안녕하세요, 이번주는 디지털 트윈 환경을 이용해 기존의 모방학습과 강화학습의 정책들을 더 강인하게 만드는 프레임워크에 대한 논문입니다. 기존의 엄청난 인력을 요구하고 강인한 정책을 학습하기 힘든 모방학습과 마찬가지로 현실적으로 충분한 데이터 수집이 어려운 강화학습의 한계점을 현실에서 적은 데이터로 만든 모방학습 정책의 시뮬레이션 환경을 통한 강화학습으로 탄탄한 정책을 만드는 시스템입니다. 아래에서 더 자세하게 다루도록 하겠습니다.
Introduction
로봇이 어떤 작업을 수행하는데에는 다양한 환경 변화를 고려해야 합니다. 예를 들어 부엌에서 접시를 정리하는 작업을 진행한다면 다양한 접시의 배치, 선반의 위치가 상황마다 다를 수 있고 주변의 잡동사니나 조명과 같은 시각적 방해 요소들도 존재합니다. 저자는 이런 로봇 작업의 특성상 로봇은 다양한 환경에 강인해야 할 필요가 있다고 주장합니다. 더 나아가 이러한 학습 프레임워크가 실제 환경에 활용 가능하려면, 다양한 작업에 적용할 수 있고 쉽게 학습 시킬 수 있는 프레임워크가 필요하다고 주장합니다.
기존의 다양한 작업에 적응할 수 있는 강인한 로봇의 개발은 방대한 양의 데이터가 필요합니다. 하지만 이는 실세게에서 수집하기 굉장히 어렵다는 문제가 있고, 특정 데이터로 로봇을 학습시킬 때 모든 환경에서 강인하게 동작하는 것을 목표로 하는 보편성을 강조하는 정책은 낮은 성공률을 나타낼 수 있습니다. 따라서 저자는 특정 환경(사용자의 환경)에서 잘 학습해 동작하는 것을 목표로, 인간의 개입을 최소화한 정책 학습을 고민했습니다.
모방학습은 정책 학습에 유용하지만 실수했을 때 복구하거나 새로운 환경에 대응하는 능력이 부족하고, 특히 데이터가 적을 경우 강인한 제어정책을 구현하기 어렵다는 문제가 있고, 모방학습의 강인성을 갖출 정도의 대규모 데이터 수집은 불가능하기 때문에 확장성 문제를 초래할 수 있습니다. 따라서 생성모델을 사용해 억지로 시각적인 방해요소를 추가해 학습하는 경우도 있지만 이러한 경우에도 물리적이거나 동적인 방해요소에 대한 학습이 불가능 하다는 한계가 남아있습니다.
강화학습은 이러한 모방학습으로만 학습된 모델의 성능을 향상시킬 수 있습니다. 기존의 연구들은 모방학습으로 학습한 정책을 fine tuning할 때 강화학습을 사용하고, 전문가 시연 데이터를 활용해 보완시켰습니다. 하지만 현실세계에서의 강화학습은 안정성 문제나 시간문제등이 발생할 수 있고, 따라서 초기의 모방학습 모델을 실제환경을 비디오 기반으로 생성한 외형적, 운동학적 특성을 정밀하게 반영한 시뮬레이션 환경에서 강화학습을 진행시키면서 그 부담을 줄이고자 RialTo라는 프레임워크를 제안했습니다.
그렇다고 시뮬레이션 기반에서 강화학습을 활용하는 연구가 없었던 것은 아닙니다. Domain Randomization, system identification등의 시뮬레이터와 현실을 현실을 대체하는 만큼 외형적, 운동학적 특성을 반영한 시뮬레이션 환경을 구축하는 것도 정말 중요한 요소인데, 저자가 말하길 실제 환경의 라그랑주 상태( 물체의 위치나 물리적 특징들이라고 이해했습니다)를 직접 얻을 수 없기 때문에 이 논문에서 Inverse-Distillation이라는 기법을 제안했다고 합니다.
한마디로 요약하자면 실세계의 모방학습을 시뮬레이션에서 강화학습(Real to Sim) 후, 다시 실세계로 전환(Sim to Real)하면서 모방학습과 강화학습의 장점을 결합하며 이 과정에서 인간의 개입을 최소화 하겠다는 취지의 프레임워크입니다. 이러한 Real-to-Sim-to-Real 프레임워크는 데이터 수집의 부담을 줄이고, 보상 함수를 엔지니어링 하는 과정 없이 기본 기법보다 67%나 향상된 성공률을 보인다고 합니다.
RialTo
RialTo는 실제 세계의 센서 입력을 로봇의 액션으로 변환하는 정책을 학습하는 것이 목표이고, 이를 위해 전문가를 동원해 15개 정도의 데이터만 시연 데이터로 활용합니다. 앞서 말했듯 시뮬레이터를 이용한 시뮬레이션 환경 기반 강화학습을 활용해 기존 시연데이터을 사용한 모방학습으로 학습하지 못 한 방해요소들에 강인함을 얻게됩니다. 이를 위해 아래와 같이 실세계 이미지를 활용한 시뮬레이션 환경 구축(Real-to-Sim Transfer) → Inverse Distillation을 통한 실세계 시연 데이터 변환 → 강화학습을 활용한 정책 미세 조정 및 강화 → 학습된 정책의 실세계 전이(Sim-to-Real Transfer)을 거칩니다. 이러한 co-training(현실세계의 시연 데이터와 시뮬레이션 데이터를 함께 학습하는 점)은 시뮬레이션을 통해서 강인함을 증가시키고 현실세계의 현실성 있는 데이터의 이점을 전부 활용할 수 있어서 최소한의 시연데이터로 인간의 개입을 최소화하여 효율적으로 학습할 수 있는 프레임워크를 제공한다고 합니다.
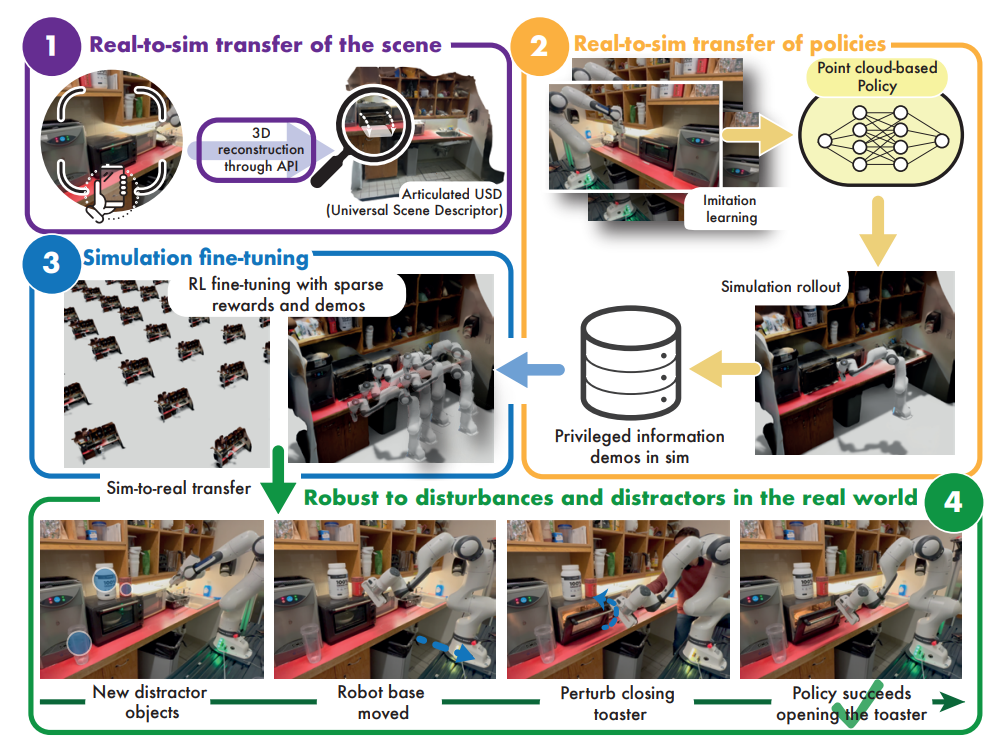
Real-To-Sim Transfer
RialTo의 첫 번째 단계인 Digital Twin 구성은 기하학적, 시각적, 역학적으로 현실적인 시뮬레이션 환경을 구축하는 과정입니다. 이를 위해 figure와 같은 단계를 통해 이미지를 기반으로 정확한 텍스처가 적용된 3D 기하 구조를 생성하고, 생성된 물체의 관절과 물리적 특성을 지정하는 과정이 필요합니다. 우선 멀티뷰 이미지나 비디오 데이터를 Polycam, ARCode와 같은 스캐닝 앱을 통해 텍스처가 적용된 3D mesh로 변환합니다. 하지만 이러한 mesh(G)는 물체가 분리되지 않고 내부 관절 구조 및 물리적 특성이 반영되지 않는 문제가 있습니다. 따라서, mesh(G)를 개별 물체 {Gi}M_{i=1}와 그에 대응하는 운동학적 관계(K), 물리적 특성(P)으로 분할하는 추가적인 과정이 필요합니다. RialTo에서는 이러한 과정을 사용자가 조작할 수 있는 GUI를 제공합니다. 직접 개별 물체를 정의해서 분리하고, 관절이 어떻게 움직이는지 추가하는 과정을 통해 스캔된 객체를 다룰 수 있고, 특정 도메인 지식이 없이도 사용할 수 있도록 설게해서 실제로 비전문가 6명을 대상으로 한 실험에서 15분 내에 복잡한 장면을 스캔하고 관절이 포함된 digital twin 환경을 구성할 수 있다고 합니다. 이제 남은 문제는 실제 환경을 정확하게 반영하는 물리적 파라미터(질량, 마찰계수)를 어떻게 설정할 것인가 인데, 저자는 정확한 물리적 특성을 파악하는 것은 가능하지만, 이를 위해서는 상당한 양의 현실에서의 노동이 필요하므로 구현이 어렵다고 합니다. 따라서 해당 연구에서는 개별 객체의 물리적 특성을 default value로 설정하고, 실세계 시연 데이터와의 일관성을 유지하도록 학습된 정책을 통해 sim-to-real gap을 보정하는 방법을 사용합니다. 최종적으로 생성된 장면 S = {{Gi}M_{i=1}, K, P}는 분리된 메시({Gi}M_{i=1}), 운동학적 관계(K), 물리적 파라미터(P)를 참조하는 USD/URDF 파일 형식으로 저장되며, 이를 그대로 시뮬레이터에서 활용합니다.

Robustifying Real-World Imitation Learning Policies in Simulation
RialTo의 두 번째 단계는 생성된 Digital Twin 환경을 이용한 시뮬레이터 환경에서 강화학습을 활용해 현실에서 수립한 모방학습 정책을 강인하게 만드는 것입니다. 일반적으로 강화학습 처음부터 시뮬레이션에서 학습하는 것은 속도가 매우 느리고, 보상함수 설계, 에이전트의 탐색문제 해결 등 수작업 엔지니어링이 많이 필요하기 때문에 비효율적이라고 합니다. 이를 보완하기 위해 RialTo는 현실세계에서 수집한 15개 정도의 시연 데이터를 기반으로 초기 정책을 설정하고, 이를 시뮬레이션에서 강화학습으로 fine-tuning 합니다. 그러나 강화학습을 visual observations에서 직접 학습하는 것은 어렵기 때문에, 낮은 차원의 Lagrangian 상태를 기반으로 학습하는것이 효율적이라고 합니다. 하지만 실세계 시연 데이터에는 이러한 상태 정보가 포함되어 있지 않기 때문에, 저자는 Inverse Distillation 기법을 도입하여 실세계 시연 데이터를 시뮬레이션 환경에서 학습 가능한 상태 기반 데이터셋으로 변환합니다.
현실세계의 시연 데이터 D_real = {(o_1^i, a_1^i), …, (o_H^i, a_H^i)}_{i=1}^{N} 는 3D 포인트 클라우드(o)와 엔드 이펙터 이동 경로(a) 를 포함합니다. 하지만 효과적인 강화학습을 위해서는 compact state representation 기반으로 정책을 fine tuning 해야 하며, 실세계 시연 데이터를 직접 강화학습에 활용하기 어렵습니다. Compact state representation을 통해 공간을 압축해서 고차원의 느린 학습속도와 sparse reward환경에서의 강화학습이 어렵다는 점을 극복할 수 있습니다. 따라서, RialTo는 시각 기반 모방 학습 정책(π_real(a|o))을 시뮬레이션에서 실행하여 새로운 데이터셋 D_sim을 생성하는 방식을 채택했습니. 이 과정에서 시뮬레이션 내에서는 Lagrangian 상태(s)가 존재하므로, 시뮬레이션에서 (o, a, s) 쌍을 만듭니다. 즉, 실세계 시연 데이터를 시뮬레이션에서 다시 실행함으로써 실세계에서는 얻을 수 없는 특권 정보(privileged state information)를 포함한 데이터셋 D_sim = {(o_1^i, a_1^i, s_1^i), …, (o_H^i, a_H^i, s_H^i)}_{i=1}^{M}을 생성할 수 있습니다. 이러한 D_sim을 만들어내는 과정을 Inverse Distillation이라고 합니다. 이러한 특권 정보가 담긴 D_sim을 통한 학습이 강화학습 fine tuning의 핵심이라고 할 수 있을 것 같습니다. 실세계에서는 Lagrangian 상태를 직접 수집할 수 없지만, 시뮬레이션에서는 센서 input과 Lagrangian 상태 간의 매핑이 이미 존재하기 때문에, 시뮬레이션을 활용하여 특권 정보를 포함한 새로운 학습 데이터셋을 생성할 수 있다는 점입니다. 이렇게 생성된 D_sim을 활용하여 강화학습을 진행하여 강인함을 얻을 수 있습니다. 제가 이해한 바로는 point cloud와 lagrangian의 관계를 이미 알고있는 시뮬레이터 환경에서 센서데이터(o)를 물리적 정보(s)로 바꿔서 더 낮은 차원의 데이터를 만드는 것입니다.
생성된 D_sim과 시뮬레이션 환경을 활용하여 강화학습을 수행하고, 최적화된 정책 π_sim^*(a|s)을 학습합니다. 그러나 강화 학습을 확장성 있게 만들기 위해서는 최소한의 보상 설계로 복잡한 보상 함수를 정의하지 않은 상태에서 강화학습을 할 수 있어야 하고, 학습된 정책이 현실세계에서도 정상적으로 동작할 수 있도록 보장해야 합니다. 저자는 domain randomization을 통해 이 문제를 해결합니다.
먼저, 탐색 문제를 해결하기 위해 희소 보상(sparse reward) 방식을 사용하며, 장면이 목표 상태에 도달했는지 감지하는 간단한 보상 함수를 task별로 아래 왼쪽과 같이 정합니다. 또한, 기본 강화 알고리즘으로 아래 오른쪽과 같 Proximal Policy Optimization (PPO) 를 사용하며, imitation learning loss를 추가하여 학습을 진행합니다. 이를 통해 정책이 실제 환경에서 물리적으로 타당한 행동을 학습하도록 유도할 수 있다고 합니다.

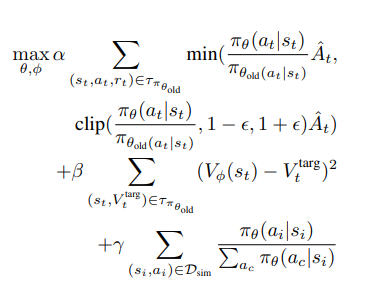
PPO의 목적함수를 자세하게 살펴보면 세개의 항으로 이루어져 있습니다. 순서대로 기존정책 (old)와 새로운 정책 간의 차이를 조절하는 역할을 하는 항으로 r_t(theta)값 (A햇+t와 곱해진 분수값)이 1보다 크면 새로운 정책이 해당 행동을 더 선호하는 것이고, 1보다 작다면 덜 선호한다는 것입니다. A햇_t 값은 그 행동이 얼마나 좋은지 (Advantage)에 해당하는 값으로 해당 값이 크면 그 행동을 더 자주 선택하게 됩니다. clip 부분은 정책이 급격하게 변하는 것을 방지하기 위해 clipping을 적용하는 부분입니다. 다음으로는 현재 상태에서 기대되는 보상을 예측하는 값과 실제로 받은 보상값의 MSE를 나타냅니다. 마지막 항이 Imitation learning Loss인데, 이 항을 통해 Inverse Distillation을 통해 얻은 D_sim을 활용해 강화학습을 하면서 비현실적인 행동을 학습하지 않는 강화학습을 가능하게 해줍니다. 한마디로 현실성을 생각한 모방학습 기반의 정확한 보상을 점진적으로 학습할 수 있도록 설계된 함수입니다.
Sim-to-Real Transfer with Co-Training on Real-World Data
특권 정보를 활용하여 시뮬레이션에서 강인한 정책을 학습했지만, 이는 시뮬레이터 상에 존재하는 값이기 때문에 현실 세계에서는 이러한 특권 정보를 사용할 수 없으며, 정책이 포인트 클라우드와 같은 센서정보 만으로 동작해야 합니다. 이를 해결하기 위해, RialTo는 Teacher-Student Distillation 기법을 활용하여 시뮬레이션에서 학습된 정책을 실세계에서도 동작할 수 있도록 변환하는 과정을 수행합니다.
이 과정에서 시뮬레이션 으로 학습한 정책이 Teacher 역할을 하고, 실세계에서 센서 입력만으로 작동하는 정책이 Student 역할을 하게 됩니다. 또한, DAgger(Dataset Aggregation) 알고리즘을 사용하여 실시간으로 데이터를 보강함으로써, 시뮬레이션과 실세계 간의 domain shift를 줄이고 일반화 성능을 향상시킵니다. DAgger는 강화학습, 모방학습에 사용되는 데이터 수집 기법으로 학습된 정책이 실제 환경에서 수행하는 과정을 전문가가 감시하면서 새로운 데이터를 추가적으로 수집해 학습 데이터의 분포를 실세계 상황과 일치하도록 지속적으로 업데이트합니다. 문제가 생기는 out of distribution 상태일 때 전문가가 추가적인 데이터를 제공해 올바르게 수행하지 못 하는 상태를 개선할 수 있다고 합니다. RialTo의 경우 전문가가 개입하지 않고 초기에 수집된 전문가 데이터를 활용해 시뮬레이션에서 자체적으로 보정합니다.
Teacher-Student 학습 과정은 아래와 같은 co-training 목적 함수를 최적화하는 방식으로 진행됩니다.
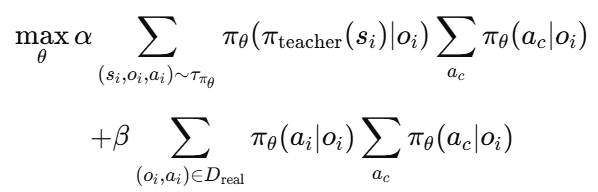
첫 번째 항은 DAgger 학습을 위한 loss이고, teacher의 행동을 student가 모방하도록 유도합니다. 두 번째 항은 D_real을 활용해 학생 정책을 추가적으로 학습하는 과정으로, 시뮬레이션 상에서 학습한 정책이 현실 세계에서도 잘 동작할 수 있도록 보정해주는 역할을 합니다. 이러한 과정을 통해 co-training을 할 수 있고, 이는 소량의 현실 데이터만으로도 효과적인 정책 학습을 하고 특권 정보를 통해 학습한 정책을 현실에서 pointcloud 만으로 동작하는 정책으로 변환시켜줄 수 있게 됩니다.
Experimental Evaluation
RialTo의 실험은 RialTo가 다양한 환경 변화(객체 배치 변화, 외형 변화, 물리적인 방해 등)에도 강인한 정책을 학습할 수 있는지, Co-Training이 현실 세계에서의 성능 향상에 기여하는지, Real-to-Sim 전이가 학습 효율성과 최종 성능 향상을 위해 필수적인지, RialTo가 다양한 실제 환경에서도 확장 가능한지에 초점을 맞추고 진행했다고 합니다. 이를 검증하기 위해, 저자는 6개의 Task를 통해 RialTo를 평가하였습니다. 실험은 난이도에 따라 점점 어려워지는 세 가지 환경 방해요소들을 추가했습니다. 물체와 로봇의 초기위치를 랜덤하게 설정하고, 주변에 의미없는 잡동사니 배치를 통한 occlusion도 밠행시키고, 한 장면을 진행하는 중 대상 물체나 목표 위치를 변경하거나 로봇 베이스를 움직이는 등의 물리적인 방해도 진행했다고 합니다. 평가는 각 방법론들 별로 최적의 정책을 활용해 평균 성공률을 측정해서 표준편차를 계산했습니다.
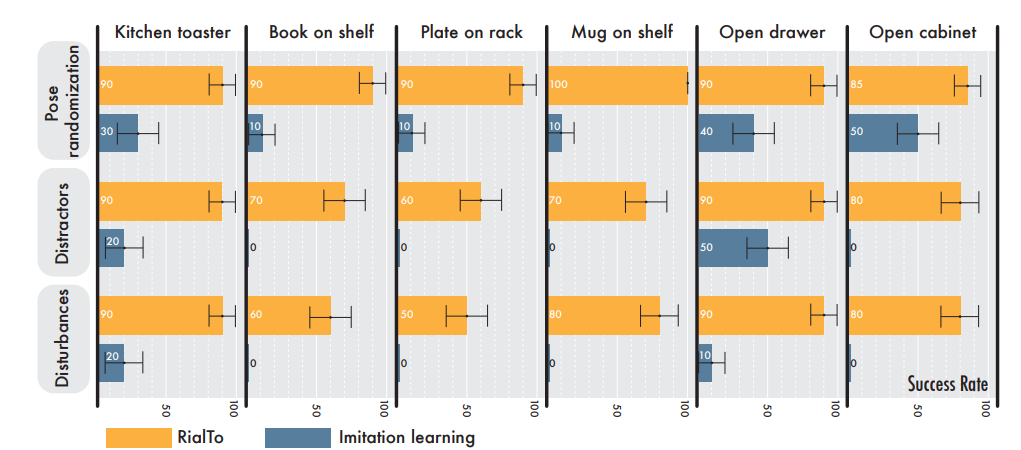
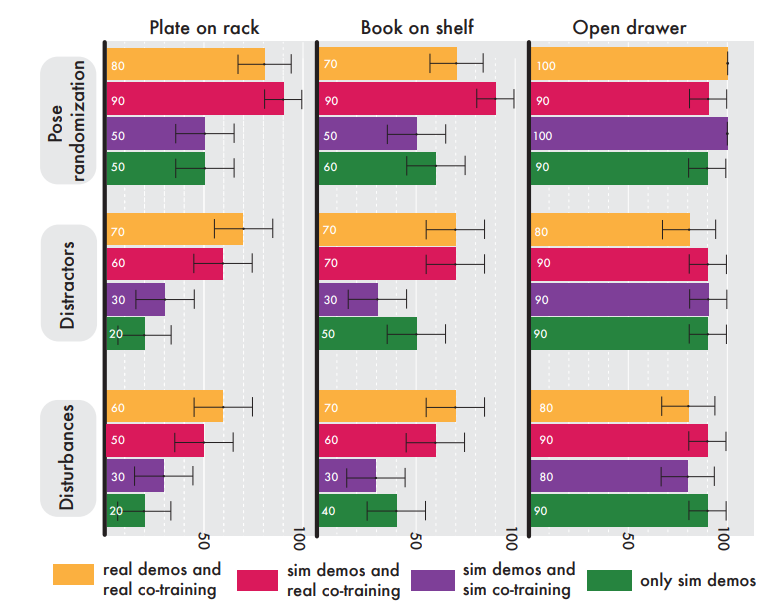
Success Rate를 보게되면 RialTo는 기존의 모방학습이 환경변화에 매우 취약한 점과 비교해 봤을 때 각종 장애물과 다양한 환경 변화에도 높은 성공률을 유지하는 것을 볼 수 있습니다.
다음은 Sim to Real transfer 과정에서의 teacher student distillation이 얼마나 성능 향상에 기여하는지에 대한 실험을 진행했습니다. 저자들은 실세계 데이터 없이 시뮬레이션 데이터만으로 학습한 정책과 비교하여 실세계에서의 성능 차이를 평가하였는데, 책을 책꽂이에 놓는것과 접시를 랙에 넣는등 특히 어려운 task에서 비약적인 성능 향상을 볼 수 있었다고 합니다. 서랍열기와 같은 쉬운 task에서는 co-training과의 차이가 거의 나타나지 않지만 어려운 task의 경우 2배에서 3배 이상까지 작업 성공률의 차이가 있었습니다. 저자는 이러한 차이가 시뮬레이션에서 생성된 pointcloud와 현실의 pointcloud가 다르기 때문이라고 주장했습니다.
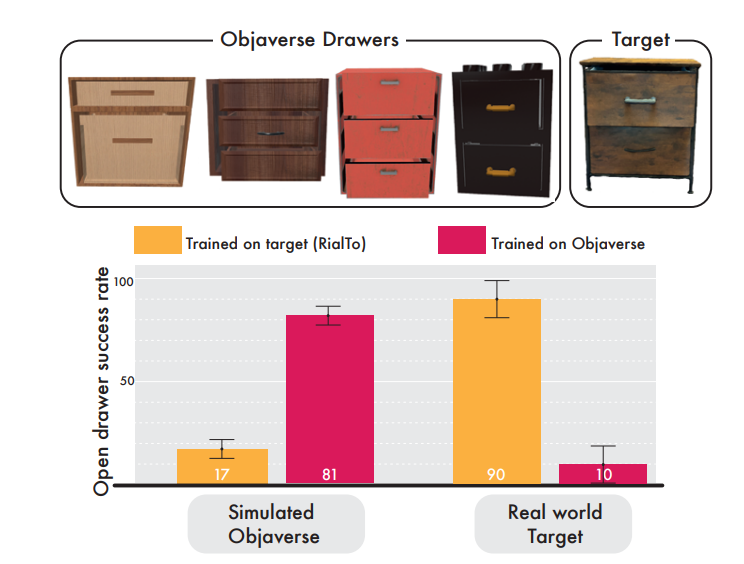
세번째는 Real-to-Sim과정이 성능 향상에 필수적인지에 대한 실험이었습니다. 이를 검증하기 위해 실제 환경을 복제한 시뮬레이션 환경 없이, 다양한 synthetic 환경에서 학습한 정책이 현실세계에서 일반화될 수 있는지, 실제 세계에서 수집한 데이터만으로 학습한 경우에 성능은 어떤지를 비교했습니다. Objaverse 데이터셋(합성 데이터셋)에서 학습된 정책은 Real World Target에서 거의 작동하지 못 하는 모습을 보여주는 반면, RialTo는 90%의 성능을 보여주었습니다. 기존에도 Real to Sim은 중요하다고 생각했지만 이렇게 수치로 보니 정말 로봇 정책 학습에 있어서 Real to Sim은 핵심인 것 같습니다.
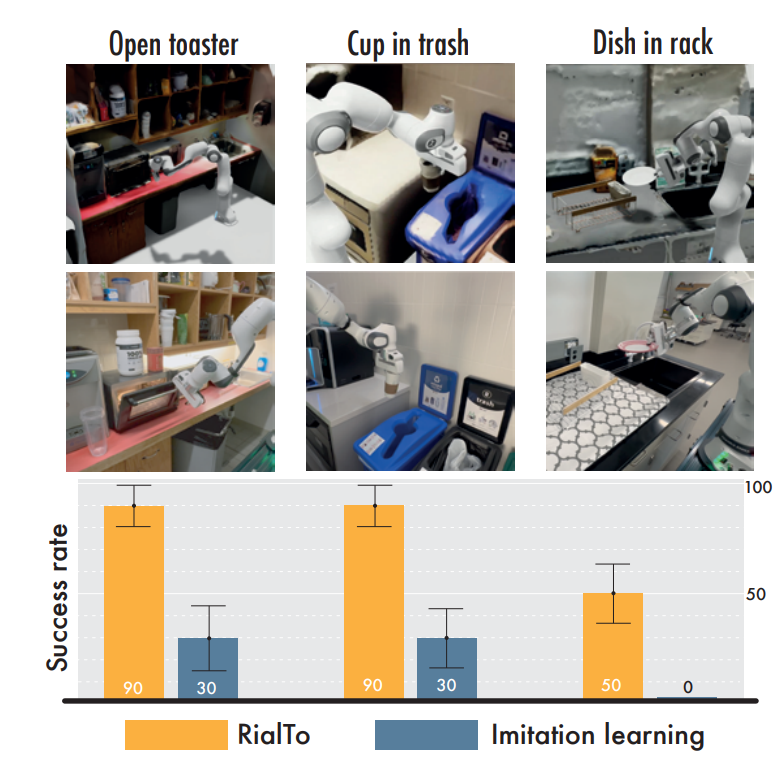
마지막으로는 이렇게 학습된 RialTo가 실험실을 벗어난 Wild 환경에서는 어떻게 동작하는지에 대한 실험이었습니다. 복잡한 현실의 환경에서도 기존 모방학습 보다 57%나 높은 성능을 보여주었습니다. 특히 접시를 받침대에 넣는것과 같은 어려운 작업은 모방학습은 의미가 아예 없었던 반면 50퍼센트의 성공률을 보여준다는 것은 정말 대단한 것 같습니다.
Ablation Study
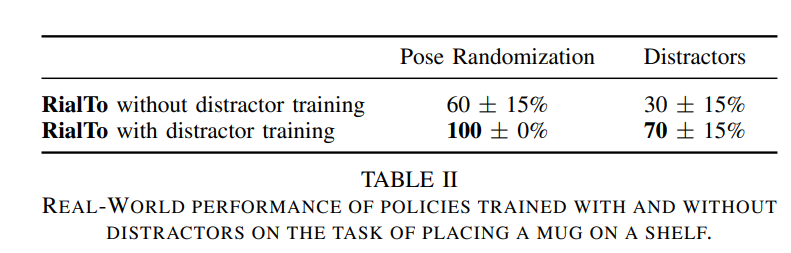
저자는 teacher-student distillation 과정에서 domain randomization뿐 만 아니라 visual distractor를 추가하는 것이 얼마나 강인함을 높여줄 수 있는지 실험을 진행했습니다. 실험 결과 Distractor를 추가한 경우 훨씬 더 높은 작업 성공률을 보였습니다. 하지만 왜 선반에 머그잔을 올려두는 task만 표에 있는지는 의문입니다..
또 RialTo의 핵심중 하나인 강화학습을 모방학습의 fine tuning으로 쓴다는 점에 대해서 PPO를 처음부터 학습하는 것과 RialTo의 방식을 비교해 봤을 때, PPO를 처음부터 학습한 경우 토스터기를 열 때 바닥을 밀어버리는 등의 현실적으로 말이 안 되는 행동을 학습하는 것을 볼 수 있었습니다. 뿐 만 아니라 전반적으로 RialTo의 학습이 안정적으로 여러 task에서 높은 성능을 기록했습니다.

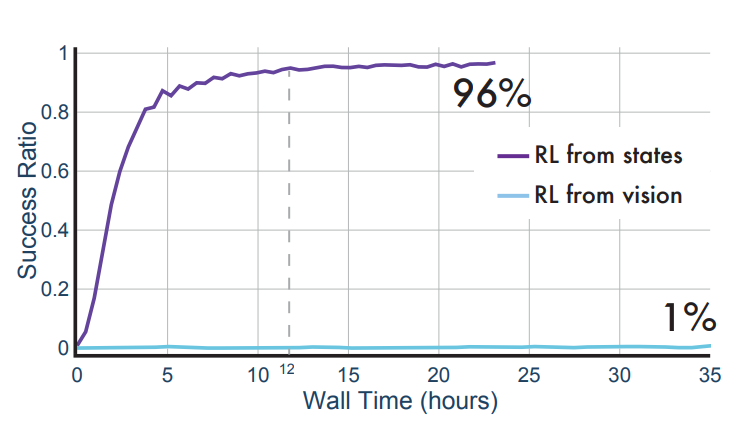
마지막으로 RialTo의 Inverse Distillation을 통해 compact state space에서 강화학습을 진행했을 때 거의 학습이 안되던 강화학습이 학습 가능해졌다는 점을 알 수 있습니다. Inverse Distillation 또한 RialTo의 굉장히 핵심적인 내용 중 하나라고 봐도 무방할 것 같습니다.
Limitations and Conclusion
RialTo는 어찌됐든 3D Pointcloud를 활용한 학습이기 때문에, 얇은 물체, 투명한 물체, 반사되는 물체를 감지하는데 많은 어려움이 있다고 합니다. 또한 Articulation이 있는 Rigid Body (강체)는 디지털로 변환이 용이하고 변형이 되지 않기 때문에 안정적으로 학습할 수 있지만 그렇지 않은 물체들은 시뮬레이터 상에 올리는 과정에서 어려움이 있다고 합니다. 또 학습 과정이 각 task당 2일정도 걸려서 빠르게 정책을 업데이트 하는것에 어려움이 있지만, 이는 pointcloud를 최적화 하거나 parallelize하는 기법을 적용하면 개선할 수 있다고 합니다. 그래도 안되던 학습이 가능해졌다는 점에서 의미가 있지 않나 싶습니다. 이번 논문을 통해 Digital Twin과 시뮬레이터의 중요성을 느끼게 되었습니다.
영규님 좋은 리뷰 감사합니다.
몇 가지 질문 남기고 가겠습니다.
Q1. Real co-training과 Sim- co-training의 차이가 무엇인지 궁금합니다.
Q2. 본 문 중 “이러한 과정을 통해 co-training을 할 수 있고, 이는 소량의 현실 데이터만으로도 효과적인 정책 학습을 하고 특권 정보를 통해 학습한 정책을 ‘현실에서 pointcloud 만으로 동작하는 정책으로 변환’시켜줄 수 있게 됩니다.”에서 해당 기법의 최종 인풋은 point cloud만 들어가는 것이 맞는지 궁금합니다.
안녕하세요 태주님 리뷰 읽어주셔서 감사합니다!
A1. 논문에 Real co-training이나 Sim co-training이라는 표현이 직접적으로 언급되진 않습니다. sim에서 강화학습을 통해 학습된 정책을 real로 distillation하는 과정 자체를 co-training으로 표현합니다. 다만 강화학습을 진행하고 real로 옮기는 과정에서 현실에서 수집한 데이터인 D_real(3D Pointcloud, trajectory), 해당 데이터를 시뮬레이터 상에 올려 물체에 대한 추가적인 정보를 합친 (Inverse Distillation 과정을 거친) D_sim을 사용해서 Real과 Sim의 상호 보완적인 학습을 진행합니다.
D_sim으로 강화학습을 진행하는 도중 out of distribution문제를 해결하기 위해 D_real 이 사용되고, D_sim으로 학습한 정책을 real로 distillation 해서 현실 세계의 데이터 만으로는 얻을 수 없는 정책을 학습합니다.
추가적으로 강화학습의 exploration이 어렵다는 점을 teacher-student distillation을 통해 해결할 수 있다고 하는데 이 점은 더 공부해봐야 알 수 있을 것 같습니다.
A2. 네. 최종적으로 학습된 정책은 PointCloud의 입력만으로 동작 가능합니다. (논문에는 센서 기반의 데이터로만 동작한다고 언급되어있습니다)
안녕하세요 영규님 좋은 리뷰 감사합니다. 궁금한 부분이 있어서 남겨놓습니다.
Q1. 생성 모델로 시각적인 방해 요소를 추가하는 경우에서 물리적이거나 동적인 방해요소에 대해 학습이 불가능하다고 하셨는데, 물리적이거나 동적인 방해요소의 예시가 궁금합니다. 그리고 동적인 방해요소에 대한 학습이 왜 불가능한지 궁금합니다.
Q2. Real-to-Sim Transfer에서 스캐닝을 통한 텍스처 Mesh와 운동학적 관계와 물리적 특성으로 나누는 과정에서 새로운 물체를 추가할 때마다 새로운 Mesh를 생성하고 다시 GUI 작업을 하는건가요?
Q3. Real-to-Sim Transfer에서 USD/URDF 파일로 저장된 것을 사용하면 고정된 환경을 사용하는 것인데, 이 환경의 신뢰도는 시연 데이터로 모방학습을 통해 학습된 정책에 완전히 의존적인 것인가요?
Q4. 특권 정보를 제외하고 D_sim과 기존의 데이터의 차이가 얼마나 있는지 궁금합니다.
Q5. Sim-to-Real Transfer with Co-Training on Real-World Data에서 DAgger는 전문가의 개입으로 새로운 Data에 대해 정의를 따로 해줘야 하는 것으로 알고 있는데요. OOD 상태에서 어떤 방식으로 전문가 데이터로 자체 보정을 한다는 것인지 궁금합니다.
감사합니다.
안녕하세요 성민님 댓글 감사합니다.
A1. Figure 기준으로 4번 (초록색 부분)이 해당합니다. 시각적인 증강만으로는 해당 상황에 대한 데이터가 없기 때문에 학습 불가능합니다.
A2. 맞습니다. 이를 해결하기 위한 다양한 scene reconstruction 연구들이 진행되고 있습니다. 관심 있으시면 3DGS나 image to 3D를 찾아보시면 됩니다.
A3. 구두로 답변했습니다.
A4. 이외의 정보는 pointcloud입니다. pointcloud의 경우 1차적으로는 3d reconstruction의 완성도가 떨어진 만큼 현실과 다르고, 시뮬레이션의 센서에는 현실과 같은 노이즈가 없기 때문에 해당 차이 또한 존재합니다. 현실보다 훨씬 더 깔끔하게 나오는데, 이게 오히려 현실과 다른 gap으로 작용합니다.
A5. OOD 상태는 RL finetuning중에 생깁니다. DAgger를 통해 특권 정보를 통해 RL 학습한 정책을 pointcloud 기반의 policy로 distill한다고 생각하면 됩니다. 다양한 OOD에서의 RL이 현실 데모와 co-training되는 것을 DAgger로 표현했다고 생각하시면 됩니다.