
매우매우 오랜만에 Optical Flow 논문을 가져와봤습니다. 가져오게된 계기는 Depth Estimation에서 물체 경계가 잘 살지 못하는 경우가 종종 관측되는데, Optical Flow도 이러한 문제점이 종종 있다보니 해당 분야에서는 어떤식으로 해결하는지 궁금하여 읽게 되었습니다.
Optical Flow에 대하여 자세히 알지 못하시는 분들은 제가 예전에 작성해놓은 리뷰 글들(optical flow, FlowNet2)을 읽으시면 좋을 것 같습니다.
Introduction
Optical Flow는 Depth Estimation과 유사하게 크게 2가지로 나뉘어져 있는 듯 합니다. 바로 Supervised 방식과 Unsupervised 방식으로 말이죠. 각각의 장단점도 Depth 때와 거의 유사합니다. Supervised는 성능이 좋은 대신에 GT를 구하기가 매우 까다롭죠. 특히나 Optical Flow의 경우는 픽셀 레벨에서 두 프레임간에 얼만큼 이동했는지에 대하여 annotation을 해야만 하기에 매우매우 구하기 힘듭니다.
그래서 Sintel과 같은 애니메이션으로 만든 데이터 셋이나, Flying Things 등과 같은 합성 데이터를 많이 사용하긴 하지만, 이러한 데이터들은 Real World가 아니기 때문에, 이를 합성 데이터로 학습한 모델을 Real World로 일반화하는 작업도 만만치가 않다고 합니다.
아무튼 이러한 문제를 극복하고자 GT가 없이 학습할 수 있는 Unsupervised method들이 많은 관심을 받고 있습니다. 해당 방식들은 Self-Supervised Monocular Depth Estimation과 유사하게 두 영상 사이에 Photometric loss를 사용하여 학습을 진행합니다.
이 때 학습을 보다 좋게 하기 위해서, 피라미드 네트워크 구조를 사용하여 Coarse-to-Fine 특징을 살려 전체 Global motion과 Local motion을 잘 학습하도록 하는게 일반적이라고 합니다. 그러나 이 피라미드 구조는 두 가지 문제점이 존재한다고 합니다.
바로 bottom-up 문제와 top-down 문제입니다. bottom-up 은 피라미드 구조 중에서 Up-sampling을 하는 모듈을 의미합니다. 기존에 방법론들은 단순히 bi-linear, 또는 bi-cubic Up-sampling을 진행하였는데 이러한 Up-sampling은 예측된 Optical Flow 결과가 blur하도록 하는 문제가 발생할 수 있으며, 이러한 에러값들이 스케일 별로 누적되면 최종적으로 Fine detail을 표현할 때 깔끔하게 생성되지 못합니다.
top-down 문제는 피라미드에 가이드 값을 줌으로써 지도 학습을 하는 것을 의미합니다. 이전의 학습 방식은 단순히 guidance loss를 오직 네트워크의 최종 출력 값에다가만 적용했다고 합니다. 하지만 각각에 스케일 레벨에서는 이러한 guidance를 제공하지 않았습니다. 이로 인해 coarser level에서의 에러 값이 크게 발생하다보니, 결국 finer level에서도 피해를 입게 된다는게 저자의 주장입니다.
그래서 저자의 contribution은 다음과 같습니다.
- Self-guided Up-sampling module을 통해 샤프한 motion edge를 생성함으로써 피라미드 네트워크의 interpolation problem을 해결하였다.
- Coarse pyramid level에서의 unsupervised learning을 위한 guidance를 제공하는 pyramid distillation loss를 제안한다.
Method
- Pyramid Structure in Optical Flow Estimation
일단 해당 섹션은 기존의 Unsupervised + Pyramid Network를 사용하는 Optical Flow 방법론에 대한 파이프라인을 설명합니다. 근데 저자는 기존의 파이프라인에서 앞서 설명한 Self-guided Up-sampling moduel과 Pyramid distillation loss를 제안한 것이다보니, 이 섹션에서 자세한 설명을 하지는 않고 UFlow 방법론을 동일하게 사용했다고만 합니다.(기회가 있으면 UFlow Net에 대해서 추가로 리뷰해보고자 합니다.)
먼저 Optical Flow Estimation을 수식화하면 다음과 같습니다.
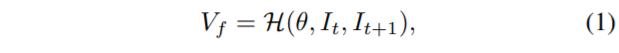
I_{t}, I_{t+1}는 앞 뒤 프레임을 의미하며, \mathcal{H}는 optical flow를 추정하는 함수, V_{f}는 현재 프레임에서 다음 프레임으로 이동되는 각 픽셀의 움직임을 나타낸 Optical Flow Map을 의미합니다.
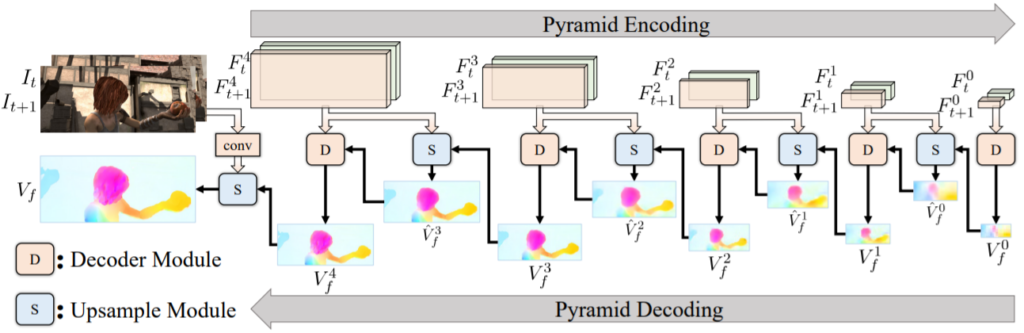
그림1은 제안하는 방법론의 전체 파이프라인으로 크게 2가지 단계로 나뉘어져있습니다. 먼저 첫번째 단계는 Pyramid encoding으로 두 대응되는 입력 영상들로부터 feature 쌍을 스케일별로 추출합니다. 그 후 두번째 단계인 Decoder moduel \mathcal{D}와 Up-sample moduel \mathcal{S}_{↑} 을 통하여 Coarse-to-fine 형식으로 optical flow를 추정합니다.
디코더의 구조는 ECCV2020 oral paper 중 하나인 UFlow의 구조를 그대로 사용했다고 합니다. 또한 UFlow에서 제안하는 Feature warping, correlation layer를 통한 Cost volume construction, cost volume normalization, fully convolutional layer를 통한 flow decoding 과정 모두 적용했습니다. 마지막으로 Decoder와 Up-sample moduel의 파라미터를 모든 피라미드 레벨에서 공유하였으며 이를 수식으로 표현하면 다음과 같습니다.
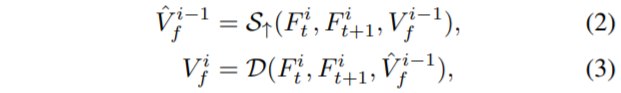
i \in {0, 1, ..., N}은 각 피라미드의 레벨을 의미하며, 값이 작을수록 coarse level을 의미합니다. F_{t}, F_{t+i} 는 현재 프레임과 그 다음 프레임의 입력으로 부터 추출된 Feature를 의미하며, \hat{V}^{i-1}_{f}는 i-1 level의 up-sampling된 flow map을 의미합니다. 보통 피라미드의 전체 레벨은 4로 설정하고 있으며, 최종적인 optical flow 결과는 제일 마지막 피라미드 레벨의 결과 값을 곧바로 up-sampling하여 얻게 됩니다.
2. Self-guided Upsample Module
그림2의 좌측편은 기존의 bi-linear interpolation을 나타낸 그림입니다. 4개의 점은 4개의 flow vector를 의미하며, 붉은 색과 푸른 색은 서로 다른 물체의 motion vector를 의미합니다.
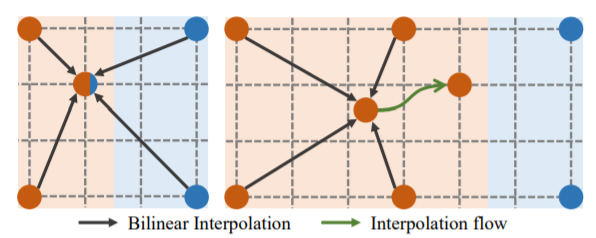
저자가 그림2에서 말하고 싶은 것은 바로 기존의 Bi-linear interpolation은 빈 영역이 붉은색 영역임에도 불구하고, 좌표값을 채우기 위하여 cross-edge 방식의 계산을 하다보니 푸른색 영역의 값들이 일부 반영된다는 것입니다. 이로 인해 물체의 바운더리가 blur해지는 것으로 보고 있으며 이를 해결하기 위해 Self-guided Up-sampling(SGU)을 제안하였습니다.
SGU의 메인 idea는 그림2 우측에 나와있습니다. 먼저 주변에 둘러싸는 red motion을 통하여 특정한 포인트를 보간합니다. 그리고 나서 학습된 interpolation flow를 통하여 target place로 결과값을 이동시킴으로써(그림2의 초록색 화살표) 보간을 완성합니다. 이렇게 진행하게 되면, 붉은 영역들끼리의 값들로 보간을 진행하였기에 다른 object 값이 섞여 들어가는 mixed interpolation problem은 방지할 수 있습니다.
하지만 이러한 interpolation flow는 보통 물체의 경계면과 같이 서로 다른 물체(or 배경)에 대해서만 사용할 수 있기에(같은 물체 내에서는 mixed interpolation problem이 발생하지 않으니) 저자는 per-pixel weight map을 학습함으로써 interpolation flow를 사용하는 곳과 그렇지 않는 곳을 지정하도록 하였습니다.
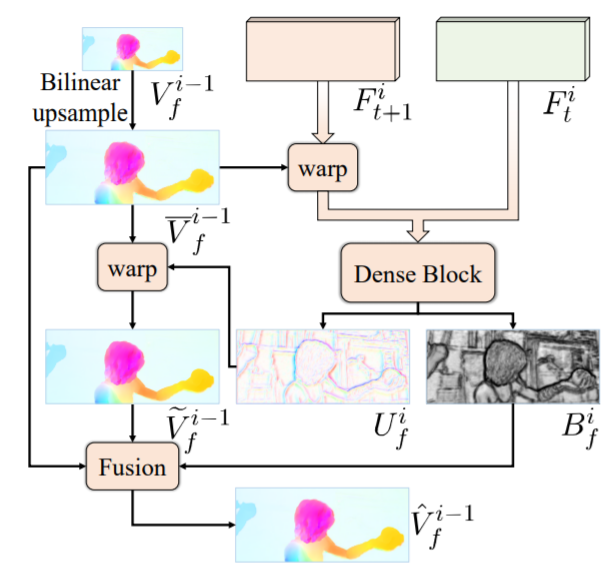
즉 SGU의 Up-sampling 과정은 bi-linear up-sampling한 flow와 interpolation flow를 통하여 warping한 up-sampled flow의 weighted combination이라고 합니다. 말이 조금 어려우니 차근차근 알아봅시다.
먼저 첫 입력은 저 해상도 flow map인 V^{i-1}_{f}을 bi-linear interpolation을 통해 Up-sampling하여 initial flow \bar{V}^{i-1}_{f}을 생성합니다.
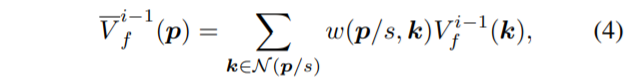
여기서 p는 high resolution의 픽셀 좌표를 의미하며, s는 scale magnification을, \mathcal{N} 는 4개의 이웃픽셀, w(p/s, k) 는 bi-linear interpolation의 가중치를 의미합니다.
그 다음 단계로, initial flow \bar{V}^{i-1}_{f}의 interpolation을 warping을 통하여 변화시키고자, 현재 프레임의 feature와 다음 프레임의 feature F^{i}_{t}, F^{i}_{t+1} 들로부터 interpolation flow U^{i}_{f} 를 계산하게 됩니다.
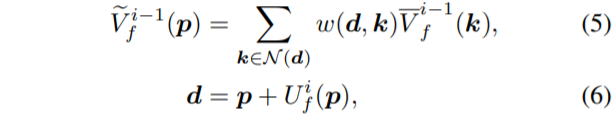
\tilde{V}^{i-1}_{f} 는 Interpolation flow를 통해 \bar{V}^{i-1}_{f}이 warping된 결과값을 의미힙나디. Interpolation blur는 오직 object edge 영역에서만 발생한다는 점 떄문에, 저자는 interpolation map B^{i}_{f}을 사용하여 노골적으로 모델이 interpolation flow을 학습할 때 오직 경계면 지역의 모션만을 보도록 하였습니다.
최종적인 up-sample result는 \tilde{V}^{i-1}_{f} 와 \bar{V}^{i-1}_{f}을 fusion함으로써 구할 수 있습니다.
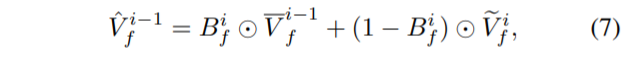
저 동글동글이들은 element-wise product를 의미합니다.
구현 과정에 대하여 조금 더 디테일하게 설명드리자면, 먼저 dense block은 5개의 컨볼루션 레이어로 구성되어 있으며, 입력으로는 warping된 F^{i}_{t+1} 과 현재 프레임 feature F^{i}_{t}을 concat한 값을 사용합니다. 최종 결과물은 3채널 tensor map이 나오게 되는데, 이때 2채널은 interpolation flow, 마지막 1채널은 sigmoid layer를 통과하여 interpolation map으로 사용됩니다.
과정이 다소 간단하면서도 복잡했는데, 조금 이해가 안되는 부분은 이러한 과정이 그림2 우측에서 보여준 SGU의 개념과 어떻게 관련이 있는지는 완벽히 이해하기 힘드네요.
Loss Guidance at Pyramid Level
- Unsupervised Optical Flow Loss
기존의 Unsupervised Optical Flow가 학습하는 loss 방식은 Self-supervised 기반 depth estimation과 매우 유사합니다. 네트워크를 통해 구한 Optical Flow Map으로 t 프레임의 영상을 t+1 프레임으로 warping 시킨 후, 그 warping된 결과와 실제 t+1 프레임 결과에 대한 밝기 값을 비교하는 것입니다. 이것을 Photometric Loss라고 부르죠.
그리고 이 때 두 프레임 사이에 시간 변화로 인하여 occlusion 영역이 생기게 되면 둘 자체에 대한 직접적인 비교를 할 수 없으므로, occulsion 영역은 loss 계산에서 제외시켜버리는 occlusion mask M_{t} 를 사용하게 됩니다. 즉 가장 기본적인 Optical Flow에서의 Photometric Loss는 다음과 같습니다.
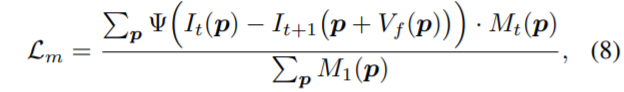
\Psi 는 robust penalty function으로 \Psi(x) = (|x| + \epsilon)^{q} , q, \epsilon = 0.4, 0.01 이라고 하는데, 다른 논문에서 가져온 개념이라 자세한 설명은 없지만, L1 loss의 변형이라고 생각하시면 될 것 같습니다.
Occlusion mask는 forward-backward checking을 통해서 구할 수 있으며, occlusion 영역은 0, 아닌 영역은 1의 값을 가지고 있어 해당 마스크를 곱해주면 occlusion 영역인 픽셀은 loss 계산에서 빠지게 됩니다.
저자는 성능 향상을 위해 기존에 여러 방법론들이 제안한 다양한 loss 함수들 (smooth loss, census loss, augmentation regularization loss, boundary dilated warping loss 등)을 사용하면 더 좋은 성능이 나온다고는 하지만, 굳이 논문에서는 다루지 않았습니다.
2. Pyramid Distillation Loss
마지막으로 논문에서 제안하는 Pyramid Distillation Loss에 대해서 다뤄봅시다. 사실 해당 loss는 매우 간단합니다. 직관적으로 보았을 때 각각의 스케일 레벨에서 나오는 출력들에 대하여 기존 Photometric loss를 적용하는 것입니다. 하지만 단순히 그렇게만 설명하면 기존의 방법론들이랑 별 차이가 없겠죠?
저자는 low resolution 결과물에 대해 photometric consistency를 측정하여 loss로 계산하는 것은 optical flow 학습에서 좋지 못하다고 이야기 합니다. 즉 각각의 중간 레벨에서 unsupervised loss를 계산하는 것은 부적절하다는 것이죠.
그래서 저자는 제일 마지막 layer까지 타고 나온 최종 output(finest output)을 다시 down sampling하여 각각의 중간 결과물에 pseudo label로 주어서 supervised loss를 계산하고자 합니다.
그리고 해당 loss를 계산할 때도 마찬가지로 occlusion region은 noise로 동작하기에, photometric loss를 계산할 때 사용한 occlusion mask 역시 down-sampling하여 사용합니다.
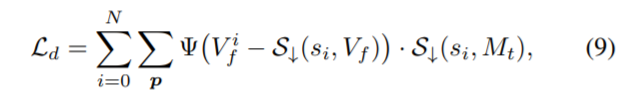
s_{i}, S_{↓}는 각각 scale magnification과 down-sampling function을 의미합니다. 즉 각 피라미드 레벨의 출력과 최종 아웃풋을 그 크기에 맞추어 down sampling한 결과와 직접적인 supervised 비교를 하는 것이죠.
Experiment
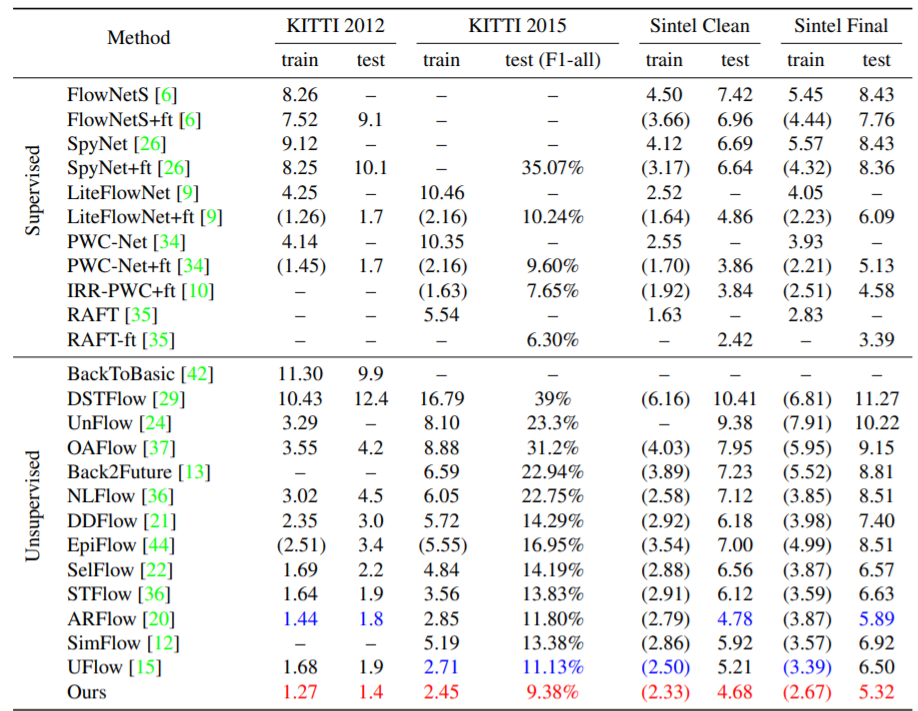
위에는 KITTI와 Sintel Dataset에 대하여 Supervised 방법론과 Unsupervised 방법론에 대해 정량적으로 비교한 결과입니다. 평가 메트릭으로 사용된 것은 endpoint error(EPE)와 percentage of erroneous pixels(F1)으로 두 값 모두 낮을수록 좋은 성능을 의미합니다.
일단 제안하는 방법론인 UPFlow가 Unsupervised에서 가장 좋은 성능을 보이고 있으며, Supervised 방법론들과 비교하였을 때도 경쟁력 있는 결과를 보이고 있습니다. 특히 KITTI 데이터 셋에서는 매우 높은 성능을 보이고 있는데, 이는 Supervised 기반 방법론들은 GT 부족으로 인해 합성 데이터 셋으로 학습 후 KITTI와 같은 real data는 평가로만 사용하는 반면, Unsupervised 방법론은 직접 KITTI 데이터셋을 학습에 사용할 수 있다보니 더 큰 성능 향상이 있는 듯 합니다.


다음은 정성적 결과입니다.
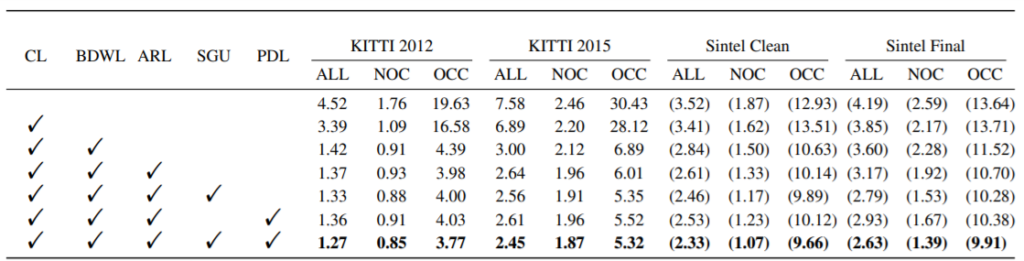
위에 테이블은 ablation study로 주의깊게 보실 점은 논문에서 제안한 SGU와 PDL의 적용 여부에 따른 성능 차이 입니다. SGU와 PDL 두 기법을 모두 사용하였을 때 성능이 큰 폭으로 오르는 것을 확인할 수 있는데, 저자는 각각의 기법들이 피라미드 네트워크의 문제점들 (bottom-up, top-down)을 모두 해결하였기에 더 큰 성능 향상이 있었다고 이야기합니다.

그림5를 살펴보시면 SGU를 적용하지 않았을 때 사람의 다리를 잘 표현하지 못하며, PDL을 적용하지 않은 경우 역시도 경계면이 완벽하게 살지 못하는 것을 확인할 수 있습니다.

마지막으로 그림 6는 Sintel Dataset에 대하여 섹션 3에서 설명드린 SGU를 적용하였을 때와 일반 Bi-linear Up-sampling의 차이 및 Interploation flow & map은 어떻게 나오는지에 대한 결과 사진입니다.
Bi-linear up-sampling을 사용하게 될 경우 대상 경계 면이 상당히 blur한 반면, SGU의 경우 선명하게 표시되어 있습니다.
좋은 리뷰 감사합니다!
interpolation flow 방식에 대해 잘 이해가 가지 않아 질문드립니다.
주변 motion을 통해 특정 포인트를 보간하고나서 학습된 interpolation flow를 통하여 target place로 결과값을 이동시킴으로써 보간을 완성한다고 하셨는데 이는 빈 부분을 단순히 주변 값을 이용해 채우는 지와 주변의 각 점들의 이동을 통해 빈 부분의 이동을 예측하고 거기서 보간을 진행하는 지의 차이가 맞나요?
음 정확히 표현하자면 저자는 그림2의 우측과 같이 동일한 물체 내 모션정보들만으로 interpolation을 하고 그 다음에 interpolation flow라는 개념을 이용해 정확한 위치로의 이동을 원했습니다.
이를 구현하는 방식으로 그림3을 보시면, 먼저 예측된 optical flow map에 bi-linear interpolation을 한번 거친 뒤, 그 값으로 t+1 frame을 warping 시킵니다. 그렇게 warping된 결과와 기존의 t frame feature를 가지고 네트워크를 태워서 interpolation flow라는 2채널 맵과 1채널 interpolation map을 만들게 되죠.
이렇게 추정된 interpolation flow를 맨 처음 bi-linear sampling한 optical flow map에 다시 warping 해줌으로써 저자가 말한 interpolation flow 위치 이동이 수행됩니다.
근데 저도 이부분에 대해서 정확히 답변 드리기는 어려운게 설명이 매우 애매합니다. 저자가 의도한 그림 2에서의 interpolation은 동일한 물체 내 모션 정보들끼리만 interpolation을 거치고 그 뒤에 interpolation flow를 통해 정확한 위치로 이동을 시키는 것인데, interpolation flow를 적용시키는 feature는 bi-linear interpolation이 수행된, 즉 mixed-interpolation map에다가 적용을 하게 되니 저자의 의도와는 조금 틀려지지 않았나 라는 생각이 드네요.