안녕하세요, 이번주엔 여태까지 진행하던 강화학습 논문들 리뷰를 접어두고 Embodied AI를 위한 벤치마크 논문을 가지고 왔습니다. BEHAVIOR-1K는 comprehensive 한 시뮬레이션 벤치마크로, BEHAVIOR-1K 데이터셋과 OmniGibson이라는 시뮬레이션을 지원한다는 점을 main contribution 으로 삼았습니다.
Introduction
BEHAVIOR-1K 벤치마크는 “로봇이 과연 기술적으로만 계속 발전시키는 것도 중요하지만, 사람들이 정말 어떤 로봇을 필요로 하는지를 생각해봐야겠다”는 생각을 통해 만들어지기 시작했다고 합니다. 이 때문에 데이터셋과 시뮬레이터 외에 저자들이 주장하는 contribution에 extensive survey라는 표현이 있었습니다. 로봇에게 어떤 일을 맡기고 싶은지는 인간 중심의 로봇 연구에서 핵심적인 질문이라고 생각했다고 합니다. BEHAVIOR-1K 벤치마크는 이러한 질문에 직접 답하기 위해 대규모 설문 조사를 바탕으로 만들어졌다고 합니다. 저자들은 미국 일반인들을 대상으로 “로봇이 당신을 위해 무엇을 해주길 바라나요?”라는 질문을 통해 약 1,461명의 응답자로부터 (저는 대규모라고 말할 수 있을 정도인지는 살짝 의문이긴 합니다..) 다양한 일상 활동에 대한 선호도를 수집했습니다. 설문 활동들은 미국 노동통계국, Eurostat 등의 시간 사용 조사 데이터와 온라인 지식 기반인 WikiHow에서 추출한 2,000여 개의 일상 작업 목록이었습니다. 참가자들은 각 활동에 대해 로봇이 대신 해줄 경우 얼마나 도움이 될지 1점 ~ 10점으로 평가했고, 이를 통해 인간이 가장 로봇에게 맡기고 싶어하는 일상 활동 순위가 도출되었다고 합니다.
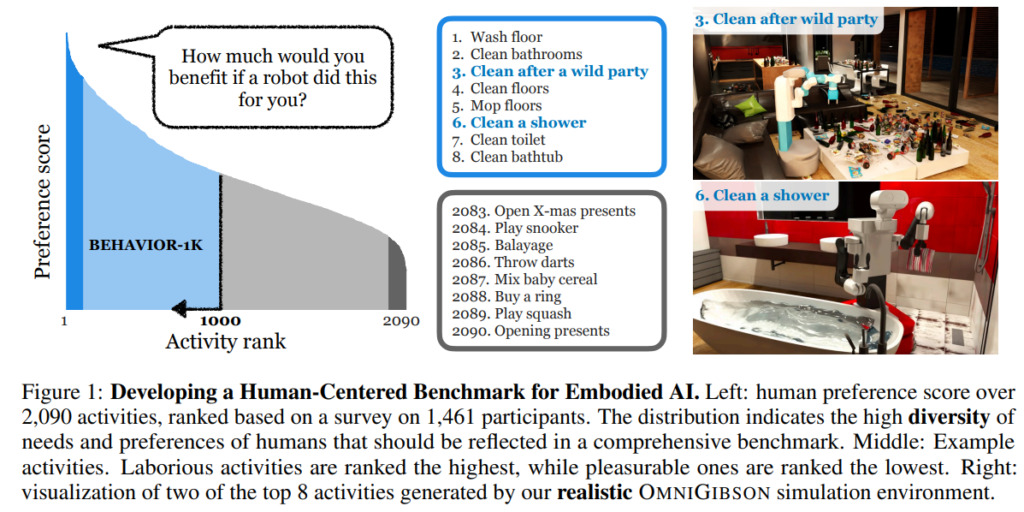
설문 결과 가장 높은 점수를 받은 일들은 위에서 볼 수 있듯 대체로 힘들고 번거로운 집안일이었다고 합니다. 예를 들어 “욕실 바닥 문지르기”나 “광란의 파티 후의 현장을 청소하기” 같은 고된 청소 업무가 최상위권에 올랐고, 반대로 “게임 같이 하기”처럼 사람들이 스스로 즐기는 활동은 하위권을 차지했습니다. 이를 통해 정리나 청소같이 고도의 지능을 필요로 하진 않지만 육체적으로 이득을 줄 수 있는 행동들을 우선적으로 타게팅 하는것이 좋겠단 생각을 했습니다. 하지만 상위권을 전반적으로 놓고 봤을 때 전체적으로 청소 관련 업무 약 200개, 요리 준비 및 조리 200여 개 등 매우 다양한 범주의 작업들이 상위에 분포하여 인간의 필요와 선호가 매우 광범위함 또한 알 수 있었다고 합니다. 가장 두드러지는 특지잉라면 반복적이고 힘든 작업일수록 로봇에게 맡기길 원했고, 오락적이거나 취미적인 활동은 직접 하길 원했다고 합니다. 또 이는 로봇 연구자들이 추측만 해오던 인간 요구를 실증적으로 확인한 결과라 할 수 있다고도 합니다. 이러한 선호도 점수를 기반으로 상위 909개 활동이 우선 선정되었고, 여기에 이전 버전인 BEHAVIOR-100 벤치마크에 포함됐던 91개 활동을 추가하여 총 1000개 일상 활동의 목록이 완성되었습니다.
Dataset
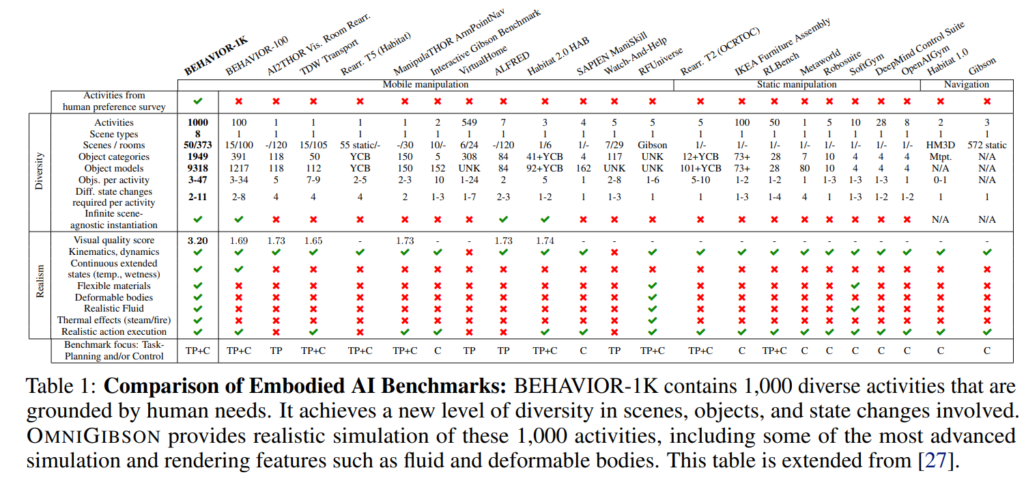
BEHAVIOR-1K 데이터셋은 크게 저자들이 제안한 BDDL이라는 활동 방식을 사용하는 활동 정의, 객체 및 상태 속성들, scene, 그리고 이를 구현하는 OmniGibson 시뮬레이션 환경으로 구성된다고 합니다. 해당 데이터셋에 존재하는 모든 task들을 수행가능한 로봇을 만드는 것은 것은 매우 어려울 것이라고 하네요,, 위 표를 보시게 되면 특히 state를 표현하는 것, deformable 하거나 fluid와 같은 복잡한 물리엔진, thermal effect 등의 표현, activity의 갯수와 scene type등 다방면에서 기존의 데이터셋보다 광범위 하고 현실적인 데이터를 제공하는 것을 확인할 수 있습니다. 아래는 CookingDinner이라는 예시를 통해 논문에 적혀있는 BEHAVIOR-1K 데이터셋의 요소들입니다. 이 뿐만 아니라 다른 구조적인 요소들 또한 살펴보도록 하겠습니다.

Scene
설문을 통해 선정된 활동들은 50가지 다양한 가상 환경에 배치되어 구현된다고 합ㄴ디ㅏ. 장면들은 일반 가정집부터 정원, 식당, 사무실 등 8가지 유형으로 분류되며, 총 373개의 room을 포함하는 풍부한 공간적 다양성을 보여준다고 합니다. 예를 들어 가정집 장면에는 거실, 주방, 욕실 등이 포함될 수 있고, 사무실 장면에는 작업실, 회의실 등이 있을 수 있습니다. 각 장면은 상호작용이 완전히 가능한 3D 환경으로 구축되었는데, 문, 서랍, 창문 같은 articulated objects는 열고 닫을 수 있고, 조리대, 싱크대, 수납장 등에는 다양한 물건들이 배치되어 실제 생활 공간처럼 꾸며져 있습니다. 일부 장면은 현실 세계의 장소를 3D로 스캔하고 텍스처 및 객체를 입히는 방식으로 만들어져 디지털 트윈에 가깝게 구성되었고, 다른 장면들도 실제 환경에 근접한 레이아웃을 갖도록 디자인되었다고 합니다. 이러한 장면 다양성은 한정된 환경에서만 통하는 솔루션이 아닌, 일반적인 환경 전반에서 동작하는 로봇을 개발하는 데 필요한 challenge를 제공한다고 합니다. 또한 task를 정의할 때 어느 장면에서 수행될 수 있는지에 대한 정보가 있어, 동일한 활동이라도 주방이 있는 집, 야외 정원 등 여러 맥락에서 시험될 수 있다고 합니다. 이는 하나의 작업을 다양한 물리적 조건에서 반복 학습함으로써 상황 변화에 강인한 로봇을 훈련하는 데 도움을 준다고 합니다. 렌더링 또한 다른 데이터셋에 비해 매우 훌륭한 것을 볼 수 있습니다. 아래 숫자는 60명의 사람한테 1점부터 5점까지 렌더링 품질을 평가하라고 한 뒤 평균을 낸 것이라고 합니다.

BDDL
1000개의 모든 활동은 BEHAVIOR-1K 전용 도메인 언어인 BDDL (Behavior Domain Definition Language) 로 기술되어 있습니다. BDDL은 인공지능 계획(PDDL)과 유사한 술어 논리 기반 서술로, 각 활동에 필요한 객체 목록(:objects), 초기 상태(:init), 목표(:goal)을 명시합니다. 이 방식은 로봇이 어떤 작업을 수행해야 할지를 명확하게 기술하고, 어떤 상태가 되었을 때 작업이 완료된 것으로 간주할지를 논리적으로 표현할 수 있는 방식이라고 합니다. (그냥 초기상태와 scene을 구성하는 객체목록, goal로 구성되어있습니다..) 아래는 예시입니다.

우선 objects 항목에는 해당 활동에 필요한 객체의 종류와 개수를 나타냅니다. 객체는 WordNet 기반 synset 이름을 사용하여 범용성과 계층 구조를 갖 예를 들어 candle.n.01은 촛불이라는 객체 유형을 나타내며, 이는 향후 시뮬레이터에서 자동으로 3D 인스턴스로 매핑됩니다. 그 다음은 init 항목입니다. 이는 작업 시작 시점의 세계 상태를 기술하는 블록으로, 객체들의 공간적 관계 (예: A가 B 위에 있다), 객체의 semantic한 속성(예: 익지 않은 상태, 닫힌 상태) 등을 논리 술어로 표현한다고 합니다. 이 정보는 시뮬레이터에서 환경을 구성하고, 로봇이 어떤 상태에서 시작하는지를 규정합니다. 마지막으로 goal은 해당 작업이 완료되었다고 판단하기 위한 논리 조건입니다. 목표 조건 역시 술어를 기반으로 기술되며 and, forall, not 등의 논리 연산자를 활용하여 복합적인 상태를 정의할 수 있다고 합니다. 예를 들어, “모든 촛불이 바구니 안에 들어있다”는 조건은 (forall (?c candle.n.01) (insdie ?c wicker_basket.n.01))과 같이 표현할 수 있다고 합니다. 이 목표 조건을 기반으로 시뮬레이터는 자동으로 현재 상태와 비교하여 작업이 성공했는지 판단하게 됩니다.
BDDL은 하나의 작업이 어떤 요소들로 구성되고, 어떤 상태를 달성해야 하는지를 논리적으로 구조화함으로써, 강화학습 알고리즘등 여러 모델들에게 일관된 정보를 제공할 수 있다고 합니다. 뿐만 아니라 BDDL은 과업 성공 조건이 분명히 명시되어 있어 강화학습 보상을 정의하거나 시뮬레이션 중 평가 지표를 구성할 때도 매우 유용하다고 주장하비낟. 무엇보다, BDDL은 BEHAVIOR-1K의 각 작업을 단순한 task list가 아닌, 검증 가능한 학습 목표로 전환시켜주는 핵심 언어이자 기반 프레임워크라고 주장했습니다. 아래는 .bddl 파일의 예시 입니다.
“테이블 위에 놓인 두 개의 촛불을 바구니에 넣어 정리하는 작업”을 정의한 것으로, 초기 상태에서 두 촛불과 바구니는 테이블 위에 놓여 있으며, 작업의 목표는 두 촛불 모두가 바구니 내부에 들어가는 것 입니다.
Annotation
BEHAVIOR-1K 데이터셋은 객체의 의미론적 특성과 물리적 조작 가능성을 정교하게 표현하기 위해, WordNet 계층 구조의 leaf-level synset마다 시뮬레이터 상에서 실제로 재현 가능한 속성들을 annotation 했다고 합니다. 이러한 속성은 단순한 분류(label)가 아니라, 해당 객체가 시뮬레이션 환경에서 어떤 행동 술어의 적용 대상이 될 수 있는지를 결정하는 기능적 메타데이터라고 합니다. 예를들어 객체가 cookable 속성을 가진다면, 이는 해당 객체에 대해 “익었다/익지 않았다”는 상태 전이가 시뮬레이션 가능하다는 의미이며, OmniGibson 환경 내의 cook 동작의 대상이 될 수 있음을 의미합니다. 전체 데이터셋에 걸쳐 2,964개의 leaf-level synset이 존재하며, 이에 적용 가능한 속성의 수는 총 13개라고 합니다. 이들 속성 중 다수는 대규모 주석 작업이 필요하므로, GPT-3를 이용한 자동 주석 또는 crowd-sourcing 방식의 인간 주석으로 수행되었다고 합니다. 특히, GPT-3를 이용한 속성 주석은 사전 검증을 통해 Hamming distance 및 false-positive rate이 사람이 수작업으로 생성한 기준답안에 비해 모두 10% 이하로 유지되는 경우에만 허용되었으며, 이에 해당하는 8가지 속성은 모두 LLM 기반 자동 주석으로 처리되었다고 합니다. 반면, 의미가 모호하거나 LLM으로는 정밀 판별이 어려운 나머지 5가지 속성은 크라우드 워커를 통해 수작업으로 annotation 됐다고 합니다. 이 외에도 일부 속성은 시뮬레이터 구현에 민감하거나 상위 속성으로부터 유도 가능한 경우, 수작업 또는 분석 기반 방식으로 보완 됐다고 합니다. 자세한 annotation pipeline은 다음과 같이 구성됐습니다.
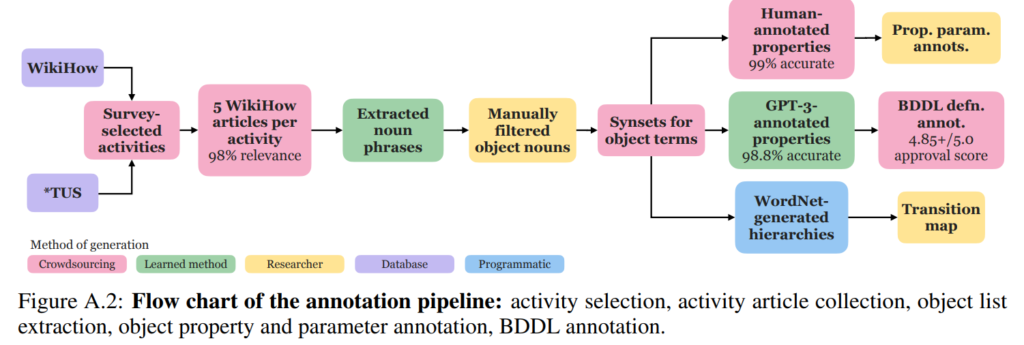
Semantic Properties
BEHAVIOR-1K의 활동들을 현실감 있게 구성하기 위해 9,000개 이상의 객체 인스턴스가 데이터셋에 포함되어 있으며, 방대한 object-state 베이스 또한 구축되어 있다고 합니다. 우선 객체들은 WordNet을 활용한 계층적 분류 체계로 관리되며, 약 3,000개에 달하는 최종 객체 분류(synset)가 존재합니다. 각 객체 분류에는 해당 객체가 지닐 수 있는 속성과 상태들이 달려 있습니다. 예를 들어 사과 같은 음식 객체는 cookable 속성을 가져 “익히지 않은”/“익힌” 두 가지 상태를 가질 수 있고, 토스터기는 togglable 속성으로 꺼짐/켜짐의 상태, 컵은 fillable 속성으로 “비어있다/채워졌다” 의 상태 및 채워진 용량 값을 가질 수 있다고 합니다. 뿐만 아니라 slice 됐는지, 등등 각종 semantic한 properties들을 표현하고, 이를 시뮬레이터를 통해서 시각화 하고 상호작용 할 수 있다고 합니다. 이러한 객체 속성들은 각 객체 유형별로 정의되어 있어, 로봇이 어떤 물체를 다룰 때 가능한 상호작용과 결과 상태를 이해할 수 있게 한다고 합니다.
더 나아가, BEHAVIOR-1K는 단순 상태 유무를 넘어서 상태 전이의 파라미터까지 명시합니다. 예를 들어 사과, 닭고기 모두 조리가능하다는 속성이 있지만, 실제로 익는데 필요한 온도와 시간은 다르기 때문에, 데이터셋에는 객체별로 “익었음” 상태로 전환되는 구체 온도 조건값이 기록되어 있다고 합니다. 이처럼 각 객체-속성 쌍마다 상태 전이 임계값(사과의 cookTemperature, 닭고기의 cookTemperature 등)을 직접 지정하여, 시뮬레이터가 현실과 비슷한 방식으로 상태 변화를 처리할 수 있도록 했다고 합니다. 뿐만 아니라 transition rules도 일부 정의되어 있는데, 이는 당시에 존재하던 물리 엔진으로 직접 시뮬레이션하기 어려운 복잡한 변화들을 논리적으로 구현한 것입니다. 예를 들어 믹서기에 토마토와 양념을 넣고 작동시키면 소스가 완성되는 시나리오나, 사포로 녹슨 표면을 문지르면 녹이 제거되는 과정 등은, 내부적으로 특정 조건 충족 시 새 객체를 생성하거나 기존 객체 상태를 바꾸는 규칙으로 모사된다고 합니다. (디테일에 엄청 신경을 쓴 것 같습니다.) 이러한 object-state 베이스와 각종 규칙을 통해 BEHAVIOR-1K는 수만 건에 이르는 사실적 상호작용 정보를 포함하고 있으며, 이는 1000개 활동 각각의 맥락에서 현실성 있는 시뮬레이션을 수행할 수 있도록 했다고 합니다.
OmniGibson
BEHAVIOR-1K의 현실성 있는 구현의 핵심은 OmniGibson 이라고 합니다. OmniGibson은 Stanford VL Lab의 기존 iGibson 환경을 발전시켜 NVIDIA Omniverse Isaac Sim 기반으로 구축한 새로운 시뮬레이션 플랫폼으로, 시각적 리얼리즘과 물리적 상호작용의 정밀도를 대폭 끌어올렸다고 합니다. (다만 실제로 설치해서 실행시켰을 때는 뭔가 매끄럽지 않은 렌더링이었어서 확인을 해봐야 할 것 같습니다). 우선 그래픽 측면에서 Omniverse의 ray tracing 렌더링과 PBR(Physically Based Rendering) 조명을 활용하여, 장면 내 조명 변화, 재질 반사, 투명 물체의 굴절 등이 실제와 가깝게 표현됐다고 합니다. 들어 유리컵이나 창문 같은 투명 객체는 빛을 통과시키고, 금속 표면은 광택을 반사하며, 시간에 따라 방 안의 햇빛 방향이 변하는 등의 효과가 시뮬레이션됩니다. 이는 로봇의 카메라나 뎁스 센서에 입력되는 영상이 한층 자연스러워졌음을 의미하며, 곧 퍼셉션 알고리즘의 성능 평가가 보다 현실에 근접하게 이루어질 수 있다고 합니다.(추후에 등장한 해당 asset을 활용한 논문에서는 파라미터를 조절해가며 사용할 수 있기 때문에 현실보다 유용한 측면도 있다고 주장하기도 했습니다)
물리 시뮬레이션 측면에서 OmniGibson은 Rigid body 동역학 뿐 만 아니라 독보적으로 기존 가상환경에서 다루기 힘들었던 Deformable body)와 Fluid의 상호작용까지 지원한다고 합니다. 예를 들어 천이나 걸레, 스펀지 같은 연성 소재 물체는 잡거나 힘을 줄 때 모양이 변형되고 구부러지며, 컵의 물을 쏟으면 바닥에 액체가 흘러 퍼지고 젖는 효과가 구현됩니다. 또한 0thermal 요소도 도입되어, 가열하면 물체의 온도가 상승하고 김이 모락모락 나는 등의 현상을 볼 수 있다고 합니다. 이러한 고도화된 물리 효과들은 BEHAVIOR-1K의 많은 활동들을 실제처럼 수행하기 위해 필수적이라고 합니다. (실제로 봤을 땐 완전 현실적이진 않긴 합니다..) 예를 들면 식탁 닦기 작업에서 걸레를 물에 적시는 장면, 요리하기 작업에서 재료를 가열해 익히는 과정, 식물에 물주기나 바닥 청소 작업에서 물이 흐르는 상황 등을 모두 시뮬레이터 내에서 표현할 수 있다고 합니다.Omniverse의 PhysX를 기반으로 고해상도 유체 입자 시뮬레이션, 천 시뮬레이션 등이 가능해졌고, 이는 1000개 활동 중 많은 수가 요구하는 복잡한 상태 변화를 제대로 재현하게 해준다고 합니다. 이는 확실히 최신 물리엔진을 활용하는 이점인 것 같습니다.
마지막으로 OmniGibson은 Isaac Sim 기반으로 로봇의 모션 및 센서 체계를 실제처럼 모사합니다. 시뮬레이터 상에서 로봇은 다관절 arm의 역학을 따라 움직이고, 충돌이나 마찰력 등의 물리법칙이 현실적으로 적용됩니다. 로봇에 장착된 RGB-D 카메라, LiDAR 같은 센서는 가상환경을 통해 심도 이미지, point cloud, RGB 영상 등을 출력하며, 실제 센서의 노이즈 특성 일부 까지도 반영되었다고 합니다. 이러한 세밀한 시뮬레이션 설정 덕분에 BEHAVIOR-1K에서 얻은 결과를 현실 로봇에 sim-to-real 할 때 겪는 격차를 줄이고, 더욱 현실성이 높아진다고 주장합니다.
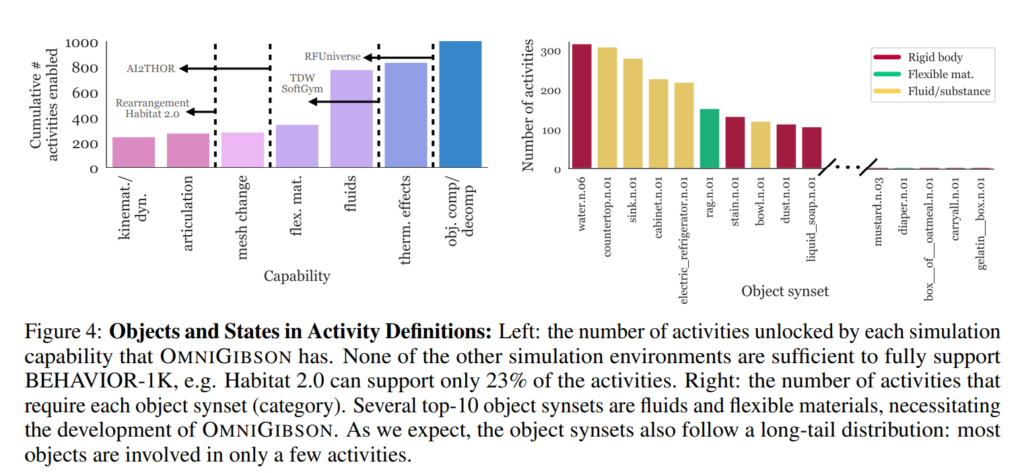
위 Figure는 이와 같은 요구 사항을 정량적으로 보여주는 시각 자료로, 왼쪽은 BEHAVIOR-1K의 활동 중 OMNIGIBSON의 각 시뮬레이션 기능이 몇 개의 작업을 가능하게 하는지, 오른쪽은 특정 객체 유형(synset)이 얼마나 많은 작업에서 요구되는지를 나타냅니다.
왼쪽 그래프를 보면 BEHAVIOR-1K를 구성하는 작업들이 단순한 rigid body dynamics만으로는 대부분 구현되지 않음을 명확히 보여주고, 오른쪽 그래프는 작업 정의에 포함되는 객체 분류(synset)의 사용 빈도를 보여줍니다.상위 10개 객체 중 상당수가 액체 또는 flexible 한 요소들입니다. Scene 자체가 사람들에게 필요한 scene들로 구성된 만큼 액체나 유연한 물리적 환경이 로봇 활동에서 중요한 역할을 한다는 것을 뜻한다고 주장하기도 했습니다. 또한 해당 그래프는 전체 객체의 분포가 전형적인 long-tail 형태를 따른다는 점도 보여준다고 합니다. 소수의 범용 객체는 많은 활동에 사용되지만, 대부분의 객체는 소수의 특화된 활동에서만 사용되는 것을 통해 데이터셋이 단순 반복 작업뿐 아니라, 다양하고 특화된 복합 과업까지 포함하고 있음을 주장합니다.
Benchmark Evaluation
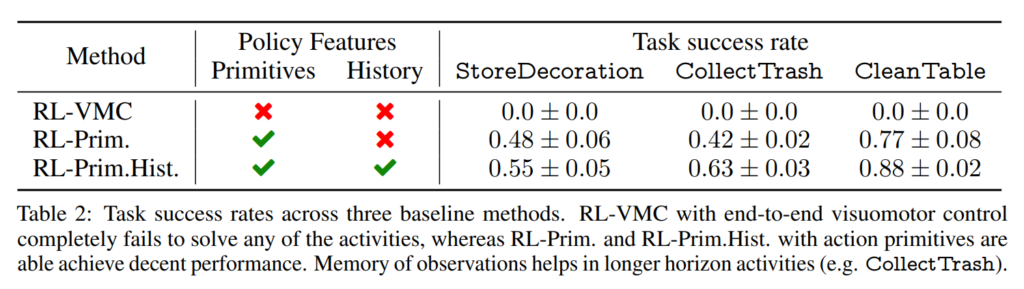
1000개의 활동은 중 우선적으로 몇 가지 전형적인 가정 내 작업을 선별하여 당시의 현존하는 기법으로 풀어보는 시도가 이루어졌습니다. 예시로 선택된 활동에는 StoreDecoration, CollectTrash, CleanTable 세 가지가 있었습니다. StoreDecoration은 방에 흩어져 있는 장식 물품들을 모아 서랍 등에 보관하는 작업으로, 이는 로봇이 물체를 집어서 지정된 수납 공간까지 이동해서 넣고, 필요시 서랍을 여닫을 필요가 있어 여러 능력을 평가할 수 있었다고 합니다. CollectTrash는 집안 곳곳의 쓰레기를 수거하여 쓰레기통에 버리는 task로, 여러 물체를 순차적으로 찾아 집어 운반하는 long horizon과 이동 능력이 요구된다고 합니다. CleanTable은 식탁 위를 닦아서 깨끗하게 만드는 작업으로, 젖은 천으로 표면을 문질러 오물을 제거해야 하므로 유체와 flexible한 물체를 다루는 섬세한 조작 기술이 필요했다고 합니다. 예시 task들은 비교적 일상적이면서도, 물체 파악, 이동, 조작에 이르는 통합적인 역량을 시험할 수 있는 시나리오라고 합니다. 또한 난이도 면에서 BEHAVIOR-1K 전체 중 비교적 단순한 축에 드는 작업들임에도, 실제로는 long horizon이고 복합 물리적인 조작을 포함하고 있어 당시의 기술로 풀기 상당히 까다롭다는 점이 강조되었습니다.
저자들은 위 활동들에 대해 강화학습 기반의 대표적인 알고리즘들을 활용한 벤치마크 실험을 수행했습니다. 구체적으로, 세 가지 접근법이 비교되었습니다. 로봇에 raw 센서 입력을 주고 학습하도록 하는 방식인 end to end Visuomotor 제어 (RL-VMC), primitive 행동(이동,집기,놓기,닦기 등) 기반 RL (RL-Prim.), RL-Prim에 history를 더해 장기간의 의존성을 더 학습시키는 방식으로 평가됐습니다. RL-VMC 방식은 세 과제 모두에서 전혀 성공하지 못했는데, 이는 상태 공간이 복잡하고 단계 수가 많은 문제에서 발생하는 이슈라고 분석했다고 합니다. 반면, Primitive motion들을 사용한 방법들은 일정 수준 성과를 보였는데, 특히 메모리까지 부여한 RL-Prim + History 에이전트는 StoreDecoration과 CollectTrash에서 40% 이상의 성공률을 달성했습니다. CleanTable의 경우 천과 액체를 다루는 난이도 높은 조작이 필요해서인지 여전히 성공률이 낮았지만, 나머지 두 작업에서는 의미 있는 정책 학습이 가능함을 확인했다고 합니다. 예컨대 CleanTable 작업은 최적 수행에 6개의 primitives(이동→집기→물적시기→이동→닦기→완료 등)이면 되지만, CollectTrash는 최소 10회 이상의 행동들이 요구되어 훨씬 긴 계획이 필요했다고 합니다.
BEHAVIOR-1K는 현실성 높은 시뮬레이션을 지향하기 때문에, 궁극적으로 시뮬레이션에서 학습한 로봇 정책을 실제 환경에 적용하는 가능성을 시험해보는 것이 중요했다고 합니다. 이를 위해 연구팀은 CollectTrash 활동을 선택하여 초기적인 Sim-to-Real 실험을 진행했습니다. Stanford 캠퍼스 연구실 내에 원룸 형태의 모형 아파트를 구성하고, 동일한 구조와 객체 배치를 가진 가상 장면(mockup_apt)을 OmniGibson에서 생성했습니다. 이 가상 장면은 실제 공간을 3D 스캔하여 벽과 바닥 형상을 얻고, 그 자리에 데이터셋의 3D 객체 모델을 대응시켜 만들었다고 합니다. 로봇 플랫폼으로는 PAL Robotics사의 Tiago 모델을 사용했는데, 7-dof dual arm을 가진 모바일 매니퓰레이터로, 사람 수준 높이의 RGB-D 카메라와 LiDAR 센서를 장착했다고 합니다. 연구팀은 시뮬레이션 상의 동일한 Tiago 로봇에게 RL-Prim.Hist. 방식으로 쓰레기 수거 정책을 학습시킨 후, 이를 실제 환경의 Tiago에게 이식하여 성능을 관찰했습니다. 결과적으로 가상환경에서 성공을 보인 정책이 현실에서도 유사한 동작을 수행하긴 했지만, 예상대로 시뮬레이션-현실 간 격차로 인한 어려움도 관찰되었다고 합니다.

왼쪽 사진을 보면 시뮬레이터 환경에서 얻은 사진과 현실에서의 사진이 조금 차이가 있다는 것을 볼 수 있습니다. 텍스쳐나 노이즈가 살짝 다르고 오른쪽 그래프는 실패의 원인을 시뮬레이션(S), 시뮬레이션 기반 정책을 실제에 적용했을 때(R-TP), 그리고 최적 정책을 실제에 적용했을 때(R-OP)로 나누어 비교 분석한 것입니다. 동작을 실패한 것과 인지를 실패한 기준으로 나누었습니다. 시뮬레이션 환경에서는 대부분의 실패가 어떻게 보면 당연하지만 부정확한 action primitive selection에 기인합니다. 반면, 실제 환경에서 시뮬레이션 기반으로 학습한 정책(R-TP)을 적용했을 때는 실패의 양상이 바뀌었스빈다. 여기서는 파지 실패와 함께 perception error가 주요 실패 원인으로 작용했습니다. 이는 시뮬레이터에서는 일관되게 렌더링된 객체가 실제 영상에서는 조명, 반사, 그림자, 센서 노이즈 등으로 인해 정확하게 인식되지 않거나, 위치 추정이 틀어지기 때문이었다고 합니다. 최적 정책(R-OP)을 사용할 경우에도 완전한 성공은 보장되지 않으며, 여전히 객체 인식의 실패가 주요 장애 요소로 나타난 것으로 봤을 때 이는 현재의 시뮬레이터가 물리적 동역학은 충실하게 모델링할 수 있어도, 시각적 인식 편차를 완전히 흡수하지는 못함을 의미한다고 합니다. 시뮬레이터의 고질적인 문제점 때문에 시뮬레이터 단일로 학습하는 것에는 상당한 어려움이 있지 않을까 합니다..
긍정적인 측면으로는 LiDAR를 통한 거리 감지나 로봇의 이동 제어 등은 비교적 그대로 현실에 적용되어, 로봇이 방을 돌아다니며 쓰레기 위치를 탐색하고 주워 담는 일련의 동작 자체는 실행 가능했다고 합니다. 그러나 시각적 인식 부분에서의 미세한 차이가 누적되어 일부 실패 사례가 발생했는데, 예를 들어 가상 시뮬레이션에서는 항상 일정한 광원과 카메라 특성으로 영상을 얻었지만, 실제 로봇 카메라는 동일한 장면에서도 조명 밝기나 색감이 다르게 보이거나 깊이 센서의 센서 잡음이 존재했다고 합니다. 특히 실제 RGB 카메라의 낮은 HDR 특성과 Depth 센서의 광 투사 방식으로 인한 그림자 효과 등은 OmniGibson에서 모델링 되지 않았고, 이러한 차이로 인해 로봇이 특정 쓰레기 물체를 인지하지 못하거나 잘못된 위치로 팔을 뻗는 문제가 일부 나타났다고 합니다. 그럼에도 불구하고, 전반적으로 시뮬레이터의 높은 물리/시각 충실도 덕분에 상당 부분 유사한 행동을 현실에서 구현할 수 있었으며, 실패 원인도 명확하게 분석할 수 있었다고 합니다. 결국 시뮬레이터의 한계는 당연하지만 그대로 남아있는 것 같습니다. 다만 최근 등장한 Digital Cousin을 활용한 Real, Synthetic Co-training이나 GR00T-n1 같은 모델들을 보면 데이터셋 자체를 활용하는 방법은 여러가지로 있지 않을까 싶습니다. 여러 복잡한 물리적인 특성들이 구현된 것도 특장점 중 하나인 것 같습니다. 다만 연구실 환경에서 켜봤을 때 렌더링이 왜 깔끔하지 않은지는 조금 더 살펴봐야 할 것 같습니다.
영규님 좋은 리뷰 감사합니다.
설문 조사를 기반으로 실제 사용자들이 필요로 하는 것이 무엇인지 조사한 뒤 이를 기반으로 데이터 셋을 구성하였다는 것이 중요한 contribution인 것 같습니다. 이에 대해 저자들이 task를 선정하는 데 만 이용한 것인 지 궁금합니다.
또한, ‘task를 정의할 때 어느 장면에서 수행될 수 있는지에 대한 정보가 있어, 동일한 활동이라도 주방이 있는 집, 야외 정원 등 여러 맥락에서 시험될 수 있다’고 하셨는데, 어느 장면에서 수행할 수 있는지에 대한 정보는 환경에 대하여 multi-label과같은 형식으로 제공되는 것인지 궁금합니다.
감사합니다.
안녕하세요 승현님 댓글 감사합니다.
말씀하신것처럼 설문조사는 단지 어떤 태스크로 구성할지만 정하는데 쓰이긴 했습니다. 다만 여태까지의 연구자 중심의 데이터셋과는 달리 사용자 수요기반으로 bottom up 접근을 취했다는 점에서 굉장한 의미가 있다고 합니다. 소비자들이 원하는 로봇을 만드는 것이 기술적 성숙도만큼 중요하다는 점을 언급했습니다.
두번쨰 질문의 경우 bddl로 정의된 scene들은 활동별로 장면 내에 필요한 객체가 존재하는지, 공간 구조나 기능적 요구조건을 만족하는지를 filtering하는 ActivitySampler가 존재합니다. 이를 통해 어떤 task가 조건을 만족하는 여러 scene에서 인스턴스화 될 수 있고, 이는 multi-label과 같은 형식입니다.
안녕하세요 영규님 좋은 리뷰 감사합니다. 궁금한 부분이 있어서 남겨놓습니다.
Q1. OmniGibson에서 Fluids나 Deformable가 어떻게 구현되어 있는지 궁금합니다. 객체 종류가 정해져 있고, 그 물리적 속성이 고정되어 있는 식으로 구현되어 있는 것인가요?
Q2. Simulation에서 렌더링 품질이 좋으면 로봇 연구 관점에서 어떤 점이 좋은지 궁금합니다.
Q3. BDDL은 OmniGibson에서만 사용할 수 있는 것인가요? BDDL이 다른 벤치마크에서도 쓰이고 있는지 궁금합니다.
Q4. Simulation이나 물리엔진이 발전됨에 따라서 Simulation의 성능을 평가할 때 사용되는 벤치마크 같은 것들이 존재하는지 궁금합니다.
감사합니다.