안녕하세요. 오늘 리뷰할 논문은 ICLR 2024에 발표된 AntGPT입니다. AntGPT는 영상을 입력 받아 영상 이후에 나올 사람의 행동을 예측하는 long-term action anticipation(이하 LTA) 문제에 대규모 언어 모델(Large Language Model, LLM)을 결합한 연구입니 가설에서 출발합니다. 비교적 단순한 구조로 여러 벤치마크에서 SOTA를 달성하여 이후 LLM 기반 행동 예측 연구의 baseline이 된 논문이라 리뷰하려 합니다.
Introduction
LTA는 1인칭 영상이 입력으로 들어오면 주어진 영상 이후에 이어질 사람의 행동을 동사와 명사의 시퀀스로 예측하는 task입니다. 일반적인 action anticipation은 short-term anticipation(이하 STA)로 영상 뒤에 이어지는 단일 행동을 예측하는 반면 LTA는 비교적 먼 미래까지 여러 개의 행동을 순서대로 예측해야하기 때문에 예측의 불확실성이 커지고 LTA에서는 정답 하나를 맞추는 것보다는 그럴듯한 행동의 연속을 예측하는 문제입니다.
저자는 LTA를 두 가지 상호보완적인 관점으로 판단합니다. 첫번째는 bottom-up 관점입니다. 관찰된 행동들의 temporal dynamics를 모델링하여 다음에 올 행동을 autoregressive하게 이어붙이는 방식입니다. 두번째는 반대로 top-down 관점입니다. 행동을 하는 주체의 장기적인 goal을 예측하고 먼저 추론한 뒤에 goal을 달성하기 위해 필요한 절차를 거꾸로 계획하는 방식입니다. top-down 방식이 goal을 정확하게 이해한다면 예측을 훨씬 정교하게 할 수 있기 때문에 더 안정적이지만 기존 LTA 벤치마크에는 goal label이 존재하지 않기 때문에 goal은 데이터 안에 잠재(latent)되어 있고 명시적으로 존재하지 않습니다. 따라서 goal-conditioned planning을 바로 적용하기는 어렵습니다.
저자는 여기에서 LLM을 활용합니다. 기존의 LTA는 LLM을 활용하지 않고 bottom-up 방식만을 활용했었습니다. 저자는 recipes, how-to와 같은 절차적인 텍스트로 사전학습된 LLM이 사람 행동의 시간적 흐름에 대한 유용한 prior를 이미 인코딩할 수 있다는 사실을 전제로 LLM이 “지금의 행동 다음에는 보통 어떤 행동이 오는가”와는 bottom-up 질문과 “관찰된 행동을 바탕으로 사람의 goal이 무엇인가”라는 top-down 질문 모두에 답변할 수 있다는 것을 활용합니다.
요리를 예시를 들어 설명드리겠습니다. 만약에 누군가가 달걀을 깨는 행동(crack eggs)를 관찰했다면 그 다음에는 달걀을 젓는 행동(mix eggs)이 올 가능성이 높다는 사실을 bottom-up으로 예측할 수 있습니다. 더 나아가 만약 그 사람의 goal이 달걀 볶음밥 만들기(making egg fried rice)라는 사실을 모델이 알고 있다면 남은 절차를 top-down으로 더 정확하게 계획할 수 있습니다. 저자는 이러한 예시를 들며 다음 행동에 대한 prior와 goal 추론이라는 두가지 능력이 모두 LTA에 필요하며 그 두 능력을 LLM이 제공할 수 있다는 점을 강조하며 LLM을 활용하는 패러다임의 중요성을 강조합니다.
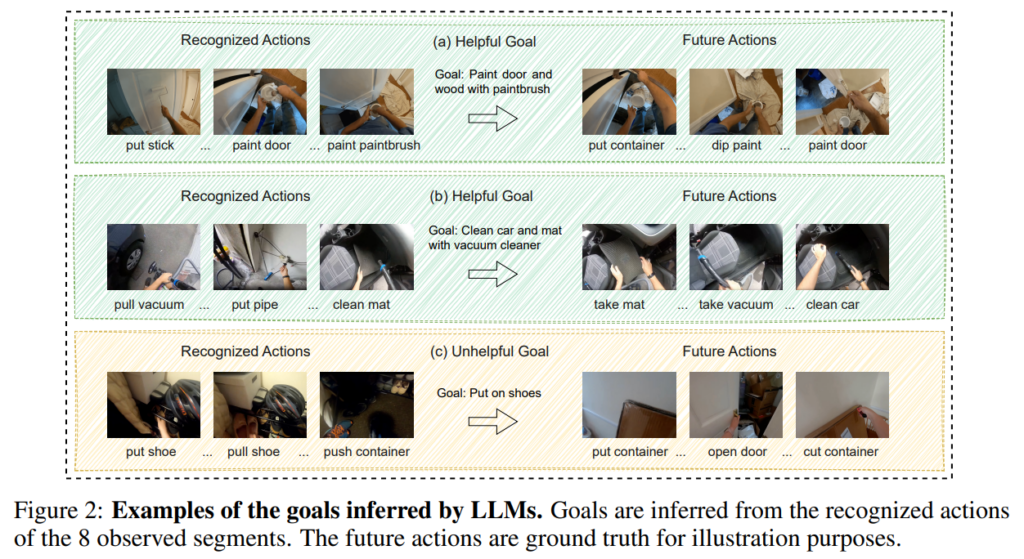
Fig 2는 LLM이 LTA에서 goal을 추론하는 것을 보여주는 정성적 예시입니다.
Method
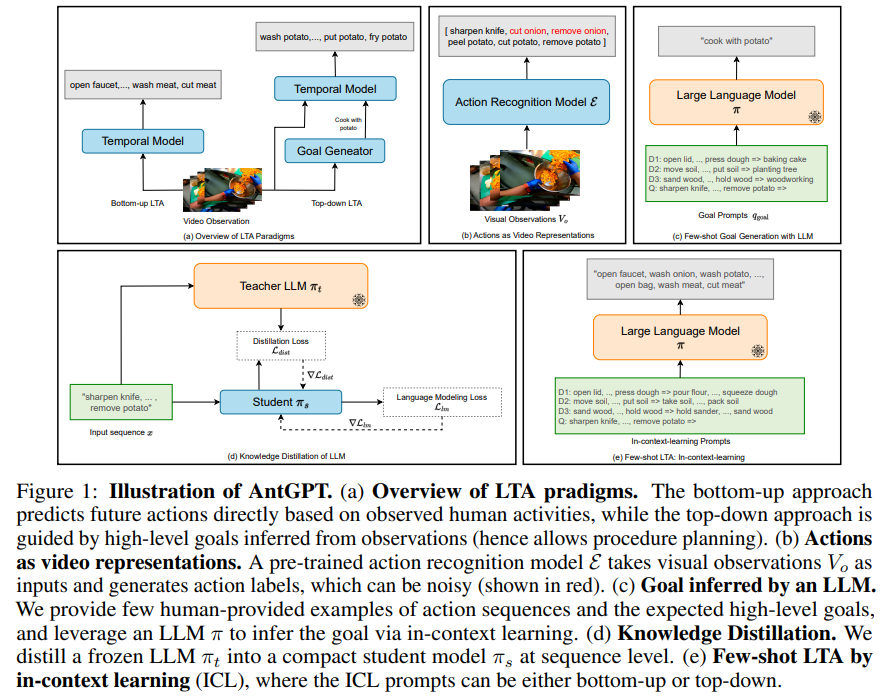
저자가 제안하는 AntGPT(Action Anticipation GPT)의 가장 핵심적인 설계는 당연히 LLM을 활용하는 방식입니다. LLM에 raw 이미지를 직접 입력하는 것이 아니라 LLM에 익숙한 형태인 action label의 시퀀스로 압축하여 입력합니다. Fig 1은 (a)부터 (e)까지 AntGPT의 sub sequence를 보여줍니다. (a)는 bottom-up와 top-down의 두가지 패러다임을 보여주고 (b)는 recognition 모델이 observation으로부터 행동 라벨을 생성하는 단계 (c)는 LLM이 in-context learning을 통해 goal을 추론하는 과정 (d)는 teacher LLM이 student LLM으로 압축하는 knowledge distillation (e)는 bottom-up 혹은 top-down 프롬프트를 사용하여 few-shot을 진행하는 in-context learning을 보여줍니다. 단계는 굉장히 많아보이지만 크게는 영상을 행동 라벨로 변환하는 1단계와 변환한 라벨을 LLM에 입력하는 것으로 추론하는 2단계로 구성됩니다.
하나의 긴 영상 V는 순서가 있는 N개의 짧은 segment 집합 \{S^j,a^j\}^N_{j=1}로 나뉩니다. 여기서 S^j는 j번째 구간이고 a^j는 action 라벨로 명사-동사 쌍 (n^j, v^j)의 형태로 구성됩니다. 영상에는 마지막으로 관찰된 구간의 인덱스를 뜻하는 T가 주어지며 이를 기준으로 관찰 구간 V_o와 미래 구간 V_f로 나뉩니다. 모델은 N_{seg}개의 관찰 구간을 입력으로 받아 미래 행동을 예측합니다.
저자는 bottom-up 단계는 \{{\hat{a}^{(T+1)}, …, \hat{a}^{(T+Z)}}\} = F_{bu}(V_o)로 관찰 영상을 토대로 미래 행동을 예측합니다. top-down 모델은 두 단계로 나뉘는데 goal을 g=G_{td}(V_o)로 추론한 뒤 \{\hat{a}^{(T+1)}, ..., \hat{a}^{(T+Z)}\} = F_{td}(V_o, g)로 goal을 조건으로 미래 행동을 계획합니다. 당연하지만 g는 goal, bu는 bottom-up, td는 top-down을 의미합니다. 미래의 불확실성을 다루기 위해서 모델은 정답 하나만 추론하는 것이 아니라 K개의 후보 시퀀스를 출력하고 그 중에 가장 정답과 가까운 후보로 평가합니다.
이제 각 단계를 자세히 설명드리겠습니다. 첫 단계는 영상을 LLM이 읽을 수 있는 action label로 바꿔주는 recognition 모델입니다. 저자는 각 구간 S^j에서 n개의 프레임을 균일하게 샘플링한 뒤 freeze된 CLIP encoder로 프레임 임베딩 E^j = {e_1, ..., e_n}을 추출합니다. recognition 모델은 트랜스포머 인코더로 구성되어 무작위로 부분 샘플링한 임베딩과 하나의 learnable query token을 입력으로 받아 인코딩된 query token을 두 개의 MLP head로 디코딩해 동사와 명사를 각각 예측합니다. 학습은 예측과 GT action 라벨사이의 크로스 엔트로피 loss로 학습됩니다. 이 결과로 action label을 명사-동사 쌍 형태로 출력되어 LLM에 입력되는 text 형태의 video representation이 됩니다. 영상을 일찍 텍스트 label로 압축하는 저자의 이 설계는 LLM이 익숙한 형태로 입력을 만들어준다는 장점이 있는 반면 recognition이 틀리면 그 오류가 그대로 LLM 단계로 전파된다는 단점도 있습니다. 실제로 뒤의 실험에서 저자는 recognition 품질이 최종 LTA 성능을 좌우하는 가장 중요한 요소 중 하나임을 반복적으로 강조합니다. 개인적으로는 이 부분이 AntGPT의 성능을 결정하는 지점이라고 생각합니다.
다음 단계는 action label을 LLM에 입력하여 미래 행동을 추론하는 단계입니다. 먼저 bottom-up 방식부터 설명하면 저자는 bottom-up을 두 가지로 구현하는데 하나는 recognition 모델과 구조가 유사한 트랜스포머 인코더 기반의 모델입니다. 부분 샘플링한 visual embedding E^j_s를 시간 축으로 이어붙여 입력으로 받고 예측할 미래 step 수만큼 learnable query token을 추가한 뒤 각 query token을 두 개의 MLP head로 디코딩해 동사와 명사를 예측합니다. 이때 query token에 bidirectional attention을 적용하면 병렬적으로 예측하고 causal attention을 적용하면 autoregressive하게 예측하게 되는데 저자는 두 방식의 성능 차이가 크지 않아 기본적으로 parallel decoding을 사용합니다. 다른 하나는 LLM 기반 방식으로, 관찰된 action label을 이어붙인 문자열을 입력으로 주고 LLM이 미래 행동 시퀀스를 이어서 생성하도록 합니다. 이 과정은 LoRA를 활용하여 학습했다고합니다. 저자는 이러한 과정에서 goal을 명시적으로 주지 않아도 이렇게 LoRA로 파인튜닝된 LLM이 충분히 경쟁력 있는 성능을 낸다는 것입니다. 저자는 이를 LLM이 시퀀스를 이어가는 과정에서 goal을 암묵적으로 가정하고 있는 것으로 해석합니다. 즉 명시적인 top-down 없이도 LLM 내부에 어느 정도 goal 추론 능력이 내재되어 있다는 걸 의미합니다.
다음은 top-down 방식입니다. top-down은 goal을 먼저 추론하는 단계와 그 goal을 조건으로 행동을 계획하는 단계로 나뉩니다. goal inference에서는 데이터에 goal label이 없기 때문에 저자는 video metadata를 pseudo goal로 사용하여 학습했다고 합니다. 이렇게 추론한 goal은 CLIP text encoder로 임베딩한 뒤 visual embedding token들 앞에 붙여 goal을 조건으로 미래 행동을 예측하는 데 사용됩니다. 추가로 저자는 학습 없이 LLM의 in-context learning 능력만으로 LTA를 수행하는 few-shot 실험도 진행합니다. 이때 프롬프트는 task와 출력 형식, 동사, 명사 vocabulary를 설명하는 instruction과 무작위로 뽑은 in-context 예시, 그리고 마지막 query로 구성됩니다. 또한 chain-of-thought(CoT) 프롬프트를 사용하면 “먼저 goal을 추론하고 그 goal을 조건으로 LTA를 수행하라”는 과정을 한 번에 few-shot으로 시킬 수 있는데 실험에서 few-shot 설정의 경우 이 top-down과 CoT를 결합한 방식이 동사와 명사 모두에서 가장 좋은 성능을 보였습니다.
마지막으로 Knowledge Distillation입니다. 저자는 7B 모델의 LLM의 추론비용이 꽤 크기 떄문에 LLM의 사전지식을 작은 모델로 옮길 수 있는 지를 확인합니다. 잘 학습된 LLM을 teacher로 두고 작은 모델을 student로 두고 language modeling loss와 distillation loss를 활용하여 distillation합니다.
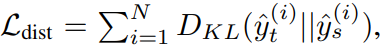
Fig 1.의 (d)에 해당하며 KL는 Kullback-Leibler divergence를 의미합니다.
Experiments
저자는 3개의 벤치마크에서 평가를 진행합니다. Ego4D, EPIC-Kitchens-55, EGTEA Gaze+입니다. 세 벤치마크 모두 LTA 벤치마크입니다. Ego4D의 평가지표는 edit distance(이하 ED)입니다. 동사, 명사, 행동 시퀀스에 대한 Damerau-Levenshtein거리입니다. K=5개의 후보 중 최소값을 취하고 미래 Z=20개 행동에 대해 계산하기 때문에 ED@20으로 표기합니다. edit distance이기 때문에 낮을수록 좋은 성능을 의미합니다.
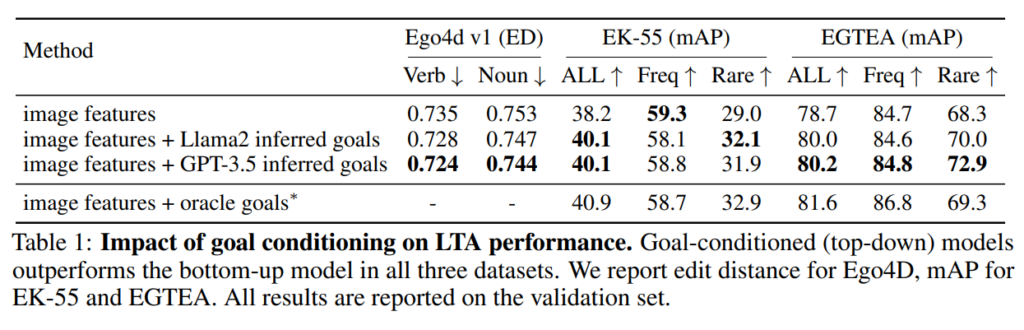
Tab 1.은 저자의 goal 추론이 도움이 되는지를 확인합니다. 신기한거는 영상 메타데이터로 만든 oracle goal을 사용해도 성능이 약간만 더 좋아졌는데 이는 추론된 goal이 이미 충분히 경쟁력 있는 향상을 제공한다는 것을 의미한다고 저자는 주장합니다. 앞서 보여드린 Fig 2가 바로 이때 Llama2가 추론한 유용한 goal과 그렇지 못한 goal의 예시입니다.
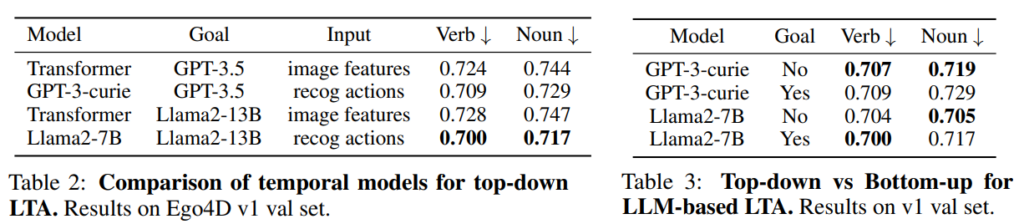
저자는 LLM이 정말로 temporal dynamics를 모델링하는지 그렇다면 왜 도움이 되는지를 분석합니다. 저자는 goal conditioning의 효과만 따로 보기 위해 동일한 Transformer encoder temporal model을 사용해 bottom-up과 top-down을 비교합니다.
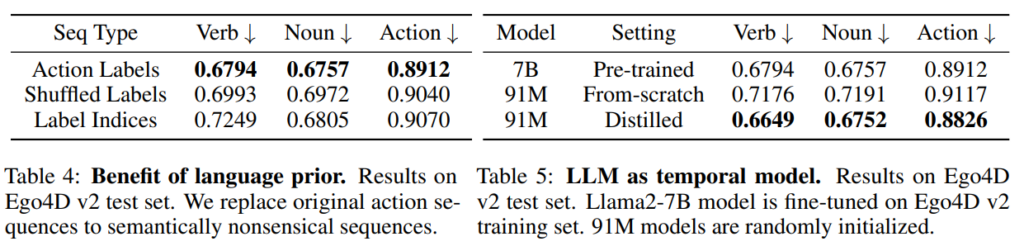
위 실험들은 semantic perturbation을 보여주는 실험입니다. action label을 무작위로 섞거나(shuffle) 의미 없는 인덱스로 치환하면 성능이 일관되게 떨어졌는데 저자는 이를 통해 LLM이 단순히 행동의 통계적 순서만 학습하는 것이 아니라 label이 담고 있는 언어적 의미, 즉 language prior를 실제로 활용한다고 주장합니다. knowledge distillation 결과도 인상적입니다. 91M student 모델이 세 지표 모두에서 7B teacher를 오히려 능가했고 같은 크기를 처음부터 학습시킨 모델 대비 개선을 보였습니다. 저자는 이를 통해 LLM의 시간 모델링 능력이 거대한 parameter에만 담겨 있는 것이 아니라 원본의 약 1.3% 크기 모델로도 충분히 옮길 수 있음을 보여줍니다.
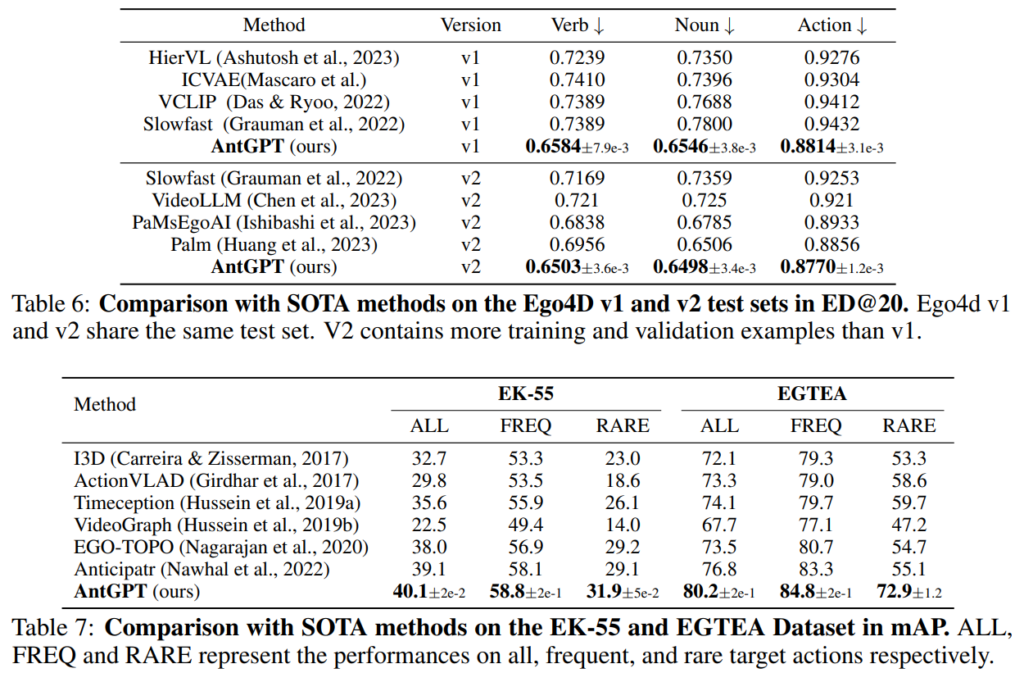
기존 SOTA 모델들과의 비교를 확인해도 꼬ㅒ 유의미하게 앞서는 것을 확인할 수 있습니다. 특히 EGTEA에서의 RARE 성능이 많이 높은데 저자는 LLM의 도움을 받는 것인 특히 데이터가 적을 때에 효과적이기 때문이라고 설명합니다. LTA task에서 처음으로 LLM을 활용한 논문이라서 fair comparison을 위한 백본 사용 등은 표에서는 보이지 않는 것 같습니다.
Conclusion
정리하면 AntGPT는 영상을 action label text로 압축해 LLM에 입력한다는 단순한 설계만으로 LLM의 사전지식이 LTA 성능을 향상시킬 수 있음을 보여준 논문입니다. 다만 1단계 recognition 오류가 그대로 전파된다는 점, LLM 입력 프롬프트 설계가 여전히 경험적이라는 점, 그리고 영상을 일찍 텍스트로 압축하면서 미세한 시각 정보를 잃는다는 점은 한계로 남습니다. 그럼에도 영상 모델의 약한 long context를 텍스트 기반 LLM의 prior로 보완하는 recognition 후 LLM을 fine-tuning하는 이 2단계 구조는 이후 여러 후속 연구에서도 활용되는 효율적인 방법입니다.
감사합니다.
안녕하세요. 성준님 좋은 리뷰 감사합니다.
AntGPT는 처음에는 goal을 먼저 추론하는 top-down 방식이 중요한 것처럼 보였는데, 실험에서는 LLM이 명시적인 goal 없이도 action label sequence를 이어서 생성하면서 좋은 성능을 내는 것으로 이해했습니다.
그렇다면 이 논문의 핵심 contribution은 goal inference 모듈 자체라기보다는, 영상을 action label이라는 언어 시퀀스로 바꾸었을 때 LLM의 절차적 사전지식이 미래 행동 예측에 활용된다는 점으로 봐도 될까요? 이 부분을 어떻게 해석하셨는지 궁금합니다.
감사합니다.
안녕하세요. 정의철 연구원님 좋은 댓글 감사합니다.
말씀해주신 것처럼 LLM의 절차적 사전지식이 미래 행동에 활용되는 부분이 중요한건 맞습니다만 저자가 강조하는 top-down 방식이 중요하지 않은 것은 아닙니다. Table 1에서 볼 수 있듯이 goal에 기반한 예측을 수행할 때에 성능이 많이 개선되기 때문입니다. 물론 LLM의 절차적 사전지식을 활용하기에 성능이 오른것도 사실입니다. top-down 방식에서 goal을 추론하기위해 LLM을 활용하고 미래행동 예측에 LLM의 절차적 사전지식도 활용하기에 결론은 둘다 중요한 것 같습니다..!
감사합니다.