논문 정보
- 저자:
- Andrew Wagenmaker1, Mitsuhiko Nakamoto1, Yunchu Zhang2, Seohong Park1, Waleed Yagoub2, Anusha Nagabandi3, Abhishek Gupta2, Sergey Levine1*
- 1: UC Berkeley, 2: University of Washington, 3: Amazon
- 링크: https://arxiv.org/abs/2506.15799
- 프로젝트페이지: https://diffusion-steering.github.io/
안녕하세요. 이번 논문 리뷰는 DP(Diffusion Policy)의 Policy Steering을 위한 RL 방법론인데, Diffusion 내의 Latent Space를 활용한 RL 방법론입니다.
사실 현재는 π^*_{0.6} 에서의 related work에 언급된 것처럼 정말 IL -> RL refine 에 대한 많은 방법론들이 쏟아지고 있는 와중, 해당 논문은 CoRL 2025에 나온 논문인지라 살짝 뒤쳐진 리뷰이긴 한데요. 그 때보다 지금이 RL방법론에 대해 점점 더 핫해지는 걸 보면 약간 로봇 도메인에서의 deepseek 모먼트에 지금 현재 시점이 가장 가까워진 상태이지 않을까 싶습니다.
각설하고. 앞서 말한 π^*_{0.6} 에서는 fully online RL loop 로 방법론을 다루지 않고 iterated offline RL loop 방식을 다루었었는데요. 이게 뭐냐면 일단 사전학습된 VLA를 deploy시에 on-robot rollouts(+ human interventions)의 수집과 라벨링을 배치단위로 진행하고, 그 배치에 대해 value와 policy를 offline SFT 학습 시그널로 재학습한뒤 업데이트하는 방식입니다. 그러다보니, π^*_{0.6} 에서도 future work로 fully online RL loop 로 나아가고 싶다고 언급하는데요.
저는 여기서 PI 측에서 future work로 삼았던 online RL으로의 발전에 대해 궁금증이 생김과 동시에 여러 궁금증 때문에 해당 논문을 리뷰하게 됐습니다.
먼저, iterated offline RL 방식에서는 ‘기본적인 IL loss에서의 supervision에 RL의 맛을 주기 위해 advantage기반으로 conditioned supervision을 주는 것’을 RL이라고 칭했는데, 과연 pretrained base policy의 개선을 위해선 SFT스러운 RL을 하는 게 맞을까에 대한 고민.
이와 연계해서, 앞으로 잠정적으로 제 연구에서 다루고자 하는 “DP-WM latent aligned 기반 failure detection으로 reward 시그널을 만들어서 online RL학습으로 policy steering하여 작업성공률 개선하는 연구”에 대한 힌트를 얻을 수 있지 않을까에 대한 고민.
에 대해 좀 구체화해보고 싶어, 조금 더 전통 RL 방법론을 적용하지만 DP Latent Space를 기반으로 한 DP -> RL policy steering 방법론을 제시한 해당 논문을 들고와보게 되었습니다.
Introduction
IL 연구 분야 히스토리
IL(모방학습), RL(강화학습)을 막론하고 Robot Learning 방법론들은 꾸준히 인상적인 파급력을 보여오고 있습니다. 저자들은 이 중 특히 전문가 데모 데이터를 기반으로 supervision을 주는 BC 컨셉 기반의 offline data-driven end-to-end IL 의 여러 예시들로 서두를 시작합니다. 2020년도부터 스멀스멀 움직임을 보이던 CNN 기반 vision/language conditioned IL 방법론부터 오늘날의 VA, VLA 들로 불리기까지 이젠 레퍼런스로 달게 너무 많죠. 꾸준히 쓰여왔던 이유는 아마 ACT나 OpenVLA 형태(autoregressive transformer)부터 DP(diffusion), π_0(flow matching) 방식들까지로 발전되어 온 경향성 속에서 simplicity, scalability, applicability 등이 큰 메리트로 작용했기 때문일 것입니다.
RL 연구 분야 히스토리
근데, 이런 IL 기법들의 가장 큰 아쉬운 점은 학습 다 끝나고 실제 deploy 시에 생겨나는 experience 데이터들을 추가로 활용하기 어렵다는 것이죠. 특히 IL 방법론들은 여전히 학습 때 보지 못한 open world 세팅의 작업에 대해 대응하기 어려워하는 모습을 보이기 때문에, 실제 deploy 시에 생기는 이 experience를 다시 활용한다면 policy를 개선하기 용이할 것입니다. 이 때 활용될 수 있는 컨셉이 RL일테지만, RL은 또 반대로 IL에 비해서 그 동안 파급력이 약해왔던 가장 큰 이유가 바로 생각보다 초기엔 학습이 비효율적이라는 것인데요. from scratch부터 RL을 학습한다는 건 IL에 비해 직접적인 supervision을 받지 못한다는 점, exploration과 exploitation의 균형을 맞춰가면서 reward를 통해 학습을 해나가야 한다는 점, 특히 대부분의 방법론들이 예로부터 MDP(Markov Desicion Process) 기반의 이상적인 상태모델링 하에서 알고리즘이 설계되었기 때문에 생각보다 현실의 모델링에 적용하기 어려운 가정을 가져서 비효율적이라는 것입니다.
물론 오늘날에는 여느 도메인을 막론하고 정말 다양한 RL 방법론들이 이런 문제점들을 타파하고, 효율적인 활용점을 찾아나가며, RL 컨셉의 잠재력을 끌어올리면서 발전의 궤도가 IL과 거의 동일선상에 점차 올랐거나 이제는 그 이상의 모먼트가 생겨나고 있다고 생각이 듭니다. 대표적인 게 DeepSeek 모먼트가 있었죠. LLM 분야에서 RLHF(RL from Human Feedback) 기반으로 대규모의 offline demo corpus에서 fine-tuning하는 용도로 좋은 효과를 보여줬습니다. 단점은 계산과 시간 측면에서 여전히 cost가 많이 든다는 점인데, 그러다보니 이를 로봇 policy 도메인에 직접 적용해보기가 지금까지는 쉽지 않았습니다. 즉 pre-trained IL Policy의 RL fine-tuning을 위한 simplicity, scalability, applicability 를 갖춘 방법론을 찾기가 어려웠던 것이죠.
저자의 빡침포인트 및 연구 철학 제안
저자들은 여기서 빡침포인트를 느낀 것 같습니다. 이를 해결하기 위해, pre-trained IL policy로부터 deploy 시 나온 experience 데이터를 활용해서 효율적으로 RL fine-tuning하고 policy steering하는 연구를 생각하게 됩니다. 현재로써는 사실상 DP에서 policy를 diffusion 기반으로 매개변수화시키는 것이 여러 연구에서 표준처럼 여겨져 활용되곤 하는데, 저자들도 이를 베이스 삼아 기존 DP + RL 과 달리, pre-trained base policy의 가중치를 건드는 대신, diffusion process에서 샘플 생성하는 데 사용되는 그 입력 noise 분포만을 변경해서 샘플링 프로세스에 조정을 주는 방식을 제안하게 됩니다. 즉 이 입력 noise에 대해 RL을 적용하면서, deploy 시에 나오는 experience 데이터들이 online으로 수집됨에 따라 policy를 더 효율적으로 빠르게 steering하는 과정을 유도하고, 이 때의 접근 방식 자체가 stable하고 sample efficiency하며, representation 또한 생각보다 정말 풍부해질 수 있다는 점을 어필합니다.
특히 핵심 철학인 것이 denoising process에서 forward pass만을 사용해서 완전히 black-box로 작용하는 방법론이기에 policy 가중치 자체를 건드리지 않아서, diffusion 과정에서의 back-propagation signal에 대한 불안정성 자체를 없애게 된다는 것입니다.
Related Work
관련 Related Work를 좀 많이 보게 되었습니다. 전반적으로 IL pre-trained DP -> RL fine-tuning 에 대한 흐름이 아래와 같이 꽤나 많이 있어왔고 계속해서 발전해 온 것으로 보입니다.
[CoRL 2024 Workshop] From Imitation to Refinement_ Residual RL for Precise Assembly
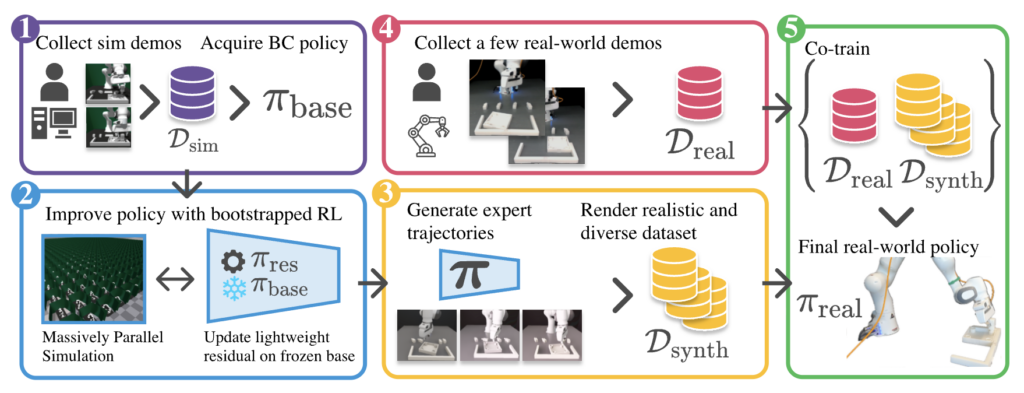
문제 정의 : Long-horizon Task같이 complex한 task를 위해 기존 DP를 10만 데모로 학습해도 성능이 80%로 saturation되더라. 그냥 매크로 수준의 trajectory planner로 밖에 기능을 못하더라.
접근 방안 : 사전학습된 DP의 long-horizon task로의 적응을 위해, sim 상에서 DP에 MLP기반 residual policy를 만들어 PPO 기반 online RL fine-tuning을 하고, sim에서 IL->RL 로 학습된 policy를 rollout해서 real에서 sim 데이터랑 co-training 추가로 진행하여 sim-to-real gap을 해소하면서 real-world 에서 성능개선을 보임.
실험환경 : FURNITURE-BENCH
[ICRL 2025] Policy Decorator: Model-Agnostic Online Refinement for Large Policy Model
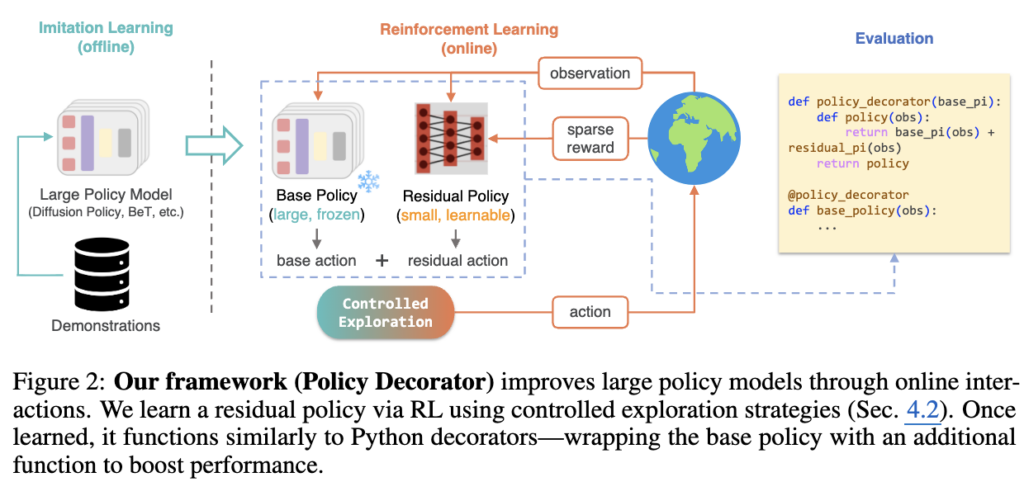
접근 방안 : MLP 기반 residual policy로부터 action 을 합산해서 SAC/PPO 등으로 online learning.
[ICLR 25′]DPPO(DP Policy Optimization)
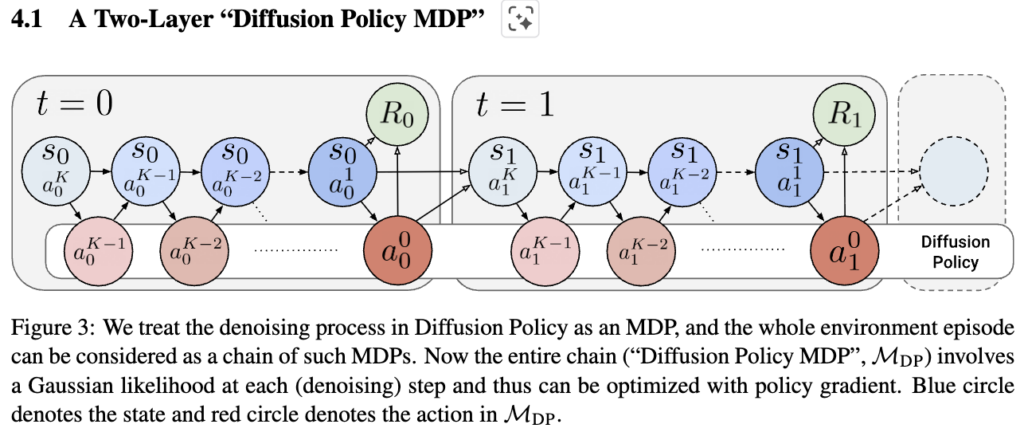
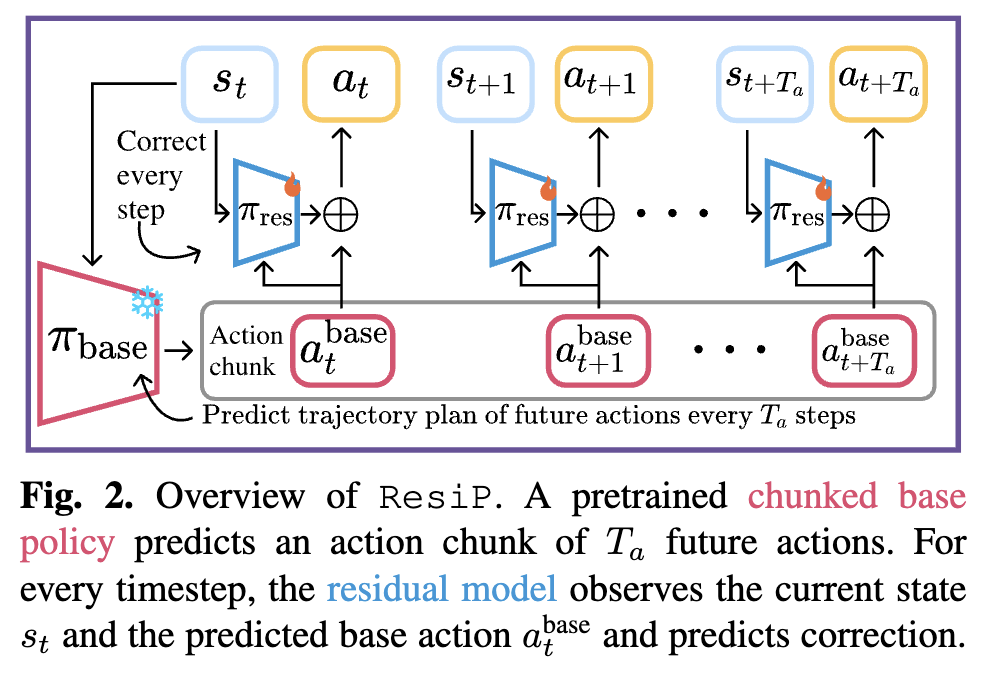
문제 정의 : 사전학습된 DP에 대한 policy gradient RL을 더 안정적이고 효율적으로 fine-tuning하게 할 수 없을까?
접근 방안 : denoising 과정을 하나의 MDP로 간주해버려서 tow-layer MDP를 구성하고, outer layer는 env와 상응하는 MDP, inner layer는 denoising MDP로 치고, PPO 기반으로 policy gradient를 optimization하는 방식 설계.
실험환경 : FURNITURE-BENCH
[ICLR 25′ WS]PA-RL(Policy Agnostic RL)
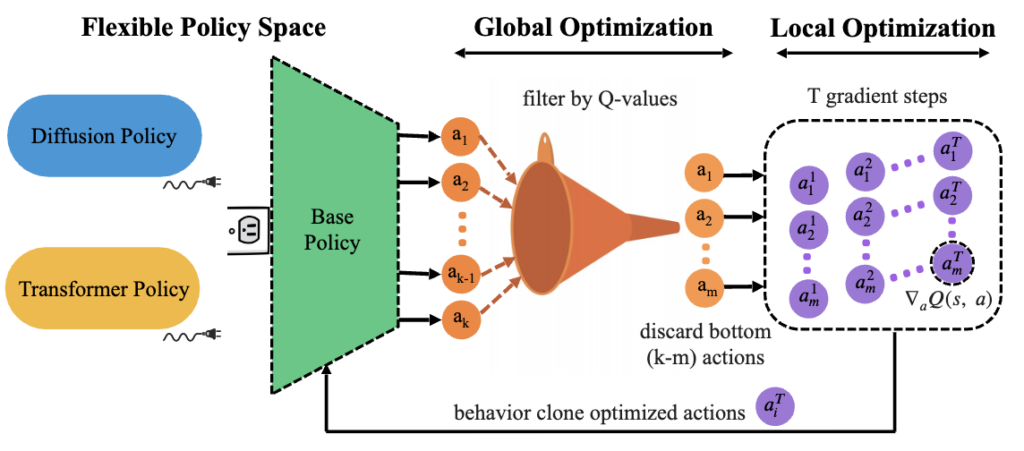
문제 정의 : 기존 Actor-Critic RL 알고리즘들이 특정 policy에 맞춰 설계되어, diffusion/autoregressive/대형 backbone 같은 다양한 policy들에 대해 안정적으로 offline/online fine-tuning 하지는 못하더라
접근 방안 : policy 자체의 파라미터로 직접 gradient 흘리지 않고, 현재 base policy에서 여러 action 샘플들만 뽑아서, Q-function으로 re-ranking(글로벌 최적화)을 하고, 그 후 action 자체에 대해 직접 gradient ascent(로컬 최적화)하면서 개선된 action을 만들고, 이를 supervision loss로 원래 policy 에 distill.
실험환경 : FrankaKitchen, CALVIN 등
[ICML 25′]FQL(Flow Q-Learning)
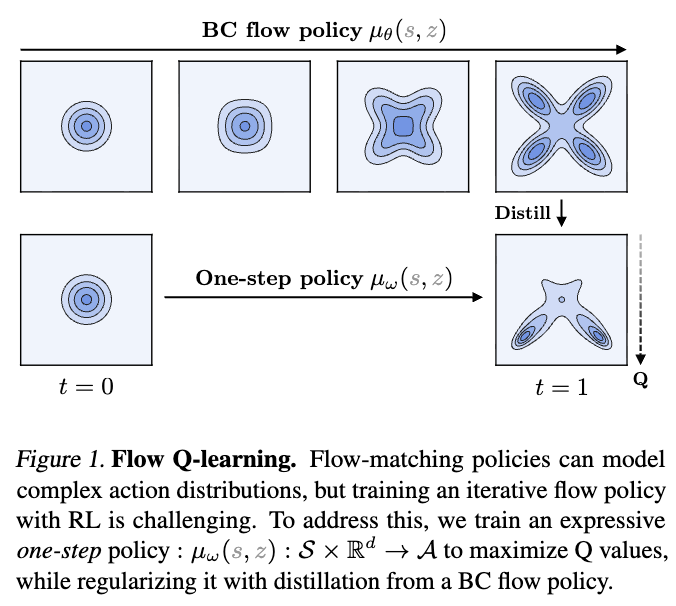
문제 정의 : 기존 Flow Matching 기반 policy에서는 iterative action generation 학습 과정에서 unstable한 recursive back-propagation을 유발하고, test time에 많은 iterative step이 필요하다는 문제점이 있었음.
preliminary : DP가 SDE(Stochastic Differential Equation; 확률 미분 방정식) 기반임에 비해 Flow policy가 ODE(Ordinary Differential Equations; 상미분 방정식) 기반이란 점에서 d차원 유클리드 공간에서의 데이터 분포 p(x)가 주어졌을 때, time-dependent velocity 벡터장을 학습하여 간단한 노이즈 분포로부터 데이터 분포로 deterministic하게 흐르게 하는 방식
접근 방식 : 사전학습된 flow policy는 flow matching만으로 학습 시그널 유지하면서, value를 최대화하기 위한 policy는 반복적인 ODE 절차를 사용하지 않는 별도의 one-step 매핑(MLP?) policy로 학습. 이 one-step policy은 flow로부터 distill되어 행동 분포의 표현력을 계승하면서도 reparameterized gradient로 안정적으로 Q-maximization을 수행.
한계? : 사전학습된 flow policy에 대한 offline RL 기법 제시는 했는데, online adaptation 시에 exploration 이 약해서 suboptimal convergence 문제가 있을 수 있음. –> 이거 해결하려고 최근 나온 논문도 있음(: [NIPS 25′] ReinFlow: Fine-tuning Flow Matching Policy with Online Reinforcement Learning)
Methods
Problem setting
기존 IL -> RL finetuning 처럼, 사전학습된 DP πdp가 주어졌다고 가정하며, 목표는 환경 M에서 특정 보상 r을 최대화하도록 그 policy를 adaptation하는 것입니다. 저자들은 π_dp의 action에 대해 명시적으로 어떠한 특성을 가지고 있다라고 가정을 하지는 않긴 했지만, 아마 제안 방식이 효과적이라면 π_dp가 “steerable” 한 특성을 가진 것이라고 가정했다고 합니다. 또한, 어떤 s ∈ S와 w ∈ W를 선택하여 π^W{dp}(s, w)를 관찰할 수 있다고 가정하되, 이외의 π^W_{dp} 내부에 대한 다른 접근은 가정하지 않는다고 합니다.
DSRL(Diffusion Steering via Reinforcement Learning)
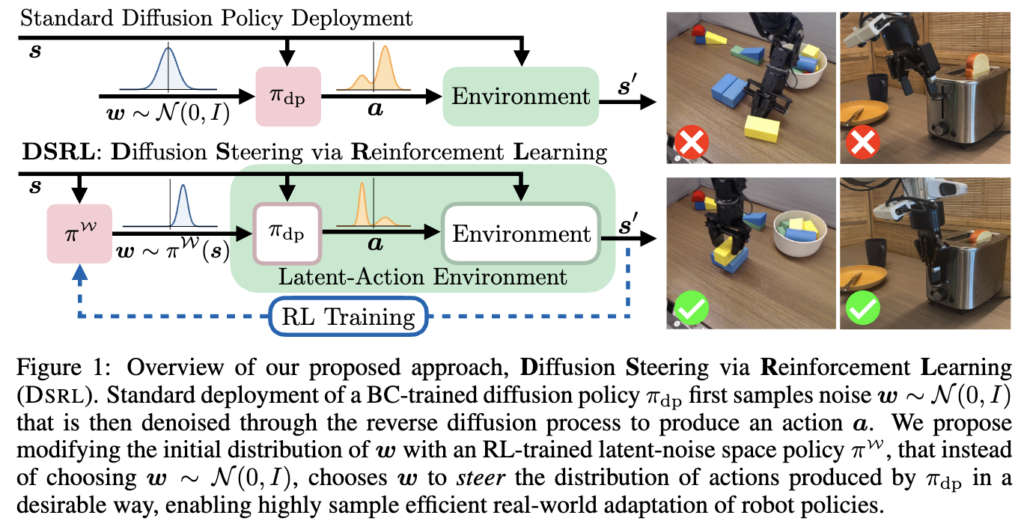
저자들의 방법론은 줄여서 DSRL(Diffusion Steering via Reinforcement Learning) 이라고 부르는데요.
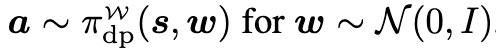
DP에서는 보통 가우시안 노이즈 w \sim \mathcal{N}(0, I) 를 입력으로 받아 action을 생성하며, 이때 생성된 action 분포는 학습 데이터의 분포와 일치하도록 학습되어 있습니다. 하지만 실제 deploy 시에는 w가 다르게 선택될 수 있고, 이 경우 생성되는 action 역시 달라져서 원래의 학습 데이터 분포를 따르지 않을 수도 있습니다. 저자들은 이 점에 착안하여, policy의 가중치를 수정하거나 출력에 후처리를 가하는 대신, 입력으로 들어가는 노이즈 w의 분포를 조절함으로써 원하는 action을 steering 하고자 했습니다.
근데 노이즈 w를 조절하면 DP 출력에 영향을 줄 수는 있겠지만, 결국 어떤 w를 선택해야되는지가 여전히 문제인데요. 이를 해결하기 위해 저자들은 DP를 단순한 policy가 아니라 latent noise w 를 실제 action으로 변환하는 함수라고 재정의합니다. 즉 상태 s에서 w를 선택하면 a=π{dp}(s,w)로 action이 결정되며, 이는 기존 action space 대신 latent noise space에서의 steering이라고 보면 될 것 같습니다.
그래서 이 관점으로 봤을 때, 아예 MDP를 latent noise space 위의 새로운 MDP로까지 재정의해버리는데요. 직접 action을 선택하는 대신 w를 선택하고, 이 w가 π{dp} 를 통해 실제 action으로 변환되어 환경에 적용되는 거로 표현합니다. 그래서 여기서의 이점으로 π_{dp}라는 base policy의 내부 동작 자체는 건들이지 않고 black-box처럼 취급해서 RL 학습이 더 용이해진다는 점이 생긴 것 같습니다.
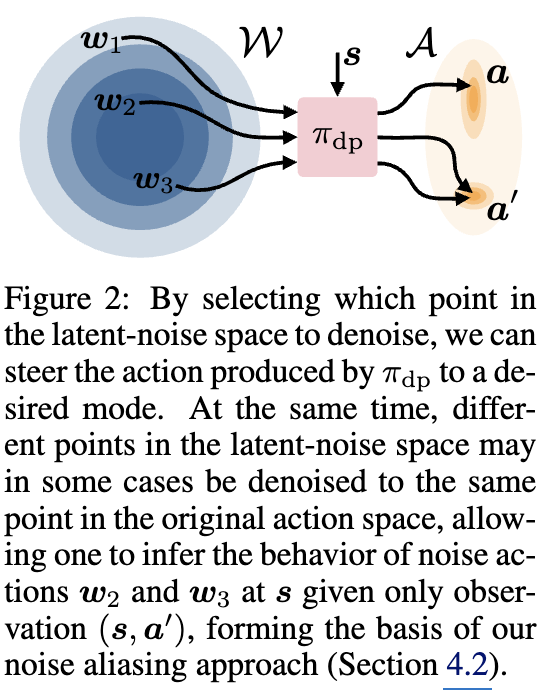
특히 일반적으로 related work에서 언급한 DP 기반 RL에서 gradient를 계산하려면 multi-step denoising 전체를 거쳐 backpropagation을 해야 해서 계산량이 크고 불안정합니다. 하지만 DSRL은 이 과정을 피하고, diffusion policy를 고정된 black-box로 두고 forward만 사용할 수 있게 됩니다. 즉, w를 입력으로 넣어 action을 얻는 과정만 활용하고, 어떤 w를 선택할지를 RL로 학습합니다. 이로 인해 계산 효율이 크게 좋아지고, 모델 내부 파라미터에 접근하지 않아도 되므로 API 기반 모델에도 적용 가능하게 됩니다.

일반 actor-critic은 latent noise 공간 \mathcal{W}에서 학습하기 어렵고, 특히 offline 데이터는 action space \mathcal{A}에만 있기 때문에 바로 쓰기 어렵습니다. 그래서 저자들은 이를 해결하기 위해 DSRL-NA는 두 개의 critic을 둡니다.
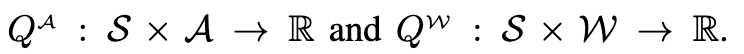
Q^A 는 실제 action 공간에서 value 학습 (offline 데이터 활용), Q^W는 latent noise 공간에서의 value 학습을 수행합니다. 그러고나서의 알고리즘 해심은 w 를 a = π_{dp}(s,w) 로 변환해서 Q^A의 값을 Q^W 로 distillation 하는 것입니다.
Experiments
실험에선 DSRL을 정말 다양한 기준으로 실험을 진행합니다.
온라인 RL, 오프라인 RL, 오프라인→온라인 전이, 그리고 시뮬레이션 환경과 실제 로봇 환경 모두 실험하는데요.
또한 DSRL-NA와 SAC 기반 변형(DSRL-SAC) 을 비교하기도 합니다.
1. DSRL on sim — DP in online RL
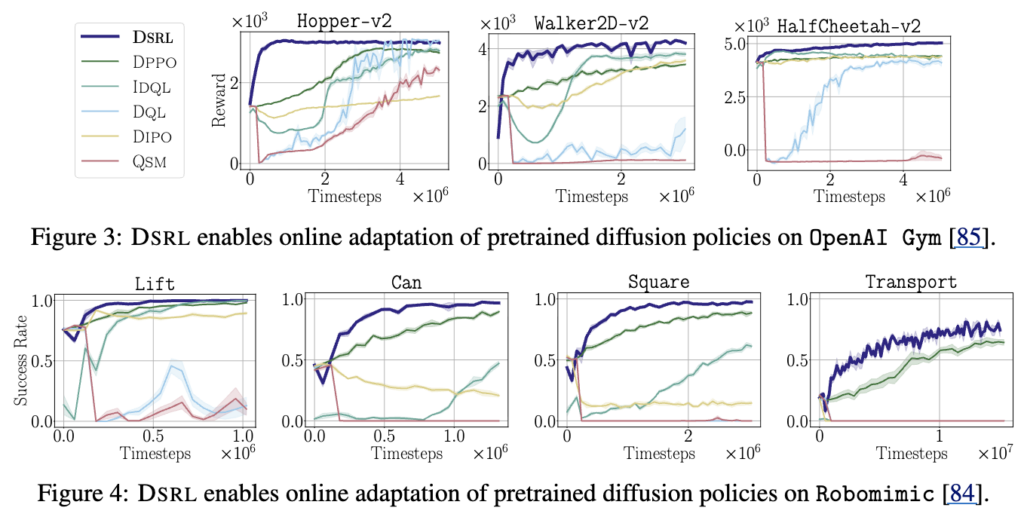
이 실험은 이미 데모로 pretrain된 DP를 다시 학습시키는 게 아니라, 그걸 그대로 두고 online RL로 얼마나 빠르고 효율적으로 adapt할 수 있는지를 보여줍니다. 기존 방식들은 policy 자체를 직접 업데이트하거나 scratch에 가깝게 다시 학습하는 반면, DSRL은 policy는 frozen하고 latent noise만 조절해서 behavior를 바꾸는 구조를 가지기에, 결국 학습 대상이 “action”이 아니라 “noise 선택”으로 바뀌게 되는데요.
그래서 결과적으로 위 figure에서와 같이, DSRL은 같은 task에서 훨씬 적은 sample로 빠르게 수렴하는 모습을 보입니다. Gym이나 Robomimic sim환경 전반에서 거의 near-optimal performance까지 올라가면서도 sample efficiency가 크게 개선되는 모습을 보입니다. 정리하면, DP 자체 즉 base policy는 최대한 건드리지 않고 noise를 latent space상에서 control 하는 것만으로도 충분히 강하게 policy adaptation이 된다는 걸 실험으로 보여준 것 같습니다.
2. DSRL on sim —> DP in offline RL
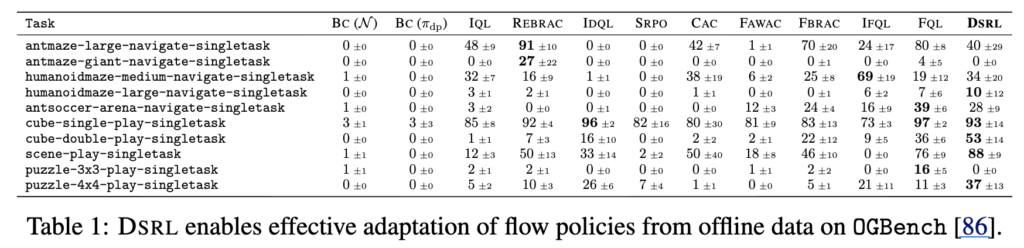
위 table 1은 offline setting에서 DSRL-NA가 얼마나 잘 동작하는지를 보여줍니다. 구조는 동일하게 먼저 offline 데이터로 DP를 학습한 뒤 이를 freeze하고, 같은 offline 데이터 위에서 DSRL-NA를 적용합니다. 다양한 offline RL baseline들과 비교했을 때, 여러 task에서 높은 성능을 보이고, 특히 기존 diffusion policy의 성능보다 유의미하게 개선되는 모습을 보입니다. 또한 online 실험에서 사용한 동일한 DSRL-NA 구조를 별도 수정 없이 그대로 offline에도 적용할 수 있다는 점을 저자들은 강조하네요.
3. DSRL on sim — in offfline-to-online
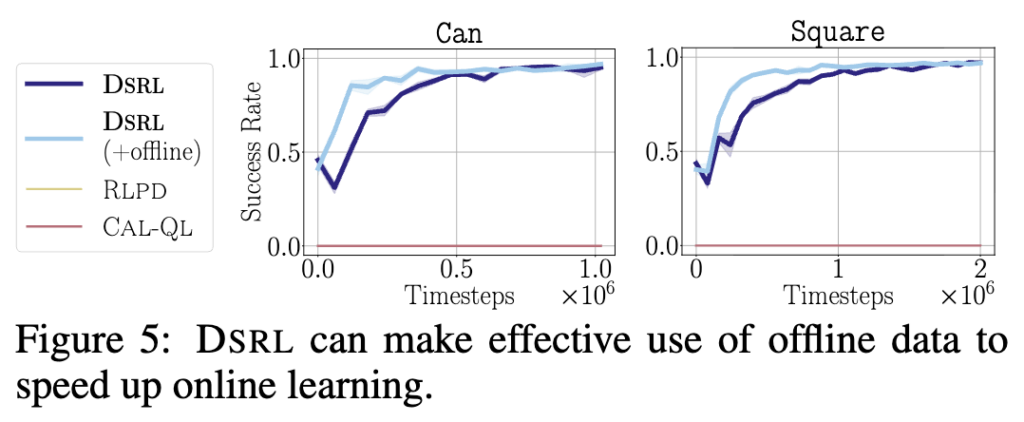
여기서는 offline→online setting에서 DSRL이 얼마나 잘 이어서 학습되는지를 보여줍니다. 즉, offline 데이터로 시작해서 online interaction으로 이어질 때 실제로 도움이 되는지를 확인하는 실험인데, 구성은 간단합니다. Robomimic task에서 offline 데이터로 초기화하고, 이후 online RL을 수행하면서 DSRL을 적용한다고 합니다. baseline으로는 RLPD, CAL-QL 같은 standard offline-to-online 방법들과 비교했습니다.
결과는 offline 데이터를 같이 쓰면 sample efficiency가 대략 2배 정도 개선되고, online 학습이 훨씬 빠르게 진행되는 결과를 보였습니다. 반면 기존 offline-to-online 방법들은 이 task들에서 거의 학습이 되지 않는 처참한 모습을 보였는데요. DSRL은 offline 정보를 실제로 잘 활용해서 online 학습까지 가속시키는 구조라는 걸 보여주는 실험인 것 같습니다.
4. Real-world robotic control settings


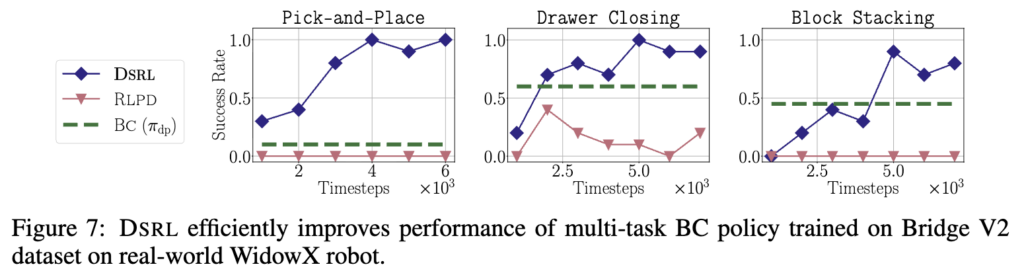
여기서는 DSRL이 실제 로봇 환경에서도 통하는지를 보여줍니다. 단일 task DP와 multi-task DP 두 경우 모두에서, pretrain된 policy를 그대로 두고 online RL로 adaptation을 진행했는데요. Table 2에 해당하는 single-task에서는 소수의 human demo로 학습된 policy를 기반으로 pick-and-place를 수행하는데, DSRL은 성공률을 약 20% 수준에서 거의 100%까지 빠르게 끌어올리는 모습을 보입니다. 반면 RLPD 방식은 학습이 거의 되지 않고, human intervention을 추가해도 task를 아예 해결하지 못하는 모습(..?)을 보입니다.(왜 그런지는 RLPD를 봐야 알 것 같습니다..)
Figure 7의 multi-task에서도 동일한 흐름인데, Bridge V2로 pretrain된 policy를 실제 환경에 적용하면 초기 성능이 부족한데, DSRL을 적용하면 적은 online step만으로 각 task에서 성능이 크게 개선되는 모습을 보입니다. 반면 RLPD는 여기서도 제대로 학습되지 않네요.
5. DSRL enables steering of generalist robot policies, in both sim and real
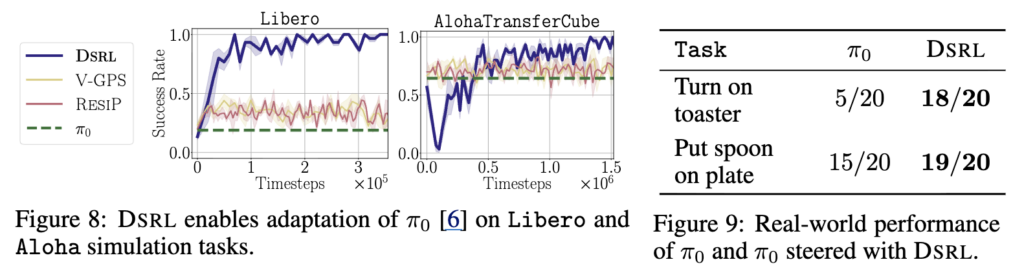
여기서는 더 큰 스케일의 generalist policy, 즉 π₀ 같은 모델에도 DSRL이 먹히는지를 보여줍니다. π₀는 DP보다 꽤나 큰 모델 파라미터, 큰 action space 를 가져서 일반적인 RL로 직접 finetuning하기 어려운 설정인데, 여기서도 먹히는 지를 본 것이죠.
앞선 실험과 같이 policy는 그대로 두고, latent noise 위에서 DSRL을 돌려서 steering하는데요. 그 결과 Figure 8에 보이는 것처럼 simulation benchmark에서는 Libero나 Aloha 같은 task에서 성능이 크게 개선되고, 특히 Libero에서는 약 20% 수준에서 거의 100%까지 올라가는 반면 ResiP나 V-GPS 같은 기존 baseline 방법론은 성능 개선이 거의 없는 모습을 보여줬습니다.
Figure 9의 real-world 실험에서도 동일한 흐름인데, toaster 켜기나 spoon 집기 같은 task에서, base policy π₀ 자체는 낮은 성공률을 보이지만, DSRL을 적용하면 성공률이 크게 상승하는 모습을 보여줍니다.
즉 DSRL이 DP같이 작은 policy뿐 아니라, 좀 더 큰 VLA등에도 그대로 적용 가능하고, 직접 finetuning이 어려운 상황에서도 효과적으로 성능을 끌어올릴 수 있다는 점을 보여주는, scalability에 적응적인 러닝방법론이라는 꽤나 의미있는 결과를 보인 실험 같습니다.
6. design decisions critical to DSRL
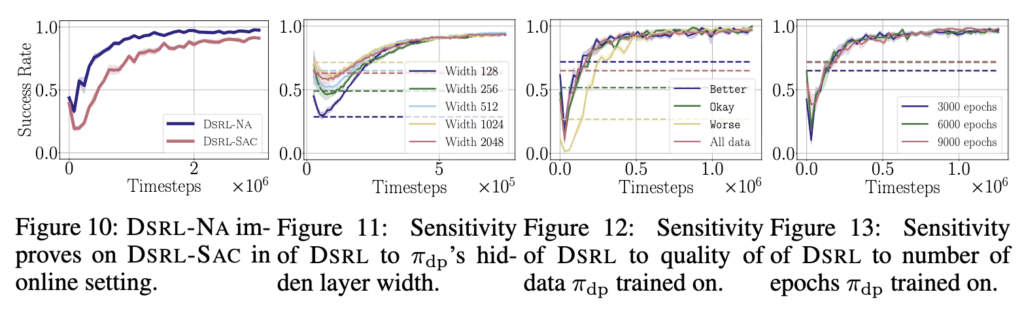
여기서는 DSRL에서 뭐가 실제로 중요한지 ablation처럼 여러가지를 실험해보는데요.
먼저 noise aliasing의 효과를 보면, DSRL-NA가 DSRL-SAC보다 같은 online setting에서도 약 2배 정도 더 적은 샘플로 학습되는데, 즉, aliasing 구조가 sample efficiency에 직접적으로 기여한다는 걸 보여줍니다.
다음으로 base policy인 π_dp의 hidden layer width 영향을 보면, 모델 크기를 바꿔도 모두 잘 steer되긴 하지만, 큰 모델이 더 빠르게 적응하는 경향을 보입니다.
다음. 데이터 quality의 경우, π_dp 성능은 크게 영향을 받지만 DSRL은 상대적으로 robust해서, 초기 성능이 낮아도 빠르게 회복하는 경향을 보이구요.
마지막으로 학습 epoch 수를 늘려서 overfitting된 π_dp도 테스트하는데, π_dp 자체 성능에는 영향이 있어도 DSRL 성능에는 거의 영향이 없는 듯한 경향성을 보입니다.
정리하면, 저자들이 제안한 DSRL에서의 noise aliasing은 핵심 요소고, DSRL은 base policy의 크기나 데이터 quality, 심지어 overfitting 여부에도 꽤나 강건하게 작동한다는 걸 보여주는 것 같습니다.
안녕하세요 재찬님 좋은 리뷰 감사합니다.
혹시 IL과 RL finetuning 과정에서 사용되는 데이터 구성에 대해 조금 더 설명해주실 수 있을까요?
감사합니다
안녕하세요 유진님, 좋은 질문 감사합니다.
IL은 로봇도메인 연구의 일반적인 VA/VLA에서의 teleoperation 시연 데이터셋 D(이미지·proprioceptive 등 관측 s와 로봇 액션 trajectory a 쌍 (보통 EEF이나 특별한 경우 joint space)) 이고, RL finetuning은 기본적으로 환경과의 transition(s,a,r,s’) 결과를 리플레이 버퍼 B에 모아 TD 기반의 critic Q_A를 학습하고, 본 논문이 말하는 DSRL의 경우 이 Q_A critic으로부터 latent-noise 공간 W의 critic Q_W를 distill하여 latent policy a=π_W^dp(s,w)를 업데이트하는 형태를 가지게 됩니다.
안녕하세요 재찬님! 좋은 논문 리뷰 감사합니다!
읽으면서 궁금한 점이 있어 댓글 남깁니다.
기존의 DP는 DDPM 방식을 사용하여 denosing 과정을 통해 action distirbution의 gradient를 학습하여 현재 state에 대한 적합한 action의 분포를 학습하는 방식으로 알고있습니다. 노이즈에 따라 action이 달라질 수 있겠지만 이를 steering하여 사용하면 DP의 장점인 mutimodality가 사라지는 것은 아닌가? 생각이 드네요. 제가 잘못 이해한 것일 수도 있으니 조금 설명 부탁드리겠습니다!
안녕하세요 인하님, 좋은 질문 감사합니다.
제가 이해한대로 말씀드리자면, 결론은 아닙니다. 본 논문인 DSRL은 인하님이 말씀하신 그 부분을 딱 회피하고 base DP의 denoising 스텝에 대한 gradient를 안 건들이면서 원래 학습분포를 최대한 유지한 채 w에 대한 샘플링 분포를 편향시켜서 steering하는 것 뿐일 겁니다.
multimodality는 본질적으로 DP의 여러 서로 다른 ω 샘플링에서 서로 다른 가능한 액션 모달리티로 매핑될 수 있음에서 오게 된다고 생각하는데, DSRL에서는 그 중 어떤 ω를 steering해서 선택하게 만들지를 RL로 더 학습할 뿐이며, base policy인 DP 자체의 매핑인 ω↦a 자체를 바꾸지 않는 게 이 논문의 핵심 contribution인 것으로 이해해주시면 됩니다. 따라서 이미 학습된 base policy에 대해 steering 용 latent policy π_W(w∣s)만을 확률적으로(또는 혼합해서) 유지시킬 수 있다면 multimodality 자체는 보존된다고 봅니다.