
이번에 리뷰할 논문의 주제는 뜬금없는 Segmentation입니다. 사실 Transformer 백본 설명할 때도 Segmentation에 대한 결과를 보였기 때문에 그렇게 뜬금없지는 않지만, 해당 논문의 contribution은 백본이 아닌 모듈에 대한 설명으로 어떠한 백본에도 사용할 수 있을 듯합니다.
Introduction
Segmentation은 픽셀 레벨로 물체를 구분하는 Dense-level prediction에 해당합니다. 이러한 Segmentation 모델들은 대부분 Encoder-Decoder 형태를 가지고 있습니다. RGB 영상을 Encoder에 넣으면 Encoder에서는 점점 down sampling된 feature map이 생성될 것이고, 이를 다시 Decoder에 태워 원본 해상도와 동일해지는 Segmentation mask를 생성합니다.
하지만 이때 Encoder 마지막 단에 생성된 feature map만으로 원본 해상도의 Output을 생성하기에는 쉽지가 않습니다. 아시다시피 Encoder 과정을 진행하면서 Feature map이 크게 Down sampling되기 때문에 전체적인 Global 정보만을 가지고 있고, 세부적인 detail한 정보들은 잃어버리기 때문이죠.
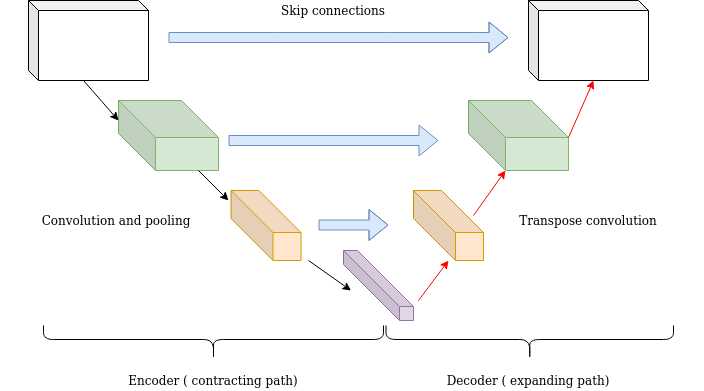
그래서 우리가 잘 알고 있는 Long Skip Connection을 통해 Decoder 각 스테이지마다 Encoder feature map을 더해주거나 Concatenate 해주어 최종적인 아웃풋을 만들 때 디테일한 정보들을 잘 보충할 수 있도록 해줍니다.
여기서 저자는 한가지 의문점을 가집니다. 과연 Encoder의 Feature map과 Decoder의 Feature map이 과연 alignment가 정확히 일치하는가에 대해서 말이죠. Segmentation, Image Translation, Depth Estimation 등 다양한 Dense-level prediction을 해본 사람들이라면 네트워크를 타고 나온 최종 output 중 object의 boundary가 깔끔하게 생성되지 못하는 경우를 한번쯤은 보셨을 겁니다.
다양한 테스크에서(제가볼 땐 Segmentation이 주로) 이러한 object boundary를 잘 잡고 보다 샤프한 결과물을 얻기 위해서 노력중이죠. 저자는 위와 같은 문제가 왜 발생했는지에 대해 보다 근본적인 원인을 찾기를 바랬고 그래서 디테일한 정보를 준다는 명목하에 사용했던 Long Skip Connection에 문제가 있는 것이 아닐까? 라는 생각을 합니다.
그리하여 저자는 Encoder Feature와 Decoder Feature의 mis-alignment가 있다고 판단하여 이를 해결하고자 Feature alignment module을 제안합니다. 또한 부수적으로 feature selection module을 통해 lower-level feature의 풍부한 공간적 정보를 강조한다고 하네요.
Method
그림2는 기존의 Feature Pyramid Network(FPN)과 저자가 제안하는 Feature aligned Pyramid Network의 차이를 보여줍니다.
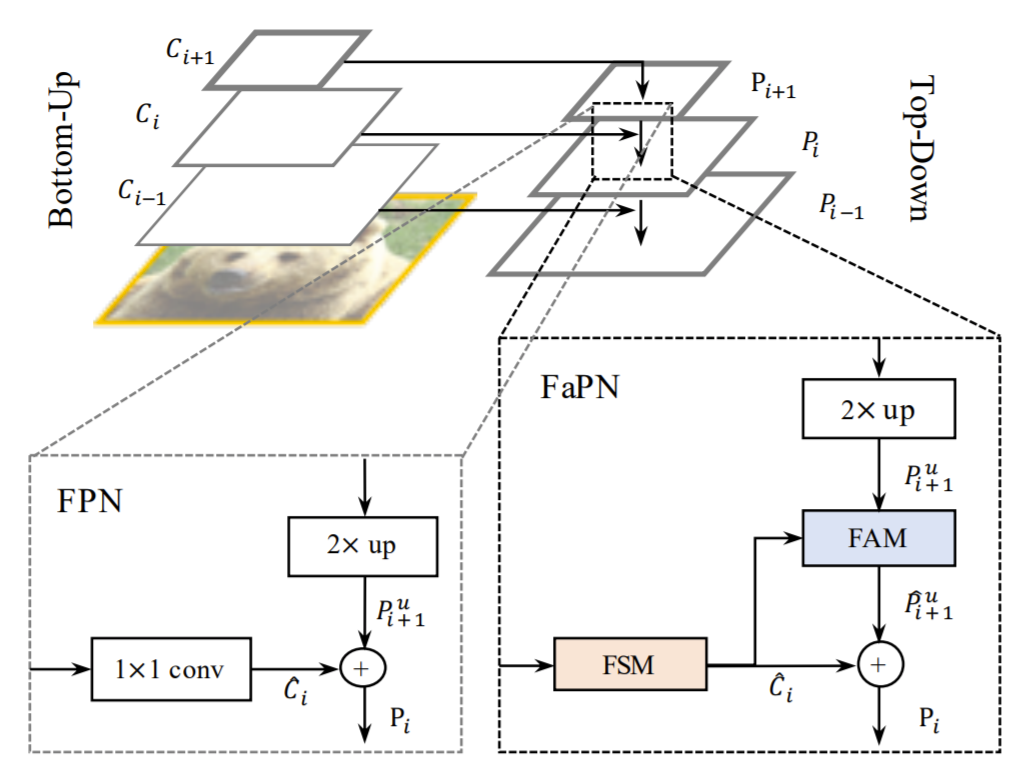
FPN은 아주 단순합니다. Encoder에서 추출한 Feature map을 1×1 컨볼루션을 태워서 up-sampling한 decoder feature와 element-wise sum을 진행해주는 것이죠. 반면 저자가 제안하는 FaPN은 Encoder feature의 경우 FSM 모듈을 한번 통과하게 되며 해당 결과물이 Decoder Feature와 함께 FAM 모듈을 통과한 후 element-wise sum을 수행하게 됩니다.
보다 자세한 설명은 아래에서 진행하겠습니다.
Feature Alignment Module
먼저 저자는 위에서도 Encoder 내부에서 반복되는 down sampling 연산으로 인해 top-down feature P^{u}_{i}와 bottom-up feature C_{i-1} 사이에 spatial misalignment가 발생할 것이라고 말합니다.
그래서 단순히 두 feature를 fusion할 때 element-wise sum 또는 channel-wise concatenation을 하는 것은 output map 내에서의 object boundary에 좋지 못한 영향을 준다는 것이죠.
그러므로 저자는 먼저 spatial location information이 2D feature map으로 표현될 때 각각의 offset 값들은 P^{u}_{i}, \hat{C}_{i-1}가 가지는 각 pixel들 사이에 2D 공간상 거리차이로 해석하였으며 feature alignment를 다음과 같은 수식으로 표현하였습니다.
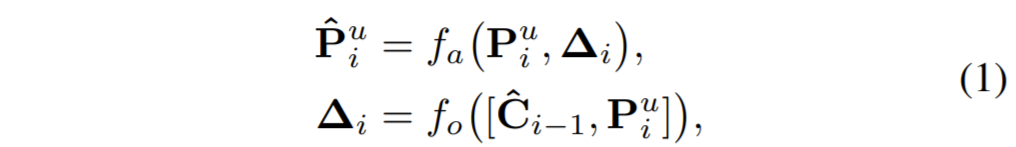
여기서 [ ] 기호는 concatenation을 의미하며 f_{o}, f_{a}는 각각 spatial difference를 학습하는offset(\Delta)과 학습된 offset을 통해 feature를 align하는 함수를 의미합니다.
이러한 f_{a}, f_{o}를 구현하기 위해서 저자는 그림3과 같이 deformable convolution을 사용했다고 합니다.
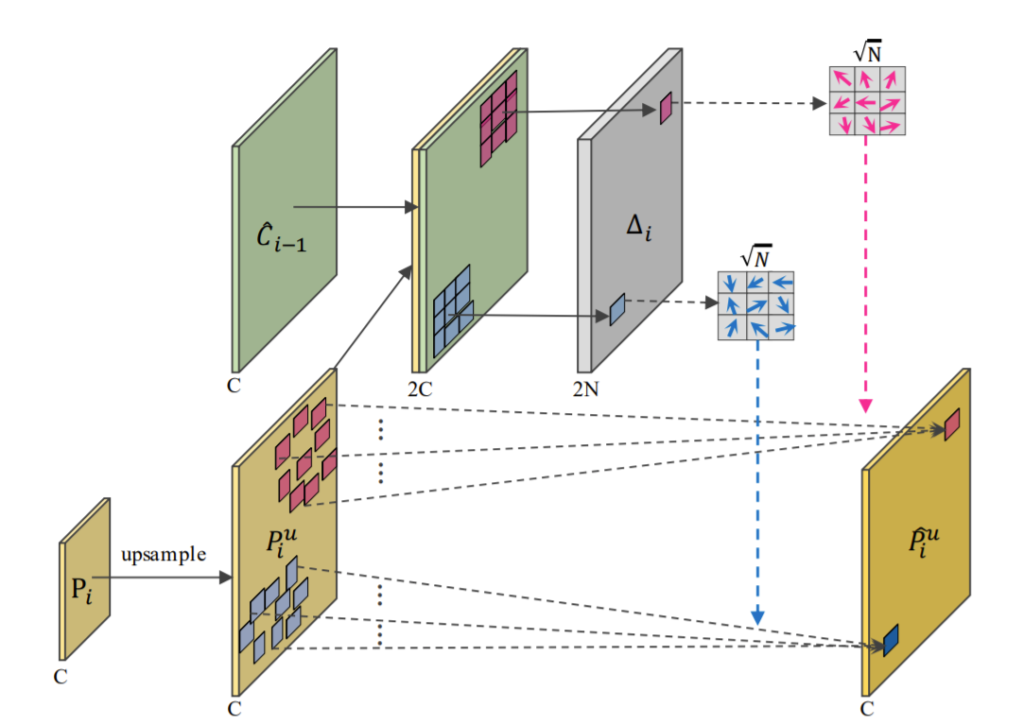
먼저 입력 feature map c_{i}와 k x k 컨볼루션이 있을 때 컨볼루션 kernel 이후에 어떠한 위치 \hat{x_{p}}에 있는 output feature를 아래와 같이 구할 수 있습니다. ( \hat{x_{p}}은 (0,0), (1,0), (0,1), … ( H_{i} - 1, W_{i} -1)를 의미합니다.
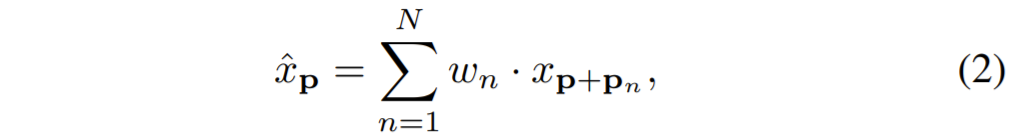
P^{u}_{i}에 deformable convolution을 적용한다음 \hat{C}_{i-1}, P^{u}_{i}를 concatenation할 때 (즉 offset fields \Delta_{i} = f_{o}([\hat{C}_{i-1}, P^{u}_{i}])인 상황) deformable convolution은 convolutional sample location에 offset을 곧바로 적용할 수 있다고 합니다.
흠 제가 쓰고도 무슨 말인지 모르겠다시피 설명을 했는데… 논문에서도 이런식으로 설명하고 그냥 끝을 내버려서 deformable convolution에 대해 무지하여 이해를 못했는가 싶습니다.
Feature Selection Module
다음으로는 Feature Selection Module에 대한 설명입니다. 위에 FAM 모듈에서는 encoder의 feature와 decoder의 feature를 align하는 역할이라면 해당 모듈의 역할은 결국 encoder의 feature map을 단순히 통째로 전달하는 것이 아니라 중요한 정보들만 추려서 전달한다는 것입니다.
먼저 Feature Selection Module은 다음과 같은 과정을 거칩니다.
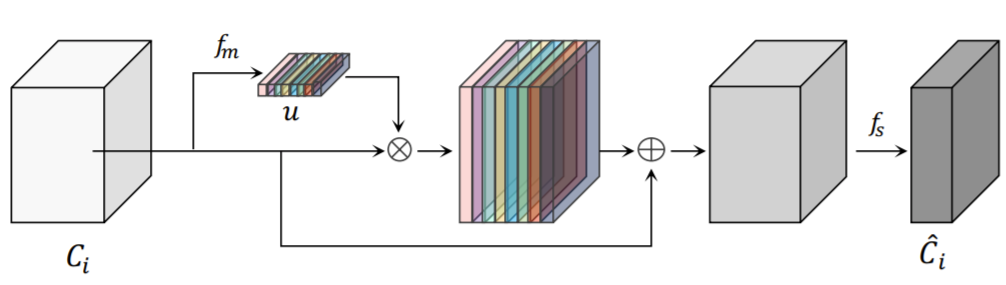
먼저 각 입력 feature map c_{i}의 global information z_{i}는 Global Average Pooling(GAP) 연산을 통해 계산됩니다. 반면에 1 x 1 컨볼루션 레이어와 sigmoid로 이루어진 feature importance modeling layer f_{m}은 각 feature map 중요도를 모델링하기 위한 중요도 벡터 u를 학습합니다.
다음으로 기존의 입력 feature map은 중요도 벡터와 스케일을 맞추는 작업(그림4에 element-wise product를 의미하는 듯하네요.) 후 다시 원래의 입력 feature map에 element-wise add를 수행하게 됩니다.
마지막으로 1×1 컨볼루션으로 이루어진 feature selection layer f_{s}를 통과하여 feature map의 채널을 줄임으로써 중요한 feature map만을 유지하고 그 외에 필요없는 feature map은 제거해버리게 됩니다.
위에 과정들을 수식으로 표현하면 다음과 같습니다.
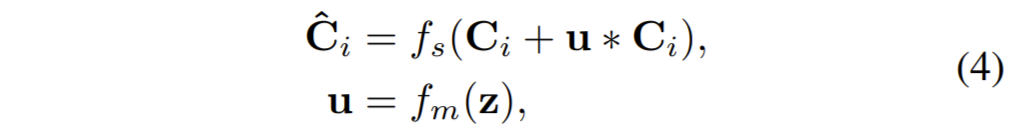
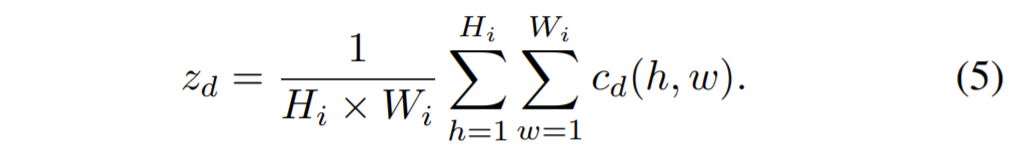
이러한 FSM 과정은 사실 2017년쯤?에 제안된 squeeze-and-excitation(SE)Net과 상당히 유사합니다. SeNet은 간단하게 설명하면 입력 feature map을 GAP 연산을 통해 1×1 vector로 squeeze해준 후 fc layer과 sigmoid를 거쳐 채널별 중요도를 계산합니다. 이렇게 구한 벡터를 다시 입력 feature map에 곱해줌으로써 재보정을 해주는 그런 방식입니다.
저자도 해당 SEnet에 영감을 얻어 위에 FSM 모듈을 제안했다고 합니다. 하지만 차이점에 대해서도 언급하는데 먼저 기존 SE module과 달리 자신들은 element-wise product 후에 다시 residual 연산을 수행한다는 점에서 구조적 차이가 존재한다고 합니다.
가게에서 사온 파스타에 파슬리 좀 얹었다고 자기가 만든 음식이 되나..? 싶을 정도로 별로 차이가 없지만서도 저자가 residual 구조를 강조하는 이유는 이러한 skip connection을 통해 특정 채널이 너무 중요도가 강조되거나 또는 너무 무시되는 현상들을 방지할 수 있다고 이야기합니다.
또한 SE는 encoder 내에서 feature extraction을 잘 하기 위한 방식으로 해당 모듈을 사용하지만, FSM은 encoder와 decoder의 feature map이 잘 합쳐지도록 할 때 사용되는 것으로 둘의 목적이 다르다 라는 식의 이야기를 하네요.
Experiments
저자는 Detection과 Segmentation에 대하여 결과를 리포팅합니다. Detection, instance and panoptic segmentation에 사용한 데이터 셋은 MS COCO 데이터셋이구요, semantic segmentation에 사용한 데이터 셋은 Cityscapes, COCO-Stuff-10K, ADE20K 입니다.
실험에 사용한 모델에 대해서도 간략하게 설명드리자면 ImageNet으로 사전학습된 ResNet을 encoder로 사용하고 기존에 FPN 구조에서 FPN 대신 자신들이 제안한 FaPN을 top-down pathway network로 사용했다고 합니다.
Ablation study
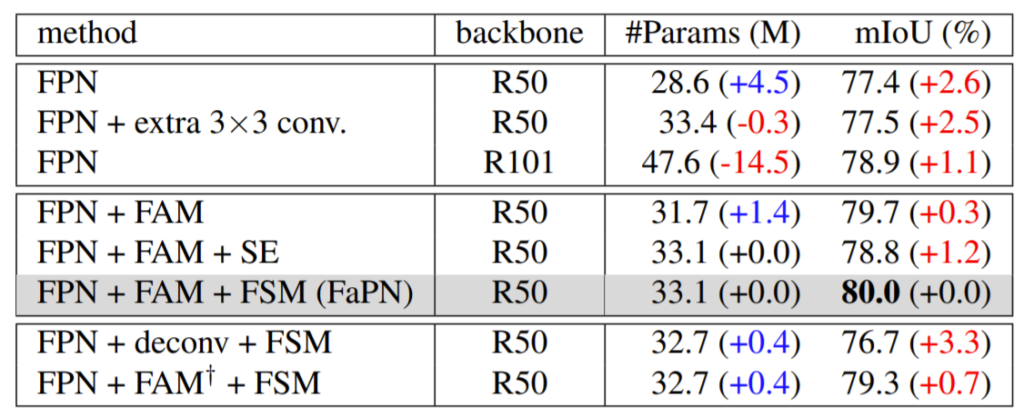
위에 표 1은 Cityscape에서의 semantic segmentation 결과를 FPN, FAM, FSM 각각을 적용했을 때의 ablation study입니다. 저기 십자가 표시는 feature fusion 이후에 FAM을 적용했을 때를 말하며 deconv는 upsample을 할 때 단순한 bi-linear interpolation이 아닌 Transposed Convolution을 의미합니다.
결과를 대충 보면 기존 FPN의 mIOU가 77.4%일 때 단순히 feature align을 수행하는 FAM을 추가하면 2.3% 성능 향상을 달성할 수 있습니다. 여기서 저자는 FSM 이전에 아마 SE를 먼저 베이스라인으로 적용한 것 같네요. SE 모듈을 통해 추가적인 성능 향상을 꽤했지만 오히려 성능은 78.8로 0.9정도 떨어졌습니다.
그래서 Residual을 추가한 FSM을 통해 80.0%의 최종적인 성능을 달성한 모습입니다. 흥미로운 점은 아래 deconvolution을 통한 upsampling은 오히려 FPN만 사용했을 때보다 성능을 더 감소시키네요. 이러한 학습가능한 up sampling 연산이 성능이 더 떨어진 이유에 대해 기존의 bi-linear interpolation과 달리 misalignment가 더 심해졌다고 볼 수 도 있을 것 같습니다.
또한 feature fusion 이후에 Feature align을 진행하는 것은 성능 향상은 있었지만 그래도 79.3%로 기존 80%보다는 줄어든 모습입니다. 이를 통해 저자는 feature fusion 전에 먼저 align을 맞추는 작업이 선행되어야 한다는 것을 강조하였습니다.(아니 근데 feature fusion 이후에 feature align은 어떻게 맞춘거지..?)
Boundary Prediction Analysis
다음은 저자가 매우 강조?하는 output 영상에서 object boundary가 샤프하게 나타났는지를 실험한 내용입니다.
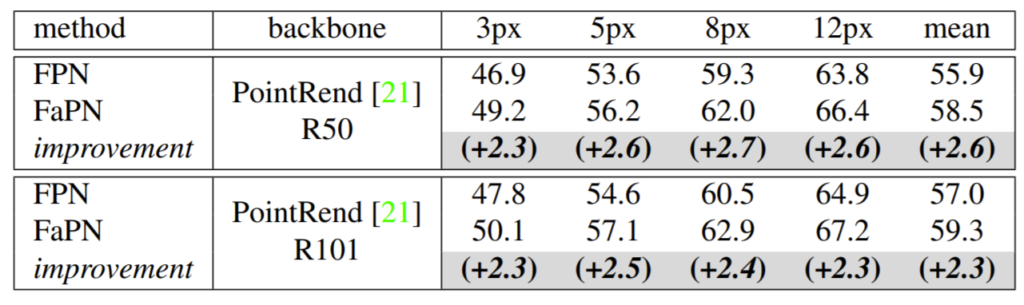
위에 표는 = boundary pixel에서의 mIoU를 정량적으로 계산한 결과입니다. 각 object의 outline 주변 n pixel들을 boundary pixel이라고 정의했으며 실험에서는 n값을 각각 3, 5, 8, 12로 설정하였습니다. 일단 뭐 boundary를 몇 픽셀로 잡는지 상관없이 FPN대비 2.3이상의 성능 향상을 보이고 있네요.
다음은 alignment를 진행하기 전 feature map과 진행 후의 feature map을 정성적으로 보인 결과입니다.

보시면 alignment 진행 전까지는 feature map이 뿌옇고 흐릿한 것을 볼 수 있었지만 FA모듈을 통과한 이후에는 상당히 object boundary가 선명하게 나타나는 모습을 확인할 수 있습니다.
Main Results
다음으로는 Object Detection, Semantic Segmentation, Instance Segmentation의 정량적 결과입니다.
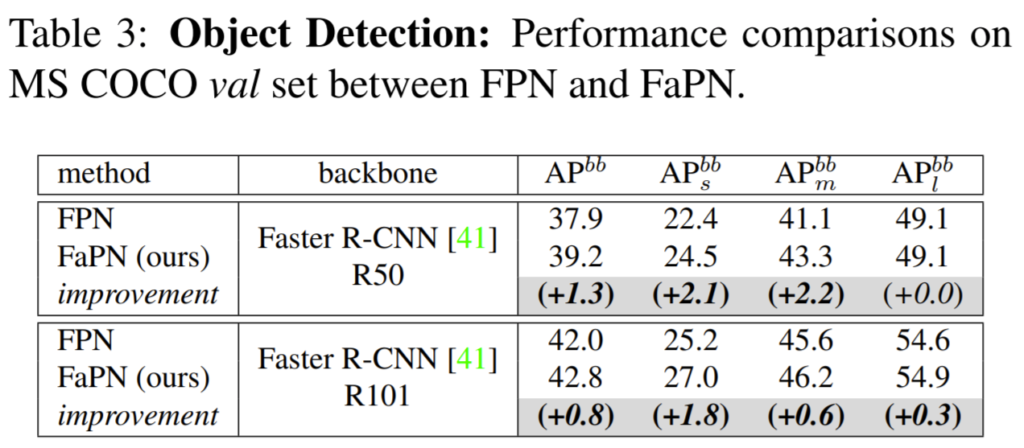
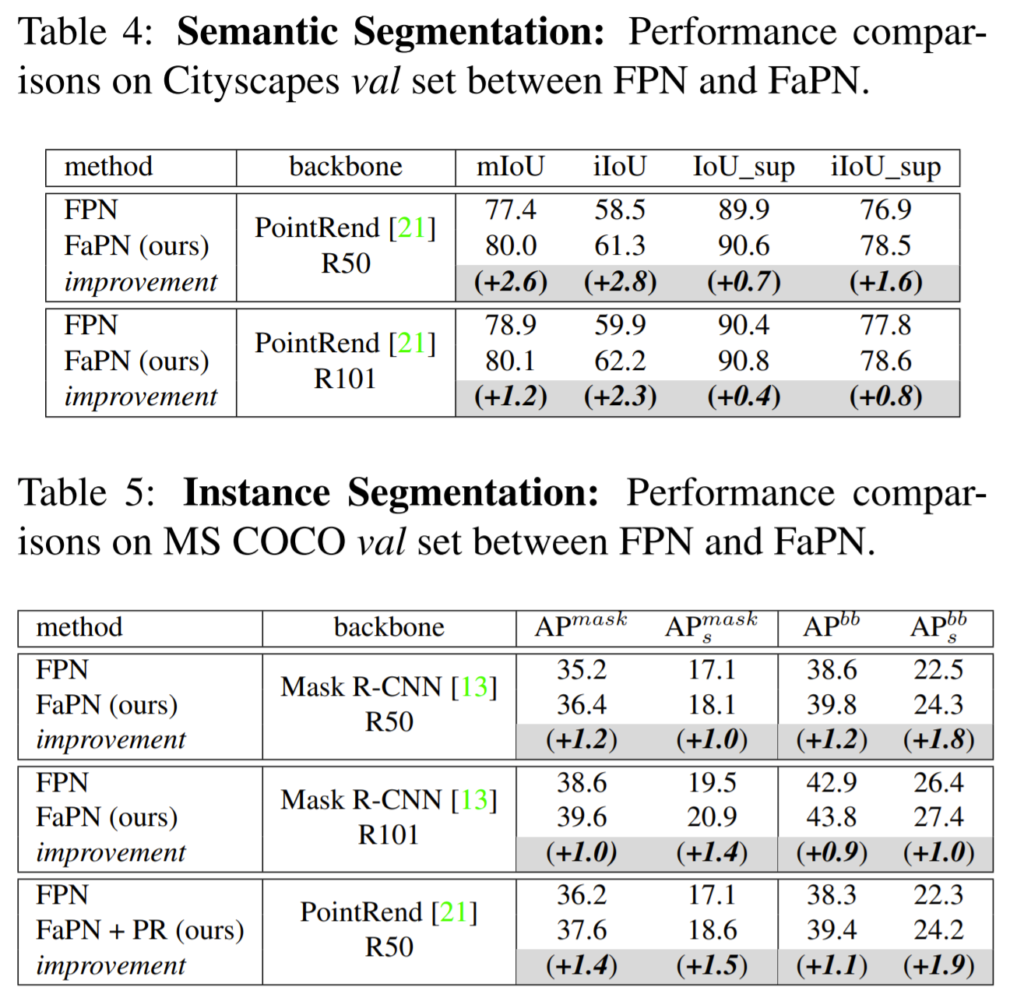
역시나 모든 task에서 FPN보다 더 좋은 성능을 보여주고 있습니다.
사실 정량적인 결과를 대충 넘긴 이유가 정성적인 결과가 너무나 아름?다워서 정량적 결과를 잘 보지 못했네요ㅎㅎ..
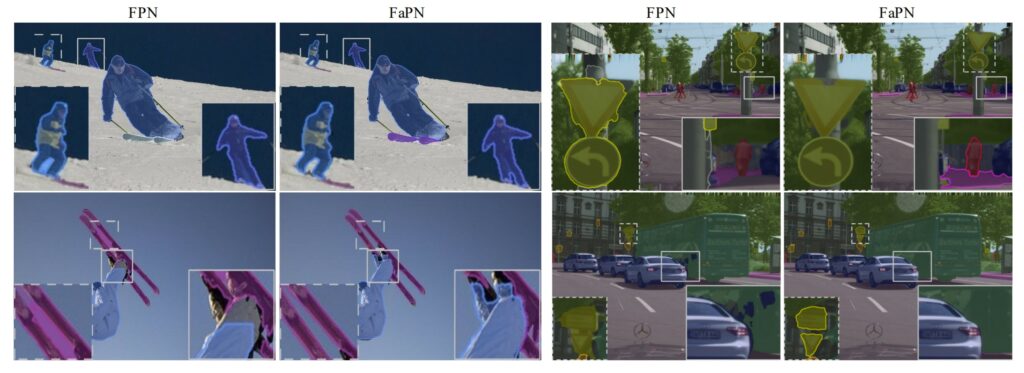
그림6은 FPN과 FaPN의 segmentation 정성적 결과입니다. 보시면 FPN의 경우 misalign문제로 인해 1행1열에 보드 타는 사람의 다리 사이 또는 2행1열에서 스키와 스키 사이에 배경 등이 한번에 동일한 label로 묶이는 반면 FaPN의 경우 정확하게 배경과 구분짓는 모습입니다.
그리고 2행3열과 4열에서도 볼 수 있듯이 FPN은 자동차와 버스 사이에 빈틈이 존재하는 반면 FaPN은 빈틈없이 샤프한 결과를 나타내고 있습니다.

결론
사실 Long Skip Connection은 2016년?2017년? 정확히 기억은 안나지만 U-net구조의 네트워크를 통한 segmentation task에서 처음 사용된 이후로 현재까지 당연하게 사용되고 있는 구조입니다.
이러한 Long Skip Connection에 그 누구도 큰 문제 없이 생각하고 있던 와중에 Encoder와 Decoder 사이에 misalignment가 발생할 것이라는 참신한 문제제기로 인하여 매우 단순한 구조를 통해서 좋은 결과물을 얻어낸 것이 해당 논문의 장점이라고 생각합니다.
최근에 드는 생각이지만… 문제를 잘 정의하면 간단한 방법을 통해서라도 값지고 유의미한 결과를 낼 수 있다는 것이 참 와닿네요…
offset을 구해서 offset을 인자로 주어 DCN을 수행하는것 같네요. 신정민 연구원님의 조언을 듣고 해당 리뷰를 확인하였는데, 다만 (제 생각에는..) 다른점은 다른 모달리티에서 추출한 feature간의 misalign 문제와 하나의 이미지에서 얻어진 feature 간의 misalign 문제는 조금 다르게 생각해봐야할 것 같습니다.