이번 리뷰 논문은 Fei-Fei Li 교수님 연구실에서 나온 논문이며, VoxPoser, ReCap 저자인 Wenlong Huang이 1저자인 페이퍼 입니다. 해당 저자는 이전 논문부터 VA, VLA와는 다른 흐름의 연구들을 진행해왔습니다. 관찰된 정보로부터 로봇 궤적을 직접 예측하는 방식이 아닌, VLM이 가지고 있는 지식들을 활용해 zero-shot으로 해결하는 방안을 제시했죠. 아마 저자는 단순한 모방 학습으로는 해가 수 없이 많은 동작들을 다재다능한 수준으로 끌어올리기 어렵다고 생각한 것 같습니다.
그러한 철학을 가지고 있는 저자가 이번 연구에서는 zero-shot을 기반으로 하던 이전 연구와는 다르게 직접 학습한 모델을 기반으로 한 연구 결과를 제시합니다. 최근 비디오 생성 모델을 활용한 월드 모델들이 그럴싸한 물리적인 조작을 결과를 보여주고 있습니다. 저자는 이에 대해 영감을 받아 물체에 대한 물리적인 조작을 그리퍼의 움직임까지 그럴싸하게 표현이 가능한 3D 월드 모델을 제시합니다.

Intro

비정형 환경에서의 World Modeling은 general-purpose robots을 도달하는 데에 있어 필수적인 요소로 볼 수 있습니다. 이는 로봇이 무엇을 보고 자신이 무엇을 하려고 하는지, 이에 대한 의도가 세계를 어떻게 변하게 만드는지를 이해하기 위한 능력이라고 볼 수 있습니다. 사람을 빗대어 본다면 사물을 잠깐 바라보거나 잠깐의 접촉만으로도 물체를 조작하기 위해 어떠한 3차원 움직임을 가져하는지를 예측 가능합니다. 이는 World Modeling이라는 것이 얼마나 많은 것들을 예측해야 하는지를 보여줍니다. 행동은 물리 법칙이 존재하는 공간과 시간 속에 존재합니다. 저자는 open-world settings에서 지각적 입력만으로 물리 법칙 공간 내에서 사람과 동등한 행동을 예측 할 수 있는 모델을 만든 것을 목적으로 하며, 이는 spatial intelligence의 궁극적인 목표라고 볼 수 있습니다.
저자는 이를 이루기 위한 철학으로 확장을 위한 통합 (unification for scaling)을 제시합니다. 즉, state와 action을 3D physical space라는 공통된 모달리티로 표현하는 것을 목적으로 합니다. 여기서 state는 RGBD로 구축된 full-scene 3D point cloud로 표현되며, 행동은 사전 정의된 embodiment에 따른 dense 3D point trajectories로 표현됩니다. 해당 표현 공간은 robot point들이 시간적 흐름에 따라 변화에 따라 3D point flow를 모델링하는 것과 동일합니다. 부분적으로 관찰된 3D scene point에 어떤한 행동 지침이 주어지면 특정 시간 동안에 걸친 그 지침에 해당하는 점들의 변위를 예측하는 방식입니다. (fig 1의 output을 참고하시면 됩니다)
해당 표현 공간은 개념적으로 간단해 보이지만, 강력한 요소들이 있습니다. 지각적인 특성 (e.g. 뷰포인트, 카메라 수)나 구조적인 특성 (e.g. cross-embodiment)에 구애 받지 않고 물리적인 특성을 하나의 action space로 묶어 줍니다. 또한 로봇의 그리퍼와 장면 간의 상호작용을 통해 객체의 특성, 관절의 움직임, 재질 등을 암시적으로 학습이 가능합니다.
즉, 저자는 태스크에 대한 목표와는 독립적으로 상호작용에 대한 기하학을 모델링함으로써, 다양한 구조, 작업에 상관 없이 물리 법칙 그 자체와 객체 간의 기하학적 상호작용을 모델링하는 것을 목적으로 합니다. 이는 LLM의 ‘next-token prediction’과 유사하게 해석 가능하지만, 이를 3D 공간과 시간에 걸친 상호작용에 적용한 것이라고 보시면 됩니다. 저자는 이러한 접근 방식을 PointWorld라고 칭합니다.
Method
3D World Modeling with POINTWORLD
저자는 environment dynamics를 신경망 \mathcal{F}_\theta : S \times A \rightarrow S 를 모델링하여 current state와 robot action을 입력으로 받아 다음 state를 예측하는 것을 목적으로 합니다. 여기서 S, A는 각각 state, action space를 의미합니다. 기존 방법론에서 정의된 수식은 single-step update s_{t+1} = \mathcal{F}_\theta(s_t, a_t) 을 가지지만 저자는 이와 반대로 data-driven modeling (e.g. ALOHA)이 따르는 multi-step (chucked) formulation을 택합니다. 즉, 모델이 horizon H에 대한 future states를 single forward pass \mathcal{F}_\theta^H : (s_t, a_{t:t+H-1}) \rightarrow s_{t+1:t+H} 예측하여 시간적 일관성을 유지하고 계산 효율을 높이고자 합니다. (저자는 H = 1 steps, 0.1s per step을 이용했다고 합니다.)
State Representation. World model을 구축하기 위해서는 state space S를 신중하게 선택해야 합니다. 해당 연구에서는 environment state로 point flows를 이용합니다. 수식적으로 s_t = \{ (p_{t,i}, f^S_i) \}_{i=1}^{N_s} 는 t에서의 point flow를 나타내며, N_s개의 points들은 각각 position p_{t, i} \in \mathbb{R}^3 와 D_s 차원을 가진 time constant features f_i^S \in \mathbb{R}^{D_s} 로 구성됩니다.
다른 표현 기법들과 비교할 때, point flow는 조작에서의 world modeling을 위해 아래와 같은 이점을 보입니다.
(1) 렌더링 기법보다는 물리 기반 시뮬레이터과 유사하게 외형 보다는 3D geometries 간의 물리적 상호작용에 집중
+ 렌더링 기법은 3DGS를 이용한 뉴럴 물리 엔진을 의미하는 것으로 보입니다.
(2) 객체에 대한 사전 지식이 없어도 RGBD에서 활용 가능
(3) 3차원 표현에서 흔히 사용되는 permutation matching 없이도 point 간의 변위에 대한 L2 loss를 통해 간단하고 안정적인 훈련이 가능
(4) 보다 쉽게 다양하고 세밀한 fine-grained contact dynamics를 포괄 가능한 표현력을 가질 수 있음
point flow를 얻기 위해서 하나 또는 약간의 캘리브레이션된 RGBD로부터 URDF 기반의 forward kinematics를 통해 로봇이 위치한 pixel을 마스킹하고, 이외의 pixel도 역투영하여 3D point를 얻습니다. 추가로, 모델은 환경으로부터 static point set을 입력으로 받으며, 변화에 따른 대응 관계는 모델의 forward pass (i.e. imagination) 내에서만 유지됨으로 추론을 위해 별도의 point tracker를 요구하지 않습니다. 또한, 포인트 수는 forward pass의 상황에 따라 변동 됩니다.
+ 즉, 카메라와 로봇 간의 관계를 아는 상황에서 point set을 구성하되, 로봇은 URDF 기반으로 point를 올린다고 보시면 됩니다.
++ 로봇은 현실에서 조작된 로봇 액션을 디지털 트윈을 수행한 시뮬레이션 정보를 활용하여 사용한다고 보시면 됩니다.
Action Representation. Heterogeneous embodiments (different kinematics, gripper geometries, and even different numbers of grippers)를 배우기 위해서, 3D point flows를 다시 사용합니다. 하지만 RGBD로부터 얻는 scene point flow와 달리 robot point flow는 로봇의 알려진 URDF를 사용한 forward kinematics를 이용해 얻습니다. 즉, 현실에서 조작된 정보를 사용하는 것이 아니라 조작된 정보를 기반으로 시뮬레이션에 업로드하고 이를 기반으로 한 정보를 토대로 point flow를 얻는 방법을 이용합니다. 해당 방법은 다양한 embodiments에 대응 가능하고, 부분적으로 가려지지 않는 완전히 관찰 가능함을 보장하기 위한 의도된 설계라고 합니다.
+ fig 2의 상단 부분이 해당 내용에 대한 설명을 그림으로 표현한 부분이라고 보시면 됩니다.
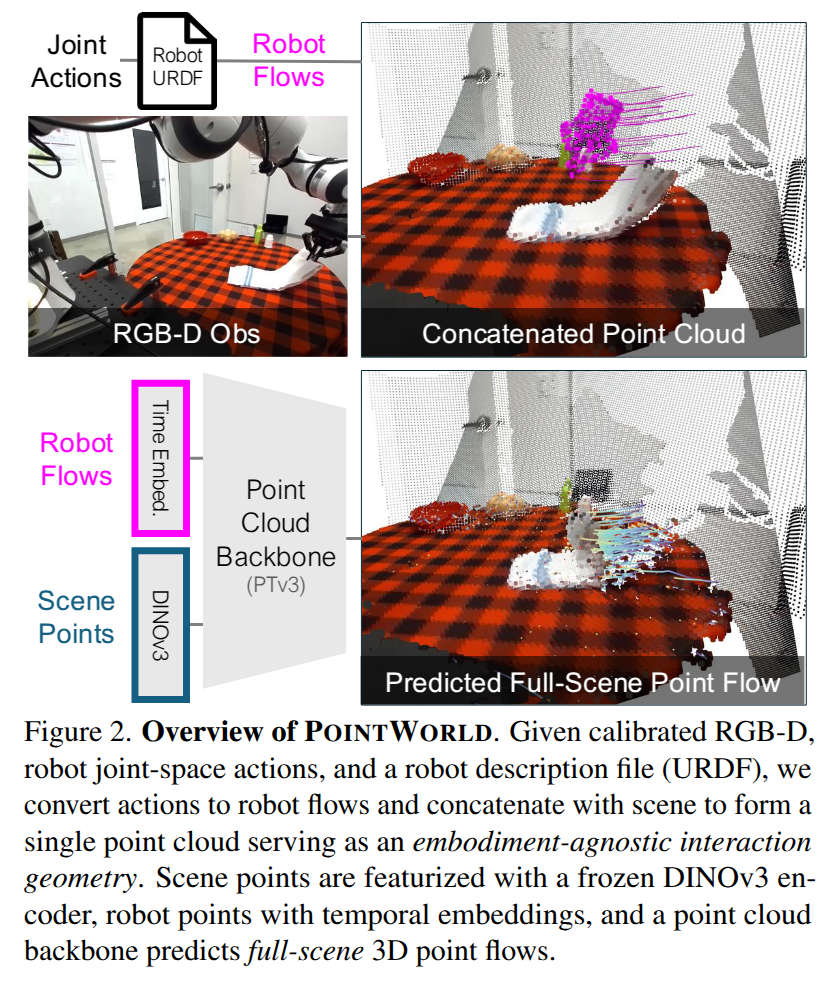
Dynamics Prediction. 위에서 보인 state-action representations을 통해서, 모델의 입력으로 정적인 full-scene point clouds S_t와 robot point flow actions a_{t:t+H-1}을 사용합니다. 저자는 해당 정보로부터 확장성과 대규모 모델링이 가능한 새로운 아키텍쳐를 설계하는 대신에 SOTA를 달성하는 point cloud backbone ~ Point Transformer V3 (PTv3)를 활용하여 임베딩을 수행합니다.
구체적으로 inital scene points와 time-stacked robot points를 concat하여 backbone에서 처리 가능한 single point cloud를 만듭니다. scene point는 2차원으로 투영하여 DINOv3로 임베딩되어지며, robot point는 시각에 따라 임베딩 (time embed.)이 수행되어집니다. 이후, point cloud backbone은 각 포인트 별로 특징을 출합니다. 그런 다음, shared MLP head로부터 길이 H의 chunk 내에서 각 스텝마다 scene point의 포인트별 변위를 single forward pass로 예측합니다.
청크 방식은 real-time latency (0.1s per batched forward pass)으로 많은 후보 궤적들을 평가 가능하며, 해당 방식은 diffusion objectives를 사용하기 때문에 일반적으로 초 단위의 시간이 걸리는 픽셀 기반 접근 방식보다 효율적인 결과를 보여줍니다.
+ fig 2의 하단 왼쪽에 입력 데이터와 모델 구조에 대해서 확인 가능합니다.
Training Objective. 구현된 방식을 토대로는 standard regression loss를 적용해도 정보를 학습하기 충분하지만, 3D World Modeling은 training signal을 더 넘어서 두 가지 challenges를 고려해야만 합니다. (i) full-scene prediction으로 인해 로봇은 장면의 일부만 조작하므로 대부분의 포인트는 정적이며, standard L2 loss로는 매우 sparse training signal을 얻을 수 밖에 없습니다. (ii) 실제 데이터는 노이즈가 많기에 이에 견고하도록 모델을 정규화해야만 합니다. 이를 해소하기 위해서, 실제 움직임으로부터 계산된 soft movement likelihood m_{k, i} \in \[0, 1\] 에 따라 각 time step의 각 포인트에 가중치를 부여하여 이동하는 포인트에 loss를 집중시키는 weighted regression objective 를 사용합니다. 이를 정리하면 m_{i,k} = \sigma(\kappa(\delta_{k, i} - \tau)) 로 구성됩니다. 여기서 time step k에서의 i 번째 point cloud에 대한 ground truth로부터 측정된 변위 \sigma_{k, i} > 0가 관측되면, 이에 따라 sigmoid function \sigma 로부터 요소를 측정합니다. \kappa, \tau 는 각각 temperature, displacement threshhold로 임계값보다 크고 temperature에 따라 조절하는 hyper parameter로 사용됩니다.
두번째 요소를 해결하기 위해서, scalar log-variance s_{k,i} 을 예측하기 위해 aleatoric uncertainty regularization을 적용하며, 포인트 간의 잔차를 위해 Huber loss을 도입합니다. 이를 정리하면 아래와 같습니다.

여기서 \rho_{/delta} 는 elementwise Huber loss이며, \hat{\boldsymbol{P}}_{t+k, i} 와 \boldsymbol{P}_{t+k, i} 는 각각 step k에서의 point i에 대한 예측된, GT position에 해당합니다. 실제로는 2D tracker가 제공하는 pseudo ground-truth에 관측되지 않는 포인트들은 무시되어집니다.
+ movement weighting과 uncertainty regularization에 대한 정성적인 결과는 fig 4에서 볼 수 있습니다.

POINTWORLD for Robotic Manipulation
사전학습된 PointWorld은 robotics의 다양한 영역에서 활용 가능하지만, 해당 연구에서는 manipulation에 한정지어 단일 사전 훈련된 PointWorld가 추가적인 시연이나 사후 훈련 없이, 단일 RGB-D 캡처만으로도 보지 못한 실제 환경에서 행동 추론을 가능하게 할 수 있는지를 보이는 것을 목적으로 합니다. 이를 위해서, 주어진 cost function으로부터 SE(3)에서의 T개의 end-effect pose targets 후보 시퀀스를 기반으로 계획 가능한 sampling-based planner MPPI를 활용합니다.
+ MPPI는 여러 후보 궤적들로부터 누가 더 적합한지 판단하는 전통적인 planner로 보시면 됩니다.
구체적으로 보정된 RGBD가 주어지면, 먼저 scene point set으로부터 initial state s_0를 구축합니다. 그런 다음 cubic-spline noise distribution에 따라 K 개의 action perturbations를 샘플링하, nominal end-effect trajectories로 가정합니다. 각 샘플링된 궤적에 따라 robot point flow action가 구성됩니다. 해당 입력값들은 PointWorld로부터 scene flows와 trajectory cost J가 누적됩니다. nominal trajectory는 J로부터의 가중 평균을 통해 반복적으로 개선되어집니다.
Cost function을 정의하기 위해서 control regularization로부터 task objectives를 나눕니다. \mathcal{I} \subseteq \{1, ... N_s \} 는 작업과 관련된 scene points의 집합을 나타내며, 해당 지점들에 대한 target positions \{ \mathbf{g}_i\}_{i \in \mathcal{I}_{task}} 에 해당합니다. 예측된 state s_k는 c_{task}(s_k) = \frac{1}{\mathcal{I_{task}} \sigma_{i \in \mathcal{I}_{task}} ||\mathbf{p}_{k,i} - \mathbf{g}_i ||_2^2 에 해당합니다. Task-relevant points는 GUI를 통해 사용자 혹은 VLMs에 의해 지정될 수 있습니다. 전체 최적화 문제는 아래와 같이 global trajectory optimization으로 정리됩니다.
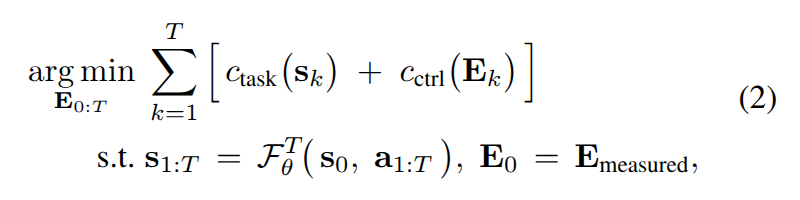
여기서 c_{ctrl} 은 경로 길이와 도달 가능성 (reachability) 정규화에 해당하며, step k에서의 E_k는 end-effect pose, E_{measured}는 현재 EE pose에 해당합니다.
+ 쉽게 정리하면 궤적을 랜덤하게 샘플링하고, cost function으로부터 cost map을 생성하여 궤적을 결정하는 MPPI를 PointWorld에 적용하기 위한 방법이라고 보시면 됩니다.
Dataset Curation and Evaluation Protocol
정확도 향상을 위해서는 large-scale 3D data를 필수적으로 활용되어야 합니다. 저자는 이를 수행하기 위해서 DROID (real-world)와 BEHAVIOR-1k (simulation)라는 2가지 주요 데이터 셋을 활용하여 3D annotation을 생성과 평가 프로토콜을 적용하는 방법을 설명합니다.
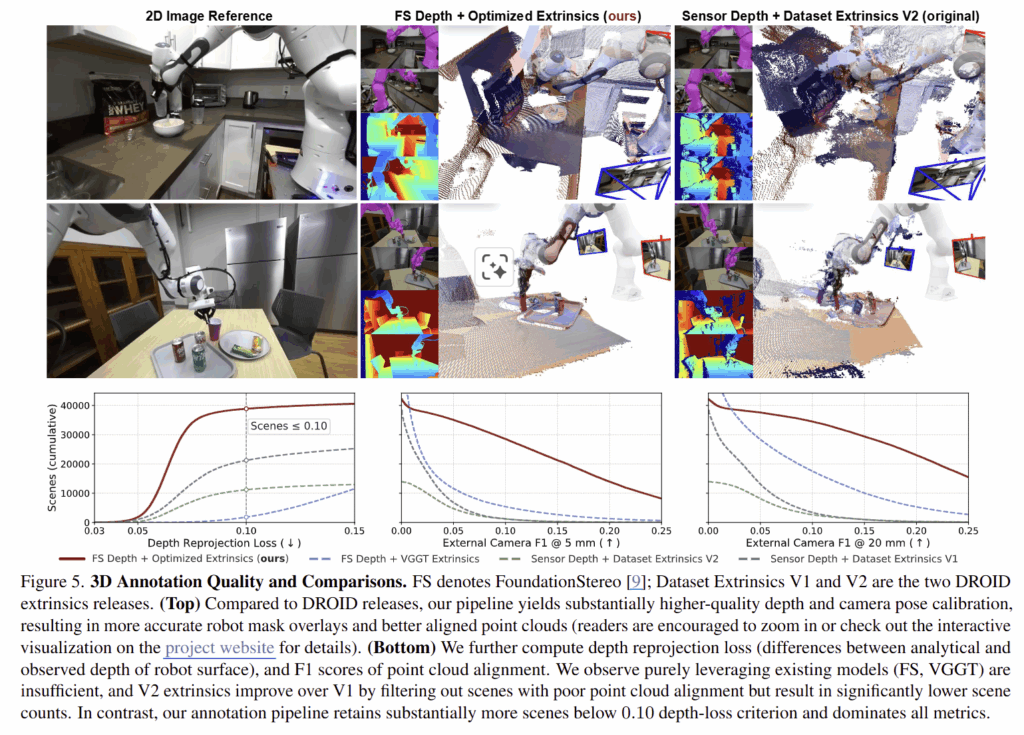
DROID. 기존 DROID 데이터 셋의 깊이 정보와 camera extrinsics은 부정확한 경우가 있어, 새로운 데이터 처리 파이프라인을 제시합니다. 깊이 추종은 FoundationStereo를 사용하여 높은 품질의 metric depth를 추정하고 외부 카메라 파라미터를 얻기 위해서 VGGT로 초기 카메라 자세를 추정하고 로봇의 URDF와 관절 상태를 사용하여 관찰된 깊이 정보와 렌더링된 로봇 형상을 일치시키도록 최적화하여 카메라 파라미터를 보정합니다. 해당 방법은 fig 5 하단에서 보이는 바와 같이 기존 정보보다 개선된 정확도를 보여줍니다. 각 포인트 추적은 CoTracker3를 사용하여 2D point를 추적하여 정확한 깊이 및 외부 카메라 파라미터를 사용하여 복원을 수행합니다. 해당 과정에서 2D tracker로부터 추적이 실패한 포인트는 학습에서 제외합니다.
BEHAVIOR-1K. 시뮬레이션에서는 기존 에피스드를 재현하고, 여러 가상 카메라를 통해서 RGB-D를 얻고, 시뮬레이션으로부터 알려진 상태 정보를 활용하여 정확한 3D point flows를 얻습니다. 해당 데이터에서는 로봇과 객체 간의 의미 있는 상호 작용이 포함된 클립만 활용합니다.

Experiments

Experiment
Scaling 3D World Models: A Roadmap. 해당 섹션에서는 PointWorld와 같은 3D world model의 성능을 향상시키기 위해서 어떤 요소들을 개선하고 확장해나가야 하는지에 대한 경험적인 연구 결과를 제시합니다. 저자는 모델을 효과적으로 스케일링하기 위해서 4가지 요소를 제시합니다.
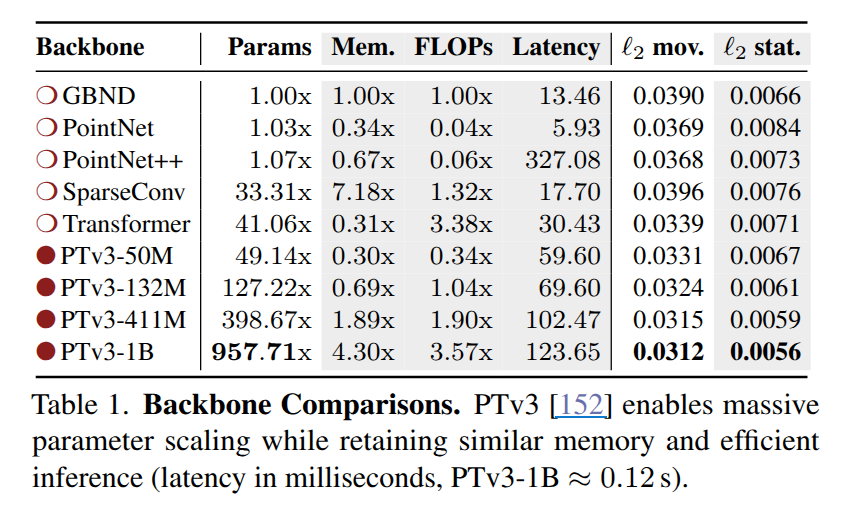
(1) backbone architecture: tab 1에서 보이는 바와 같이 더 크고 복잡한 3D 데이터를 효율적으로 처리하기 위해서는 PTv3와 같은 대형 모델의 필요성을 확인 할 수 있습니다.
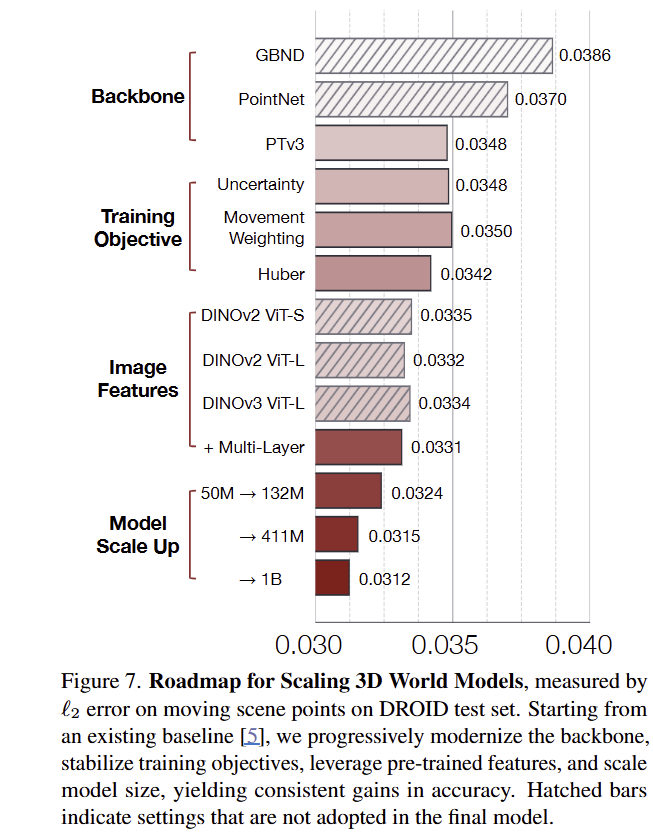
(2) Training Objectives: 실제 데이터의 노이즈와 희소한 동적인 포인트에 대한 학습 신호가 부족한 문제를 해결하기 위해서 저자는 Movement Weighting, Uncertainty Regularization, Huber loss를 통해 개선된 결과를 fig 7를 통해 보여줍니다.
(3) Pre-trained 2D Features: 3D 정보에 대한 고품질 데이터가 부족한 상황에서 DINOv3와 같은 강력한 2D 비전 모델에서 추출된 특징을 활용하여 객체성과 같은 사전 정보를 주입하는 것이 성능 향상이 된다는 것을 Fig 7에서 보여줍니다.
(4) Model Size Scaling: 기존 foundation model에서도 관측된 스케일링 법칙과 유사하게, 모델의 파라미터를 50M에서 1B로 확장하면서 꾸준히 향상되는 결과 (fig 7)를 보여주면서 3D world modeling에서도 동일하게 적용됨을 보여줍니다.
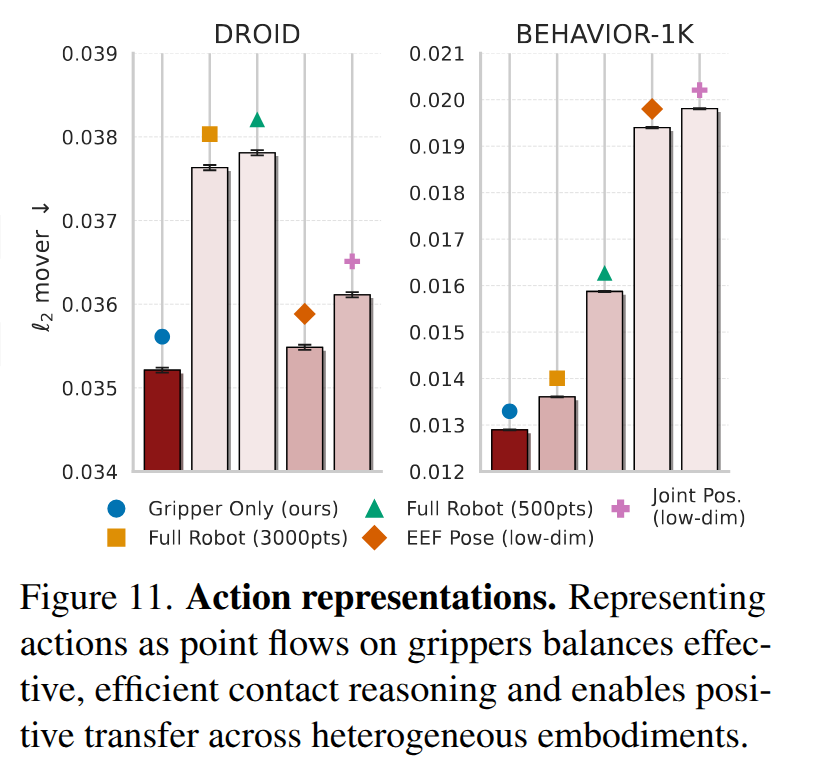
Action representations. 저자는 robot flow를 어디서 사용하면 효과적인지를 분석하기 위해서 fig 11에서 full robot, joint position, EE pose, gripper only에 대한 실험을 진행했습니다. Full robot에서는 성능이 크게 하락하는 경우를 보여주는데, robot 전체가 객체와 상호 작용에 있어 큰 도움이 않으며, 많은 노이즈들이 학습에 방해가 될 수 있음을 보여줍니다. EE Pose와 Joint Pos.는 모방 학습과 동일하게 저차원으로 표현하는 방식에 해당합니다. 실제 환경에서는 좋은 결과를 보여주지만, 노이즈가 없는 시뮬레이션 내에서는 성능이 하락되는 결과를 토대로 간접적인 표현보다는 직관적인 영역에서의 표현인 Gripper only가 가장 좋은 성능을 보여줍니다.
Chunked Prediction. 예측 전략에 따라 성능 차이를 보여주는 실험으로 Auto-regressive (AR)에 대해서 self-feeding (sf)는 예측 값을 다음 스텝의 입력으로 활용, teacher-forcing (tf)는 학습 시에 항상 GT를 다음 스텝의 입력으로 활용하는 방식입니다. Chunk -> window는 슬라이딩 윈도우 방식으로 모델이 고정된 길이의 윈도우 내에서 예측을 수행하며, 윈도우를 이동시키며 연속적인 예측을 만드는 방식입니다. Chunck->Chunk는 주어진 chunk 단위 만큼 한 번의 forward pass로 동시에 예측하는 방식입니다. fig 12에서 보이는 바와 같이 AR 방식들은 누적되는 오차로 인해 시간이 흐름에 따라 오차의 크기가 커지는 경향을 보여줍니다. 이에 반해 Chunk 기반인 방식들은 드리프 방식이 훨씬 적은 결과를 보여줍니다. 이러한 경향에 따라 한번에 예측은 수행하는 chunk->chunk에서 가장 적은 드리프트를 보여줍니다.

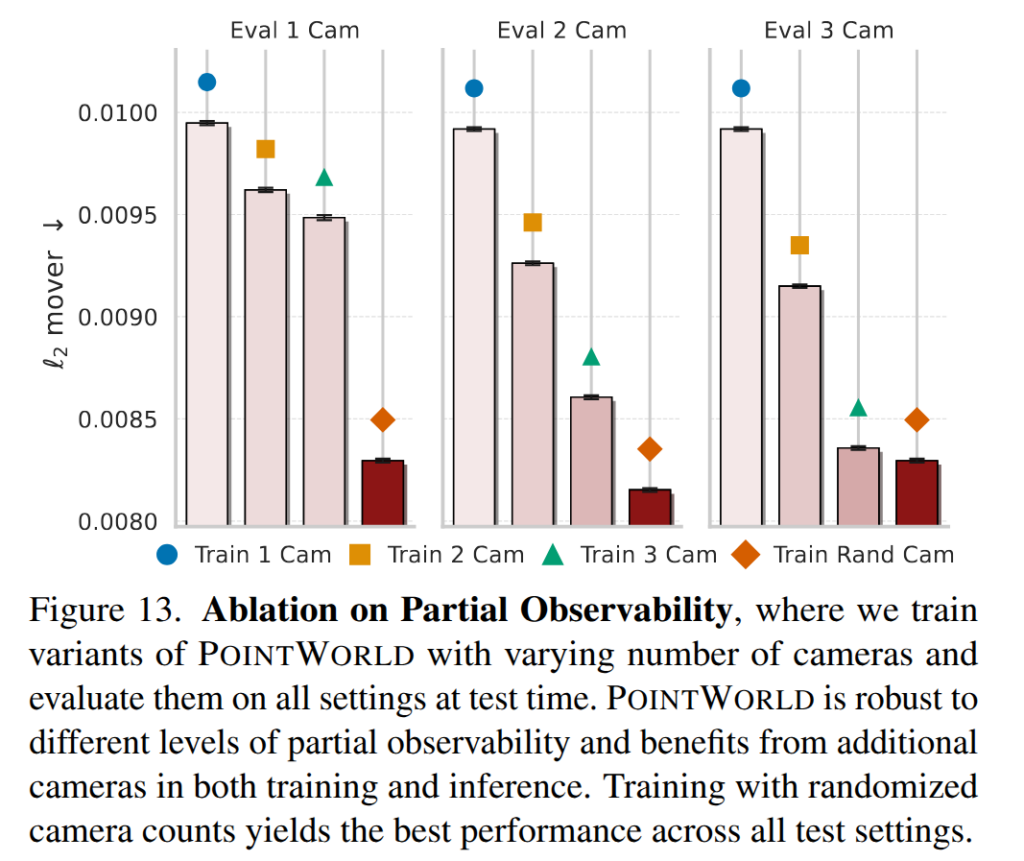
Partial Observability. 부분적인 관찰 환경에 얼마나 강건한지에 대한 실험 (fig 13)으로 카메라 수를 1~3대 또는 무작위로 선택된 개수 (Train Rand Cam: 1~3대 내에서 랜덤하게 학습)를 사용하여 모델을 학습시킵니다. 실험 결과, 학습된 카메라 수가 많을 수록 적은 카메라로 평가했을 때도 좋은 성능을 보여줍니다. 이는 모델이 많은 시점을 관찰하면서 환경을 더 잘 이해하는 것으로 볼 수 있습니다. 특히 흥미로운 점이 있는데, Train Rand Cam이 모든 테스트에서 가장 우수한 성능을 보여줍니다. 이는 다양한 관찰 시나리오에 노출됨으로서 부분적인 관측에서도 강인성을 높여 성능을 유지하거나 향상시키는데 도움이 됨을 보여줍니다.