안녕하세요. 이번 5월달에 Yolo의 10번째 버전이 발표되었다는 소식을 듣고, 이를 기념삼아 Yolov10의 리뷰를 작성하게 되었습니다. 제가 연구실에 처음 들어왔을 때 즈음, Yolov8이 나왔었는데 발전이 굉장히 빠르네요. 물론 Yolo가 매 버전이 출시될때마다 엄청난 새로운 인사이트를 보인다고 하기에는 어렵지만, 오늘날에서는 큰 쓰임이 보이지 않는 2D Object Detection의 연구도 어느 부분에서는 지속되고 있다는 점 또한 주목할만합니다. 최근 OVOD의 YOLO-WORLD를 리뷰했었는데, 이처럼 Yolo라는 네트워크는 다양한 분야에서 활용되는 동시에 그 자체로도 일부에선 연구되고 있다는 점이 흥미롭네요. 이전의 Yolo 시리즈들을 읽지 않았더라도, 이해엔 어려움이 없을 것입니다. 그럼, 리뷰시작하겠습니다.
Introduction
현 시점에서 전통적인 2D object detection 모델은 특수한 목적에선 대체될 여지가 많습니다. 하지만 연구 측면에서 실시간성을 고려 시, 쓰임새는 있습니다. 그 중 Yolo는 v10까지 발전할 정도로 관심이 많으며, 다른 연구에서도 Yolo를 기반으로 하기도 합니다. 저자는 Yolo 모델이 크게 두 부분인 모델 포워딩과 NMS 후처리로 구성되어 있지만, 이 둘의 어떠한 약점이 정확도와 추론 시간에 대해 최적화되지 않고 있다고 분석합니다. NMS가 필요한 이유는 곧즉 모델이 학습 도중 하나의 객체에 다중의 Anchor를 매칭시키는 one-to-many 방식을 사용하기 때문입니다. 이는 다양한 크기의 객체에 대응하기 용이하면서도, 학습 시 Loss function에서 다양한 Positive sample에 대해 학습할 수 있는 장점이 있습니다. 해당 방식은 성능 측면에서 이점을 보이나, 우리가 잘 아는 바와 같이 해당 방식은 추론 시 최적의 예측을 위한 NMS 과정을 요구하며, 이는 추론 속도를 느리게 만들고, 하이퍼파라미터에 민감하게 반응하여 일반화된 성능을 기대하기 어렵습니다. one-to-one 방식으로 대표적인 DETR (그 중 특히 RT-DETR)의 경우, uncertainty-minimal query selection의 방법을 통해 DETR을 real-time의 분야로 나아가게 하나, 저자는 DETR의 구조 자체가 내재된 복잡성으로 인해 정확도와 속도 사이 최적점을 찾기 어려우니, 여전히 Yolo의 구조가 특히 속도에서 큰 이점을 보이나 이러한 시도가 없었음을 언급하며 이를 시도하고자 합니다.
두 번째는 Yolo의 버전이 발전함에 따라 각 버전에서 “A모듈을 더하고, A모듈에 B모듈을 더하고”와 같은 방식으로 발전해왔으나, 그러한 구성이 특히 속도 측면에서 최적이 아님을 언급합니다. 즉, 몇몇의 전략들은 오히려 성능이 조금 오르더라도 속도가 느려지거나, 혹은 그 반대가 되어 아쉬움을 보인다고 합니다. 그러므로 저자는 이제껏 사용된 PAN, BiC, GD, RepGFPN 등의 방식과 Model scaling, Re-parameterization 등의 전략을 분석하여 쉽게 말하자면 “좋은 것은 유지하고, 아쉬운건 제거하는 방식”으로 모델을 구성하고자 합니다. 저자가 언급하는 주된 Contribution은 다음과 같습니다.
- Post-processing에서 NMS를 대체하고자, Dual assignment 전략을 통한 NMS-free 방식의 Yolo를 제안합니다. 이를 위한 Dual-label assignment와 matching metric이 존재합니다.
- 모델 구성에 있어 전체적으로 Efficiency-accuracy을 고려한 모델 디자인을 제안합니다. Efficiency를 위해 저자는 경량화된 classification head와 spatial-channel decoupled downsampling, rank-guided block design을 제안합니다. Accuracy를 위해서는 Large-kernel convolution과 Effective partial self-attention을 제안합니다.
Methodology
Consistent Dual Assignments for NMS-free Training
[설명에 있어, 이전 Yolo에서 사용된 방법론들을 한-두 줄만 짚고 넘어가겠습니다]. 학습 시 Yolo는 각 인스턴스에 대해 여러 positive sample을 할당하고자 TAL(Task-Alignment Learning: Classification과 Bounding Box Regression의 두 태스크에 대해 Alignment하는 방법)을 활용합니다. 기존의 one-to-many 방식은 풍부한 Supervision을 줄 수 있어 최적으로 수렴하는데 도움이 되나, NMS를 필수적으로 요구하기에 속도 면에서 아쉬움을 보일 수 밖에 없습니다. 이전 연구들에서의 One-to-one 방식은 중복된 예측을 억제하나, 앞서 언급한 바처럼 Suboptimal에 머무르기 때문에 저자는 이를 극복하기 위한 방법을 제시합니다.
Dual label assignments
one-to-one matching경우 gt에 대해 하나의 예측만 할당되도록 하는 전략으로, NMS 과정이 필요하지 않지만 Supervision이 약하기에 Suboptimal에 빠진다는 단점이 있습니다. 반면 one-to-many의 경우 강한 Supervision을 보이지만 느린 속도를 보이기에, 저자는 이 둘을 결합한 Dual-label assignment를 제안합니다. 아래의 Figure-(a)와 같이, 저자는 학습 시 기존의 one-to-many detection head에 one-to-one detection head를 추가로 활용합니다. 이 둘은 동일한 구성으로 단순히 예측 시 many, one의 출력층 차이만 존재하기에 동시에 최적화시키도록 설계할 수 있기에 이 점을 활용하고자 하였는데, 해당 구성을 통해 backbone과 PAN (PAN: Bottom-up Path augmentation을 통해 마치 FPN과 유사한 작동을 하는 네트워크 구성)에 강한 Supervision을 줄 수 있습니다. Inference 시에는 이제 속도가 문제가 되니 One-to-many detection head는 제외한 채 One-to-one detection head만 사용합니다. 이는 One-to-one detection head도 One-to-many detection head로부터 학습 시 Supervision을 전달받을 수 있고, 다른 말로는 결국 One-to-many와 유사하도록 학습되니 (동시에 최적화 과정을 거치기에) 예측에 있어 큰 문제가 되지 않습니다.
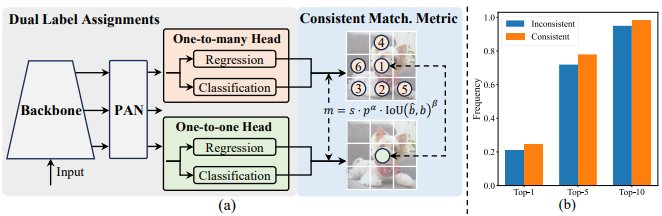
One-to-one matching에 대해 살펴보자면, 결국 Yolo의 end-to-end 특성을 살리면서 적은 inference cost를 위함이 주되면서도 성능면에서 큰 손해를 보지 않아야하니, Hungarian matching (DETR)과 유사한 효용을 보여야하며, 저자는 이것이 Top-one selection (학습 시 GT에 대한 N개의 positive sample이 있더라도, 이 중 가장 높은 하나의 Score만 fg, 나머지는 bg로 학습시키는 전략)을 선택하였습니다.
Consistent matching metric
Dual-label assignment 과정에 대해 설명 드리며 언급드린 내용 중 “One-to-one, One-to-many를 동시에 최적화 함”을 말했습니다. one-to-one과 one-to-many의 전략이 예측과 gt 간 일치되는 수준을 판단하기 위한 metric으로, 저자는 전형적인 IoU matching metric을 사용합니다.
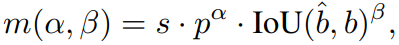
수식 1에서 p는 classification score, \hat{b}, b 는 각각 예측과 gt의 bounding box를 의미하며, s는 spatial prior에 대한 indicator (predefined anchor point가 instance 내 (fg 후보, 1), 혹은 밖 (bg, 0)인지를 구분)에 해당합니다. \alpha, \beta 는 semantic prediction task와 location regression task에 대한 균형을 위한 하이퍼파라미터로, 결국 수식을 해석해보면 일반적인 gt와 예측 간의 IoU를 통해 예측의 수준을 평가하여 Loss에 활용합니다.
Dual-label assignment에서도 One-to-many branch는 One-to-one에 비해 풍부한 supervision 신호를 줄 수 있으며, 직관적으로 각 branch (detection head)에서의 supervision을 일치시키면 추론 시에 one-to-one branch만 사용해도 좋은 성능을 기대할 수 있습니다. 하지만 현재는 각각 다른 branch이므로, 물론 backbone, pan에서 간접적으로 영향을 받는다할지언정 뭔가 부족함이 있습니다. 저자는 이를 위해 우선 두 branch에서 얼마나 supervision에서 차이를 보이는지 분석하고자 합니다. 학습 도중의 랜덤성을 모두 제거한 채 두 branch를 동일한 값으로 초기화하여 분석하였을 때 (각 prediction-gt 쌍의 classification score와 IoU가 초기에 동일하도록), 우선 객체에 대해 예측과의 최대 IoU를 u^{*}, one-to-many와 one-to-one의 matching score 최댓값을 각각 m^{*}_{o2m}, m^{*}_{o2o} 로 정의합니다. one-to-many branch가 positive sample ( \Omega )을 만들어내고 one-to-one branch가 m^{*}_{o2o} = m_{o2o, i} 의 i번째 예측을 선택한다고 가정할 때, classification target ( t_{o2m, j} )을 task aligned loss로 볼 수 있습니다. 이 때의 1-Wassertein distance를 각각의 branch에 대한 supervision gap으로 수식으로 정의한다고 합니다만, 결국 한 마디로 하나의 동일한 Regression 예측에 대한 Classification branch에서의 값들 간의 차이를 Supervision gap으로 보기 위한 수식 설계입니다.
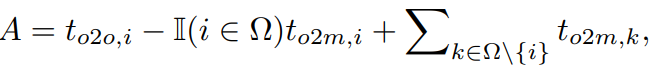
단순히 Classification score간의 차이도 Supervision gap으로 볼 수 있을테지만, 저자는 위 수식을 설계하여 분석 시 위 Figure-(a)에 보이는 바와 같이, “수식적으로 분석해보니 One-to-many의 최상의 Positive sample (그림에서의 (1))은 One-to-one의 최상의 Positive sample (아래 초록색 포인트)와 동일하더라~ 그럼 결국 하나의 Detection head를 최적화 함이 곧 두 Detection head를 최적화하는 방향과 같으니, 현재의 구성이 서로 조화를 이루면서 Loss의 방향이 일치되는 방향임을 증명함”으로 해석하면 될듯합니다. 그렇다면 결국 각 Detection head에서 사용될 하이퍼파라미터도 동일해야겠습니다.
Holistic Efficiency-Accuracy Driven Model Design
NMS-free를 위한 one-to-one 전략에 이어, 저자는 Yolo의 모델 구조를 분석하여 “뼈는 취하고, 살은 버리는” 방식을 택합니다. v10까지 오기까지의 다양한 방법들에 대한 분석이 부족했음을 언급하며 결과적으로 무시해도 될만한 computational redundancy (속도 측면)나 제한된 성능을 보이게끔 (성능 측면) 만드는 요소들에 대해 분석하는데, 우선 Efficiency driven model design입니다. (속도 측면)
Efficiency driven model design
(1) Lightweight classification head: classification, regression head는 Yolo 버전이 업그레이드됨에도 동일한 구조를 유지하였습니다. 그러나, 이 둘을 비교 시 꽤나 많은 computational overhead의 불균형이 있음을 발견하였는데, classification head의 FLOPs와 parameter 수가 regression head에 비해 2.4~2.5배 수준 많음을 발견했습니다 (Yolo v8-S 기준). 그러나 실제 성능 측면에서 분석 시에는 classification에 비해 regression error가 더 큰 영향을 가짐을 발견합니다. 결과적으로 classification head를 경량화하더라도, 성능 측면에서는 큰 하락을 보이지 않을 것을 예상하여 두 개의 depthwise separable convolution (1×1, 3×3 convolution으로 구성된)의 classification head로 변경해도 무방하다고 언급합니다.
(2) Spatial-channel decoupled downsampling: Yolo는 기본적으로 3×3 (stride:2) convolution 레이어를 활용하여 spatial downsampling을 진행합니다 (한 번 convolution layer를 거칠 때마다 높이, 넓이 각각 절반, 채널 수는 2배가 됩니다). 하지만 이 방식은 computational cost와 parameter count를 보았을 때 각각 9/2HWC^{2}, 18C^{2}으로 무시할만한 수준이 아니기에, 이전과 동일한 효과를 보이면서 파라미터 수를 줄이고자 pointwise convolution을 통해 channel을 조절하고, depthwise convolution을 통해 spatial downsampling을 구현합니다. pointwise, depthwise의 경우 일반적으로도 쉽게 사용되는 전략이기에 크게 특별하게 보이지는 않습니다. 위 전략을 실행 시 파라미터는 이전에 비해 각각 9/2HWC{2 + 2HWC^{2}}, 18C + 2C^{2}으로 줄어든 모습을 볼 수 있습니다.
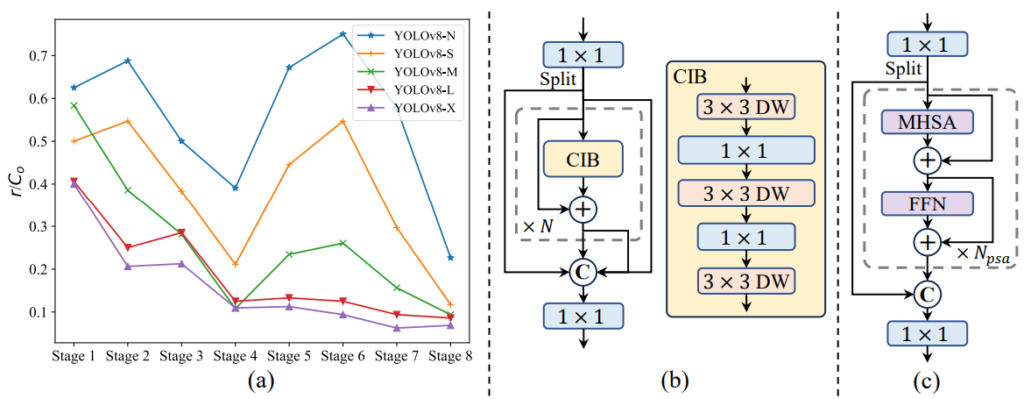
(3) Rank-guided block design: Yolo는 일반적으로 모든 Stage에서 동일한 구조 (building block)을 활용합니다. 그런 동일한 디자인에 대해 각 Stage가 어느 정도의 영향력을 보이는지 평가하고자 intrinsic rank를 도입하였으며 이 rank는 각 Stage에서의 redundancy를 평가합니다 (low lank는 redundancy가 높음을, high rank는 압축된 정보가 존재함을 의미합니다). Intrinsic rank를 통해 평가 결과, 모든 Stage에서 동일한 구조를 가져감을 Suboptmal (Capacity-efficiency trade-off에서 좋지 못함)에 빠지는 결과를 보이며 그렇기에 이 Rank를 기준으로한 Rank-guided block design 구조를 제안합니다. 해당 디자인은 Architecture에서 필요한 부분은 두고, 영향력이 크지 않은 부분은 축소하는 방향으로 조금 더 압축하겠다는 의미인데, 곧즉 Compact Invereted Block (CIB)라는 바로 위 (2)의 pointwise, depthwise convolution을 통해 구현됩니다. 아래의 사진을 보면 각 Stage에서의 Rank (yCNR)를 분석한 그림으로, 모델의 크기에 따라 다르긴 하나 결국 하고자 하는 말은 CIB block을 통해 모델의 파라미터를 축소시킬 수 있으며, 구체적으로는 모델에 대해 모든 Stage를 intrinsic rank에 따라 오름차순 정렬시킨 후 기존 구성을 CIB block을 채운 구성으로 변경 시켜 이 때의 성능 차이가 미미하다면, CIB Block으로 갈아끼우는 실험에서 기인하는 모델 디자인을 선보입니다. 개인적으로 이 점은 실험적으로 구성된다는 점에서 딱히 끌리진 않네요 (Depthwise가 이제서는 새롭거나하는 방식이 아님에도 그렇구요)
Accuracy driven model design
(1) Large-kernel convolution: Receptive field를 늘리기 위한 Large-kernel 방식입니다. 하지만 Large-kernel을 모든 Stage에 도입하면 그 특성 상 Small-object 검출에 부정적 영향을 미칠 수 있으며 High-resolution stage에서는 연산량을 늘릴 수 있으므로, 위에서 소개한 CIB에서만 (Computational cost를 많이 소비하지 않는 Rank 단계) Large-kernel depthwise convolution 방식으로 활용합니다. Large-kernel도 사실 굉장히 예전 방법론이므로, Fancy하게 와닿진 않습니다.
(2) Partial self-attention (PSA). Attention 방법이 성능에 도움은 되나 Computational cost를 많이 잡아먹기 때문에 이를 어떻게 할까하다가, 1×1 covnolution을 거친 이후 Feature map을 두 갈래로 나누어 Multi-Head Self-Attention (MHSA)와 FFN을 거치는 방식이지만, 사실 이 부분도 제 생각엔 너무 예전 방식입니다. 오히려 위의 Efficiency에서의 Lightweight classification head에서 분석한 Classification head와 Regression head가 얼마나 성능에 영향을 미치는지, 그러면서 Computational은 어느 정도의 차이이니, 이를 해결하기 위한 방법 정도만 설득력 있었습니다. Yolov10이 나왔다고 하여 한 번 읽어보았는데, 개인적으로 방법론에서는 사실 “One-to-one matching strategy를 사용하기 위한 탐색과정”을 제외한다면 지금까지 그냥 흔히들 사용되는 몇몇 방법론을 사용한것에 그치지 않나 하는, 그런 Fancy함을 찾아보긴 어려워 많이 아쉽습니다. 실험은 익히들 아실테니, 표를 보며 중요한 몇몇 부분을 짚고 마치겠습니다.
Experiments
저자는 베이스라인 모델로는 Yolov8을 사용합니다. Yolov9에 대해 언뜻 들어만 봤지만, 요즘 Yolo를 사용한 모델이라고 한다면 보통 Yolov8, 혹은 그 이전이라면 Yolov4가 주로 사용되는듯 합니다.
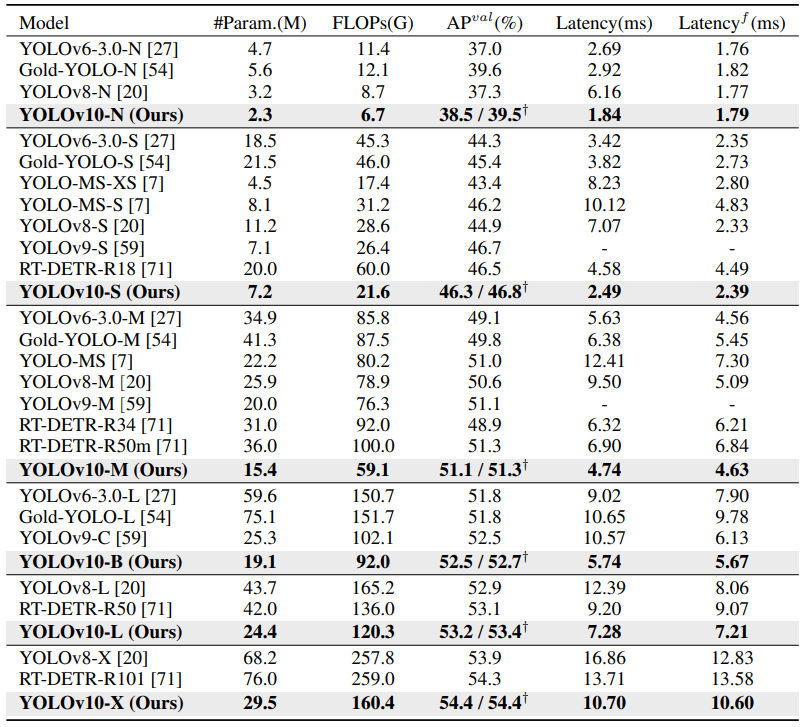
우선 벤치마킹 표를 살펴봐야겠죠. Yolov6? 이후로는 보통 모델의 크기가 파라미터에 따라 S, M, L, X 정도로 세분화됩니다. 지금 이 논문이 나온지 얼마되지 않음에도 16 정도의 Citation을 보이는데, 실험 테이블을 보면 COCO에서만 학습/평가가 끝입니다. Arxiv라할지언정, 최소 COCO, Pascal, 요즘에는 2D OD여도 Long-tailed dataset에서 실험을 진행하는데, 베이스라인으로 삼은 Yolov8과 위에서 설명한 one-to-one matching 방식의 RT-DETR을 제외한 다른 논문의 실험은 가져오지 않았네요. 우선 Params와 FLOPs를 따져본다면, 그래도 이전 Yolov8 대비 두 배 이상으로 최적화된 모습을 보입니다. 물론 본 논문은 “Real-time Applicable”이 더욱 중점이여서 저자도 실험 설명에서 Yolov8과 유사하거나 그 이상의 성능을 보인다고 언급하며 오히려 어떤 모델 크기라 할지언정 그 정도의 성능에서 속도가 개선되었으니 유의미하다고 평가합니다. 사실 제가 본 논문을 읽은게 물론 기념비적인 10번째 시리즈임에도는 맞지만, 요즘까지 2D object detection에 대해 연구하는 분들이 얼마나 본인의 방법론을 설득시키기 위해 다양한 실험을 진행할까였는데, 뒤의 Ablation study에서도 단 하나의 데이터셋인 COCO밖에 없는 점은 아주 개탄스럽습니다.
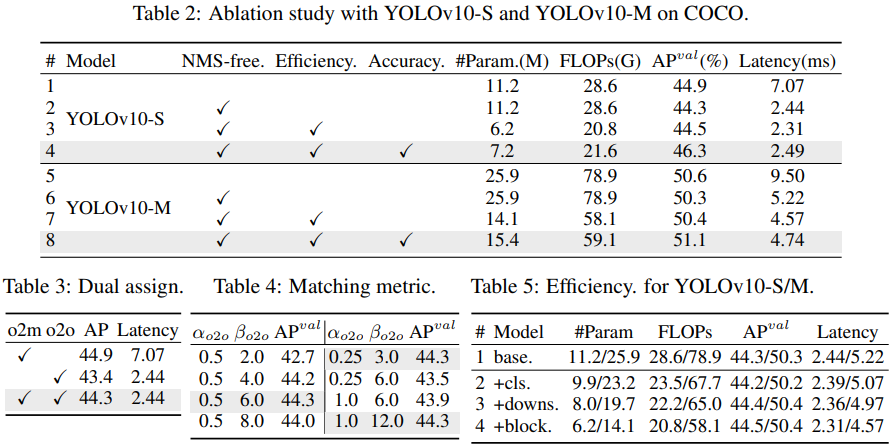
Ablation study는 많이 진행하였습니다. 그 중 주요하게 살펴볼 점인 NMS-free에 대한 점을 위주로 보면 좋겠는데, Table 2에서 #1과 #2를 비교 시 NMS-free에 대한 AP와 Latency를 분석 시, 44.9에서 44.3으로 0.6의 성능이 아쉬운 점 (물론 one-to-one이 one-to-many만큼 최적화될지언정 추론 시 더 정확한 예측은 one-to-many 방식의 이점이 있을 수 밖에 없습니다)을 보이지만, Latency에서 3배 이상 빨라진 점이 주목될만합니다. Efficiency와 Accuracy 측면에서는 Efficiency를 위한 위 문단의 Lightweight classification head 등이 사용되었음에도 오히려 좋은 성능을 보이는데, 이를 통해 Lightweight classification head, 즉 classification error가 아닌 localization error에서 AP의 성능 하락이 기인하였으며 아주 간단한 방식인 Pointwise, depthwise convolution을 통해 성능이 조금이라도 오르면서, Latency가 조금 더 빨라진 (저 Latency로 성능 측정이 곧즉 FPS의 역수에 비례한다고 볼 수 있는데, 얼만큼 빨라진지는 쉽게 감이 오진 않네요) 측면을 살펴볼 수 있습니다. 또한 Table 3에서의 Dual assign 경우, o2m (one-to-many)에 비해 o2o (one-to-one)이 1.5% 정도로 성능 하락이 있지만, 이 둘을 함께 활용 시 더 좋으 ㄴ성능을 보임을 알 수 있습니다. 이렇듯 Table 4,5에 대한 실험도 언급은 하나, 사실 보이는 바와 같이 크게 유의미함을 느끼지 못하였습니다. 특히 실험이 COCO에서만 이루어지며 Appendix에서 다음 문장과 같이 “Computational resource”가 부족하다고 하는데, 음? 이 정도도? 싶긴 하네요 허허.. 어찌되었든 이번에는 10번째 버전이라는 기념비적으로 Yolo 시리즈를 한 v3 이후 처음 읽어보았는데, 그 사이 많은 점이 바뀌었음에도 어느 누군가는 연구를 진행하구나 하는 점 정도로 보고 넘어가겠습니다. 감사합니다.

안녕하세요 상인연구원님,
좋은 리뷰에 진심으로 감사드립니다. 캡스톤 프로젝트를 준비하면서 YOLOv10을 사용하게 되었는데, 연구원님께서 소개해주신 논문의 NMS-free 전략 덕분에 공부하는 데 큰 도움이 되었습니다.
저는 이 방식을 -학습 단계에서 One-to-many와 One-to-one 두 branch를 동시에 최적화하여 Supervision과 중복 억제 효과를 동시에 얻고, 실제 추론 단계에서는 One-to-one branch만을 사용하여 NMS를 생략한다”라는 개념으로 이해했습니다. 덕분에 기존 YOLO 구조의 장점을 유지하면서도 복잡한 NMS 과정 없이 중복 예측을 억제할 수 있다는 점이 특히 인상적이었습니다. 추가적으로 논문 내에서 소개된 Rank-guided block design, Large-kernel convolution, Partial self-attention과 같은 기법들은 처음엔 이해가 부족했는데, 연구원님의 설명 덕분에 명확히 이해하게 되었습니다.
덕분에 논문을 쉽게 이해할 수 있었고 많은 도움을 받았습니다. 다시 한번 감사드립니다!