오늘은 LMM(대형 멀티모달 모델)이 단순히 정지된 사진을 넘어서, ‘비디오’라는 연속적인 데이터를 얼마나 잘 이해하는지 평가하는 최초의 종합 벤치마크(Video-MME)에 대한 논문을 가져왔습니다. MLLM을 Video에 적용하는 부분에 있어 분석을 제시한 논문들에 대해 살펴보다 해당 논문을 보게 되었네요.
CVPR 2025 에 게재된 논문임에도, 그 짧은 기간동안 벌써 인용수가 1K 가 넘어가는 것만으로 해당 연구가 얼마나 유의미한지 이해하실 수 있을 것 같습니다. 바로 리뷰 시작하겠습니다.
- Venue: CVPR 2025
- Authors: Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, Ran He, Xing Sun
- Affiliation: Nanjing University, etc.
- Title: [CVPR 2025] Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
- Code: GitHub, Project Page
1. Introduction
최근 MLLM은 다양한 멀티모달 벤치마크에서 강한 성능을 보이고 있지만, 그 중심에는 MLLM은 여전히 정적인 이미지 (Static image) 이해에만 집중하고 있다는 점이 있습니다. 그러나 실제 환경에서는 장면이 시간에 따라 변화하고, 여러 단서가 순차적으로 제시되는 비디오 이해가 더 중요할 수 있는데, 이 부분은 아직 충분히 평가되지 못하고 있었죠. 특히 기존 video benchmark들은 영상 종류의 다양성, temporal dynamics에 대한 충분한 커버리지, 그리고 subtitle/audio와 같은 modality 측면에서 한계를 가지고 있었습니다.
따라서 본 논문에서는 이러한 문제를 해결하고자, MLLM의 비디오 분석 능력을 다양하게 평가할 수 있는 최초의 종합 벤치마크인 Video-MME (Multi-Modal Evaluation benchmark crafted for MLLMs in Video analysis) 를 제안하였습니다.
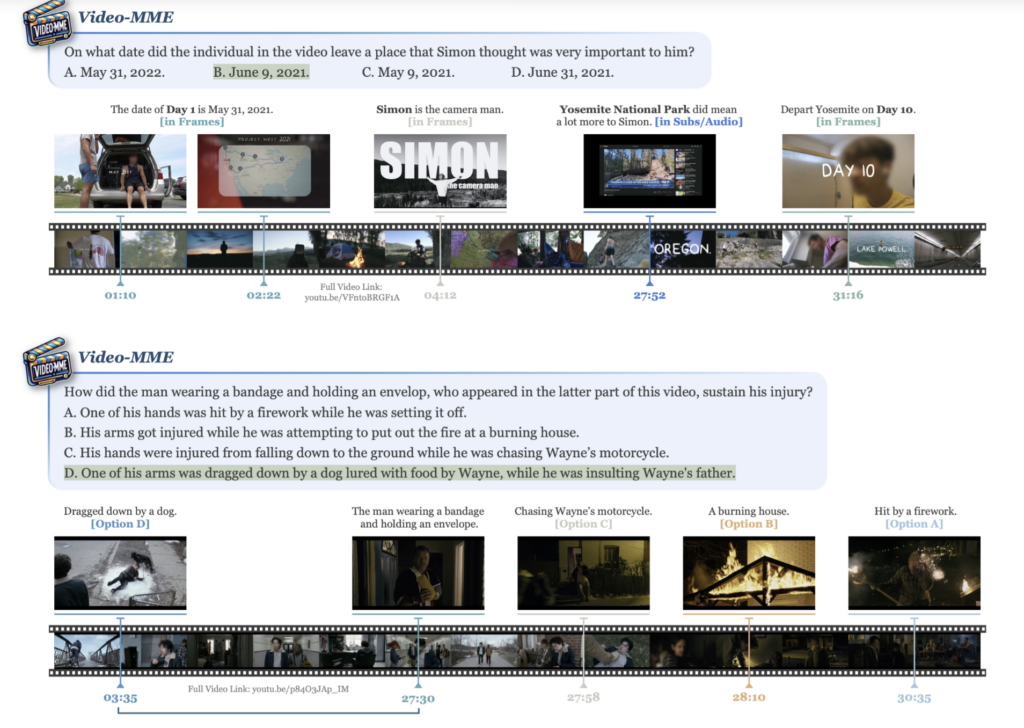
상단 그림은 본 논문의 벤치마크인 Video-MME의 예시인데요.
(1) 첫 번째 예시는 frame 정보와 subtitle/audio 정보를 함께 봐야 하고, 그것들을 연결해서 날짜를 계산해야 정답을 맞힐 수 있습니다. (2) 두 번째 예시는 질문에 필요한 단서가 영상의 뒤쪽에 있고, 선택지에 해당하는 장면들은 영상 여러 구간에 흩어져 있어 전체 맥락을 따라가야 합니다.
따라서 저자가 제안하는 새로운 벤치마크 Video-MME는 단순 장면 인식이 아니라 긴 맥락 이해, multi-modal 활용, 그리고 temporal reasoning까지 함께 요구한다는 점에서 차이가 있다고 합니다. 이제 본격적으로 어떤 데이터로 구성되어 있는지 알아보겠습니다.
2. Video-MME
Video-MME는 단순히 비디오를 많이 모아둔 벤치마크가 아니라, 비디오 이해에서 중요한 요소들을 함께 평가할 수 있도록 설계된 데이터셋입니다. 그 평가 요소로는 크게 다음과 같은 네 가지가 있습니다: ① 다양성 (Diversity) ② 영상 길이 (Duration) ③ 멀티모달 입력 (Modality) ④ 데이터 품질 (Quality).
이런 측면에서 기존 benchmark보다 더 종합적인 평가를 수행할 수 있었는데요. 이러한 차이는 아래 Table 1에서 기존 benchmark와 비교했을 때 더욱 명확하게 확인할 수 있습니다.
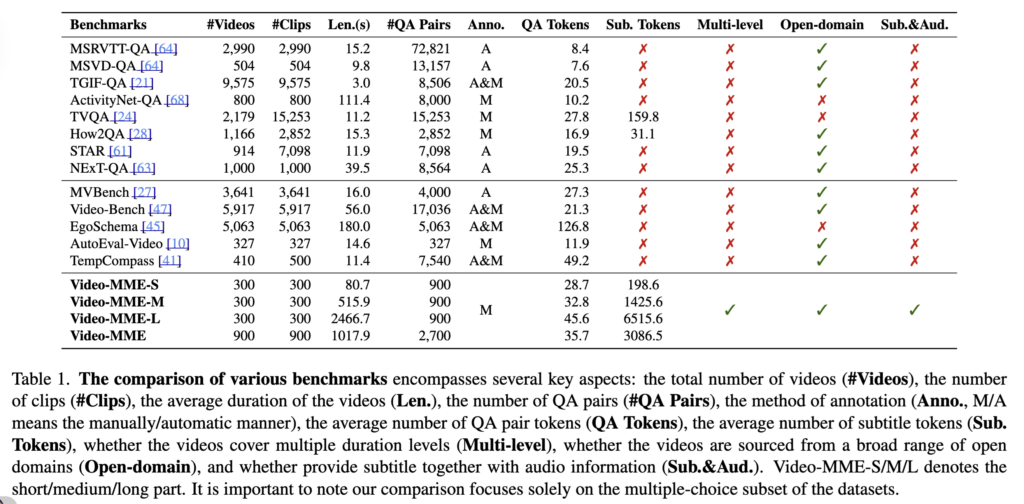
Video-MME 데이터셋 구성
– 총 900개 비디오
– 총 2,700개 객관식 QA pair
– 6개 주요 도메인, 30개 세부 카테고리
– 영상 길이를 short / medium / long 으로 구분
– subtitle과 audio도 함께 제공 (다양한 모달리티 활용 가능)
① 다양성 (Diversity)
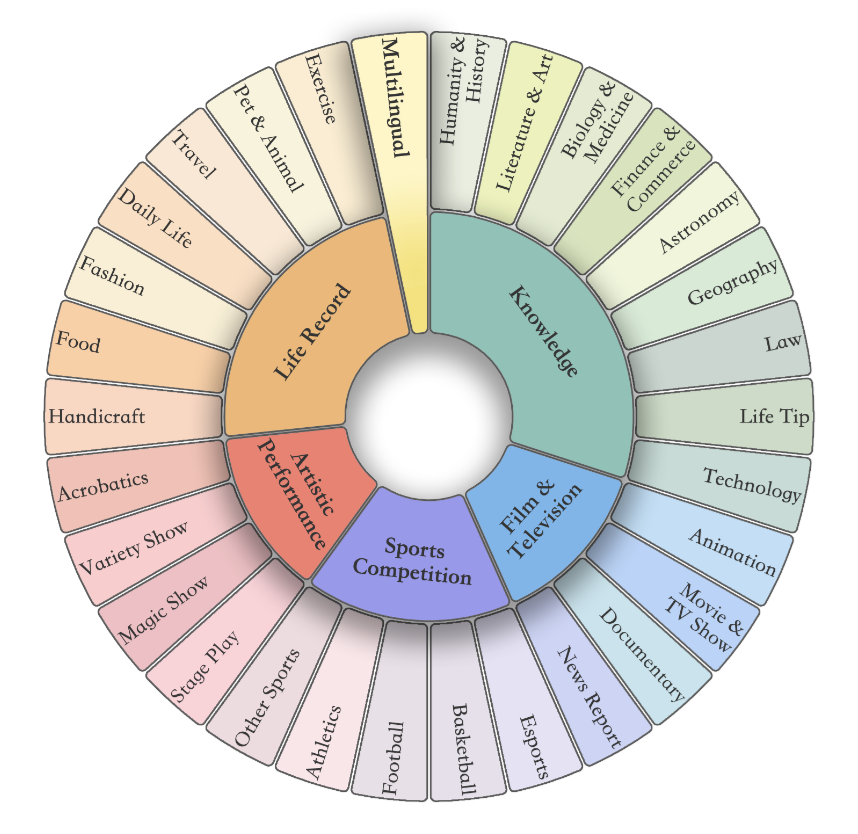
상단 그림(그림 2 왼쪽) 을 보면, Video-MME가 어떤 영상들로 구성되어 있는지를 보여줍니다.
지식(Knowledge), 영화/TV(Film & Television), 스포츠(Sports Competition), 예술(Artistic Performance), 일상(Life Record), 다국어(Multilingual) 등 6개 주요 도메인과 30개 세부 카테고리를 아우르는 비디오를 포함하여, 특정 장르에 치우치지 않고 다양한 실제 비디오를 폭넓게 다루고 있습니다.
참고로 기존에 사용되던 대표적인 비디오셋은 다음과 같은 예시가 있습니다. Kinetics, ActivityNet, UCF101 는 사람의 특정 ‘행동’ 위주로, HowTo100M 은 요리하는 법, 기계 수리하는 법 등 설명(Instructional) 중심의 영상들로 구성됩니다. 이러한 데이터셋으로는 모델이 특정 장르에만 과적합되어 ‘범용적인 영상 이해 능력’을 갖췄는지 평가하기 어렵죠.
② 영상 길이 (Duration)
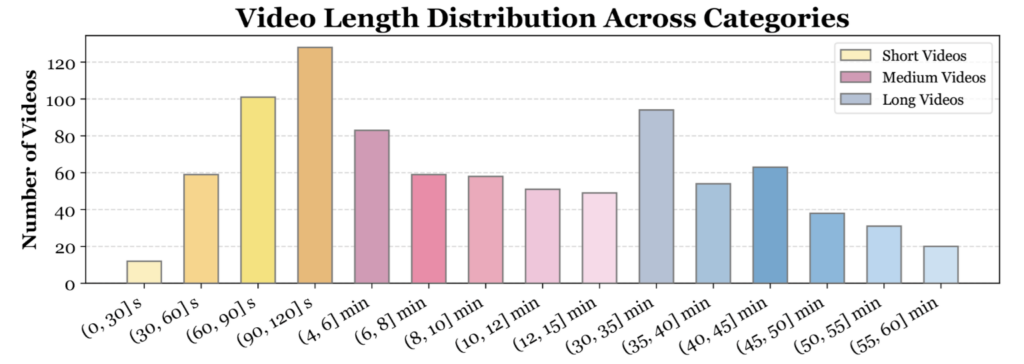
이번 그림 (그림2 오른쪽 상단) 은 Video-MME의 영상 길이 분포를 보여줍니다. short는 2분 미만, medium은 4분에서 15분, long은 30분에서 60분으로 구성되는데, 이를 통해 짧은 clip뿐 아니라 긴 시간축을 따라 맥락을 이해해야 하는 상황까지 함께 평가하려는 의도를 확인할 수 있습니다.
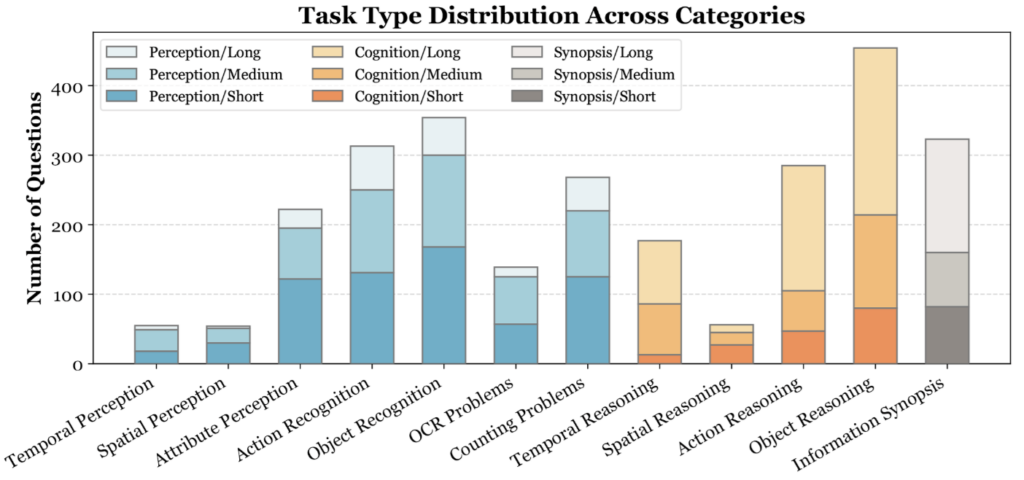
상단 그림 (그림2 오른쪽 하단) 은 질문 유형 분포를 의미합니다. 짧은 영상에서는 perception 비중이 높지만, 영상이 길어질수록 reasoning 비중이 커진다고 합니다. 즉, Video-MME 에서는 단순히 길이만 늘린 것이 아니라, 긴 영상을 볼수록 더 복잡한 추론을 요구하도록 설계되었다는 점이 중요할 것 같네요
③ 멀티모달 입력 (Modality)
Video-MME의 또 다른 특징은 단순히 비디오 프레임만 제공하는 것이 아니라, subtitle과 audio 정보도 함께 제공한다는 점입니다.
< modality of Video-MME >
– 총 900개 비디오에 대해 audio 제공
– 이 중 744개 비디오에는 subtitle 포함
– frame-only가 아니라 text/audio까지 함께 활용 가능한 구조
– 실제 비디오 이해에 가까운 multi-modal benchmark로 설계
이 부분이 중요한 이유는 실제 비디오 이해가 프레임만으로 해결되지 않는 경우가 많기 때문입니다. 예를 들어 누가 무엇을 말했는지, 특정 장소나 사건의 이름이 무엇인지, 혹은 장면만 봐서는 알기 어려운 맥락 정보는 subtitle이나 audio가 있어야 더 정확히 파악할 수 있었죠
④ 데이터 품질 (Quality)
마지막으로 저자들은 Video-MME의 데이터 품질도 꽤 신경 썼다고 합니다. 각 annotator (사람) 는 비디오 전체를 충분히 시청한 뒤, 비디오 내용에 기반한 3개의 객관식 문제와 4개의 선택지를 작성하였다고 합니다. 이렇게 해서 최종적으로 총 2,700개의 QA pair를 만들었습니다.
< Data Quality of Video-MME>
– 각 annotator가 비디오 전체를 시청한 뒤 문제 작성
– 비디오당 3개의 객관식 QA 구성
– 이후 다른 annotator가 재검수 수행
– text-only로도 풀리는 문제는 제거하여 비디오 의존성 확보
또한 저자들은 질문이 정말 비디오를 봐야만 풀 수 있는지를 보장하기 위해, 질문 텍스트만 Gemini 1.5 Pro에 입력해 정답을 맞힐 수 있는 경우를 걸러냈습니다. 즉, 상식이나 문장만 보고도 풀 수 있는 문제는 제외하고, 실제 비디오 내용이 핵심 단서가 되는 문제만 남기려고 한 것이죠. 이 text-only 설정에서 Gemini 1.5 Pro의 정확도는 15% 미만이었다고 하며, 이를 통해 Video-MME가 텍스트 편향이 적고 실제 비디오 이해를 요구하는 benchmark임을 보여주고 있습니다.
(+) Certificate Length Analysis
아무리 1시간짜리 영상이라도 단 5초의 장면만 보고 정답을 맞힐 수 있다면, 그건 진정한 롱폼 이해 능력을 평가한다고 볼 수 없습니다. 그래서 저자들은 Certificate Length(필수 단서 구간 길이)라는 개념을 도입했습니다. 이는 문제를 풀기 위해 영상 내에서 반드시 시청하고 맥락을 연결해야 하는 구간들의 시간 총합을 의미합니다.
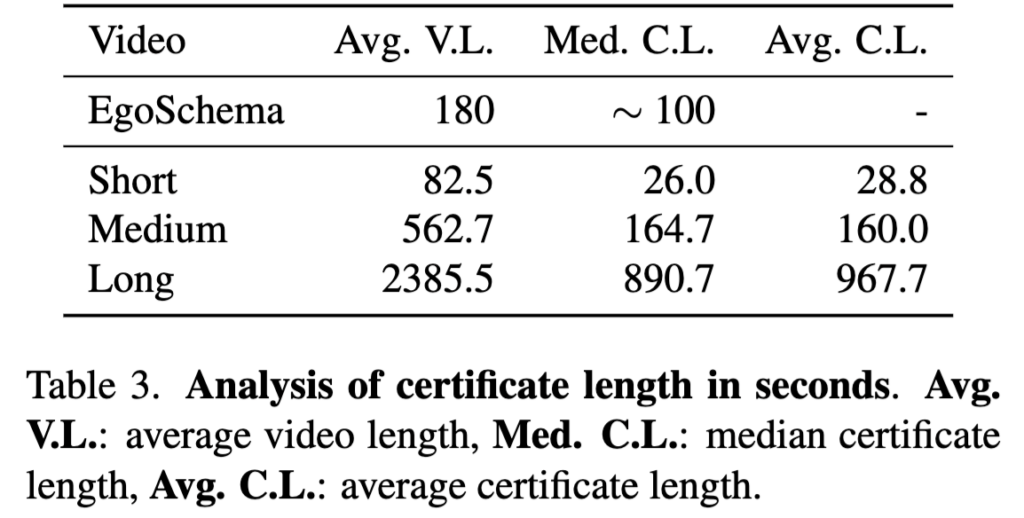
저자들이 직접 샘플링하여 분석한 결과 , Video-MME의 긴 영상(Long) 서브셋은 문제를 풀기 위해 평균적으로 약 890.7초(약 15분) 분량의 단서를 소화해야 했습니다. 이는 기존에 긴 영상 벤치마크로 가장 유명했던 EgoSchema(약 100초 요구)보다 무려 8~9배나 더 긴 맥락 이해를 요구하는 수준이라고 합니다. 즉, 이 벤치마크는 이름만 롱 비디오가 아니라, 모델이 영상의 앞뒤 맥락을 오랫동안 기억하고 종합해야만 살아남을 수 있는 데이터셋임을 보여주는 게 아닐까요
3. Experiments
그렇다면 이렇게 정교하게 만든 Video-MME 벤치마크로 최신 AI 모델들을 테스트해 본 결과는 어땠을까요? 저자들은 최신 상용 모델들과 다양한 오픈소스 모델들을 평가하여 다음과 같은 4가지 흥미로운 사실을 발견했다고 합니다.
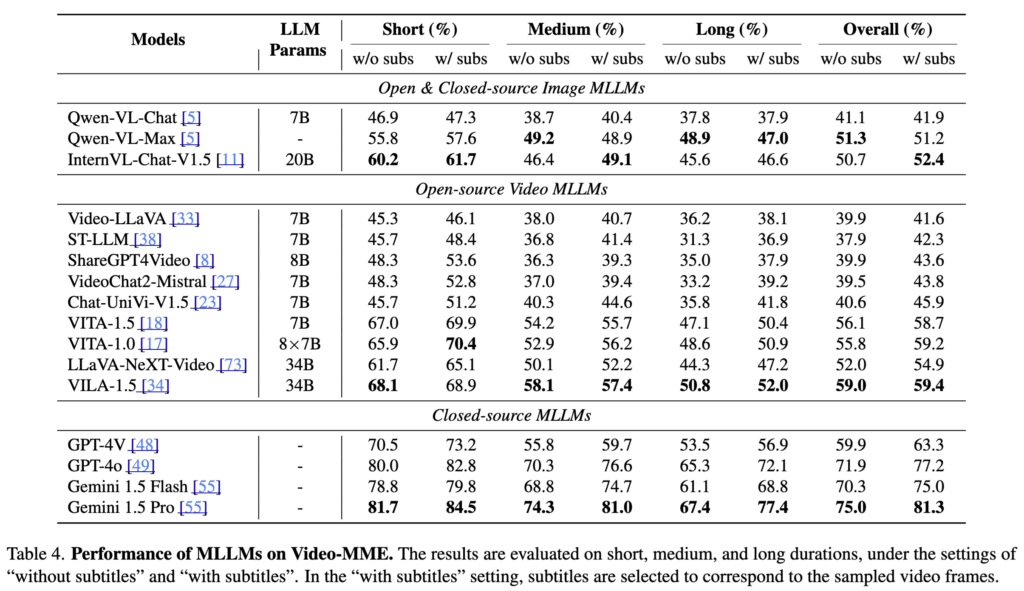
우선 Table 4는 Video-MME 벤치마크를 활용해 다양한 MLLM(상용 및 오픈소스)을 영상 길이별, 자막 유무별로 평가한 결과입니다.
① 상용 모델의 강세와 오픈소스 모델의 한계
평가 결과, 상용 모델인 Gemini 1.5 Pro가 전체 평균 75%의 정확도를 달성하며 압도적인 1위의 성능을 보였습니다. 그 뒤를 GPT-4o가 71.9%로 뒤에 랭킹하였죠. 반면, 오픈소스 진영에서 가장 성능이 뛰어나다고 평가받는 VILA-1.5(34B) 모델은 전체 정확도 59%를 기록하는 데 그쳤습니다. 이는 아직 상용 모델과 오픈소스 커뮤니티 간에 영상 이해 능력에 있어 상당한 성능 격차가 존재함을 보여준다고 합니다.
그렇다면 상용 모델은 모든 영역에서 완벽할까요? 이를 위해 저자들은 기존 모델들의 세부 태스크(인지 vs 추론 등 12개 유형) 결과를 확인해보았습니다
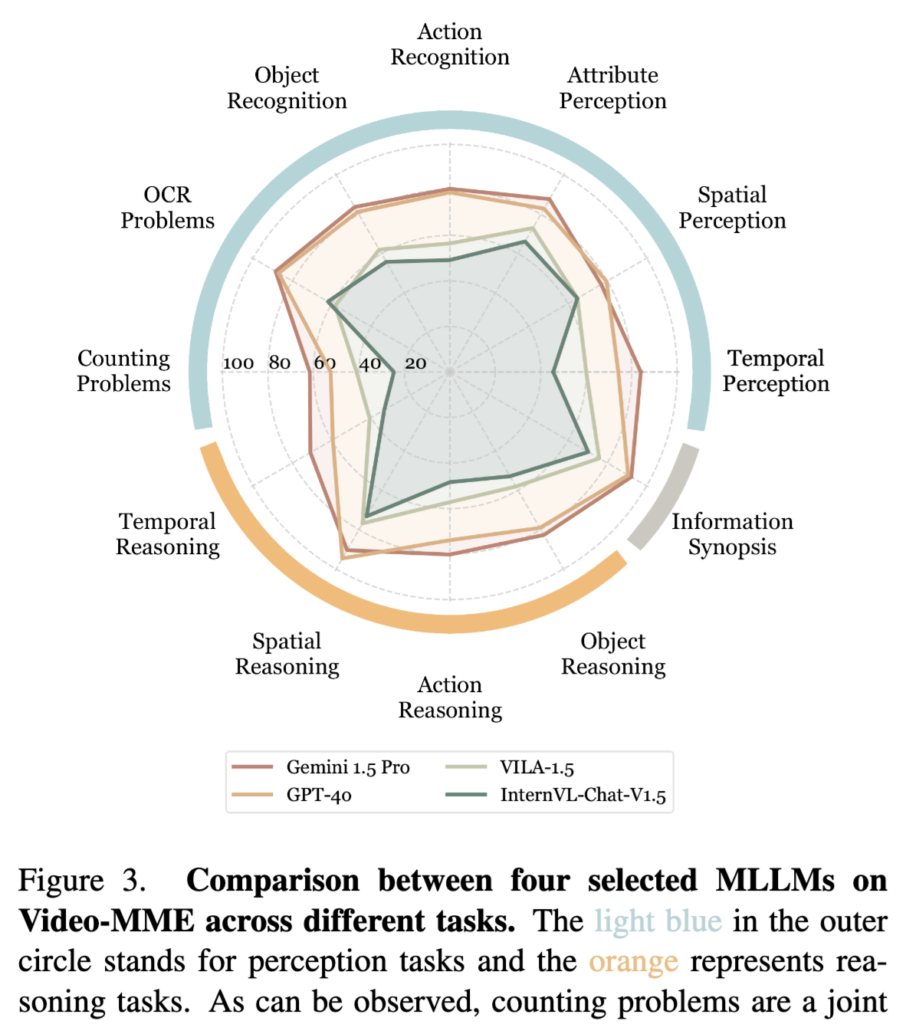
상단 Figure 3은 Gemini 1.5 Pro, GPT-4o, VILA-1.5 등 주요 모델들의 세부 태스크별 능력을 보여주는 차트인데요.
차트를 보면 모델을 불문하고 안쪽으로 푹 파인 구간들이 있습니다. 특히 비디오 안에서 특정 사건이나 객체의 수를 세는 ‘Counting Problems (개수 세기)’ 태스크는 현재 모든 멀티모달 모델들이 겪고 있는 공통적인 치명적 한계(Bottleneck)임을 확인할 수 있었다고 합니다. 또한, Action Recognition (행동 인식)이나 Temporal Perception (시간적 인지)에서도 1등인 Gemini조차 상대적으로 고전하고 있다고 하네요.
② 이미지 모델의 비디오 처리 능력
다시 위에있는 테이블 4로 돌아가봅시다. 재밌는 부분이 하나 있는데, 비디오 전용으로 학습되지 않은 강력한 ‘이미지 MLLM’들의 성능이었습니다. Qwen-VL-Max나 InternVL-Chat-V1.5 같은 이미지 모델에 여러 장의 프레임을 입력해 평가한 결과, 약 50% 수준의 정확도를 보였습니다. 이는 비디오 특화 모델인 LLaVA-NeXT-Video와 거의 유사한 수준입니다. 즉, 이미지 이해 능력이 곧 비디오 이해의 기반이 된다는 사실을 보여주는 결과라고 합니다.
③ 멀티모달(자막 및 오디오)의 시너지
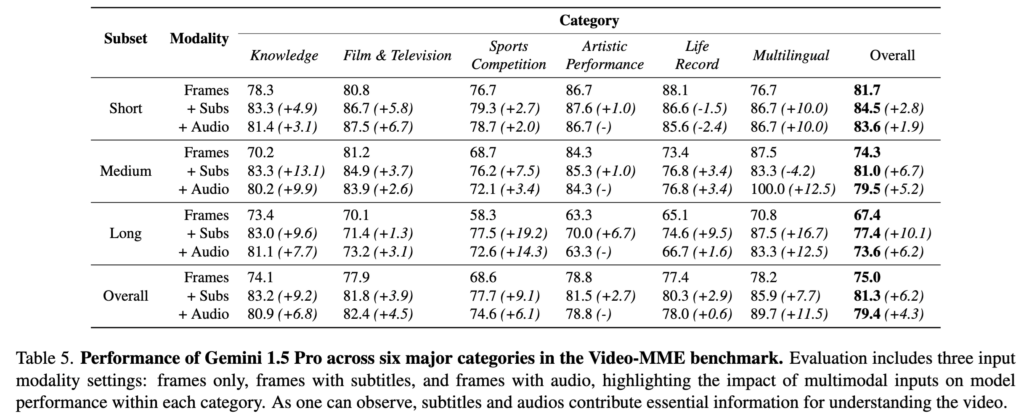
Table 5는 최고 성능을 낸 Gemini 1.5 Pro 모델을 대상으로, 단순히 프레임만 주었을 때(Frames)와 자막(+Subs), 오디오(+Audio)를 각각 추가했을 때 카테고리별/길이별 성능이 어떻게 변하는지 분석한 표입니다.
앞서 Video-MME의 특징으로 자막과 오디오가 함께 제공된다는 점을 꼽았는데요, 이 추가 모달리티의 효과는 확실히 눈에 띄었습니다. Gemini 1.5 Pro의 경우, 프레임만 보았을 때보다 자막과 오디오를 통합했을 때 정확도가 각각 6.2%, 4.3% 상승하였습니다.
특히 영상의 길이가 긴 long video에서는 subtitle 추가 시 전체 정확도가 +10.1% 개선되고 multilingual에서는 +16.7%까지 올라가는 등, 자막이나 오디오가 제공하는 힌트(?)의 효과가 훨씬 크게 나타났습니다. 이는 비디오 이해가 단순히 frame만 잘 본다고 해결되는 문제가 아니라, 멀티모달 정보를 함께 활용해야 하는 문제라는 점 보여주죠.
마지막으로 MLLM에게는 오디오의 주변 소음보다 언어적 정보를 명확히 담은 자막 (Subtitle)이 더 효과적이었다고 하네요
④ 긴 영상의 병목 (Long-context Bottleneck)
마지막으로 짚고 넘어갈 가장 중요한 한계점입니다. 위에서 봤던 Table 4를 보면, 오픈소스와 상용 모델을 막론하고 비디오의 길이가 길어질수록 모델의 성능이 지속적으로 하락하는 경향을 확인할 수 있었습니다.
저자들은 그 원인을 세 가지로 분석했습니다. 첫째, 긴 영상일수록 복잡한 추론(Reasoning) 문제가 많고 , 둘째, 긴 영상을 처리하기 위해 프레임을 듬성듬성(Sparse) 추출하다 보니 핵심 정보가 누락되며 , 셋째, 긴 맥락(Long context) 자체를 온전히 기억하고 이해하는 능력 자체가 아직 부족하기 때문입니다.
4. Conclusion
이제 논문을 정리해보겠습니다.
기존 비디오 벤치마크들은 영상의 종류가 한정적이고, 길이가 짧으며, 시각(Frame) 정보에만 의존한다는 한계가 있었습니다. Video-MME는 이러한 한계를 해결하고자, MLLM이 복잡하고 긴 비디오를 ‘다양한 모달리티(자막, 오디오)’와 ‘긴 맥락(Long-context)’ 등을 얼마나 종합적으로 이해하는지 평가하기 위해 제안되었습니다. 이 벤치마크를 통해 기억해야할 내용은 크게 두 가지 같습니다.
첫째, 비디오 이해는 멀티모달 융합이 중요합니다. 비디오는 단순히 프레임의 연속이 아니라는 점입니다. 특히 비디오가 길고 복잡해질수록 자막과 오디오 정보를 함께 활용했을 때 모델의 성능이 비약적으로 상승한다는 점은, 향후 비디오 모델이 반드시 Multi-modal을 잘 다뤄야한다는 점을 보여준 것 같습니다.
둘째, Long-context와 Counting 등 세밀한 인지 영역은 여전히 어려운 부분입니다. 현재 최고의 상용 모델조차 영상이 길어질수록 성능이 하락하는 치명적인 문제를 겪고 있습니다. 또한, 동영상 속 객체의 개수를 세거나 정밀한 시간 흐름을 인지하는 작업에서는 모든 모델이 공통적인 취약점을 보였죠
즉, Video-MME는 현재 MLLM들이 보이는 한계를 보여준 데이터셋이라고 정리할 수 있겠네요! 저희 연구실에서도 제한된 프레임 수를 극복하기 위한 구조적 기법이나, 긴 영상 속에서 필요한 정보만 적응적으로 찾아내는 방법론 등을 후속 연구로 고민해 본다면 아주 좋은 방향이 될 것 같습니다!