안녕하세요. 오늘 review할 논문은 ICCV 2023에 게재된 SurroundOcc: Multi-camera 3D Occupancy Prediction for Autonomous Driving입니다. 리뷰를 시작하기 전에 본 논문이 하고자 하는 것을 간단히 소개드리자면, single 혹은 multi-camera images(2차원)로 부터 3차원 scene을 reconstruction하는 것 입니다. 그런데 3차원 scene을 reconstruction한다는 것은 주로 3차원 공간에 존재하는 모든 점을 복원함과 동시에 그 클래스까지 예측을 하는 3D segmentation을 주로 생각하실 수 있습니다. 그러나 자율주행 관점에서 3D segmentation이 풀고자하는 3차원 공간의 복원과 클래스 예측이라는 테스크가 매우 어렵고, 단순히 차량을 주행하는 관점에서 모든 점들의 클래스는 과한 정보라고 생각할 수 있습니다. 대신 3차원 공간을 특정한 복셀 공간으로 나누어서 해당 공간이 차량이 주행할 수 있는 공간인지 여부만 판단하는 차선책에 대한 연구가 진행되고 있습니다. 여기서 차량이 주행할 수 있는 공간인지 여부를 점유여부(occupancy여부)로 판단하는 것은 단순한 binary classification문제로 클래스예측에 대한 어려움을 해소할 수 있게 됩니다.
(해당 내용에 대해서 우리 연구실 졸업생이신 김형준 연구님 세미나때 간단히 소개된 내용입니다.)
이렇게 특정 3차원 공간의 점유여부를 확인하는 방법은 테슬라의 FSD 시스템에 적용되어 2022년부터 자율주행 분야에서 자주 언급되고 있으나, 테슬라의 방법론은 오픈소스가 아닌 관계로 베일에 싸여 있습니다. 그러나 여전히 그 실용성 때문인지 학계에서도 연구가 활발히 진행되고 있는 모습입니다. 이 논문을 가지고 온 이유는 평소 관심분야 였던 자율주행 상황에서의 환경인식을 위한 솔루션으로 실제로 테슬라라는 큰 기업이 적용한 사례가 있다는 점, 그리고 현재 석사 연구 주제에 대한 탐구 중에 있는 데, 해당 방법론을 석사 기간 동안 파볼만 한 녀석인가? 하는 관심에 찾아서 읽어보게 되었습니다.
그럼 x-review 시작하도록 하겠습니다.

1. introduction
자율주행 관점에서 차량 주변의 3차원 scene에 대한 이해는 필수적인데요. 이를 제공하는 직관적인 솔루션인 Lidar 센서가 존재하긴 합니다만. 이런 라이다 센서의 단점인 비싼 가격과 sparse한 points들을 제공한다는 점이 여러가지 어플리케이션에 적용하는 것에 제한 요소로 지목되고 있습니다.
최근 들어서 이런 라이다의 단점을 보완하거나 대체하고자 “vision-centric autonomous driving”에 대한 연구가 지속되고 있는데요. 그 예시로는 multi-camera images를 인풋으로 받아서 3D Detection, depth estimation, semantic map construction을 하는 것들이 대표적인 예시가 될 것입니다. (다들 이미지의 한계인 2차원을 벗어나 3차원 정보를 생성하려는 노력을 하고 있습니다.)
그러나 가장 보편적으로 쓰이는 3D detection은 data imbalance가 야기하는 long-tail problem과 real world에서 등장하는 학습 상황에서 제공 받지 못한 클래스에 대한 예측이 불가능하다는 단점이 있습니다. 이러한 문제점으로부터 저자는 오히려 surrounding 3D scene을 reconstruction하는 것이 더 나은 방법이라고 주장합니다.
그러면 3D scene reconstruction방법으로 맨 처음 생각나는 방법이 현재도 많이 사용되고 있는 2D surrounding scene에 대해서 depth를 예측하여 3D 공간으로 뿌려주는 방법이 있을텐데요. 그러나, 이러한 방법은 depth map을 형성하는 과정에서 문제가 나타납니다. 바로 3차원 공간 상의 물체로부터 카메라 렌즈로 ray를 쏠 때, 렌즈와 가장 가까운 물체에 대한 depth만을 depth map으로 표현한다는 것 입니다. 즉 동일한 ray상의 앞 물체에 가려진 물체(occlusion)에 대한 depth는 예측하지 않는다는 것입니다.
이런 부분이 depth map을 활용하여 만든 3D scene에서 occluded 되어있는 부분에 대한 reconstruction를 할 수 없게 만듭니다. 이러한 depth를 거쳐서 3차원 공간을 reconstruction하는 방법과는 다르게 또 다른 트렌드로 떠오르는 것이 3차원 공간의 점유여부(3D occupancy)를 바로 예측하는 방법입니다.
이 방법은 모델로 하여금 3차원 복셀의 각 그리드 셀에 대해서 점유여부를 확률적으로 예측하도록 하는 것입니다. 이런 방식의 좋은 점이 multi-camera geometry consistency를 자연스럽게 지키고, 가려진 부분에 대한 recovery를 할 수 있다는 것입니다. 또한 각 class에 대한 head만 추가하면 더 고차원적인 3D semantic segmentation을 수행할 수 있다는 점처럼 다른 3D downstream task에 적용하기에 용의하다는 것입니다.
기존의 이러한 단안 이미지에서 3차원의 복셀화된 의미론적 scene(3D voxelized semantic scene)을 구축하려는 선행연구와 TPVFormer라는 Lidar points를 정답으로 supervision을 제공하는 방법론이 존재하였는데요. 그들은 모두 sparse한 3D occupancy를 예측할 수 밖에 없었다고 합니다.
이러한 선행 연구들의 문제점을 해결하고자 저자는 SurroundOcc를 제안하였습니다.
저자들이 주장하는 contribution은 아래와 같습니다.
(1) SurroundOcc라는 새로운 3D dense occupancy 예측을 위한 아키텍쳐를 고완하였다.
(2) sparse한 lidar points로 부터 dense한 정답 Scene을 생성하기 위한 파이프라인을 개발하였다.
(3) nuScene dataset 에서 SoTA달성
2. Approach
2.1. Problem Formulation
(Introduction 이전에 첨부한 그림 중 Figure 1을 참고해주시면 이해하시는 데 도움이 됩니다!)
테스크 자체는 간단합니다. 딥러닝 모델이 Ego vehicle기준으로 360 전방향에 대한 surrounding multi-cameras images를 받아서, 차량 기준 전방향의 3차원 surrounding 3D voxel에 대한 점유 확률(occupancy probability)을 예측하는 것 입니다. 수식으로는 아래 (1)과 같이 표현됩니다.
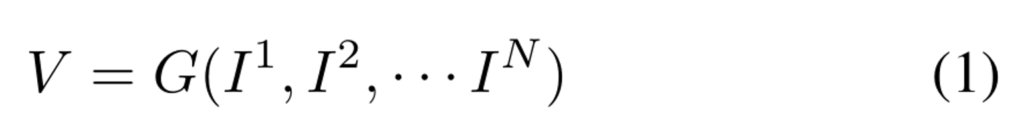
여기서 I^{1},I^{2},...,I^{N}는 N개의 카메라로부터 얻은 360도 이미지를 의미합니다.
G는 Neural network모델에 해당합니다. 그리고 출력에 해당하는 V\in\mathbb{R}^{H\times{W}\times{Z}}는 3D occupancy가 voxel형태로 나오게 됩니다. V의 값은 0~1사이의 확률이 grid마다 할당됩니다. (만약 여기서 V를 semantic한 정보를 예측하게 만들고 싶다면 class의 수에 해당하는 L을 추가하여 (L,H,W,Z)차원에 대한 출력이 나오도록 하게 하면 된다고 하네요)
이렇게 예측한 3D occupancy는 multi-camera 3D scene reconstruction을 위한 좋은 representation을 제공합니다. 저자가 언급한 3D occupancy의 장점은 3가지가 있는데요.
첫 번째로, 3D occupancy는 3D space에 대해서 예측을 합니다. 이는 자연스럽게 geometry multi-camera consistency를 만족하게 합니다. (2D 이미지로 부터 3D space를 reconstuction하기 위해 필요한 조건 일정한 내,외부 파라미터, 에피폴라제약 등)
두번째로 모델이 occlusion이 일어난 곳의 주변에 존재하는 의미론적 정보들을 활용하여 가려진 부분에 대한 예측을 진행해서 scene을 reconstruction합니다.
마지막으로는 3D occupancy가 3D semantic segmentation, scene flow estimation등의 downstream task로 확장하기 쉽다고 합니다.
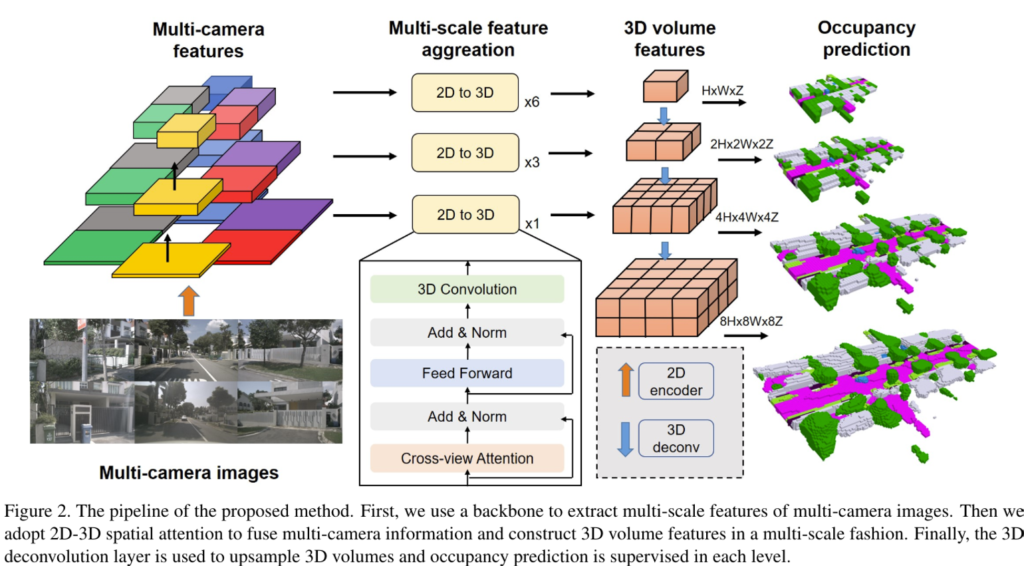
위에 figure 2.가 3D occupancy를 예측하는 전체적인 파이프라인을 보여줍니다.
먼저, multi-camera images를 인풋으로 받아서 각 카메라 프레임 마다 ResNet-101같은 backbone에 태워서 2D multi-scale 특징 맵들을 뽑게됩니다.
그림을 보면 각 색상 별로 서로 다른 카메라에 대한 이미지들이 2D encoder(backbone)에 의해 multi-scale 특징 맵으로 뽑힌 것을 알 수 있습니다.
그 다음에 scale-level에 대해서 multi-camera 특징맵들을 퓨전하기 위해서 트렌스포머를 활용하여 spatial cross attention 계산해줍니다. spatial attention layer의 결과는 3D volume features로 나오게 되는 데요. 이후 계산된 scale 별 3D volume features를 3D conv 연산을 태워서 multi-camera 3D volume features를 조합하는데 사용합니다.
이렇게 예측된 각 스케일 별 occupancy prediction은 dense occupancy ground truth를 통해서 loss연산을 수행하여 supervision을 얻게 됩니다.
3.3. 2D-3D Spatial Attention
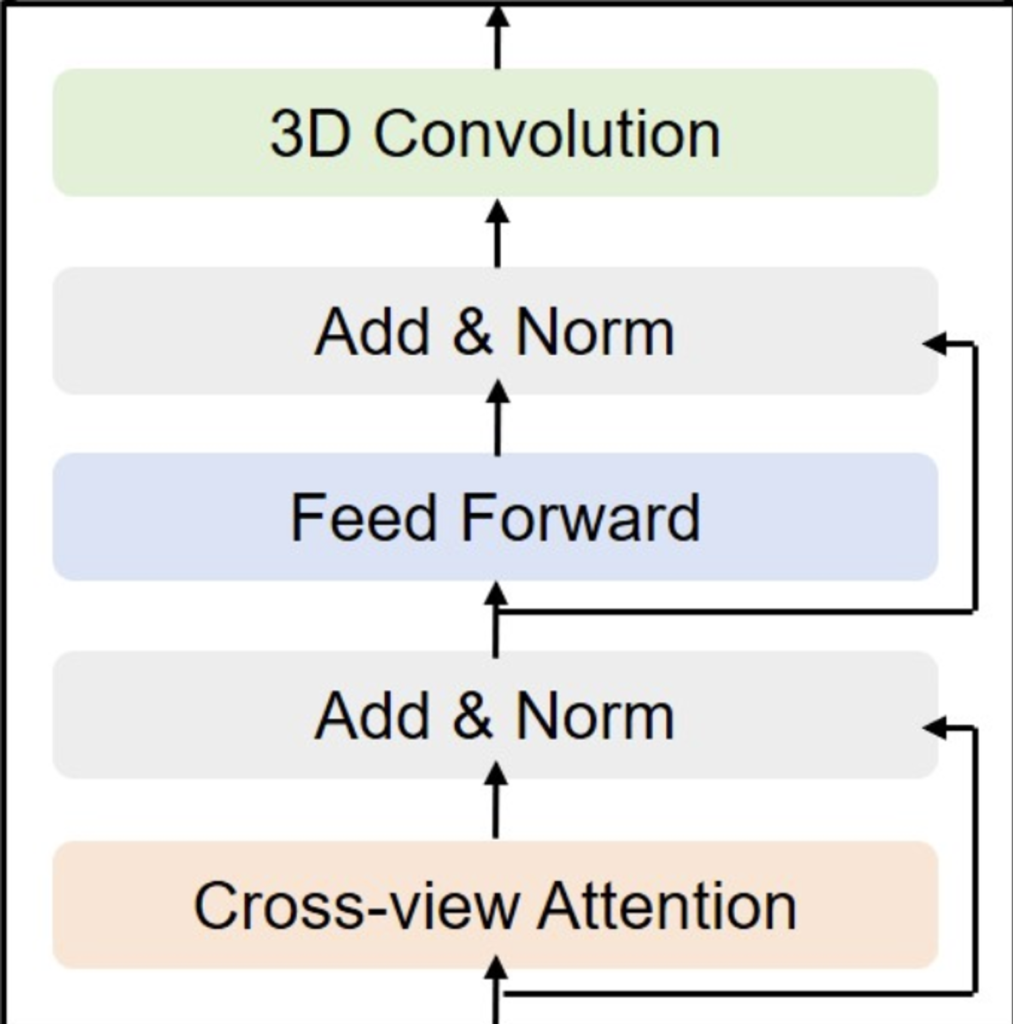
전체 파이프라인의 각 모듈에 대해서 조금 더 자세히 살펴보도록 하겠습니다.
먼저 앞서 언급했 듯, multi-camera 이미지들에 2D encoder를 태워서 multi-scale 2차원 특징맵을 뽑아 줍니다. 이후 2D-3D 모듈의 인풋으로 넣어줍니다.
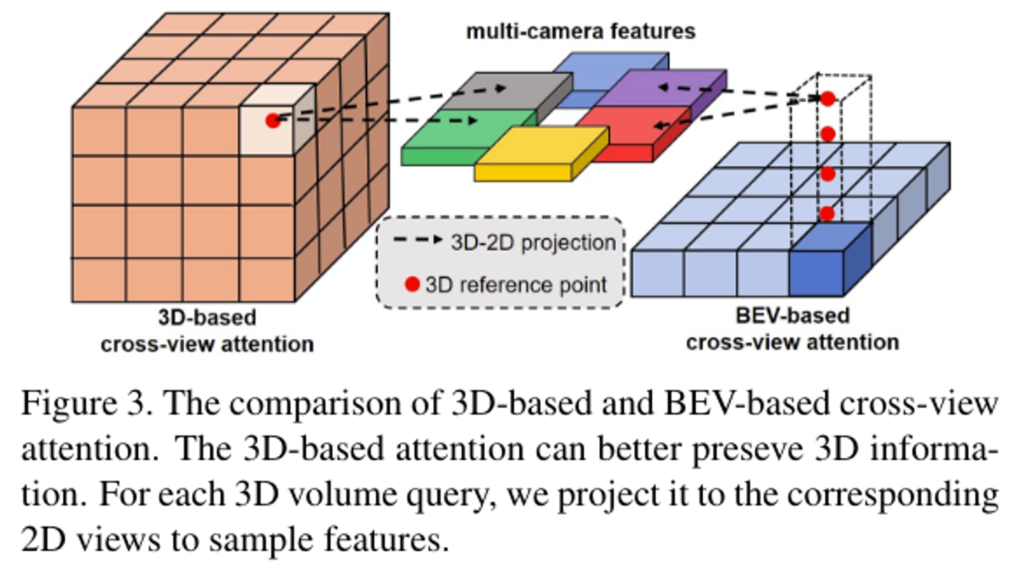
3D-2D 모듈은 2D multi-camera features 사이의 정보를 합쳐서 3차원 복셀공간의 특징으로 바꿔주는 역할을 합니다. 간단히 정리하자면(Figure 3의 3D-based cross-view attention을 참고해주세요.),
3차원 복셀공간의 각 grid의 centroid점(reference point)들을 2D views로 projection시킨 뒤에 deformabale attention을 적용하여 해당 grid의 특징을 뽑아내는 과정입니다.
차근 차근 알아보겠습니다. 먼저 Figure 3은 기존의 방법론들이 사용한 3D 복셀공간에 대한 쿼리가 아닌 2D BEV공간에 대한 grid를 쿼리로 사용하는 것의 비교에 대한 이미지 입니다. 본 논문에서는 Figure 3의 왼쪽에 해당하는 3D-based 방법론에 대한 그림만 참고해주시면 될 것 같습니다.
첫 번째, 3차원 공간에 대한 즉각적인 예측과 공간 정보를 최대한 유지해주기 위해서 3차원 볼륨 쿼리(Q)를 만듭니다.
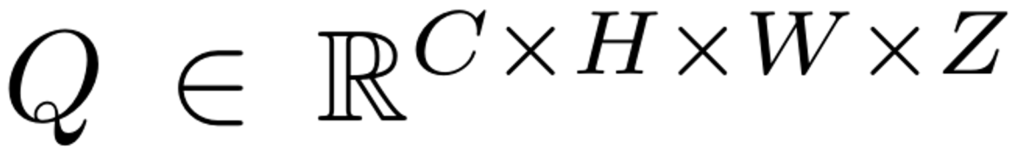
주어진 내부, 외부파라미터를 사용하여 3차원 복셀 쿼리와 일치되는 3차원 복셀상의 점(reference point)을 2D scene들로 projection시킵니다. 이로서 360도 scene에 대한 2차원 특징맵으로 부터 특정 3차원 복셀에 대한 특징을 뽑을 때, 투영점이 나타나지 않는 이미지를 배제합니다
그리고, 3D reference point가 projection되어서 상이 생긴 scene에 대해서만 2D features를 샘플링하게 되는데요. 이때 상이 생긴 위치의 주변의 특징들만 샘플링해서 사용한다고 합니다. 코드를 까보지 않아서 어느 정도 범위를 계산 영역에 포함시키는 지는 알 수 없으나, 연산량을 줄이기 위한 노력으로 예상됩니다.
이렇게 샘플링된 2D features들을 C차원으로 projection시켜서 key, value를 생성합니다. 쿼리와 키 사이의 deformable attention 매커니즘을 따라서 뽑은 weight를 적용한 value의 합을 이용해서 3차원 복셀공간의 특징(F)을 얻습니다.
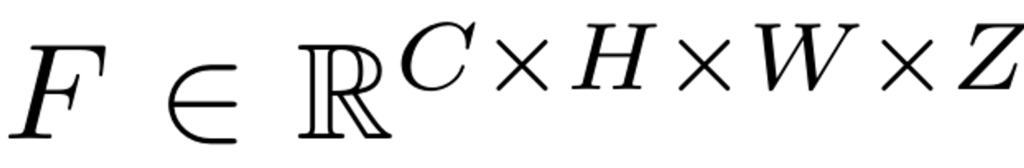
위 과정을 수식으로 나타내면 아래와 같습니다.

F^{p}, Q^{p}는 각각 3차원 출력 특징의 p번째 요소, p번째 3차원 볼륨쿼리를 의미합니다.
q^{p}는 p번째 볼륨쿼리의 3차원 공간상의 위치를 의미합니다.
\mathcal{P}는 주어진 내,외부 파라미터를 이용한 3차원에서 2차원으로 projection시키는 함수입니다.
\mathcal{V}_{hit}는 3차원 볼륨쿼리의 위치를 2차원 scenes으로 projection했을 때, 상이 맺힌 scene들의 집합을 의미합니다.
\mathcal{W}{i}, \mathcal{W}{i}^{'}는 learnable weights를 의미합니다.
\mathcal{A}_{ij}는 attention weight로 쿼리와 키의 dot product연산으로 얻은 0~1사이의 값입니다.
x(p+\triangle{p_{ij}})는 p+\triangle{p_{ij}}위치에 있는 2D 특징을 의미합니다.
해당 그림은 Figure 2의 2D to 3D 모듈의 구성을 가지고 온 것인데요. 위에서 설명한 cross-view attention연산을 수행하여 생성된 3차원 복셀 특징들을 퓨전하기 위해서 3D convolution연산을 해줍니다. (3D self-attention의 비싼 연산을 피하고자 해당 방식을 사용했다고 합니다.)
이런 방법으로 동일 스케일에 대해서 특징을 뽑아주고, 이를 멀티스케일 관점으로 확장해서도 진행해주었다고 언급만 하고 있습니다.
Multi-scale Occupancy Prediction
Figure2의 3번째 단계인 굵은 글씨로 “3D volume features”라고 쓰여있는 부분을 참고해주시면 감사하겠습니다.
3D scene reconstruction은 각 위치의 voxel grid에 대한 정확한 예측을 수행하기 위해서 디테일하고 low-level features들이 중요합니다. 이런 관점에서 저자들은 마치 U-Net architecture처럼 다른 수의 2D-3D spatial attention layer를 적용하여 서로 다른 해상도의 multi-scale 3차원 볼륨 특징들을 만들었습니다. 특히 2D-3D spatial attention layer를 한번 통과 시켜 높은 디테일을 갖고 있는 특징을 만들었습니다.
또한 높은 해상도의 특징의 부족한 의미론적 특징을 채워주기 위해서 낮은 스케일(j – 1)의 3D 볼륨 특징을 3D deconvolution layer를 통해서 upsampling 시킨 후에 높은 스케일(j)의 특징과 더해주었습니다.
이를 수식적으로 표현하면, 식(3)과 같습니다.
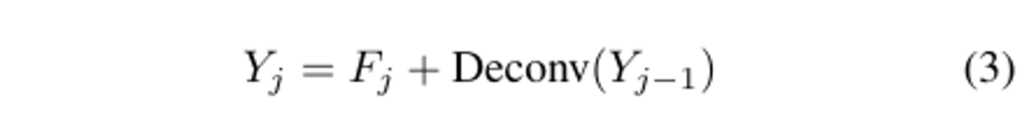
이렇게 각 스케일(j)에 대한 3D occupancy prediction인 F_{j}를 뽑아내게 됩니다.
그리고 모든 스케일에 대해서 강인한 3D occupancy를 예측하기 위해서 각 scale 마다 Loss를 계산해서 supervision을 제공해주었다고 합니다.
loss로는 cross-entropy loss와 scene-class affinity loss라는 것을 사용했다고 합니다. 또한 예측으로서 가장 높은 해상도의 예측이 중요하므로, scale에 대해서 decayed loss weight를 사용하여 높은 해상도에 대한 loss를 가장 크게 반영해주었습니다.
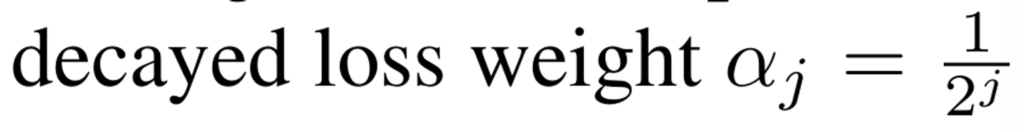
4. Dense Occupancy Ground Truth
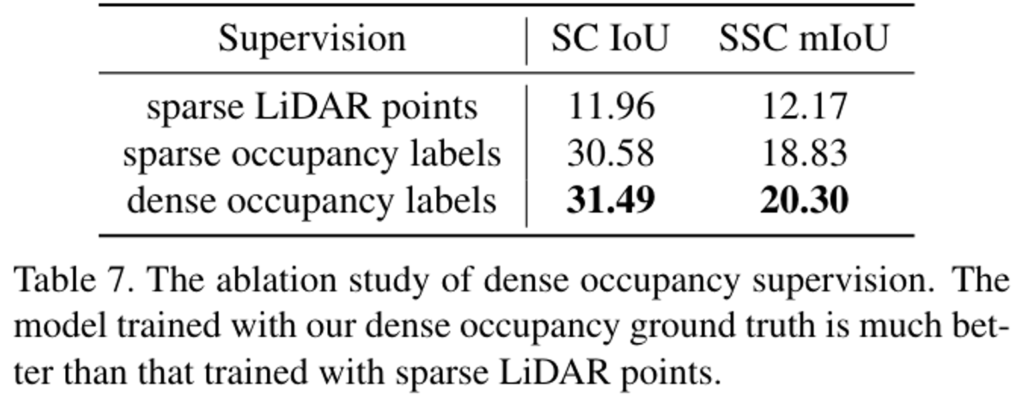
저자들은 sparse한 Lidar points를 정답으로 supervision을 주는 경우에 dense한 3D occupancy를 예측해내지 못하는 것을 실험적으로 발견하였습니다. 따라서 저자들은 dense한 occupancy labels을 생성하기 위한 파이프라인을 개발하였습니다.
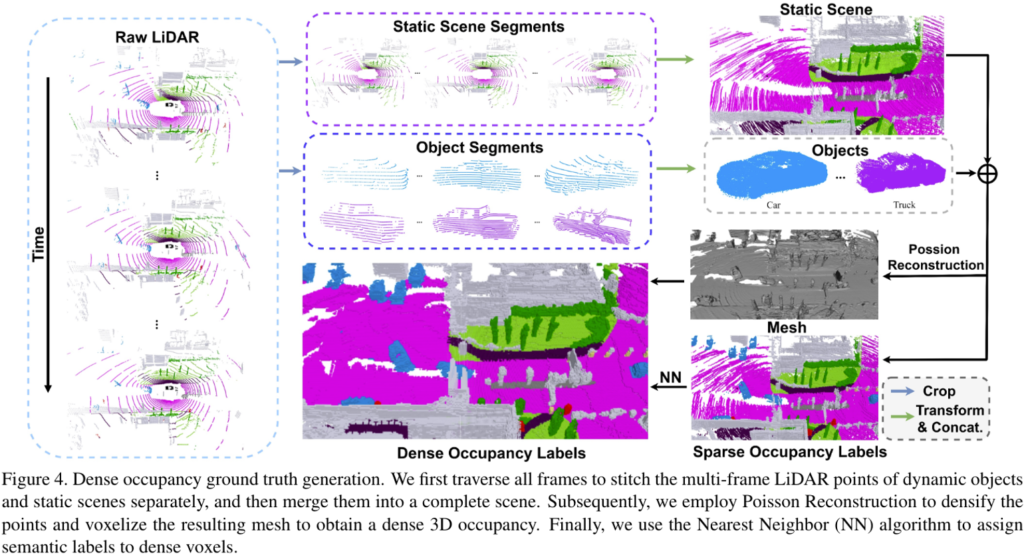
저자들은 직관적으로 여러 프레임의 Lidar pointcloud sequence를 특정 프레임 시점의 coordinate으로 변환하여 축적시켰습니다. 그리고 복셀화를 진행하였습니다. 그러나 이러한 방법은 오직 멈춰져있는 scene에 대해서만 적용이 가능하였고, 움직이는 물체에 대해서는 모델링할 수 없었습니다. 그리고 축적 시킨 라이다 포인트가 부족했는 지 많은 hole들이 발견되었다고 합니다.
이러한 문제점을 완화하고자 static scene과 dynamic object를 각각 모델링하는 방법을 선택했다고 합니다. 그리고 Posson Reconsturction을 사용해서 holes 매우는 방식으로 Lidar point cloud sequence로 부터 dense한 정답을 생성했다고 합니다. 해당 부분은 저자들의 큰 contribution 중에 하나이지만, 제가 관심을 갖고 있는 부분은 아니기 때문에 이 정도로 간단히 언급만 하고 지나가도록 하겠습니다!
5. Experiments
평가로는 multi-camera large-scale autonomous driving dataset인 nuScenes dataset을 활용하였다고 합니다. 그리고 x,y axis 방향으로 [-50m, 50m], z axis방향으로 [-5m, 3m]에 해당하는 반경에 대해서 shape이 200x200x16 이고 grid마다 사이즈가 0.5m인 복셀에 대한 semantic occupancy를 예측하여 평가하였다고 합니다.
semantic occupancy는 단순히 저자의 모델과 존재하는 비교군 occupancy모델에 semantic 카테고리를 예측하는 분류기 헤드를 추가하여 classification도 함께 진행해준 것을 의미합니다. 따라서 실험에 대한 평가도 각 복셀마다 occupancy여부와 class를 같이 고려한 것으로 종합적으로 해주고 있습니다.
또한 해당 방법론의 우수성을 평가하기 위해서 유사한 task인 monocular semantic scene completion에 대한 평가를 추가적으로 진행했다고 합니다. 모든 실험을 8개의 RTX 3090에서 진행하였다고 하네요… 아마 이 주제로 연구하는 것은 힘들지 않을까? 생각해봅니다! 몇 시간 걸렸는지는 안 나와있네요!
성능평가는 아래 식(4)로 진행하였습니다.
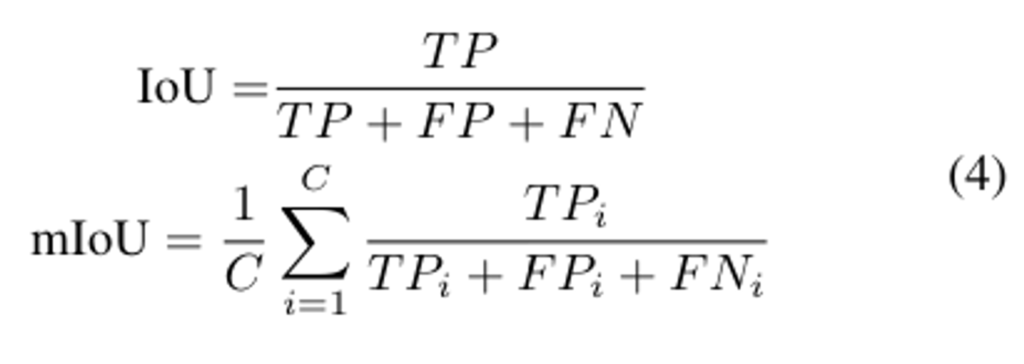
mIoU는 의미론적인 class를 함께 고려하여 평가하기 위해서 사용하였고, IoU로는 class에 대한 영향이 없이 단순히 3D occupancy를 평가하기 위해서 사용하였습니다.
먼저 Table 1은 3D semantic occupancy 예측에 대한 실험 결과입니다. 타 비교군 모델에 비해서 월등히 높은 성능을 보여주고 있습니다.
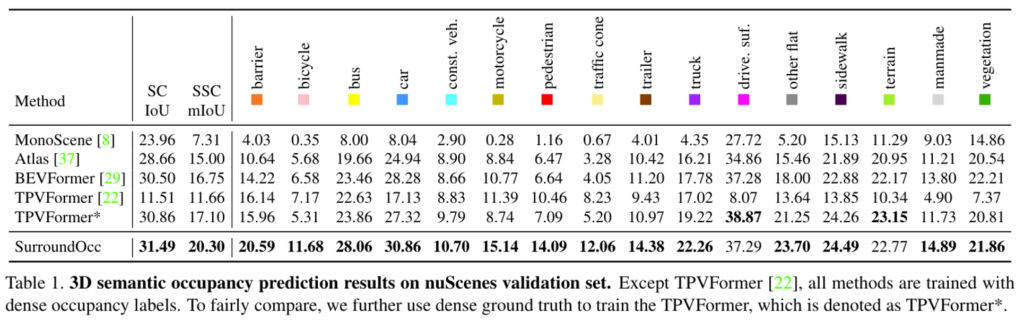
아래 table 3은 추가적으로 시행한 monocular 3D semantic scene completion을 수행한 것에 대한 결과입니다. 저자의 모델이 모든 클레스에 대해서 성능이 가장 우수한 것은 아니지만, 종합적으로 IoU와 mIoU를 보았을 때 가장 좋은 성능을 보여주고 있습니다.
아래의 Figure 6은 정성적인 결과인데요. 본 데이터셋에서 challenging한 상황이라고 평가받는 낮이나, 우천 시에도 곧 잘 동작하는 것을 확인 할 수 있습니다.

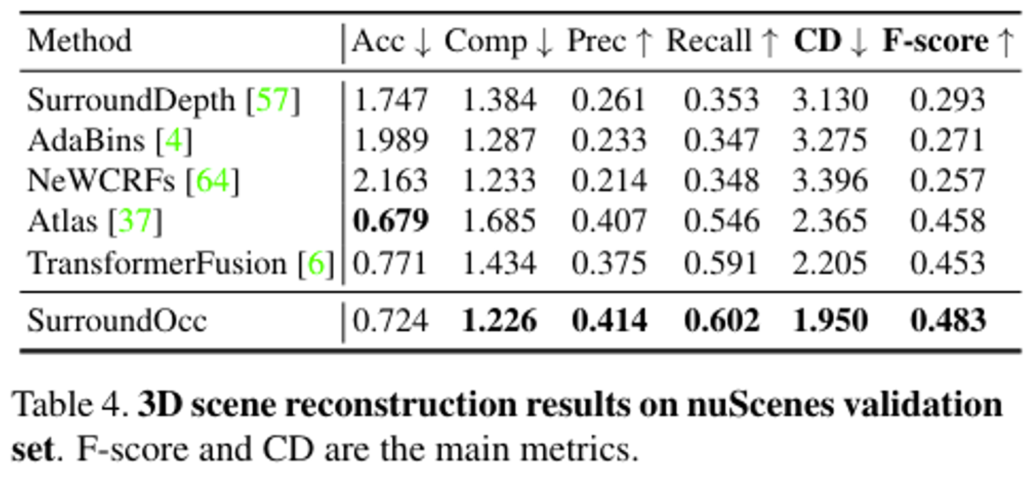
또한 평가를 위해서 3D occupancy예측이라는 task에 semantic label을 추가적으로 예측한다는 점에서 3D scene reconstruction task와 굉장히 유사하기 때문에 해당 테스크의 평가 metric으로도 성능을 뽑아보았다고 합니다. 평가 매트릭은 Table 9와 같습니다.

결과만 확인해보면, 3D scene reconstruction task에서 주요 평가지표로 사용하는 CD, F-score에 대해서 가장 좋은 성능을 보여주며 그 우수성을 증명하고 있습니다.
5.4 Ablation Study
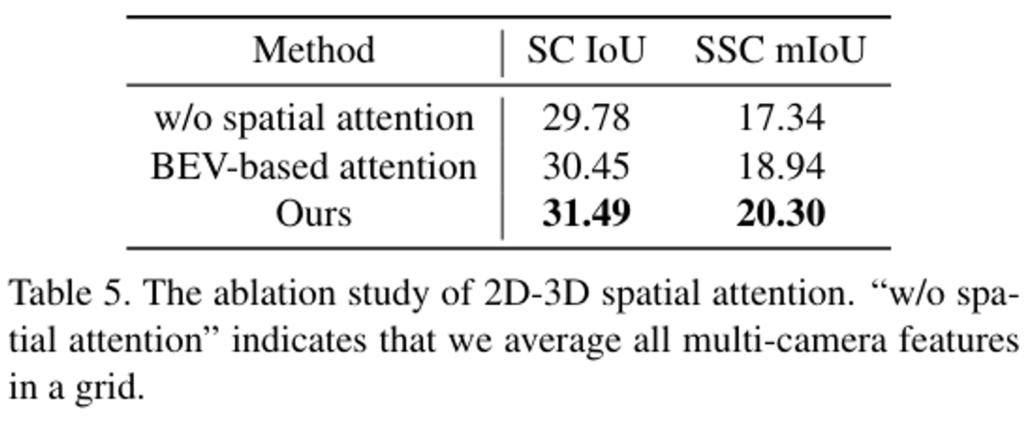
(1) 첫 번째 ablation study로는 2D-3D spatial attention layer의 효용성에 대한 실험인데요. 저자들이 제안하는 3차원 복셀 볼륨 쿼리를 사용하는 것이 가장 좋은 성능을 보이네요.
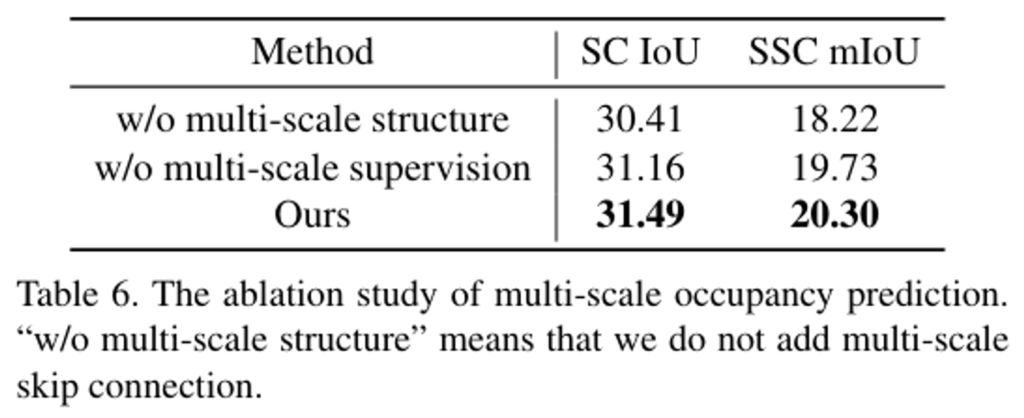
(2) 두 번째 ablation study로는 multi-scale 3D occupancy 예측과 각 스케일마다 supervision을 주는 방법에 대한 효용성을 실험한 것입니다.
(3) 세 번째는 저자들이 제안한 dense 3D occupancy label로 loss를 계산하여 supervision을 주게 되는 경우에 대한 효용성 평가입니다.
5.5. Model Efficiency
해당 실험은 추론 시간과 추론 시 사용되는 메모리에 대한 모델 별 비교인데요. 모두 RTX3090 한 장, 6대의 카메라 이미지를 input으로 받아서 추론한 것에 대한 리포팅입니다.
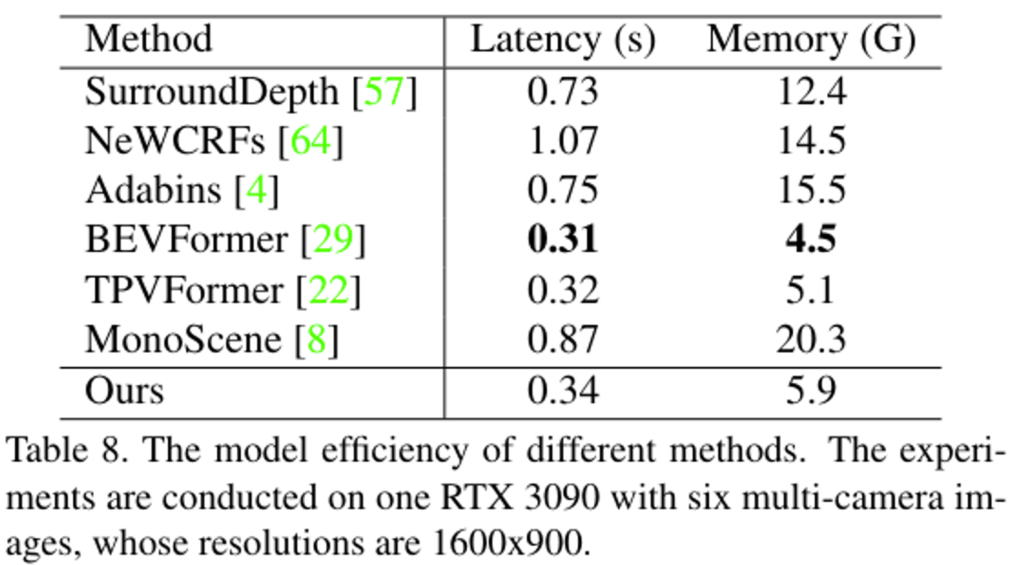
6장의 이미지 인풋을 받아서 RTX3090 한 장을 사용하여 연산했을 때, 추론 FPS가 가장 빠른 모델과 저자의 모델이 3FPS정도 나오는 것을 확인 할 수 있습니다.
감사합니다!
안녕하세요. 리뷰 잘 읽었습니다.
1) Multi-scale Occupancy Prediction에서 해상도란 어떤 의미로 해석해야 하나요? 이전의 소개를 들으면 동일한 Configuration의 카메라를 360도로 배치하는 방식으로 이해했는데, 쓰이는 카메라의 스펙 차이가 존재한다는 가정인가요? 그 해석에 따른 “높은 해상도가 가장 중요하다”는 의미를 어떻게 이해하면 좋을지 궁금합니다.
2) Posson Reconsturction이란 어떤 방법인가요? 적혀진 설명으로는 해당 방법이 결국 Dynamic object에 대해 모델링함과 동시에 Hole을 채우는 주된 접근법으로 생각되는데, 이에 대한 설명이 비어있어 질문드립니다.
3) 보통의 실험이 8개의 RTX 3090에서 진행되었다해도, 2대 혹은 4대의 GPU로 연구도 가능합니다. Linear formula scaling (정확한 명칭이 생각나지 않네요)에 따라 Max iteration (Epoch), Learning rate, warm up 등을 조절하면 학습/평가가 가능할 수 있습니다만, 현재 우려되는 바가 360도 영상을 모두 활용하므로 그 수준이나 학습 시간 등에 주된 관심이 있어야할 것으로 보입니다. 사실 현재 리뷰를 읽었을 때 실험 분야에 대한 리뷰가 조금 부족하네요. 실험 파트에 대해서 저자의 고찰 등을 읽어보심이 중요합니다. 지금처럼 이 표는 이렇다, 저 표는 저렇다는 단순한 보여주기 만으로는 해당 태스크의 실험 파트에서 어떤 면을 우리가 보아야하고, 그 실험이 왜 진행되었는지에 대한 분석을 알기 어려워 그 부분을 추후 리뷰에선 보충해주시길 바랍니다~
안녕하세요. 상인님, 리뷰 읽어주셔서 감사합니다.
(1) 음. 제가 전달 드리고자 했던 Multi-scale Occupancy Prediction의 의미를 설명 드리자면, Figure 2에서 서로 색상이 다른 Multi-camera feature를 SSD처럼 여러 스케일에 대해서 뽑고, 그 이후 각 동일한 scale level에 대해서 2D to 3D 과정을 거쳐서 3D volume features를 뽑아줍니다. 이때 2D to 3D과정에서 3D conv를 태우기 때문에 2D to 3D layer를 더 많이 통과한 high scale level에 대한 feature들은 더 작은 HxWxZ의 볼륨 feature로 reconstuction됩니다. 리뷰에서 언급한 “해상도”는 3D volume features의 HxWxZ를 의미합니다! “높은 해상도가 가장 중요하다”라는 의미는 dense하게 scene을 reconstruction 해야 한다는 관점에서 local detail이 덜 소실된 low scale level에서 reconstruction한 3D volume features로 예측한 Occupancy prediction이 중요하고, 해당 예측에 대해서 가장 큰 supervision을 주어 모델을 학습해야 한다는 의미입니다!
(2) 앞서 인접 라이다 프레임으로 누적 시킨 프레임에서 hole에 대한 부분을 채우기 위한 접근법으로 적용이 된 알고리즘입니다. 해당 방법론의 full name은 “Poisson Surface Reconstruction”로, 논문에서는 자세한 설명없이 그냥 reference만 걸어두었습니다.
Michael Kazhdan, Matthew Bolitho, and Hugues Hoppe. Poisson surface reconstruction. In Proceedings of the fourth Eurographics symposium on Geometry processing, volume 7, 2006. 2, 5
그래서 완전한 이해는 하지 못한 상태이나(해당 논문을 찾아서 보았는데 굉장히 수학적으로 어렵습니다..ㅠ), 컨셉만 설명드리자면 샘플 밀도를 기반으로 샘플의 기여도를 조정하여 잡음이 많은 영역에서는 더 부드럽게, 비어있는 영역에서는 정밀하게 reconstruction을 하는 방법입니다. 논문에서 hole을 제거하기 위한 작동방식은 다음과 같습니다. local neighborhood points로 부터 surface normal vector들을 구하고, Possion surface reconstruction 알고리즘에 normal vector와 pointcloud를 넣어서 triangular mesh를 뽑아냅니다. 이 triangular mesh가 hole을 균등한 분포 reconstruction한 녀석이고, 이를 이전에 hole이 존재하는 프레임과 concat해서 dense한 프레임을 만들어줍니다.
(3) 넵! 실험 부분에 대한 저자의 고찰 및 분석 부분을 더 자세히 읽어보고, 추후 리뷰에는 추가하도록 하겠습니다!
감사합니다.
안녕하세요 현석님, 좋은 리뷰 감사합니다.
질문사항 몇 가지 드리면,
1. N개의 카메라로 360 이미지를 얻는다고 하셨는데, 이미지를 받는 카메라의 배치에 따라서도 정보의 차이가 생길 수 있을 것 같고, 또 그런 N개라는 인풋용 이미지 개수에 따라서도
성능이라던지 연산량이라던지 등에서 차이가 있을 것 같은데, 그것들에 대한 ablation study는 없나요? 추가로 카메라의 배치는 카메라가 6대 사용되었다면, 360/6 으로 60도씩 일정하게 배치되었단 뜻인가요?
2. 3D-2D 모듈 에서 “3D reference point가 projection되어서 상이 생긴 scene에 대해서만 2D features를 샘플링하게 되는데요. 이때 상이 생긴 위치의 주변의 특징들만 샘플링해서 사용한다” 이 말이, 상이 생긴 영역에 대해 해당 영역의 특징을 샘플링해줘서 이를 3D reference point의 voxel 특징으로 만들어주는 것인지, 아니면 그 주변의 특징들을 활용해서 3D reference point의 voxel 특징으로 만들어주는 것인지 헷갈려서 이 부분에 대해서도 질문 드립니다.
3. Dense Occupancy Ground Truth에서 “축적 시킨 라이다 포인트가 부족했는 지 많은 hole들이 발견”에서 hole은 무슨 hole인가요? 라이다 포인트클라우드의 분포가 hole형태로 텅 빈 부분이 생겼다는 뜻인가요?
감사합니다.
안녕하세요. 재찬님, 리뷰 읽어주셔서 감사합니다.
(1) 카메라 배치에 대한 디테일적인 부분이나 ablation study는 없었습니다. 다만 당연히 카메라를 더 많이 사용하여 이미지들을 받게 되면 연산량은 올라갈 것입니다. 또한 모델 자체가 2D 이미지의 semantic info를 이용하여 각 복셀마다의 점유여부를 direct로 예측하기 때문에 정보의 양이 많아 진다는 것은 긍정적으로 작동할 것 같다고 생각이 됩니다만. occlusion여부나, 다양한 환경적인 요소가 복합적으로 작동한다면 부정확한 정보가 제공이 될 수 있기 때문에 확실하게 성능향상이 된다? 라는 것은 확신할 수 없을 것 같습니다.
(2) 넵 후자에 해당합니다. 말 그대로 정면부에 3차원 복셀에 해당하는 점의 정보를 reconstruction하는데 후면 이미지를 참고할 필요는 없겠죠? 그런 관점에서 3차원 복셀점을 multi-image로 projection시켰을 때, 상이 맺히는 정면부 이미지만을 사용하는 것이고, 추가적으로 그 이미지를 전체적으로 고려하기보다는 상이 맺힌 지점에의 주변 부의 특징들만을 고려하여 3차원 복셀점에 대한 feature를 뽑겠다는 의미입니다.
(마치 CNN이 주변 정보로 특징을 뽑는 것과 같은 맥락이라고 생각해주시면 될 것 같습니다.)
(3) 넵 이해하신 바가 맞습니다. Figure 4의 “Static Scene”을 봐주시면, 라이다가 포인트클라우드를 얻는 방식에 의한 한계로 하얀색 층?? 구조로 비어있는 부분이 존재하게 됩니다. 해당 공간에는 아무런 정보가 없고, 이런 부분을 hole이라고 말합니다.
감사합니다.