안녕하세요. 이번에 리뷰로 가져온 논문은 Can Vision Foundation Models Navigate? Zero-Shot Real-World Evaluation and Lessons Learned라는 논문입니다. 제목 그대로 최근 mobile robot navigation 쪽에서 많이 사용되는 VNM(Visual Navigation Model) 들이 실제 real-world 환경에서 zero-shot으로 얼마나 잘 동작하는가를 평가한 논문이라고 보시면 좋을 것 같습니다.
지금까지 VNM들은 보통 Success Rate 즉 목표에 도달했는지만 중심으로 평가되어 왔는데 이 논문은 단순히 어떤 모델이 SR이 높다를 보는 것이 아니라, path length, distance to goal, collision, topological node error, goal prediction, LPIPS/DSSIM/PSNR 같은 visual metric, 그리고 blur, sunflare perturbation에 대한 robustness까지 함께 평가를 다시하는 그런 논문이라고 보시면 좋을 것 같습니다. 해당 논문이 요즘 제가 계속 고민하고 있는 mobile robot navigation benchmark 문제랑 잘 연결되는 것 같아서 읽게 됐고 리뷰로 들고 왔습니다. 자율주행 쪽은 NAVSIM, Bench2Drive, HUGSIM처럼 점점 평가 프로토콜이 정교해지는 흐름이 있는데 mobile robot visual navigation 쪽은 여전히 각 논문이 자기 환경에서 자기 방식으로 평가하는 경우가 많습니다. 이런 상황에서 해당 논문은 VNM을 제대로 평가하기 위해서 어떤식의 설계를 하고 평가를 했는지 한번 리뷰하도록 하겠습니다. 바로 리뷰 시작하도록 하겠습니다.
Introduction
기존 visual navigation 연구에서는 camera-only robot navigation을 목표로 합니다. 즉 LiDAR나 pre-built metric map 없이, 로봇이 보는 RGB 이미지와 goal 이미지만 가지고 목표 지점까지 이동하는 문제입니다. 이런 방식은 전통적인 geometric map 기반 navigation보다 확장성이 좋고 다양한 환경에 일반화될 수 있다는 장점이 있습니다.
Visual Navigation Model, 줄여서 VNM은 보통 다음과 같은 입력을 받습니다. 현재 시점의 observation 이미지, 과거 몇 장의 이미지 history, 그리고 goal 이미지입니다. 모델은 이 입력을 바탕으로 다음 waypoint 또는 future trajectory를 예측합니다. 일부 모델은 현재 위치에서 goal까지 얼마나 남았는지를 나타내는 temporal distance도 함께 예측합니다.
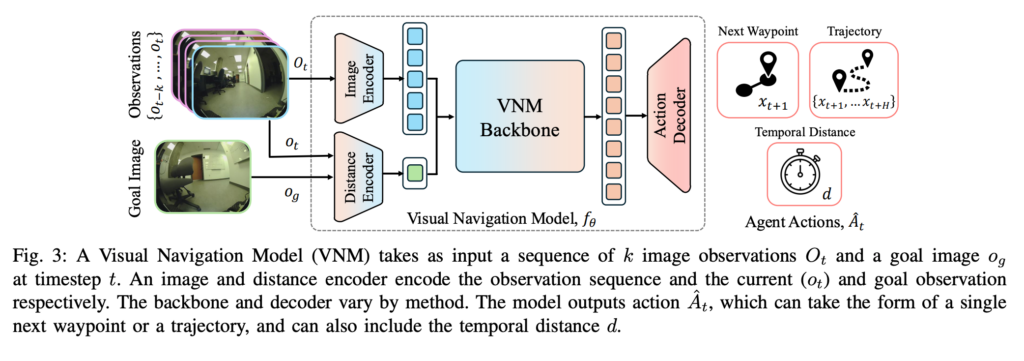
위 Fig. 3은 VNM의 일반적인 구조를 보여줍니다. observation history와 goal 이미지가 각각 이미지 encoder와 distance encoder를 거치고, backbone과 decoder를 통해 다음 가야할 waypoint 또는 trajectory, temporal distance를 출력하는 흐름을 보여줍니다.
그런데 문제는 이런 VNM들이 점점 foundation model처럼 이야기되고 있음에도 불구하고 실제 real-world deployment에서 어떤 방식으로 실패하는지에 대한 분석은 아직 부족했다는 점입니다. 많은 논문들이 목표에 도달했는가?를 중심으로 평가하지만 이것만으로는 모델의 실제 한계를 파악하기는 힘듭니다.
예를 들어 success는 했지만 경로가 매우 길게 빙글 빙글 비효율적으로 돌아서 갔을 수도 있고 로봇이 중간에 여러 번 부딪혔을 수도 있습니다. 반대로 goal 이미지와 비슷한 장소를 goal로 착각해서 얼리 스탑을 했을 수도 있습니다. 이런 경우 단순 SR만 보면 왜 실패했는지 알 수가 없습니다.
그래서 저자들은 이런 문제를 지적하고 VNM을 실제 로봇 플랫폼 두 개, 즉 Bunker tracked mobile robot과 Spot quadruped robot에 올려서 총 다섯 개 환경에서 다시 평가를 합니다. 환경은 실내 corridor, office loop, stairs, arena뿐만 아니라 outdoor snow 환경까지 포함합니다.
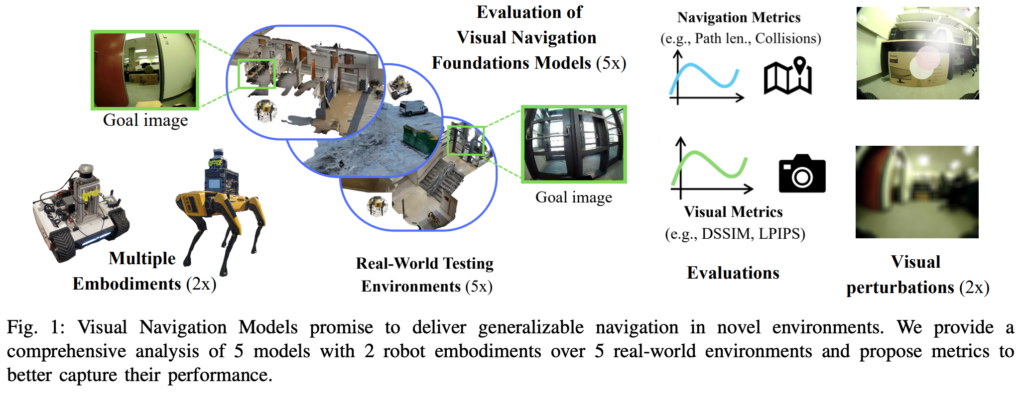
Fig. 1은 이 논문의 전체 평가 구성을 요약한 그림이라고 보시면 좋을 것 같습니다. 두 개의 robot embodiment, 다섯 개의 리얼 월드 평가 환경, 그리고 다섯 개의 VNM, visual perturbation, visual metric과 navigation metric을 함께 평가하겠다 라는 것을 보여주는 그림이라고 보시면 좋을 것 같습니다.
해당 논문은 새로운 navigation model을 제안하는 논문이라기보다는, 현재 visual navigation foundation model들이 실제 real-world에서 어디까지 가능한지, 그리고 어떤 부분에서 실패하는지를 체계적으로 분석하는 evaluation paper라고 보시면 좋을 것 같습니다.
Visual Navigation Models
이 논문에서 다루는 모델들은 GNM, ViNT, NoMaD, NaviBridger, CrossFormer 이고 이 모델들은 visual navigation 분야에서 그래도 자주 등장하는 navigation policy들인데 공통적으로 현재 이미지, goal 이미지, 과거 observation history를 입력으로 받아서 waypoint 또는 trajectory를 예측하는 구조를 가지고 있습니다. 특히 ViNT나 NoMaD 같은 모델은 제가 이전에도 자주 언급했던 visual navigation 베이스라인이고, CityWalker나 여러 open-world navigation 연구에서도 비교 대상으로 자주 등장합니다.
NaviBridger나 CrossFormer에 대해서는 이전에 한번도 언급한적이 없어서 논문에 나온대로 설명드리면, NaviBridger는 NoMaD처럼 diffusion 기반 모델인데 여기에 learned action prior를 추가합니다. 논문에서는 conditional VAE를 가지고 action prior를 학습하고, diffusion bridge 방식으로 visual navigation을 수행하는 구조로 설명합니다. CrossFormer 같은 경우는 GNM, VINT, NoMaD와 비슷하게 여러 embodiment를 하나의 policy로 다루려는 cross-embodied learning 계열의 모델입니다. 이 논문에서는 CrossFormer를 VNM 평가에 포함해서 더 큰 generalist robot policy 계열이 visual navigation에서도 잘 동작하는지를 확인하고자 비교모델에 포함시켰다고 합니다.
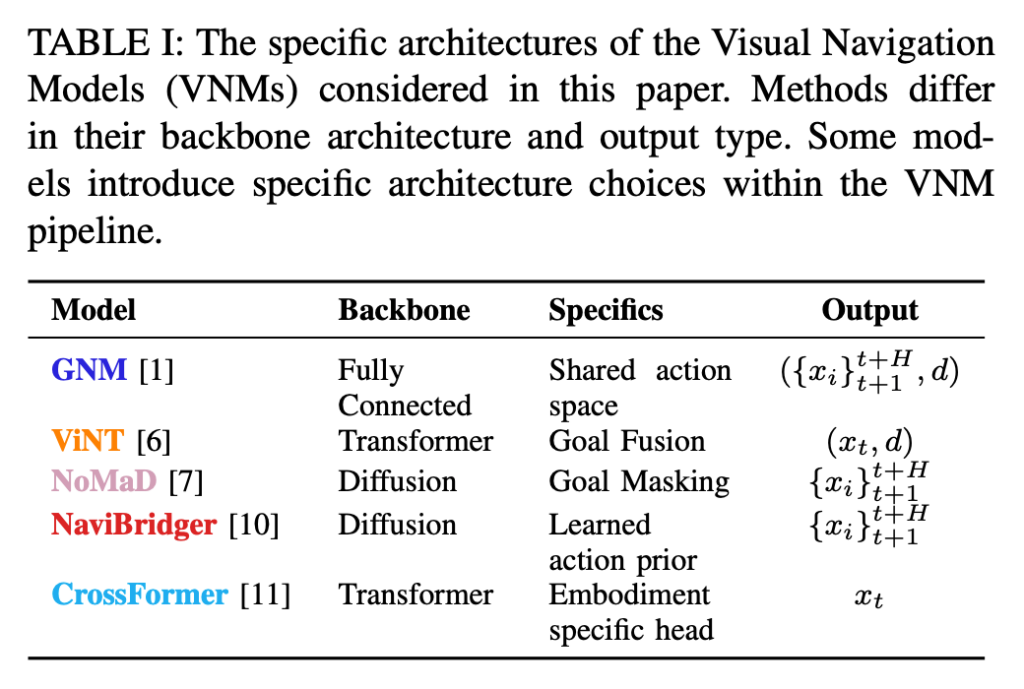
Table I은 GNM, ViNT, NoMaD, NaviBridger, CrossFormer의 메인 policy backbone, 핵심 구조, output 형태를 비교합니다. 각 모델이 어떤 encoder/backbone/output을 사용하는지 한눈에 비교하는 표라고 보시면 좋을 것 같습니다.
여기서 중요한 점은, 최신 모델일수록 구조가 복잡해진다는 것입니다. GNM은 상대적으로 단순한 MobileNetV2 + FC 구조이고, ViNT는 Transformer, NoMaD와 NaviBridger는 Diffusion, CrossFormer는 embodiment-specific transformer head를 사용합니다. 일반적으로는 구조가 복잡해질수록 더 좋은 성능을 기대하는데 뒤에 보여드릴거지만 실험 결과를 보면 단순한 GNM이 여러 환경에서 생각보다 잘 버티고, 오히려 diffusion이나 transformer 기반 모델들이 collision이나 goal prediction에서 실패하는 경우가 많습니다. 여기서 저자들이 말하고 싶은 핵심은 아키텍쳐에 뭐가 복잡하게 붙는다고 해서 이게 곧 real-world navigation robustness를 보장하지 않는다는 점입니다.
기존 VNM 논문들은 주로 Success Rate를 사용합니다. 목표 지점에 도달했는지 또는 topological map에서 goal node 근처까지 갔는지를 기준으로 성공 여부를 판단합니다. 물론 SR은 직관적이고 비교하기 쉬운 지표이긴 하지만 실제 로봇 주행에서는 SR만으로는 부족합니다.
앞서 예시를 한번 들었지만 다시 말씀드리면 두 모델이 모두 goal에 도달했다고 해도, 하나는 짧고 부드러운 경로로 이동했고, 다른 하나는 벽에 여러 번 부딪히면서 멀리 돌아갔다면 두 모델의 실제 성능은 다르게 봐야 합니다. 하지만 SR만 보면 둘 다 성공으로 기록될 수 있습니다. 그래서 저자들은 평가 지표를 크게 두 가지로 나눕니다.
첫 번째는 navigation metric입니다. 여기에는 path length, distance to goal, collision occurrence, topological node error, goal prediction이 포함됩니다. path length는 로봇이 얼마나 길게 이동했는지, distance to goal은 최종 위치가 goal에서 얼마나 떨어져 있는지, collision은 주행 중 충돌이 발생했는지, topological node error는 모델이 현재 자신이 topomap의 어느 node 근처에 있다고 믿는지가 실제 위치와 얼마나 다른지를 측정합니다. goal prediction은 모델이 스스로 goal에 도달했다고 판단했는지를 의미합니다.
두 번째는 vision-based metric입니다. 최종 observation과 goal image가 얼마나 비슷한지를 LPIPS, DSSIM, PSNR로 측정합니다. LPIPS와 DSSIM은 낮을수록 좋고, PSNR은 높을수록 좋습니다. 이 metric들은 단순한 위치 오차가 아니라, 모델이 실제로 goal image와 유사한 visual state에 도달했는지를 확인하기 위한 지표라고 보시면 좋을 것 같습니다.
정리하면 이 논문은 VNM 평가에서 robotics metric과 visual metric을 함께 봐야 한다고 주장합니다. 그리고 이 부분이 기존 단순 SR 기반 평가와의 가장 큰 차이라고 볼 수 있습니다.
Dataset & Evaluation Setup
실험 환경은 총 다섯 개입니다.
첫 번째는 Corridor입니다. 짧은 직선 주행 환경이고, Bunker 로봇으로 box를 향해 이동하는 비교적 쉬운 환경입니다. reference trajectory (정답 traj라고 봐도 무방) 길이는 약 3.7m입니다.
두 번째는 Stairs입니다. Spot 로봇이 계단을 올라가는 환경입니다. 여기에는 visually similar한 두 개의 계단 구조가 있어서, 모델이 비슷한 visual feature를 어떻게 구분하는지 확인할 수 있다고 합니다.
세 번째는 Office Loop입니다. 사무실 내부를 한 바퀴 도는 long-horizon trajectory입니다. 책상, 의자, 컴퓨터, 서랍 등 clutter가 많은 실내 환경이기 때문에 단순 corridor보다 훨씬 어렵습니다.
네 번째는 Arena입니다. 문이 여러 개 있는 환경에서 특정 문으로 이동해야 하는 task입니다. 목표 문 앞에는 다른 열린 문들이 먼저 등장하기 때문에, 모델이 visually similar한 door들을 구분할 수 있는지가 중요합니다.
다섯 번째는 Snow입니다. 야외 눈 덮인 주차장 환경입니다. 이 환경은 training distribution과 꽤 다른 out-of-distribution 환경으로 사용되고 모델의 generalization을 평가하는 요소가 된다고 합니다.
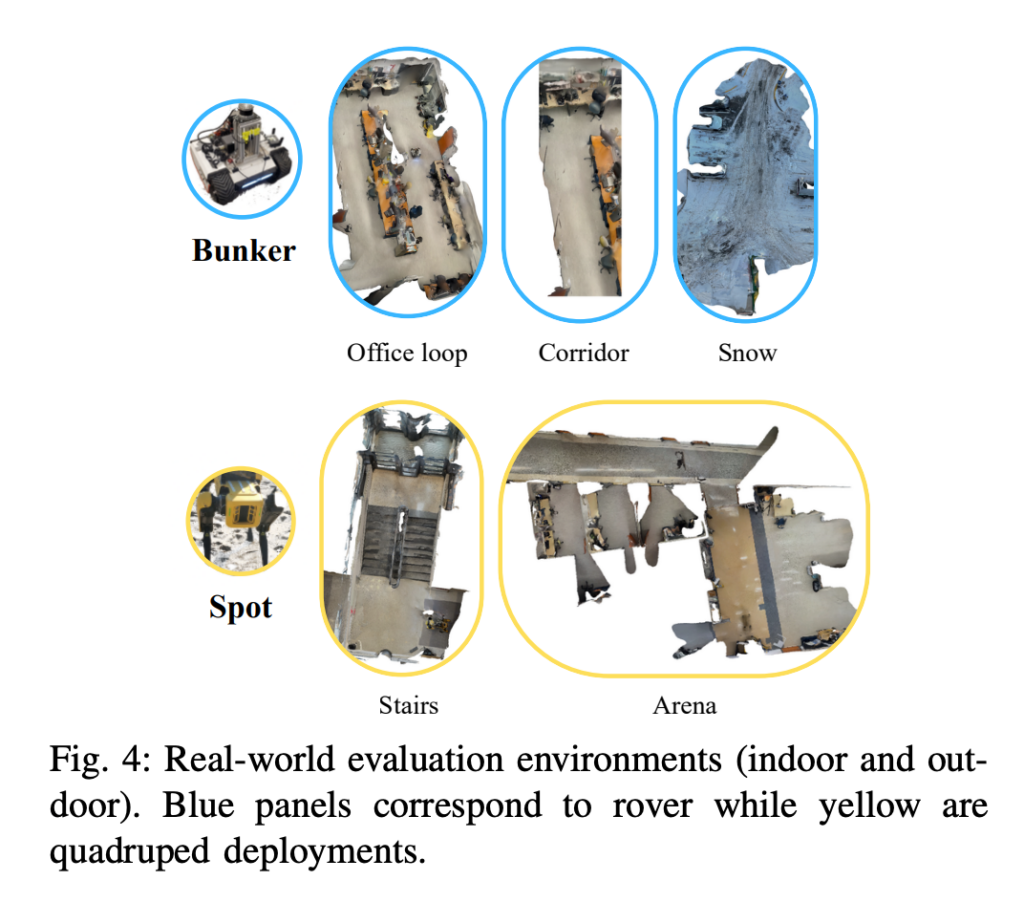
Fig. 4는 실제 평가 환경을 보여줍니다. 파란색 패널은 Bunker rover가 사용된 환경이고, 노란색 패널은 Spot quadruped가 사용된 환경입니다. Corridor, Office loop, Snow는 Bunker, Stairs와 Arena는 Spot으로 평가했다고 합니다.
평가 방식은 먼저 사람이 로봇을 수동으로 조종해서 reference trajectory를 기록하는데 이때 RGB image와 pose를 함께 저장하고, 일정 간격으로 image를 샘플링해서 linear topological map을 구성합니다. 그 다음 각 모델은 이 topomap을 따라 goal node까지 주행합니다. 근데 여기서 Bunker는 별도의 collision avoidance 메커니즘이 없습니다. 그래서 모델이 잘못된 waypoint를 내면 그대로 부딪힐 수 있는 반면 Spot 같은 경우는 억대 로봇개라서 그런지 built-in controller가 collision을 어느 정도 방지합니다. 따라서 Spot에서의 실패는 주로 goal에 도달하지 못하거나, stuck되거나, overshoot하는 형태로 나타난다고 합니다.
그래서 이러한 부분을 고려해서 저자들은 실험해석을 하였고 Bunker에서 collision이 많이 발생했다는 것은 모델 자체가 obstacle geometry를 충분히 이해하지 못했다는 의미로 볼 수 있고, Spot에서 collision이 줄어든 경우에는 low-level controller가 어느 정도 안전성을 보완했다고 해석을 합니다.
Experiments
저자들은 세 가지 질문을 던지고 이에 대한 평가를 진행합니다.
첫 번째는 VNM들이 familiar environment에서 실제로 잘 동작하는가? 입니다. 즉 corridor, office, stairs처럼 비교적 일반적인 실내 환경에서 모델들이 goal을 잘 찾고, reference trajectory를 잘 따라가고, 충돌 없이 이동하는지를 봅니다.
두 번째는 VNM들이 visually similar한 장소를 구분할 수 있는가?입니다. Arena나 Stairs처럼 비슷한 문, 비슷한 계단, 반복적인 구조가 있는 환경에서 모델이 goal image를 제대로 구분할 수 있는지 분석합니다.
세 번째는 distribution shift에 강건한가?입니다. Snow 환경이나 motion blur, sunflare perturbation을 통해, 환경 변화에 대한 robustness를 평가합니다.
Collision Hotspots: Geometry를 이해하지 못하는 문제

먼저 Corridor 환경을 보면 GNM과 ViNT는 모든 trial에서 goal에 성공적으로 도달합니다. 평균 goal distance도 낮고, path length도 reference trajectory와 크게 다르지 않습니다.
반면 CrossFormer, NoMaD, NaviBridger는 goal prediction과 collision avoidance에서 실패합니다. 특히 NoMaD와 CrossFormer는 corridor처럼 단순한 환경에서도 collision이 발생합니다.
Fig. 6은 Corridor deployment 결과를 보여줍니다. 왼쪽 초록색 영역은 GNM과 ViNT가 collision 없이 성공한 trajectory이고, 오른쪽 빨간색 영역은 CrossFormer, NoMaD, NaviBridger가 collision을 일으킨 경우를 보여줍니다.
여기서 저자들이 말하고 싶은 것은 최신 transformer 기반 모델이나 diffusion 기반 모델이라고 해서 반드시 obstacle geometry를 잘 이해하는 것은 아니라는 점입니다. 즉 waypoint prediction 자체는 그럴듯하게 보일 수 있지만,실제 로봇이 이동 가능한 안전한 경로인지까지 이해하는 것은 별개의 문제라고 설명합니다.
Visual navigation model은 RGB image만 보고 action을 예측하기 때문에 명시적인 depth나 occupancy map 없이 obstacle geometry를 implicit하게 학습해야 합니다. 그런데 학습데이터에 collision이나 리커버리 할 수 있는 시나리오가 충분히 없다면 모델은 사람이 주행한 안전한 trajectory를 따라가는 법은 배울 수 있어도, 주행 중 장애물이 생기거나 약간만 trajectory에서 벗어났을 때 어떻게 회피해야 하는지는 배우기 어려울 수 가 있습니다.
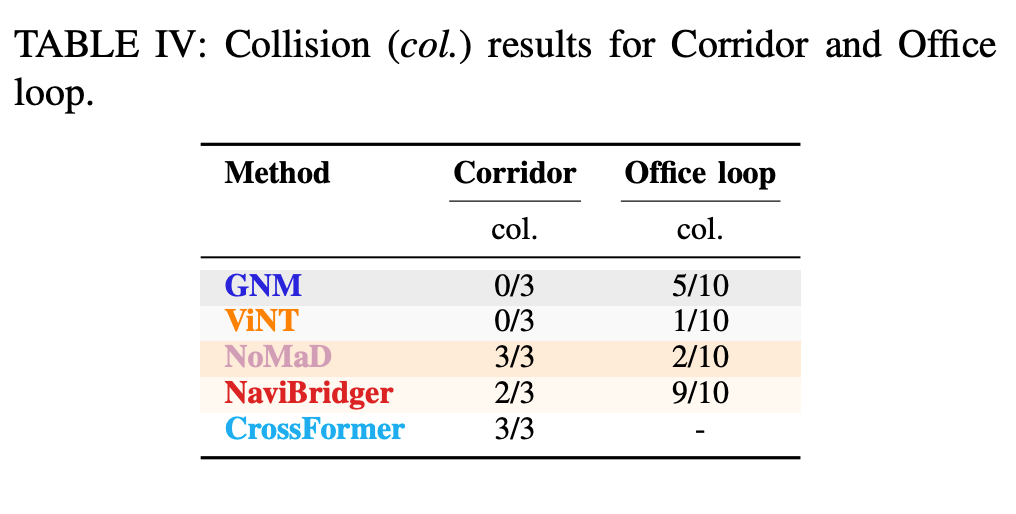
Table IV는 Corridor와 Office loop에서의 collision 결과를 보여줍니다. Corridor에서는 GNM과 ViNT가 0/3 collision인 반면, NoMaD는 3/3, NaviBridger는 2/3, CrossFormer는 3/3 collision을 보입니다. Office loop에서는 NaviBridger가 9/10 collision으로 매우 높은 충돌률을 보입니다.
VNM은 navigation을 한다고 하지만 실제로는 collision-free navigation을 보장하지는 않는다라고 볼 수 있습니다. 특히 real robot에서 low-level의 안전 장치 없이 VNM waypoint만 따라가게 하면 모델이 생각보다 쉽게 충돌할 수 있습니다.
그래서 저자들은 이후 실험에서 Spot의 low-level controller를 활용해 collision avoidance를 어느 정도 분리하고, visual navigation 자체의 failure mode를 더 집중적으로 보는 실험도 진행합니다.
Precision vs Completion: Goal prediction이 왜 어려운가
다음은 goal prediction 문제인데 Stairs 환경에서는 GNM, ViNT, NoMaD가 reference trajectory를 꽤 잘 따라가고, goal 이미지도 잘 인식합니다. 특히 NoMaD는 Corridor에서는 goal prediction이 좋지 않았지만, Stairs에서는 3/3 결과를 보입니다.
근데 여러 개의 문이 비슷하게 생긴 Arena환경에서 로봇은 첫 번째, 두 번째 문을 지나서 세 번째 문으로 들어가야 합니다. 단순히 문이 보인다를 인식하는 것이 아니라 여러 비슷한 문 중에서 goal image와 정확히 대응되는 문을 구분해야 합니다.
Fig. 9는 Arena 환경에서 각 모델의 trajectory를 보여줍니다. reference trajectory와 비교했을 때, 모델들이 문 근처에서 trajectory를 벗어나거나, 목표가 아닌 곳에서 goal prediction을 하는 모습을 확인할 수 있습니다.
결과를 보면 NoMaD와 ViNT는 path length가 길게 나오지만 goal distance가 높은 것을 확인할 수 있습니다. 어느 정도 움직이기는 하지만, 실제 목표에 정확히 도달하지 못합니다. CrossFormer와 NaviBridger도 평균 goal distance가 reference trajectory보다 훨씬 긴 path length를 보입니다.
저자들은 이게 모델이 topological map 상에서 progress를 제대로 추정하지 못하고 있기 때문에 그렇다고 합니다. 특히 visually similar한 장소가 반복될 때 모델은 현재 내가 어느 node에 있는지를 헷갈릴 수 있습니다.
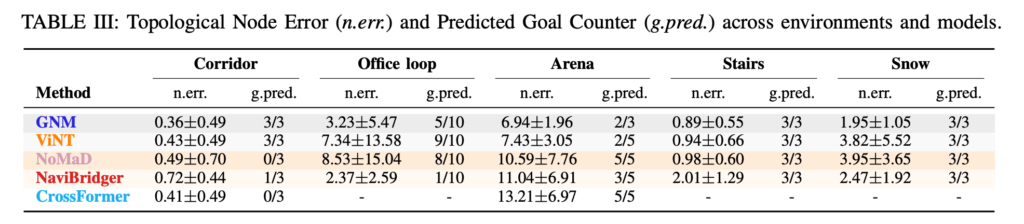
Table III은 topological node error와 goal prediction counter결과를 보여주는 표입니다. Arena 환경에서 CrossFormer는 5/5 goal prediction을 하지만, node error와 goal distance가 큽니다. 모델은 자신이 goal에 도달했다고 생각하지만 실제로는 그렇지 않은 경우가 많다는 뜻입니다.
여기서 중요한 점은 goal prediction이 단순히 visual similarity 문제만은 아니라는 것입니다. VNM은 topomap에서 현재 위치를 추정하고, 그에 따라 다음 subgoal을 선택해야 합니다. 그런데 반복적인 실내 구조에서는 여러 장소가 비슷하게 보이기 때문에, visual encoder가 충분히 subgoal과 observation이 구별력이 없으면 즉 너무 비슷하게 생기면 현재 위치가 흔들릴 수 있습니다.
위 결과를 보고 저자들은 특히 GNM의 단순한 MobileNetV2 encoder가 예상보다 robust하게 작동했다는 점을 강조합니다. 오히려 더 복잡한 EfficientNet-B0, diffusion, transformer 계열 모델들이 visually similar한 환경에서 헷갈리는 경우가 많았다고 합니다.
보통은 이미지 백본 architecture가 복잡해지면 더 좋은 representation을 학습할 것이라고 기대하는데 실제 navigation에서는 모델이 보는 feature가 시맨틱한 정보가 풍부한가보다는 goal을 구분하는 데 필요한 위치적,시각적 단서가 안정적인가 더 중요할 수도 있겠다라는 생각이 듭니다.
From Pixels to Waypoints: Visual Encoding의 역할
저자들은 goal prediction failure를 더 자세히 보기 위해 visual metric을 사용합니다. 최종 observation과 goal 이미지 사이의 LPIPS, DSSIM, PSNR을 측정해서, 모델이 실제로 goal과 비슷한 visual state에 도달했는지 확인합니다.

Fig. 5는 Arena와 Snow 환경에서 goal-predicted case의 이미지 퀄리티 metric을 보여줍니다. 위쪽은 Arena, 아래쪽은 Snow 환경입니다. 각 모델의 최종 observation과 goal 이미지를 비교하고, LPIPS, DSSIM, PSNR 값을 함께 제시합니다.
Arena에서는 GNM이 가장 낮은 LPIPS/DSSIM과 가장 높은 PSNR을 보입니다. 즉 GNM이 골 이미지와 가장 유사한 뷰지점에 도달했다는 뜻입니다. 반면 ViNT, NoMaD, NaviBridger, CrossFormer는 비슷한 수준의 metric을 보이며, goal image와 실제 도달 view 사이에 차이가 더 큽니다.
저자들은 이 결과를 이미지 encoder 랑 연결해서 분석하는데 ViNT, NoMaD, NaviBridger는 EfficientNet-B0 계열 encoder를 공유하거나 유사한 visual representation을 사용하기 때문에 반복적인 패턴이 보이는횐경에서 비슷한 f실패 패턴을 보인다고 해석합니다.
Snow는 out-of-distribution 환경이기 때문에 모델들이 더 어려워할 것 같지만,오히려 일부 visual metric은 indoor Arena보다 좋아집니다. 저자들은 이를 outdoor 환경이 indoor보다 visual ambiguity가 덜할 수 있기 때문이라고 해석합니다. 즉 눈이나 조명 변화는 분명 distribution shift이지만 공간 구조 자체는 Arena처럼 반복적인 문 구조보다 구분하기 쉬웠을 수 있다고 설명합니다.
Generalization Under Distribution Shift
저자들은 Snow 환경뿐만 아니라 Corridor topological map에 perturbation(모션 블러-blur와 빛 번짐-sunflare)을 적용합니다. 이때 중요한 건 실제 robot observation은 바꾸지 않고 topomap 이미지에만 perturbation을 적용했다는 것입니다. 이렇게 하면 모델이 goal 이미지나 topomap 이미지의 시각적 차이에 얼마나 민감한지 확인할 수 있습니다.
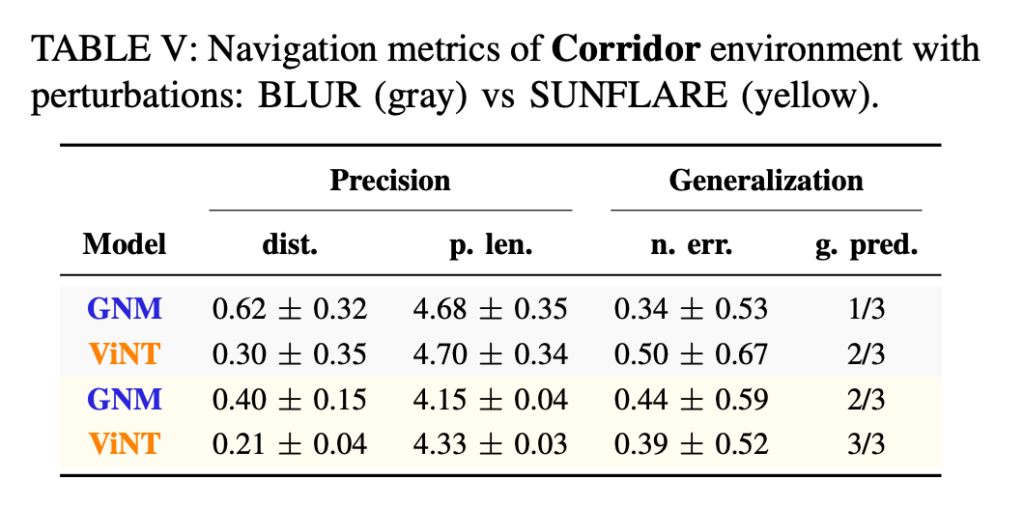
Table V는 Corridor 환경에서 blur와 sunflare perturbation을 적용했을 때 GNM과 ViNT의 결과를 보여줍니다. 두 모델 모두 standard Corridor에서 성공했기 때문에 perturbation 실험 대상으로 사용햇다고 합니다.
결과를 보면 GNM과 ViNT는 perturbation 조건에서도 어느 정도 navigation을 유지합니다. 특히 ViNT는 sunflare 조건에서 goal prediction 3/3을 달성합니다. 하지만 blur 조건에서는 goal prediction이 떨어집니다. GNM도 blur와 빛 번짐에서 goal prediction counter가 낮아지는 모습을 보입니다.
이 결과를 통해 저자들은 일부 모델은 visual perturbation에 어느 정도 robust하지만 여전히 환경 변화에 민감하다는 점을 주장합니다. 특히 diffusion-based model들은 distribution shift에서 더 취약한 모습을 보였다고 해석합니다.

Fig. 8은 Snow 환경에서 각 모델의 trajectory를 보여줍니다. reference trajectory와 비교했을 때, 모델들이 어느 정도 따라가다가 중간에 goal을 잘못 예측하거나 trajectory가 벗어나는 모습을 확인할 수 있습니다.
정리하면 distribution shift 실험에서의 핵심은,최신 구조가 반드시 더 robust하지 않다는 것입니다. 오히려 단순한 GNM이 Snow 환경에서 꽤 안정적인 결과를 보입니다.
Lessons Learned
이 부분은 저자들이 실험 결과를 바탕으로 분석후 중요한 인사이트를 정리한 부분인데 총 4가지를 정리하였습니다.
첫 번째는 Simpler architectures may be undervalued입니다. GNM은 MobileNetV2 기반의 비교적 단순한 모델이지만, 여러 metric에서 transformer나 diffusion 기반 모델과 비슷하거나 더 나은 성능을 보입니다. 특히 Corridor, Stairs, Snow 환경에서 GNM은 ViNT와 비슷하거나 더 좋은 결과를 보여주는 결과를 보였고 이런 결과를 봤을 때 단순하고 가벼운 아키텍쳐는 너무 과소평가되고 있지 않나라고 저자들을 주장합니다. 단순히 GNM이 더 좋은 모델이라는 의미라기보다는 현재 VNM 분야에서 architecture complexity가 실제 성능 향상으로 충분히 이어지지 못하고 있다는 의미라고 생각하시면 좋을 것 같습니다.
두 번째는 data is not enough입니다. 저자들은 복잡한 모델들이 더 큰 representation capacity를 가지고 있지만, training data가 그만큼 충분히 스케일업 되지 않았다고 봅니다. GNM과 ViNT는 각각 약 70시간, 80시간 정도의 navigation data로 학습된 것으로 언급되고, 이후 모델들은 이 foundation 위에서 구조를 더 복잡하게 만들었지만, 데이터 규모와 구성은 그에 비례해서 충분히 확장되지 않았다는 것입니다.
세 번째는 training data composition matters입니다. 단순히 데이터 양만 늘리는 것이 아니라, 어떤 상황이 데이터에 포함되어 있는지가 중요하다고 합니다. collision이 거의 없는 expert demonstration만 학습하면, 모델은 collision을 피하는 법을 직접적으로 배우기 어렵습니다. 또한 obstacle에 가까워졌을 때 어떻게 회피하고, 잘못된 방향으로 갔을 때 어떻게 recovery해야 하는지도 학습하기 어렵습니다. 이 부분은 CityWalker나 YouTube 기반 navigation data를 사용할 때도 생각해볼 지점이 있는게 웹 스케일 walking video는 손쉽게 얻을 수 있다는 장점은 있지만 실제 robot control 관점에서 collision, recovery, traversability, embodiment-specific constraint가 명확히 포함되어 있지는 않습니다. 따라서 visual feature pretraining에는 좋을 수 있지만, closed-loop navigation policy를 안정적으로 만들기 위해서는 additional safety-aware data나 geometric signal이 필요할 수 있다고 합니다.
네 번째는 repeated features confuse goal prediction입니다. 이 논문에서 Snow보다Arena 같은 indoor 반봇 환경이 더 어려운 경우가 나왔습니다. 즉 모델은 단순히 날씨나 조명 변화에만 취약한 것이 아니라 비슷하게 생긴 장소가 반복될 때 현재 위치와 goal을 구분하는 데 어려움을 겪습니다. 이것은 topological navigation에서 특히 중요한 문제입니다. topomap은 스파스한 이미지 노드들로 구성되기 때문에 각 노드가 충분히 구별력이 있어야 합니다. 만약 비슷한 이미지가 여러 노드에 존재하면 distance encoder가 현재 위치를 잘못 추정하고 그 결과 subgoal 선택이 흔들릴 수 있습니다.
Conclusion
이 논문은 visual navigation policy를 연구하는 입장에서 참고할 만한 논문인 것 같습니다. 특히 CityWalker나 NoMaD, ViNT 계열 모델을 실제 closed-loop로 평가하려고 할 때, 단순히 SR,SPL 만 보는 것이 아니라 real robot deployment에서 어떤 failure가 생기는지까지 평가해야 한다는 점을 잘 보여주는 것 같습니다.
또 저자들은 큰 모델을 만들면 navigation이 해결된다보다는 navigation에는 visual representation, geometry, topological localization, collision avoidance, recovery behavior가 모두 필요하다는 점을 중요하게 생각하는 것 같습니다. VNM 연구는 단순히 아키텍쳐 자체를 복잡하게 만드는 방향보다는 geometry-aware signal이나 safety-aware data를 결합하는 방향으로 나아가야하나라는 고민이 생깁니다.
이상 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요, 우현님. 좋은 리뷰 감사합니다.
리뷰 초반에서 자율주행 분야와 mobile robot navigation 분야는 평가 방식이나 benchmark 발전 흐름이 조금 다르다고 느껴졌습니다. 이와 관련해, 자율주행 분야에서 사용되는 평가 방식들을 mobile robot navigation에 그대로 적용하기 어려운 이유가 자율 주행의 환경이 더 단순해서인지, 아니면 mobile 환경에서는 더 많은 시나리오가 있어서인지 궁금합니다.
그리고 goal prediction 부분에서, 비슷한 문들이 여러 개 있는 환경에서 로봇이 지정된 문으로 들어가야 한다고 하셨는데, 이때 모델이 문의 생김새 자체를 goal image와 비교해서 구분하는 방식인지, 아니면 topological map에서 지나온 순서나 현재 위치의 흐름을 추정하면서 목표 문을 판단하는 방식인지 궁금합니다.
좋은 리뷰 감사합니다!
안녕하세요 기현님 좋은 댓글 감사합니다.
첫번째 질문에 대해서는 기현님이 말씀 주신대로 자율 주행의 환경이 더 정형화 되어있고 단순하기 때문에 해당 지표를 mobile robot 환경에서 바로 평가하기엔 부족할 수 있다고는 개인적으로 생각하지만, 그래도 navigation 관점에서 시작지점과 goal 지점까지 안전하게 주행해야한다는 점을 봤을 때에는 큰 차이는 없다고 생각합니다. 따라서 자율주행의 평가 방식들을 참고해서 모바일 로봇 쪽에도 변형해서 사용가능할 것 같습니다.
그리고 두번째 질문에 대해서는 topological map에서 지나온 순서나 현재 위치의 흐름을 추정하는 과정에서 문이 찍힌 이미지와 goal image와 비교하여 판단한다고 이해하시면 좋을 것 같습니다.
감사합니다.
안녕하세요 우현님 좋은리뷰 감사합니다
요약하면 VNM들이 real-world에서 SR만으로는 안 드러나는 failure mode가 많고 복잡한 architecture가 단순한 GNM보다 항상 낫지는 않다는 점을 5개 환경에서 보여준 evaluation paper네요. collision, goal prediction, repeated feature 문제를 navigation/visual metric으로 함께 본 게 핵심인 것 같습니다. 맞나요 ?
질문 하나 드리면, Perturbation 실험에서 topomap 이미지에만 blur/sunflare를 적용하고 실제 observation은 그대로 둔 이유가 궁금합니다. 실제 deployment에서는 계절이나 조명 변화가 로봇의 현재 observation에 영향을 줄 텐데observation 쪽에 perturbation을 준 경우나 양쪽 다 준 경우도 실험해보셨는지, 결과가 달라졌을지 궁금합니다.
안녕하세요 우진님 좋은 댓글 감사합니다.
일단 첫번 쨰 질문에 대해서는 이해하신게 맞습니다.
그리고 두번 째 질문에 대해서는 제가 이해를 잘 못 한거 같은데, 일단 관련 실험은 없습니다. observation과 topomap 양쪽다 주는 경우는 사실 큰 의미가 없는 실험인 것 같고, topomap은 과거에 촬영했던 것일 수 있기 때문에 현재 deploy환경과 어느정도 도메인 갭이 있어도 강건히 잘 동작하는지를 판단하고자 그런 도메인갭을 부여하고자 blur/sunflare를 적용했다라고 보시면 좋을 것 같습니다. 감사합니다.