이번 X-Review에 제가 소개해드릴 논문은 2021년도 CVPR에 게재된 “CoLA: Weakly-Supervised Temporal Action Localization with Snippet Contrastive Learning” (이하 CoLA)라는 논문입니다.
ETRI 과제에서 현재 CoLA 방법론을 기반으로 하고 있기에 사실 소개해드린다기보단 스스로 조금 더 꼼꼼하게 정리하고 넘어가기 위해 작성합니다. 이 논문은 일전에 임근택, 조원 연구원님께서 잘 작성해주신 리뷰가 있으니 함께 참고하셔도 좋을 것 같습니다.

먼저 논문의 제목을 보면 video-level label만을 이용해 action 구간과 클래스를 찾는 task (WTAL)를 수행할건데, 이를 snippet 단위의 contrastive learning을 통해 하겠구나, 정도를 예상해 볼 수 있습니다.
Contrastive learning을 사용한다면 다들 ‘positive/negative snippet pair를 어떻게 만들어줄까’에 대해 궁금하실텐데, 그런 부분들을 핵심으로 두고 논문을 살펴보도록 하겠습니다.
1. Introduction
기본적으로 해당 task를 수행할 때 여러 frame을 묶은 하나의 clip 또는 snippet 단위로 처리한다는 것을 다들 아실겁니다. 저자는 이 때 WTAL에서는 action의 시간 구간에 대한 annotation (frame-level supervision)이 없기 때문에 ‘single snippet cheating issue’가 발생한다고 합니다. cheating이라는 것이 단순히 이게 action인지 아닌지 헷갈려 하는 상황을 의미한다고 이해하시면 됩니다.
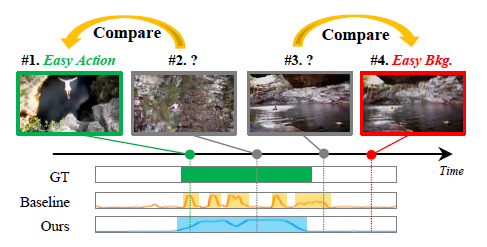
위 그림에서 THUMOS14 dataset의 CliffDiving 클래스에 해당하는 비디오를 예시로 ‘single snippet cheating issue’를 설명 하고 있습니다. Baseline의 action score를 보시면 GT와 비교했을 때 제대로 찾아내지 못한 snippet들이 존재합니다. #2 snippet은 아예 다른 클래스로 분류된 것이고, #3 snippet의 경우 분류는 잘 되었지만 잘못 localization된 것을 볼 수 있습니다.
저자는 이러한 문제를 해결하기 위해 #1과 #4인 easy action/background에 주목합니다. 같은 맥락으로 #2와 #3을 각각 hard action/background라고 해석할 수 있겠네요. Contrastive learning을 통해 #2와 #1은 다른 각도에서 본 것일 뿐 같은 장면에 해당함을 학습시킬 수 있고, #3도 #4를 보여줌으로써 같은 background에 해당함을 학습시킬 수 있을 것입니다.
Hard action/background에 상대적으로 찾기 쉬운 Easy action/background의 문맥적 정보를 더해줌으로써 hard snippet들의 구별력을 높이겠다는 것이 CoLA의 기본적인 아이디어에 해당합니다.
하지만 생각해보면 학습 과정에서 action의 시간 구간에 대한 annotation이 없기에 hard snippet들을 찾아낼 특정 모델링이 필요해 보입니다. 그래서 저자는 ‘hard snippet은 action의 경계에 존재한다’는 단순한 직관을 도입해 ‘boundary-aware Hard Snippet Mining algorithm을 제안합니다.
기존 연구들에도 action completeness를 지적하며 모델이 예측해낸 action의 시작과 끝(경계) 부분을 좀 더 보완해주는 방법론들이 있었는데, 이와 비슷한 맥락이라고 생각해 볼 수도 있습니다.
Introduction에서는 기본적인 아이디어만 살펴보고, 자세한 방법론은 Method에서 다루도록 하겠습니다.
논문의 contribution은 2가지로 정리할 수 있습니다.
- Easy-Hard snippet들을 찾아 그들의 contrastive representation을 학습하는 WTAL에서의 새로운 방식 제안: hard snippet들의 구별력을 뚜렷하게 만들어 준다.
- 논문에서 제안한 Hard Snippet Mining algorithm은 잠재적 hard snippet인 action의 경계 부분 snippet들을 찾아냄으로써 시간적 annotation이 없는 상황 속 효율적인 방식이다.
2. Method
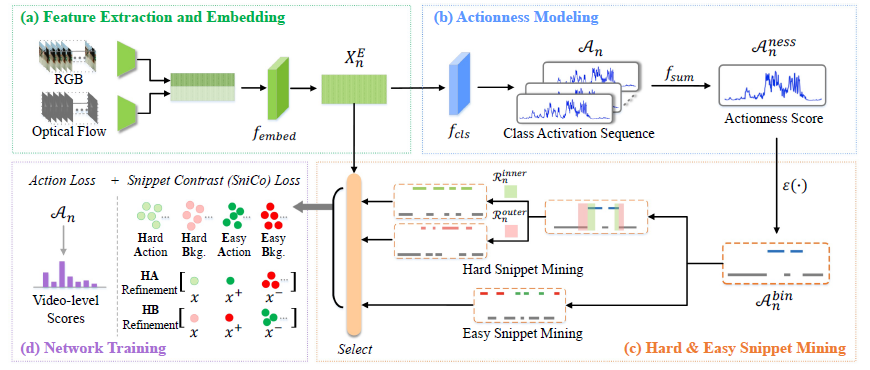
CoLA의 학습 과정은 총 4단계로 나눠 볼 수 있습니다.
- Feature Extraction and Embedding
- Actionness Modeling
- Hard & Easy Snippet Mining
- Network Training
1단계부터 차례대로 보겠습니다.
2.1 Feature Extraction and Embedding
비디오를 학습에 사용하기 위해 feature로 embedding 해주는 단계입니다.
Raw untrimmed video를 겹치지 않는 16 frame으로 나누어 각 비디오마다 L개의 snippet을 만들어 내고, 그 중 T개의 snippet을 샘플링합니다. 이후 T개의 snippet들을 사전 학습된 backbone network(I3D)에 태워 RGB feature를 추출하고, TVL1 알고리즘을 통해 optical flow feature도 추출합니다.
이후 두 feature를 concat하고 1D Conv, ReLU 연산을 적용해 하나의 비디오에 대한 embedded feature X_{n}^{E} \in{} \mathbb{R}^{T \times{} 2d}를 얻습니다. n은 전체 N개 중 n번째 비디오, 2d는 d차원의 RGB feature, d차원의 flow feature가 concat됨으로써 얻은 형태에 해당합니다.
2.2 Actionness Modeling
우선 Actionness라는 것은 어떤 action 클래스이든 관계 없이 그냥 action일 확률을 의미합니다. Actionness를 찾는 이유는 이후 방법론의 핵심인 hard action/background를 찾는 마스크를 만들어주기 위함입니다.
그렇다면 앞에서 얻은 비디오의 feature X_{n}^{E}에서 actionness를 어떻게 추출하는지 보겠습니다.
이전 리뷰나 세미나 때에도 계속 CAS에 대해 설명드렸기 때문에 다들 아실텐데요, 마찬가지로 X_{n}^{E}를 1D Conv에 태운 후 ReLU 연산을 거쳐 n번째 비디오에 대한 CAS \mathcal{A}_{n} \in{} \mathbb{R}^{T \times{} C}를 얻어냅니다.
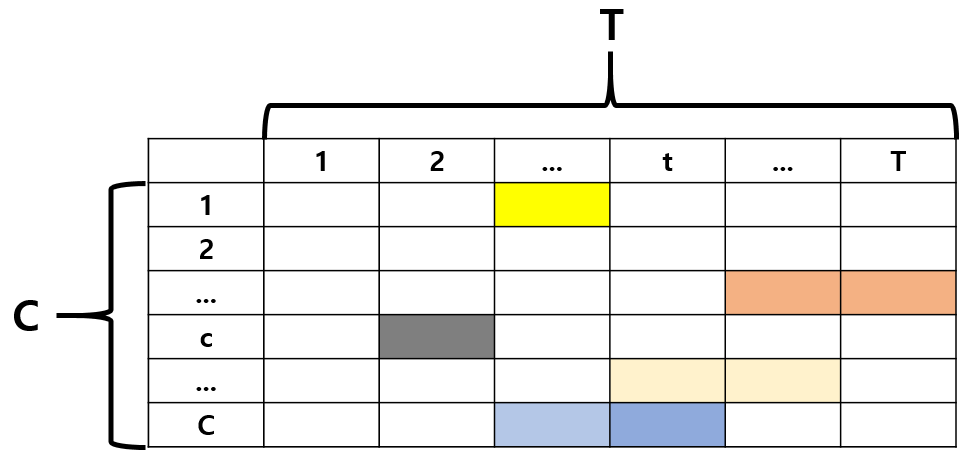
CAS \mathcal{A}_{n}은 위 그림과 같은 형태에 해당할 것이고, CAS의 특정 원소 \mathcal{A}_{n}(c, t)는 전체 T개의 snippet 중 t번째 snippet이 전체 C개의 클래스 중 c번째 클래스 action을 포함할 확률을 의미합니다.
CAS로부터 Actionness score \mathcal{A}_{n}^{ness}를 얻는 것은 어렵지 않습니다. 단순히 각 snippet을 기준으로 모든 클래스 점수를 더하고 sigmoid 연산을 취해주면 됩니다. 이를 통해 \mathcal{A}_{n}^{ness} \in{} \mathbb{R}^{T}를 얻을 수 있습니다.
\mathcal{A}_{n}^{ness} = Sigmoid(f_{sum}(\mathcal{A}_{n}))
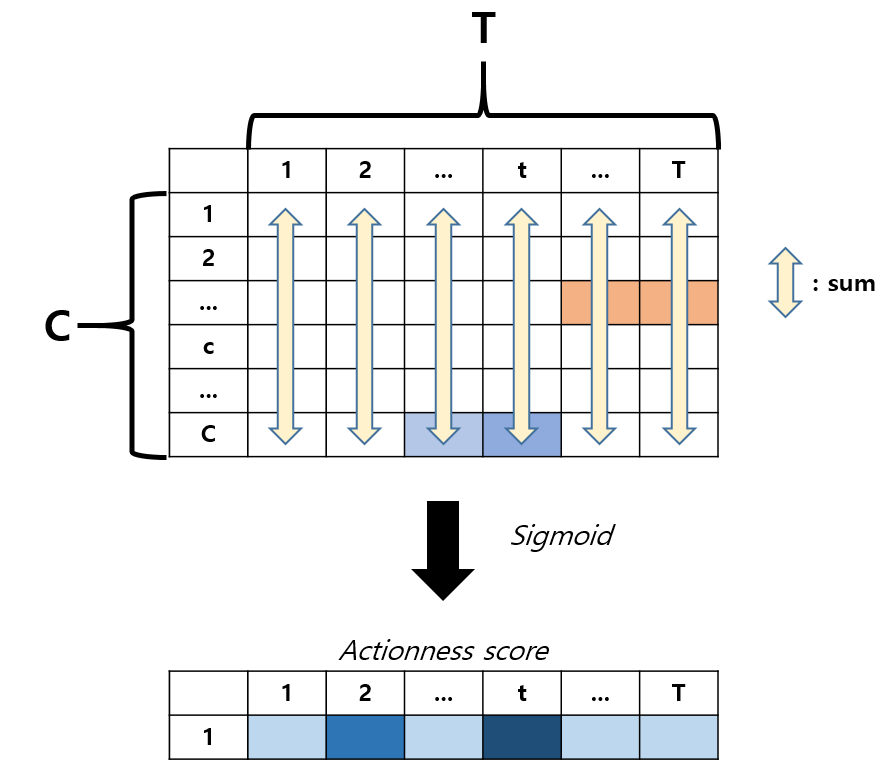
여기까지 하면 각 snippet이 클래스에 관계 없이 action에 해당할 확률이 얼마인지 알 수 있습니다.
2.3 Hard, Easy Snippet Mining
Action의 시간 구간 annotation이 없는 상황 속에서, 효율적인 Contrastive learning pair를 생성하기 위해 저자는 어렵고 쉬운 쌍을 어떻게 생성해내는지 살펴보겠습니다.
2.3.1 Hard Snippet Mining
맨 처음에 첨부해드린 그림에서도 알 수 있듯, 비디오에서 action 구간을 찾을 때 가장 혼동되는 부분은 모델이 찾은 action의 경계 부분에 해당합니다.
모델이 찾은 action의 중심부에 속하는 snippet은 상대적으로 확고하게 action에 대한 representation을 가지고 있다고 볼 수 있고, 반대로 모델이 찾은 action과 멀리 떨어진 background에 해당하는 snippet은 확고하게 background에 대한 representation을 갖고 있다고 볼 수 있습니다.
정리하자면 저자는 모델이 예측해낸 action의 경계 부분에서 hard action/background를 모두 모델링합니다. 이러한 모델링을 위해 dilation과 erosion, 즉 침식과 팽창 기법을 사용합니다. 무엇에 대해 침식과 팽창을 적용하는지 먼저 설명드리겠습니다.
먼저 2.2에서 얻은 Actionness score \mathcal{A}_{n}^{ness}에 thresholding을 통해 binary mask \mathcal{A}_{n}^{bin}을 만들어줍니다.
\mathcal{A}_{n}^{bin} = \epsilon{}(\mathcal{A}_{n}^{ness} - \theta{}_{b})
여기서 \epsilon{}은 heaviside step function이고 \theta{}_b는 threshold 값에 해당합니다. 그러니까 특정 snippet의 actionness score가 \theta{}_b보다 크면 1, 작으면 0으로 하여 \mathcal{A}_{n}^{bin}을 생성합니다.

이렇게 얻은 \mathcal{A}_{n}^{bin} 중 1로 지정된 action 구간에 대해 침식과 팽창을 적용하여 hard action/background snippet을 찾아냅니다.
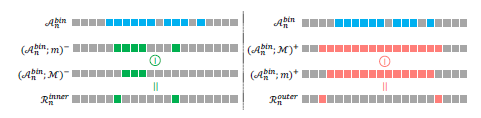
그림에서 왼쪽은 hard action, 오른쪽은 hard background를 찾는 과정입니다.
왼쪽 부분인 hard action을 찾는 과정부터 설명드리겠습니다. 먼저 \mathcal{A}_{n}^{bin}에 존재하는 하나의 action 구간에 대해 작은 mask m과 큰 mask \mathcal{M}을 만들어냅니다.
- (\mathcal{A}_{n}^{bin} ; m)^{-}: 작은 mask m으로 침식(-)
- (\mathcal{A}_{n}^{bin} ; \mathcal{M})^{-}: 큰 mask \mathcal{M}으로 침식(-)
- 위 두 구간의 차이를 \mathcal{R}_{n}^{inner}으로 지정
다시 그림과 함께 정리하자면, action에 대해 적게 침식시킨 구간에서 많이 침식시킨 구간을 빼면 기존 action의 내부이면서 경계인 부분이 남게 되고 이를 \mathcal{R}_{n}^{inner}으로 설정하여 학습에 사용합니다.
오른쪽 hard background를 찾는 과정은 반대로 팽창을 사용합니다. 마찬가지로 작은 mask m과 큰 mask \mathcal{M}를 팽창에 적용합니다.
- (\mathcal{A}_{n}^{bin} ; \mathcal{M})^{+}: 큰 mask \mathcal{M}으로 팽창(+)
- (\mathcal{A}_{n}^{bin} ; m)^{+}: 작은 mask m으로 팽창(+)
- 위 두 구간의 차이를 \mathcal{R}_{n}^{outer}으로 지정
똑같이 정리해보자면, 기존 action 구간에 대해 더 많이 팽창시킨 구간에서 더 적게 팽창시킨 구간을 빼면 기존 action 구간의 외부이면서 경계 부분에 해당하는 부분을 얻을 수 있고 이를 \mathcal{R}_{n}^{outer}으로 지정합니다.
얻은 \mathcal{R}_{n}^{inner}, \mathcal{R}_{n}^{outer} 구간에 해당하는 snippet을 모두 사용하는 것은 아니고, 이 중 각각 k^{hard}개의 snippet을 추출해낸 X_{n}^{HA}, X_{n}^{HB}학습에 사용합니다. HA, HB는 Hard Action, Hard Background를 의미합니다.
경계 부분에서 hard action과 background를 찾을 때, 모델이 찾은 action을 어느정도 신뢰하여 내부 쪽 경계는 hard action, 외부 쪽 경계는 hard background로 지정해주겠다는 아이디어라고 볼 수 있습니다.
2.3.2 Easy Snippet Mining
Hard snippet을 찾는 과정에 비해 Easy snippet을 찾는 과정은 매우 간단합니다.
앞서 얻은 Actionness score \mathcal{A}_{n}^{ness}에서 score가 높은 순서대로 k^{easy}개의 snippet은 Easy Action으로, score가 낮은 순서대로 k^{easy}개의 snippet은 Easy background로 지정하여 학습에 사용합니다.
만약 Easy action 또는 background로 찾은 snippet이 HA, HB에 해당한다면 EA, EB에서 제외하고 HA, HB로 사용합니다. k^{easy}, k^{hard}는 지정해주는 하이퍼파라미터에 해당합니다.
2.4 Network Training
CoLA는 2가지 loss를 통해 학습합니다.
\mathcal{L}_{total} = \mathcal{L}_{a} + \lambda{}\mathcal{L}_{s}
- \mathcal{L}_{a}
\mathcal{L}_{a}는 Action loss를 의미하고, 대부분의 WTAL task에서 사용됩니다.
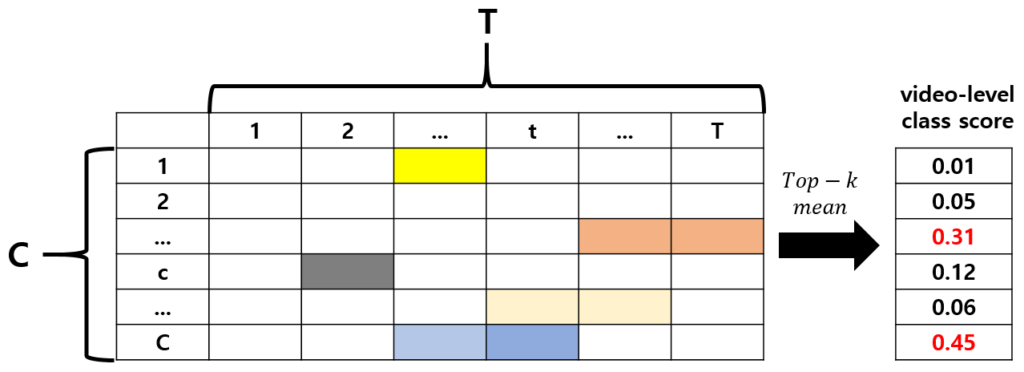
CAS에서 클래스 별로 k^{easy}개의 snippet score를 가져와 평균 내고, softmax를 통해 한 비디오의 클래스 별 score를 얻습니다. 이후 우리가 알고 있는 video-level label과의 Cross Entropy Loss를 통해 비디오에 존재하는 클래스를 학습합니다.
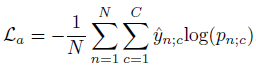
- \mathcal{L}_{s} – Snippet Contrastive (SniCo) Loss
앞서 구한 Hard Action, Hard Background, Easy Action, Easy Background (HA, HB, EA, EB)의 contrastive representation을 학습하는 과정이 필요합니다.
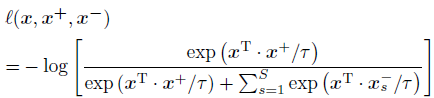
Contrastive를 위해 기본적으로 InfoNCE loss를 적용하고, 이를 HA에 대해 한 번, HB에 대해 한 번 적용하여 최종 \mathcal{L}_{s}를 구성합니다.
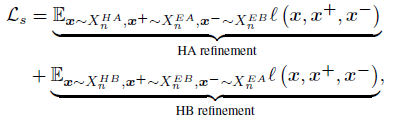
\mathcal{L}_{s}의 학습 방향에 대해 살펴보겠습니다.
먼저 HA refinement 부분에서는 HA의 feature representation이 EA와 가까워지고, EB와 멀어지는 형태로 구성되어 있고, HB refinement 부분에서는 HB의 feature representation이 EB와 가까워지고, EA와는 멀어지도록 되어있습니다. 이러한 학습을 통해 모델이 혼동할 수 있는 Hard snippet들이 자명한 Easy snippet들의 representation을 따라감으로써 조금 도 구별력을 갖추게 된다고 볼 수 있습니다.
2.5 Inference
Inference 단계에서 video feature를 임베딩 하는 convolution layer와 CAS를 뽑아내는 convolution layer는 CoLA의 목적에 맞게 hard snippet에 대해서도 구별력을 갖춘 feature를 만들어낼 수 있도록 잘 학습되었다고 가정합니다.
하나의 비디오로부터 CAS를 만들어낸 뒤 top-k mean pooling을 통해 localization 할 action을 찾아냅니다. 이후 CAS로 돌아가 해당 클래스들의 snippet 별 점수를 thresholding 하고, 연속된 구간을 proposal로 만들어냅니다. 마지막엔 NMS를 적용하여 중복된 proposal을 제거한 뒤 최종 proposal을 만들게 됩니다.
3. Experiments
Comparisons with State-of-the-Arts
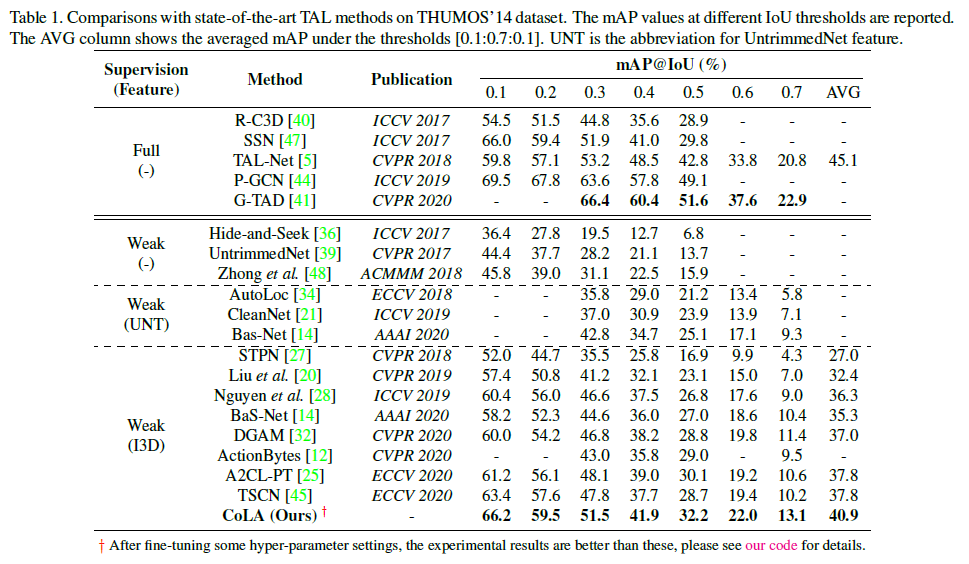
THUMOS 데이터셋에 대한 벤치마크 성능입니다. tIoU 0.1-0.7 평균 mAP를 봤을 때 20년도에 나온 방법론들보다 3% 이상의 성능 향상을 보인 것을 확인할 수 있습니다.
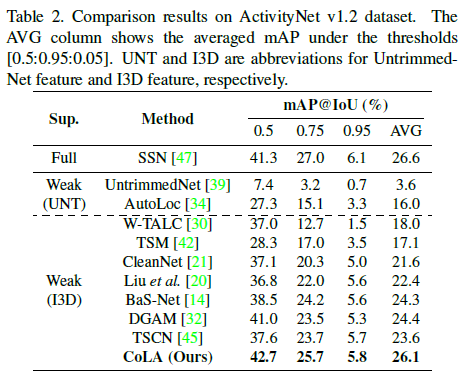
ActivityNet dataset에 대한 성능도 그 당시 SOTA 방법론들 대비 2% 이상 향상된 것을 볼 수 있습니다.
Ablation Studies
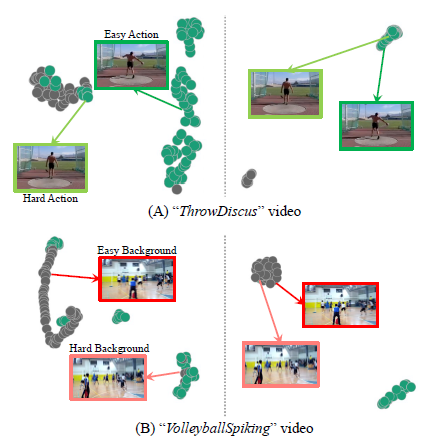
위 그림은 Action과 Background의 feature representation을 시각화 한 것입니다. 가운데 점선을 기준으로 왼쪽은 baseline, 오른쪽은 CoLA에 해당합니다. 물론 feature representation이 뚜렷하게 구분되는 클래스를 보여준 것이겠지만 Baseline 방법론보다 확실히 Hard snippet들의 representation이 혼동되지 않고 서로 잘 구별되는 것을 볼 수 있습니다.

다음은 SniCo loss에 대한 실험입니다. 두 term 중 하나 씩을 제외하고 학습하였을 때의 성능인데, HA에 대한 refinement만 진행한 경우가 성능이 더 낮은 것으로 보아 HB refinement가 HA refinement보다 성능 향상에 좀 더 기여했다고 볼 수 있겠네요. 저자도 이에 대한 추가적 분석은 따로 하고 있지 않았습니다.
Qualitative Results
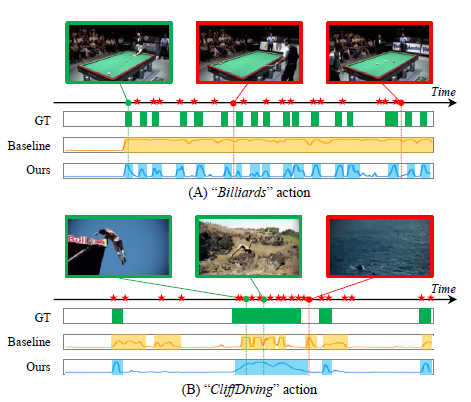
마지막으로 정성적 결과입니다. 빨간 별은 CoLA 모델이 Hard snippet이라고 판단한 구간입니다. Billiards 클래스에 대해서는 GT 구간이 굉장히 띄엄띄엄 존재하여 Baseline 모델은 전체 구간에 대해 action이라고 판단하였지만, 그와 다르게 CoLA는 Hard snippet을 잘 찾아 이에 대한 구별력을 갖춤으로써 신기할만큼 정확히 맞추는 것을 볼 수 있습니다.
아래 CliffDiving 클래스에서는 반대로 하나의 action 구간을 Baseline은 띄엄띄엄 예측하고 있지만, CoLA는 전체 구간을 잘 예측하고 있는 것을 볼 수 있습니다. 또한 다이빙 하는 action을 다른 각도에서 본 것을 baseline은 제대로 예측하지 못하지만, CoLA는 한 비디오 내에서 contextual한 정보를 학습하였기 때문에 이에 대해서도 잘 대응하는 것을 볼 수 있습니다.
이상으로 리뷰 마치겠습니다.