안녕하세요, 열아홉번째 x-review 입니다. 이번 논문은 2023년도 CVPR에 게재된 stereo thermal을 사용한 데이터셋 취득 및 depth estimation 방법론에 대한 논문 입니다. 그럼 바로 리뷰 시작하겠습니다 !
1. Introduction
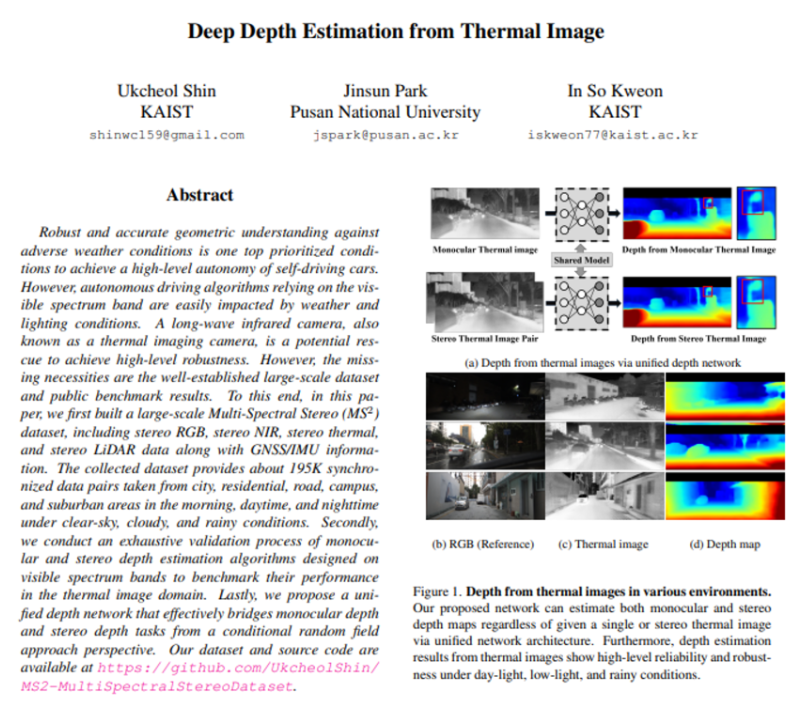
현재 자율 주행 관점에서 널리 사용되는 벤치마크 데이터셋 (KITTI, nuScenes)에서 정확하고 강인한 3차원 인지를 위한 연구가 진행 중 입니다. 보통 딥러닝 네트워크나 데이터 기반의 머신 러닝 기법으로 정확도를 올리고자 하는데요, 그러기 위해서는 large scale의 데이터셋이 필요하기 마련 입니다. 그런데 만약 real world 관점으로 보았을 때 위와 같은 알고리즘들은 보통 가시광선 스펙트럼의 이미지를 기준으로 다루어지고 날씨나 조도 변화에 쉽게 영향을 받게 됩니다. 그래서 최근에는 가시광선이 아닌 NIR 카메라나 라이다 혹은 LWIR 카메라를 사용하고자 합니다. 그 중에서도 LWIR 카메라(열화상 카메라)는 물체가 가지고 있는 열에 반응하여 열악한 환경에 강인하게 반응할 수 있습니다. 이러한 장점에도 불구하고 현재 LWIR 뿐만 아니라 NIR 파장대의 센서로 취득한 데이터가 포함된 데이터셋은 매우 드물게 존재합니다. 그나마 가시광선 이외 파장대의 센서가 포함되어 있더라도 데이터셋이 작은 규모이거나 공개적으로 사용이 불가하거나 혹은 제한된 개수의 센서를 사용하고 있다고 합니다. 그렇기 때문에 다양한 센서를 사용하면서 large scale으로 구성된 자율주행 데이터셋이 필요한 상황 입니다. 또한 열화상 카메라를 사용하기 위해서는 LWIR 파장에서 어플리케이션 성능을 검증해야 한다는 것 입니다. monocular나 스테레오 이미지에서 depth를 추정하는 것은 scene의 기하학적인 구조를 이해하기 위해서 기본이 되는 task 중 하나 입니다. 최근 depth estimation에 대해 많은 연구가 진행되고 있는데, 보통 RGB 이미지를 이용하는데 초점을 맞추고 있습니다. 그러나 만약 지금과 같이 열화상 카메라를 사용하려고 하게 되면 RGB 이미지보다 해상도가 낮고 텍스처 정보가 부족하기 때문에 스테레오 매칭 알고리즘을 설계하는 것이 더 어려워집니다. 즉 RGB 이미지에서는 성능이 보장되던 스테레오 매칭 알고리즘들이 열화상 영상으로 오게 되면 그 성능이 불확실해진다는 것이죠. 이를 해결하기 위해서 본 논문에서는 large scale의 여러 스펙트럼 범위를 포함하고 있는 다중 센서 데이터셋 취득과 동시에 해당 데이터셋으로 진행한 실험 결과를 보이며 다중 센서를 사용하는 것이 기하학적인 알고리즘에 대한 높은 수준을 끌어올릴 수 있고 이상 환경에서도 강인성을 띈다는 것을 보여주고 있습니다.
여기서 본 논문의 main contribution을 정리하면 다음과 같습니다.
- RGB, NIR, Thermal, LiDAR를 모두 스테레오로 세팅한 lare scale의 멀티 스펙트럴 스테레오(MS2) 데이터셋을 제공한다. 제공하는 데이터셋은 맑은 날씨 뿐만 아니라 흐린 날, 비 오는 날을 배경으로 아침, 낮, 밤 시간대의 도시, 도로, 캠퍼스 및 교외 지역에서 촬영한 195만개의 동기화된 데이터를 제공한다.
- monocular와 스테레오 depth estimation 알고리즘이 열화상 대역에서의 작동이 합리적인 성능을 보이는지 검증
- monocular와 스테레오 depth estimation을 연결하는 통합적인 depth 네트워크를 제안
2. Related Work
2.1. Thermal Image Dataset for 3D Vision
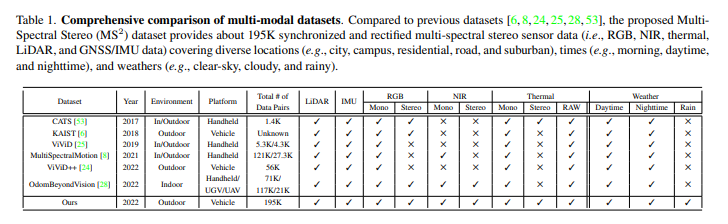
가시광선 스펙트럼의 RGB 데이터셋은 KITTI, Cityscape, nuScenes돠 같이 large scale의 데이터셋이 구축되어 있습니다. 그러나 적외선 영역의 영상으로 이루어진 데이터셋은 가시광선 대비 여러 환경에 강인함에도 불구하고 몇몇 데이터셋에 일부 포함되어 있습니다. Tab1에서 확인할 수 있듯이 현재 대부분의 열화상 영상이 포함된 데이터셋은 멀티스펙트럴 이미지 센서에 대한 feasability를 확인이 불충분한 상황으로 그 이유로는 indoor 기반이거나 데이터셋의 규모가 작거나 혹은 공개 데이터셋이 아닌 경우가 있습니다. 또한 센서의 다양성이 부족하거나 일반적인 환경에서만 촬영하여 눈이나 안개와 같은 기상 환경에 대한 셋이 존재하지 않고 raw 열화상 데이터가 존재하지 않는 등의 이유가 있습니다.
2.2. Depth From Visible Spectrum Band
Monocular Depth Estimation (MDE)
MDE는 단일 이미지에서 depth map을 측정하기 때문에 스테레오에 비해 사용이 활용이 더욱 용이합니다. 신경망을 통해서 각 픽셀별로 depth 값을 측정하는 regression과 연속적인 depth의 범위를 discrete한 구간으로 변형하는 classification으로 나눌 수 있습니다. 그러나 이러한 MDE는 무한히 많은 3D scene에서 하나의 2D 이미지를 만듬으로써 추정된 depth map이 근본적으로 정확히 만들어진 것인지가 모호해지고 일반화된 성능이 낮아 stereo 이상의 이미지에 대한 depth estimation보다 낮은 성능을 제공하고 있습니다.
Stereo Depth Estimation (SDE)
반면 SDE는 스테레오 이미지 쌍에서 주어진 카메라 베이스라인과 disparity map을 이용하여 depth estimation을 수행합니다. 기존의 스테레오 매칭 네트워크는 3D cost volume과 4D cost cost volume 기반의 방법으로 나뉠 수 있는데, 전자는 왼쪽과 오른쪽 이미지 쌍의 feature 사이의 유사도를 측정하여 single 채널의 cost volumeD\times H \times W을 추정한 다음 2D 컨보루션을 통과하게 됩니다. 이러한 방식의 SDE는 높은 메모리와 계산 효율성을 가지지만 인코딩된 volume이 feature의 많은 정보를 잃게 되면서 정확도가 저하된다는 문제점을 가지고 있습니다. 후자의 경우 두 왼쪽-오른쪽 이미지의 feature volume을 합침으로써 multiple 채널의 cost volume (D \times C \times H \times W)을 만들게 됩니다. 그런 다음 3D 컨볼루션 레이어로 4D cost voume을 형성하게 됩니다. 현재 SOTA 모델이나 최신 방법들은 대부분 후자의 방식을 기반으로 하고 있습니다. 그러나 이러한 방식은 메모리 소비와 계산 복잡도가 높아 실제 어플리케이션 측면에서는 많은 비용을 필요로 합니다. 또한 SDE는 MDE에 비해 상당히 높은 성능 향상을 보이지만 occlusion이나 texture가 없거나 혹은 반사되는 표면인 경우에 두 이미지 쌍에서 정확한 feature matching을 하는 것이 여전히 challenge한 점으로 남아있습니다.
3. Multi-Spectral Streo MS^2 Dataset

3.1. Multi-Spectral Stereo Sensor System
열화상 카메라의 명확한 장점에도 불구하고 이를 포함한 large scale의 데이터셋이 없다는 점이 LWIR 파장에서 어떠한 조건에 구애받지 않는 시스템의 개발을 어렵게 하고 있습니다. 이를 해결하기 위해 Figure 2의 (a), (b), (c)와 같이 RGB, NIR, thermal, LiDAR 스테레오 시스템으로 구성된 데이터를 수집할 플랫폼을 설계하였다고 합니다. 그리고 센서를 구성하는데 있어서 동기화는 매우 중요한 문제인데요, 이는 depth estimation 뿐만 아니라 3D detection이나 reconstruction처럼 여러 센서를 사용하는 task에서 중요하게 여겨지는 조건 중 하나 입니다. 따라서 본 논문에서는 RGB와 NIR 스테레오 카메라를 external synchronizer을 통해 동기화를 맞추었습니다. 열화상 스테레오 카메라는 왼쪽 열화상 카메라의 동기화 신호와 맞춰지고 소프트웨어 trigger를 사용하여서 각 데이터를 취득하기 시작하는 시점부터 두 센서를 동기화 하게 됩니다.
3.2. Data Collection
앞서 이야기하였듯 다중 센서의 스테레오 구성으로 다양한 위치와 조도 환경, 그리고 기상 환경에서의 데이터를 수집할 수 있습니다. 캠퍼스, 도시, 교외 지역 뿐만 아니라 도로 환경에서 동기화를 마친 다중 센서를 통해 데이터를 취득하게 됩니다. 추가적으로 각 scene을 대표하는 위치에 대해서 다양한 시간대 (아침, 낮, 밤)과 날씨 (맑은 날씨, 흐리거나 비오는 날씨)에서의 영상을 제공합니다. 이를 통해 하고자 하는 것은 딥러닝 네트워크의 다양한 환경에서의 성능 일반화와 도메인 갭을 줄이는 능력을 확인하는 것이라고 합니다. 또한 이전의 데이터셋들에 비해 큰 규모의 다양한 파장 대역을 사용하는 센서들에 대한 데이터를 제공할 수 있다는 것이 큰 장점이라고 할 수 있습니다.
3.3. Multi-Specral Stereo (MS^2) Depth Dataset
Ground-Truth Generation Process
데이터의 GT depth map을 만들기 위해서 KITTI 데이터셋과 유사하게 10개의 연속적인 스테레오 LiDAR 데이터를 축적하여 사용한다고 합니다. 각 센서의 타임 스탬프에 대해서 각각의 모든 포즈 정보를 GNSS/IMU 센서 데이터를 보간하여 계산하게 됩니다. 그 후에 연속된 프레임의 데이터 간에 transformatio matrix를 통해서 각 타겟이 되는 열화상 이미지에 대해 10개의 연속적인 스테레오 LidAR 데이터를 모아서 ICP 알고리즘을 통해 의미있는 포인트 클라우드로 refine하게 됩니다. 그 후에 모은 포인트 클라우드를 열화상 평면 차원에 projection하여 최종적으로 GT depth map을 얻을 수 있습니다.
4. Depth Estimation from Thermal Image
4.1. Bridging Monocular and Stereo Depth Estimation
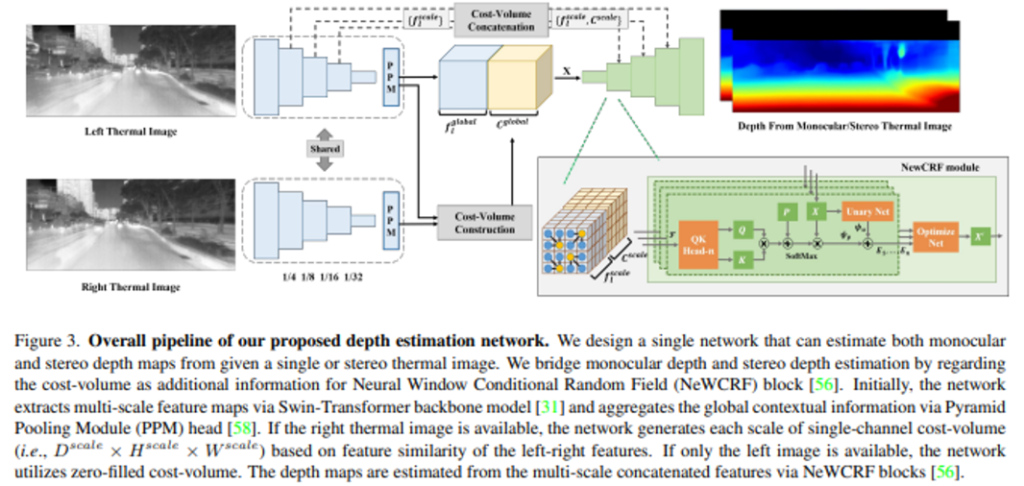
이제 데이터셋 취득에 이어 설계한 depth estimation 알고리즘에 대한 내용인데요, 해당 파트에서는 CRF 관점에서 monocular depth estimation(MDE)와 stereo depth estimation(SDE) task를 연결한 구조 입니다. MDE 네트워크는 우선 extrinsic 파라미터 정보나 여러 이미지와 같은 추가적인 정보가 필요 없기에 높은 범용성을 가진다는 특징이 있습니다. 반면 SDE 네트워크는 왼쪽과 오른쪽 이미지에 대한 rectification을 통해 수평에 대한 대응점을 찾아서 정확한 depth map을 제공할 수 있습니다. 그러나 SDE 네트워크는 occlusion이나 texture가 없는 영역 혹은 반사되는 표면과 같은 영역에서 신뢰할 수 있는 depth map을 제공할 수 없습니다.
이러한 MDE와 SDE 네트워크를 서로 연결하여 두 task의 장단점을 보완하면서 주어지는 monocular 또는 stereo 이미지에서 depth map을 추정할 수 있도록 하였습니다. 이를 위해 이전에 제안되었던 MDE 네트워크인 Neural Window FC CRF(NeWCRF)를 활용하였다고 합니다. Figure3에서 추정된 cost volume을 NeWCRF 블럭에 대한 추가적인 정보로 여기게 됩니다. 그렇기 때문에 오른쪽 이미지가 주어지게 되면 왼쪽 이미지의 특징 F^{scale}_L에 멀티 스케일의 왼쪽과 오른쪽 이미지 특징에 대한 cost volume을 각각 추가합니다. 만약에 왼쪽 이미지만 사용할 수 있다면 네트워크는 cost volume을 모두 0으로 채워 구성하게 됩니다.
4.2. Feature Extraction and Aggregration
우선 백본 네트워크로는 swin transformer을 사용하며 주어진 이미지에 대해서 4개의 스케일로 feature을 추출하게 됩니다. 그 후 피라미드 pooling 모듈(PPM)으로 마지막 스케일 레벨에서 receptive field 1, 2, 3, 6을 가지고 global average pooling을 통해 global한 컨텍스트 정보를 얻습니다. 나머지 scale의 feature들은 skip connection을 통해 각 scale 레벨에서의 디코더의 입력으로 들어가게 됩니다.
4.3. Cost Volume Construction
최근 stereo 매칭 네트워크가 더 높은 성능을 달성하기 위해서 3D 컨볼루션 레이어와 함께 4D cost volume을 활용하고 있다고 합니다. 그러나 4D cost volume을 기반으로 하는 방식은 메모리와 계산 비용이 많이 소모되고 항상 왼쪽과 오른쪽의 feature map을 모두 무조건 사용해야함으로써 네트워크 구조에서 monocular depth estimation을 연결하는 것은 어려운 상황 입니다. 그래서 해결책으로 각 왼쪽-오른쪽 이미지 쌍에 대한 deisparity 수준에 따라서 하나의 채널로 이루어진 correlation map을 가지는 correlation cost volume, 즉 3D cost volume을 사용합니다. 이러한 방법은 왼쪽과 오른쪽 이미지의 feature 사이의 상관 관계 정보를 일부 손실할 순 있지만 추가적인 정보로 monocular depth estimation 네트워크와 쉽게 연결할 수 있게 됩니다. 각각의 스케일에 대한 cost volume은 아래 식(1)과 같습니다.
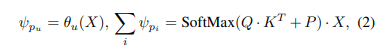
4.5. Disparity and Inverse Depth Prediction
앞서 제안된 네트워크는 마지막 네 개의 NeWCRF 블록으로부터 네 단계의 스케일에 대한 예측 결과 (1/4, 1/8, 1/16, 1/32)를 추저하게 됩니다. 단일 이미지가 네트워크에 주어지면 예측 결과는 Inverse Depth map으로 주어집니다. 스테레오 쌍으로 주어지면 예측 결과는 common disparity map으로 주어지게 됩니다. 각 스케일의 예측 feautre X에 대해서 네트워크는 두 개의 컨볼루션 레이러를 사용해서 단일 채널(disparity map / Inverse Depth map)을 얻게 됩니다. 그 후에 volume을 업샘플링하여 disparity 차원을 따라 소프트맥스 함수를 사용하여 예측값을 계산하는 것이 식(3)으로 정의할 수 있습니다.
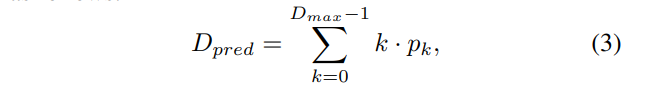
여기서 k는 disparity 레벨을 나타내고 p_k는 대응하는 확률이며, D_{max}는 disparity 범위의 최댓값을 의미합니다.
4.6. Loss Function

Loss Function은 SDE task에서 일반적으로 사용하는 멀티 스케일의 smooth L1 loss를 활용하여 학습하게 됩니다. D_{GT}는 GT disaprity map을 의미하겠죠.
5. Experimental Results
5.1. Implementation Details
MDE and SDE Networks
취득한 MS2 데이터셋을 가시 영역의 스펙트럼 대역을 위해 설계된 여러 MDE와 SDE 네트워크에서에서 학습하여 검증하였습니다. 회귀, 분류부터 시작해서 최신 트랜스포머 기반의 MDE 네트워크(DORN, AdaBins, NeWCRF)와 3D cost volume 및 4D cost volume 기반의 SDE 네트워크(AANet, GwcNet, ACVNet)를 사용하였습니다.
5.2. Depth Estimation from Thrmal Images
Monocular Detph Estimation
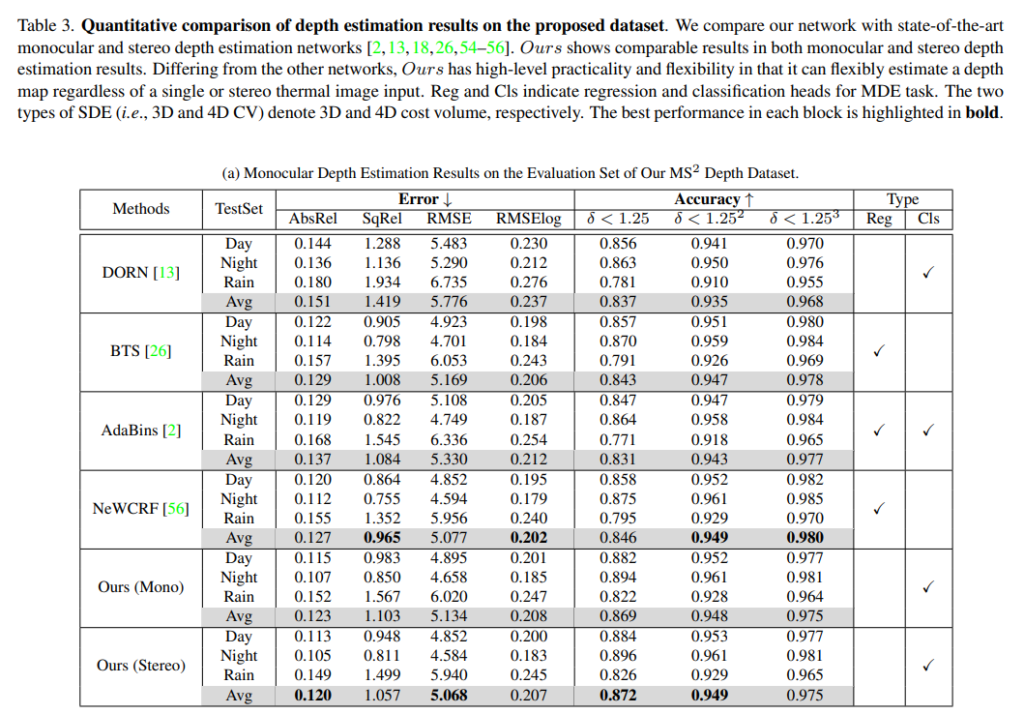
MDE 네트워크의 성능은 일반적으로 열화상 스펙트럼 영역에서 유지되는 경향을 보이면서 KITTI depth 벤치마크에서와 유사한 결과를 보이고 있습니다. depth map 예측을 위해서 regression head를 사용하는 MDE 네트워크(BTS, NeWCRF)는 정확한 depth 값을 regression함으로써 classification head를 사용하는 방식에 비해 비교적 높은 성능을 보이고 있습니다. 본 논문에서 제안한 연결 네트워크는 일반적으로 Accuracy에서도 높은 성능을 보이며 일부 Error를 측정하는 지표에서도 낮은 error를 보이며 최신 MDE 방법과 유사한 결과를 보여주고 있습니다. 이러한 결과는 depth를 예측하기 위한 head와 loss fuction의 차이에서 비롯된다고 분석하고 있습니다. 모든 MDE 네트워크는 정확한 depth를 제공하기 위해 GT depth map을 사용하는데요, 본 논문의 네트워크는 discreted disparity map으로 학습하게 됩니다. 그러나 통합 구조로 인한 이미지에 대한 추가적인 정보를 얻을 수 있기 때문에 성능 차이를 좁힐 수 있었다고 합니다.
Stereo Depth Estimation
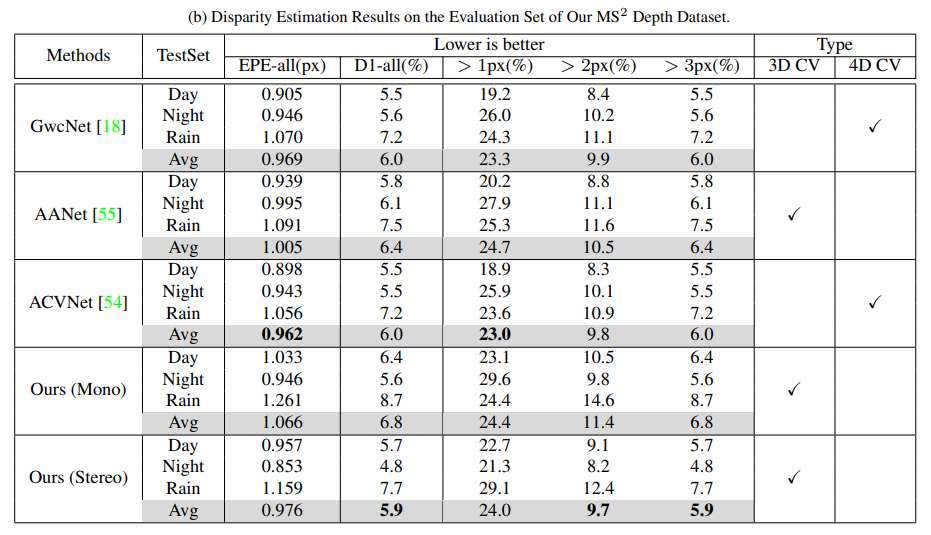
다음은 stetero depth estimation에 대한 실험 결과로 일반적으로 3D 컨볼루션 레이어와 4D cost volume을 활용하는 방법(GwcNet과 ACVNet)에서 3D cost volume을 사용하는(AANet과 본 논문의 방법론)보다 정밀한 depth 예측 결과를 보여주고 있습니다. 그러나 왼쪽-오른쪽 이미지 쌍에 대한 제약 사항이 존재하여 네트워크의 flexibility가 낮다는 단점이 존재합니다. 그에 비해 본 논문의 네트워크는 monocular와 stereo depth estimation의 장점을 모두 사용할 수 있기 때문에 이미지 쌍에 대한 제약이 줄어들어 depth estimation에 단일 네트워크를 활용함으로써 높은 실용성과 flexibility을 보여주고 있습니다. 또한 4D cost volume 기반의 방법론과 유사한 성능을 제공함으로써 통합된 네트워크를 통해서 stereo depth estimation을 처리할 수 있는 가능성을 확인할 수 있습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
monocular와 stereo depth estimation을 연결하여 하나의 통합적인 구조를 제안하였다고 하는데, 이 구조는 그럼 monocular로 입력이 들어올 때와 stereo로 입력이 들어올 때를 나누어 유동적으로 사용이 가능한것인가요 ? 아니면 어떤 특정한 구조의 입력이 동일하게 들어오고 하나의 픽스된 통합 구조를 사용해야 하는 것인가요??
그리고 제안된 depth estimation 구조를 Figure3에서도 그렇고 thermal image에 초점을 맞추어서 설명을 해주고 있는데 그렇다면 실험에서는 취득한 MS2 데이터셋에서 stereo thermal image만을 입력 데이터로 하여 진행한 것인가요 ? 만약 맞다면 MS2의 강점은 많은 센서를 stereo 셋으로 구성되어 있다는 점인데 혹시 다른 센서로 취득한 데이터셋에 대한 실험을 진행한 것은 없었는지 궁금합니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
먼저 첫번째 질문에 대한 답변으로는, 유동적으로 통합 구조를 사용할 수 있다고 말씀드릴 수 있습니다.
본문에서 언급된 바와 같이 pair한 쌍이 주어지면 cost volume이 이미지 쌍에 대해서 각각 추가되며, 하나의 이미지만 사용된다면 cost volume을 0으로 채워서 구성하게 됩니다.
두번째로는 실험에서 depth estimation을 진행한 것은 thermal 이미지에 대해서만 진행한 것이 맞습니다. 아쉽게도 다른 센서로 취득한 영상에 대한 실험을 진행하지는 않았네요 . .
안녕하세요. 손건화 연구원님.
새해 첫 X-REVIEW 귀하네요…
정말 매우매우 간단한 질문이 두 가지 있는데, 혹시 cost volume이 무엇인지 간단하게 설명해주실 수 있나요? 제가 이 분야를 몰라서인지 딱 이해가 되지 않네요…
그리고 제안한 모델의 목적이 제가 하고 싶은 멀티모달 데이터 중 특정 모달 정보만 주어질 때 강건한 모델을 만드는 것과 비슷하여 흥미로운데, 좌우 이미지 중 하나의 이미지가 들어오지 않는 상황은 말 그대로 한 쪽 이미지의 모든 픽셀이 0일 때만 인가요? 혹은 두 이미지 중 하나가 잘못된 입력임을 판별하는 기준이 있나요?
감사합니다!
안녕하세요, 손건화 연구원님.
좋은 연구를 공유해 주셔서 감사합니다!
논문에서 MS2 데이터셋이 낮, 밤, 날씨 변화 등 다양한 환경을 포함하고 있다고 설명해 주셨는데,
혹시 낮 환경에서 RGB 기반 Depth Estimation 모델과 Thermal 기반 모델을 직접 비교한 실험 결과가 포함되어 있을까요?
논문을 살펴보니, Thermal 기반 Depth Estimation이 야간 및 악천후 환경에서는 강점을 보이는 것으로 확인되었는데,
낮 환경에서 RGB 모델과 비교했을 때 성능 차이가 어떻게 나타나는지 궁금합니다.
혹시 관련된 실험이 진행되지 않았다면, 낮 환경에서도 Thermal Depth Estimation이 RGB 모델과 동등한 성능을 보일 가능성이 있는지, 또는 특정한 상황에서만 유리할 것인지 궁금합니다.
감사합니다!