안녕하세요 손우진입니다.
이번에 리뷰할 논문은 6D pose estimation 입니다. 그동안 thermal이나 VLA, 멀티센서 쪽을 주로 봤는데, 오랜만에 unseen object pose estimation 논문을 가져와봤습니다. 제목은 PoseGAM: Robust Unseen Object Pose Estimation via Geometry-Aware Multi-View Reasoning 입니다.
이 논문은 기존 unseen object pose 방법들이 거의 다 matching + PnP 구조에 묶여 있었는데, 이 논문은 matching 단계를 없애버리고 multi-view foundation model(VGGT 계열)에 객체 geometry를 끼워 넣어서 포즈를 직접 회귀해버린다는 점입니다. 최근 DUSt3R / VGGT 같은 멀티뷰 기반 모델들이 워낙 잘 나오다 보니, 이걸 pose estimation으로 끌고 온 시도라고 보시면 될 것 같습니다.

Figure 1이 이 논문의 한 장 요약입니다. CAD 모델들을 query 이미지의 공간 배치에 맞춰서 정렬시키는 게 목표인데, 빨간 평면이 초기 CAD 포즈, 초록 평면이 추정 후 포즈입니다.
Introduction
본격적으로 6D는 추정의 초기 연구들은 instance-level이나 category-level에 집중되어 있었는데, 이런 방식들은 학습 때 못 본 객체에는 일반화가 안 된다는 한계가 있었습니다.
그래서 최근에는 unseen object pose estimation 쪽으로 연구가 옮겨갔는데요, 기존 방법들은 대부분 match-localize 아니면 match-refine 중 하나를 따릅니다. 둘 다 공통적으로 query 이미지와 (객체의 3D 모델 or 포즈를 아는 template 이미지들) 사이의 feature correspondence를 구성합니다. 그렇게 대응점을 만든 다음 least-squares나 PnP 같은 geometric solver로 포즈를 푸는 구조인데 이것이 성능은 괜찮게 나왔지만 결국 matching 품질에 성능이 의존한다는 것이 문제입니다. 매칭이 불안정하면 포즈도 같이 무너집니다.
저자들은 해당 부분에서 문제 정의를 하고 matching 없이 end-to-end 네트워크로 포즈를 바로 뽑는 시도를 합니다. 그래서 VGGT, RayZer 같은 멀티뷰 foundation model을 가져와서, query 이미지와 여러 장의 template 이미지를 같이 넣고 포즈를 직접 추론하게 만듭니다.
하지만 이 멀티뷰 모델들을 그대로 쓰기엔 두 가지 문제가 있는데 우선, 이 모델들은 순수하게 이미지 입력만 받습니다. 카메라 포즈는 추정할 수 있어도, pose estimation에서 보통 주어지는 객체의 3D 모델 정보를 활용하지 못합니다. 다음으로는, view들끼리 형태가 일관되다고 가정합니다. 그런데 CAD 렌더링과 실제 관측 사이엔 domain gap이 커서, appearance 변화에 굉장히 민감합니다. 이 두 문제를 풀기 위해 저자들은 객체 geometry를 멀티뷰 구조에 주입하고, 대규모 합성 데이터셋을 구축합니다.
논문에서 저자들이 제시한 Contribution을 정리하면 다음과 같습니다.
- 멀티뷰 feedforward 네트워크 제안: query 이미지와 template 이미지를 입력으로 받아 end-to-end로 객체 포즈를 예측하며, 기존의 명시적 feature matching 단계를 제거했습니다.
- 객체 geometry 주입: explicit point map과 learned geometry representation을 멀티뷰 프레임워크에 넣되, raw geometry token을 그대로 쓰지 않고 view-map 형태로 투영해서 네트워크가 더 효과적으로 reasoning하도록 했습니다.
- 대규모 합성 데이터셋 구축: 조명, appearance 변화 등 다양한 시나리오를 포함한 19만 개 이상의 객체 데이터셋을 만들어 robustness와 일반화를 끌어올렸습니다.
Method
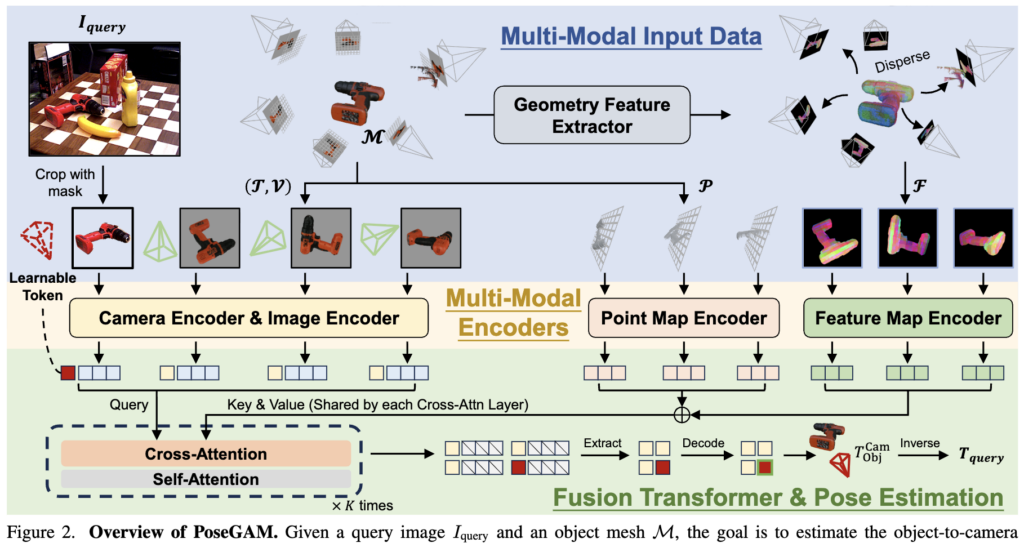
전체 파이프라인은 위 Figure 2와 같습니다. query 이미지I_<em>{query} 와 객체 mesh M이 주어졌을 때, 객체-카메라 변환T_{query}를 추정하는 게 목표입니다. 흐름을 보면, 먼저 객체 M 주위에 카메라 포즈를 샘플링해서 이미지 V와 point map P를 렌더링합니다. 그다음 query 이미지와 V를 image token으로 인코딩하고 각 token에 camera token을 붙이는데, 렌더 view는 카메라 포즈를 알기에 known intrinsic/extrinsic으로 camera token을 계산하고 query는 모르기에 learnable embedding으로 둡니다. 그리고 geometry feature extractor가 전역 객체 표현을 만들어 각 view에 분배해 view별 feature F를 구성하고, 이를 point map P와 함께 key-value token으로 cross-attention에 투입합니다. 마지막으로 출력 camera token을 디코딩해 camera-to-object 변환 cam2obj를 예측하고, 역행렬로 최종 T_{query}를 얻습니다. 자세한 설명은 아래서 드리겠습니당.
3.1 Multi-View Network
먼저 입력 형식다음과 같습니다.
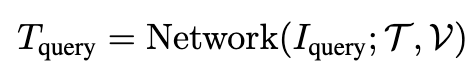
여기서 T는 객체 주위에 직접 정해둔 카메라 변환들이고, V는 그 포즈에서 렌더링한 RGB template 이미지들입니다. 포즈를 아는 여러 장의 참조 이미지라고 보시면 됩니다. 그리고 여기에 객체 모델 M에서 유도한 geometry 정보를 추가한 아래입니다.
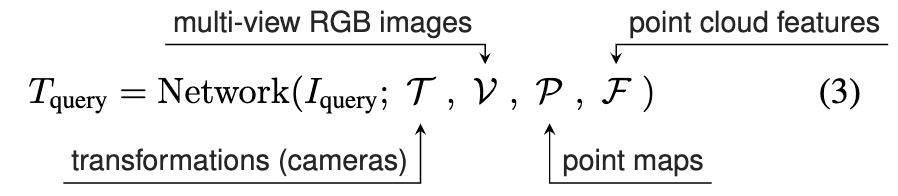
추가된 P는 point map, F는 per-point feature입니다. 정리하면 V는 외형, P는 같은 시점의 3D 좌표 F는 학습된 geometry feature인데 셋 다 같은 카메라 포즈 T에서 정렬되어 들어간다는 게 포인트입니다. 외형만으로 매칭하면 CAD 와 실제 gap에 취약하니, 같은 시점의 geometry를 같이 넣어줍니다. 네트워크 동작을 보면, 각 이미지 I<em> 를 pretrained 네트워크(DINOv2)에 넣어 feature token을 뽑고, 카메라 포즈 T_i는 camera encoder로 camera token c_i 하나로 인코딩해 붙입니다.
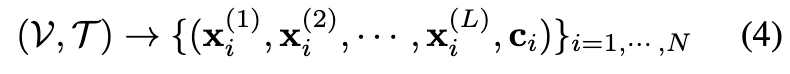
query 이미지도 똑같이 token을 뽑고, camera token 자리에는 learnable token c{query} 를 붙입니다. 그래서 네트워크가 처리하는 전체 token 수는 다음과 같습니다.
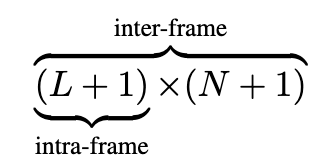
한 view당 (패치 token L개 + 카메라 token 1개)이고 view가 (N+1)개이니, 총 (L+1)×(N+1)개의 token이 흐릅니다. 여기서 intra-frame과 inter-frame(view들 사이)이라는 것이 등장하는데, 저자들은 VGGT의 설계를 따라 intra-frame self-attention과 inter-frame self-attention을 번갈아 쌓습니다. intra에서는 이 한 장 안에서 self attention 을 하고 inter에서는 전체 attention 을 하게됩니다. 이걸 여러 번 반복하면서, query view가 포즈를 아는 template들 사이에서 자기 포즈를 추론하게 됩니다.
그리고 PoseGAM은 여기에 추가를 하는데, 각 self-attention layer 직전에 cross-attention(CA)을 하나 넣어서 geometry를 주입합니다.
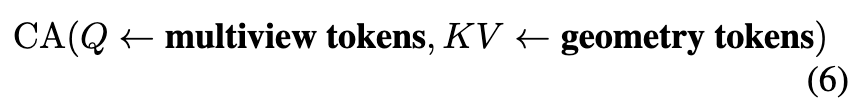
Query가 multiview token(이미지+카메라)이고 Key/Value가 geometry token(P, F)입니다. geometry를 메인 시퀀스에 직접 더하지 않고 cross-attention으로만 참조한다는 게 중요한데, 이유는 뒤에서 다시 나옵니다. 마지막으로 여러 attention layer를 다 통과한 뒤, camera token에 해당하는 출력만 head로 디코딩해 포즈를 예측합니다.
3.2 Geometry Processing via Point Maps
객체 geometry를 point map 형태로 만들어 넣는 법은. 이미 알고 있는 카메라 포즈 T에서 객체를 depth map으로 렌더하고, 카메라 intrinsic으로 각 픽셀을 world 좌표의 3D 점으로 역투영합니다.
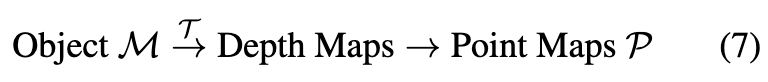
여기서 point map이라는 개념이 핵심입니다. 일반 point cloud는 점들의 집합인데, point map은 (H×W)를 유지한 채 각 픽셀 자리에 그 픽셀이 가리키는 3D 좌표 (x,y,z)를 담은 겁니다. RGB 이미지가 픽셀마다 (R,G,B)를 갖듯, point map은 픽셀마다 (x,y,z)를 갖는 거죠. 그래서 RGB 이미지와 같은 격자 구조라 정렬이 잘 됩니다. 이 point map을 가벼운 conv에 통과시켜 token으로 만듭니다.
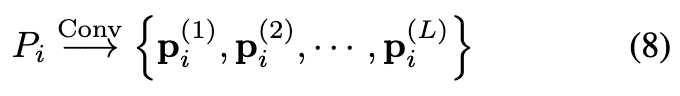
그리고 이 point map token을 RGB token에 그냥 더하지 않습니다 저자들은 pretrained 모델의 입력 분포와 큰 modality gap이 생겨서 학습에 방해한다고 합니다. 그래서 앞에서 본 cross-attention으로만 주입합니다.
3.3 Geometry Processing via Point Cloud Networks
추가적으로 PointTransformer v3로 객체의 전역 표현을 뽑아 넣는 건데요. 입력은 point cloud(좌표 + point color + normal)이고, 출력은 점마다 feature 벡터입니다. 그런데 저자들이 실험해보니 이 point feature를 raw 형태 그대로 넣으면 네트워크가 잘 활용을 못 합니다. 메인 token은 이미지 격자 기반인데 geometry feature는 순서만 있는 점 나열이라 정렬이 안 된다고 합니다. 그래서 저자들은 이 부분을 point feature를 view-map 형식으로 만들고, point map의 좌표 채널을 추출된 feature 벡터로 바서 feature map을 형성하는 식으로 처리합니다. 이 부분이 이해가 잘 안될 수 있는데 쉽게 말해면 point map이 픽셀마다 (x,y,z)를 담은 격자면, feature map(3.3)은 그 (x,y,z) 자리에 PTv3 feature 벡터를 대신 넣은 것입니다. 격자 구조(H×W)는 그대로 유지하고, 각 칸의 값만 좌표에서 학습된 feature로 교체한 거죠.

PTv3에 넣기 전에 각 점이 원래 어느 view의 어느 픽셀 (u_i, v_i)에서 나왔는지를 mask index로 기록해둡니다. PTv3가 점마다 feature e_i를 뽑으면, 그 feature를 원래 픽셀 자리에 도로 꽂아넣습니다.
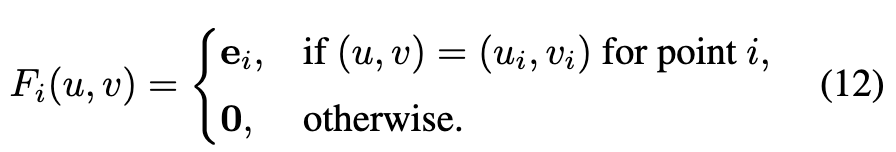
빈 칸은 0으로 둡니다. 즉 점 시퀀스를 다시 이미지 격자로 되돌리는 작업입니다. 이렇게 만든 feature map도 conv로 token화한 뒤, point map token에 더해서 함께 cross-attention의 KV로 들어갑니다.
개인적으로 이게 해당 논문에 킥이였던게 아닐까 생각듭니다. DINOv2 같은 출력을 CNN spatial map으로 잇는 문제와도 비슷한데, 여기선 DPT 같은 무거운 adapter 대신 strided conv + view-map 단순하게 처리해주는 방법으로 활용함으로 써 효과적이였지 않을까 ? 라는 생각이 듭니다.
Data Construction
Toys4K, 3D-FUTURE, ABO, HSSD, Objaverse 등 공개 데이터셋에서 객체를 모으고, 품질 낮은 mesh를 필터링해서 19만 개 이상의 물체를 만들 데이터셋을 구축했습니다.
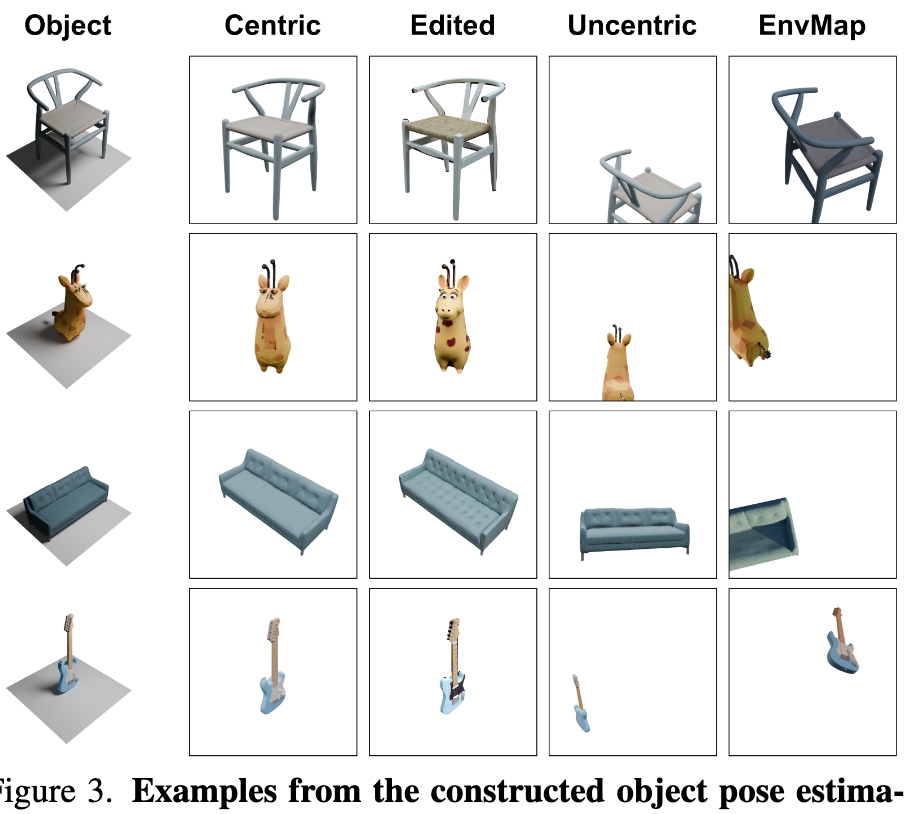
객체당 50개 카메라 포즈를 배치하고, 각 포즈에서 텍스처 이미지와 depth/normal/mask 맵을 렌더합니다. 그리고 query 이미지는 4가지 난이도 시나리오로 렌더하는데 Figure 3이 그 예시입니다.
첫 번째는 Centric으로, 카메라가 객체 중심을 향하고 조명이 고정된 가장 쉬운 기본형입니다. 두 번째는 Uncentric으로, 카메라 위치와 랜덤으로 해서 객체가 화면 중앙에 안 오게 만들었습니다 이는 부분 가림에 강인한 셋을 만들려 했다고 합니다. 세 번째는 Uncentric에 조명 변화를 더한 것 입니다. 네 번째는 Appearance-edited로, noise를 주입한 뒤 텍스트 조건 diffusion으로 생성했다고하는데 이는 query 이미지랑 Ref 이미지가 다를 수 있다는 관점에서 만들었다고 하는데 열화상에 적용 해볼수 있지않을까 생각도 들었습니다. 열화상은 보는 뷰에 따라 다르기때문에 이게 잘 먹힌다면 충분히 가능할 것 같다는 개인적인 생각도 드네요. 저자들도 세 번째(조명)와 네 번째(외형 편집) 시나리오가 멀티뷰 foundation model의 약점인 CAD 와 실사 appearance gap을 학습 단계에서 미리 보게 학습을 시킨다고 합니다.
Experiments
학습은 4장의 합성 데이터셋으로 하고, 평가는 학습에 안 쓴 unseen 벤치마크 5개(LM-O, T-LESS, YCB-V, TUD-L, IC-BIN, 전부 BOP 표준)로 합니다. 메인 비교는 BOP 표준인 AR(Average Recall) 지표(VSD, MSSD, MSPD 평균)를 쓰고, ablation은 회전·translation 정확도 기반 AUC@N 변형을 씁니다.
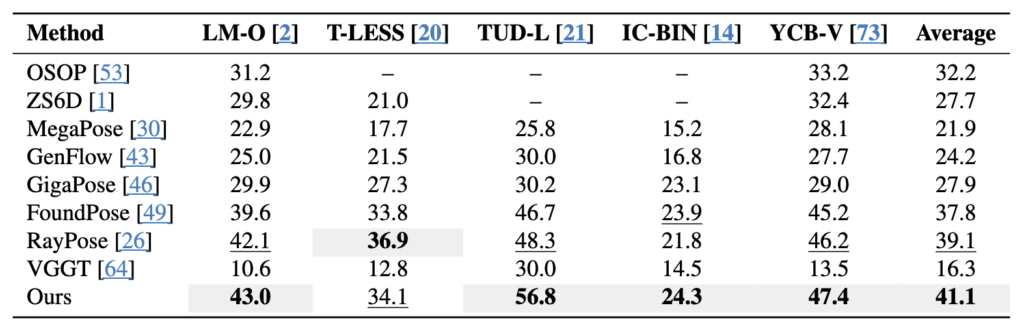
Table 1이 메인 결과입니다. refinement 네트워크나 multi-hypothesis 없이 측정한 수치인데, 평균 AR 41.1로 RayPose 대비 +5.1%를 기록했습니다. 특히 TUD-L에서 가장 큰 폭으로 올랐는데, 저자들은 TUD-L이 단일 객체·가림 적은 이미지라 합성 학습 데이터 조건과 잘 맞아서라고 설명합니다. 그리고 VGGT를 그대로 가져다 쓰면 16.3에 불과합니다. 객체 geometry 정보가 없고 appearance 불일치에 취약하기 때문인데 이게 geometry 주입 + 합성 데이터 fine-tuning이 결정적이라고 합니다.
다음으로는 ablation 중에서도 모달리티 부분입니다.
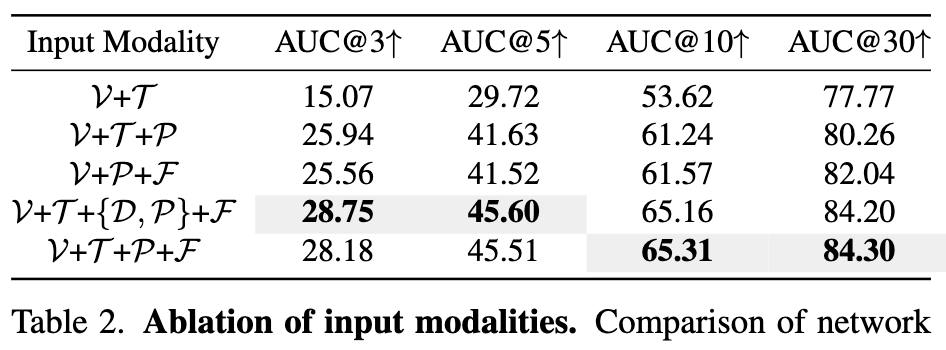
RGB(V)+카메라(T)만 쓰면 성능이 하락하고, point map을 추가하면 확 오릅니다. feature map(F)까지 더하면 추가로 오릅니다. depth map(D)을 더 넣어봤지만 거의 개선이 없었는데, 이미 카메라+point map에서 depth를 추론할 수 있어서 정보가 중복되기 때문이라고 합니다.
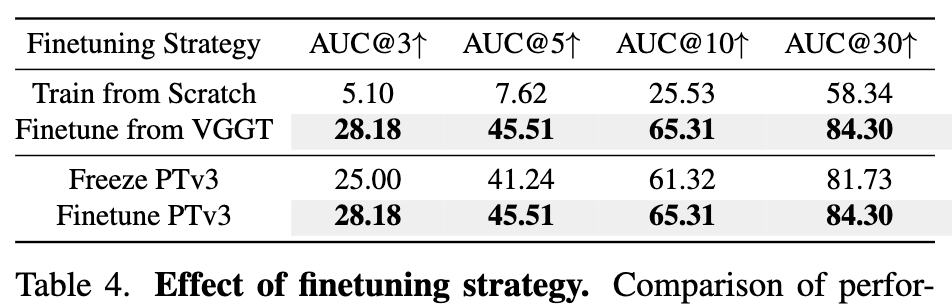
fine tuning 전략입니다. VGGT의 학습방식과 초기 weight를 사용함으로써 효율 성을 입증한 것 같습니다 scratch 학습대비 성능 향상이 많이 이루어지는 것을 보실 수있습니다. 마지막으로 geometry 주입 방식 비교입니다.
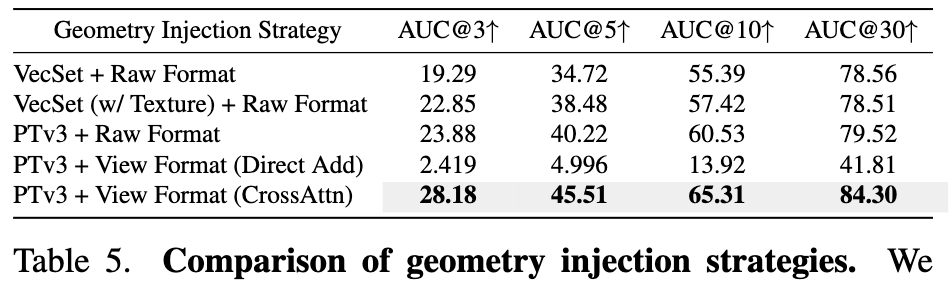
raw 형식(point cloud)은 23.88인데, view-map + cross-attention은 28.18로 최고입니다. 반대로 view-map인데 cross attention을 하지않고 더하면 하면 2.4로 하락하는데. pretrained 입력 분포를 깨버려서 거의 학습 실패한다고 저자들은 얘기를 합니다. 결국 feature를 view-map 형태로 만들고 직접 더하지 말고 cross-attention으로 주입하는 것을 실험으로 보여주었습니다
6D 연구에서 matching → PnP일반적인 방식을 깨고 attention으로 포즈를 직접 회귀한다는 전환인데, 멀티뷰 foundation model이 잘 나오면서 가능해진 접근이라 재밌게 읽었던 것 같습니다.
감사합니다
안녕하세요, 우진님. 좋은 리뷰 잘 읽었습니다.
좀 헷갈리는 부분이 있는데, matching 없는 아키텍처가 성능 향상의 주된 요인인가요 geometry 주입이 성능 향상의 주된 요인인가요?