안녕하세요 류지연입니다.
저는 이번주부터 Text Spotting이란 새로운 task에 대한 논문을 보고 있습니다. Text Spotting은 이미지 속 단어들의 위치를 찾고 각 단어를 인식하는 task를 말합니다. 자율주행 환경에서 주변환경을 정학히 인식하기 위해 필요한 기술입니다.
*본 논문은 Transformer, DETR, Deformable attention에 대한 사전 지식이 있으면 이해하기가 쉽습니다.
1. Introduction
보통 Text Spotting task는 두 가지 단계로 나눠 다뤄졌었습니다. 이미지에서 텍스트가 있는 위치를 우선 localize한 후 해당 text box 안에서 글자를 인식합니다. (이전 text spotting 모델들은 이미지에서 텍스트가 위치해 있는 영역에 대해 region proposal을 진행하고 그 region에서 recognition 진행합니다 ) 또한 Text Spotting이 쉽지 않았던 데는 이미지에 등장하는 text들이 다양한 형태를 갖는다는 점에 있습니다. 각양각색의 텍스트를 모두 정확하게 인식하는 게 중요한데 이전 연구들로는 이 부분이 충분히 해결이 되지 않았었고 개선이 필요한 상태였습니다.
저자는 이 문제를 해결하고자 TESTR라는 Transformer를 사용해서 text 검출과 인식을 동시에 수행하는 End-to-End 모델을 제안합니다. TESTR은 텍스트 박스에 대해서 고정된 개수의 control points를 예측해서 이를 가지고 굴곡진 형태의 텍스트 박스를 그릴 수 있도록 해 글자가 굴곡져 있어도 잘 인식하도록 구현되었습니다. 또한, TESTR은 기존 방법과 달리 트랜스포머 기반으로 direct하게 텍스트의 위치와 함께 텍스트 인식이 동시에 수행됩니다. 기존 detection 방법론에서는 필요하던 바운딩 박스에 대한 NMS같은 후작업도 필요없어 구조 또한 아주 간단합니다. (TESTR은 DETR를 Text Spotting task에 확장한 것으로 DETR이 detection 과정에서 추가적인 ROI 연산이 필요하지 않던 장점을 그대로 가져갑니다) 그럼 리뷰 계속해 저자가 제안한 방법론에 대해서 자세히 알아보도록 하겠습니다
2. Methods
저자가 제안하는 TExt Spotting TRansformer(TESTR)는 텍스트 검출과 인식을 통합된 프레임워크에서 수행하는 모델이다. 저자는 크게 3가지 contribution을 제안합니다.
1) 단일 인코더에서의 multiple-scale deformable attention (Deformable DETR연구에서와 동일)
2) 이중 디코더 사용 (검출과 인식 분리돼 있지만 동시에 병렬적으로 학습 및 추론 가능함)
3) box-to-polygon detection 과정을 추가한 것이 있습니다.
아래에 각 방법론을 하나씩 자세히 다뤄보겠습니다.
우선 다음은 TESTR의 전체적인 구조입니다.
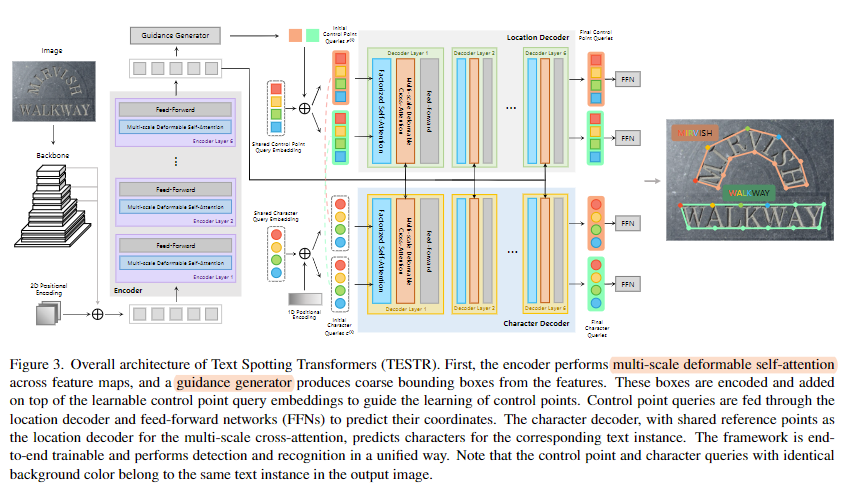
2.1 Multi-Scale Deformable Attention
text spotting task에서 해결하지 못한 문제 중 하나는 작은 크기의 텍스트를 잘 검출해내지 못하는 것이었습니다. 앞선 연구들은 이 문제를 해결하기 위해 입력 이미지로부터 특징을 추출한 여러 스케일의 feature map을 사용하는 방법을 시도했었습니다. (FPN과 같은) 본 연구도 앞선 연구와 동일하게 여러 스케일의 feature map을 사용하고 이를 적절하게 사용할 수 있게 multi-scale attention module을 사용합니다.
기존의 attention은 모든 인풋 토큰에 대해서 각 임베딩 벡터와 나머지 벡터간의 attention weight을 계산하기 때문에 multi-scale 중 high resolution feature map에서 attention을 진행한다면 feature map의 크기가 (c, w, h)이라고 했을 때 O((wh)^2 x h)의 복잡도로 굉장히 많은 비용이 요구되는 작업입니다. 하지만 논문에서 사용하는 multi-scale attention은 deformable attention을 수행해 이런 고비용 문제를 해결합니다.
기존에는 각 feature map 마다 모든 픽셀에 대해 attention을 수행했지만 본 연구는 객체가 있을 법한 곳마다 일정 개수만큼의 sampling point를 뽑고 attention을 수행해 해당 과정을 단순화 시킵니다.
2.2 Dual decoders
Guidance generator로 제안한 영역마다 텍스트 박스의 control points의 좌표와 클래스 예측값을 동시에 예측하는 단계입니다. 본 연구는 이런 텍스트 검출을 하나의 set prediction problem으로 정의하고 풉니다. 이는 DETR에서 제안된 방법과 동일한데요 잠깐 설명을 드리자면..
DETR에서는 기존의 Detection model들이 사전에 사람이 지정한 종횡비의 앵커박스를 가지고 ROI proposal을 하고 각 ROI proposal에 대해서 분류를 진행하고 같은 인스턴스에 대한 중복 검출을 해결하기 위해 사람이 또한 따로 임계값을 지정해줘야 하는 NMS(Non maximum Suprresion) 같은 human-crafted components를 요구하는 작업에 대한 한계를 지적합니다. 그리고 이로부터 자유로운 방법을 제안합니다. 해당 연구에서는 트랜스포머 기반의 detection model을 제안해 direct하게 detection을 수행합니다. 그리고 모든 이미지에 대해서 고정된 개수의 예측을 하도록 한 후 이를 각 GT와 매칭되도록 하는 이분 매칭의 방법으로 NMS를 사용하지 않고도 인스턴스에 대한 중복 예측 문제를 해결하였습니다.
TESTR 본 연구 또한 DETR의 detection 방법론을 차용한 연구입니다. 학습 시 고정된 개수의 예측을 내도록 하고 각 GT와 매칭을 한 후 loss를 계산합니다. (각 예측에 대해서 사전에 GT 정해져 있지 않은 상태입니다. 학습 과정에서 각 예측이 적절한 GT와 매칭이 돼 loss를 구하고 이를 줄이는 방식으로 학습이 진행됩니다. 매칭되는 방법은 모델의 예측과 GT를 모두 1:1로 대응시킨 다음 모든 매치에서 둘간의 loss를 최소화하는 매치를 (조합을) 선택하는 것입니다.)
그리고 TESTR은 인코더를 통과하고 나와서 두개의 디코더로 출력이 전달되는데요. 두개의 디코더에서 텍스트 박스의 control points의 좌표 예측과 텍스트 인식이 동시에 따로 진행됩니다.
모델의 예측은 다음과 같이 나타나집니다.
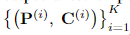
이미지 내의 K개의 텍스트가 있다고 할 때
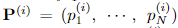
i 번째 텍스트의 N개의 control points의 좌표 예측과
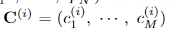
해당 텍스트에서의 각 characters에 대한 예측으로 하나의 텍스트 인스턴스에 대한 쿼리(예측)가 구성됩니다.
여기서 어떤 텍스트 인스턴스에 대해서 N개의 control points, M개의 character 예측 하나하나를 subquery라고 지칭합니다.
1. Location decoder
각 텍스트 인스턴스 마다 control points를 출력하는 디코더입니다. 이 control points를 가지고 polygon이나 bezier 곡선을 그려 텍스트 테두리에 그려지는 다각형의 텍스트 박스를 그릴 수 있게 됩니다. 서로 다른 텍스트 인스턴스의 같은 인덱스의 control points간, 같은 텍스트 인스턴스에 대해서 각 control points간의 관계를 모두 학습하는데요 각 control points 예측에 대해서 attention을 수행합니다. 같은 텍스트 인스턴스 내에서 모든 control points간의 attention을 수행하는 intra-group attention과 다른 query이지만 (같은 이미지내 다른 텍스트이지만) 같은 위치 인덱스를 가지는 subquery 간의 attention을 수행하는 inter-group attention이 있습니다. 여러 계층의 디코더 블록을 통과한 쿼리는 이후에 classification header를 통과해 confidence score를 예측하고(텍스트 인지 아닌지를 구분합니다) 2 channel의 회귀를 수행하는 헤더를 통과해 각 sub query 마다 x, y 형태의 좌표를 얻게 됩니다. 여기서 해당 좌표는 polygon을 직접 그리기 위한 점일 수 있고요 아니면 bezier curve를 그리기 위한 점일 수 있습니다. 저자는 이렇게 text box를 나타내는 방법을 달리해 이후 실험 부분에서도 확인하실 수 있겠지만 둘을 비교합니다. (미리 얘기를 드리자면 polygon을 직접 그리는 polygonal annotation 방식이 조금 더 좋은 결과를 냅니다.)
2. character decoder
location decoder와 학습 과정은 거의 유사합니다. control points가 아닌 텍스트 인스턴스의 각 글자에 대한 예측이 이뤄진다는 점에서 차이를 갖습니다.
2.3 Box-to-Polygon Detection Process
다각형 텍스트 박스가 복잡한지라 바로 예측하는 게 쉽지 않아
decoder 입력 전 Guidance generator를 통해 대략적인 바운딩 박스를 제시합니다. 추후 디코더를 거쳐 더 자세한 굴곡을 잘 표현하는 다각형 텍스트 박스로 예측을 더 정확하게 하는 단계를 거칩니다. 아래는 Guidance Generator의 구조를 더 자세하게 나타낸 도식도입니다.

2.4 Training Losses
다음은 모델의 예측과 GT가 이분 매칭되는 방법과 학습에서 사용되는 loss들에 대해서 설명을 드리도록 하겠습니다.
Bipartite matching (이분 매칭)
우선 학습 시 모델의 예측 (control points의 자표와 각 텍스트 속 characters에 대한 예측)과 GT를 매칭시키는 게 필요합니다.
이미지 마다 고정된 개수의 subquery에 대한 예측이 수행됩니다. (물론 해당 이미지에 그 개수보다 텍스트가 적다면 잉여 예측에 대해서는 의미 없는 값이 들어갈 것입니다) 그리고 그 개수와 동일한 GT를 두고 매칭을 하는데. 모든 매치에서의 loss를 줄이는 과정에서 최적의 매칭 조합을 찾는 것이 목표입니다. 이렇게 모델의 예측과 GT를 1:1로 매칭하는 것을 이분 매칭이라고 칭합니다.
모델 예측과 GT간의 cost function은 다음과 같습니다.
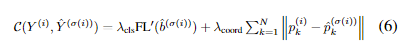
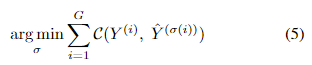
그리고 위의 cost function을 이용해 이를 줄이는 매치의 조합을 찾는 것을 나타낸 것이 그 아래의 식이 되겠습니다.
(6) 식에 대해서 설명을 드리자면.. 어떤 예측이 GT의 텍스트일 확률에 대해서 focal loss를 적용한 것이 좌측 componenet이고 예측과 정답 텍스트 박스의 좌표간 L1 loss를 나타낸 것이 위 식의 우측 components입니다.
매칭 loss를 최대한 작게하는 이분 매칭을 하기위해 헝가리언 알고리즘이 사용됩니다.
다음은 학습과정에서 사용하는 손실함수들입니다
Instance classification loss
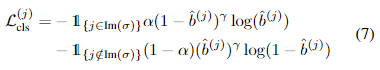
이는 각 인스턴스마다 알맞게 예측하였는지를 focal loss로 나타낸 것입니다. 실제 모델이 예측한 영역에 텍스트가 있는지와 없는지를 분류하는 문제로 다뤄지는데요
Control point loss
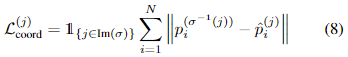
다음은 예측 텍스트 박스와 GT 텍스트 박스간의 좌표간의 L1 거리로 구해 나타낸 loss입니다.
Character classification loss
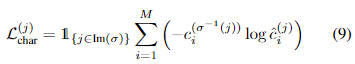
다음은 모델의 예측이 정답 텍스트와 같은 문자들로 구성되게 예측을 하였는지에 대해 cross entropy loss를 가지고 loss를 정의한 것입니다.
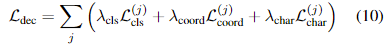
앞선 세개의 loss 함수를 더해 최종적인 두개의 디코더에 대한 loss를 나타낼 수 있습니다.
인코더에서도 간단한 예측 결과가 출력되고 이는 Guidance generator에서 최종 다각형 예측의 보조 역할을 하는 바운딩 박스를 생성하는 데 사용됩니다. 따라서 인코더단 단의 loss 함수도 정의해서 학습에 사용됩니다. 식은 다음과 같습니다. 디코더의 최종 loss function과 거의 유사하지만 character에 대한 classification loss가 없고 추가적으로 gIoU란 loss가 추가돼 있습니다.
cls, coord loss는 앞서 봤던 decoder에서의 loss와 동일합니다.
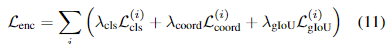
3. Expreiments
다음은 실험 결과입니다. 본 연구에서는 SynText 150k, ICDAR 2015, Total-text, CTW 1500 총 4개의 데이터셋에 대해서 실험을 진행하였습니다. 이 중 Total-text, CTW는 curved scene text가 포함돼 있어 특히 arbitrary-shaped text에 대한 검출 성능을 확인하기에 아주 적합한 데이터셋이라 볼 수 있습니다.
각 데이터셋에서 사용하는 평가지표를 그대로 따랐다고 합니다. 그리고 예측된 베지에 곡선을 가지고 다각형 box로 변환 후 GT와 비교후 loss가 계산됩니다.
3.2 Implementation Details
multi-scale feature map을 추출하기 위한 백본으로는 ResNet-50을 사용합니다. 각 인코더와 디코더 마다 6개의 레이어를 거칩니다. 학습 전 데이터 증강도 수행됩니다. 랜덤하게 짧은 변을 특정 범위의 값으로 긴 변은 길이를 고정하는 이미지 사이즈를 줄이는 증강과 각 텍스트를 고려해 텍스트가 잘려나가지 않도록 크롭을 진행하는데 크롭한 이미지가 원본 이미지의 절반 크기보단 크도록 합니다. 추론 시 짧은 변은 1600으로 고정하고 긴 변은 1892로 고정시킵니다. SynthText 150k, MLT 2017, TotalText 데이터셋의 조합으로 데이터를 구성해 사전 학습을 진행한 후 이후 각 개별적인 데이터셋에 대해서 파인튜닝을 진행하고 아래의 실험 결과를 냈습니다.
3.3 Results
다음은 실험결과에 대해 보여드리겠습니다.
Irregular texts
arbitrary-shaped text에 대한 성능을 검증한 실험입니다. Total-Text, CTW 1500에 대해서 실험을 진행하였습니다.
Detection과 End-to-End 항목이 나눠져서 성능 평가가 이뤄졌는데요 Detection은 텍스트 검출 자체 즉 텍스트의 위치를 정확하게 찾았는지를 보는 실험이고 End-to-End는 검출과 텍스트 인식까지 모두 평가한다고 보시면 됩니다. Detection 항목에서의 평가 지표로는 P(Precision), R(Recall), F-score이 있는데요. Precision과 Recall은 익숙하시겠지만 F-score은 저는 처음 들어보는데요 이는 Precesion과 Recall의 조화 평균을 구한 지표입니다. 그리고 End-to-End 항목에서는 None, Full으로 나뉘는데요 이는 Lexicon의 유무입니다. Lexicon이란 모델이 텍스트를 예측할 때 참고할 목록으로 이것이 주어지는냐 마느냐 또 어떻게 주어지는지에 따른 성능을 비교 분석하였습니다. 또한, TESTR에 대해 텍스트 박스에 대한 annotation을 bezier curve로 하거나 그냥 다각형 점들로 하느냐에 따라 TESTR-Bezier (ours)과 TESTR-Polygon (ours)로 나뉩니다. 이 annotation 차이에 대한 ablation study도 논문에서 진행되는데요 다음에서 더 자세하게 설명하도록 하겠습니다.
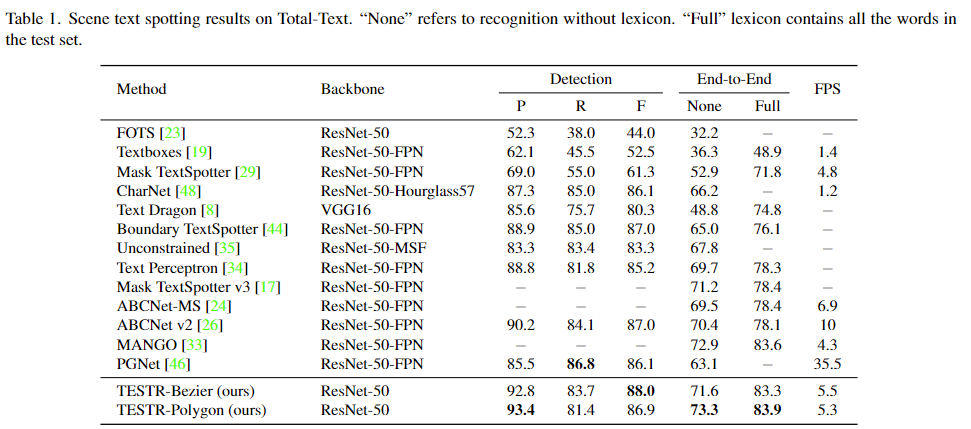
위 테이블을 Total-Text에 대한 실험 결과입니다.
text detection 차원에서 TESTR-Beizer 방법이 기존 방법 중 제일 정확한 모델인 ABCNet v2나 Boundary TextSpotter보다 F score 지표에서 1.0% 보다 정확함을 확인할 수 있습니다. TESTR-Polygon은 TESTR-Beizer보단 결과가 낮지만 ABCNet v2와 거의 같은 성능을 보입니다. (TESTR-Beizer보다 훨씬 간단한 annotation 방법입니다) end-to-End 항목에서 lexicon이 주어지지 않았을 때는 0.4%, Full lexiicon이 주어졌을 때 .3%의 향상을 보입니다.
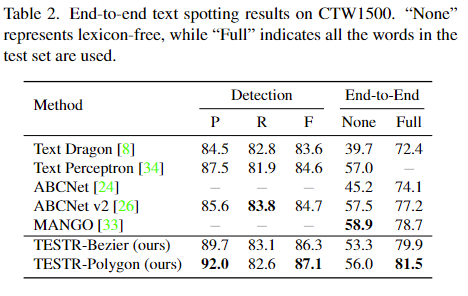
다른 데이터셋에 대해서도 확인해보겠습니다. 앞선 Total-text에 비해서 ABCNet v2를 추월하는 정도가 더 큽니다. (Beizer는 1.6%, polygon은 2.4%로) end-to-end 항목에 대해서도 Full lexicon이 주어졌을 때 TESTR-Polygon은 MANGO방법론 대비 2.8% 정도 향상된 성능을 보입니다.
다음은 각 데이터셋에 대한 정성적 결과입니다.


결과를 보면 논문에서 제안하는 방법론이 직선형태의 텍스트 뿐만 아니라 굽은 곡선형태의 문자또한 잘 검출하고 인식함을 확인할 수 있습니다.
앞서 정량적으로도 End-to-End 즉 전체적인 텍스트 spottng에 대해서는 Bezer 곡선 annotaton을 사용하는 것 보다 polygonal annotation을 사용하는 게 더 결과가 좋았습니다. 이는 정성적으로도 확인할 수 있는데요 Figure5. 의 맨 우측 열의 이미지 두장을 비교해보면 ANKYLOSAURUS라는 텍스트를 bezier로는 정확히 모든 단어에 대해 검출하지 못한 반면 아래 polygonal annotation으로는 잘 검출이 됐습니다.
실험해본 결과, 논문에서 제안한 TESTR이 기존 모델 보다 성능이 개선되었고 TESTR-Polygon이 TESTR-Bezier보다 대부분의 실험 항목에서 더 나은 결과를 보임을 확인하였습니다.
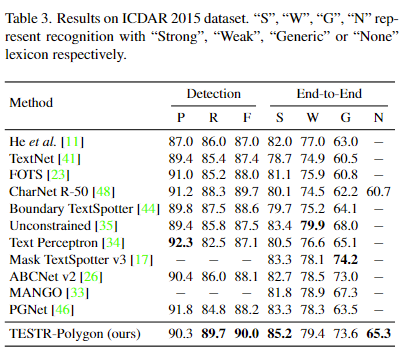
Figure 6의 우측 열의 정성적인 결과와 테이블 3을 확인했을 때 arbitrary-shaped text에서 뿐만 아니라 직선형 텍스트 또한 기존 모델들 보다 정확히 검출함을 확인할 수 있습니다.
3.4 Ablation Studies
다음 Ablation Studies는 Total-Text 데이터셋에 polygonal annotation을 써서 실험하였습니다.
Box-to-polygon detection process
우선 모델 설계할 때 디코더로 넘어가기 전에 Guidance generator를 두어 대략적인 바운딩 박스를 그리는 것이 추후 모델이 최종적인 다각형의 텍스트 박스를 치는 데 성능 개선에 영향을 주는지에 대한 실험입니다.
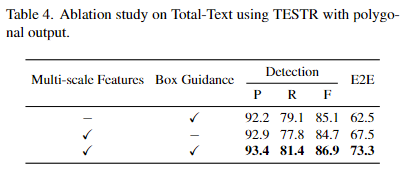
Box-guidance를 주는 것이 모든 지표들에서 성능 향상을 (순서대로 1.2%, 2.3%, 1.8%, 10.8%의 성능 향상을 보입니다.
Multi-scale feature
같은 테이블을 참고하겠습니다. 저자는 작은 텍스트에 대한 검출 성능을 향상하고자 백본으로 부터 Multi-scale feature을 가져와 encoder에 전달했었는데요 이 방법또한 (4 테이블의 1행과 마지막 행 비교) 성능 향상이 되었음을 확인할 수 있습니다.
4. Discussions
저자는 본 연구가 고정된 control points를 두었다는 점에서 한계를 갖는다고 하였고 추후 텍스트에 따라 유동적으로 control points를 정하고 검출을 진행하도록 하는 연구를 할 것이라고 하였습니다.
Conclusion
리뷰를 마무리하면서 본 연구에 대해서 정리를 해보도록 하겠습니다. 단일 인코더와 두개의 디코더 구조를 가진 트랜스포머 기반의 text-spotter TESTR를 제안한 연구로 이미지속에서 나타나는 text가 대부분이 단순한 직선형태로 나열되 있지 않고 방향또한 모두 같지 않은 arbitraty-shaped text라는 것을 지적하며 이런 텍스트 모두 정확하게 검출하고 인식할 수 있는 방법론을 제안한 것이었습니다. 그리고 검출과 인식을 병렬적으로 수행해 end-to-end하게 구현했다는 것도 본 연구에서 중요한 contribution이 되겠습니다. 성능 평가와 여러 ablation studies를 통해 연구에서 제안하는 TESTR이 기존의 제일 정확했던 방법론 보다 더 나은 성능을 보임을 확인했고 저자가 제안한 Box-to-polygonal detection module, Multi-scale features 등이 성능 개선에 영향을 주었음을 확인하였습니다.
감사합니다.
안녕하세요 지연님 리뷰 감사합니다
control point 예측에 있어서 polygon이랑 bezier 방식 중 bezier 방식이 polygon 방식이 더 좋은 성능을 보인 이유가 무엇일까요? ANKYLOSAURUS라는 텍스트를 bezier로는 정확히 모든 단어에 대해 검출하지 못한 반면 아래 polygonal annotation으로는 잘 검출이 된 이유가 궁금합니다!
안녕하세요 영규님 질문 감사합니다.
영규님께서 궁금해하시는 부분에 대해서 논문에서 직접적으로 언급이 되지는 않았는데요 제가 생각하기에 bezier 방법이 arbitrary-shaped에 대해 더 세밀하게 detection boundary를 그릴 수 있는 방법인 건 맞지만 control points 위에 그려지는 게 아니고 이를 가지고 표현되는 곡선을 구해 최종적인 예측을 하는 것이기 때문에 오차로 인한
불안정성이 더 클 것 같고 평가 지표 자체가 기존의 polygonal annotation에 맞춰져 있어서 (현재 사용되는 지표인 IoU 자체가 text box가 얼마나 세밀하게 나타내는지에 대한 지표는 아니기에) 그런 결과가 나오지 않았나 싶습니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다
이전 연구들에서 멀티 스케일의 feature map을 사용했지만 작은 텍스트를 검출하는데 한계가 있었다고 말씀해주셨습니다. 근데 본 논문에서도 동일하게 멀티스케일 feature map을 사용했는데도 작은 텍스트를 검출할 수 있었던 이유는 단순히 어텐션 연산을 추가했기 때문인가요 ?? 그럼 이전 논문들에서는 어텐션과 같은 연산 과정을 진행했던 연구가 없었던건지도 궁금합니다.
네 안녕하세요 건화님
질문 감사합니다!
이전 연구에서도 본 연구와 동일하게 멀티 스케일을 활용해 작은 물체를 검출하고자 했지만 특히 본 연구의 기반이 되는 Deformable DETR의 선행 연구인 DETR에서 멀티 스케일을 그대로 사용해 인코딩에 적용한다면 pixel-by-pixel간 attention이 수행되기 때문에 이 경우 비용이 많이 든다는 것이 한계였다고 이해해주시면 될 것 같습니다.
감사합니다~!
안녕하세요 지연님 자세한 리뷰 감사합니다.
읽다가 조금 궁금한 점이 생겨서 질문드립니다.
location decoder 부분에서 서로 다른 텍스트 인스턴스의 같은 인덱스의 control points간, 같은 텍스트 인스턴스에 대해서 각 control points간의 관계를 모두 학습한다고 하셨는데, 같은 텍스트나 다른텍스트에서의 같은 인덱스라는 표현이 정확히 와닿지가 않아서 해당 location decoder의 동작 방식을 조금 더 구체적으로 설명해주시면 감사하겠습니다.
안녕하세요 질문 달아주셔서 감사합니다 신인택 연구원님.
연구원님께서 질문 주신 부분은 location decoder의 Factorized self-attention 부분에 해당합니다.
해당 attention module은 intra-group, inter-goup attention이 병렬적으로 함께 수행된다고 보시면 되는데요. 디코더의 입력으로 이미지 속 하나의 (word-level) 텍스트와 대응되는 K개의 object query가 전달되고 각 디코더 레이어를 통과하면서 각 쿼리를 GT에 근사하도록 학습시키는 것이 목표입니다.
쿼리마다 텍스트 박스의 N개의 control points 좌표값으로 (p_i: p_1 … p_N) 구성됩니다. 이때 하나의 쿼리를 이루는 각 좌표값을 논문에서는 subquery라고 지칭합니다. 여러개의 subquery가 하나의 object subquery를 이루게 되는 거지요. Factorized attention layer에서 같은 텍스트 인스턴스에 대한 다른 좌표값들에 대한 attention (P_1의 p_1과 p_3) 을 intra-group attention이라고 하고 서로 다른 텍스트 인스터이지만 인덱스가 같은 subquery의 attention을 (P_1의 p_1과 P_11의 p_1) inter-group attention이라고 합니다.
여기까지가 한 decoder 블록의 첫 attention module인 것이고 이후 정해진 reference point에 대해 deformable attention이 (cross attention) 수행되고 FFN을 통과해 예측을 하는 것 까지가 하나의 디코더 블록을 통과하는 process가 됩니다. 이를 6차례 진행해 최종적인 예측을 도출하는 것이 디코더에서의 학습 과정이 되겠습니다.
감사합니다.
안녕하세요 지연님 좋은 리뷰 감사드립니다.
해당 논문에서는 모델이 고정된 control points를 예측한다고 했는데 이 방식이 실제 arbitrary-shaped text에 대해 얼마나 유연한 표현력을 갖는지가 궁금합니다. 단순히 든 생각은 고정된 control points눈 긴 텍스트에 대해 표현력이 감소할 수 도 있지 않을까 생각이 들었습니다. 극단적으로 글자 수가 많은 긴 텍스트에 대해서도 충분히 표현이 가능한지 혹은 논문에서 테스트된 실험 등이 있었는지가 궁금합니다!
감사합니다.
control point의 개수가 고정돼 있을 뿐 형태는 꼭 사각형일 필요는 없고 간격 또한 고정된 것은 아니라 그런 이유에서 긴 텍스트를 검출하는데 어려움이 있다는 언급은 따로 없었습니다. 그리고 따로 길이가 긴 텍스트에 대한 실험이 리포팅된 것은 없었는데요 SoTA와 성능 비교에 사용하는 데이터셋 중 line-level로 annotation이 제공되는 CTW1500 데이터셋에 대한 정성적인 결과로 보시면 긴 텍스트들도 잘 검출이 된다는 것을 확인할 수 있습니다.(Figure 6의 좌측열)