안녕하세요. 이번에는 REI-BENCH: Can Embodied Agents Understand Vague Human Instructions in Task Planning?이라는 논문을 읽어보게 되었습니다. 쉽게 말하면, 로봇이 사람이 애매하게 말한 지시를 얼마나 잘 이해할 수 있는지 평가한 논문입니다.
예를 들어 사람이 로봇에게 “냄비를 옮겨줘”라고 말하면 비교적 명확합니다. 그런데 실제 대화에서는 “그거 옮겨줘”, “무거운 것 좀 옮겨줘”, “아까 말한 데워진 것 싱크대에 놔줘”처럼 말할 수 있죠. 사람은 앞뒤 대화를 보고 대충 알아듣지만, 로봇은 이걸 꽤 어려워할 수 있습니다. 이 논문은 바로 그 지점을 정면으로 다룹니다. 그럼 시작하겠습니다.
1. Introduction
최근 기존의 전통적인 task planning 방법들은 특정 환경이나 특정 task domain에 묶이는 경우가 많았는데, LLM을 쓰면 훨씬 다양한 자연어 지시를 로봇 계획에 연결할 수 있을 것처럼 보입니다.
하지만 저자들은 여기서 중요한 가정 하나를 지적합니다. 기존 LLM-based task planner들은 보통 사람이 주는 instruction이 항상 clear하고 complete하며 unambiguous하다고 가정한다는 것입니다. 그런데 실제 사람은 그렇게 말하지 않죠. 특히 home robot이나 assistive robot이 실제 생활 공간에서 쓰인다면, 사용자는 정확하게 물체 이름을 매번 말하지 않을 가능성이 큽니다.
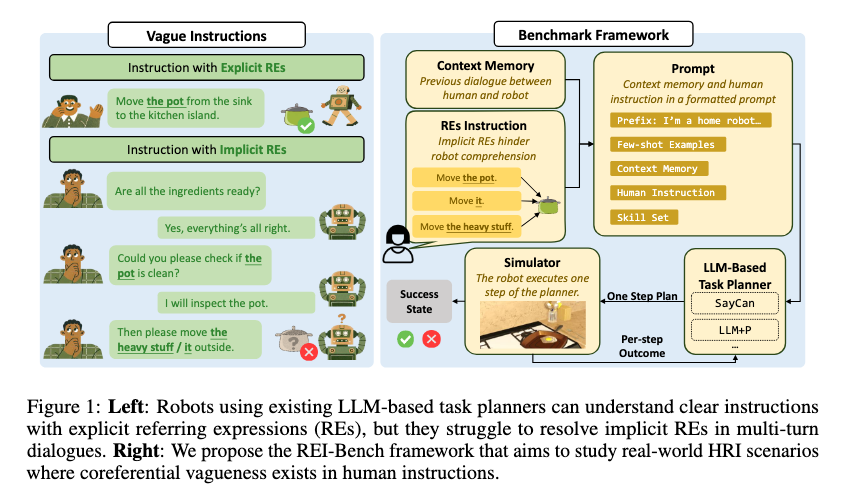
예를 들어 논문에서 보여주는 상황을 보면, 사람이 처음에는 pot을 말했지만 나중에는 “it”이나 “heavy stuff”처럼 말합니다. 사람은 앞 대화와 상황을 보고 “아, 여기서 heavy stuff는 pot이겠구나”라고 이해할 수 있습니다. 하지만 로봇 planner는 plate나 pan 같은 다른 물체를 고를 수도 있습니다. 별것 아닌 것처럼 보이지만, 로봇이 실제로 행동한다면 완전히 다른 task를 수행하게 되는 문제입니다.
논문은 이런 문제를 coreferential vagueness, 즉 공동지시 모호성으로 봅니다. 같은 대상을 여러 표현이 가리키고 있는데, 그 연결을 context memory를 이용해 추론해야 하는 상황입니다. 예를 들어 “the heated one”이라는 표현만 보면 무엇을 말하는지 알기 어렵지만, 앞에서 potato를 요리하는 대화가 있었다면 “데워진 것”은 potato일 가능성이 높습니다.
여기서 논문의 핵심 질문은 다음과 같습니다.
- implicit referring expressions, 즉 implicit REs가 LLM-based task planner의 성능을 떨어뜨리는가?
- implicit REs가 많아질수록 success rate는 어떻게 변하는가?
- 성능 저하의 원인은 무엇이고, 이를 줄이려면 어떤 방식이 필요한가?
저자들은 이 질문에 답하기 위해 REI-Bench를 제안합니다. REI-Bench는 Referring Expressions Instruction Benchmark라고 볼 수 있는데요. 지칭 표현이 들어간 로봇 지시를 체계적으로 만들고, 그 모호성이 task planning 성능에 어떤 영향을 주는지 평가하는 benchmark입니다.
본 논문의 contribution을 정리하면 아래와 같습니다.
- robot task planning에서 referring expressions로 생기는 instruction vagueness를 체계적으로 분석함
- REI-Bench라는 benchmark를 만들고, RE type과 context memory type을 조합해 9개의 vagueness level을 구성함
- 여러 LLM-based planner에서 implicit REs가 success rate를 크게 떨어뜨린다는 것을 보임
- 실패 원인이 주로 object omission, 즉 목표 물체를 놓치는 데 있음을 분석함
- 이를 완화하기 위해 Task-Oriented Context Cognition, TOCC를 제안함
2. Related Works
Related Works에서는 크게 두 가지 흐름을 다룹니다.
첫 번째는 Embodied Task Planning입니다. 여기에는 SayCan, ProgPrompt와 같은 연구와 환경이 포함되는데요. 이 흐름의 핵심은 사람이 자연어로 말한 high-level instruction을 로봇이 수행 가능한 action sequence로 바꾸는 것입니다. 예를 들어 SayCan은 LLM이 “무엇을 해야 하는지”를 제안하고, 로봇이 실제로 “무엇을 할 수 있는지”를 affordance와 연결해서 계획을 만듭니다.
두 번째는 Linguistic Vagueness in LLMs입니다. 기존 NLP 연구에서는 ambiguity나 vague query를 다루는 benchmark가 있었고, embodied AI에서도 로봇이 clarification question을 하거나 uncertainty를 추론하게 하는 연구들이 있었습니다. 하지만 저자들은 기존 연구가 robot task planning에서 모호한 언어가 실제 task success에 어떤 영향을 주는지 충분히 체계적으로 보지 않았다고 말합니다.
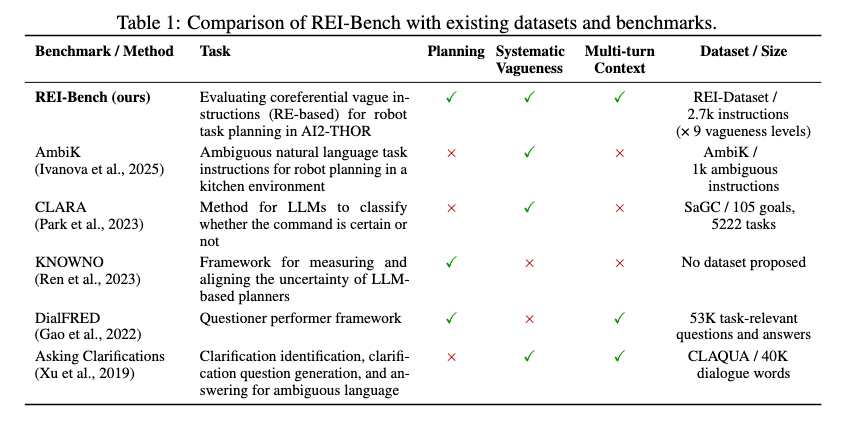
Table 1을 통해서 구체적으로 확인할 수 있는데요. REI-Bench는 task planning, systematic vagueness, multi-turn context를 모두 포함하는 반면에, AmbiK는 ambiguous instruction은 다루지만 multi-turn context는 약하고, CLARA나 KNOWNO도 각각 불확실성이나 clarification에 초점이 있지 RE 기반 모호성을 체계적으로 평가하는 benchmark는 아닌 것을 볼 수 있습니다.
3. Approach
3.1. Formalizing Vagueness by Implicit REs and Human-Robot Dialogue Context
먼저 저자들은 자연어의 vagueness를 signifier와 signified의 관계로 설명합니다. 예를 들어 mouse라는 단어는 동물 쥐를 뜻할 수도 있고, 컴퓨터 마우스를 뜻할 수도 있습니다. 단어 하나가 여러 대상을 가리킬 수 있는 것이죠.
화용론에서는 이런 모호성을 Referring Expressions, REs와 Deictic Expressions, DEs로 나눕니다. REs는 언어 맥락을 통해 풀 수 있는 지칭 표현입니다. 예를 들어 “mouse and keyboard”라고 하면 여기서 mouse는 컴퓨터 입력 장치일 가능성이 큽니다. 반면 DEs는 “오른쪽”, “여기”, “저기”처럼 시간, 공간, 화자의 위치가 필요한 표현입니다.
이 논문은 그중에서도 REs에 집중합니다. 로봇 task planning에서 물체를 잘못 이해하면 계획 전체가 틀어지기 때문입니다.
논문은 REs를 크게 explicit REs와 implicit REs로 나눕니다. explicit REs는 apple, the apple, an apple처럼 물체를 직접적으로 말하는 표현입니다. implicit REs는 it, them, sweet fruit처럼 앞뒤 맥락을 봐야 무엇인지 알 수 있는 표현입니다.
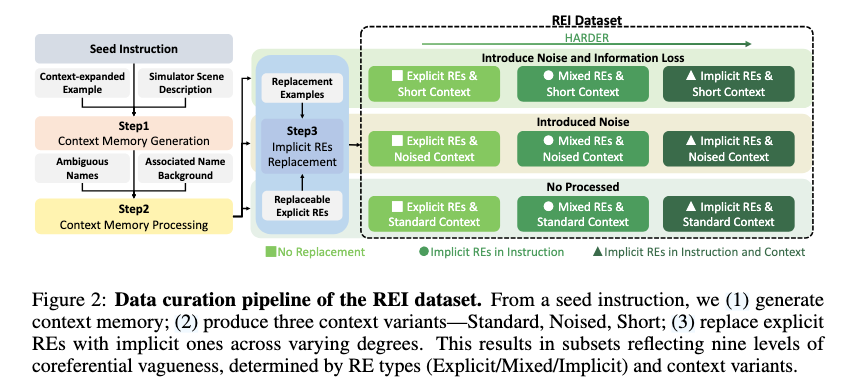
그런다음, RE 난이도를 세 단계로 나눕니다. (Figure 2를 통해 시각적으로 확인할 수 있습니다)
- Explicit REs: 원래 데이터의 명확한 표현을 그대로 유지한 경우
- Mixed REs: instruction 안의 explicit REs를 implicit REs로 바꾸고, context memory에는 명확한 표현을 남겨둔 경우
- Implicit REs: context memory의 첫 번째 표현을 제외하고 대부분을 implicit REs로 바꾼 경우
Context memory도 세 단계로 나눕니다.
- Standard Context: task와 관련된 정보가 충분히 들어 있는 일반 맥락
- Noised Context: Apple 같은 물체 이름과 비슷한 사람 이름이나 브랜드 이름을 넣어 헷갈리게 만든 맥락
- Short Context: noise를 넣고, 여기에 더해 task-relevant information 일부를 제거한 맥락
정리하면, RE level 3개와 context memory type 3개가 만나서 총 3 \times 3 = 9개의 난이도 조건이 만들어집니다. 이 구성이 꽤 깔끔한데요. 단순히 “애매한 문장”을 모아놓은 것이 아니라, 어떤 종류의 모호성이 얼마나 들어갔는지를 실험적으로 조절할 수 있게 만든 것입니다.
3.2. REI-Bench Dataset
REI-Bench는 ALFRED benchmark를 기반으로 만들어졌습니다. ALFRED는 가정 환경에서 로봇이 수행해야 하는 embodied household task를 다루는 dataset입니다.
저자들은 ALFRED에서 6개의 task type을 선택하여 구성하였습니다. Pick & Place, Stack & Place, Clean & Place, Heat & Place, Cool & Place, Examine in Light입니다. Pick Two & Place는 제외했는데, 이유는 embodied agent가 안정적으로 완료하기 어렵기 때문이라고 합니다.
또 하나 중요한 점은, clear instruction에서도 실패하는 task는 제외했다는 것입니다. 이 논문의 관심은 “로봇이 원래 어려운 task를 못한다”가 아니라, “명확하면 할 수 있는 task를 모호하게 말했을 때 못하게 되는가”이기 때문입니다. 그래서 LLaMA + SayCan 모델을 시뮬레이터에서 실행해 clear instruction에서 성공한 task만 seed instruction으로 남겼다고 합니다.
데이터 생성 과정은 세 단계입니다.
첫 번째는 context memory generation입니다. GPT-4o-mini를 사용해서 seed instruction 주변에 자연스러운 human-robot dialogue를 만듭니다. 즉, 단순히 “감자를 냉장고에 넣어라” 같은 문장 하나가 아니라, 앞에서 사람이 감자에 대해 이야기하고 로봇이 대답하는 대화 맥락이 붙습니다.
두 번째는 context memory processing입니다. 여기서 standard context는 그대로 두고, noised context에는 ambiguous name을 넣습니다. 예를 들어 simulator 안에 Rose라는 object가 있으면 Mrs. Rose 같은 사람 이름을 대화에 넣을 수 있습니다. short context에서는 일부 noun phrase를 제거해서 정보가 부족한 상황을 만듭니다.
세 번째는 implicit REs replacement입니다. explicit REs를 it, them, the fruit, the heated one 같은 implicit expression으로 바꿉니다. 이때 OntoNotes의 예시를 활용해 자연스러운 표현이 되도록 만들었다고 합니다.
최종적으로 REI-Bench는 2,700개의 examples를 포함합니다. 그리고 이 2,700개는 앞서 말한 9개 vagueness level로 나뉩니다.
3.3. Task-Oriented Context Cognition
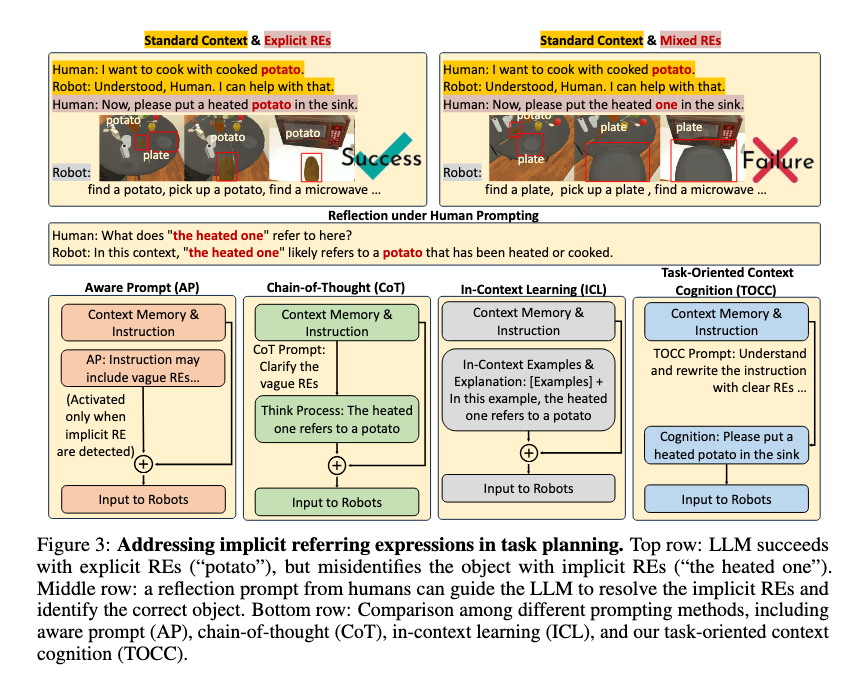
이제 저자들이 제안한 완화 방법인 TOCC를 보겠습니다. TOCC는 Task-Oriented Context Cognition의 약자입니다.
논문에서 흥미롭게 볼 점은 LLM이 implicit REs를 아예 못 푸는 것은 아니라는 점입니다. 예를 들어 사람에게 “the heated one이 여기서 무엇을 가리키니?”라고 물으면, LLM은 앞뒤 context를 보고 potato라고 답할 수 있습니다. 그런데 같은 LLM이 planner로 들어가서 바로 action sequence를 만들어야 할 때는 potato 대신 plate를 고르는 것을 볼 수 있습니다.
왜 그럴까요? 저자들은 LLM이 planning에 너무 많은 attention을 쓰면서, 원래 가지고 있던 language understanding 능력을 충분히 쓰지 못한다고 봅니다. 이 부분이 꽤 중요한데요. “LLM을 planner에 넣으면 자연어 이해도 알아서 되겠지”라는 기대가 실제로는 맞지 않을 수 있다는 뜻입니다.
저자들은 네 가지 방법을 비교합니다. 이는 Figure 3에서 시각적으로 확인할 수 있습니다.
- AP, Aware Prompt: instruction에 vague REs가 있을 수 있다고 알려주는 방식
- CoT, Chain-of-Thought: RE를 찾고, referent를 추론하고, 그 다음 계획하게 하는 방식
- ICL, In-Context Learning: 예시를 보여주고 비슷하게 추론하게 하는 방식
- TOCC: 먼저 instruction을 명확하게 다시 쓴 뒤, 그 명확한 instruction으로 planning하는 방식
TOCC의 핵심은 분리입니다. reference resolution과 planning을 한 번에 하지 않고, 먼저 “사람이 말한 애매한 표현이 실제로 무엇을 뜻하는지”를 clear instruction으로 바꿉니다. 그 다음 planner는 그 clear instruction만 보고 action을 고르게 됩니다.
쉽게 말하면, 로봇에게 바로 문제를 풀게 하는 것이 아니라, 문제 문장을 먼저 쉬운 말로 고쳐 쓰고 나서 풀게 하는 방식입니다. 개인적으로 이 부분이 꽤 실용적이라고 느껴졌습니다. 엄청 복잡한 architecture를 새로 만드는 것이 아니라, planner 앞단에 context 이해 단계를 하나 넣는 방식이기 때문입니다.
4. Experiment
4.1. Experimental Setup
실험에서는 네 가지 LLM-based embodied task planning framework를 평가합니다. 1) SayCan, 2) DAG-Plan, 3) HPE, 4) LLM+P입니다.
- SayCan은 LLM이 가능한 subtask를 제안하고, feasibility assessment를 통해 어떤 action을 할지 고르는 방식입니다.
- DAG-Plan은 Directed Acyclic Graph 형태로 subtask dependency를 구성합니다.
- HPE는 hierarchical memory bank를 이용한 framework를 말합니다.
- LLM+P는 자연어 지시를 PDDL 같은 symbolic representation으로 바꾼 뒤 classical planner를 사용하는 방식입니다.
사용한 LLM은 GPT-4o-mini와 같은 모델을 사용했는데, mobile robot에 올릴 수 있는 lightweight model이 중요하다고 보고, 비교적 작은 언어 모델를 사용하였다고 합니다. 평가에는 REI-Bench에서 stratified sampling으로 뽑은 1,000-task subset을 사용했습니다.
4.2. Benchmark Results of LLM-Based Task Planners
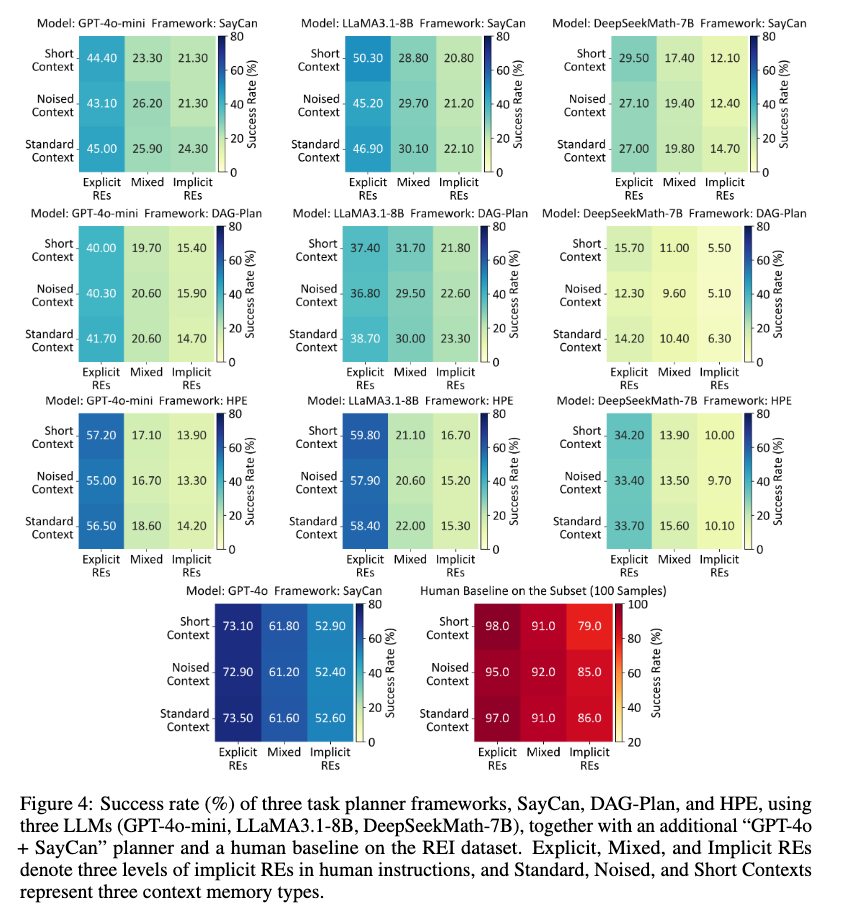
결과를 보면, 먼저 multi-turn dialogue 자체가 planner에게 어려운 것을 볼 수 있습니다. LLaMA + SayCan은 instruction만 봤을 때 57.7% success rate를 기록한 것을 볼 수 있는데 Standard Context가 포함된 multi-turn dialogue를 넣으면 explicit REs만 있어도 success rate가 46.90%로 뚝 떨어지는 것을 볼 수 있습니다. 즉, 모호한 표현이 없어도 대화 맥락이 들어오는 순간 planner가 흔들릴 수 있다는 것이죠.
더 중요한 결과는 implicit REs가 많아질수록 성능이 꾸준히 떨어진다는 점입니다. LLaM + SayCan을 봤을 때 Explicit REs -> Mixed REs -> Implicit REs로 성능을 보면, 46.90% -> 30.10% -> 22.10%로 성능이 떨어지는 것 확인할 수 있습니다. 다른 모델들도 비슷하게 성능이 점점 떨어지는 것을 볼 수 있습니다.
제일 마지막 줄의 오른쪽을 보면 Human baseline도 확인할 수 있는데요. 사람도 Short Context + Implicit REs에서는 79.0%까지 내려가는 것을 볼 수 있는데, 이걸 보면 이 문제가 단순히 특정 모델이 약해서 생긴 문제라기보다는 context와 reference resolution 자체가 어려운 문제라는 생각도 듭니다.
4.3. Ablation Study on Different Prompting Methods
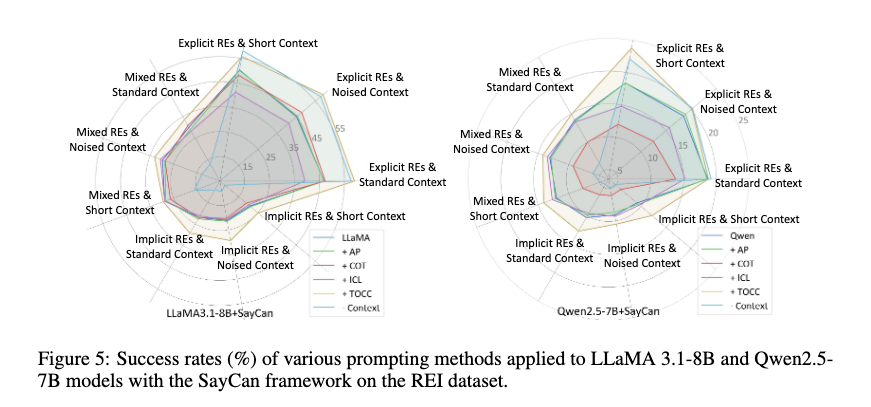
이 섹션에서는 AP, CoT, ICL, TOCC를 비교하는데요.
AP는 “지시 안에 모호한 지칭 표현이 있을 수 있다”고 알려주는 방식입니다. 대부분의 경우 조금 도움이 되지만, explicit instruction에서는 오히려 성능이 떨어질 수 있습니다. 왜냐하면 원래 명확한 문장인데도 모델이 억지로 모호성을 찾으려 하면서 hallucination을 만들 수 있기 때문입니다.
ICL은 예시를 보여주고 따라 하게 하는 방식인데, 논문에서는 거의 모든 category에서 성능이 떨어졌다고 합니다. 저자들은 small onboard LLM-based planner가 few-shot example을 충분히 잘 활용하지 못한다고 해석합니다.
CoT는 AP보다 더 낫습니다. 먼저 어떤 RE가 있고, 그것이 무엇을 가리키는지 추론하게 하기 때문입니다. 하지만 CoT는 prompt가 길어지고 latency가 커집니다. 실제 로봇에 올리는 상황에서는 이 비용도 무시하기 어렵겠죠.
TOCC는 가장 좋은 성능을 보입니다. LLaMA + SayCan에서 average success rate improvement가 6.5%였다고 합니다. 핵심은 planner에게 모든 것을 한 번에 시키지 않고, 먼저 instruction을 clear하게 바꾼 뒤 planning하도록 한다는 점입니다.
4.4. Analysis of LLM-Based Planner Errors
마지막으로 error analysis를 보겠습니다. 저자들은 planning error를 두 가지로 나눕니다.
첫 번째는 object omission입니다. planner가 instruction에서 말하는 target object를 제대로 찾지 못하는 경우입니다. 두 번째는 execution error입니다. target object는 맞게 찾았지만, goal을 달성하는 action sequence를 제대로 만들지 못하는 경우입니다.
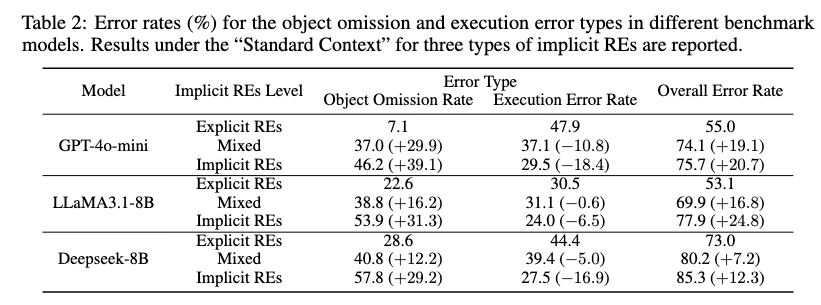
Table 2를 보면 implicit REs가 늘어날수록 object omission rate가 크게 증가합니다. GPT-4o-mini는 Standard Context에서 object omission rate가 Explicit REs 7.1%, Mixed REs 37.0%, Implicit REs 46.2%로 증가합니다. 다른 모델들도 마찬가지입니다.
반대로 execution error rate는 줄어드는 경향이 있습니다. 이게 조금 이상해 보일 수 있는데요. 해석하면 이렇습니다. implicit REs가 어려워질수록 planner가 action sequence를 잘 만들고 못 만들고의 문제 이전에, 아예 어떤 object를 대상으로 해야 하는지를 놓쳐버립니다. 그래서 failure의 중심이 execution planning보다 reference resolution 쪽으로 이동하는 것입니다.
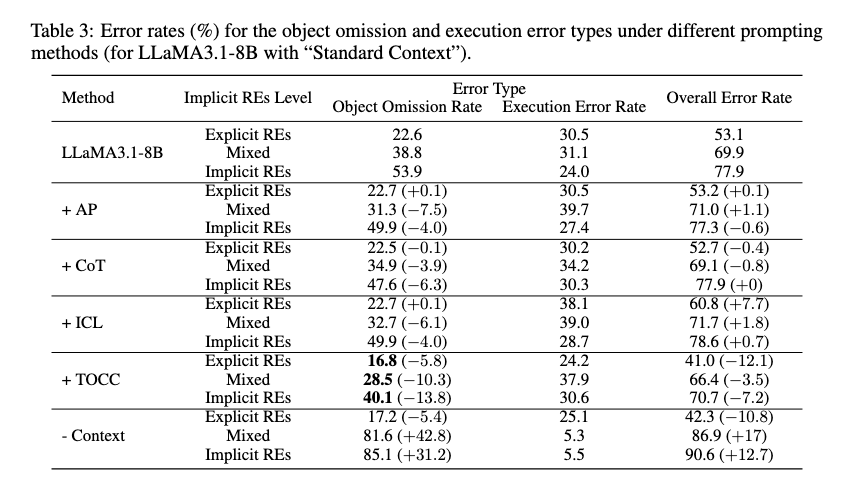
Table 3에서는 prompting method별 error도 보여줍니다. LLaMA의 Standard Context에서 TOCC를 쓰면 overall error rate가 Explicit REs에서 53.1%에서 41.0%로, Mixed REs에서 69.9%에서 66.4%로, Implicit REs에서 77.9%에서 70.7%로 내려갑니다. object omission rate도 각각 22.6%에서 16.8%, 38.8%에서 28.5%, 53.9%에서 40.1%로 줄어듭니다.
반면 context를 제거하면 Mixed REs와 Implicit REs에서 error가 매우 커집니다. Standard Context에서 context 제거 조건은 Mixed REs overall error rate가 86.9%, Implicit REs가 90.6%입니다. 이 결과는 context memory가 implicit REs 해석에 거의 필수적이라는 점을 잘 보여줍니다.
5. Conclusions
논문은 coreferential vagueness가 robot task planning에 꽤 큰 영향을 준다는 것을 보여줍니다. 특히 LLM-based planner가 명확한 instruction에서는 어느 정도 task를 수행할 수 있어도, 사람이 실제 대화처럼 it, that one, the heated one 같은 표현을 쓰기 시작하면 success rate가 크게 떨어집니다.
저자들이 제안한 TOCC는 이 문제를 완전히 해결하는 방법이라기보다는, 꽤 단순하지만 효과적인 완화 방법에 가깝습니다. 먼저 context를 보고 instruction을 명확하게 고쳐 쓰고, 그다음 planner가 계획하게 만드는 방식입니다. 이 접근은 실제 시스템에서도 꽤 적용 가능성이 있어 보입니다.
다만 한계도 있습니다. 이 논문은 REs, 즉 지칭 표현에 집중합니다. “여기”, “저쪽”, “오른쪽” 같은 deictic expressions는 다루지 않습니다. 또한 AI2-THOR simulator에서 text-based planning을 평가하기 때문에, 실제 robot의 visual perception, spatial grounding, manipulation uncertainty까지 다루지는 못합니다. 그래서 실제 physical robot에 적용하려면 더 많은 검증이 필요합니다.
이렇게 리뷰를 마쳐봅니다. 이 논문은 제가 관심 있는 caregiving이나 service robot 상황과도 꽤 연결된다고 느꼈습니다. 실제 사용자는 로봇에게 항상 정확하게 말하지 않을 가능성이 굉장히 높습니다. 특히 노인이나 아이, 혹은 인지적으로 피곤한 상황에 있는 사람은 “그거”, “아까 말한 것”, “데워진 것”, “무거운 것”처럼 말할 수 있죠.
그런데 로봇 입장에서는 이런 작은 표현 하나가 task 전체를 바꿔버릴 수 있습니다. 그래서 이 논문은 “LLM이 자연어를 잘하니까 로봇도 알아서 이해하겠지”라는 생각을 조금 조심해야 한다는 것을 보여줍니다. language understanding과 task planning은 붙어 있지만, 실제 시스템에서는 분리해서 다루어야 할 수도 있다는 점이 인상적이었습니다.
개인적으로는 TOCC가 특히 흥미로웠습니다. 엄청 큰 모델이나 복잡한 architecture보다, 먼저 instruction을 명확하게 다시 쓰는 작은 단계가 planning 성능을 높일 수 있다는 점이 좋았습니다. 돌봄 로봇이나 서비스 로봇에서도 사용자의 모호한 말을 바로 action으로 보내기보다, 먼저 context-aware clarification이나 instruction rewriting을 거치는 구조가 중요해질 것 같습니다. 앞으로 deictic expression이나 multimodal context까지 확장되면 더 재밌는 연구 방향이 될 것 같네요.
안녕하세요 김주연 연구원님, 좋은 리뷰 감사합니다.
모호한 표현이 없어도 대화 맥락이 들어오는 순간 planner가 흔들릴 수 있다고 설명해주셨는데, 맥락이 도움이 아니라 방해가 되는 이유는 무엇일까요? planner의 한계인지 아니면 단순히 prompt가 길어져서 그런건지 궁금합니다.
감사합니다.
좋은 질문 감사합니다.
제가 이해한 바로는, 이 논문에서 “맥락이 들어오면 planner가 흔들린다”는 현상은 단순히 prompt가 길어져서라기보다, planner가 대화 맥락 안에서 task-relevant information과 distractor information을 구분하는 능력이 약하기 때문에 가깝다고 볼 수 있습니다. 이 때문에 맥락이 들어오면 planner가 집중해야 할 정보에 집중하지 못하고 제대로 동작하지 못하게 되는 것이지요.
감사합니다.
안녕하세요 주연님 리뷰 감사합니다.
기존 맥락에 잘 집중하던 agent가 planning을 하는 순간 기존 맥락을 놓치고 예시로 들어주신 무엇이 데워졌냐는 질문에 답이 바뀌는 것을 볼 수 있었는데요, 혹시 implicit RE 시에 프롬프팅을 먼저 맥락에 대한 답을 하고 나서 planning을 하라고 하거나 하는 식으로 바꾼 실험이나, gemini나 GPT같은 더 큰 모델들로 실험한 결과도 있을까요?
+ 문제가 엄청 어려운건지 벤치마크에서 사람이 80점 아래가 나올 수 있다는 것도 되게 충격이네요,,
좋은 질문 감사합니다.
논문에서는 먼저 맥락을 해석하고 planning하게 하자는 방향의 실험이 있기는 했었는데요. CoT나 TOCC가 이에 해당한다고 볼 수 있을 것 같습니다. 특히 TOCC가 모호한 지시를 먼저 명확한 지시로 rewrite한 뒤에 planner가 planning하도록 분리합니다. 그럼에도 이 방식이 완전히 문제를 해결하지는 못하는 것이 planner가 맥락 이해나 행동 계획을 한번에 처리할 때 attention이 분산되기 때문에 task-relevant context와 distractor를 안정적으로 구분하지 못하는 모습을 보이기도 합니다.
더 큰 모델도 실험이 됐었는데, 성능은 좋아지지만 implicit RE가 늘어나면 여전히 성능 저하 문제가 발생하는 모습을 보입니다. 모델 크기 만으로 해결되는 문제는 아닌 거죠.
감사합니다.
안녕하세요 주연님, 좋은 리뷰 감사합니다.
제가 잠시 묵혀두고 있는 LLM planning 시 모호성 판단 연구 에서 CLARA를 벤치마크 베이스삼았었는데요. CLARA가 막상 뜯어보니 허점이 너무 많아서 정말 짜증났던 기억이 있습니다. 더 좋은 벤치마크 없나 하다가 CLARA 벤치마크 중 중복되는 데이터는 제거하고 이미지생성으로 증강하여 연구 진행했었는데요. REI-BENCH 연구는 그런 점들 중 지시어 관련해서 RE 쪽의 모호함에 더 집중하고 benchmark 제시한 게 되게 꿀맛 같네요.
궁금한 점은,
1. CoT와 TOCC간 본질적으로 다른 것이 정확히 뭔가요? 뭔가 제가 진행했던 연구의 방법론(inverse planning)이랑 되게 유사해서 더 잘 이해하고 싶어서 질문드립니다.
2. 사실 저는 저번 논문 작성하면서, 모호성이라는 걸 불확실성 스코어로 연결짓는 평가만 하고, Success Rate 까지는 접근을 못해서 부족한 점이 많았는데요. 본 논문은 보통의 모호성 판단 연구에서 주로 활용하는 불확실성 스코어를 활용하지 않은 이유가 무엇인지 궁금합니다.
좋은 질문 감사합니다.
1. CoT와 TOCC의 차이는 “추론을 하느냐”보다 추론 결과를 planning과 분리하느냐에 있는 것 같습니다. CoT는 같은 prompt 안에서 지칭 표현을 찾고 -> 맥락으로 해석하고 -> 계획하라고 시킵니다. 그래서 planner가 여전히 긴 맥락, 추론 과정, planning을 한 번에 처리해야 합니다. 반면에 TOCC는 먼저 모호한 instruction을 명확한 instruction으로 rewrite하고, 그 결과만 planner에 넘깁니다.
2. 제 생각에는 불확실성 스코어를 쓰지 않은 이유가 해당 논문의 초점이 “모호성을 감지했는가”보다 모호한 지시가 실제 task success를 얼마나 망가뜨리는가에 있기 때문이라고 이해했습니다. 불확실성 스코어는 모델이 헷갈린다고 느끼는지를 볼 수는 있지만 로봇이 실제로 올바른 물체를 선택하고 task를 끝냈는지는 직접 보여주지 못한다고 생각이 드는데요. 또 모호한 표현이 있어도 context로 충분히 풀 수 있는 경우가 있고 반대로 모델이 확신하면서 틀리는 경우가 있기 때문에 이를 보기 위해서 success rate까지 간 것이 아닐까? 생각이 듭니다.
감사합니다.
안녕하세요 주연님, 좋은 리뷰 감사합니다!
TOCC를 통해 모호한 표현을 먼저 명확한 표현으로 바꾼 뒤 planning을 수행하는 방법론이라고 이해했습니다.
CoT가 프롬프트가 길고 latency가 크다고 설명되고 있는데, TOCC도 clear한 instruction으로 바꾸는 과정에서 LLM 추론시간이 어느정도 걸릴 것 같은데, CoT와의 비교나 절대적인 처리 속도에 대한 설명이 논문에 언급되었는지 궁금합니다.
감사합니다!
좋은 질문 감사합니다.
처리 속도에 대해서도 appendix로 언급을 하였는데요. 속도적인 측면에서 CoT가 길게, TOCC가 짧게 나오는 것으로 확인하였습니다. 이 이유는 CoT가 한번에 굉장히 많은 것을 처리해야하기 때문인데요. TOCC의 경우, reasoning을 길게 출력하지 않고, planning 입력을 짧게 만드는게, 그것에 비해서 CoT는
1. 모호한 표현 찾고
2. 맥락 근거 설명하고
3. 지칭 대상 추론하고
4. instruction rewrite하고
5. planning까지 한번에 처리하게 됩니다.
이 때문에 CoT가 느리게 동작하게 됩니다.
감사합니다.