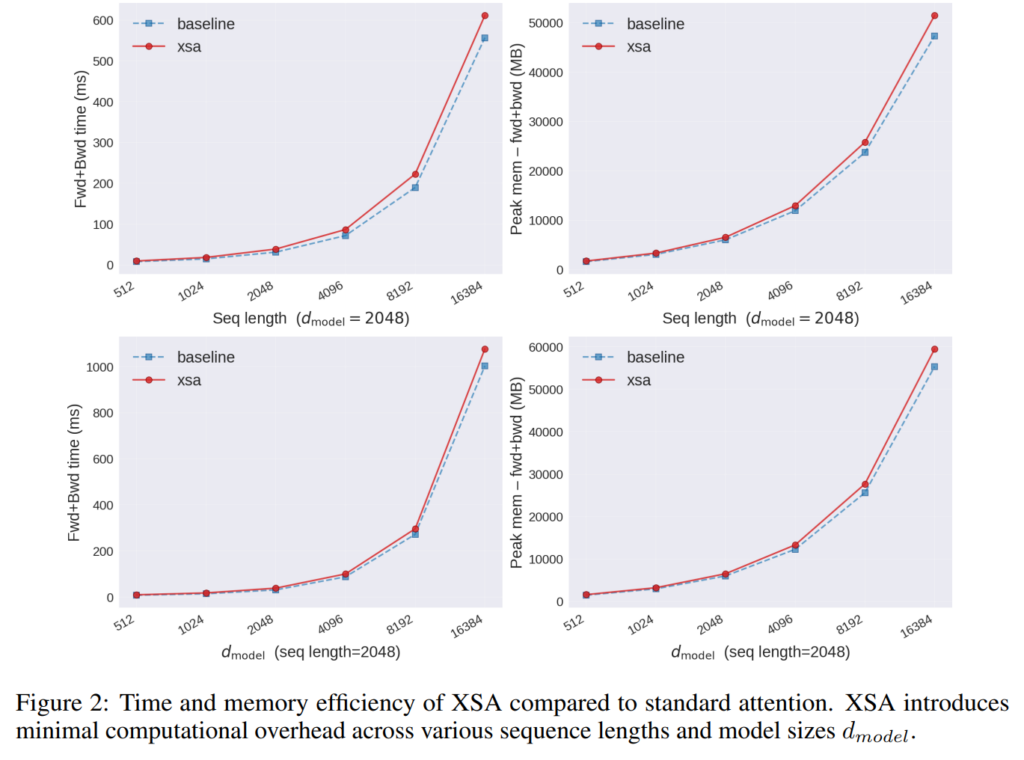
위의 그림2는 일반적인 transformer의 SA와 저자들의 XSA를 적용하였을 때 사용되는 시간 및 메모리 효율성을 나타낸 것으로 시퀀스 길이가 길어지면 길어질수록 exclusive 과정을 위한 내적 연산량이 늘어나긴 하지만 attention 연산처럼 길이의 제곱배만큼 늘어나고 그런 것은 아니다보니 요구되는 메모리와 추론 시간이 미미한 것을 확인할 수 있습니다.
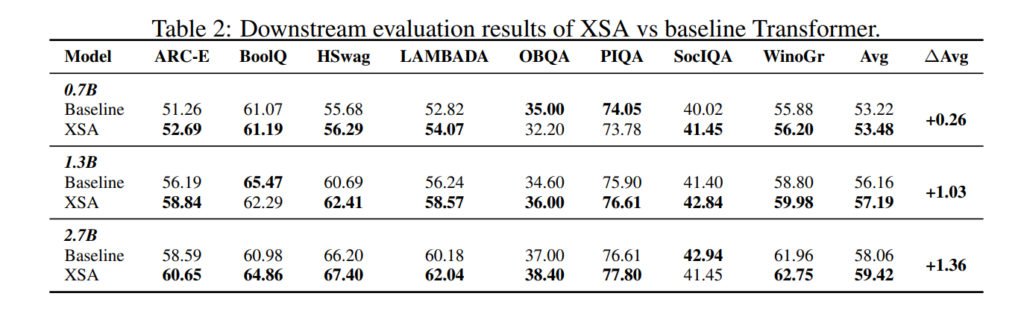
표2의 경우에는 XSA와 baseline 트랜스포머를 각각 8개의 다운스트림 테스크에 적용하였을 때 결과값으로, 저자들의 방법론이 거의 대부분의 task에서 베이스라인 대비 더 좋은 성능을 보여주고 있습니다. 그리고 재밌는 점은 모델의 사이즈가 커지면 커질수록 XSA를 통해서 얻을 수 있는 성능의 향상 이점이 더 크다는 점으로, 모델의 크기와 학습 데이터의 크기가 더 커지는 larger scale training 상황에서 좋은 이점을 누릴 수 있다고 합니다.
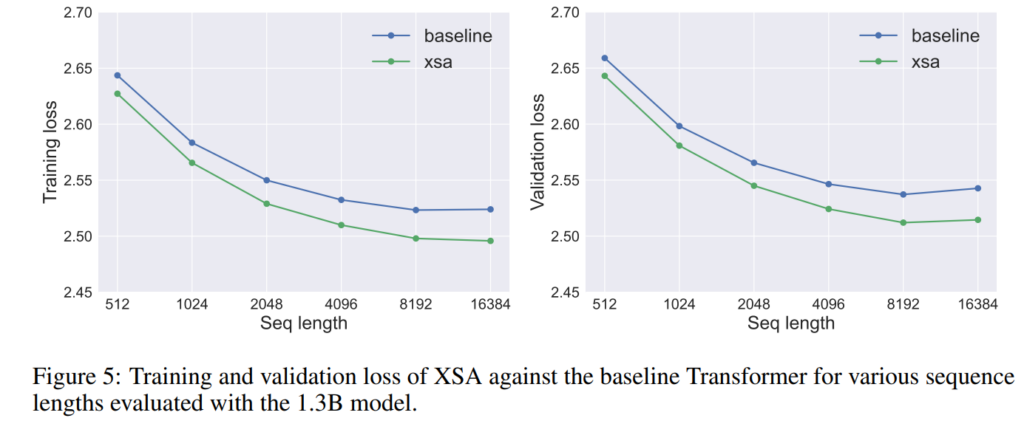
다음은 1.3B 사이즈의 모델에 대하여 sequence length에 따른 XSA와 SA의 loss 변화에 대한 결과입니다. 저자들의 XSA는 Seq length가 길면 길수록 더 loss값이 작게 나오는 것을 확인할 수 있는데, 이는 입력의 길이가 더 길어진만큼 context를 파악하는 능력이 더욱 중요해지는 점에서 XSA가 자기자신에 대한 집중을 배제하고 더 좋은 맥락 파악 능력을 가진다는 것을 보여주는 결과라고 합니다.
결론
우선 테크니컬 리포트여서 그런지 글이 짧고 간결하게 작성이 되어있습니다. 저자도 한명이라서 그런지 실험은 NLP 부분에 대해서만 다루어져있으며, vision쪽 모달리티에 대해서는 실험결과가 없다는 점이 아쉽네요. 그렇지만 저자들이 문제 정의한 부분과 이를 해결하는 부분이 간결하고 직관적이라는 점, 게다가 적용하기도 매우 쉬워서 혹시나 Transformer의 context 모델링 능력에 대한 고민이 있으시던 분들은 가볍게 읽어보기 좋은 글이었던 것 같습니다.
안녕하세요 정민님 좋은 리뷰 감사합니다. 궁금한 부분이 있어서 남겨놓습니다.
FFN의 역할이 번복된다는 부분에서 의문점이 생겼습니다. FFN과 SA의 출력이 자기 자신과 유사하다는 점이 역할이 비슷해 보일 수는 있지만, 연산 구조 자체가 달라서 중복이라고 볼 수 없을 것 같은데, residual이 SA에서 제거한 부분을 채워주는 역할을 한 것 같기도 해서 FFN과의 연관성에 더 의문이 생깁니다. 정민님의 의견이 궁금합니다!
안녕하세요. 일단 성민님 말씀대로 FFN이 SA와 엄연히는 다른 연산 구조를 가지고 있기 때문에 이 둘이 100% 같다. 중복이다. 라고 할 수는 없습니다. 제가 리뷰에서 표현한 내용들은 둘이 같다라는 의미로 쓴 것이 아니라 FFN과 SA의 역할이 서로 100% 다르다는 것을 기대했지만 SA의 output과 Value의 유사도가 생각했던 것 보다 높게 나왔다는 점에서 저자들의 표현을 옮겨사용한 것입니다.
우선 residual은 저자들의 Exclusive SA의 우려점을 해결해준다는 부분에 대한 내용이었으므로 지금 질문과는 관련이 없는 것 같고, FFN과 기존의 SA에 대해서 저자들이 왜 중복이라고 표현한 부분에 대해서만 보충 설명을 드리자면 우선 트랜스포머 레이어에 입력 x가 있을 때, value는 x에 FC layer를 태워서 만든 값입니다. 여기서 attention map을 계산한다음에 v에 적용한 것이 y인데, 이때 어텐션 연산은 마치 입력 특징의 길이와 동일한 크기의 컨볼루션 연산을 취한 것처럼 receptive field가 global하게 작동합니다.
반면 FFN은 개별 토큰 하나하나에 대해서 dimension 축으로 연산이 적용되기 때문에 receptive field가 SA와 비교해서 매우매우 국소적입니다. 즉 SA는 한번에 전체를 보는 연산이고, FFN은 1토큰씩 개별적으로 보는 연산이죠. 근데 문제는 attention map이 적용된 y가 global하게 봤음에도 불구하고 attention map이 적용되기 전 입력인 v와 유사도가 높다고 저자들은 주장합니다 (참고로 저자 기준입니다. 다른 사람 주관에서는 유사도가 높지 않다고 생각할 수 있습니다.). 이는 곧 개별토큰들의 SA 결과값이 다른 위치의 토큰들의 값에 크게 영향을 받았다기 보다는 자기 자신에 대한 값에 더 비중있는 영향을 받았다고 해석이 가능합니다.
이러한 점에서 저자들은 자기 자신에 대한 연산만을 수행하는 FFN과 비슷한 동작을 했다고 보고 기존의 SA가 FFN과 그 역할을 중복되게 수행하고 있다고 표현한 것입니다. 즉, 중복이라는 키워드는 이 둘이 100% 같다라는 말로 사용한 것이 아닌 SA가 우리가 기대했던 역할(토큰들간의 관계 계산)을 수행 못하고 FFN과 비슷하게 자기중심적인 연산을 하고 있는 것 같다는 의미로 사용된 것입니다.
리뷰 잘 읽었습니다. SA가 가질 수 있는 attention similarity bias 라는 문제를 찾고 이를 해결하기 위한 XSA 를 제안한 리포트 같습니다. 처음에 읽을 땐 Self-Attention 결과 y에서 value v 방향 성분을 빼는 이 행위(?)가 과하지 않은가 라고 생각했다만 residual connection 때문에 어느정도 초기값이 유지될 수는 있겠군요
다만 궁금한 점이 있다면, 결국 이 XSA가 잘 워킹하는지를 보이기 위해서는 generalization를 보여야할 것 같은데 .. 아 물론 Table 2에서 여러 NLP benchmark를 평가하긴 했지만, 객관식 이해·상식추론 계열에 집중되어 있는 것 같아서요. XSA에 대해 더 다양한 유형의 text task 실험은 없나요? vision 같은 모달리티가 없다하니 더 궁금해지네요
두번째로 긴 문맥에서 loss가 낮아진 것이 실제 long-context task 성능 향상으로도 이어졌는지 궁금합니다.
안녕하세요. 우선 해당 논문은 어떠한 학회나 저널을 타겟으로 하는 느낌보다는 말그대로 테크니컬 리포트에 가까워서요. 아직 아카이브에 공개된지 얼마 안된 시점에서 얼마나 더 수정되고 개선될지는 모르겠으나 현재 버전이 완성도가 높다고 느껴지지는 않았습니다.
그러한 관점에서 질문 주신 부분들에 대해 답변드리면 더 다양한 유형의 text task에 대한 실험이 딱히 없으며 loss에 대한 부분만 언급할 뿐 long-context task에 대한 정량 지표에 대한 실험 결과도 없습니다. 근데 제 생각에 해당 방법론의 문제정의 및 해결 방식이 vision modality에도 유효하다면 해당 방법론을 개선시킬만한 방향성이 있는 것 같아서 리뷰로 가져와봤습니다.