안녕하세요. 오늘은 CLIP을 Scene Text Recognition task에 적용한 연구에 대한 리뷰를 하게 되었습니다. CLIP이 가지는 text perception의 능력에 주목해 구조는 간단하지만서도 이를 효과적으로 활용해 SoTA 성능까지 낸 CLIP4STR을 제안한 연구입니다. 저는 개인적으로 흥미롭게 읽었는데요 여러분도 그러길 바라면 리뷰 시작하겠습니다.
1. Abstract
사전학습된 VLM을 여러 downstream task에 접목 시켜 사용하는 추세다. 하지만 VLM이 scene text을 인식하는데 충분한 잠재력을 가지고 있음에도 불구하고 Scene text recognition이란 분야에서는 아직 하나의 visual 모달리티로 학습된 백본 네트워크를 사용하는 것이 대부분이다. CLIP이 이미지 속 텍스트를 인식 가능하다는 점에서 이 논문의 저자는 CLIP을 Scene Text Recognition method에 적용한 연구를 하며 CLIP4STR을 제안한다. 각각 image, text 인코더로 구성된 두개의 visual, cross-modal 브랜치로 모델 구조가 설계되었다. visual branch에서 image encoder를 타고 학습된 visual feature들을 가지고 초기 예측을하면 cross-modal branch에서 visual branch에서의 visual features와 예측된 text를 가지고 초기 예측을 조정한다. 13개의 STR 벤치마크에 대해 SoTA의 준하는 recognition 결과를 확인할 수 있었다. 고로 간단하지만 VLM을 STR에 적용할 방법을 제안했고 베이스라인을 구축했다는 점에서 의미가 있는 연구라고 할 수 있겠다.
2. Introduction
CLIP이나 ALIGN 같은 Vision-Language Model (VLM)은 VQA나, information retrieval, referring expression comprehension, image captioning, 여러 태스크에 적용했을 때 제로샷 성능이 검증됐었다. 하나의 파운데이션 모델로 자리잡았다고 할 수 있다. STR 분야도 image와 텍스트에 대한 이해가 수반되는 cross-modal task라고 할 수 있다. 대량의 데이터로 사전학습된 VLM을 활용하던 다른 태스크에서와는 달리 STR 방법은 single-modality로만 학습됐던 네트워크를 백본 모델로 사용하고 있다. 저자는 image-text 쌍으로 사전 학습된 VLM이 충분히 scene text를 이해하는데 강력한 능력을 갖고 있을 것이라고 생각했고, 이를 확인하면 VLM은 STR에서도 강인한 백본으로 자리잡게 될 것이라고 하며 이 논문에서 CLIP을 VLM으로 사용한 CLIP4STR을 제안한다.
STR 분야에서 회전이 돼 있거나, 굽어있거나, 흐릿하건, 가려져 있는 irregular text를 인식하는 게 중요하다. 저자는 CLIP이 강인하게 natural image에서 이런 irregular text를 잘 인식한다는 것을 확인하였다. 그 실험 결과는 아래 Figure 1.으로 확인하기를 바란다.
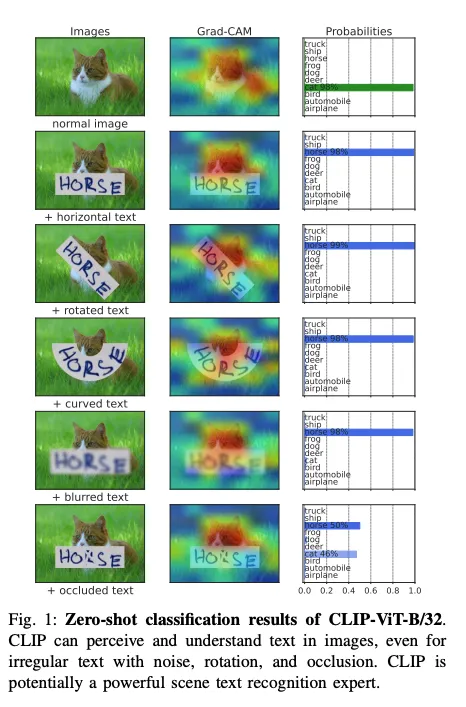
irregular하게 텍스트 스티커를 natural image (natural image란?)에 넣은 후 CLIP 모델이 분류하도록 학습시켰더니 텍스트 자체에 집중하며 정확하게 텍스트의 내용을 기반으로 분류를 수행한 것을 확인할 수 있다. 이로써 CLIP이 text 에 대한 perception 능력이 확인됐다고 볼 수 있겠는데 저자는 과연 text recognition에 사용되는 crop 된 텍스트 이미지에 대해서도 동일한 능력을 보일 수 있을지가 궁금했다고 한다. 이를 확인한 결과는 다음과 같았다.

앞서 얘기했던 irregular text에 대한 CLIP의 recognition 결과인데 충분히 인식이 잘 된다는 것도 확인이 됐다. 이렇게 CLIP이 갖는 text perception 능력을 활용해 STR 모델에서 강력한 백본으로써의 베이스라인을 구축하고자 제안된 것이 CLIP4STR이다. 이 모델은 두개의 encoder-decoder 조합의 브랜치로 구성된다. 여기서 사용되는 image encoder와 text encoder 모두 CLIP의 것을 사용한다. 디코더는 트랜스포머 디코더를 기반으로 사용한다. 단어 속에서의 글자가 오는 자리하는 그 관계성에대해서 학습이 되도록 PARseq 연구에서 제안됐던 pemuted sequence modeling이란 기법이 사용되었다. 이 기법을 사용해서 특정 읽기 순서에 상관없이 character를 예측할 수 있었다고 한다.
학습과 추론 과정을 따로 설명하자면 학습 때는 visual branch에서 visual features으로 초기 예측을 낸 다음 이후 이를 cross-moda branch에서 visual feature와 text 사이의 간극을 줄여 조정하는 식으로 이뤄진다. (사실 추론 시에는 뭐가 달라진다는 것인지 이해 못함.)
모델의 크기도 변경하고 사전학습 하기 위한 데이터 본 학습에 사용하는 데이터를 달리한 실험에 대한 분석을 통해 large-scale pre-trained VLMs을 STR 모델의 백본으로서의 효과를 확실히 검증한 연구다. 먼저 방법론에 대해서 자세하게 설명한 후 그 분석된 내용을 함께 설명하겠다.
3. Methods
논문에서와 같이 구체적인 방법론을 설명하기에 앞서 CLIP과 PARseq 기법에 대해서 소개하겠다.
CLIP
텍스트 인코더와 이미지 인코더로 구성된다. 대조학습을 통해 4억개의 이미지 텍스트쌍에 대해 학습됐다. 대량의 데이터에 대하 학습해 이미지와 텍스트 특징들은 두 모달리티가 공존하는 이미지-텍스트 임베딩 공간에 함께 정렬돼 있다. CLIP은 이미지 인코더로 ViT (Vision Transformer)를 사용한다. ViT는 visual tokenizer를 중간에 두어 일정한 크기로 겹치는 부분없게 패치로 나뉜 다음 패치를 나열해 이미지 시퀀스를 구성한다. 이미지 시퀀스 앞에 [CLASS] 토큰이 붙어 인코더의 출력으로 이 토큰만이 반환되어 이미지 분류를 수행하지만 CLIP4STR에서는 반환되는 모든 토큰을 사용한다. 문자 단위의 인식을 요구하기 때문에 모든 패치에서의 작은 특징이라도 필요한 것이다. CLIP의 텍스트 인코더는 트랜스포머 인코더를 사용한다. text tokenizer로는 lower-cased byte pair encoding 방법의 것을 사용한다. 49,152개의 character에 대해 인코딩이 가능하다. 텍스트의 시퀀스의 맨 처음과 끝은 [SOS], [EOS]로 이뤄진다. 두 인코더에서 추출된 visual feature, linguistic feature은 모두 정규화된 뒤 linear하게 projected 돼서 통합된 이미지-텍스트 임베딩 공간에서 자리를 잡게 된다.
Permuted sequence modeling
디코더 단에서 autoregressive 하게 예측이 되는데 보통 left-to-right 방향으로 예측된다. STR도 마찬가지로left-to-rignt, 혹은 right-to-left 방향으로 text의 sequence를 인식해 나가고 이를 학습 때는 attention mask로 이전에 출력된 토큰만과 attetnion이 수행되게 한다. 하지만 저자는 문장 속 단어를 예측할 때 고정된 방향이 필요하지 않고 여러 형태로 부터 의존성을 학습시키기 위해서 T개의 입력 토큰에 대해 가능한 조합을 가지고 가능한 순서대로 마스킹을 하는 permuted sequence modeling 기법을 사용한다. 이때 이전의 출력된 토큰만을 참조할 수 있다는 것은 변함이 없다.

Encoder
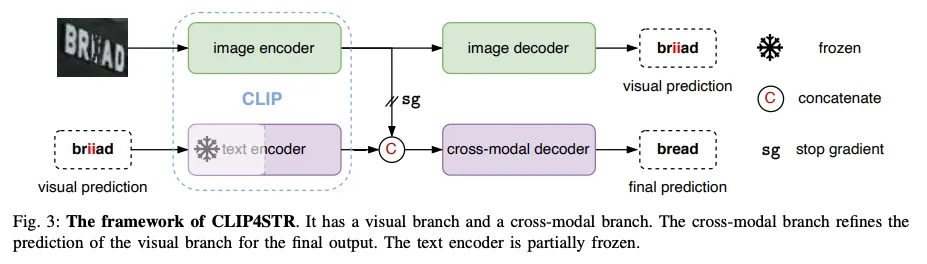
CLIP4STR의 구조는 이렇다. 이중 인코더-디코더가 결합돼 있다. visual branch, cross-modal branch로 이루어 져 있다. 텍스트 인코더와 이미지 인코더는 CLIP에서의 인코더 구조와 학습된 가중치를 모두 가져온다. visual branch에서 초기 예측을 수행하는데 이미지 인코더로 부터 추출된 특징을 기반으로 예측된다. cross-modal branch에서는 앞서 예측된 텍스트의 의미정보와 visual branch에서의 visual feature간의 간극을 줄이고 연관성을 높이는 방향으로 예측을 조정한다. 초기 예측을 말이 되게 철자를 고쳐주는 것이 cross-modal branch의 역할이라고 보면 되겠다.
텍스트 인코더는 일부만 freeze 돼 있고 나머지는 학습된다. 사전에 습득된 텍스트 이해 능력을 일부 그대로 사용하며 학습 비용을 절감하기 위함이다. large language model을 transfer learning을 할 때 주로 사용되는 방법이다. 반면에 이미지 인코더는 고정시키는 곳 없이 모두 학습되는데 이는 CLIP이 학습하는 데이터와 STR에서 사용하는 데이터 간의 도메인 갭을 완화하고 STR에 맞춰 학습시키기 위함이다. CLIP은 웹에서 수집된 natural image로 학습됐지만 STR은 이런 natural image에서 텍스트가 있는 부분만을 크롭한 이미지로 학습된다. 그리고, cross modal branch에서 visual branch로 gradient가 흐르지 않도록 해 image 인코더에서는 오직 이미지 정보만을 가지고 초기 예측을 수행하도록 한다.
이미지 인코더를 g, 텍스트 인코더를 h, 입력 텍스트와 이미지를 각각 t, x라고 할 때 인코더를 타고 나오는 text, image, cross-modal feature는 모두 다음과 같이 나타낼 수 있다. L_t, L_i는 텍스트 시퀀스, 이미지 토큰의 개수이고 D는 임베딩 공간의 차원수다. cross-modal feature에 대해 시퀀스 길이는 L_i와 L_t를 더한 L_c가 되겠다.
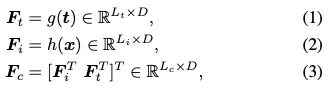
Decoder
두 브랜치에서의 디코더는 인코더로 부터 추출된 F_i, F_t를 가지고 text의 character 정보를 얻고자 한다. 아래는 디코더 단의 학습 과정을 도식화한 것이다.
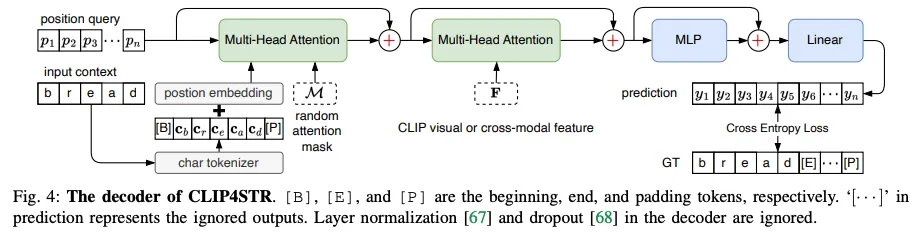
트랜스포머의 구조를 기반으로 두며 앞서 소개했던 PSM이 적용돼 있다.
두 브랜치에서의 디코더는 구조는 동일하지만 입력되는 게 다르다. 학습 가능한 position query p, 입력되는 context c, 랟덤하게 생성된 attention mask를 입력받고 출력으로는 N개의 텍스트 시퀀스의 길이와 C개의 character class에 대해 y의 예측을 반환한다. 디코딩 과정을 다음 한줄로 요약된다.
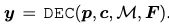
디코딩 과정을 한줄 씩 풀어보면 다음과 같다.
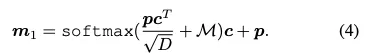
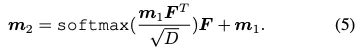
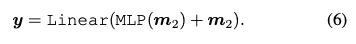
두차례의 Multi head attention을 지나 mlp와 linear projection을 통과해 각 브랜치에서의 결과가 예측된다.
학습 때는 여러 다른 char 배열에서 각 단어가 위치하게 되는 그 관계를 파악하기 위해 attention mask가 일반적으로 left-to-right한 방향으로 이전 출력만을 참조하도록 마스킹 됐던 게 가능한 모든 조합에 대해 랜덤하게 생성돼서 적용된다. 디코더 단에서 첫번째 멀티 MHA에서 입력되는 마스크가 그 부분이다.
학습 때 한번의 입력에 대해 총 6개의 마스크를 적용한다. 2개의 첫 마스크는 left-to-right, right-to-left 방향을 따르는 마스크를 사용하고 나머지 4개에 대해서는 입력 토큰에 대해 가능한 조합 중 4개를 랜덤으로 선택해 생성한다. (이때 출력된 토큰만을 참조할 수 있단 건 일반적인 attention mask에서와 같으니 이 점을 유의해야 한다.)
CLIP4STR은 두 브랜치에서 예측되는 텍스트 시퀀스에서 각 character에 대한 cross entropy의 합을 최종 loss로 하며 이를 줄이도록 최적화된다.
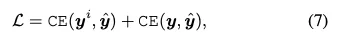
4. Experiments
A. Experimental Details
실험은 CLIP 모델을 달리해 비교했다. CLIP-ViT-B/16, CLIP-ViT-L/14, CLIP-ViT-H/14를 이용해 진행했다. 아래는 각 모델 사용시 함께 적용했던 파라미터 값들이다.
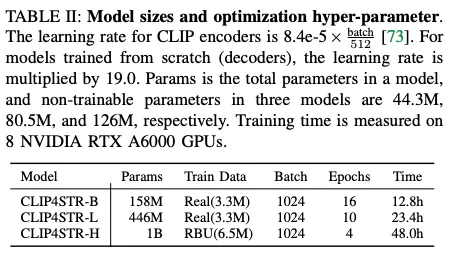
그리고 벤치마크 성능은 대중적인 STR에서의 벤치마크 데이터셋을 사용해 검증하였다. STR 이미지에 대해서 한번 더 학습할 때 다음의 데이터셋을 사용하였다. 1) MJ + SJ (두개의 합성 데이터를 더한 데이터셋) 2) Real (여러 real image 로 구성된 여러 데이터셋을 더한 것) 3) RBU (앞선 Real 데이터셋에 벤치마크 데이터셋의 일부를 더한 것)
입력되는 이미지 크기는 224×224로 고정된다. [B] 토큰과 [E] 토큰을 포함해 총 텍스트 토큰의 개수는 N=26으로 설정하였다. (시퀀스의 길이를 25로 고정한 셈. 디코더 입력에는 [B] 토큰이 출력에는 [E] 토큰이 더해진다. ) 학습 때는 Character class는 94개로 설정되지만 실제 추론 시에는 대소문자 구분을 하지 않고 소문자만을 포함한 36개의 character class로 각 character level로 예측된다.
B. Comparison to State-of-the-art
아래는 10개의 벤치마크 데이터셋에 대해 근래 SoTA의 성능을 달성한 기존에 제안됐던 모델간의 성능을 비교한 표다. 10개의 벤치마크에 대해 모두 큰 간격으로 기존 SoTA 성능을 넘으며 새롭게 SoTA 성능을 내었다. 특히 occlusion 데이터셋에 대해서 성능 향상이 큰 실험 결과가 인상적이다. regular, irregular 텍스트에 대해서 모두 높은 정확도를 보인다. CLIP을 사용한 CLIP-OCR, CLIPTER과의 결과 비교도 함께 주의 깊게 볼 부분이다. 비교 둘보다 간단한 모델 설계로도 충분히 더 나은 결과를 보였다.
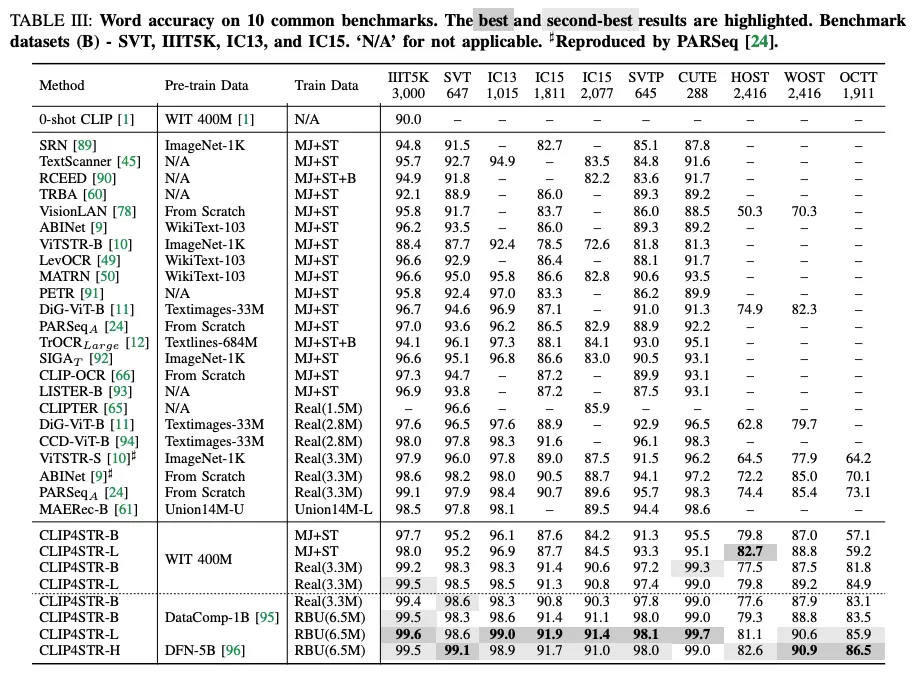
위 테이블은 작은 크기의 데이터셋에 대한 벤치마크 성능이고 아래는 그보다 더 큰 데이터셋에 대한 성능이다
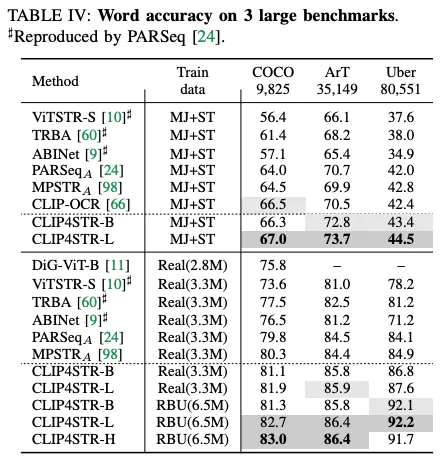
학습 데이터와 무관하게 동일한 경향을 보인다.
5. Empirical Study
아래는 CLIP4STR을 구성하는 모든 요소에 대한 ablation study를 진행한 결과다.

베이스라인은 ViT로 ViT-S을 사용하며 STR 데이터로 학습되지 않았다. 여기에 PSM을 visual decoder와 PARseq에서의 학습 과정을 그대로 따랐을 때 0.7% 정도의 성능 향상이 됐다. 이미지 인코더를 CLIP-ViT-B/16으로 바꿨을 때 눈에 띄는 변화는 없었다. CLIP이 가지는 장점을 최대한 활용하기 위해 앞서 따랐던 학습 과정에서 조정했더니 비교적 성능 차이를 보였다. 여기서 다시 한번 PSM의 효과를 보기 위해 제거하고 실험한 결과는 0.8 하락한 결과를 보이며 유효성이 다시 한번 확인됐다고 할 수 있다.
또한 이 논문에서의 또 다른 contribution이었던 cross-modal branchㅣ를 추가했을 때의 성능 향상을 보인 것으로 이에 대한 유효성도 확인이 됐다. class나 EOS 결과만을 사용하는 것 보다 모든 패치의 feature를 전부 활용하는 것이 더 효과적이다. 또한 모델 크기를 키워도 성능 향상을 보였다.
아래는 이미지. 텍스트 인코더에 레이어를 freeze 시키며 그 영향을 확인한 실험이다. 이미지 인코더를 freeze 하는 것 보다 텍스트 인코더의 레이어를 추가적으로 freeze 하는 레이어를 늘렸을 때의 영향이 더 작다. Text recognition을 하는 것이 일반적으로 긴 문장의 언어를 이해하는 것 보다 훨씬 쉽기 때문에 사전에 학습된 그 가중치 그대로 적용해도 크게 limitation을 보이지 않았다고 저자는 설명한다. 하지만 CLIP이 학습됐던 natural image와 STR 이미지간의 도메인 갭은 상당히 커 freeze 시킬 수록 하락하는 정도가 컸다. 이런 이유로 저자는 이미지 인코더는 모든 레이어를 전부 다시 학습시키기로 결정한 것이라고 할 수 있다.
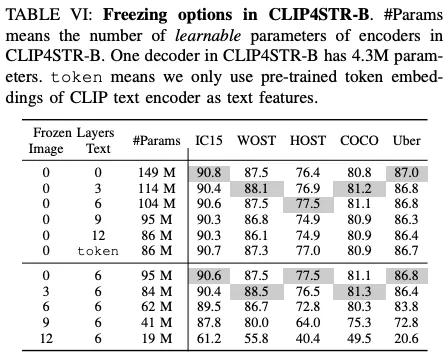
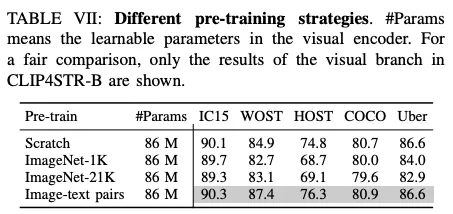
아래는 CLIP 이미지 인코더를 단일 모달리티 즉 이미지를 가지고 classification task로 사전 학습한 ViT로 변경해 그 결과를 확인한 것이다. 이후 학습에서의 learning rate와 학습 과정은 기존 CLIP4STR과 동일하게 유지하고 실험을 진행했다. 결과는 좋지 않았고 오히려 사전학습 하지 않고 랜덤하게 초기화 해 학습한 경우가 더 높은 성능을 보였다. ImageNet으로 이미지 분류를 하도록 학습된 ViT 모델이 충분한 text perception 능력을 기르지 못했다고 설명한다.
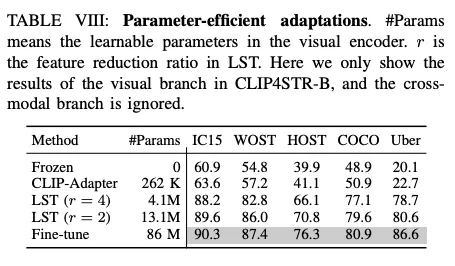
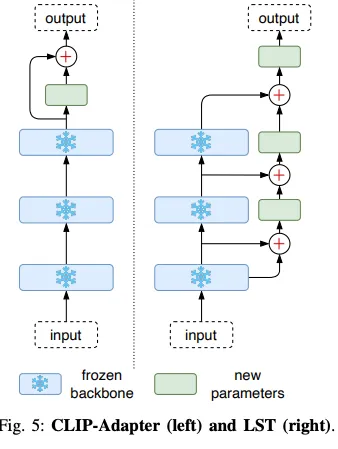
다음은 full fine tune 하지 않고 기존의 VLM은 대부분 freeze 시킨 뒤 학습 가능한 레이어를 붙여 적은 파라미터수로도 효과적으로 학습되는 방법인 parameter-efficient finetuning (PEFT) 두가지를 적용한 결과다. 구조도 또한 함께 아래에서 확인할 수 있다. CLIP을 모두 freeze 시킨 다음에 레이어만 몇 개 추가해 학습하는 CLIP-Adapterd의 방법은 전부 freeze를 시키는 경우보다는 높지만 full fine tuning 한 것과 비교했을때는 역부족이다. LST의 방법은 이보다 좋았지만 여전히 full finetuning 하는 것을 따라잡진 못했다. 하지만 LST의 방법으로 파라미터수만을 늘렸을 때 성능 향상이 있어 학습 자원이 한정적일 때 대안책으로 사용될 수 있겠다고 한다.
아래는 CLIP4STR의 정량적인 결과다. irregular한 텍스트도 강건하게 잘 인식함을 확인할 수 있다. 추가적으로 일부 가려진 경우에도 이를 채워넣는 능력이 탁월하다. 하지만 이를 정량적으로 확인하는 실험은 진행하지 않았다.

6. Conclusion
지금까지 CLIP4STR에 대한 리뷰를 했습니다. VLM 모델을 STR 태스크에 효과적으로 적용한 방법이라는 생각이 들고 고로 기존 모델 보다 더 정확한 인식 성능을 내지 않았나 싶습니다. CLIP이 가지는 linguistic한 지식을 가지고 모델의 예측을 refine 해 보정하겠다는 방식이 간단하지만 그 효과는 대단한 것 같습니다. 저는 지금 industrial domain에서의 text recognition을 개선할 방법에 대해서 찾고 있습니다. 파운데이션 모델을 활용하는 방법은 없을까 하고서 읽게 된 논문인데요 물론 serial number가 대부분인 industrial text에는 숫자 조합의 규칙 말고는 특별히 텍스트 자체에 의미가 없기 때문에 이 논문에서의 방법론이 충분히 효과적이지는 않겠다는 생각이 듭니다. 그래도 STR에 처음으로 효과적으로 파운데이션 모델을 적용한 연구라는 점에서 굉장히 흥미롭게 읽었습니다.
그럼 이만 리뷰 마칩니다. 읽어주셔서 감사합니다!
안녕하세요. 좋은 리뷰 감사합니다.
본 논문에서 CLIP이 기본적으로 irregular text를 잘 인식한는 것을 보이기 위해 수행한 실험을 보면, 고양이 그림에 Horse라고 적힌 스티커를 붙인 것으로 보이고 이에 대해 전부 Horse라고 예측한 것으로 보았습니다. 이런 겨로가에 대해서 그냥 text에 대한 CLIP의 perception 능력이 확인됐다고 하고 넘어갔는데, 왜 text 이미지와 text transcription 끼리 alignment가 맞도록 학습하지 않았음에도 이런 결과가 나온 것인지 궁금합니다. 또, decoder 단에서 left-to-right나 right-to-left 방향으로 인식해 나간다고 했는데, 만약 세로로 틀어진 경우에는 어떻게 동작하는지 궁금합니다.
감사합니다.
안녕하세요 질문 감사합니다.
해당 실험은 아래 연구를 재현한 것이었는데요 파인 튜닝을 하지 않은 이미지에 대해서 결과를 보였다고 합니다. 해당 연구에서도 CLIP이 생각 했던 것 보다 text를 읽는데 탁월했다고 설명하더군요.
논문의 저자는 CLIP이 웹 상의 대량의 데이터셋에 대해 학습할 때 scene text를 포함하는 이미지를 학습했기 때문에 앞선 결과에서 보듯 text perception 능력을 얻게 된 게 아닐까라고 설명합니다.
(링크: https://stanislavfort.com/blog/OpenAI_CLIP_stickers_and_adversarial_examples/)
두번째 질문에 답변을 드리면, 우선 해당 논문에서 제안하는 방법은 기존 STR 모델이 따르던 left-to-right이나 right-to-left의 순서를 따르지 않고 랜덤한 순서로 예측됩니다. 예를 들면 cat이란 단어를 인식하는 과정에서 ‘t’->’c’->’a’ 순으로 예측을 수행한다고 보시면 됩니다. text가 horizontally하지 않고 수직으로 나열된 경우에 대해서 질문을 주신 것 같은데요 그 부분도 랜덤한 순서로 각 글자가 예측될 것으로 생각합니다.
감사합니다.
하이요. 우선 질문에 들어가기 앞서 정정사항 하나 말씀드리면 제목 옆에 보통 해당 논문이 어디에 붙었는지 학회명이나 저널명을 붙이는데 지금 IEEE 라는 출판사 이름을 넣은 것 같아요. 해당 논문 찾아보니 Transaction on Image Processing (TIP)에 붙은 것 같으니 참고 바랄게요.
저도 웬만하면 다른 사람 질문한 부분을 물어보지는 않는데 이건 물어봐야할 것 같아서요. 윤서님이 앞서 댓글 단것처럼 intro 소개할 때 사용된 고양이와 horse 글씨에 대하여 CLIP 모델의 output 결과값이 참으로 흥미로운데, 제가 알기로 CLIP은 말 그림과 “horse”라는 단어에서 각각 추출한 특징들이 서로 같아지도록 하는 contrastive learning 기반으로 학습되는 것으로 알고 있어요. 그래서 실제로 “horse”라는 글씨가 적인 이미지와 “horse”라는 text 사이에 관련성은 학습을 안한 것으로 생각했는데 저 그림1의 결과는 그럼 글씨가 적힌 이미지와 글씨 사이의 관련성을 모델이 스스로 알게 된건가요? 아니면 학습에 사용된 데이터에 저 텍스트 영상과 실제 텍스트 사이가 같아지도록 학습이 된건가요?
그리고 2번째 질문은 그림 2번에 대해서 CLIP이 scene text recognition도 잘하는지를 평가한 것인데, CLIP은 원래 그냥 백본 아닌가요? 그림2와 같이 이미지 입력으로 했을 때 text 값이 이렇게 나왔다고 어떻게 추론한건가요? 이 (가령 코카콜라 텍스트가 적힌) 이미지와 가장 연관성이 높은 text를 100개의 text list 안에서 찾아줘. 같은 식으로 찾은건가요? 아니면 이러한 pre-defined text list 없이 모델이 영상 입력 받아서 곧바로 text를 예측한건가요?
안녕하세요 정정과 질문 감사합니다.
1. 실험 결과는 해당 종류의 sticker 이미지에 대해서 따로 학습을 하지 않고 분류를 수행한 결과라고 합니다. 논문의 저자는 CLIP이 대량의 데이터셋으로 학습하는 가운데 natural scene에서 text가 포함된 이미지를 함께 학습하며 자연스럽게 image에서 text를 인지하는 능력이 생긴 게 아닐까 하고 설명합니다. 해당 실험이 궁금하시다면 아래의 링크에서 확인해도 좋을 듯 합니다. (https://stanislavfort.com/blog/OpenAI_CLIP_stickers_and_adversarial_examples/)
2. 논문의 저자는 해당 figure에 대해서 STR에 대한 CLIP의 시각화 결과라는 설명 밖에 하지 않아 CLIP에 추가로 text 인식하는 모듈을 붙여 예측한 결과인지는 모르겠으나 각 STR 이미지를 입력으로 주었을 때 CLIP이 집중하던 부분을 시각환 이미지와 해당 STR의 이미지를 옆에 명시한 것 같습니다.