안녕하세요 다시 Visual Place Recognition 논문으로 돌아왔습니다. 오늘 소개할 논문은 Learnable Query를 이용하여 VPR을 진행하는 논문입니다. 정말 간단한 구조로 이루어져 있지만 높은 성능을 달성하였습니다. 시작해보겠습니다.
Introduction
VPR에서는 항상 DB와 현재(query)과의 환경이 다른 것이 문제입니다. 다른 환경은 시간대, 날씨, 계절, 물체 등 정말 다양한 것이 달라집니다. 그래서 VPR을 잘하기 위해서는 어떤 상황이든 존재하며, 또 장소를 구분하기에 충분히 구분력 있는 것을 잡아내어야 합니다.
물론 이게 쉽지 않습니다. 왜냐하면 query로 들어오는 이미지와 데이터베이스(DB)의 이미지는 view point도 달라지고 심지어 카메라 세팅도 다를 수 있습니다. 게다가 빠른 비교를 위해서 저장하는 특징기술자(descriptor)는 적은 용량으로 저장해야합니다.
기존에는 이러한 상황에서 CNN backbone을 이용하여 feature를 추출한 후, VLAD와 같은 방식을 이용하여 장소를 구분했습니다. 이후 NetVLAD, GeM과 같은 다양한 기법으로 더욱 특징적인 부분을 잡아내어 구분력을 올렸습니다. 그리고 ViT와 DINOv2가 VPR에서 강한 성능을 보인다는 것을 AnyLoc가 증명한 이후에는 모든 이들이 DINOv2를 backbone으로 사용하고 이후 aggregation을 발전시키거나 Re-ranking을 통해 비용이 높아지더라도 높은 성능을 가지도록 설계하였습니다.
그러나 처음부터 끝까지, feature map이 backbone에 의해 완성된 이후에 그걸 활용하는 방식이였습니다. 오늘 리뷰할 BoQ는 이것을 지적합니다. Feature map을 후처리하여 장소인식을 위한 descriptor로 생성하는 것이 아닌 learnable query를 이용하여 장소인식에 적합한 특징들만 추출하자는 아이디어를 제시합니다. Learnble query가 정말 많이 쓰이는 세상에(e.g. DETR, latent query, VPR 등등) 이것이 VPR을 위한 aggregation을 효율적으로 할 수 있음을 증명한 논문이라고 보면 될 것 같습니다.
Methodology
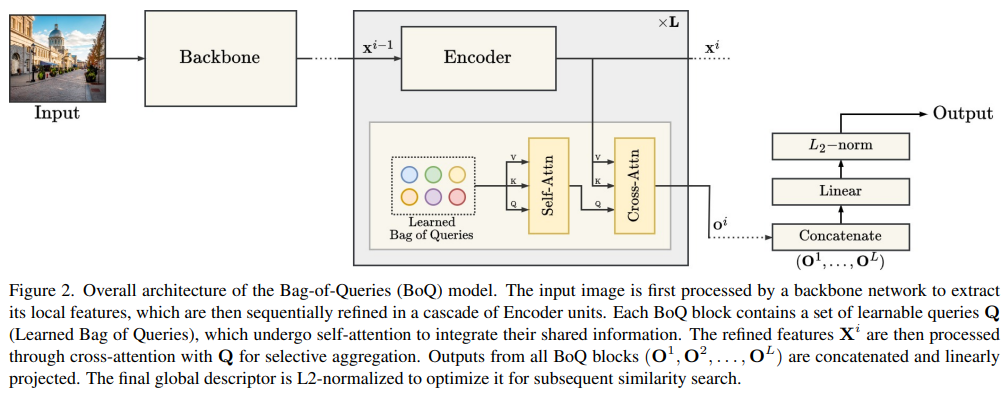
저자들은 새로운 aggreagation 방법인 BoQ(Bag-of-Queries)를 제안합니다. end-to-end로 학습하고 간단한 것이 장점입니다.
BoQ는 CNN과 ViT backbone 모두 적용될 수 있습니다. N개의 patch와 channel 차원을 d라고 할 때, patch embedding X = [x_1^0, x_2^0, ..., x_N^0]으로 표현할 수 있습니다.
따라서 i번째 layer를 타고 나온 결과는 아래 수식처럼 표현됩니다.
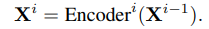
이제 BoQ block입니다. BoQ block은 M개의 learnable query들을 가지고 있습니다. 그리고 이는 Q^i로 표현합니다.(저자는 learnable query와 query image를 혼동하지말라고 친절히 설명까지해줍니다..)
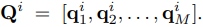
각 BoQ block은 aggregation하기 전에 먼저 self attention을 거칩니다. 그리고 Q^i와 X^i 사이에 cross attention을 진행합니다. 이때 Q^i가 Query, X^i가 Key/Value입니다.
이렇게 layer마다 Self/Cross attention을 거친 BoQ Block은 이후 concat되어 최종 descriptor로 표현합니다(+L2 norm도 해줍니다).
총 정리를 해보자면, 결국 learnable query M개를 self attention한 후, backbone의 각 layer output과 cross attention을 해주었고 이것을 concat하여 최종 descriptor로 사용하였다고 정리할 수 있습니다. 정말 간단합니다.
Relations to other methods
Learnable Query는 다른 분야에서도 활발히 쓰입니다. 저자들은 그것과 어떤게 다른지 얘기해줍니다. 먼저 DETR(Detection Transformer model)입니다. DETR은 residue connection이 존재하기 때문에, query가 출력의 일부가 됩니다. 그러나 BoQ는 residue가 없는 순수 cross attention이기 때문에 exclusively하게 정보를 추출하고 모이기만 한다고 합니다. 그리고 이것이 DETR과 가장 큰 차이입니다.
NetVLAD와의 비교입니다. NetVLAD는 learned cluster center를 정의하고, 이를 중심으로 잔차를 가중합해줍니다. BoQ는 dynamically cross attention을 통해 상관관계를 계산하기 때문에 다르다고 합니다.
Experiments
Training
학습은 대부분의 SOTA VPR이 따르는 추세 그대로 학습되었습니다. training dataset으로는 GSV-Cities를 선택하였고, 해당 데이터셋은 place-sampling되었기 때문에 Multi-Similarity loss를 사용하였습니다. 다만 저자가 강조하는 것은 NetVLAD, CosPlace, EigenPlaces와 같은 방법론은 480×640로 학습하지만 우리는 더 작은 resolution으로 학습한다는 것을 강조합니다.
Result
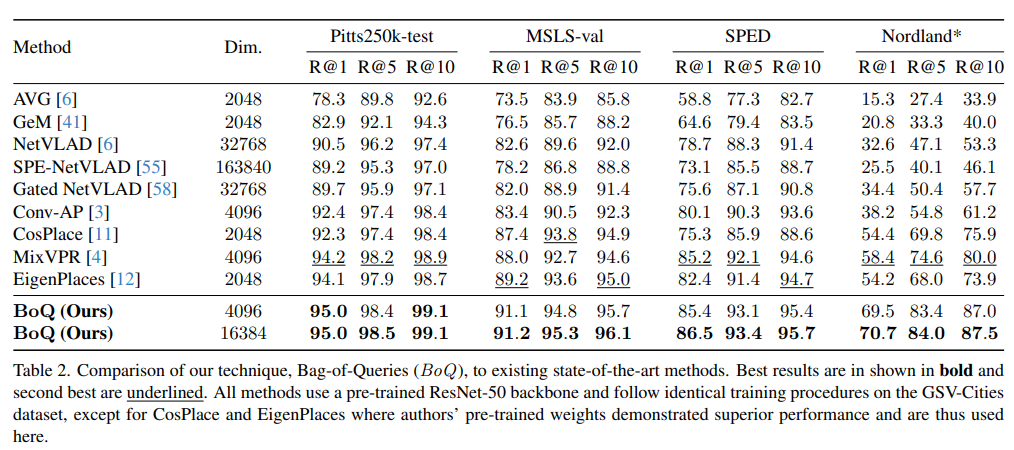
모든 지표에서 높은 성능을 보이는 것을 확인할 수 있습니다. 그중 가장 두드러지는 것은 Nordland입니다. Nordland는 계절에 따른 변화가 큰 데이터셋으로 굉장히 어려운 것으로 유명합니다. 그러한 Nordland에서 이전 SOTA인 MixVPR과 12%가 넘는 차이는 냈습니다. 또한 개인적으로 놀라운 것은 Descriptor를 linear를 태워 16384->4096로 낮췄음에도 성능 하락이 거의 없다는 점입니다.
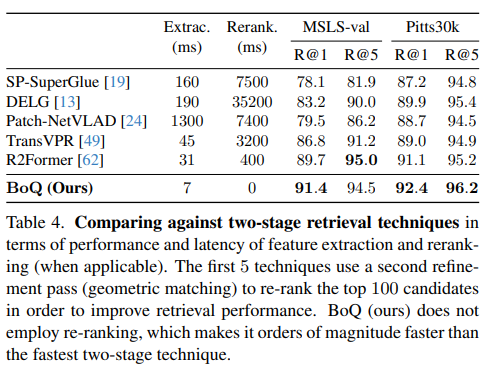
Table 4.는 re-ranking하는 방법론과의 비교입니다. R2Former에게 MSLS-val(R@5)에서 진것을 제외하면 다 이기는 것을 볼 수 있습니다. 심지어 MSLS-val도 가장 어려운 지표인 R@1에서는 꽤 큰 차이로 이기는 것을 볼 수 있습니다. 그리고 BoQ는 re-ranking이 아닌 1stage 방법론이기에 Reranking 속도가 0입니다. 그렇기에 저자는 우리는 엄청나게 빠른데도 무거운 방법론들보다 우월하다~를 보여주고 있습니다. 논문 쓸 맛날 것 같습니다.
Ablation Studies
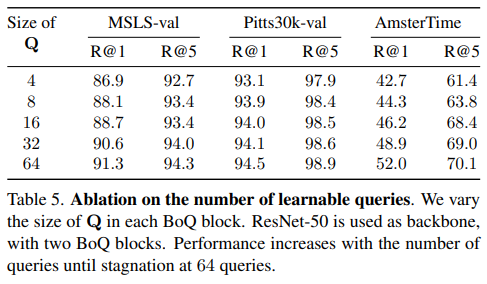
Table 5.는Query의 개수에 따른 성능 비교입니다. 성능적으로 64개가 제일 좋은 것을 볼 수 있습니다. 저자는 query의 개수가 많아져도 less diverse한 scene(Pitts30k)에서는 향상이 marginal(0.2%)이지만 high diverse한 scene(AmsterTime)에서는 큰 향상을 불러왔다고 합니다.
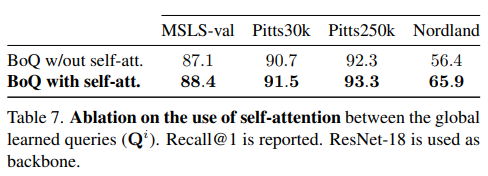
Table 7.는 BoQ block에서 self attention의 여부에 따른 성능 비교입니다. 특히, Nordland에서 차이가 큰 것을 볼 수 있습니다. 저자는 BoQ block의 self-attention까지는 cached 놓으면 더 빨라질 수 있다고도 추가적으로 얘기합니다.
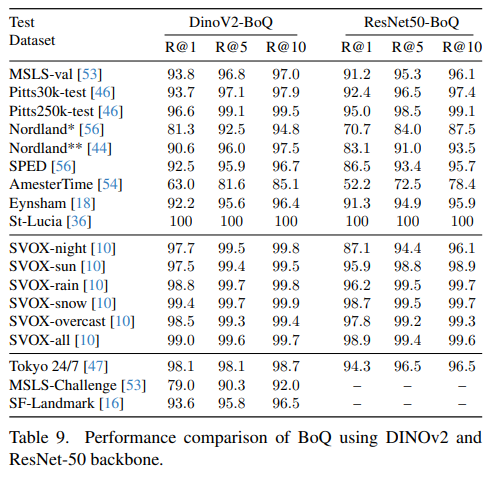
Table 9.는 DINOv2와 ResNet50에 따른 비교입니다. 사실 저자가 논문을 쓰기 시작했을 때는 DINOv2가 주류가 아니였다고 합니다(AnyLoc이 2023, 이 논문이 2024긴 합니다). 그래서 위 모든 실험은 ResNet으로 진행되었습니다. 그리고 이것만으로 SOTA를 달성했습니다. 저자들은 DINOv2가 VPR에 좋다더라니까 한번 실험해볼게~ 느낌으로 추가 ablation을 진행하였습니다. 그리고 모든 지표에서 높은 성능향상을 보였습니다.
Visualization
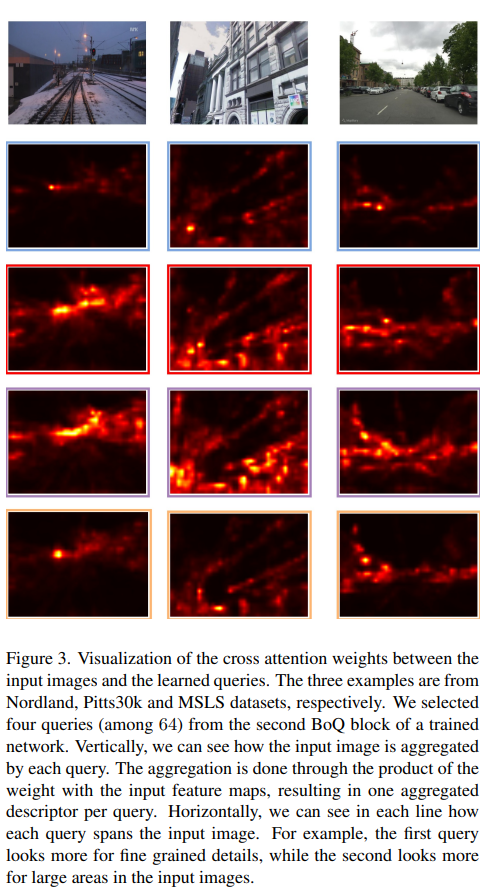
Figure 3.은 64개의 learnable query중 4개를 골라서 시각화한 것입니다. 이를 통해, 각 query가 어느부분을 보고 있는지를 시각화했습니다. 보면 첫번째(파랑색) query가 더 fine-grained 디테일에 집중하고, 두번째(빨강색)은 더 넓은 영역에 집중하는 것을 볼 수 있습니다.
안녕하세요 정우님
좋은 리뷰 감사합니다.
제가 잘 이해한지는? 모르겠지만 읽으면서 궁금한 부분이 있었는데요
learnable query가 결국 이미지에 대한 정보를 함축하고 이를 통해서 learnable query만 사용하면 되므로 게산량이 감소한다 이렇게 이해하는게 맞을까요? 그러면 학습 과정에서 본 장소만 이해할 수 있을 것 같기도 한데.. VPR이 실제 어디에 쓰이는지 알 수 있을까요?
감사합니다.
안녕하세요 인하님 좋은 질문 감사합니다.
1. BoQ에서 learnable query는 Cross attention으로 정보를 가져오는 query의 역할을 하게됩니다.
제한된 64개의 query만 가지고 모든 장소를 구분력 있게 분별할 수 있어야하므로
잘 구분할 수 있는 예리한 부분을 잡아내도록 학습됩니다.
그러므로 처음 보는 이미지가 들어와도 예리한 query에 의해 구분력 있는 descriptor를 만들 수 있습니다.
2. 그리고 연산량은 결국 DINOv2를 쭉 태워야하기에 여전히 무겁습니다.
감사합니다.