안녕하세요 이번 논문으로는 OWL-ViT를 가져왔습니다. Open world Localization with vision transformer 라는 뜻인데 말을 보면 유추할 수 있듯이 Open world 상황에서 기존 CLIP이 classification만 가능했다면 이를 localization 영역까지 확장한 Google research 논문입니다. 논문 리뷰 시작하겠습니다.
Abstract
앞서 언급했듯이 classification 에서는 large-scale pretrained 모델을 사용하는 것이 잘 되어온 상황이었습니다. OWL-ViT는 간단한 ViT 구조에 contrastive image-text pretraining과 end to end fine tuning을 결합하여 zero-shot 및 one-shot OVOD에서 강력한 성능을 달성한다고 언급합니다. 또한 사전학습된 데이터량과 모델의 크기가 성능 향상에 일관되게 기여함을 분석했다고 합니다.
Introduction
기존 객체탐지 모델은 라벨수가 제한된 데이터에 의존했지만, 이미지-텍스트 쌍을 활용한 contrastive 학습과 언어 인코더의 발전으로 zero shot 객체 분류와 텍스트 기반 작업에서 큰 성능 향상이 이루어졌습니다.
기존 연구들은 language 모델의 능력을 Object detection으로 전이하려고 시도를 하였고, distillation이나 weak supervision 혹인 self training 등의 방식을 사용했습니다.
저자의 모델인 OWL-ViT는 이러한 복잡한 기법 없이도 간단한 구조로 open vocabulary object detection을 효과적으로 수행한다고 어필합니다.
우선 ViT 백본을 가지고 대규모의 image text 데이터로 contrastive pretraining을 수행하고 탐지를 위해 기존 구조에서 token pooling을 제거하고 각 토큰에 detection head를 붙였습니다. 이후 COCO나 LVIS와 같은 데이터셋으로 detection head부분을 학습하여 detection을 가능하게 합니다.
해당 모델의 3가지 contribution을 정리해보면
1. 간단하고 강력한 전이학습 OVOD 모델을 만들었다.
2. one-shot detection 에서 SOTA를 달성하는데, 이전 SOTA 성능을 크게 상회합니다. (26.0 to 41.8 AP50)
3. 저자의 모델을 증명할 자세한 scaling과 ablation이 존재합니다.
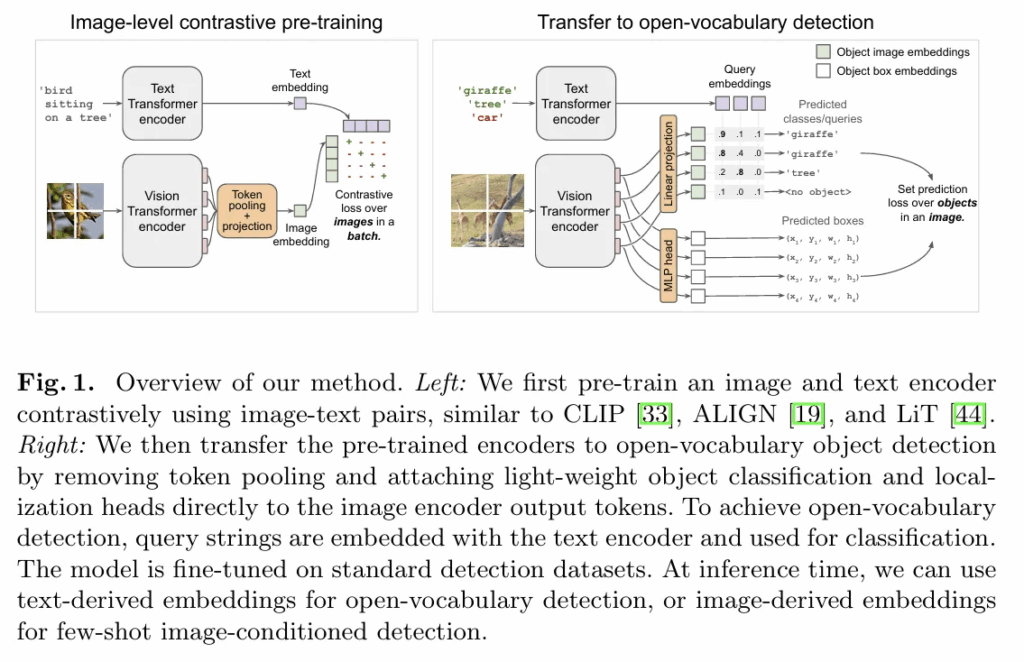
모델 구조입니다.
CLIP 스타일의 사전학습을 통해 이미지와 텍스트쌍의 대조학습을 진행합니다.
해당 과정을 통해 얻은 가중치를 그대로 사용하며 Token pooling을 제거하고 Linear projection을 통한 CLS 예측과 detection head를 붙여 위치를 학습합니다. 해당 과정에서의 linear projection은 ViT encoder 에서 나온representation 을 text 임베딩벡터와 cosine similarity를 계산할 수 있는 형태로 바꿔줍니다. bbox 위치는 MLP를 통해 학습하는 것을 알 수 있습니다.
closed-vocabulary object detection
DETR은 object queries로 100개를 고정하여 object를 찾습니다. 저자는 이러한 additional detection tokens를 쓰는 DETR과는 다르게 patch단위로 바로 object를 찾아서 구조변화가 없다고 합니다.
저자가 언급하지는 않지만 patch개수로 OD를 진행하면 (768/16)^2 개수로 2304개인데 오히려 DETR보다 계산량이 증가하지 않을까 싶기는 합니다. 물론 구조적으로 CLIP을 덜 변화시키기는 합니다.
Image-Conditioned Detection
텍스트 쿼리가 아닌 이미지 한장으로 같은 카테고리의 다른 이미지를 찾아내는 작업에서 이미지의 이름을 모르더라도 이미지의 쿼리를 통해 few-shot이 가능합니다. 기존 CLIP은 단일 이미지와 텍스트를 비교하여 OD가 불가능했지만, OWL-ViT는 패치단위의 cls,bbox 예측으로 이미지속 어디에 nonseen 객체가 있는지 찾기가 가능합니다.
Model architecture
위에 설명했듯이 ViT를 이미지 인코더로, 트랜스포머를 텍스트 인코더로 사용합니다. 이미지 인코더를 detection에 사용하기 위해 token pooling을 제거하고 linearly projection을 통해 classification을 수행합니다. 예측될 객체의 총 개수는 토큰의 개수와 같습니다. 여기서 저자는 576개수의 객체를 찾을 수 있는데 (ViT-B/32 기준 , (768/32)^2) LVIS 데이터셋에서 가장 많은 객체인 294보다 훨씬 많아 충분하다고 합니다. DETR과는 비슷하지만 decoder를 제거한것을 어필합니다. 여기서도 물론 많은 객체를 찾는거에 대한 게산량 단점은 언급하지 않습니다.
Open-vocabulary object detection
OVOD 에서는 OD를 하기 위해 텍스트 임베딩을 사용하고 이를 queries라고 부릅니다. 카테고리 이름이나 기타 객체에 대한 캡션들을 텍스트 인코더에 통과시켜 얻고 이때 query가 각 이미지마다 다를 수 있기 때문에 각 이미지마다 구별되는 라벨 공간이 정의됩니다. 이러한 방식은 기존의 closed vocabulary 방식을 포괄하는 방식인데 만약 모든 클래스 이름을 query로 사용한다면 이는 일반적인 closed set object detection이라고 합니다.
One or Few shot Transfer
저자의 방식은 query embedding이 반드시 텍스트 기반일 필요가 없다고 합니다. 이미지로 만든 임베딩도 쿼리로서 사용할 수 있고 이러한 구조는 텍스트로 설명하기 어려운 객체의 경우 이미지 임베딩을 쿼리로 사용하는 방식이 매우 효과적일 수 있다고 합니다. ViLD나 GLIP MDETR 같은 경우는 CLIP 기반의 이미지와 텍스트 특징을 concat하여 이용하거나 joint encoder 에 넣어서 비교하기 때문에 이러한 방식이 불가능하다고 합니다.
Image-level Contrastive Pre-training
clip에서처럼 이미지-텍스트 데이터셋으로 대조학습을 적용하고 ( 사전학습 )
모델의 대부분의 파라미터가 encoder-only 구조로 인코더에 존재하여 downstream task에 fine tuning 시 기존의 사전학습된 파라미터를 효과적으로 이용할 수 있습니다.
Training the Detector
기존 closed-vocabulary 탐지기와 거의 동일한 절차를 가지지만 이미지마다 객체 카테고리 이름들을 query로 제공하다는 차이점이 있습니다.
DETR의 bipartite matching loss를 사용하되, long-tailed / open-vocabulary detection 문제에 맞게 아래와 같이 조정합니다.
모든 이미지를 완벽하게 라벨링하는 것은 어렵기 때문에, 객체가 여러 라벨을 가질 수 있게함.
일반적인 softmax대신 sigmoid 방식의 focal cross entropy loss를 사용
softmax는 하나의 class만을 가지는데 federated dataset은 한 객체가 animal, dog, golden retriever 모두와 관련을 가질 수 있기 때문에 sigmoid로 multi-label을 선택할 수 있습니다. focla loss는 클래스의 불균형이 심각할때 적합하다고 합니다.
(추가로 softmax나 sigmoid를 사용하여 나오는 확률값을 confidence score로서 사용하지만, 이는 실제 확신하는 정도를 완벽하게 대변하기 어렵습니다. 지수함수는 작은값에도 민감하게 확률값이 달라지므로 이를 보완하기 위해 CLIP 에서도 사용하는 similariy 계산에서의 temperature scaling을 0.01값으로 고정하여 사용한다고 합니다.)
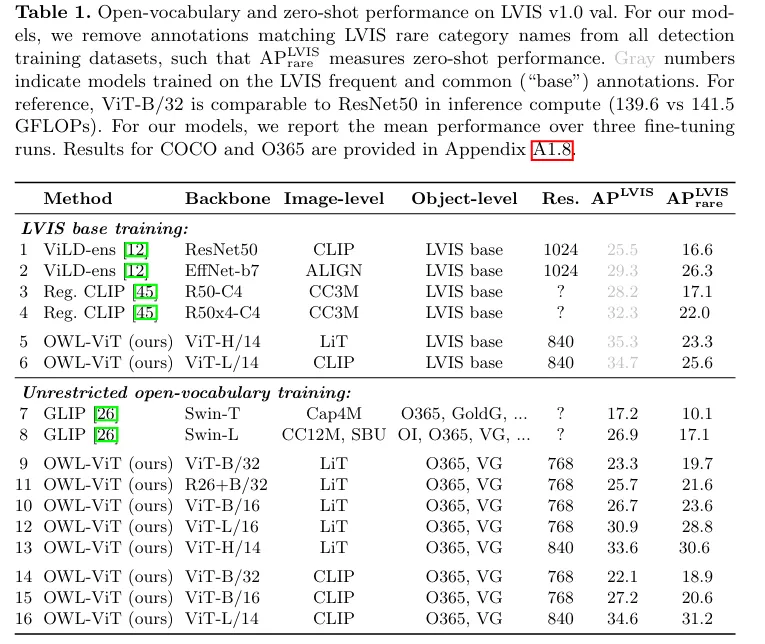
OWL_ViT를 학습할때 LVIS에 존재하는 rare category들을 훈련용 데이터셋에서 모두 제거한 버전의 real zero shot 성능이 AP LVIS rare 입니다. 이때 LVIS 는 COCO 기반의 long-tailed OD 데이터셋입니다. (rare/common/frequent로 분류) 이중 rare 제외한거만 학습합니다.
Open Vocabulary detection performance
LIVS는 클래스가 많고 희귀 클래스 비율이 높아 open vocabulary 평가에 매우 적합한 벤치마크라고 합니다.
1203개의 클래스가 있고 이를 텍스트 query로 넣어서 탐지합니다.

one shot 성능의 figure로 텍스트쿼리로 luna moth 를 주는거보다 이미지를 query로 줬을때 효과적임을 보입니다.
Few-shot Image-Conditioned Detection Performance
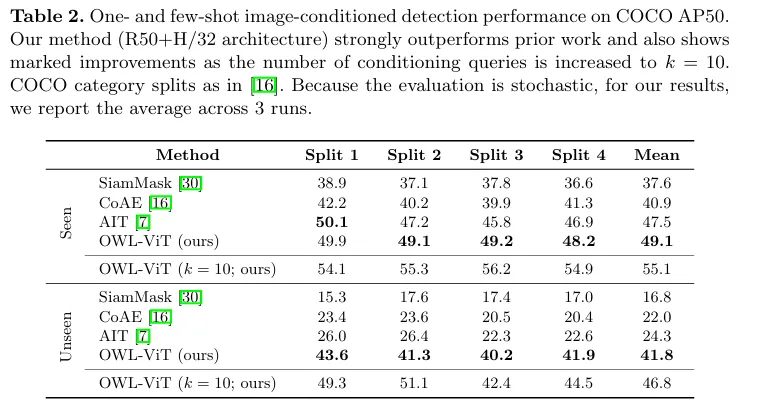
이미지 기반 one-shot & few-shot OD 성능입니다.
COCO 일부 클래스를 학습에서 제외하여 seen, unseen을 평가합니다. (k 값이 few shot 장수입니다.)
Scaling of Image-Level pre-Training
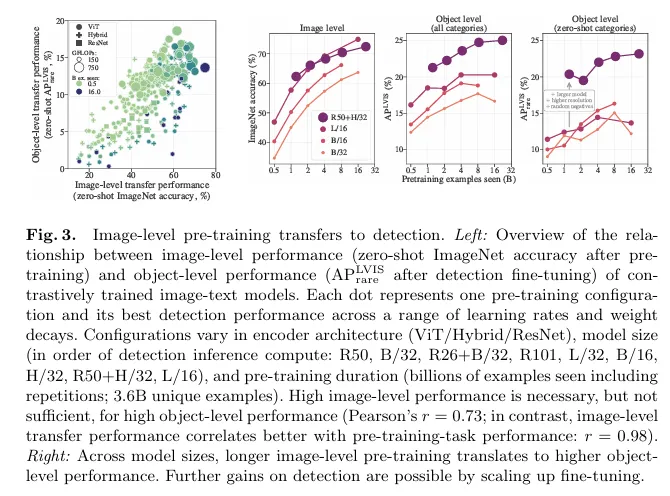
좌측 그래프
x축: 이미지 – 텍스트 사전학습 성능
y축: LIVS rare 클래스의 제로샷 성능
사전학습 성능이 좋아야 탐지 성능도 좋지만, 사전학습이 좋아도 탐지 성능이 좋은게 보장되지는 않는걸 보입니다.
우측 그래프
사전학습 데이터량이 많아지면 탐지 성능이 오르긴 하지만 한계가 존재하여 모델크기나 fine tuning이 필요하다고 합니다.
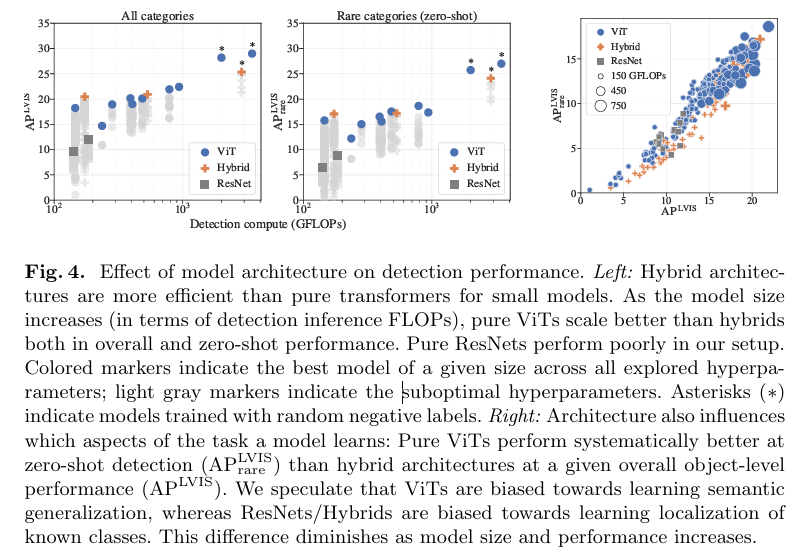
x 축은 연산량 FLOPs 이며 y축은 AP LVIS 값입니다.
이때 연산량이 적을땐 hybrid 모델이 더 좋고 연산량이 늘어감에 따라 ViT모델 성능이 더 좋음을 알 수 있습니다.
이를 저자는 scaling effeciency가 ViT가 좋다고 설명합니다.
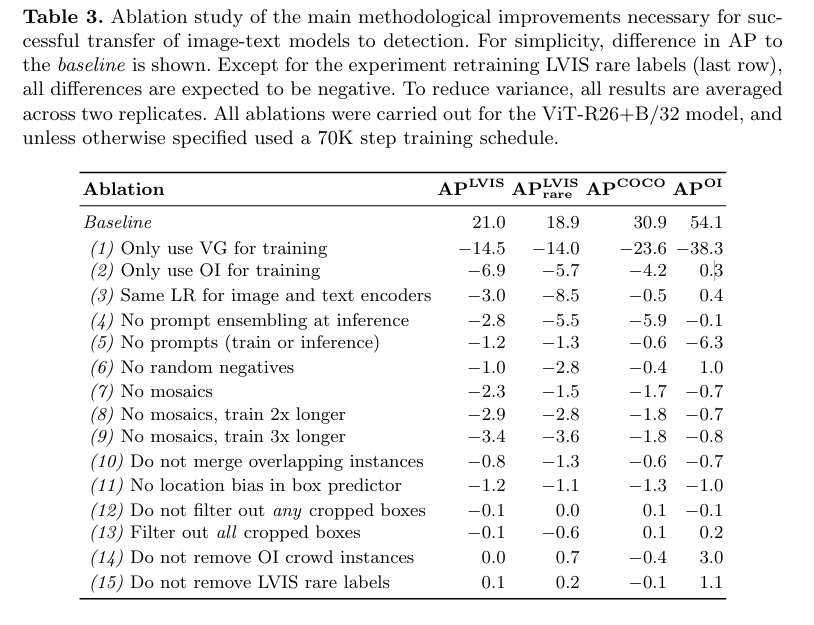
Ablation으로 사전학습때 VG나 OI 데이터셋만 사용하는것이 가장 성능에 영향을 주는 것을 알 수 있습니다.
random negative는 명시적으로 pair가 아닌 쌍을 negative로 학습하는 것입니다.
mosaics은 이미지를 여러장 붙여 학습에 이용하여 더 다양한 배경을 보게하고, 작은객체 탐지를 위한 data augmentation이라고 보면 됩니다. 이때 batch size가 늘어나는 효과도 있습니다.
마지막의 Do not removes LVIS rare labels 부분은 학습시 rare를 없애 온전한 zero shot 성능을 위해 진행하였던 부분으로 제거하지 않으면 성능이 오르는 것을 확인할 수 있습니다.
Conclusion
CLIP 이 나오고 1년 반쯤 뒤에 OD task에도 접목시킨 여러 논문중 하나로 CLIP 의 구조를 간단하게 변화시키면서도 좋은성능을 내는 모델입니다. 실제 코드를 살펴보아도 CLIP에 사용된 ViT encoder를 그대로 불러오고 DETR의 함수들을 재사용하여 모델 구조를 쉽게 이해할 수 있게 되어있습니다. 해당 논문을 baseline으로 추가적인 방법론들을 적용시켜 창의학기제도 진행할 예정입니다. 읽어주셔서 감사합니다.
안녕하세요 신인택 연구원님 리뷰 잘 읽었습니다.
읽다가 생긴 질문들 남깁니다.
1. OWL-ViT는 DETR과 다르게 따로 object query를 학습하지 않고 인코딩된 패치에 대해서 각각 예측을 수행한다고 설명해주셨는데요 그러면 패치 하나당 객체 하나가 대응되는 걸까요? 그건 왠지 아닐 것 같은 생각인데요.. 설명 부탁드립니다.
2. 그리고 텍스트 대신 이미지를 쿼리로 사용해도 가능하다고 하셨는데요 이때 이미지는 비전 인코더에 넣지만 projection 은 수행하지 않는다고 이해하면 될까요 아니면 텍스트 인코더에 이미지를 입력하는 걸까요?
3. 마지막으로 OWL-ViT가 어떻게 non seen 객체에 대한 이해와 예측이 가능할 수 있는지가 궁금합니다.
안녕하세요 지연님 답변 감사합니다. 질문에 답해드리자면
1. 우선 본문에서 OWL-ViT는 DETR과 다르게 decoder를 사용하지 않고 추가적인 detection tokens가 필요하지 않다고 언급합니다, 그리고 한 물체를 한 이미지 토큰과 directly 예측한다고 되어있어 패치 하나당 하나의 객체가 대응되는 것이 맞습니다. 추가적인 방법들이 있을수는 있으나 논문의 다른 부분에도 ViT-B/32 를 사용하고 768^2 해상도로 이미지를 넣었을때 576개의 예측이 가능한데 이는 오늘날의 데이터셋중 가장 instance가 많은 것보다 훨씬 높은 숫자라 대응이 가능하다고 되어있습니다.
2, 이미지 쿼리로 사용가능할때 텍스트 인코더를 사용하지는 않습니다. 물론 제일 비슷한 class 가 무엇인지 SIM 계산을 해볼수는 있지만, Fig. 2 에 존재하는 예시로 swallowtail butterfly는 텍스트쿼리로 찾을 수 있었지만 luna moth는 텍스트쿼리로는 찾을 수 없었고 이미지 쿼리로 찾을 수 있었다는 것과 같이, rare class에 대해 임베딩 공간에 존재하지 않는 정보는 이미지끼리의 SIM이 높은 객체를 찾는 데에 사용할 수 있다는 것입니다.
3. non seen 이라는 개념이 조금 모호하다고 생각하는데, 이러한 zero shot 이 가능한 모델들도 단한번도 본적 없는 데이터는 사실 구별해낼 수 없습니다. 다만 굉장히 많은 데이터셋으로 최대한 넓은 임베딩 공간을 만들어 비슷한 simulariy를 가지는 객체를 찾을 수 있게하여 지도학습 기반이 아니어도 zero-shot 이 가능하다고 주장하는 것인데, OWL_ViT가 non seen이 가능한건 CLIP의 이미지 인코더와 텍스트 인코더를 그대로 사용한 것 때문에 사전에 본적이 없더라도 가장 비슷한 표현을 가지는 객체를 유추해낼 수 있다고 생각하면 될 것 같습니다.
안녕하세요, 좋은 리뷰 감사합니다.
제가 OWL-ViT 논문을 제대로 읽어본 적이 없어서 재밌게 읽었습니다. 읽다 보니 몇가지 궁금한 게 있어서 질문 남기겠습니다.
1. 기존의 ViT 구조에서 token pooling을 제거했다고 하는데, token pooling이 구체적으로 무엇이고 어떤 목적으로 사용되는것인가요? 그리고 OWL-ViT에서는 왜 제거된 것인가요?
2. contrastive learning으로 사전학습을 하려면 대규모 image-text pair 데이터셋이 있어야 할텐데, 이 데이터셋은 무엇을 사용하나요? clip을 그대로 사용하는것은 아닌 것 같아서 질문합니다.
3. finetuning은 어떻게 진행하나요? 본문 보면 객체 분류 라벨값이 원핫벡터가 아니라 soft-label인것처럼 작성되어있는데, 이를 위한 특수한 데이터셋을 사용한건가요?
안녕하세요 재연님 답글 감사합니다.
질문에 답해드리자면
1. 기존의 ViT 구조는 OD 를 수행하기에 적합한 구조가 아닌 classification을 위한 CLS 토큰과 각 이미지 패치들의 attention 구조를 이용하여 전체 이미지의 글로벌 피처로 사용합니다. 이를 token pooling이라는 명칭으로 사용한 것이고, OWL_ViT 에서는 OD를 수행하고자 사전학습때만 이미지 인코더의 학습을 위해 token pooling을 사용하고 이후 downstream task에서는 불필요하여 제거하고 detection head와 linear projection 부분을 추가하는 것입니다.
2. “Pre-training is performed from scratch as in
LiT [44] (uu in their notation) on their dataset of 3.6 billion image-text pairs.” 이라고 언급되어 있는데 36억쌍의 웹 기반 noisy한 데이터입니다.
3. 파인튜닝은 이미지 인코더와 텍스트 인코더는 freeze 시켜놓고 COCO, LIVS 등의 데이터셋으로 지도학습을 진행합니다. soft label처럼 보이는 것은 LVIS 데이터셋의 특성때문인데 long tailed 분포에 학습시키는 데이터가 GT가 존재하는경우, 존재하지 않는경우, 그리고 알 수 없는 경우로 나뉘기 때문에 soft label처럼 학습을 시키고 평가때는 hard label로 평가합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
OWL ViT가 생각보다 단순한 방법으로 detection을 한다는 점이 놀라웠습니다. 여기서 생기는 의문점이 하나가 있는데요
리뷰에서는 자세하게 다뤄주시진 않은 것 같지만, 구조적으로 고정된 patch size를 사용해 토큰 레벨로 bounding box를 예측하는 방식으로 보이는 것 같습니다. 그런데 실제 이미지에서는 객체의 크기가 제각각일 수 있는데, 이렇게 고정된 patch size를 사용하는 경우, 크기가 큰 객체 혹은 작은 객체에 대해 발생할 수 있는 표현력의 제한이나 scale 부분에서의 detection 성능 문제는 없었는지가 궁금합니다.
안녕하세요 우현님 질문감사합니다.
충분히 들 수 있는 의문입니다만 논문에서는 작은객체에 대한 성능이 안좋다거나 하는 언급은 없었습니다.
다만 넓은 scale의 ViT로 학습이 된 만큼 작은 객체에 대해서도 충분히 경쟁력 있는 성능을 보입니다. 물론 엄청 작은 객체에 대해서는 FPN 등을 사용하는 백본 모델보다는 작은객체 검출률이 낮을 수 있다고 생각합니다. 감사합니다.