참고논문: SSD : Single Shot Multibox Detector, ECCV2016
깃허브: https://github.com/weiliu89/caffe/tree/ssd (원저자)
SSD는 Single Shot Multibox Detector의 약자로 말 그대로 하나의 이미지에서 여러개의 박스를 찾아내는 Image Detection의 한 방법론 입니다.
Image Detection은 쉽게말해서 다음과 같은 이미지가 모델에 전달되면,

다음 이미지와 같이
물체를 찾아내고, 그 물체의 위치가 어디인지, 그 물체가 무엇인지 분류해 낼 수 있도록 하는것입니다.

그럼 SSD 모델은 어떠한 방법으로 학습 하는지 알아봅시다.
딥러닝 모델은 입력 정보에 대해 정답을 예측하고, 그 예측과 실제 정답(Ground Truth -GT)간의 오차를 구하여 오차가 작아지도록(예측이 정답에 가까워지도록) 보정을 하며 학습을 합니다. SSD도 마찬가지입니다. 우선 예측을 해야하는데요, 그 예측 방법은 아래와 같습니다.
우선 SSD는 저해상도 이미지에서 높은 성능이 나오기 때문에, 인풋 이미지는 300×300크기의 저해상도 이미지를 사용합니다.
300x300x3(RGB이미지는 3개의 채널을 같기 때문에 이렇게 표현됨)의 이미지가 모델에 들어오면, VGG-16이라는 Net을 통과하고 나면, 300x300x3크기의 한장의 이미지는 38x38x512크기의 이미지로 줄어들게 됩니다.

그렇게 줄어든 크기의 이미지는 위의 사진처럼 1x1x256까지 총 6개로 줄어들게 되는데요, 이를 feature map 이라고 부릅니다.
이렇게 이미지를 축소 시키는 컨셉은 다음을 반영합니다.
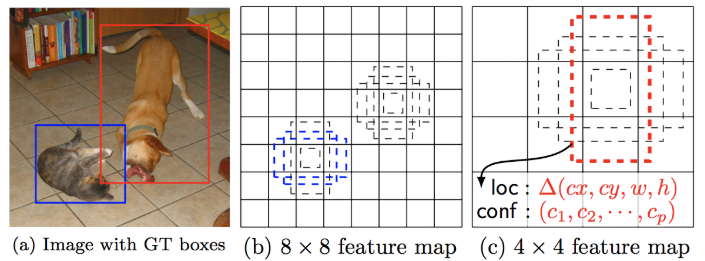
같은 크기의 박스들로 이미지에서 물체를 찾을때, 작은 물체인 고양이는 8×8의 큰 피쳐맵에서 찾게되고, 큰 물체인 강아지는 4×4의 작은 피처맵에서 찾게됩니다. 즉, 물체의 크기에 상관없이 모든 물체를 찾을 수 있도록 하는것입니다. (같은 크기의 상자를 쓰는 이유는 나중에 나옵니다.)
이제 모델은 각각의 이미지에서, class(물체)를 찾아내 박스를 칩니다. 맨 처음 이미지에서 자동차와 의자에 박스를 친것처럼 말이죠. (이러한 박스를 Bounding box라고 부릅니다.)
물체를 찾아내 해당 물체의 위치를 파악하고, 그 물체가 무엇인지 알아내는것은 쉬운일이 아닙니다. 그렇기 때문에 모델을 학습시키는거죠.
물체를 찾아내는 방법은 다음과 같습니다.
위 6개의 피쳐맵의 각 픽셀마다 바운딩 박스를 칩니다. 각 박스는 박스 중심의 좌표(x, y), 높이(h)와 너비(w) 4개(offset)와 분류할 classes 각각의 확률(이 박스가 고양이를 가르킬 확률, 강아지를 가르킬 확률, 등 모든 클래스에 대한 확률) 정보를 가지며,
38×38에서는 픽셀당 4개, 19×19 에서는 6개, 10×10은 6, 5×5 : 6, 3×3 : 4, 1×1 : 4
개의 박스를 찾아냅니다. 그렇게 되면
38x38x4 = 5776, 19x19x6 = 2116 10x10x6 = 600, 5x5x6 = 150, 3x3x4 = 36, 1x1x4 = 4
총합 8732개의 바운딩 박스를 갖게됩니다.

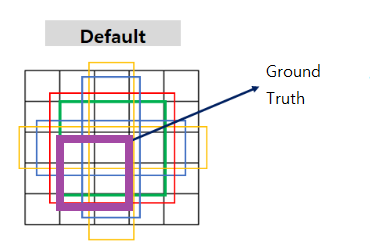
학습 최초의 박스는 그냥 임의로 치는것이 아닙니다. 미리 정해놓은 크기의 박스들과 피처맵의 크기에 대한 비율을 계산한 박스를 치게 됩니다. 이 때 미리 정해놓은 크기의 박스를 default box라고 합니다.
비율을 통해 상자를 그리기 때문에 원 이미지보다 작은 피처맵에서 구한 박스들이 입력 이미지에 그려질 수 있는 것입니다.
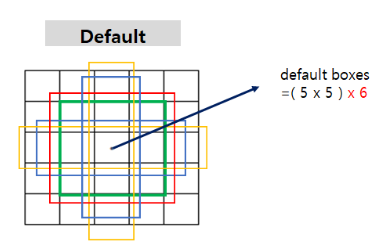
그 6개의 박스가 바로 디폴트박스 입니다.(유색의 박스 6개)
자, 그럼 우리의 모델은 지금 300×300의 이미지안에 8732개의 박스를 그렸습니다. 이 박스들은 모두 안에 물체가 있을 가능성이 있는 박스들이죠. 다음 이미지들 봅시다

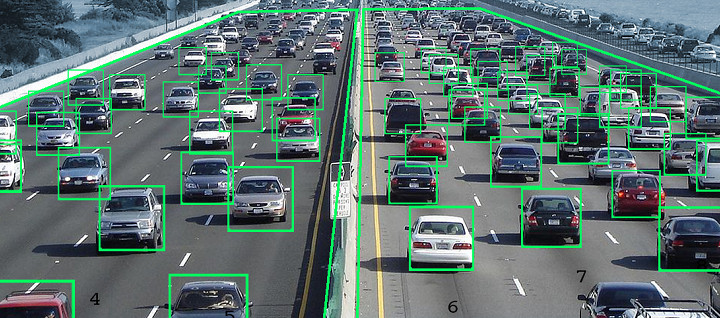
맨 처음의 이미지보다 박스의 수가 훨씬 많아 보입니다. 하지만, 이렇게 많은 박스도 100개가 채 되지않죠.
피쳐맵의 모든 픽셀을 고려한 8732개의 박스는 불합리하다고 볼 수 있습니다.
그렇기 때문에, 실제 물체가 있는 곳의 박스만 남겨주어야 합니다.
그 과정을 Non-Max-Suppression(NMS)라고 부릅니다.
NMS의 과정은 다음과 같습니다.
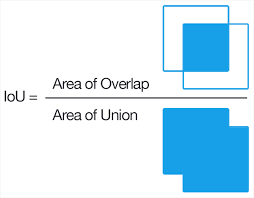
우선 각 피처맵의 모든 픽셀에 대한 디폴트 박스(모델이 예측한것이 아님)와 정답 박스와의 IOU(Intersection Over Union)를 계산하여 그 값이 0.5를 넘는 박스들
에 해당하는 위치의 예측 박스들 만을 남기고 나머지는 제거(고려하지않음)합니다.
아래와 같은 상황에서는 가운데 픽셀(13번째 픽셀)에 대해서 초록색 디폴트 박스의 인덱스와 같은 인덱스의 예측 박스만 남고 나머지는 없어지게 되겠네요. 뿐만 아니라, 근처의 픽셀에 대해서도 초록색 박스나 파란색 박스정도가 남게 될것입니다.
하지만 그렇게 예측상자를 줄여도 바로 아래와 같이 많은 상자가 남게 될것입니다.

그래서 위의 Convnet과 같은 과정이 필요합니다.
이 과정은 한 물체가 여러개의 박스들을 중복해서 갖게 될때, 같은말로 여러개의 박스가 한 물체를 중복해서 가르키는 경우를 제거하여 주는것 입니다.
위에서 말한 것 처럼 박스는 박스의 위치와 높이 넓이 뿐만 아니라, class 전체에 대한 확률을 가지고 있는데요, 이 과정은 클래스 마다 계산을 합니다.
하나의 클래스에 대해 각 박스들을 높은 확률을 갖는 순으로 정렬을 합니다.
그리고 특정 값(Thresh hold)를 넘지 못하는 값들은 0으로 취해줍니다.
그리고 가장 높은 확률의 박스에 대하여 나머지 상자들의 IOU를 구하고,
이번엔 특정 값을 넘기는 박스들을 0으로 취해줍니다. 그렇게 되면 위의 사진과 아래의 사진과 같은 결과가 나옵니다.
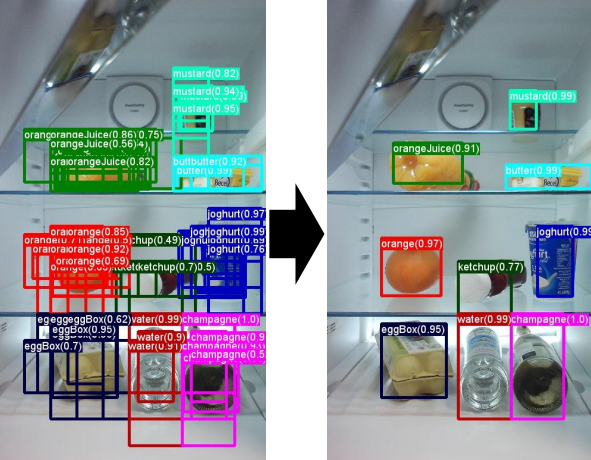
8732개의 바운딩 박스가 위처럼 유의미한 소수의 바운딩 박스로 줄어들게 되었습니다. 이 과정이 NMS 입니다.
위의 사진을 보시면 물체의 이름과 숫자가 붙어있는게 보이시죠 그것이 바로 확률입니다.
학습 과정에서 모델은 최종적으로, 위와같이 입력 이미지에 대해 바운딩박스 정보(Localization)와 각 박스의 클래스 확률(Confidence)을 반환합니다. 이것들이 바로 SSD 모델의 예측값 입니다.
GT 역시 똑같은 정보를 담고있습니다. 이미지에서 물체의 위치(Localization)와 그 물체가 무엇(Confidence)인지 나타내는 정보. 모델은 이 예측값과 Ground Truth와의 차이(Loss)를 계산하며 그 값(Loss)가 작아지는 방향으로 학습을 하게 됩니다.
지금까지 SSD의 학습 방법에 대한 설명이였습니다.