안녕하세요. 이번 x-review는 기존 VLA 아키텍쳐에 JEPA 기반 video world model 과의 결합을 다룬 논문입니다. 요즘 제가 다루는 LeJEPA기반 LeWM이 real-world robotic task나 흔히 사용되던 sim benchmark에 얼마나 align이 맞춰질 수 있는 학습 프레임워크 및 아키텍쳐인지가 좀 의문이 생겼었는데, 본 논문은 VLA 구조에 바로 JEPA 스타일로 V-JEPA latent align 맞춘 해당 논문이었습니다. 더구나 human video pretraining으로 latent action representation을 temporal frame변화에 주로 반응하는 reconstruction objective 위주로 담게 만드는 게 아니라, future state transition(dynamics representation)을 담는 objective로 JEPA기반 objective를 활용한다는 점에서 눈길이 많이 갔는데요. 어떤 점이 기존 baseline급 VLA나 world model integrated VLA 와 다른 지를 위주로 한번 살펴보겠습니다.
1. Introduction
[Internet-scale video data -> VLA pre-training on Robot Learning]
로봇 학습 분야에서 인터넷 규모의 비디오 데이터로부터 VLA policy를 학습하는 것은 이제 거의 주류 연구가 되었다고 해도 과언이 아닙니다. 보통 이 때 쓰이는 로봇 상호작용 데이터는 수집 비용이 높고 다루는 태스크에 대한 커버리지 자체는 좁은 반면, unlabeled human video나 unlabeled robot video는 풍부하고 다양하며, temporal하게 variants가 생기는 부분들에 대한 풍부한 demonstrations을 잠재적으로 가진다고 볼 수 있습니다.
이러한 흐름은 VLA latent-action 사전 학습 연구를 촉진했는데요. 이 VLA 사전학습연구들은 sparse한 control trajectories만으로 policy의 action을 학습하는 대신, 먼저 비디오로부터 잠재적인 representations과 state transition의 경향을 학습한 다음, 이를 다운스트림 제어에 adaptation하는 방식으로 보통 사전학습을 진행합니다.
[기존 video 기반 VLA latent-action pre-training 방식의 문제점]
하지만 본 논문은 최근의 VLA들이 “비디오로 사전학습된 latent action” 의 objective가 로봇 제어에 실제로 필요한 것을 학습하지 못하는 경우가 많다고 주장합니다. 로봇 에이전트에게 “액션”의 가장 유용한 개념은 픽셀 차이를 압축하는 게 아니라, 상호작용 하에서 근본적인 상태가 어떻게 진화할지를 포착하는 변수, 즉 액션 관련 상태 전이(action-relevant state transition)에 대한 액션 의미론이라고 볼 수 있는데요. 사전 학습이 이와 잘못 정렬될 경우, 다운스트림 정책은 시간적으로는 예측 가능하지만 제어 가능한 구조와는 약하게 연결된 표현을 학습할 때 배우게 되어, 취약한 행동, 낮은 전이 및 비효율적인 미세 조정 문제로 이어지게 됩니다.
저자들은 latent-action 사전 학습이 앞선 액션 의미론에서 벗어나는 4가지의 주요 실패 원인을 먼저 말합니다.
- [Appearance bias] pixel-wise goal은 표현을 액션이 아닌 appearance 자체에 편향되게 합니다.
기존 VLA들이 쓰는 VQ-VAE 기반 loss처럼 미래 프레임을 직접 예측하거나 frame difference를 latent로 압축하면, supervision은 자연스럽게 시각적으로 많이 변하는 요소에 끌립니다. texture, illumination, clutter, viewpoint는 예측 손실에는 크게 작용하지만, robot control에 필요한 controllable factor와는 약하게 연결됩니다. - [Nuisance motion] 사전학습 시의 real-world의 video 자체는 노이즈가 많은 움직임을 증폭시킵니다.
특히 human video/ in-the-wild video 등에서는 카메라 움직임과 비인과적인 배경의 변화는 상호작용에 의해 유발되는 state transition 자체에 집중하게 만들기보다는 더 강하게 노이즈스러운 영향력을 끼칠 수도 있게 됩니다. frame-difference 기반 latent action은 이런 노이즈스러운 신호까지 action인 것처럼 인코딩하기 쉽습니다. 이 경우 latent action이 의미 있는 transition dynamics의 표현이 아니라 nuisance motion의 delta-frame encoder(영상에서 많이 바뀐 부분에 대한 반영)의 느낌으로 변질되게 만든다는 문제가 있습니다. - [Information leakage] 전이학습 과정에서 정보 유출로 “latent action”을 shortcut에 의해 붕괴시키게 만듭니다.
이게 가장 중요한 실패 모드라고 하는데, 기존 latent-action 파이프라인은 현재 관측과 미래 관측을 같은 모듈에 넣거나, 미래 context가 latent action 형성에 개입하면 shortcut이 생깁니다. loss는 내려가지만, control에 필요한 의미 있는 factorization은 생기지 않는 문제가 발생한다고 합니다. - [Multi-stage fragility] 다단계 학습 파이프라인 자체가 복잡하고 취약합니다.
보통 위와 같은 문제를 해결하려고 학습안정화를 위해서 기존 많은 접근 방식들이 representation 사전 학습 -> latent-action 학습/정렬 -> 정책 학습 이라는 3단계나 혹은 그 이상의 학습절차를 따릅니다. 근데 해당 파이프라인은 stage-wise mismatch가 생기고, 방법론의 핵심이 objective인지 engineering recipe인지 흐려지게 만든다고 합니다.
결과적으로 위 문제들은 많은 latent-action objective가 action-relevant state transition을 학습하기보다 pixel variation에 암묵적으로 묶여 있다는 하나의 근본적인 문제점으로 귀결됩니다. 로봇 제어에서 action은 단순히 두 프레임 사이의 시각적 차이를 요약한 값이 아닐 수 있습니다. action은 상호작용을 통해 상태가 어떻게 변하는지를 설명하는 변수여야 하는데, 예를 들자면 컵을 집는 행동에서 중요한 것은 손과 컵의 접촉, 파지 가능성, 물체의 pose 변화, 후속 trajectory의 안정성이라고 볼 수 있을 것 같습니다. 이런 것처럼 배경의 조명 변화나 카메라 흔들림은 영상에서는 큰 변화일 수 있지만, 제어 관점에서는 대부분 nuisance이기에, 로봇 제어를 잘하기 위해서는 nuisance appearance를 버리면서도 상호작용 하에서 상태 진화를 지배하는 요소를 보존하는 가치 있는 latent state가 필요합니다.
이 지점에서 VLA-JEPA의 설계 철학이 나오게 되는데, 액션 관련 전이 구조를 반영하는 미래 latent state를 예측하되, 미래 정보가 predictor 입력으로 새면 안 된다. 에 주목하게 됩니다. 저자들의 이 철학이 픽셀 자체가 아닌 표현을 학습하고 예측하려는 JEPA 계열의 철학과 잘 맞게 되는데, JEPA는 pixel reconstruction 대신 latent-space prediction을 사용합니다. 따라서 low-level appearance 즉 저수준의 픽셀노이즈 자체까지 복원하려는 어떤 압력을 줄이고, 더 의미론적인 state 추상화 능력을 학습하게 만듭니다. VLA-JEPA는 해당 철학을 바로 VLA policy pretraining으로 가져오면서 frozen target encoder가 미래 latent state를 제공하고, student는 현재 observation과 instruction만으로 이를 예측하게 하는 구성을 띄게 됩니다.
Contribution은 세 가지로 요약할 수 있습니다.
- latent-action pretraining의 주요 실패 원인을 pixel tethering, nuisance motion, information leakage 관점에서 정리합니다.
- 미래 프레임을 supervision target으로만 사용하고 predictor 입력에서는 배제하는 leakage-free JEPA-style latent world modeling objective를 제안합니다.
- human video pretraining과 robot action fine-tuning을 하나의 2-stage workflow로 묶고, simulation(LIBERO, LIBERO-Plus, SimplerEnv)과 real-world manipulation에서 기존 다단계 latent-action 파이프라인에 비해 학습을 간소화하면서도 generalization 및 robustness 향상을 보입니다.
2. Methodology
기존 접근 방식의 한계를 해결하기 위해, 본 논문은 action-free human video와 action-labeled robot data 모두에 대한 사전 학습을 가능하게 하는 통합 프레임워크인 VLA-JEPA를 소개합니다.
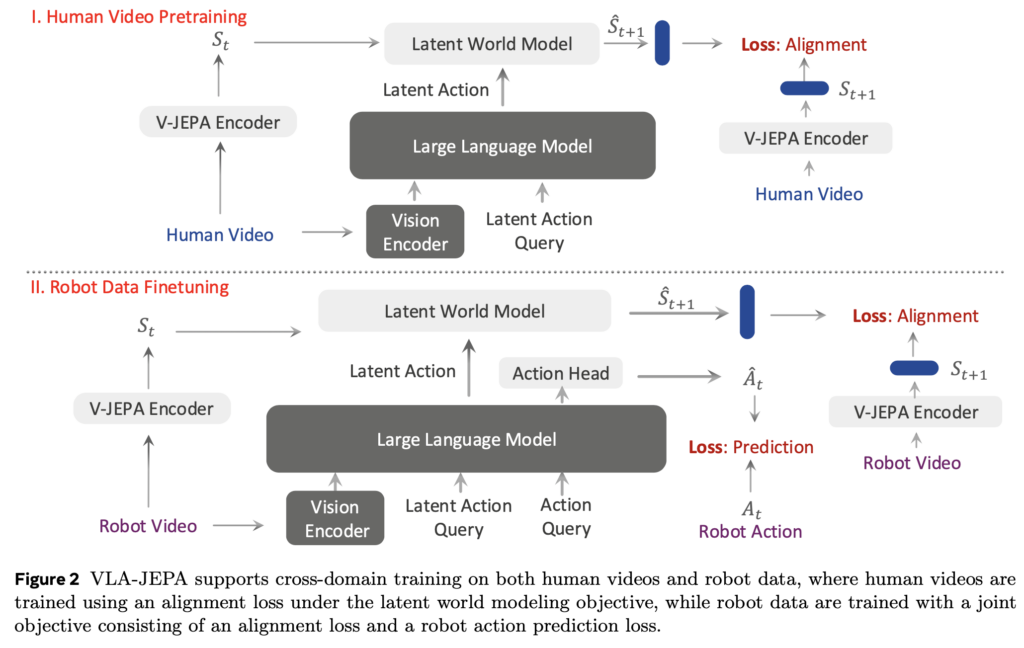
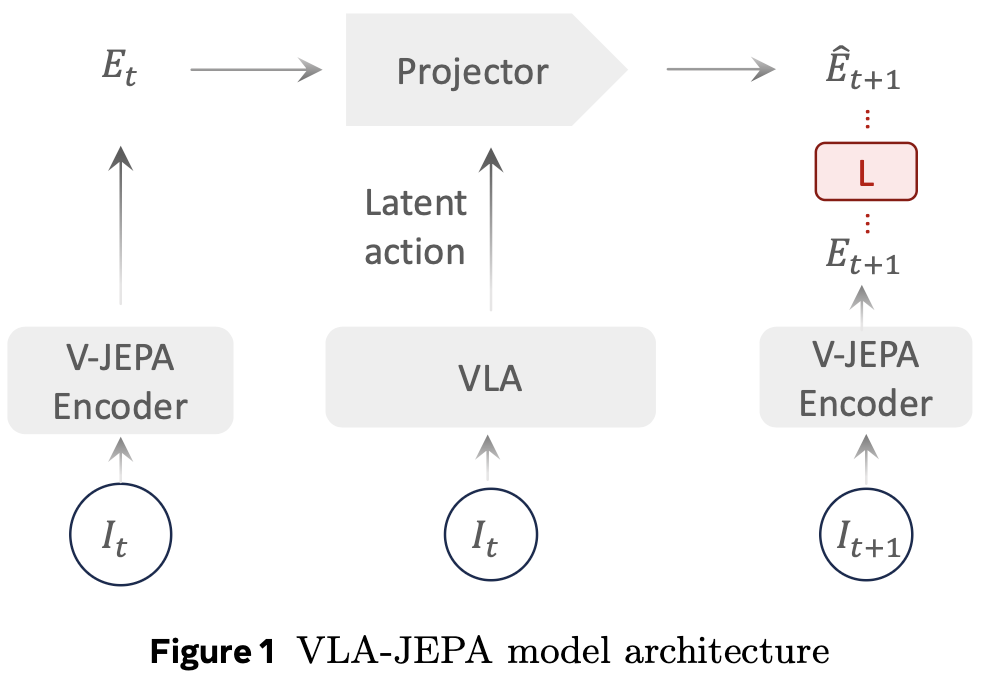
전체 프레임워크는 4 부분으로 구성됩니다.
- Qwen3-VL-2B-Instruct VLM backbone
- frozen V-JEPA2 world state encoder (vjepa2-vitl-fpc64-256)(약 300M)
- autoregressive latent world model (V-JEPA2-AC predictor 모듈인 것으로 추정, ViT 기반)
- flow-matching action head (DiT-B기반)
앞서 말했듯이 설계 의도는 latent action은 미래 프레임을 압축해서 얻는 변수가 아니라, 현재 관측과 instruction으로부터 미래 latent state를 예측하는 데 필요한 transition variable을 유도하는 게 목표입니다.
위 Fig2. 구조에서 윗 구조에 해당하는 human video pretraining은 action label 없이 world modeling loss (JEPA기반 loss)로 학습됩니다. 아랫 구조에 해당하는 robot data finetuning은 world modeling loss(JEPA 기반 loss)와 action head에서의 action prediction loss를 함께 사용합니다. 결국 여기서 human video는 로봇 action을 직접 가르치는 데이터라기보다, state transition에 대한 robust latent prior representation을 갖길 바라는 데이터가 되고, 로봇데이터는 그를 기반으로 더 fine한 action trajectory를 예측하게 만드는 것이라고 보면 될 것 같습니다.
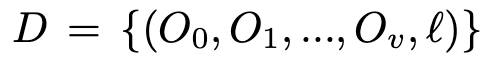
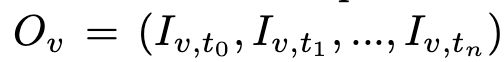
3.1 VLM backbone과 latent/action token
VLA-JEPA는 Qwen3-VL-2B를 VLM backbone으로 사용합니다. vision encoder는 SigLIP-2 기반이며, 대규모 지식 속에 잠재적으로 내재된 세계 지식을 VLM으로부터 추출하기 위해 모델 안에 ⟨latenti⟩와 ⟨action⟩ 이라는 learnable한 2종류의 토큰을 추가합니다.
⟨latenti⟩: latent action token (각 time step의 state transition을 표현)⟨action⟩: embodied action token (실제 robot action trajectory 생성을 조건화)
latent action token은 timestep i 별로 정의됩니다. 예를 들어 <latent0>는 s0에서 s1로 넘어가는 transition을 담는 역할을 맡습니다. 구현상 각 latent token은 K번 반복되며, K는 24/T 로 설정됩니다. 여기서 T는 future video horizon입니다. 이 T의 세팅은 latent action token이 VLM 내부 attention에서 충분한 표현 용량을 갖기 위함입니다.
중요한 점은 latent token이 미래 프레임을 직접 보지 않는다는 것입니다. VLM은 initial observation과 language instruction만 입력으로 받습니다. latent token은 이 입력을 바탕으로 future world state를 예측하는 데 필요한 transition representation으로 학습됩니다.
3.2 World state encoder: frozen V-JEPA2
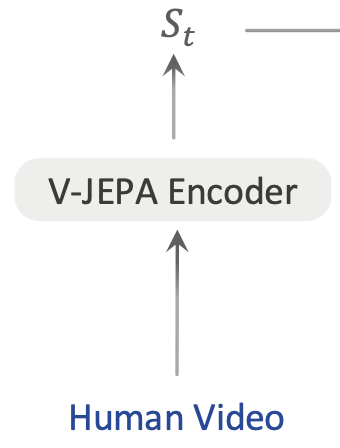
VLA-JEPA는 사전에 self-supervised 학습된 V-JEPA2 encoder를 frozen world state encoder로 사용합니다. 각 view의 video frame을 V-JEPA2 encoder F로 인코딩하고, multi-view representation은 concatenation으로 합칩니다.
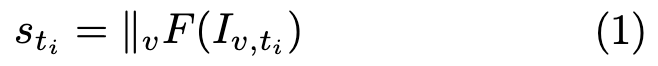
여기서 s_ti는 time step t_i의 unified world-state representation이고, \parallel는 벡터 연결 연산자입니다. F는 frozen인데, 이건 parameter saving 이상의 의미가 있습니다.
첫째, target representation이 고정되므로 predictor가 target encoder와 함께 무너지는 collapse를 줄일 수 있습니다. 둘째, future frame은 frozen encoder를 통해 target latent를 만들 때만 사용되므로, VLM이 미래 정보를 직접 읽는 shortcut을 차단합니다. 셋째, pixel-level reconstruction이 아니라 pretrained video representation 공간에서 prediction을 수행하므로, low-level appearance 변화에 덜 민감한 objective가 됩니다.
이 부분이 앞선 인트로에서 말한 논문의 핵심이라고 보시면 되고, 이게 inductive bias가 되는 것 같습니다. V-JEPA2가 좋은 video representation을 이미 갖고 있다는 가정 위에서, VLA-JEPA는 이를 robotics pretraining의 supervision generator로 사용합니다.
3.3 Latent world model: leakage-free state prediction
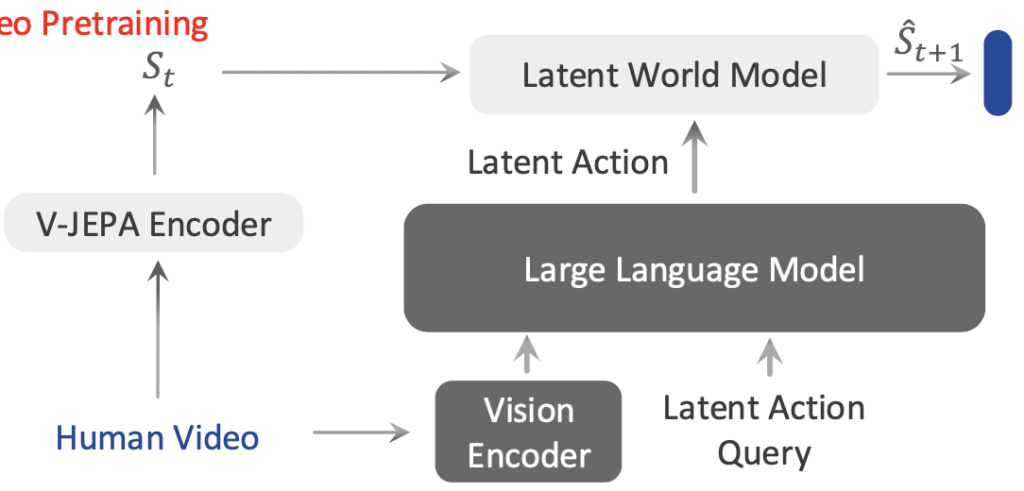
VLM은 초기 multi-view observation 이미지를 SigLIP-2으로 임베딩하고, instruction을 입력으로 받고 Latent Action Query 로써 ⟨latenti⟩ 토큰을 컨디션으로 붙여서 Latent Action representation인 z_ti를 만듭니다.(위 그림엔 z_ti notation이 없습니다.)
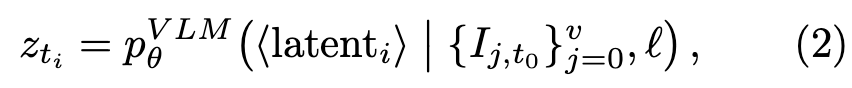
그 다음 위의 autoregressive Transformer 기반 world model이 이전 world states s_{t0:i}와 Latent Action representations z_{t0:i}를 조건으로 다음 state chunk \hat{s}_{t1:i+1}을 예측합니다. 이는 [t1, ti+1]에 걸쳐 예측된 world states chunk입니다. 이 때, 각 특수 latent 토큰 ⟨latenti⟩의 역할이 드러나는데, 입력 시퀀스에서 K번(하이퍼파라미터) 복제되어 가변 길이(variable-length) latent action 인코딩 -> world states chunk 구조가 가능하게 하는 역할로 쓰이게 됩니다.
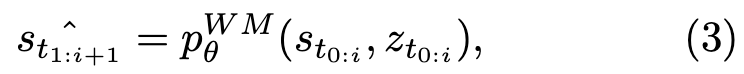
이 WM 부분은 time-causal attention 구조를 사용하는 게 핵심인데, 서로 같은 time step 내에서 모든 latent action token과 world state token이 bidirectional full attention을 취하게 만듭니다. 하지만 서로 다른 time step 사이에서는 causal mask가 걸리게 만들어서 t 시점 token은 t 이전과 t 자신만 볼 수 있고, 미래 time step의 token은 볼 수 없게 마스킹되어 있습니다. 이 구조는 앞서 인트로에서 말한 information leakage를 regularization의 의미로써 완화하는 방식은 아닌 것 같고, attention 과정 자체에서 future access를 막으면서 latent action이 future frame을 숨겨 전달하는 shortcut으로 붕괴할 가능성을 줄이는 역할을 하는 것으로 보입니다.

위는 WM의 layer configuration입니다.
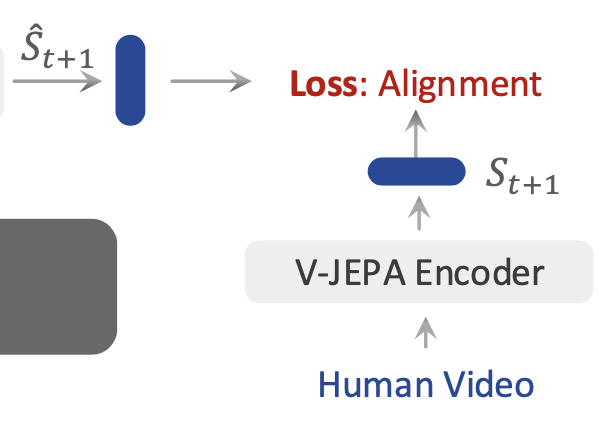
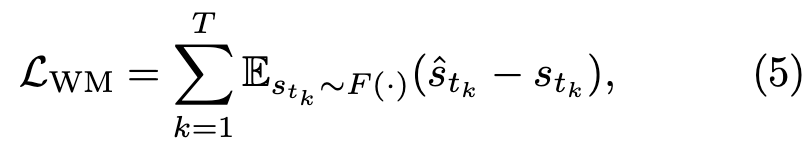
그 다음 world modeling loss는 predicted latent state와 frozen V-JEPA2 target latent state를 정렬하게됩니다.
논문은 기존 JEPA objective를 제시했던 V-jepa, V-jepa2 관점에서 말하길, VLA-JEPA의 world model 학습을 확률적 ELBO(Evidence Lower Bound; 직접 계산하기 어려운 log-likelihood의 아래쪽 근사값) 관점으로 해석할 수 있다고 말하는데요. JEPA objective가 그랬듯 semantic space에서 predictive log-likelihood의 ELBO를 최대화하는 아래의 수식으로 표현된다고 합니다. 우리가 진짜 최대화하고 싶은 것은 보통, 데이터 x가 관측될 확률인데, \log p(x) 이 값은 “모델이 이 데이터를 얼마나 그럴듯하게 설명하는가”를 나타내고, 여기서 evidence는 관측된 데이터 x를 뜻합니다. 그래서 \log p(x)를 log evidence라고도 부르는데요. 그런데 WM같이 latent variable $z$를 구성하는 모델에서는 보통 다음의 p(x) = \int p(x, z) dz 적분이 필요합니다. 근데 이 적분이 복잡해서 직접 계산하기 어렵습니다. 그래서 ELBO라는 형식으로 근사하는 것이라고 보면 될 것 같습니다. 구체적으로, 타겟 월드 상태 s_{ti}를 생성하는 frozen V-JEPA2 인코더 F와 z_{ti}에 조건화되어 \hat{s}_{ti}를 예측하는 월드 모델 p가 주어지면, objective는 다음과 같이 작성될 수 있습니다:
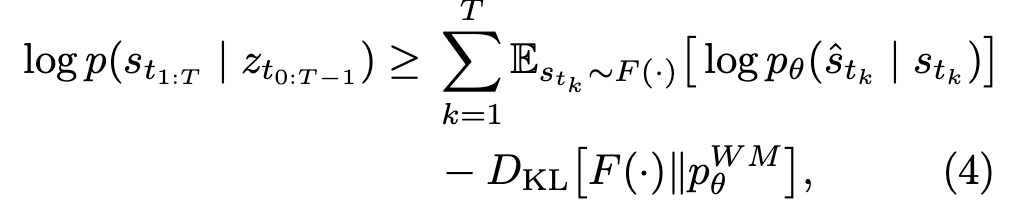
이 때, V-JEPA2 encoder F() 가 frozen이고 확률분포를 내뱉는 구조가 아니라 하나의 고정된 벡터인 deterministic embedding을 내뱉기 때문에(sampling, mean/variance, posterior distribution 다 없음) KL 항은 사라진다고 보면 됩니다. 그래서 실제 학습은 latent reconstruction loss로 단순화되는 구조가 된다고 합니다. 이론적으로 아주 강한 novelty라기보다는, 확률분포 기반의 JEPA objective를 VLA pretraining과 leakage-free 구조로 안정적 결합되는 loss 설계를 의도했다는 데 의미가 있는 것 같습니다.
3.4 Flow-matching action head
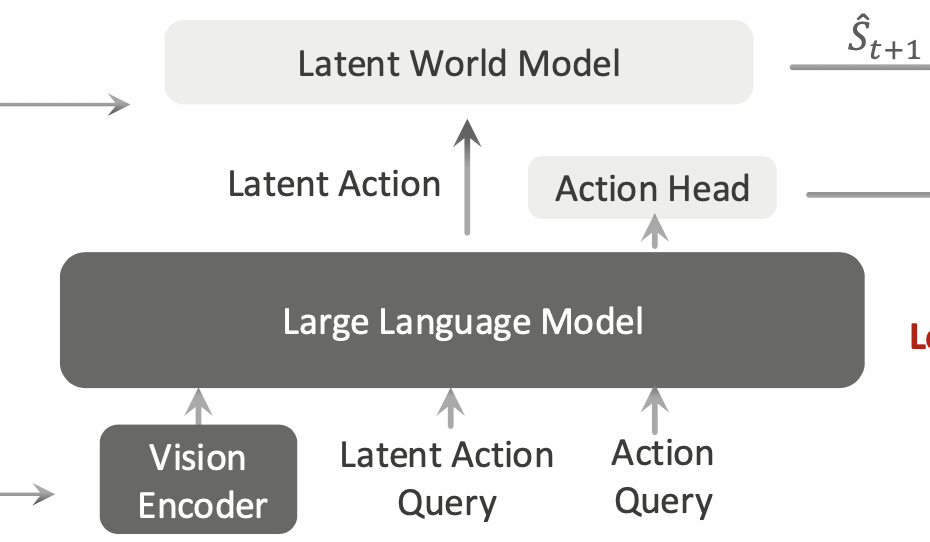
앞선 human video pretraining 표현을 활용하여 액션 예측으로 파인튜닝하기 위해, 본 논문은 joint optimization objectives를 설계합니다. 로봇 데이터셋의 멀티뷰 RGB 비디오에 대해, 앞선 WM loss(수식5)와 동일한 학습 loss를 그대로 같이 붙이고, flow matching action head 쪽에서 action loss 만들어 붙여서 로봇 데이터 도메인과 얼라인 맞춰서 latent action 표현을 파인튜닝하게 됩니다. 이를 위해 VLA-JEPA는 ⟨latenti⟩ 토큰이랑 같이 앞서 말했듯이 추가로 ⟨action⟩ 이라는 embodied action token을 컨디션으로 붙이고, VLM의 causal attention을 통해 global action-conditioning representation z_a를 얻습니다.
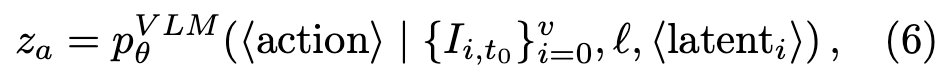
이 z_a는 conditional flow-matching action head에 컨디션으로 들어갑니다. action head는 DiT-B 기반 Transformer이며, continuous action trajectory distribution 모델링 기반입니다. action은 end-effector delta position과 delta axis-angle representation, gripper command로 구성되었고, appendix 기준 action dim은 7이고, future action horizon H 도 7이었습니다.
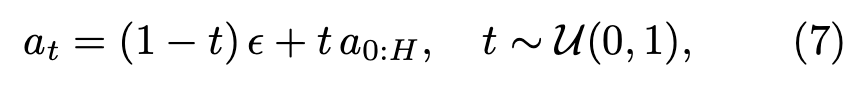
표준 flow-matching 공식에 따라, 본 논문은 time-dependent interpolation을 위 수식7과 같이 정의하고, 호라이즌 H에 걸친 ground-truth 액션 시퀀스를 a_{0:H}로, 학습된 흐름에 의해 생성된 예측 액션 시퀀스를 \hat{a}_{0:H}로 둡니다. 액션 헤드는 z_a에 조건화된 벡터 필드 v_{\theta}(a_t, t | z_a)를 매개변수화하며, 이는 ground-truth 조건부 흐름과 일치하도록 학습됩니다. 입실론은 가우시안 노이즈입니다.
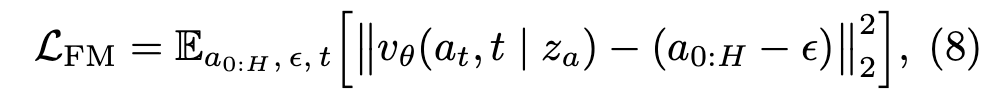
Flow-matching loss 는 위 수식8과 같고, v항은 예측된 action 속도벡터장, 뒤에 항은 가우시안 걷어내면서 선형 보간에 의해 유도된 타겟 action속도이며, 이 둘 간 MSE 취하는 형태입니다.
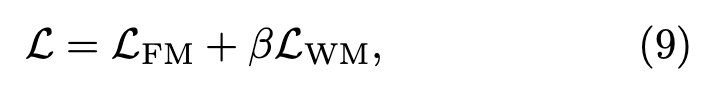
최종 loss는 이 둘을 합해주는 형태입니다.
human video에는 action label이 없으므로 L_WM만 사용합니다. robot data에는 action label이 있으므로 L_FM과 L_WM을 함께 사용합니다. 따라서 VLA-JEPA는 action label이 없는 video와 action-labeled robot demonstration을 동일한 latent transition framework 안에서 다룰 수 있습니다. 여기서 latent action은 단순히 인접 프레임의 appearance delta를 재구성하기 위한 code가 아니라, 현재 latent state로부터 미래 latent state를 예측하는 데 필요한 transition variable로 학습됩니다. Robot data에서는 이 latent transition representation이 downstream action generation, 특히 flow-matching 기반 action head와 연결되면서 실제 executable action으로 정렬됩니다. 이 지점에서 VLA-JEPA는 기존 LAPA처럼 VQ-VAE 기반 reconstruction objective로 frame-to-frame latent action을 먼저 양자화하고 이후 policy로 매핑하는 LAM(Latent Action Model)계열과 구분되는 것 같습니다.
4. Experiments

실험은 네 축으로 구성됩니다.
- LIBERO: simulation in-distribution manipulation
- SimplerEnv: real-to-sim gap이 있는 OOD evaluation
- LIBERO-Plus: seven perturbation dimensions를 통한 robustness evaluation
- real-world Franka manipulation
학습 설정은 다음과 같습니다. pretraining에는 Something-Something-v2의 human video 220K개와 DROID의 robot demonstration 76K trajectory를 사용합니다. world state encoder인 V-JEPA2는 freeze하고, 나머지 파라미터는 학습합니다. pretraining은 8장 NVIDIA A100에서 50K step 진행됩니다. LIBERO와 LIBERO-Plus fine-tuning에는 약 2K simulated expert demonstrations만 사용하며, LIBERO-Plus의 augmented data는 쓰지 않습니다. real-world 실험은 3개 task에서 수집한 100개 demonstration으로 post-training합니다.
비교군은 LAPA, UniVLA, Moto, villa-X, CoT-VLA, WorldVLA, GR00T N1, OpenVLA-OFT, π0, π0-Fast, π0.5 등으로 폭넓게 잡혀 있습니다. latent-action 계열과 최신 open-source VLA를 함께 비교한 점은 실험 설계상 장점입니다.
4.1 LIBERO
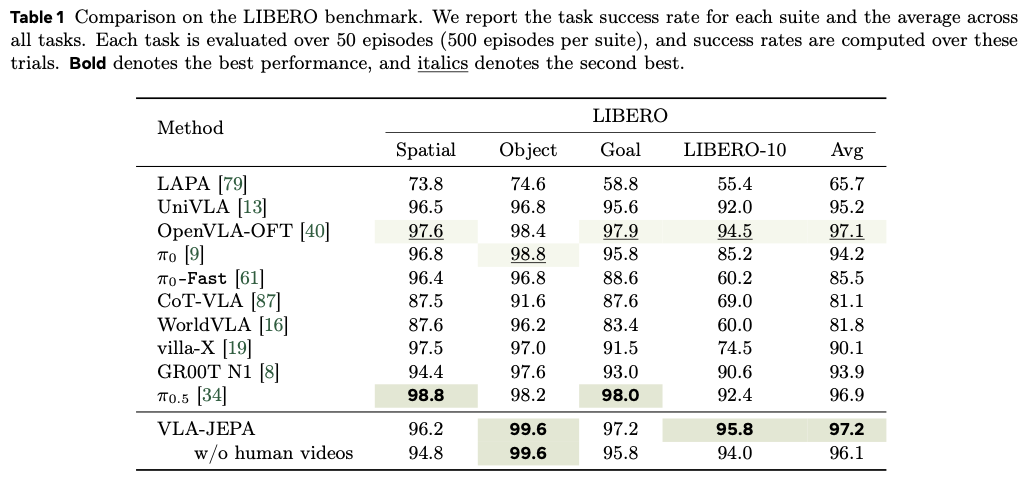
LIBERO에서 VLA-JEPA는 평균 성공률 97.2로 가장 높은 SR을 기록합니다. suite별로는 4개 중 2개에서 best인데요. 특히 OpenVLA-OFT, π0.5처럼 강한 VLA baseline이 대규모 robot data 기반이었던 것과 비교하면, VLA-JEPA가 상대적으로 적은 downstream data로 경쟁력 있는 성능을 냈습니다. LIBERO는 이미 saturation 되어있어서 좀 감안해야겠지만 VLA-JEPA가 평균적으로 우위는 있되, JEPA기반 latent-action pretraining의 설계 차이가 충분히 강한 baseline 수준까지 가능하다 정도로 봐주시면 될 것 같습니다.
추가로 LAPA, UniVLA, villa-X, CoT-VLA 같은 human video 혹은 latent-action model 관련 baseline과의 격차도 있는데요. 이 계열이 전반적으로 VLA-JEPA보다 낮은 성능을 보인다는 점은 저자들의 문제 제기와 잘 맞는 경향이 나왔습니다. frame-difference나 future-conditioned latent action은 temporal prediction에는 유용할 수 있지만, control에 필요한 action-centric transition semantics을 안정적으로 만들지는 못한다는 주장에 힘을 실은 게 아닐까 싶습니다.
4.2 SimplerEnv
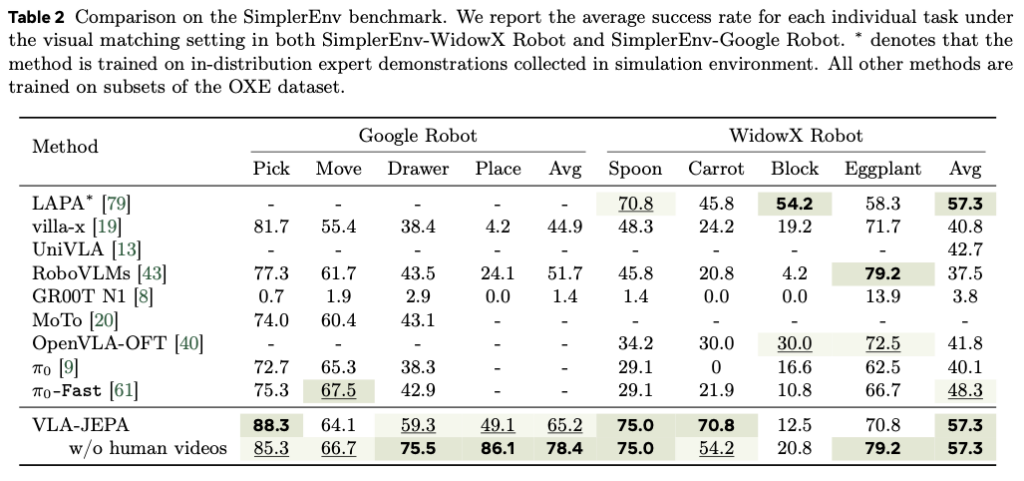
SimplerEnv에서는 Google Robot 태스크, WidowX Robot 태스크 모두 평균적으로 sota스러운 성능을 보입니다. 논문은 특히 Google Robot에서 VLA-JEPA가 강하다고 말하는데요. WidowX에서는 villa-X보다 학습데이터를 1% 미만만 사용하고도 성능이 높았다고 말합니다.
특히 SimplerEnv에는 expert demonstration이 직접 제공되지 않기 때문에, 어떤 데이터를 post-training에 쓰느냐가 성능에 크게 작용하는데요. LAPA가 성공 rollout만 선별해 training에 사용했을 때 WidowX에서 좋은 성능을 보인 것이라고 저자들은 말합니다. 즉, SimplerEnv 결과는 pretraining objective의 우수성만으로 설명되기보다, post-training 시 데이터 자체의 분포와 필터링 전략의 영향까지 함께 봐야 하기에, VLA-JEPA는 이런 것들 배제하고도 data-efficient pretraining 만으로도 충분히 경쟁력있다는 점을 어필하는 결과인 것 같습니다.
4.3 LIBERO-Plus
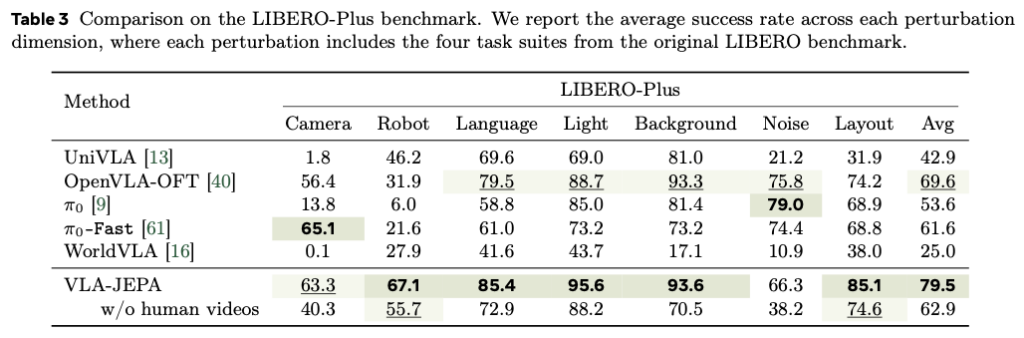
개인적으로 좀 인상깊었습니다. LIBERO-Plus는 Camera, Robot, Language, Light, Background, Noise, Layout의 7개 perturbation dimension으로 VLA robustness를 평가하는데요. VLA-JEPA는 7개 중 5개 perturbation에서 best를 기록하고, 평균 79.5로 가장 높은 성능을 보입니다. 특히 VLA-JEPA가 Language 85.4, Light 95.6, Background 93.6, Layout 85.1에서 뚜렷이 높고, Robot perturbation에서도 67.1로 가장 높습니다. 이는 latent action이 단순한 pixel 변화나 visual 노이즈에 덜 묶이고, task-agnostic disturbance에 더 안정적이면서 future state transition dynamics 자체를 반영한 representation을 만든다는 논문의 주장과 직접적으로 연결되는 것 같아서 인상깊었습니다.
반면 Camera perturbation에서는 63.3으로 π0-Fast의 65.1보다 낮고, Noise perturbation에서는 66.3으로 π0의 79.0에 비해 낮았는데요. VLA-JEPA가 camera viewpoint shift나 sensory noise에 대해서는 frozen V-JEPA2 latent prediction만으로 latent 표현에 충분하지 않다는 의미로도 해석이 됐는데, 카메라 포즈에 민감하고 센서노이즈 drift가 있는 Camera perturbation 환경에는 강건하지 못하다로 이해했습니다.
4.4 Real-world Franka
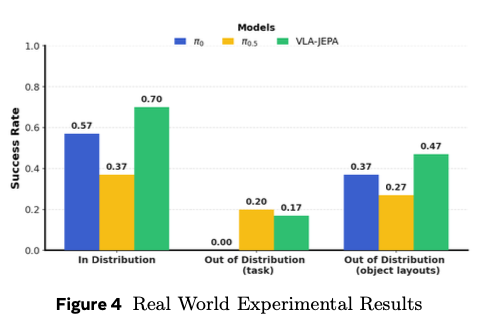
리얼 실험은 Franka Research 3, Robotiq 2F-85 gripper, Intel RealSense D435 camera 3대로 구성됩니다. 두 개는 3rd view이고 하나는 wrist view입니다. 학습 데이터는 grapes, apples, mangoes, oranges를 plate나 bowl로 옮기는 간단한 pick and place 태스크이고, 총 3가지 task. 각각 100 demonstrations으로 학습했습니다. OOD는 2가지 세팅이었는데, task OOD는 ID랑 아예 task가 다른 경우, object layouts OOD는 ID와 object 배치를 랜덤하게 넣어줬는데 task는 같은 경우입니다.
결과적으로 VLA-JEPA는 object layouts OOD에서 높았고, task-level OOD에서도 π0.5와 비교했을 땐 좀 낮지만 비슷한 결과를 보였습니다. 논문에서는 π0.5와의 성능 차이에 대해 추가 설명을 했습니다. π0.5는 instruction을 더 정확하게 따라 target object에 접촉하는 경향이 있지만, position control이 safety boundary를 자주 위반해 실행 실패가 발생하는 경향이 있는 반면, 반대로 VLA-JEPA는 fine-grained language reasoning이 약해 가끔 command와 다른 object를 잡지만, robot safety constraint는 잘 지키는 경향을 보여줬다고 합니다. VLA + JEPA latent world modeling이 trajectory 안정성과 execution reliability를 개선하는 데 더 직접적인 장점이 있다는 말로 해석됐습니다.
별개로 또 하나 눈에 띄는 실험결과는 qualitative observation은 repeated grasping이 있었다고 합니다. VLA-JEPA는 grasp에 실패하면 gripper를 다시 열고 재시도하는 행동을 보이는 반면, π0와 π0.5에서는 이 행동이 관찰되지 않았다고 합니다. robot 데이터에는 이런 repeated grasping behavior가 거의 없기 때문에, 저자들은 human video pretraining에서 언제 다시 잡아야 하는지에 대한 temporal decision prior를 얻었을 가능성을 언급했습니다.
4.5 LIBERO-Plus. Effect of proportion of human video in pretraining on SR
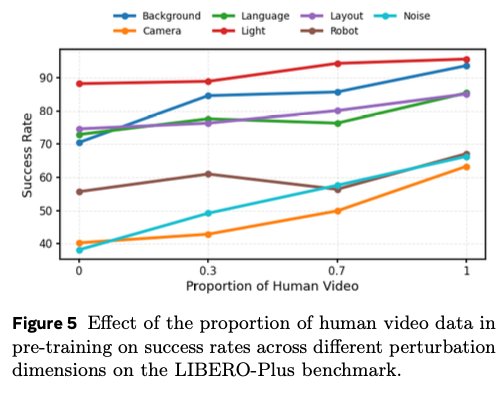
위는 사전학습때 사용한 human video 비율을 점진적으로 늘림에 따른 LIBERO-PLUS에서의 성공률 비율입니다. human video를 스케일링 할수록 충분히 유의미하게 latent action prior를 학습하고 이를 action head의 동작 단에서 robustness 와 stability 를 높이는 데 충분히 기여한 것으로 해석했습니다.
4.6 Visualization of attention of latent action tokens

이건 기존 LAPA와 UniVLA 대비 VLA-JEPA 가 latent action token의 attention 경향성이 덜 operation-irrelevant details을 가진다는 시각화 결과인데요. 보시면 일단 LAPA에 비해서는 작업 자체와 관련없는 영역을 attention하고 있는 경향이 덜한 모습을 볼 수 있습니다. UniVLA는 LAPA대비 작업과 관련된 instruction에 집중하여 이 문제를 어느 정도 완화한 것 같은 모습을 보였다고 합니다. 하지만 UniVLA는 그런 instruction의 semantic information을 지나치게 강조하기 때문에, 여전히 조작과 직접 관련 없는 배경 요소에 가끔 attention이 가는 문제가 있습니다. 예를 들어 human video에서는 움직이지 않는 펜에 주목하거나, real-world wrist-view recording에서는 식탁보의 texture에 주목하는 식입니다.
4.7 추가 ablation
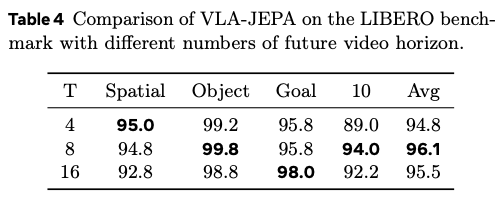
비디오 horizon T가 사전 정의된 action horizon (appendix에서는 7)에 가까울 때 최고 성능.
- T가 너무 작으면: 인코딩되는 정보 부족.
- T가 너무 크면: 중복(redundant) 정보 유입.
VLA-JEPA는 latent-action 기반 VLA 사전학습의 핵심 문제인 픽셀변화에 너무 묶여버린 latent action representation 개선에 초점을 맞췄고, 그에 대한 방안으로 JEPA 기반 world modeling을 활용한 joint objectness를 제안했습니다. 저는 특히 기존 VLA 프레임워크 속에 JEPA가 성능하락없이 잘 녹아든 모습을 실험으로 보여준 점이 인상깊었습니다. action-free human video를 VLA 학습에 쓰려면, 단순히 frame difference기반의 loss로 latent action embedding을 만들 것이 아니라, 현재 관측만으로 미래 latent state를 예측하도록 학습하는 JEPA 구조를 활용해야하지 않을까 + JEPA는 scaling도 충분히 받춰주는 것 같은데? 의 저의 막연한 생각의 뒷받침이 되는 논문인 것 같아서 이후 제 연구 방향에 대한 고민이 생기는 논문인 것 같습니다. 자꾸 LeWM 기반으로만 고집했던 것 같은데, 이거 기반으로 failure-prediction module 붙이거나 추가 RL로 latent policy steering 하는 기반이 될 수도 있을 것 같습니다.