안녕하세요, 이번주 x-review는 Amazon Robotics에서 나온 시뮬레이터에서 활용 가능한 asset generation에 관한 논문입니다. 기존의 논문들과 다르게 3d reconstruction을 진행할 때 pick and place setup을 이용해 사람이 카메라를 움직여가며 스캔하는것이 아니라 카메라를 고정해둔 채 물체를 카메라 앞에서 회전시키며 진행합니다. 뿐만 아니라 물체를 집고있는 상태에서 로봇을 이리저리 움직이며 토크 센서의 값들을 통해 inertia matrix와 같은 physical parameter까지 구할 수 있습니다. 기존의 방법들과 차별화된 파이프라인을 통해서 물체의 asset화에 대한 자동화를 이루어 낸 것 같습니다.
Introduction
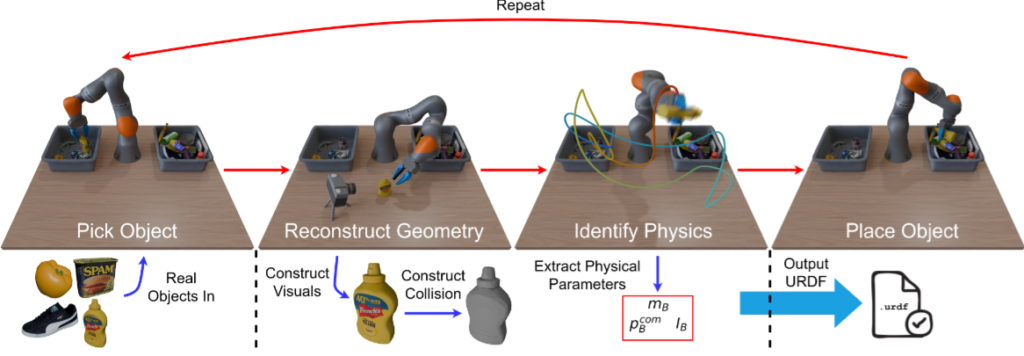
Sim2Real 패러다임은 시뮬레이션 환경이 현실과 매우 유사할 때 잘 작동하지만, 이러한 시뮬레이션을 위한 asset을 생성하려면 일반적으로 실제 물체를 수작업으로 모델링하고 물리적 파라미터를 조정해야 했습니다. 다만 asset을 생성하는 프로세스는 느리고 전문 지식이 필요하며 많은 수의 오브젝트로 확장할 수 없는 한계를 지니고 있다고 합니다. 이전의 Real2Sim 방법은 오브젝트 geometry를 캡쳐하거나 물리량(질량, 관성, 마찰)을 식별하는 데 중점을 두는 경우가 많았지만, 두 가지를 함께 사용하는 것은 아니었다고 합니다. 또 생성형 ai를 사용한 연구들은 이미지와 텍스트로부터 3D 에셋을 합성할 수 있지만, 이렇게 얻은 asset은 실제 물체의 물리적 동작과 일치하지 않을 수 있다고 합니다. 따라서 저자들이 제안한 Scalable Real2Sim은 매니퓰레이터와 RGB-D 카메라만으로 visual mehs, collision mesh, inertia matrix를 포함한 완전한 시뮬레이션 자산을 자동으로 생성합니다. 매니퓰레이터가 물체를 집어 든 뒤 카메라 앞에서 회전, 그립을 반복하며 모든 면을 스캔하고, 정보량을 극대화하도록 설계된 궤적을 따라 물체를 흔들어 관성 파라미터를 식별한 후 다음 물체로 넘어가는 구조입니다. 저자들은 contribution으로 완전 자동화된 real2sim 파이프라인과 더불어 그리퍼에 가려진 부위 또한 투명화 파라미터를 사용해 모든 radiance field 방법들에서 그리퍼에 가려진 부분을 복원할 수 있음을 언급했습니다.
Methods
Scalable Real2Sim 파이프라인은 로봇 매니퓰레이터, 두 개의 bin, 그리고 외부 RGB-D 카메라로 구성된 전형적인 pick and place 세팅입니다. 파이프라인을 통해 각 물체마다 세 가지 시뮬레이션 자산을 생성합니다. 텍스처가 입혀진 visual 메시, 볼록 메시들의 합으로 이루어진 collision 메시, 질량·무게중심·회전 관성으로 구성된 물리 파라미터 P를 생성하게 됩니다.
데이터 수집 단계에서 로봇은 아래와 같이 두 개의 서로 직교한 축을 중심으로 물체를 회전시키며, 필요할 때마다 재그립을 수행해 그리퍼로 인한 가려짐을 최소화한다고 합니다. 이렇게 하면 모든 면이 카메라에 노출되어 완전한 표면 정보를 얻을 수 있다고 합니다. 또 스캔 도중에 얻은 과다한 RGB 프레임은 계산 효율을 위해 다운샘플링한다고 합니다. K번째 프레임마다 프레임을 하나씩 고르고, 이후 남은 프레임 중에서 이미 선택된 프레임들과 DINO 특성 공간에서 코사인 거리가 가장 큰 프레임을 반복적으로 추가해 총 N 장의 이미지 세트를 완성합니다. 이후 파이프라인의 단계들을 위해 프레임들에 대해 SAM2로 물체와 그리퍼의 마스크를 추출합니다.
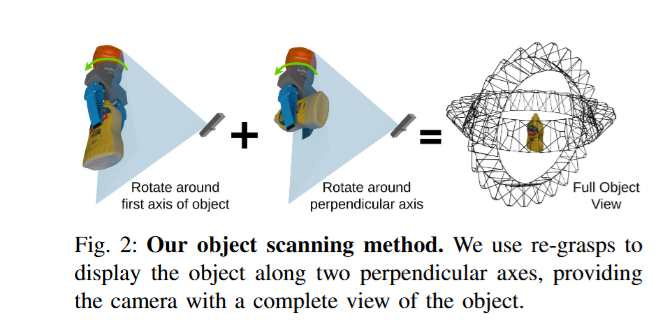
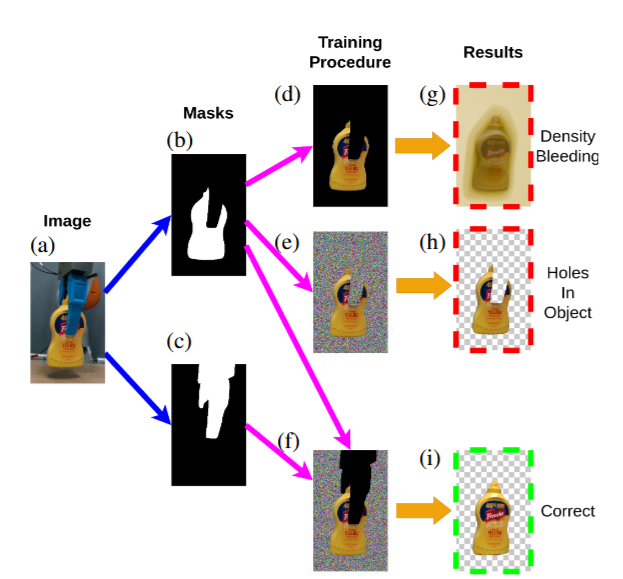
재구성 단계에서 모델은 객체 중심 텍스처 메시를 얻는다. 기존 방법들은 주로 정적 장면을 재구성하지만 scalable real2sim 파이프라인 설정에서는 물체가 움직이고 카메라는 고정되어 있기 때문에 기존의 3d reconstruction 방법들을 그대로 적용할 수 없다고 합니다. 따라서 물체 좌표계를 월드 좌표계로 재정의하고 배경 픽셀을 모두 마스킹해, 비마스킹 영역(실제 물체)이 새 월드 좌표계에서는 정적이 되도록 만든다고 합니다. 이후 camera pose를 역으로 추정해서 카메라가 움직이는 대신 물체가 정지한 기존의 상황으로 변환한다고 합니다. 학습 시에는 물체 마스크를 이용해 물체 픽셀만 사용하지만, 배경을 완전히 배제하면 density bleeding 현상이 발생하기 떄문에 이를 막기 위해 alpha-transparent 학습을 사용한다고 합니다. 이 방법은 학습 데이터의 배경 픽셀을 iteration마다 무작위 색으로 바꾸고, 예측 이미지에도 동일 색을 투영해 모델이 배경에 0 밀도를 할당하도록 유도한다고 합니다. NerfStudio에도 적용해서 object centric한 reconstruction을 진행할 수 있게 했다는데 코드로 확인을 해봐야 할 것 같습니다. 그리퍼로 인한 가려짐은 투명 영역으로 잘못 처리될 수 있기 때문에 그리퍼 마스크를 우선 적용해 해당 픽셀을 loss 계산에서 제외한다고 합니다.
아래 그림과 같이 정리를 해보자면 먼저 RGB 이미지들을 수집해서 SAM2를 통해 물체와 그리퍼에 해당하는 마스크를 따내고, 배경 픽셀들을 없애기 위해 마스크를 활용하지만, 이때 물체 마스크만 사용하면 density bleeding 현상이 발생하기 때문에 alpha-transparent를 활용하게 됩니다.(e)처럼 되는데, 이 때 그리퍼에 가려진 영역도 투명화가 되기 때문에 그리퍼 마스크를 통해서 그리퍼에 해당하는 부분의 alpha transparent 부분을 계산에서 제외하면 결과적으로 (i)와 같은 결과를 얻을 수 있다고 합니다.
시각적인 mesh를 얻은 이후에는 approximate convex decomposition이라는 알고리즘을 활용해 mesh를 단순화된 조각들로 나누고, 이에 대한 collision을 계산한 후에 여러개의 조각을 합친다고 합니다. 다만 이 때 해당 연구에서 사용한 모델이 포인트 접촉 기반의 모델이어서 괜찮지만 collision을 계산하는 모델들에 따라 조각 사이의 틈에 압력이 왜곡돼 dynamics에 이상을 유발할 수도 있다고 합니다. 또 저자들이 사용한 point 기반의 모델들도 조각이 조금이라도 겹치는 경우 내부 접촉점이 생성되는 문제가 있다고 합니다. 따라서 전반적으로 다양한 시뮬레이터에서 범용적으로 잘 동작하는 표현 방식이 향후 목표로 남아있다고 합니다. Collision Mesh를 계산하는 것에 대한 고민을 많이 안 해본 터라 이게 물리량까지 섞여있어서 그런건지 기존의 asset들은 이런 문제가 없는건지 고민을 좀 해봐야 할 것 같습니다.
마지막으로는 물체의 물리적인 파라미터들을 구하게 됩니다. 로봇팔이 아무것도 들고있지 않을 때의 움직임의 관성과 마찰력을 기준으로 물체를 들고있을 때 같은 움직임의 관성과 마찰력의 차이로 질량, 무게중심, 회전 관성 행렬을 통해 psudo-inertia matrix를 계산한다고 합니다. 로봇의 동역학과 관련된 내용들과 수식이 많아서 해당 부분은 자세하게 다루지는 않도록 하겠습니다.. (이해가 필요한 순간이 오면 공부해서 이해해볼 생각입니다..) 텍스트를 통해서 이해한 느낌은 물체를 들고 모든 방향으로 흔드는 과정에서 관성과 마찰력을 구해 그 차이로 “이정도 힘을 느꼈다면 이정도의 질량과 무게중심을 갖는다”를 계산하고 현실적인 범위의 값으로 조정을 거친다고 이해했습니다.
실제로 방법을 적용할떄의 세팅은 다음과 같습니다. 먼저 물체를 가장 안정적으로 잡을 수 있는 안티포달 그립을 계산하고, 충돌 없이 이동할 수 있도록 모션 플래너를 이용해 trajectory를 생성한 뒤. 다음으로 객체 추적 단계에서는 고정된 RGB-D 카메라 한 대로 물체를 계속 촬영하면서, 필터링된 이미지와 물체 마스크를 입력으로 BundleSDF를 실행해 프레임마다 camera pose를 추정합니다. 부산물로 visual gemetry를 생성한다고 나와있는데 bundle sdf를 통한 mesh reconstruction도 진행하는 것 같습니다. 이후 alpha-transparent, 마스킹하는 절차를 거쳐 Nerfstudio의 Nerfacto, Gaussian Frosting, Neuralangelo 세 가지 최신 기법에 그대로 적용해 고해상도 텍스처 메시를 얻는다고 합니다. 마지막으로 물리 파라미터 식별을 수행합니다. 로봇 자체 파라미터를 안정적으로 추정하기 위해 서로 다른 10개의 궤적을 실행해 위치·토크 데이터를 평균 내고, 신호 대 잡음비를 높인다고 하ㅂ니다. 물체 식별은 시간 절약을 위해 한 번의 궤적으로 끝내되, 속도·가속도는 두 번 미분해 구하고 모든 신호는 저역 통과 필터를 거친다고 합니다. 또 그리퍼가 열려 있는 각도를 달리하면 로봇 동역학이 달라질 수 있으므로, 로봇 식별을 여러 그리퍼 폭으로 반복해 두었다가 물체를 잡을 때 가장 근접한 설정을 골라 사용한다고 합니다. 마지막으로 포인트 클라우드를 재구성된 메시에 ICP로 정합해 실제 그립 위치를 정확히 맞추고, 이렇게 얻은 좌표계에서 관성 값들을 계산합니다.

Kuka LBR iiwa 7 로봇 팔에 Schunk WSG-50 그리퍼와 Toyota Research Institute의 Finray 핑거를 장착한 구성이며, 작업 공간은 총 다섯 대의 RealSense로 관측한다고 합니다. Base Cam으로 설정된 D415 카메라 세 대가 고정돼 있고(주황색 원), 오른쪽 에서 물체를 집어 올릴 때는 초록색 원 D435를 통해 인식한다고 합니다. 물체를 스캔할 때는 빨간색 원 부분에 거치된 D415가 사용되고 모든 카메라는 640×480 해상도의 컬러와 깊이 영상을 동기화해 사용한다고 합니다. 640*480 해상도를 사용하면서도 다운샘플링을 하는것으로 봤을 때 앞으로 연구를 진행하면서 높은 해상도를 고수할 이유가 없는것 같다는 생각도 들었습니다.
Results

우선 시각적인 결과는 위에서 볼 수 있듯, 또 기존의 3d reconstruction 파이프라인이 훌륭한 만큼 완성도 있는 모습을 볼 수 있었습니다. 다만 그리퍼와 배경을 잘 날려서 기존의 asset generation 파이프라인과 유사한 결과물이 나왔다는게 대단한 것 같습니다. 그리고 결과물을 다양한 각도에서 바라봤을 때 해당 방법론의 진가가 드러납니다. 물체를 세워두고 캡쳐했을 때 보이지 않는 부분들 (바닥면) 또한 구성이 되어있는 것을 확인할 수 있습니다.

재구성 정확도는 YCB 데이터셋에 포함된 머스타드 병, 통조림, 표백제 용기, 젤라틴 상자 네 종류를 대상으로 평가했다고 합니. 로봇이 직접 스캔해 BundleSDF로 얻은 메시를 해당 객체의 원본 3D 스캐너 모델과 비교해 챔퍼 거리를 계산한 결과, 평균 오차가 각각 0.93 mm, 1.68 mm, 5.58 mm, 0.80 mm밖에 나지 않았다고 합니다.

또 BundleSDF가 생성한 메시에는 경계 면이 흩어져 있거나 non-manifold 정점이 포함되는 등 토폴로지 결함이 잦아, 단순 렌더러나 mesh watertight을 요구하는 시뮬레이터에서 문제가 될 수 있었다는 점도 어필했습니다. 이를 완화하려면 고성능이긴 하지만 느린 Blender Cycles로 렌더링하거나, Neuralangelo 같은 최신 기법을 활용하는 것이 좋다고 합니다. Nerualangelo는 해당 논문에서 처음 접한 방법이라 한 번 찾아봐야 할 것 같습니다. BundleSDF와 Neuralangelo를 비교해보면 texture가 훨씬 더 깔끔한 것을 확인할 수 있습니다.

마지막으로 물리량의 경우 기존의 asset보다 훨씬 정교하게 계산된 물리량이 적용된 만큼 시뮬레이션 환경에서 현실과 매우 유사한 양상을 보일 수 있었다고 합니다. 위의 figure보다는 프로젝트 페이지의 영상을 확인하면 그 차이를 확실하게 볼 수 있습니다. 경사면에서의 무게중심의 역할이나 물체가 넘어가는 양상이 많이 기존의 시뮬레이션과 비교했을 때 굉장히 real world와 유사합니다. 시뮬레이션의 물리엔진의 성능도 완벽하진 않지만 sim2real gap에 asset이 차지하고 있는 비중도 상당하겠구나,, 라는 생각을 해보게 됐습니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
흥미로운 리뷰 잘 읽었습니다!
처음 보는 내용이 많아서 내용 면에서 질문 하나랑, 살짝 발산하는 질문이 하나씩 있는데요.
1. density bleeding 현상과 alpha-transparent의 관계가 무엇인지 잘 이해를 못했습니다. alpha-transparent는 대충 tv에서 없는 채널 돌렸을 때 마치 지글지글한 모습이 나오는 것처럼 배경노이즈 넣는 거라고 이해했는데, 이것이 왜 density bleeding 현상을 막는 것인지 추가 설명 부탁드립니다!
2. collision mesh 만드는 과정에서, visual mesh를 approximate convex decomposition이라는 알고리즘을 활용해 mesh조각을 쫙 쪼갠다음에, 각각 collision 계산하고 그 조각들을 다시 합치는 것으로 이해했습니다.
여기서 ACD(Approximate Convex Decomposition) 논문이 흥미로워서 좀 봤는데, input으로 3D asset이 들어가고 MCTS(Monte Calro Tree Search)라는 비학습 알고리즘 방법론으로 분해된 convex asset들에 대한 output이 나오는 것 같은데, 해당 asset decomposition이 마치 GARField에서의 객체 분해처럼 느껴졌습니다. 영규님이 생각하기엔 혹시 ACD 로 분할된 convex asset의 mesh 표면으로부터 3D point sampling을 하고 난 후 해당 point에 대한 visual feature 유사도 학습 및 clustering 기반으로 grouping하는 것이 가능할까요? GARField에서 쓰인 affinity 기반 contrastive learning + HDBSCAN clustering 처럼? ACD 논문 보니 알고리즘 time cost가 200초 정도 밖에 안 들던데, 그럼 SAM 2D mask 후보랑 3DGS조합 으로 30분 넘게 초기 학습 시간이 걸리는 GARField보다 속도 이점을 가지면서 3D asset decomposition & grouping할 수 있지 않을까 싶어서요. 약간 엥 스러울 수도 있지만 ACD를 처음 봐서 활용도가 좋아보여 질문드립니다!
감사합니다.
안녕하세요 재찬님 댓글 감사합니다
1. Density bleeding 현상의 경우 3DGS와 같이 특정 형상을 묘사할 때 적분의 개념이 들어가는 경우 (한 선 상의 모든 RGBA의 합으로 표현하는 경우) 마스크를 활용해 해당 부분만 업데이트 하면 엣지에 있는 가우시안들이 좀 삐져나와 있어서 계산이 거듭될수록 뿌옇게 흐려지는 현상이 발생하게 됩니다. 그래서 학습중에 배경 픽셀 색을 매 반복마다 무작위로 바꿔서 모델이 배경에 밀도를 채우면 예측 색이 랜덤 값과 섞여 손실이 커지므로, 자연스럽게 배경 밀도를 0으로 만들도록 유도해서 깔끔한 테두리를 얻는가도 합니다.
2. 음,,, ACD를 하고난 한 덩이가 DINO의 feature가 쪼개져있는 부분보다 크거나 하는 일이 발생할 수도 있지 않을까…? 싶습니다. 가능한지 안 한지 확실하게 알 수는 없지만 된다면 확실히 시간을 매우 단축할 수 있을 것 같습니다. 흥미로운 접근인 것 같습니다 ㅎㅎ,,
영규님 좋은 리뷰 감사합니다.
자동으로 물체의 asset을 생성할 수 있는 파이프라인이라는 점에서 활용도가 높은 방법론 같습니다.
물체 마스크만 사용하면 density bleeding 현상이 발생한다고 하셨는데, 이 현상에 대한 설명 부탁드립니다. 윤곽이 뚜렷하지 않은 것을 의미하는걸까요? 그렇다면 물체 마스크를 쓰는 게 윤곽이 뚜렷하지 않을 것 과 어떤 연관이 있는지도 설명 부탁드립니다.
또한, 정성적 결과가 굉장히 잘 나와보이는데, 캐찹 통처럼 형태가 조금 일그러진 경우에는 시뮬레이션 상에서 물체를 세워두기 어려워 이를 활용하는 데 어려움이 있을 것 같습니다. 캐찹 통이 유리라 이런 오차가 발생한건지에 대한 분석이나 이를 보완하는 별도의 평가 시스템은 따로 없었는 지 궁금합니다.
추가로, 해당 논문의 핵심은 자동으로 asset을 생성한 것으로 이해하였는데, 최초로 asset 생성 자동화방식인지, 아니라면 다른 기존의 방법론과 비교한 결과는 없었는 지 궁금합니다.
안녕하세요 승현님 댓글 감사합니다.
Density bleeding 현상의 경우 3DGS와 같이 특정 형상을 묘사할 때 적분의 개념이 들어가는 경우 (한 선 상의 모든 RGBA의 합으로 표현하는 경우) 물체의 마스크를 활용해 오차를 업데이트 하면 모서리에 해당하는 부분에 오차가 반영되지 않은 찌꺼기(?)들이 남아있는 현상을 의미합니다.
케찹통의 경우 플라스틱인데, 로봇이 잡는 힘이 있어서 조금 구겨진 것이 아닌가 생각합니다. 많이 구겨져서 바닥과의 접촉면이 면 단위에서 봤을 때 세우기 힘들 정도로 망가진다면 시뮬레이터 상에서 활용하기 어려운 한계들이 있지 않을까 싶긴 합니다. 이를 보완하는 시도나 평가는 없었습니다.
해당 논문과 같은 접근방식은 제가 아는 한에서는 최초이고, pick and place 구성을 asset generation에 활용했다는 점을 저자들도 contribution으로 주장했습니다.
안녕하세요 영규님 좋은 리뷰 감사합니다. 궁금한 부분이 있어서 남겨놓습니다.
Q1. 그리퍼가 물체를 흔들거나 회전시키면 그리퍼에서 약간의 위치가 변경되거나 그리퍼의 접촉면에서 미끄러지는 경우가 생길 것 같은데, 안티포달 그립으로 해결이 되는 부분인지 궁금합니다.
Q2. 계산 효율을 위해 다운샘플링을 하는 것 같은데, 해상도에 따라서 성능이 달라지는지 궁금합니다.
감사합니다.