안녕하세요. 이번에 리뷰로 가져온 논문은 ICLR 2026에 게재된 UrbanVerse: Scaling Urban Simulation by Watching City-Tour Videos라는 논문입니다.
이 논문은 제목 그대로 city-tour video 도시 투어 영상을 보고 urban simulation scene을 자동으로 만들어보자는 논문입니다. 조금 더 정확히 말하면 단순히 3D scene을 보기 좋게 복원하는 것이 아니라 embodied AI agent 예를 들어 delivery robot, quadruped, humanoid 같은 agent가 실제로 그 안에서 움직이고, 충돌하고, 장애물을 피하고, goal까지 도달하는 학습/평가 환경을 만들고자 하는 연구라고 보시면 좋을 것 같습니다.
제가 이전에 리뷰했던 WANDERLAND와도 결이 좀 비슷한데, 다만 WANDERLAND가 LiDAR, IMU, GNSS 같은 multi-sensor 기반으로 metric geometry와 collision layer의 신뢰성을 확보하는 쪽에 집중했다면UrbanVerse는 crowd-sourced city-tour video와 대규모 3D asset database를 활용해서 훨씬 더 scalable한 urban simulation scene generation을 목표로 한다고 볼 수 있습니다. WANDERLAND가 closed-loop evaluation을 신뢰할 수 있으려면 geometry가 정확해야 한다에 가까운 논문이었다면UrbanVerse는 실제 도시 분포를 반영하는 interactive simulation scene을 대량으로 만들 수 있어야 policy generalization이 가능하다에 가까운 논문이라고 보시면 좋을 것 같습니다.
자세한 내용은 리뷰에서 다루도록 하겠습니다. 바로 리뷰 시작하도록 하겠습니다.
Introduction
기존 navigation 연구에서는 크게 두 가지 방식의 데이터가 사용되어 왔다고 볼 수 있습니다.
첫 번째는 real-world demonstration data입니다. 예를 들어 사람이 실제로 로봇을 조종하거나, 사람이 걸어다니면서 촬영한 video를 이용해서 policy를 학습하는 방식입니다. NoMaD, ViNT, CityWalker 같은 visual navigation foundation model 계열이 이쪽 흐름에 가깝다고 볼 수 있습니다. 근데 이 방식의 큰 단점은 영상은 passive data이기 때문에 agent가 특정 action을 취했을 때 실제로 어떻게 움직이고 어떻게 장애물을 피해 돌아갈 수 있는지를 직접 경험할 수 없다는 점입니다.
두 번째는 simulation 기반 학습입니다. CARLA, MetaUrban, UrbanSim 같은 simulator를 사용하면 agent가 실제로 action을 수행하고, reward를 받고, collision을 경험하면서 RL을 할 수 있습니다. 하지만 기존 simulator의 문제는 scene이 핸드 크래프트이거나 procedural generation(사람이 규칙을 정해놓고 컴퓨터가 그 규칙에 따라 scene을 자동 생성하는 방식) 기반이라는 점입니다. CARLA는 씬 퀄리티는 좋지만 사람이 직접 만든 scene이라 스케일 업이 어렵고 MetaUrban이나 UrbanSim은 procedural rule로 scene을 만들기 때문에 실제 도시의 뭔가 좀 messy한 분포를 충분히 반영하기 어렵다고 합니다.
여기서 저자들은 실제 world에 존재하는 city-tour video를 활용해서 real-world distribution을 반영하면서도 agent가 직접 움직이고 상호작용할 수 있는 simulation scene을 대량으로 만들 수 있는지에 대해서 고민을 하고 UrbanVerse라는 방법론을 제안합니다.
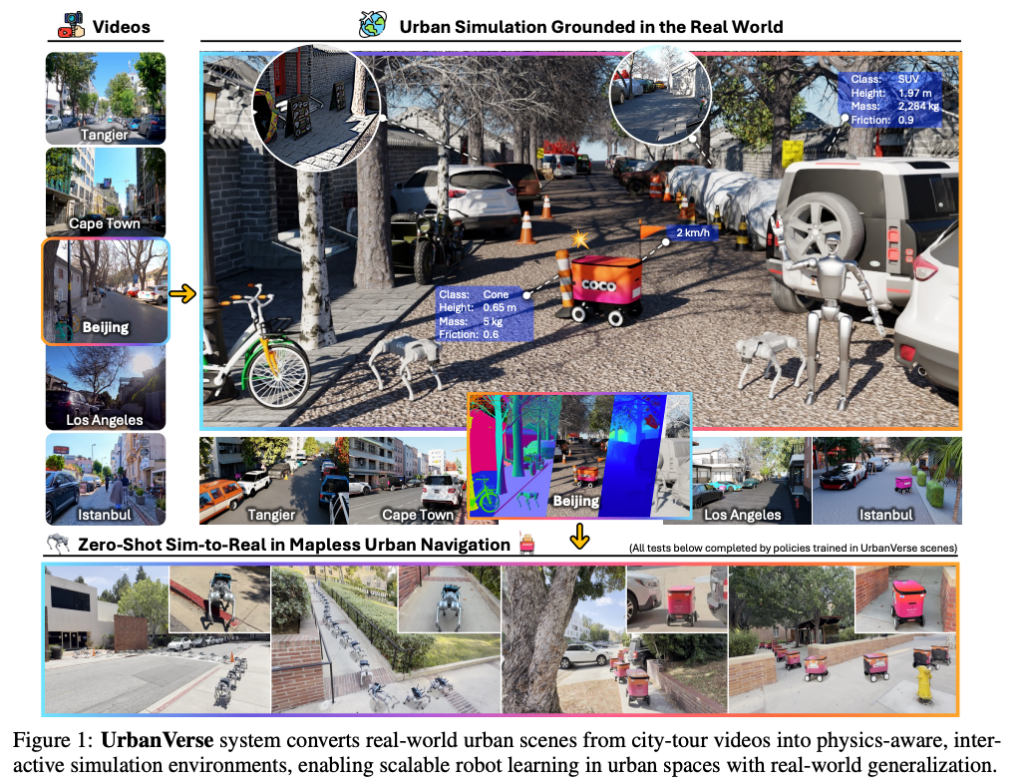
위 Fig 1은 UrbanVerse의 전체적인 목표를 보여주는 그림인데, 왼쪽에는 Tangier, Cape Town, Los Angeles, Istanbul 같은 실제 city-tour video가 있고,오른쪽에는 이 영상으로부터 생성된 simulation scene이 있습니다. 여기서 중요한 건 해당 방법론이 단순히 영상처럼 보이는 3D 렌더링을 잘 하는 것이 아니라 차량, 콘, sidewalk와 같은 것들이 semantic/physical attribute 정보를 잘 가지고 있고 그 위에서 robot policy를 학습했을 때 실제 real-world 환경에서 zero-shot으로 navigation을 수행할 수 있다는 점입니다.
결국 저자들이 제안한 방법론은 urban embodied AI에서도 단순 city tour video를 그냥 offline imitation learning용 데이터로만 쓰는 것이 아니라 interactive한 시뮬레이션 환을를 만들기 위한 소스로 쓸 수 있다는 확장 가능성을 보여줍니다.
CityWalker는 web-scale walking video를 사용해서 urban navigation을 수행하지만 기본적으로 passive한 video 기반이기 때문에 agent가 직접 환경과 상호작용하면서 충돌을 피하는 능력을 학습하기에는 한계가 있다고 합니다. 근데 UrbanVerse는 이런 passive한 비디오를 기반으로 real-world layout과 semantic 피쳐를 뽑고, 이를 3D asset으로 재구성해서 agent가 실제로 움직일 수 있는 interactive environment를 만들고 해당 환경에서 만든 데이터로 학습을 시키면 좀더 환경과 상호작용할 수 있는 그런 policy를 학습할 수 있급니다.
그리고 저자들은 digital cousin scene generation이라는 방향으로 프레임 워크를 설계를 하는데, 실제 video의 정확한 geometry를 완벽히 복원하는 것이 아니라 실제 scene의 layout, semantics, object distribution을 보존하면서, 저자들이 만든 asset database에서 비슷한 3D object를 가져와 simulation scene을 만드는 방식입니다. 즉 Wanderland처럼 정확한 geometry를 복원하는게 아니라 현재 비디오의 씬에 대한 정보를 기반으로 sim에 아주 정밀하게 구현된 asset을 가져와서 해당 비디오 씬처럼 재구성하는 식이다 라고 이해하시면 좋을 것 같습니다.
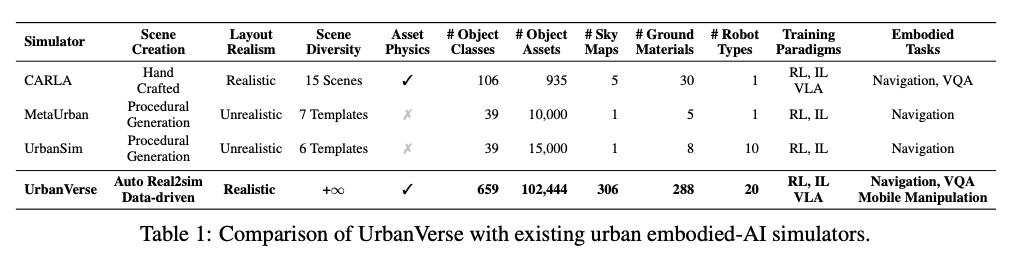
Table 1은 UrbanVerse와 기존 urban embodied AI simulator를 비교한 표입니다. 여기서 저자들이 강조하는 차이는 UrbanVerse가 핸드 크래프트도 아니고 procedural도 아니고 또 object class 수, object asset 수, sky map, ground material, physics annotation, robot type, task support 측면에서 기존 simulator보다 훨씬 더 풍부한 구성을 가진다고 주장합니다.
뭔가 두서 없이 써서 핵심이 없어 보이는데 정리하면 이 인트로에서 저자들이 말하고 싶은 핵심은 Urban embodied AI policy를 잘 학습시키려면 실제 urban 환경과 상호작용이 가능한 시뮬레이션이 필요하고,그 simulation은 단순히 procedural하게 랜덤으로 만든 씬들이 아니라 실제 도시의 layout과 object distribution을 반영해야 한다는 것입니다. 그래서 저자들의 이 UrbanVerse는 real-world distribution fidelity를 만족시키기 위한 framework라고 보시면 좋을 것 같습니다.
Method
UrbanVerse의 Method는 크게 세 부분으로 구성되어있는데, 첫 번째는 도시 시뮬레이션에 필요한 대규모 asset database인 UrbanVerse-100K를 구축하는 것이고 두 번째는 city-tour video로부터 scene layout을 추출하고 simulation scene으로 변환하는 UrbanVerse-Gen pipeline입니다. 그리고 마지막 세 번째는 이렇게 생성된 scene들을 모아 policy learning과 evaluation에 사용할 수 있는 UrbanVerse scene library와 benchmark를 만드는 것입니다.
앞서 인트로에서 설명드렸지만 UrbanVerse는 단순히 video를 3D로 복원하는 논문이라기보다는, 실제 도시 영상에서 semantic layout과 spatial layout을 추출하고 이를 3D asset database와 연결해서 robot이 실제로 움직일 수 있는 interactive simulation scene으로 만드는 framework라고 보시면 좋을 것 같습니다.
자세한 내용은 아래에서 차근 차근 설명드리도록 하겠습니다.
UrbanVerse-100K Asset Database
먼저 UrbanVerse-100K는 UrbanVerse의 기반이 되는 대규모 urban asset database입니다. 저자들은 도시 환경을 제대로 시뮬레이션하기 위해서는 단순히 3D object만 많은 것이 아니라 각 object가 실제 metric scale을 가지고 있어야 하고 mass, friction, affordance 같은 물리적 속성도 함께 필요하다고 봅니다.
이를 위해 저자들은 UrbanVerse-100K는 세 가지 collection으로 구성합니다.
첫 번째는 Object collection로 여기에는 659개 category에 걸친 102,444개의 GLB object가 포함되어 있다고 합니다. 각 object는 semantic label뿐만 아니라 physical attribute와 affordance attribute도 함께 annotation되어 있습니다.
두 번째는 Ground collection입니다. 이는 road와 sidewalk를 표현하기 위한 288개의 photorealistic PBR material로 구성됩니다. 단순히 회색 바닥을 쓰는 것이 아니라, 아스팔트 도로, 콘크리트 보도, 자갈길처럼 다양한 지면 재질을 표현하기 위한 요소입니다.
세 번째는 Sky collection입니다. 이는 306개의 HDRI sky map으로 구성되며, realistic global illumination과 360도 background를 제공하는 역할을 합니다.

위 Fig. 2는 UrbanVerse-100K에 포함된 object asset, ground material, sky map의 예시를 보여주는 그림입니다. UrbanVerse가 object뿐만 아니라 ground와 lighting 조건까지 함께 다양화하려고 했다라는 것을 보여주는 그림이라고 보시면 좋을 것 같습니다.
근데 여기서 중요한 점은 저자들이 모든 asset을 처음부터 직접 모델링한 것은 아니라고 합니다. Object asset은 주로 Objaverse에서 가져오고, ground material은 FreePBR과 AmbientCG에서, sky map은 PolyHaven에서 수집했다고 합니다. 다만 이를 그대로 사용하는 것이 아니라, 도시 시뮬레이션에 적합하도록 filtering, categorization, metric-scale normalization, physical annotation을 직접 저자들이 따로 수행했다고 합니다.
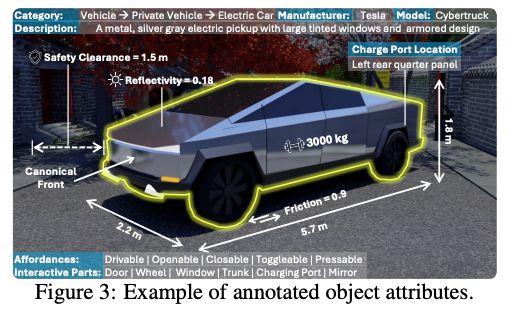
위 Fig. 3은 Tesla Cybertruck asset에 대해 height, mass, friction, affordance, interactive parts 등이 annotation된 예시입니다. 이 그림은 UrbanVerse-100K가 단순한 3D object 모음이 아니라, 시뮬레이션 위robot interaction을 고려한 physics aware한 asset database라는 점을 보여줍니다.
UrbanVerse-Gen Scene Construction Pipeline
위까지가 asset을 구성하는 부분이라면 이제 부터가 실제 interacitve simulation scene을 만드는 파이프라인이라고 보시면 좋을 것 같습니다.
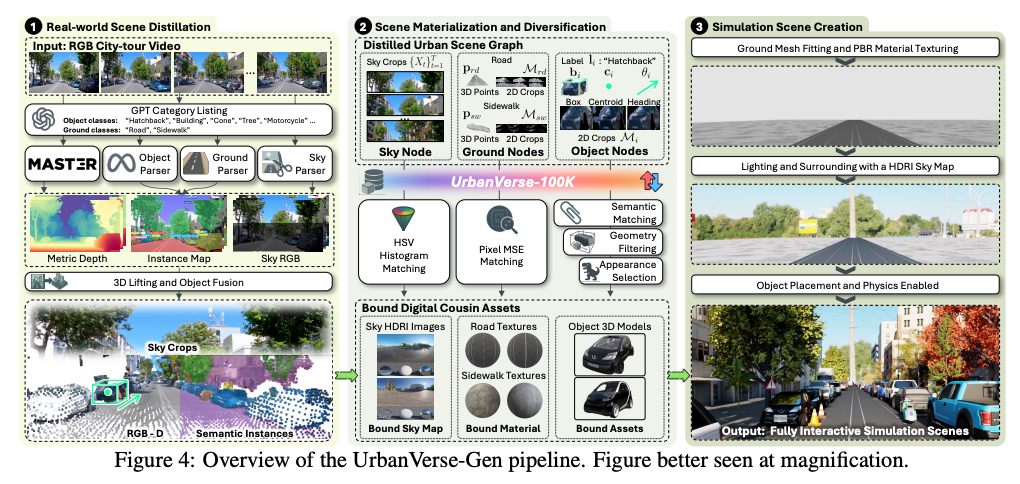
UrbanVerse-Gen은 uncalibrated RGB city-tour video를 입력으로 받아서 실제 도시의 layout을 반영한 interactive simulation scene을 자동으로 생성하는 pipeline입니다.
Fig 4에 나온 것 처럼 UrbanVerse-Gen의 과정은 크게 세 단계로 이루어져 있습니다.
첫 번째는 Real-world Scene Distillation 단계로 이 단계에서는 입력 video에서 object, ground, sky 정보를 추출합니다. 먼저 GPT-4.1을 사용해 영상에 등장할 수 있는 object category 후보를 만들고, MASt3R를 사용해 depth, camera intrinsics, camera pose를 추정합니다. 그리고 이후 YOLO-World와 SAM2를 사용해 object detection과 instance segmentation을 수행하고, 이 2D mask들을 depth와 pose를 이용해 3D 공간으로 리프팅합니다. 그리고 이렇게 비디오에서 추출한 정보들을 3D urban scene graph로 정리합니다. 이 scene graph는 크게 object node, ground node, sky node로 구성됩니다.
Object node는 car, building, cone, tree 같은 물체를 의미하고 category, location, orientation, appearance 정보를 포함합니다. Ground node는 road와 sidewalk를 의미하고 마찬가지로 각 ground의 spatial 정보와 appearance 정보를 가집니다. Sky node는 조명 조건과 distant background를 담는 역할을 위한 정보를 가지고 있다고 보시면 좋을 것 같습니다.
이 과정은 video를 바로 simulation scene으로 바꾸는 것이 아니라 먼저 이 장면에 어떤 object가 어디에 있고, 도로와 보도는 어디이며 또 하늘과 조명은 어떤지를 scene graph 형태로 정리한 뒤,이를 기반으로 simulation을 생성하도록 하기 위한 설계도를 만드는 과정이다 라고 이해하시면 좋을 것 같습니다.
두 번째는 Scene Materialization and Diversification입니다. 앞 단계에서 만든 scene graph는 단순히 설계도 이기 때문에 이 위치에 car가 위치해야 한다는 것은 알지만 실제 IsaacSim에 넣을 car asset은 아직 정해지지 않은 상태입니다. 그래서 해당 부분에서는 UrbanVerse-100K에서 각 node에 맞는 digital cousin asset을 찾아서 매칭하는 과정이라고 보시면 좋을 것 같습니다. 이 매칭 과정 역시 또 세 단계로 진행됩니다. 먼저 CLIP을 사용해 semantic matching을 수행하여 object label과 잘 맞는 카테고리들을 찾고 그 다음으로 object의 3D bounding box와 asset bounding box를 비교해 geometry가 비슷한 후보를 남깁니다. 그리고 마지막으로 DINOv2 feature를 사용해 video crop과 asset thumbnail의 appearance similarity를 비교하여 최종 asset을 선택합니다. (완전 색까지 비슷한 asset선택) 그리고 Ground node의 경우에는 road와 sidewalk crop에 가장 비슷한 PBR material을 선택하고, sky node의 경우에는 sky crop과 비슷한 HDRI sky map을 선택힌다고 합니다. 여기서 중요한 점은 하나의 scene graph에서 하나의 scene만 만드는 것이 아니라, 여러 개의 digital cousin을 만들 수 있다는 점입니다. 같은 layout을 유지하면서도 car asset, road material, sky lighting 등을 다르게 선택하면 다양한 simulation scene을 만들 수 있습니다.
그리고 마지막 세 번째는 Simulation Scene Creation입니다. 이 단계에서는 선택된 asset, ground material, sky map을 실제 IsaacSim scene 안에 배치하는 과정입니다. erical background로 적용합니다. 이를 통해 하늘 배경뿐 아니라 전체 scene의 조명 조건도 함께 설정됩니다. Object는 앞서 추정된 geometry 정보를 기반으로 해당 위치에 배치되고, object heading에 맞게 방향이 정렬된다고 합니다. 이후 object끼리 겹치거나 바닥에 박히는 penetration이 발생하지 않도록 위치를 조정하고 마지막으로 각 object에 mass, friction 같은 physical parameter를 부여하고 rigid-body dynamics를 활성화한다고 합니다. 정리하면 UrbanVerse-Gen은 city-tour video에서 추출한 layout을 기반으로, 실제 scale을 가진 object와 ground, sky, physics 속성을 포함한 interactive urban simulation scene을 생성하는 과정이다라고 이해하시면 좋을 것 같습니다.
Dynamic Agent Population
UrbanVerse는 static scene만 생성하는 것이 아니라, pedestrian, car, wheelchair user, scooter rider 같은 dynamic agent도 배치할 수 있습니다. 그래서 저자들은 이런 real 환경에서의 dynamic요소도 포함시키고자 ORCA 기반 planner를 사용해서 실제 시뮬레이션에 액터들을 심어뒀다고 합니다.
각 scene에서 2D occupancy map을 만들고, dynamic agent의 start-goal pair를 sampling한 뒤, collision-free path를 계산합니다. 이후 agent들은 simulation 중에 velocity를 계속 조정하면서 서로 충돌하지 않도록 움직입니다.

Fig 5는 UrbanVerse scene 안에 pedestrian, car, wheelchair user, scooter rider 같은 다양한 dynamic agent가 배치된 예시를 보여줍니다.
UrbanVerse Scene Library and Benchmark
마지막으로 저자들은 UrbanVerse를 사용해 policy learning과 evaluation을 위한 scene library를 구축합니다.
Training library는 Creative Commons License로 공개된 YouTube city-tour video 32개를 기반으로 만들었다고 합니다. 이 영상들은 7개 대륙, 24개국, 27개 도시에 걸쳐서 각 video는 UrbanVerse-Gen을 통해 하나의 layout-grounded scene으로 변환되고 이후 각 layout에서 5개의 digital cousin variant를 생성하여 총 160개의 training scene을 생성했다고 합니다. ( 전체 training scene 수는 32개의 city-tour video layout × 5개의 digital cousin = 160 scenes )
그리고 또 closed-loop evaluation을 위해 두 가지 benchmark를 구성합니다. 첫 번째는 AutoBench로 training에 사용하지 않은 hold-out city-tour video로부터 자동 생성한 10개의 scene이라고 보시면 될 것 같고 그리고 두 번째는 CraftBench로 CraftBench는 3D artist가 직접 만든 10개의 test scene라고 보시면 될 것 같습니다.

위는 3D artist가 만든 CraftBench의 10개 test scene을 보여줍니다. autobench 보다는 좀더 어려운 그런 씬들을 많이 포함하도 있다고 합니다. 왜냐면 CraftBench는 artist-designed scene으로 구성되어 있기 때문이고 또 UrbanVerse-Gen이 만든 scene과는 다른 distribution에서 policy generalization을 평가할 수 있다고 합니다.
Experiments
실험은 크게 세 가지를 평가합니다. UrbanVerse-Gen이 실제 video로부터 scene semantics와 layout을 얼마나 잘 복원하는지 그리고 UrbanVerse scene을 scale-up해서 학습하면 policy generalization이 좋아지는지 마지막으로 UrbanVerse에서 학습한 policy가 실제 robot으로 zero-shot sim-to-real transfer가 되는지를 평가합니다.
각각 차례대로 보겠습니다.
Scene Construction Fidelity and Quality
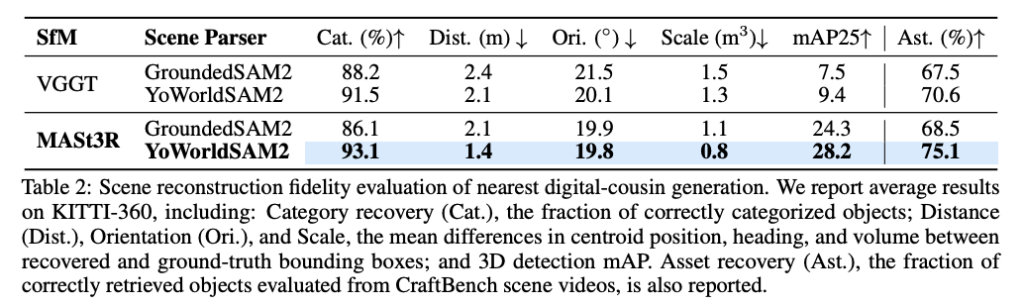
먼저 scene construction fidelity 실험입니다. 저자들은 KITTI-360의 45개 video sequence를 사용해서 UrbanVerse-Gen이 object category, 위치, orientation, scale을 얼마나 잘 복원하는지 평가합니다. 여기서 MASt3R와 VGGT를 SfM model로 비교하고, GroundedSAM2와 YoWorldSAM2를 scene parser로 비교해서 평가합니다. Table 2를 보면 MASt3R + YoWorldSAM2 조합이 가장 좋은 성능을 보입니다. 그래서 저자들은 이 조합을 기본 세팅으로 가져가서 평가를 진행했다고 합니다.

Fig7은 정성적 결과인데 Cape Town과 Morocco city-tour video에서 생성된 UrbanVerse scene을 보여줍니다. 도로변에 있는 차량, 건물, 오토바이, crane 같은 object placement가 꽤 그럴듯하게 재현되는 모습을 확인할 수 있습니다.

다음은 human evaluation입니다. 저자들은 32명의 undergraduate participant를 대상으로 UrbanVerse scene과 UrbanSim procedural generation scene을 비교합니다. diversity, layout, 전반적인 realism 측면에서 UrbanVerse가 더 선호되는지를 평가하고 별도로 scene quality rating도 진행했다고 합니다.
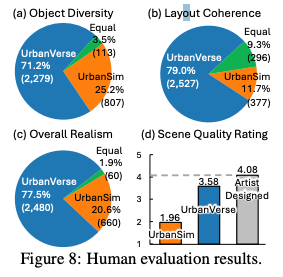
Fig 8을 보면 참가자들은 이런 설문조사 a-c 모두에서 UrbanVerse를 UrbanSim보다 더 선호하는 결과를 보입니다.
Scaling UrbanVerse for Policy Generalization
저자들은 UrbanVerse scene에서 PPO 기반 mapless urban navigation policy를 학습합니다. Task는 position-goal navigation입니다. Agent는 RGB observation과 goal relative position만 받고, global map은 사용하지 않았다고 합니다.
이 실험에서는 복잡한 foundation model이나 large-scale transformer를 쓰는 것이 아니라, RGB encoder와 goal MLP를 가진 actor-critic PPO 구조를 사용합니다.
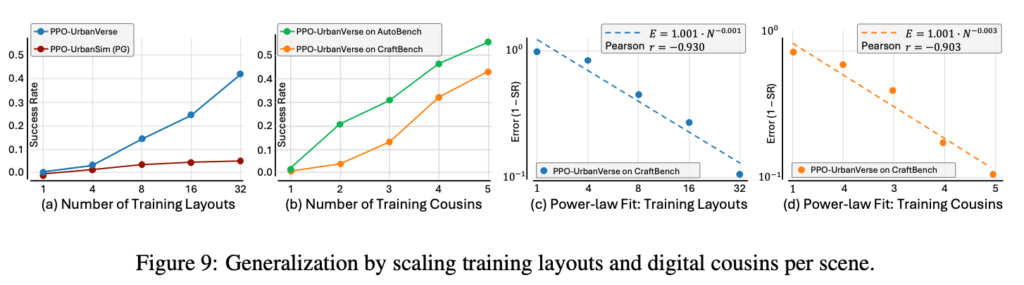
Fig9는 training layout 수와 digital cousin 수를 늘렸을 때 policy 성능이 어떻게 변하는지를 보여줍니다.
먼저 layout 수를 늘리면 UrbanVerse에서 학습한 PPO policy의 success rate가 꾸준히 증가하는 반면 UrbanSim procedural generation scene에서 학습한 PPO policy는 layout 수를 늘려도 성능 향상이 크게 나타나지 않는 결과를 보입니다. 저자들은 여기서 단순히 scene 개수만 많다고 generalization이 좋아지는 것이 아니라 그 scene들이 실제 도시 분포를 잘 반영해야 한다라고 주장합니다.
다음으로 digital cousin 수를 늘리는 실험도 있습니다. 하나의 layout에서 top-k asset을 다르게 선택해 여러 cousin scene을 만들면, 같은 layout 구조를 유지하면서도 object appearance, geometry, material, lighting이 달라집니다. Figure 9(b)를 보면 cousin 수가 증가할수록 AutoBench와 CraftBench 성능이 모두 좋아지는 결과를 보입니다.
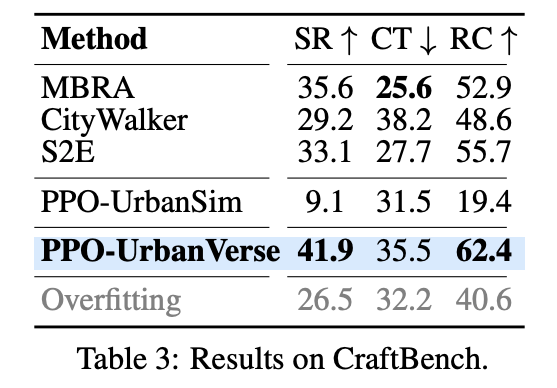
Table 3은 CraftBench에서 여러 baseline을 비교한 결과입니다. 여기서 PPO-UrbanVerse가 가장 좋은 성능을 보입니다. PPO-UrbanVerse가 복잡한 navigation foundation model이 아니라 오히려 simple PPO policy인데도 UrbanVerse에서 interactive하게 학습했기 때문에, passive data 기반 복잡한 model보다 더 좋은 성능을 보였다고 합니다.
Zero-Shot Sim-to-Real Policy Transfer
마지막은 real-world sim-to-real transfer 실험입니다.

저자들은 UrbanVerse 160개 scene에서 학습한 PPO-UrbanVerse policy를 실제 도시 환경 16개 scenario에 zero-shot으로 배포합니다. robot platform은 두 가지입니다. 하나는 Coco wheeled delivery robot이고 다른 하나는 Unitree Go2 quadruped입니다. 각 route는 평균 24.6m이고, 각 실험은 세 번 반복했다고 합니다. 평가 metric은 SR, CT, RC, DTG입니다. 각 지표에 대해서 간단하게 설명드리면 SR은 goal에 도달한 episode 비율입니다. CT는 Collision Time으로 전체 episode 시간 중 collision 상태에 있던 비율 그리고 RC는 Route Completion으로 종료 전까지 route를 얼마나 진행했는지 나타냅니다. DTG는 Distance to Goal, 즉 종료 시점에서 goal까지 남은 거리입니다.
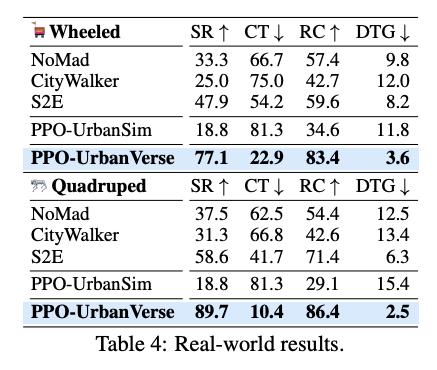

Table 4를 보면 두 플랫폼 모두에서 PPO-UrbanVerse는 제일 좋은 성능을 보입니다. 저자들은 이결과를 가지고 UrbanVerse에서 학습한 interactive capability가 실제 환경으로 transfer된다는 점을 주장합니다. 다른 model들은 obstacle-free case에서는 어느 정도 잘하지만, turning 후 갑자기 장애물이 나타나거나, sidewalk가 막혀 있거나, crossing 상황이 나오면 실패하는 경우가 많다고 설명합니다. 근데 PPO-UrbanVerse는 UrbanVerse 안에서 obstacle avoidance를 직접 경험했기 때문에 실제 환경에서도 더 안정적인 obstacle avoidance를 보인다고 주장합니다.
Figure 10은 real-world 결과 visualization입니다. 실제 robot이 goal까지 이동하는 trajectory와 중간 장면이라고 합니다.

위는 16개 real-world testing scenario를 보여주는 그림입니다.. 단순히 몇 개의 쉬운 route에서 테스트한 것이 아니라, 실제 urban navigation에서 문제가 되는 case들을 의도적으로 구성해서 실험을 진행했따고 합니다.
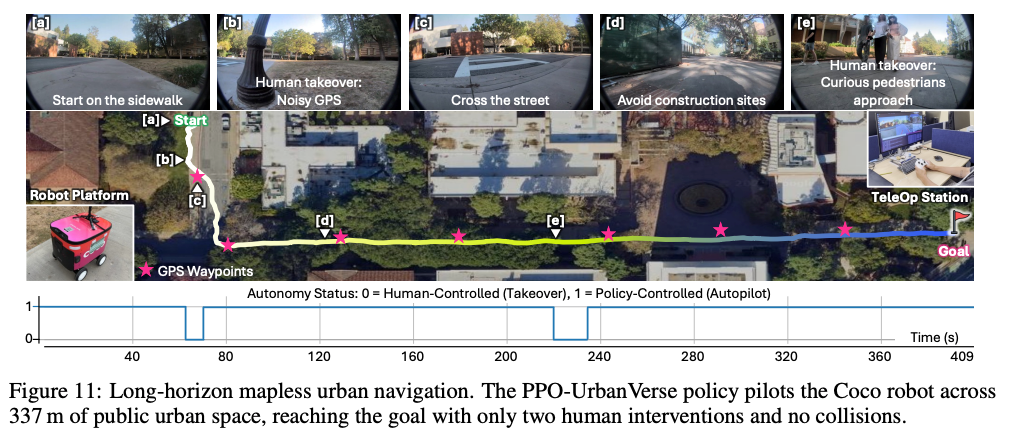
위 Fig 11은 장거리 real-world 수행 결과입니다. PPO-UrbanVerse policy가 Coco robot을 337m public urban space에서 주행시키고 두 번의 human 개입만으로 goal에 도달했다고 합니다. GPS waypoint는 10m 간격으로 주어졌다고 합니다. 물론 두 번의 human 개입이 있었고, 완전 success라고 표현하기에는 좀 그렇지만 UrbanVerse에서 학습한 policy가 단순한 simulation 결과에 머무르지 않고 실제 deployment 가능성을 보여주기 위한 실험으로 넣지 않았나 싶습니다.
Conclusion
이런 UrbanVerse-Gen은 wanderland랑은 다르게 RGB city-tour video 기반이기 때문에 입력 영상 품질에 영향을 받을 수 있다는 한계가 있긴합니다. 그래서 카메라가 빠르게 움직인다던가 심한 occlusion이 있는 경우에 depth나 pose 추정에 drift가 생길 수 있기 떄문에 결과적으로 이런 geometry 정보가 부정확해질 수 있다는 점은 여전히 해결해야할 문제인 것 같습니다. 이만 리뷰 마치도록 하겠습니다.
안녕하세요 우현님 리뷰 감사합니다.
Manipulation 쪽과 비슷하게 Large Scale data asset으로 부터 retrival을 통해 digital cousin을 만드는 연구가 나온 것 같습니다. 정말 방대한 Asset Library에서 검색을 해야하고 시뮬레이션 내에 배치해야 함과 동시에 asset library에 있는 asset 자체의 좌표계가 일관되게 정의되지는 않았을 것 같은데, 대응되는 Asset을 검색하고 Mast3R를 통한 depth에 align 시키는 과정에서 해당 문제에 대한 이야기는 없었나요?
안녕하세요 영규님 좋은 댓글 감사합니다.
제가 이해한 바로, 저자들이 asset library의 좌표계나 또 추가적으로 생길 수 있는 scale inconsistency 문제를 완전히 별도의 문제로 깊게 분석한 것은 아니지만 pipeline 안에서 이를 완화하기 위한 처리는 어느 정도 들어가 있긴합니다.
먼저 UrbanVerse-100K를 구축할 때 각 asset에 대해 size와 front-view를 annotation하고, 이를 이용해 모든 asset을 metric scale과 consistent orientation으로 표준화했다고 설명합니다. Objaverse에서 가져온 asset을 그대로 쓰는 것이 아니라 실제 크기 단위와 방향을 맞추는 전처리를 수행했다고 합니다.
그리고 UrbanVerse-Gen에서 asset retrieval 과정에서 바로 asset을 하나 고르는 것이 아니라 먼저 CLIP 기반 semantic matching으로 category를 맞추고 그 category 안에서 object의 3D box와 후보 asset box 사이의 distortion을 기준으로 geometry filtering을 수행합니다. 이 과정이 depth,layout에서 추정된 크기와 asset 크기가 크게 어긋나는 경우를 줄이기 위한 장치이지 않을까 싶습니다.
그리고 마지막 scene generation 단계에서는 선택된 asset을 centroid 위치에 배치하고 asset의 canonical front를 추정된 heading과 align한 뒤,object끼리 서로 뚫고 들어가는 penetration이 생기지 않도록 위치를 조정하는 방식으로 뭔가 전반적인 align을 이런식으로 맞추고자 한것 같습니다.
근데 말씀해주신 것처럼 실제로 asset coordinate가 완전히 일관되지 않거나 MASt3R depth/pose 추정에 drift가 생기는 경우에는 위치 오차가 발생할 수 있을 것 같습니다. 실제로 이미지 기반으로 기하학정보를 알아내는 것은 여전히 부정확하기 때문에 이런 문제는 한계인 것 같습니다.
감사합니다.