안녕하세요. 이번에 리뷰로 가져온 논문은 CVPR 2026에 올라온 SocialNav: Training Human-Inspired Foundation Model for Socially-Aware Embodied Navigation라는 논문이고 oral 페이퍼입니다.
이 논문은 제목 그대로 socially-aware embodied navigation 로봇이 단순히 목적지까지 잘 가는 것을 넘어서 사람이 보기에 사회적으로 자연스럽고 적절한 방식으로 이동하는 내비게이션 모델을 제안하는 논문입니다.
기존 visual navigation 연구들은 보통 목적지까지 잘 도착하는지 충돌은 안했는지 효율적인 경로로 갔는지를 중요하게 봤는데 사실 실제 도심이나 캠퍼스 공원 같은 환경에서는 이것만으로는 부족하다고 합니다. 예를 들어 로봇이 횡단보도가 아닌 곳으로 가거나 사람이 다니면 안 되는 구역을 지나간다면 충돌은 안 했더라도 사회적으로는 부적절한 행동일 수가 있습니다. 그래서 저자들은 이런 사회적으로 허용되는(?) 경로를 이해하고 선택하는 단순하게 말하면 실제 사람처럼 움직이는 그런 모델을 설계하고자 합니다. 자세한 내용은 아래 리뷰에서 다루도록 하겠습니다.
Introduction
기존의 embodied navigation 모델들은 대부분 이미지나 goal 정보를 해당 목적지에 잘 도착하는지에만 초점이 맞춰져서 학습하는 방식입니다. GNM, ViNT, NoMaD, CityWalker 같은 모델들도 큰 흐름에서 보면 visual navigation policy의 일반화 성능을 높이는 데 초점이 맞춰져 있고 실제 사람처럼 움직이는 방법을 명시적으로 배우지는 않습니다. 예를 들어 로봇 입장에서는 잔디밭을 가로질러 가는 것이 가장 빠를 수 있는데 사람 입장에서는 보도를 따라 돌아가는 것이 더 자연스럽고 사회적으로도 맞는 행동입니다. 해당 논문은 이런 사회적으로 적합한 행동 기준을 social compliance라고 보고 navigation policy가 이 기준까지 함께 만족해야 한다고 주장합니다.
저자들이 제안하는 SocialNav는 크게 두 가지 능력을 동시에 가지도록 설계됩니다.
첫 번째는 사회적 규칙을 이해하는 능력입니다. 예를 들어 여기는 잔디밭이라 지나가면 안된다 처럼 high-level semantic reasoning을 할 수 있는 능력이라고 보시면 좋을 것 같습니다. 그리고 두 번째는 앞선 reasoning을 바탕으로 앞서 high level의 결과를 가지고 실제 trajectory로 바꾸는 능력입니다. 실제 로봇이 따라갈 수 있는 waypoint나 action sequence로 변환하는 능력이라고 보시면 좋을 것 같습니다. 이 두 가지를 위해 저자들은 SocialNav를 Brain-Action hierarchical architecture로 구성합니다.
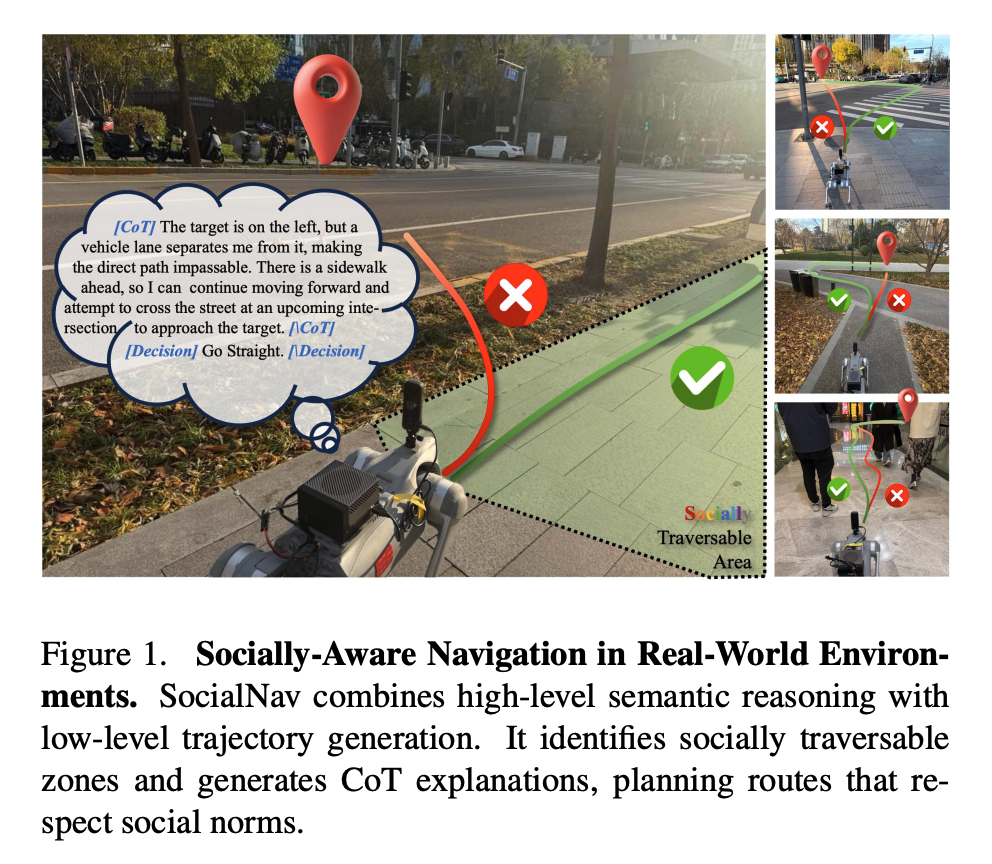
위 fig 1은 SocialNav가 scene을 보고 socially traversable area를 인식하고,그에 맞는 경로를 생성하는 전체 컨셉을 직관적으로 보여주는 그림이라고 보시면 좋을 것 같습니다.
SocNav Dataset & Benchmark
그리고 저자들은 모델 구조만 제안한 것이 아니라,이를 학습시키기 위한 데이터셋과 평가 benchmark까지 함께 제안합니다. SocNav Dataset라는 대규모 데이터셋을 만드는데 약 7M개의 샘플로 구성되어있다고 하고 모든 데이터의 형태가 동일한게 아니라 크게 두 가지 형태로 분리되어서 구성되어있습니다. 하나는 reasoning을 위한 학습데이터(CAD), 하나는 action generation을 위한 데이터(ETP) 이렇게 보시면 좋을 것 같습니다. 각각에 대해서 자세하게 설명드리도록 하겠습니다.
ETP(Expert Trajectories Pyramid)
이 부분은 실제 navigation trajectory를 학습하기 위한 데이터라고 보시면 좋을 것 같습니다. 인터넷 비디오, 시뮬레이션, 실제 로봇 데이터까지 포함된 데이터입니다.
인터넷 비디오 데이터(D_{video})는 다양한 도시 환경에서 수집된 영상으로부터 pseudo trajectory를 만드는 방식이고 시뮬레이션 데이터(D_{sim})는 Isaac Sim이랑 3DGS 기반 scene을 활용해서 생성된다고 보시면 좋을 것 같습니다. 특히 SocCity라는 dynamic urban scene도 포함되어 있고 동적인 객체인 보행자나 vehicle이 있는 상황에서 trajectory를 생성했다고 합니다.
실제 로봇 데이터(D_{real})는 SCAND, Huron, Recon, CityWalker teleoperation data 등을 포함합니다. 이 데이터는 실제 물리적 dynamics와 sensor noise를 포함하기 때문에 나중에 자세히 설명드리겠지만 모델 학습시 sim-to-real gap을 줄이는 데 사용됩니다.
CAD(Cognitive Activation Dataset)
이 부분이 기존 방식들과 다른 SocialNav의 차별점이라고 볼 수 있는데, 일반 navigation trajectory만 넣는 것이 아니라 모델이 사회적 규칙을 이해하도록 하기 위한 cognition 데이터입니다.
CAD에는 socially traversable region annotation, navigation chain-of-thought, VQA 데이터가 포함됩니다. 예를 들어 이미지에서 어디가 사회적으로 지나가도 되는 영역인지를 polygon 형태로 예측하게 하거나 왜 이 경로를 선택해야 하는지에 대한 CoT reasoning을 학습시키기 위한 데이터라고 보시면 좋을 것 같습니다.
그리고 저자들은 Benchmark도 따로 제안합니다. SocNav Benchmark는 Isaac Sim + 3DGS 기반으로 9개의 large-scale social scene으로 구성되어 있고, 공원, 길거리 도로, 오피스, 캠퍼스 같은 환경을 포함합니다. 평가 시에는 Unitree Go2 robot을 사용하고, 각 scene마다 20m / 100m 거리의 start-goal pair를 구성했다고 합니다.

위는 SocNav Dataset & benchmark를 직관적으로 보여주는 그림입니다. 정리하면 SocNav Dataset은 ETP와 CAD로 나뉜다고 benchmark가 Isaac Sim + 3DGS 기반으로 구성되는 전체 구조를 보여줍니다.
Method
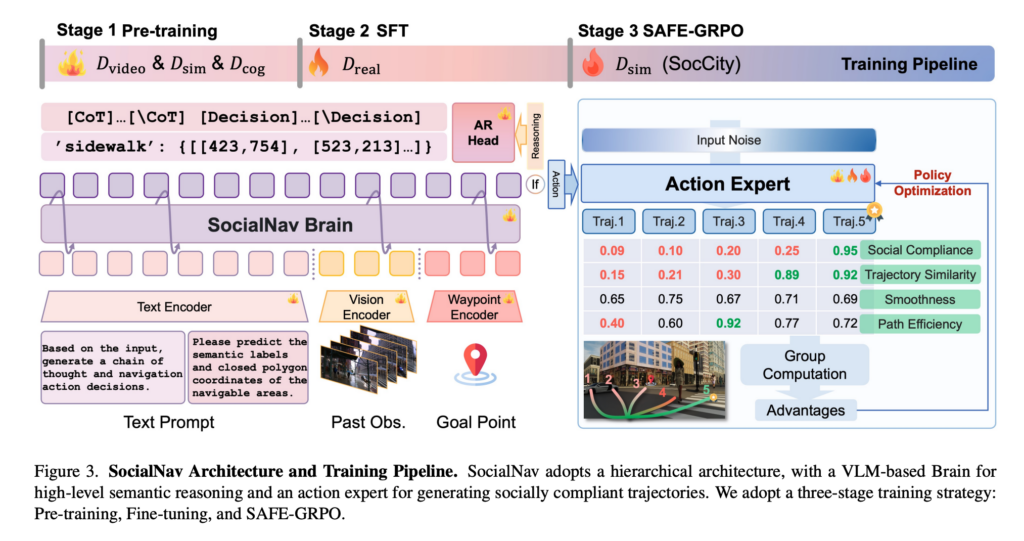
SocialNav의 구조는 크게 Brain Module과 Action Expert로 나뉩니다. Brain Module이 사람처럼 이해하고 움직일 수 있도록 high level의 resoning을 담당하는 친구고 action Expert는 해당 reasoning을 기반으로 action traj를 생성하는 모듈이라고 이해하시면 좋을 것 같습니다.
위 아키텍쳐에서 왼쪽이 Brain Module이라고 보시면 좋을 것 같습니다. Brain Module은 Qwen2.5-VL을 사용했다고하고 이 모듈의 역할은 이미지,텍스트, goal pose를 보고 high-level semantic reasoning을 수행한다고 보시면 좋을 것 같습니다.
그리고 Brain Module은 3가지를 내뱉습니다. socially traversable region(폴리곤 형태 좌표값), navigation decision에 대한 chain-of-thought 결과, scene understanding을 위한 VQA 결과 이렇게 3가지의 output을 뱉습니다. 이 환경에서 어디가 사회적으로 이동 가능한 영역인지를 이해하도록 만드는 역할을 하는 모듈이다라고 보시면 될 것 같습니다.
Action Expert는 실제 trajectory를 생성하는 부분안데 이 부분은 conditional flow matching 기반으로 설계되어 있습니다. Brain Module이 제공한 semantic prior를 바탕으로 앞으로 이동할 waypoint sequence를 생성하는 모듈이라고 보시면 될 것 같습니다. 여기서 중요한 건 Brain과 Action이 완전히 분리된 게 아니라 socialNav Brain의 VLM feature가 Action Expert에 condition으로 들어가는 형태입니다. 그래서 Action Expert는 Brain이 이해한 social semantic 정보를 반영해서 action traj 를 생성한다고 보시면 좋을 것 같습니다.
그리고 학습은 세 단계로 진행됩니다.
1 stage 에서는 D_{video}, D_{sim}, D_{cog}를 사용해서 전체 모델을 full 튜닝합니다. 여기서 D_{real}은 쓰이지 않습니다. 이 단계에서 모델은 기본적인 genaral한 navigation 능력이랑 social reasoning 능력을 같이 배우게 된다고 합니다. D_{video}는 다양한 real-world의 visual prior를 제공하고, D_{sim}같은 경우는 rare case를 보완 할 수 있다고 합니다. 그리고 D_{cog}는 CoT, VQA, traversability prediction을 통해 Brain Module이 사회적 규칙을 이해하도록 돕습니다.
2 stage에서는 실제 로봇 trajectory인 D_{real}을 사용해서 파인튜닝합니다. 이때 VLM은 freeze하고, Action Expert만 학습합니다. 이 데이터는 실제 물리적 dynamics와 sensor noise를 가지고 있어서 실제 로봇들의 물리적 dynamics를 반영하고 실제 real 환경에서 잘 동작하게 하기 위해서 이런식으로 action expert만 파인튜닝하는 것 같습니다.
3 stage가 이 논문의 핵심 중 하나인 SAFE-GRPO입니다. 저자들은 IL만으로는 사회적 규칙을 충분히 잘 따르기 어렵다고 합니다. 왜냐하면 IL은 결국 demonstration을 따라 하는 방식이라서 왜 이 행동이 사회적으로 적절한지에 대한 causal understanding이 부족할 수 있기 때문입니다. 여기서 causal understanding은 원인과 결과에 대한 이해라고 보시면 좋을 것 같습니다. 그래서 저자들은 SAFE-GRPO라는 RL 단계를 추가했다고 합니다. 이때 리워드는 단순히 goal에 빨리 도착하는 것만 보지 않고 사회적으로 traversable한 영역을 잘 따라가는지랑 expert trajectory와 비슷한지, 움직임이 부드러운지, goal로 효율적으로 가는지를 함께 보고 설계했다고 합니다.
Experiments
실험은 크게 세 가지로 진행됩니다.
첫 번째는 CityWalker benchmark에서의 open-loop evaluation입니다.
두 번째는 저자들이 제안한 SocNav Benchmark에서의 closed-loop evaluation입니다.
세 번째는 실제 Unitree Go2 robot을 사용한 real-world deployment입니다.
Open-loop Evaluation
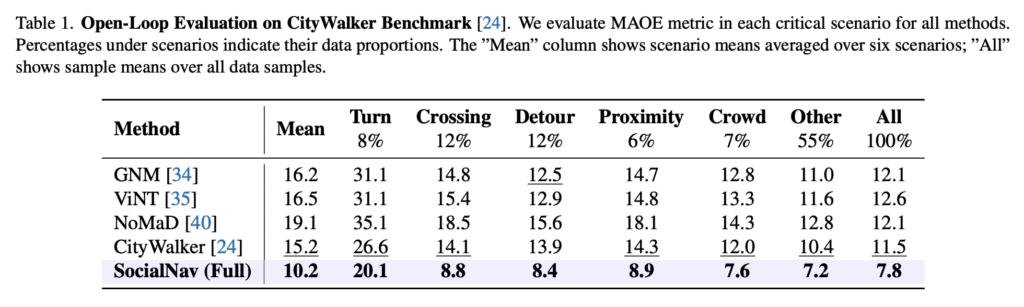
Open-loop에서는 CityWalker benchmark를 사용하고 metric으로 MAOE만 사용합니다. 여기서 SocialNav는 기존 베이스라인보다 낮은 error를 보입니다. 여기서 MAOE 모델이 예측한 action traj와 gt traj간 각도 오차라고 보시면 좋을 것 같습니다. 여기서 SocialNav가 단순히 전체 평균에서만 좋은 것이 아니라, crossing이나 crowd 같은 사회적 판단이 필요한 상황에서도 성능이 좋은 결과를 보입니다.
Closed-loop Evaluation
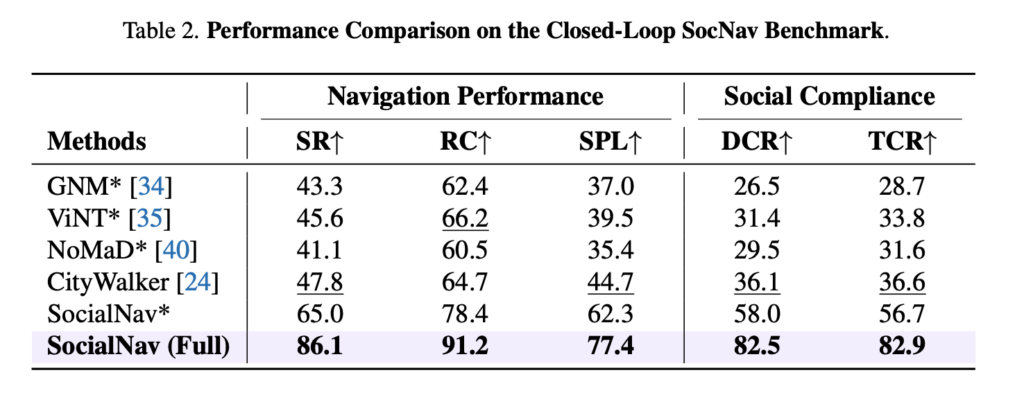
Closed-loop에서는 저자들이 제안한 SocNav Benchmark를 사용합니다. 여기서는 SR, RC, SPL 같은 navigation metric뿐 아니라 로봇이 얼마나 사회적으로 적절한 영역 안에서 이동했는지를 보기 위해서 DCR, TCR이라는 이런 social compliance metric도 함께 봅니다. DCR은 성공한 episode에서 로봇이 실제 이동한 거리 중 얼마나 많은 비율을 사회적으로 허용 가능한 영역 안에서 이동했는지를 나타낸거고 TCR도 DCR이랑 비슷한데 다만 거리 기준이 아니라 시간 기준으로 측정한 지표라고 보시면 좋을 것 같습니다.
위 결과를 보면 SocialNav Full 모델이 모든 메트릭에서 가장 좋은 성능을 보이고 *이 붙은건 D_{real} 데이터만으로 학습한 세팅이라고 하는데 이게 3-stage 방식에서 어떤식으로 학습을 했는지는 모르겠습니다.

위는 정성적 결과입니다. CityWalker baseline은 잔디밭이나 restricted region을 가로지르는 반면 SocialNav는 보도를 따라서 잘 주행하는 결과를 보입니다.
Real-world Deployment
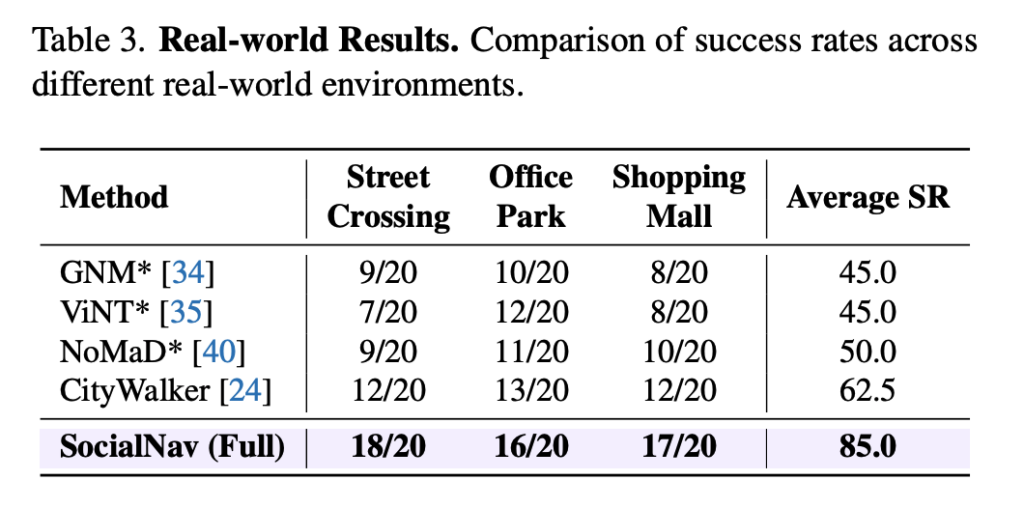
저자들은 실제 Unitree Go2 robot을 사용해서 street crossing, office park, shopping mall 세 가지 환경에서 실험합니다. 각 환경마다 20번씩 trial을 수행했고 결과적으로 기존 베이스라인 대비 SocialNav가 가장 높은 성공률을 보입니다.
Ablation Study
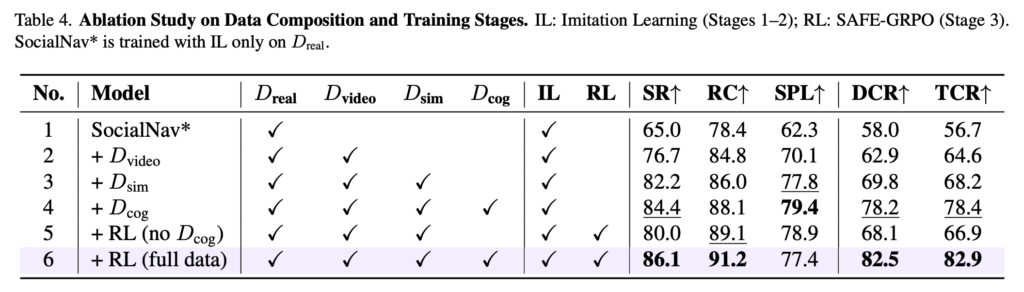
Dcog를 추가하면 DCR이 크게 올라갑니다. 단순히 trajectory를 많이 넣는 것보다 social traversability나 CoT reasoning 같은 cognitive signal이 social compliance를 높이는 데 중요하다라는 것을 보여주는 결과 입니다. 그리고 여기서 RL을 적용하면 SPL이 79.4에서 77.4로 살짝 떨어집니다. 이 부분에 대해서는 저자들은 이를 사회적으로 적절한 행동을 하다 보면 최단 경로를 포기해야 하는 경우가 있기 때문이라고 설명합니다. 사회적 규범을 지키는 주행에 있어서는 SPL은 엄청 중요한 지표는 아닐 수 있다라고 보시면 좋을 것 같습니다.
Conclusion
뭔가 2025년 mobile robot navigation 쪽 논문들을 읽었을 때의 아쉬웠던 점은 closed loop에 대한 벤치마크가 없다는 점이었고 그래서 self eval 결과에 대한 의문이 많았었는데 2026년 논문들에서는 이제 해당 분야에도 수많은 벤치마크가 나오고 있는 추세인 것 같습니다. 근데도 여기서 짚고 넘어가야할 부분은 사실 기존 베이스라인 모델들은 상대적으로 가벼운 visual navigation policy에 가깝고, 대부분 단일 시각 모달리티 기반으로 설계된 반면 SocialNav는 Qwen2.5-VL 기반에, 2D position, goal input, language reasoning, social traversability supervision, 추가적인 데이터, 그리고 SAFE-GRPO까지 활용합니다. 추론할 때에도 고사양 GPU 서버에서 돌린다고 합니다. 이 성능 향상이 과연 SocialNav architecture만의 순수한 우위일까라는 생각이 들긴합니다. 중간에 사실 D_real로만 학습시킨 결과가 있긴한데 이것도 딱 하나의 테이블에만 리포팅을 해서 살짝 아쉽긴 합니다. 근데 또 반대로 이건 개인적인 생각이지만 로보틱스 분야에서는 결국 어플리케이션 관점에서 베이스라인들과의 비교보다는 실제 urbanNavigation을 잘 수행했는지 실제 라스트마일 배송을 잘 할 수 있는지만을 봤을 때 이런 세팅이 상대적으로 중요하지 않을 수도 있겠구나 라는 생각이 드는 것 같습니다. 이만 리뷰 마치도록 하겠습니다.
안녕하세요. 우현님, 좋은 리뷰 감사합니다.
socially-aware navigation이라는 분야의 논문은 처음 읽은 것 같은데 덕분에 쉽게 이해할 수 있었습니다. congnitive를 추가한 것이 가장 인사이트가 있었고 실제로 성능에도 많은 향상을 보여준것 같습니다. d_cog가 제일 중요한 역할인데 제가 리뷰 내용을 다 파악하지 못해서인지 이게 무엇인지 잘 모르겠습니다. 제 생각에는 brain module? 혹은 branin module이 내뱉은 output 중 하나?일거 같은데 맞을까요?
그리고 인상깊게 본 것이 VQA를 사용했다는 것인데, navigation은 실시간으로 경로를 파악하는 것이 중요한 task인거 같은데 VQA를 사용하게 되면서 latency가 느려지면 navigation의 성능 하락으로도 이어질 수 있을 것 같다는 생각도 했습니다. 그런데 experiment 결과를 보니 성능이 높게 나와서 VQA를 활용한 방법론적으로 성능을 많이 가져간것 같다는 생각도 했습니다. 우현님께서는 이 부분에 대해서 어떻게 생각하시는지 궁금합니다.
감사합니다.
안녕하세요 우현님 좋은 리뷰 감사합니다.
재밌게 읽으면서 질문이 생겨 댓글 남깁니다.
저자들이 SAFE-GRPO를 추가한 이유가 IL은 단순히 모방하는 것이기 때문에 casual-understanding 능력을 기르기 위해서라고 이해하였습니다. 뒤에 설명이 이해가 잘 안가는데 사회적으로 traversable한 영역을 잘 따라가는지랑 expert trajectory와 비슷한지, 움직임이 부드러운지, goal로 효율적으로 가는지가 단순한 모방을 넘어 어떻게 casual understanding을 보장하는지가 궁금합니다.
좀 더 풀어서 설명하면 이동 가능한 영역, expert를 모방하는 능력, goal로 효율적으로 가는 것을 RL로 푸는 것이 어떻게 원인과 결과에 대한 이해와 사회적 규칙을 잘 따르게 하는지 궁금합니다.