안녕하세요. 박성준 연구원입니다. 오늘 제가 리뷰할 논문은 ECCV2024에 게재된 R2-Tuning 입니다.
Introduction
먼저 R2-Tuning은 Video Temporal Grounding(VTG) task를 다룬 논문입니다. VTG란, untrimmed(정제되지 않은) video 내에서 자연어 쿼리과 연관있는 구간을 반환하는 task로 큰 범주에서 Video Moment Retrieval(VMR)과 같은 연구입니다. 보통 쿼리에 따라 영상 내 중요 구간을 반환하는 Video Highlight Detection(VHD), 쿼리와 연관있는 부분을 요약하는 Video Summarization(VS) 등의 여러가지 task 중 한가지 task에만 국한되지 않는 general한 연구를 VTG 연구라고 칭하지만 헷갈리기 때문에(?) untrimmed video와 text를 다뤄 video를 grounding하는 task가 VTG이고 grounding은 localizing과 비슷하게 이해해주시면 될 것 같습니다.
리뷰로 돌아와서, 대부분의 VTG 모델이 image-text 사전학습이 되어있는 CLIP의 frame-wise final-layer를 사용해 video의 feature를 추출하고 여기에 정교한 temporal 정보를 추가하기 위하여 SlowFast(video backbone모델로 temporal 정보를 담고 있음)를 추가로 사용합니다. R2-Tuning은 CLIP은 이미 fine-grained level에서 spatial(공간) 정보뿐만 아니라 temporal(시간) 정보를 모델링하는 데에 큰 잠재력을 보여준다고 주장합니다. 또한 CLIP의 마지막 layer만을 사용하는 것이 아닌 각 layer를 사용하는 것으로 각기 다른 granularity에서 유용한 정보를 얻어낼 수 있다고 주장합니다. 위의 motivation에 따라 저자는 Reversed Recurrent Tuning(R2-Tuning)을 제안합니다. 저자가 제안하는 R2-Tuning은 매개변수의 1.5%만을 사용하여 점진적으로 spatial-temporal(시공간) 모델링을 수핼하는 R2 block을 학습합니다. 또한 CLIP의 마지막 layer부터 이전 layer에서의 공간적인 특징을 통합하고 쿼리에 따른 시간적 상관관계를 조정하는 것으로 coarse-to-fine scheme으로 구성되어 있습니다. CLIP backbone만을 활용해 저자는 VMR, VHD, VS의 3가지 task에서 SOTA를 달성함을 강조하고 있습니다.
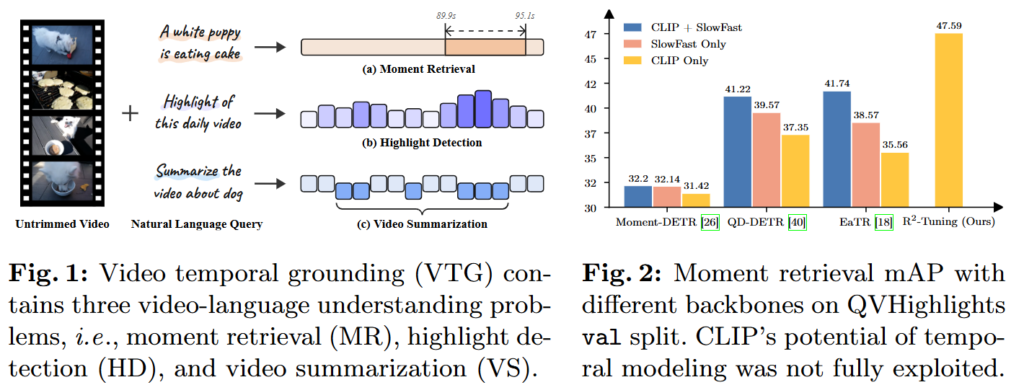
Fig. 1은 VTG task가 3개의 task를 동시에 수행하는 모습을 시각화했고, Fig. 2는 기존 연구들이 backbone모델을 어떻게 사용하는 지에 따른 VMR 성능을 시각화하여 보여주고 있습니다. R2-Tuning은 기존 연구들이 backbone 2개를 사용하여 시간, 공간 특징을 추출하던 것을 CLIP만을 사용함으로 메모리 효율적인 동시에 성능 또한 높아진 것을 실험을 통해 보여주고 있습니다.
사실 기존의 연구들이 CLIP과 SlowFast를 사용한 데에는 이유가 있습니다. Vision-Language Model(VLM)이 몇 년 전부터 인기를 얻으며 많은 VTG 방법론들이 이러한 VLM들을 사용하기 시작했고 그 중 CLIP이 image-text 사전학습 모델로 많이 사용되었습니다. 기존 방법론들은 image와 text의 feature 추출을 위해서 CLIP의 final-layer의 특징에 기반하는 경우가 많았지만 CLIP은 image-text pretrain으로 video의 temporal 정보를 담고 있지 않기 때문에 추가적인 backbone(SlowFast)을 활용하여 temporal 정보를 보완할 수 있도록 했습니다.
하지만, CLIP과 SlowFast 두 backbone 모델을 사용하는 것에는 두가지 단점이 있음을 저자는 지적하고 있습니다. 첫 번째는 유사한 역할을 하는 두가지 backbone을 사용하는 것은 비효율적입니다. vision-text align이 되면서 동시에 spatio-temporal(시공간) 모델링이 가능한 하나의 backbone을 사용하는 것이 더 효율적이라고 주장합니다. 두 번째는 VTG 쿼리는 coarse-grained level부터 fine-grained level까지 다양하게 존재하는 데 CLIP의 final layer만을 사용하는 것은 융통성이 부족하고 high-level detail은 포착하지만, low-level detail은 부족하다는 점을 지적합니다.
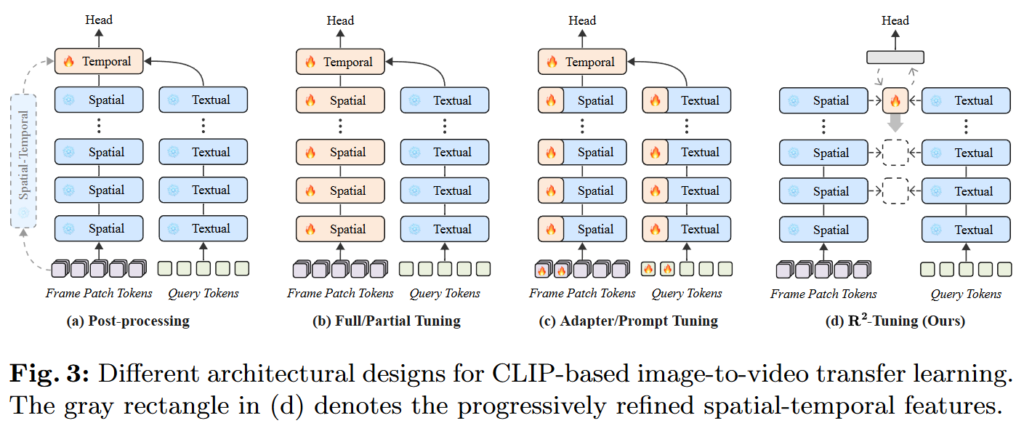
결국 저자가 제일 집중한 부분을 정리하면 efficiency(효율성)과 granularity flexibility입니다. 위 Figure. 3은 (d)에 저저가 제안하는 구조를 보여주며 기존의 다른 방법론들과의 자신들이 제안하는 방법의 차이점을 보여주고 있습니다. (a) Post-processing 방법은 CLIP을 공간 및 텍스트의 feature extracter로 활용하는 가장 간단한 방법입니다. 모든 Temporal 모델링은 CLIP의 final layer의 출력에서 모델링되며 SlowFast와 같은 추가적인 Temporal 백본을 활용하여 시공간 정보를 보완합니다. (b) Full/Partial Tuning은 CLIP의 이미지 혹은 텍스트 백본을 freeze하지 않고 temporal 모듈과 같이 학습하는 방법입니다. 이러한 방법을 채용하는 방법론들은 potential catastrophic forgetting 문제를 해결하기 위해 후처리 작업이 동반됩니다. potential catastrophic forgetting 문제는 인공지능이 새로운 정보를 습득하는 과정에서 기존에 갖고 있던 지식을 잊는 문제로 여기서는 temporal 모델링을 위해 CLIP의 사전학습 정보를 잃어버리는 문제를 말합니다. (c) Adapter/Prompt Tuning 방법은 adapter 혹은 prompt token을 활용하여 사전학습된 지식을 이용합니다. 저자는 이 방법 또한 학습가능한 서브 모듈이나 토큰이 원래의 사전지식 패턴을 방해할 수 있다고 지적합니다. (d)는 저자가 제안하는 방법으로 메인 네트워크에서 사이드 블록으로 adapter를 사용하여 multi-granularity 표현을 활용하면서 정보의 패턴을 유지할 수 있다고 말합니다. 이에 따른 저자의 contribution은 다음과 같습니다.
- Video Temporal Grounding을 위한 새로운 프레임워크 R2-Tuning을 제안합니다.
- query-modulated spatial pooling과 recurrent temporal refinement의 두가지 효과적인 전략을 구상했습니다.
- CLIP의 visual, text encoder의 granularities를 calibrate(정렬)하기 위해 video-level와 layer-wise contrastive constraints(제약)를 소개해 각 layer의 distinct 정보를 distill합니다.
- 여러 데이터셋에서의 벤치마크를 통해 R2-Tuning의 효율성과 강력함을 증명합니다.
Method
R2-Tuning이 다루는 VTG는 크게 3가지 task들을 얘기하는 것으로 각 task에 대해 먼저 간략하게 설명하고 방법론을 설명하겠습니다.
Moment Retrieval은 쿼리 Q=\{q_i\}^L_{i=1}에 해당하는 relevant moments를 비디오 V=\{v_i\}^T_{i=1}에서 찾는 task로 boundary timestamp b_i=[b^s_i,b^e_i] \in \mathbb{R}^2를 반환하는 것을 목표로 하는 task입니다.
Highlight Detection은 V와 Q 사이의 frame-level relevancies를 구하는 task로 모든 frame v_i의 유사성 점수 s_i \in [0,1]를 구하는 것을 목표로 하는 task입니다.
Video Summarization은 Q에 해당하는 V의 subset을 구하는 task로 모든 frame v_i이 Q와 연관 있는지 없는지 이진분류하는 f_i \in \{0,1\}를 구하는 것을 목표로 하는 task입니다.
R2-Tuning은 위 3개의 task를 모두 다루는 VTG task로 V와 Q를 입렵으로 받아 (b_i, s_i, f_i)를 반환하는 task입니다.
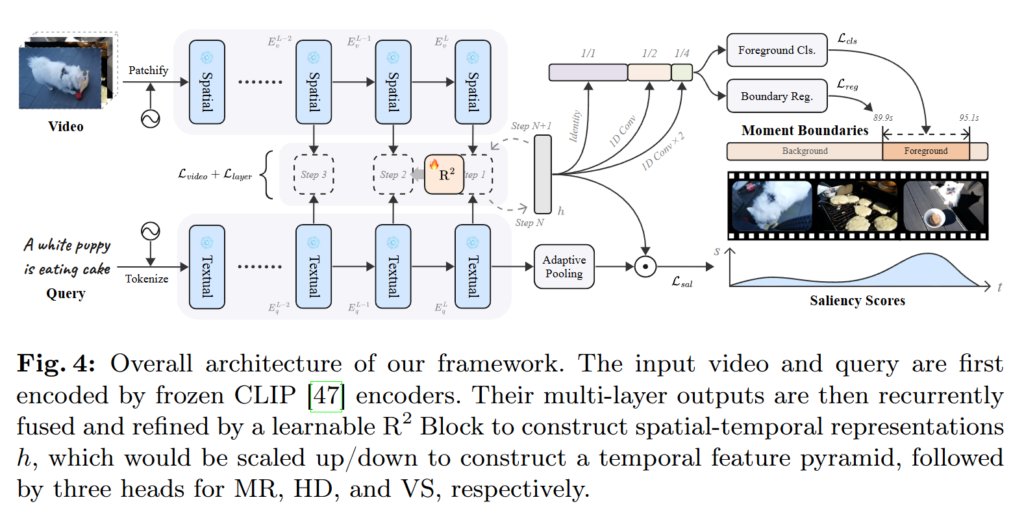
Figure. 4는 R2-Tuning의 Framework입니다. 저자는 CLIP만을 사용하는 것으로 spatial(공간) 정보와 temporal(시간) 정보를 모두 모델링합니다. 가중치가 고정된 ViT(Vision Transformer)를 backbone으로 사용하고 R2-Block을 사용해 반복적으로 spatial정보와 textual 정보를 융합하고 세분화합니다. 이러한 과정을 거치며 spatia-temporal(시공간적) 특징을 모델링합니다. 이렇게 해서 생성된 특징은 위/아래로 확장되어 feature pyramid를 생성하고 prediction head를 거침으로 MR, HD, VS 세 task를 수행합니다.
인풋으로 들어오는 V와 Q는 각각 비디오 인코더 E_v와 [/latex]E_q[/latex]를 거쳐 visual feature e_v \in \mathbb{R}^{B \times N \times T \times (P+1) \times D_v }와 textual feature e_q \in \mathbb{R}^{B \times N \times T \times D_q}를 추출합니다. B, N, T, P , L, D_v, D_q는 각각 batchsize, num_encoders, num_videos, num_patches, num_queries, visual feaure의 차원과 textual feature의 차원을 의미합니다. e_v와 e_q는 R2-Block을 통해 융합되어 fused feature h \in \mathbb{R}^{B \times T \times C}를 생성합니다. [latex]C는 frame feature의 차원을 의미합니다.
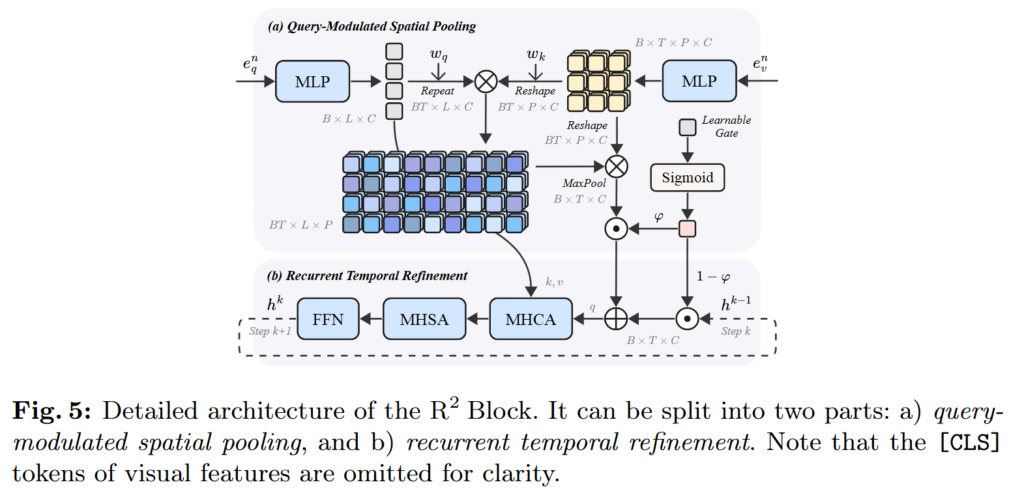
Figure 내에 있는 notation들의 의미를 알았으니 구체적으로 Reversed Recurrent(R2) Block의 구성을 확인해보겠습니다. 저자의 기존의 방법들과 다르게 CLIP 인코더의 final layer의 정보만을 활용하는 것이 아닌 모든 layer의 정보를 활용하겠다는 취지대로 여러 단계를 거쳐 CLIP 인코더의 마지막 K layer에 반복적으로 연결되게되고 이 과정에서 fused feature(hidden state)는 매 step마다 h^k = \mathcal{F}_{\theta}(d^n_v,d^n_q,h^{k-1})로 갱신됩니다. 여기서 \mathcal{F}_{\theta}는 refinement 연산을 의미하고 k \in [1,K]는 현재 step을 의미하고 n = N - k +1로 CLIP의 layer 인덱스를 의미합니다. \mathcal{F}_{\theta}는 query-modulated spatial pooling과 recurrent temporal refinement의 두 파트로 구성되어 있습니다.
Query-Modulated Spatial Pooling
Figure 5 (a)에 해당하는 이 모듈은 패치 수준의 visual feature e^n_v를 query featuree^n_q와 상호작용하는 것으로 단일 토큰 e^n_{pool}로 조정하는 과정으로 각 프레임에서의 시각 정보를 쿼리에 맞게 갱신됩니다. visual feature와 query feature를 같은 임베딩 공간에 매핑하기 위해 MLP연산을 통해 매핑시킨 후에 패치-토큰 쌍의 유사도 a를 구합니다.
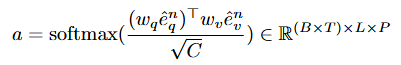
w_v, w_q는 각각 feature를 투영하기 위한 학습 가능한 행렬입니다. 유사도 a는 이후 visual feature e^n_v와 곱해져 패치와 상호작용할 수 있도록 한 후에 Max Pooling 연산과 residual 연산을 통해 통합된 특징을 생성합니다.
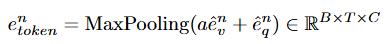
최종적으로 query-modulated spatial feature는 다음의 연산을 거쳐 생성됩니다.
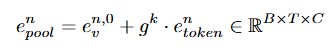
g^k \in (-1,1)는 0으로 시작해 k 단계에 대해 학습 가능한 gate로 Tanh 연산을 통해 -1 ~ 1 사이의 수로 결정됩니다. 최종적으로 생성되는 e^n_{pool}은 model temporal correlation을 위해 사용되고 recurrent(재귀)적으로 refine됩니다.
Recurrent Temporal Refinement
이 과정에서는 이전 단계의 fuse feature(hidden state) \hat{h}^{k-1}와 위의 query-modulated spatial pooling을 통해 생성된 feature e^n_{pool}를 결합하여 새로운 fused feature(hidden state)를 생성합니다.
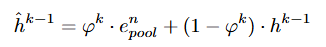
\varphi^k는 step K의 학습 가능한 gate를 의미합니다. 이후 Multi-Head Cross Attention (MHCA) 연산과 Feed Forwad Nework(FFN)을 통해 fused feature (hidden state)를 갱신합니다.
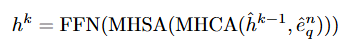
추가적인 디테일로 모든 블록은 DropPath 연산을 추가하여 과적합을 방지한다고 합니다. DropPath는 DropOut과 비슷한 연산으로 블록단위로 행해지는 DropOut 연산이라고 생각해주시면 될 것 같습니다. 위의 여러번의 재귀 연산(R2 Block 연산)을 통해 R2-Tuning은 시공간 특징을 학습할 수 있습니다.
Granularity Calibration
CLIP 모델에서 visual, textual feature가 같은 layer에 있는 경우, 이 feature들이 잘 정렬되었을 것이라 가정하지만, 저자는 사전 학습 중에 두 feature들이 서로 독립적으로 학습되었기 때문에 최종 결과는 잘 정렬되었을지 모르지만, 각각의 layer에서의 정렬이 잘 되었을 것이라고 보장할 수 없다고 말합니다(실제로 ablation study에서 granularity calibration 모듈의 유무로 인한 성능차이가 있어 어느정도 신빙성이 있는 주장이라고 생각됩니다). 따라서 수동적으로 각 layer들의 정밀도를 보정하는 모듈이 필요하다고 주장하고 있습니다. 저자는 이를 위해 visual feature는 Average Pooling을, textual feature는 token-wise adaptive pooling 연산을 통해 특징을 추출한 후에 저자는 같은 배치 내에서 샘플간의 대조를 InfoNCE loss를 통해 수행합니다.
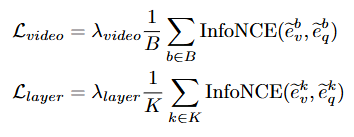
InfoNCE loss는 우리가 일반적으로 알고 있는 contrastive loss에서 많이 사용되는 loss로 코사인 유사도를 통해 양성 샘플 사이의 코사인 유사도를 증가시키고, 음성 샘플 간의 코사인 유사도를 낮추도록 학습을 유도하는 함수입니다.
Prediction Head
마지막으로 각 task 수행을 위한 prediction head입니다.
MR 수행을 위한 Boundary Regression은 L1 loss가 사용됩니다. 1D convolution 연산을 통해 start timestamp와 end timestamp를 예측하고 예측 timestamp와 GT timestamp와의 L1 loss를 통해 boundary를 예측해 쿼리에 해당하는 구간을 반환합니다.
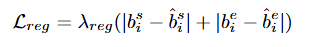
HD 수행을 위한 Saliency Prediction은 코사인 유사도를 통해 계산됩니다. 마지막 R2 Block을 통해 추출된 adaptive pooled textual(쿼리) feature e^{~K}_q와 각 토큰의 spatial-temporal(시공간) feature h와의 코사인 유사도 \hat{s}_i를 구한 후에 contrastive loss를 통해 학습합니다.
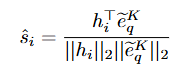
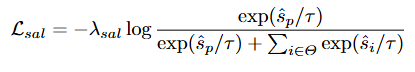
VS 수행을 위한 Foreground-Background Classification은 1D convolution 연상을 거친 후에 focal loss를 통해 학습합니다.
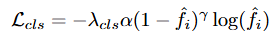
Experiments
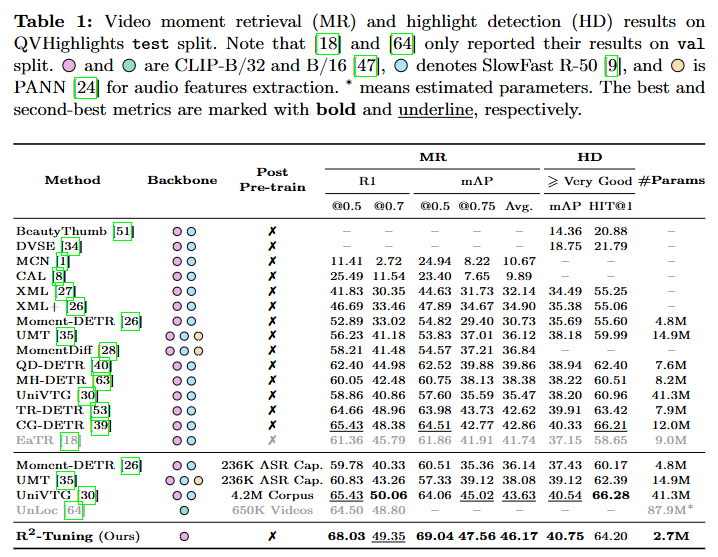
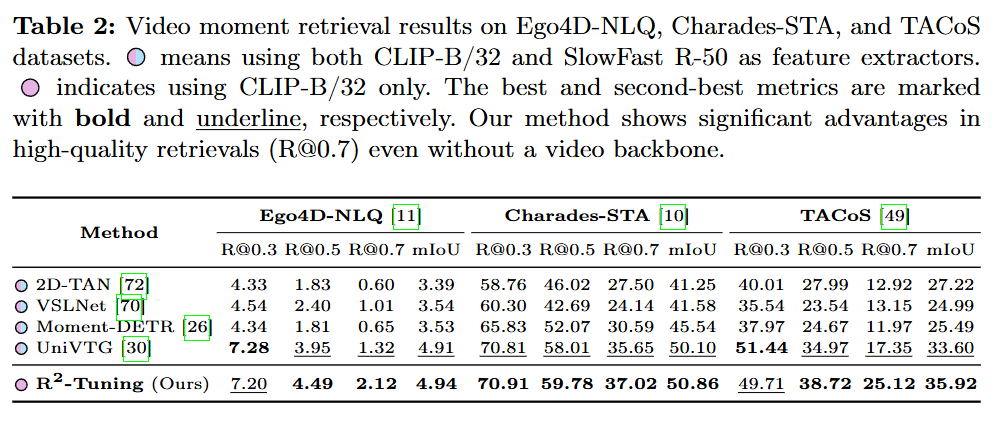
위 Table 1, 2는 MR의 성능을 보여줍니다. R2-Tuning은 다른 기존의 방법론들과는 다르게 backbone을 CLIP만을 사용하면서도 SOTA 성능을 달성하여 R2 Block을 사용하여 temporal 모델링하는 방법이 SlowFast와 같은 temporal 정보를 담고 있는 backbone을 사용하여 모델링하는 것보다 더욱 효과적임을 보여주고 있습니다. 특히 Moment DETR 기반의 MR과 HD를 수행하고 VS를 수행하지 않는 방법론들과 다르게 VTG 즉, MR, HD, VS 3개의 task를 수행함에도 좋은 성능을 보여준다는 것이 인상적입니다.
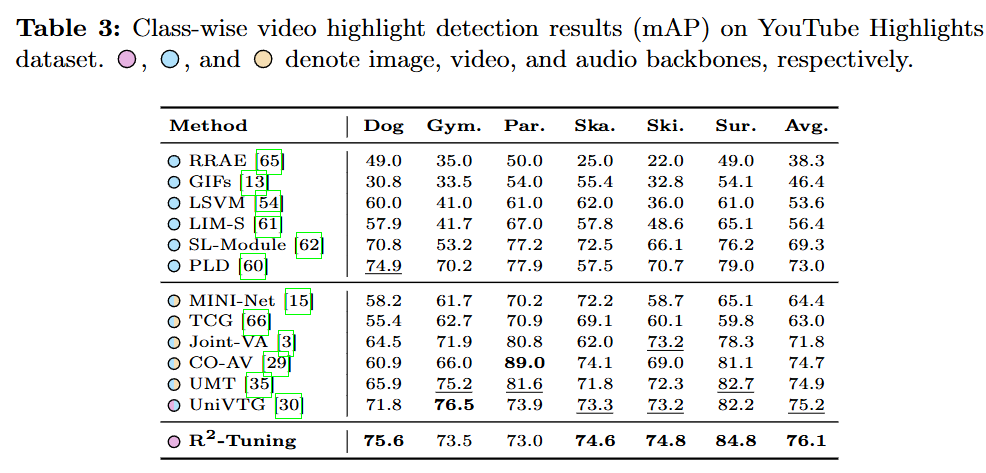
Table 3는 HD의 성능으로 모든 클래스에서 SOTA를 달성한 것은 아니지만 Avg. 성능이 제일 높고 MR와 마찬가지로 다른 모델들은 video backbone을 사용하고 있지만, R2-Tuning은 image backbone(CLIP)을 사용함에도 성능이 제일 높아 temporal정보를 담고 있지 않은 CLIP 백본으로도 충분히 temporal 정보를 잘 모델링해 비디오 downstream task들에서의 가능성을 시사하고 있는 것 같습니다.
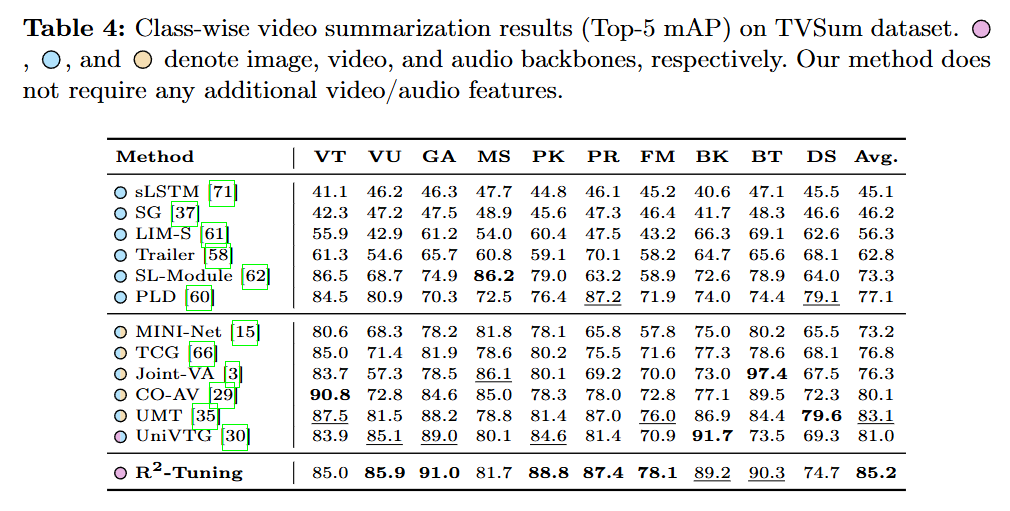
마지막으로 VS 성능입니다. 계속 같은 말은 반복하는 것 같지만, image backbone(CLIP)만을 사용하면서도 temporal 정보를 담고 있는 video backbone을 활용하는 다른 방법론들보다 좋은 성능을 보이는 것이 신기하네요. 저자가 제안하는 Reversed Recurrent 방법이 확실히 temporal 정보를 잘 모델링하고 있음을 실험을 통해 보여주고 있는 것 같습니다.
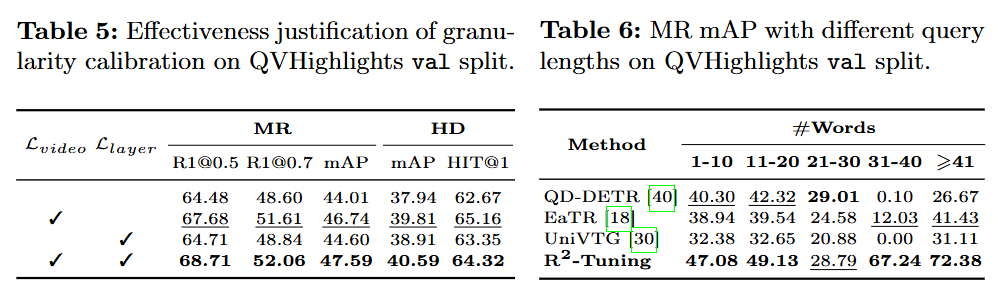
Ablation Study는 granularity calibration 모듈 앞서 method 설명할 때 CLIP의 image와 text가 서로 독립적으로 학습되기 때문에 최종 layer가 아닌 사이사이의 layer들이 모두 잘 정렬되었다고 장담할 수 없다고 저자가 주장했었는데 ablation study에서 각 layer에서의 granularity calibration을 통해 모든 layer들을 align시키는 것이 확실히 유의미한 성능차이를 보이는 것을 Table 3를 통해 확인할 수 있습니다.
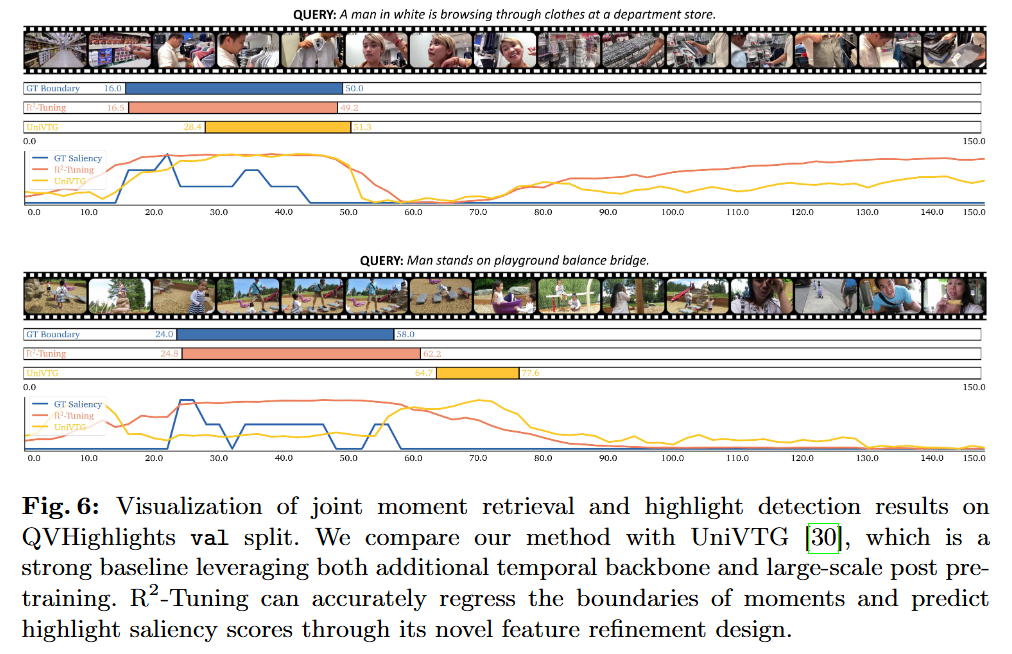
정성적으로 보여주는 R2-Tuning의 결과입니다. 비교군인 UniVTG는 2023년도에 공개된 논문으로 VTG (MR, HD, VS)를 다룬 이전 SOTA 모델입니다. 당연히(?) 체리피킹해서 가져온 정성적 결과이긴하겠지만, R2-Tuning이 VTG를 잘 수행하고 있다는 것을 한번 더 강조하는 Figure입니다.
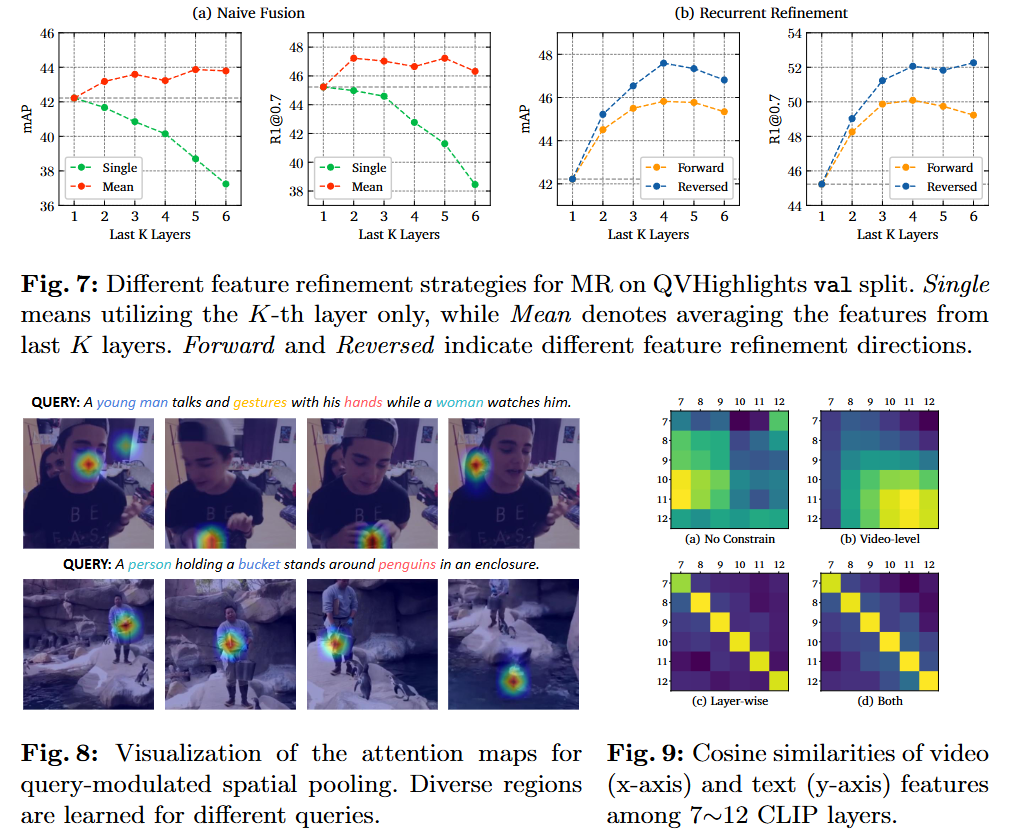
마지막으로 일반적인 fusion과 reversed recurrent 방식의 차이를 보여주는 그래프와 attention, 코사인 유사도를 시각화한 Figure를 보여주며 저자가 제안하는 각각의 모듈들이 실제로 효과가 있다는 것을 보여주고 있습니다.
image-text Pretraining에서 더 나아가 최근 video-text Pretraining 연구(InternVideo 등)가 많이 진행되면서 image backbone을 video backbone으로 교체하는 연구, 기존 backbone의 한계점을 지적하는 연구들이 많이 나오고 있습니다. R2-Tuning은 오히려 video backbone을 사용하지 않고 image backbone만을 사용면서도 다른 video backbone을 활용한 연구들보다 메모리, 성능면에서 좋은 모습을 보여주고 있는데 어찌보면 다른사람들과 다른 방향으로 연구를 해서 성과를 냈다는 점이 굉장히 인상적이고 신기하네요.
오늘 리뷰는 여기서 마치도록 하겠습니다. 감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
확실히 feature 추출에 사용되는 백본을 줄인다는 점부터 확실히 유의미한 연구인 것 같습니다.
Granularity calibration loss의 목적이 CLIP의 두 백본 layer 간 granularity를 조정하기 위한 것으로 이해했는데, video loss는 어떤 역할을 하는 것인가요? 정확히는 e_{v}^{b}, e_{q}^{b}가 어떻게 정의되는 것인지 궁금합니다.
또한 표 6에서 단어의 개수가 21-30인 경우 갑자기 성능이 크게 떨어지는 것이 잘 납득이 안되는데, 이에 대한 저자의 분석이 있나요? 처음보는 현상이라 궁금합니다.