안녕하세요! 이번에 소개할 논문은 Long Video Understanding에서 긴 비디오를 효과적으로 이해하기 어려운 문제를 해결하기 위해 shot단위의 점진적인 추론 방식인 Chain-of-Shot 프레임워크(VideoChat-A1)를 제안한 연구입니다
이 논문은 기존 MLLM 기반 방법들이 프레임 단위의 처리로 비디오를 이해하며 중요한 장면을 놓치기 쉬웠다는 점을 문제로 지적하면서 사람이 긴 영상을 볼때 장면을 하나씩 되짚어가는 사고를 모방한 에이전트 구조를 제안합니다
그럼 논문리뷰 바로 시작하겠습니다
Intro
Video Understanding에서 성능향상은 대부분 MLLM에 의해 주도되어 왔지만 긴 시간적 맥락을 가지는 비디오를 이해하는 것에는 여전히 어려움이 있다. 이를 해결하기 위해 최근에는 MLLM을 에이전트로 활용하는데, 긴 비디오에서 맥락 정보를 검색하는 다양한 에이전트 프레임워크가 제안되고 있다.
그러나 기존의 에이전트들은 Long Video(LV)는 여러 개의 shot으로 구성되어 있다는 사실을 간과하고 프레임 단위의 전역적 샘플링이나 단순 retrieval에 의존하는 경향이 있다. 그 결과로 질문과 직접적으로 관련 없는 중복되거나 잡음이 많은 시간적 맥락이 선택되기도 하며 이는 장시간 비디오 이해 성능을 제한하는 요인이 된다.
LVU에서 에이전트는 크게 두가지로 나뉜다.
- 긴 비디오에서 정보를 한번 추출해두고 이것을 retrieval로 답하는 방식
- 여러 라운드에 걸쳐 핵심정보를 탐색하는 방식 하지만 두 접근 모두 롱 비디오의 기본 구조단위인 shot에 대한 고려가 부족하다는 한계를 가진다
저자들은 shot단위로 장면을 선택하고 점차 자세히 살펴보는 Chain-of-Shot 추론 프레임워크(VideoChat-A1)을 제안한다. VideoChat-A1은 사용자의 질문과 관련된 샷을 단계적으로 선택하고 선택된 샷을 coarse-to-fine 방식으로 나누어 분석한다. 이러한 과정을 반복하면서 샷들의 흐름을 따라 추론하고, 질문과 무관한 장면은 배제함으로 필요한 장면에 집중할 수 있게 된다. 결과적으로 사람이 긴 영상을 보며 중요한 장면을 다시 찾아 확인하는 사고방식과 유사한 추론과정을 구현하게 된다.
구체적으로 각 샷의 추론 단계마다 MLLM을 에이전트로 사용해서 관련 샷 선택 → 샷 분할 → subshot바탕으로 한 답변 추론을 수행한다. 이때 답변의 confidence가 낮다면 현재 선택된 subshot만으로는 정보가 불충분 하다고 판단하고 추가적인 샷추론을 반복한다(chain-of-shot). 다시말해긴 비디오 샷들을 반복적으로 들여다 보면서 답을 점진적으로 추구하는 사람의 사고과정을 모방하여 추론하는 것이다
Method
Chain-of-Shot(CoS) 추론 패러다임으로 크게 3step으로 진행된다.
3step : Shot Selection, Shot Partition, Shot Reflection

[Video Glance]
- 모든 질문이 shot단위 분석을 필요로 하는 것이 아니기 때문에 사전 판단(이 질문 자세히 파봐야해?)을 위한 video glance 단계를 도입했다. 먼저 비디오 전체에서 4개의 프레임을 uniform샘플링으로 뽑아 비디오를 대략적으로 요약한다. 이 4프레임고 QA를 함께 MLLM에 입력해서 질문에 답하기 위해 전체 비디오를 더 볼필요가 있는지(국소적인 질문인지) 판단하도록 한다. → 질문이 Global 질문이다 판단하면 그냥 여기서 32개 프레임을 추가로 uniform샘플링해서 여기서 답변을 생성한다 → 반대로 질문이 Local 질문이다 판단되면 이때 Chain-of-shot추론을 시작한다 (필요할 때만 발동! 효율성 수치에 효과가 있음)
3.1 Shot Selection
(지금 까지 본 정보 기준으로 어느 장면을 더 볼지)
shot selection 단계는 정답을 확정하는 단계가 아니라 shot의 후보를 고르는 단계로 전체→일부샷으로 공간을 줄이는게 목표이다 이때 1라운드는 전체 비디오가 하나의 shot이고 2라운드부터 이전에 나눈 샷들이 여러개 존재하는 형태이다.
[Key Information Summary]
이전 라운드의 추론 결과를 바탕으로 mllm을 통해 key info를 얻는다 구체적으로 직전라운드까지 무엇을 봤고, 어떤 답을 골랐고, 왜 그렇게 생각하는지를 전부 포함한 히스토리 기반의 요약을 key info로 만든다. 이 구조 덕분에 shot selection이 정적인 retrieval이 아닌 동적 selection이 된다.
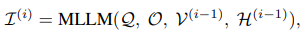
- Q(질문), O(답변선택지),
- V(i-1) (직전 라운드까지 선택된 샷들에서 샘플링된 비디오 프레임)
- H(i-1) (직전 라운드의 핵심정보(I(i-1)), 선택된답(A(i-1)), 이유(R(i-1))를 포함하는 과거 추론 정보)
[Shot selection via Retrieval]
핵심 텍스트정보(key info, I(i))를 얻은 후, I(i)를 샷 선택을 위한 context가이드로 활용한다 이때 shot selection은 shot-text retrieval을 통해 수행이 된다 파인튜닝된 LongCLIP을 Shot Selection로 사용하며 I(i)와 S(i-1)에 포함된 각 shot사이의 코사인 유사도를 계산하여 상위 N개의 샷을 선택해 다음 단계에서 분석할 **후보 샷 집합C(i)**를 구성한다. 이때 샷은 프레임 묶음으로 지금까지 생각한 내용과 가장 잘 맞는 장면이 무엇인지 검색하는 장면 단위의 retrieval이다
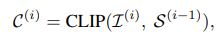
- 첫번째 라운드에서는 전체 비디오만 존재하기 때문에 이 하나의 shot을 그대로 후보샷으로 사용한다.
3.2 Shot Partition
(선택한 장면 더 잘게 나누기)
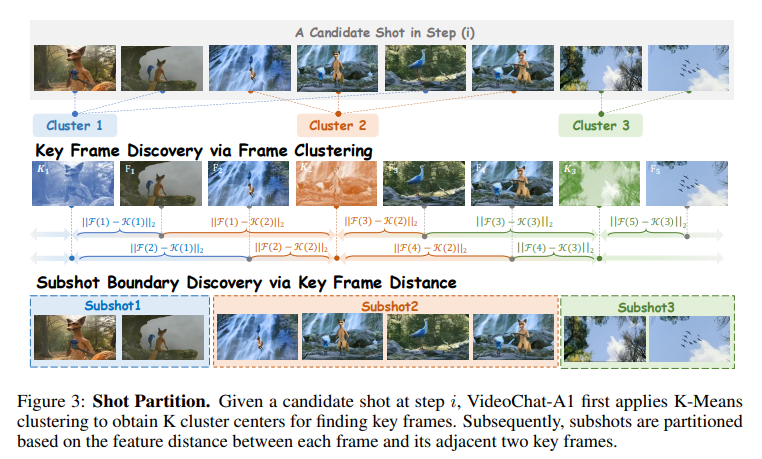
후보 샷 C(i)를 얻은 후 각 후보샷을 더 깊이 분석하기 위해 subshot으로 추가 분할을 진행한다. 다시말해 선택된 샷 안에서 의미적(semantic)으로 다른 장면들을 분리한다. (fig3, 하나의 후보샷에 대해 subshot을 추가 분할하는 과정)
[Key Frame Discovery]
후보샷 내의 subshot을 찾기 위해 먼저 해당 subshot을 대표하는 key frame(1fps & 유니폼샘플링)을 탐색한다. 뽑은 프레임에 대한 특징을 CLIP으로 추출하고 해당 특징들에 대해 K-means클러스터링을 수행한다
그 결과 K개의 클러스터가 만들어지는데, 하나의 클러스터는 하나의 subshot을 대략적으로 반영한다 하지만 k-means클러스터링은 시간적인 순서를 고려하지 않기 때문에 시간적인 순서(temporal order)를 가진 subshot으로 구성하기 위해 각 클러스터에서 가장 해당 클러스터의 의미를 잘 대표하는 하나의 key frame을 추가로 선택하여 이 키 프레임들을 시간 순서로 정렬한다.
[Subshot Boundary Discovery]
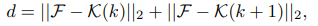
- 어떤 프레임 F가 key frame과도 멀고 뒤 key frame과도 멀면 의미가 바뀌는 중간지점이기 때문에 그 프임을 subshot의 경계로 선택한다. 이때 인접한 두 키프레임 사이의 거리를 계산하기 위해 L2 feature distance를 계산해준다. 이후 이를 합산해 의미적 편차(semantic deviation) 지표로 사용한다.
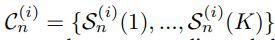
- 각 후보샷C(i)은 K개의 subshot으로 분할된다.
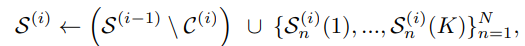
- 결과적으로 하나의 shot안에 K개의 subshot이 생기는 것이다. 전체 샷 집합에서 후보샷은 제거하고 해당 subshot들로 교체 해줌으로 갱신된다
3.3 Shot Reflection
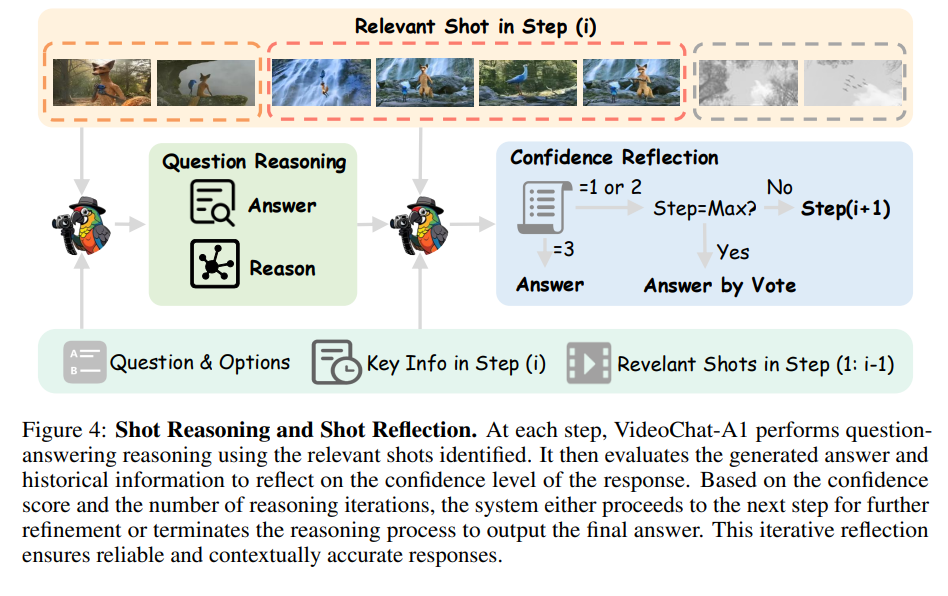
[Question Reasoning]
직전 step으로 더 세분화된 subshot을 얻은 후 fig4처럼 MLLM을 대화 에이전트로 사용해서 질문에 대한 답(A(i))과 그 이유(R(i))를 생성한다.
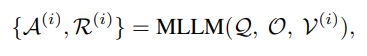
- V(i) : 각 subshot에서 8개의 프레임을 생플링 하고 이전 라운드의 프레임 집합V(i-1)과 결합해 V(i)를 구성한다
[Confidence Reflection]
위에서 생성된 답변이 믿을만한지를 판단하기위해 답변과 이유를 MLLM에 함께 다시 넣어줌으로 confidence를 생성한다.
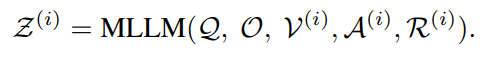
- confidence값인 Z(i)를 0~3으로 설정해 신뢰도가 2보다 크면 해당 답변을 최종 결과로 선택한다. 만약 2보다 작다면 현재 라운드에서 선택된 subshot만으로는 질문에 답하기에 불충분한 상황으로 판단하고, 이에 따라 다음 단계에서 다시 샷 Selection→ Partition→ Reflection을 수행한다.
- 이때 최대 추론 라운드 수(3번)를 지정해 최대 라운드까지도 충분한 신뢰도 답변을 얻지 못한다면 모든 라운드의 답변들 중 다수결로 최종 답을 결정한다
Experiment
[Comparison with SOTA]
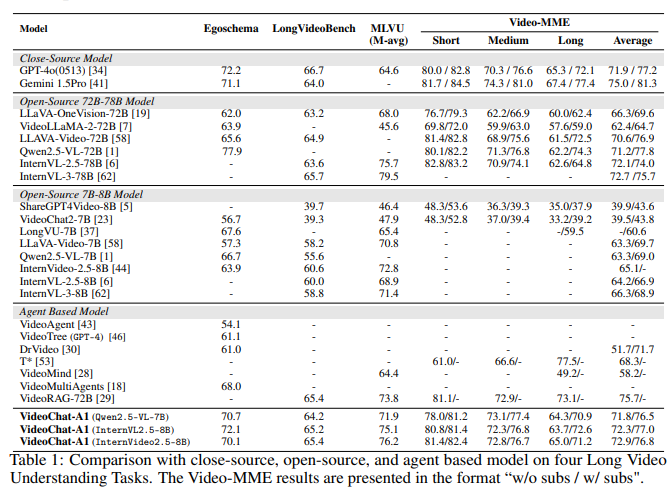
- (Table1.)기본 MLLM으로 Qwen2.5-VL-7B, InternVL2.5-8B, InternVideo2.5-8B를 사용했고 LV대표 벤치마크 4개로 비교분석한 결과, 7B나 8B 모델로도 대규모 오픈소스모델이나 closed모델들과 비교해도 얼추 비슷하거나 더 나은 성능을 보인다.
[Ablation]
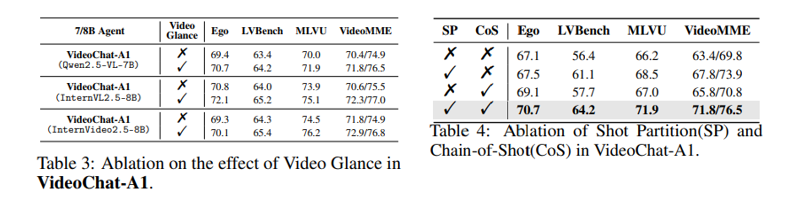
- table3 & 4는 각각 video glance와 shot partition+Chain-of-shot에 대한 결과이다
video glance를 사용하는 모든 모델에서 높은 성능을 보였고 shot partition과 Chain-of-shot은 각각 단독으로 사용해도 성능향상이 있지만 함께 사용했을때 가장 좋은 성능을 보인다.
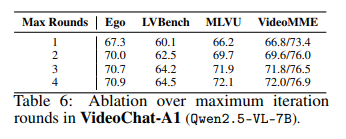
- table6은 여러 벤치마크에서 Reflection 최대 라운드 수에 대한 ablation으로 라운드 수를 늘릴수록 모든 데이터셋에서 성능이 다 향상되는걸 볼수있지만 CoS과정을 3번 했을때부터 충분히 만족스러운 결과를 얻을 수 있었다. (4번부턴 성능향상 있긴하지만 미미함) 이에 따라 저자들은 성능과 비용간의 균형을 고려해 최대 라운드수를 3으로 지정하였다
안녕하세요 좋은리뷰 감사합니다.
답변과 이유를 다시 MLLM에 입력하여 확신도를 생성하는 방법은 처음 접한것 같습니다.
해당 방법도 논문이 제시한 부분인지 다른 논문을 차용한 것인지 궁금합니다.
만약 제시한 것이라면 관련한 신뢰성 분석 실험이 있을까요?