안녕하세요 오늘은 월드 모델을 가지고 왔습니다. 근데 그냥 월드 모델이 아니라 Zero-shot World Model이라고 해서 어떤 부분에서 Zero-shot이고 어디에 쓸 수 있는지 궁금해서 좀 들고 왔습니다. 아직 월드 모델에 대해서 그렇게 전문적으로 알지는 못하지만, 그래도 신기한 주제라서 들고 왔으니 재밌게 봐주시면 좋겠습니다!

- Conference: arXiv 2026
- Authors: Khai Loong Aw, Klemen Kotar, Wanhee Lee, Seungwoo Kim, Khaled Jedoui, Rahul Venkatesh, Lilian Naing Chen, Michael C. Frank, Daniel L.K. Yamins
- Affiliation: Stanford University
- Title: Zero-shot World Models Are Developmentally Efficient Learners
1. Introduction
해당 논문이 다루는 핵심 문제는 “어떻게 하면 적은 데이터로도, 그리고 별도의 task-specific 학습 없이도 다양한 시각 인지 능력을 갖출 수 있을까”입니다. 논문에서는 그 출발점을 사람의 발달 과정에서 찾고 있습니다. 어린 아이들은 한 명의 개인이 경험하는 매우 제한된 양의 시각 데이터만으로도 깊이(depth) 추정, motion 추적, 물체 인식, 물체 간 상호작용 같은 다양한 physical understanding 능력을 보여줍니다. 게다가 이런 능력은 특정 task를 위해 따로 배운 것이 아니라, 하나의 general-purpose representation으로부터 zero-shot으로 발휘된다고 합니다.
저자는 이 두 가지 특성을 각각 data efficiency(적은 데이터로 학습)와 flexibility(별도 예시 없이 새로운 task 수행, 즉 zero-shot)라고 부르며, 현재의 AI 시스템이 이 두 가지를 동시에 만족하지 못한다는 점을 문제로 지적합니다.
기존 연구와 비교했을 때, 초기 DNN은 ImageNet 같은 대규모 라벨 데이터에 대한 supervision이 필요했고, 이후 등장한 self-supervised 모델은 라벨 없이도 좋은 representation을 학습할 수 있게 되었습니다. 하지만 논문에서는 이런 self-supervised 모델조차 “절반만 채워진 잔”이라고 표현합니다. 그 이유는 두 가지입니다. 첫째, 실제 아이들이 보는 자연 영상(camera motion, blur, occlusion이 많고 환경 다양성이 낮은 데이터)으로 학습하면 ImageNet 같은 잘 정제된 데이터로 학습할 때보다 성능이 크게 떨어집니다. 둘째, 이런 모델들은 representation은 학습하지만 task를 직접 수행하지 못해서, 각 downstream task마다 라벨 데이터로 별도의 readout(probe)을 학습시켜야 합니다. 결국 task마다 별도의 학습 파이프라인이 필요한 셈인데, 이건 사람의 인지 방식과는 거리가 멀다고 볼 수 있습니다. 쉽게 정리하자면, 언어 분야의 LLM은 다양한 task를 zero-shot으로 처리하지만 그 대신 엄청난 양의 데이터를 필요로 하고, 비전 분야의 self-supervised 모델은 데이터 효율은 낫지만 task마다 별도 readout이 필요합니다. 이 논문은 비전 분야에서 적은 데이터 + zero-shot을 동시에 달성하는 것을 목표로 합니다.
이를 위해 저자가 제안하는 것이 Zero-shot Visual World Model(ZWM)입니다. ZWM은 라벨이나 task별 예시 없이도 광범위한 visual-cognitive task를 zero-shot으로 수행하는 self-supervised neural network이고, 세 가지 핵심 원리에 기반합니다.
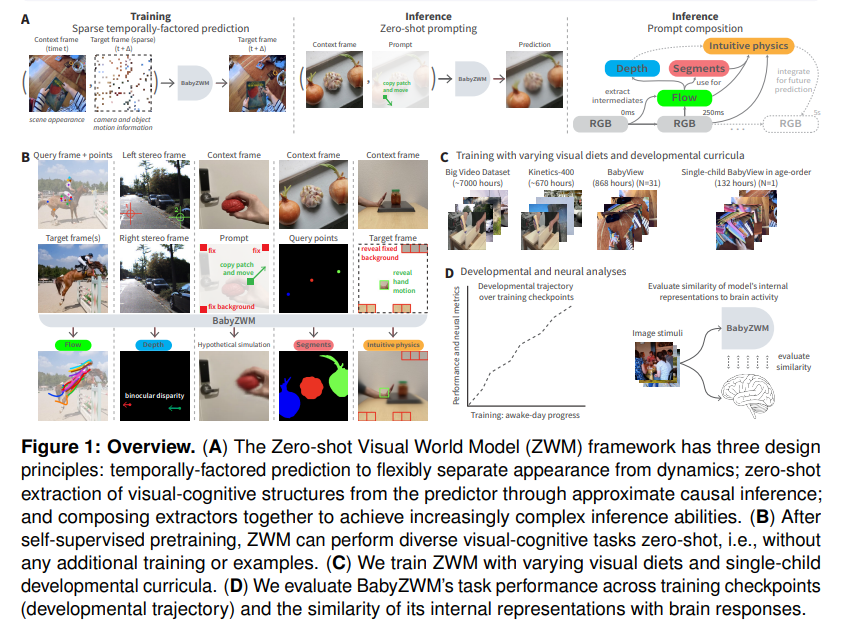
Figure 1을 보면 ZWM 프레임워크 전체가 한눈에 정리되어 있습니다. (A)는 ZWM의 세 가지 설계 원리를, (B)는 학습 후 다양한 visual-cognitive task를 zero-shot으로 수행하는 모습을, (C)는 어떤 데이터(visual diet)로 학습하는지를, (D)는 학습 checkpoint별 성능 변화(developmental trajectory)와 뇌 반응과의 유사성을 어떻게 평가하는지를 보여줍니다. 따라서 이 그림은 논문 전체 흐름을 잡는 데 가장 먼저 봐야 하는 그림이라고 할 수 있습니다.
ZWM의 세 가지 원리를 미리 정리하면 다음과 같습니다. 첫째, temporally-factored prediction으로, appearance(겉모습)와 dynamics(움직임)를 분리해서 예측하는 sparse predictor를 학습합니다. 둘째, zero-shot extraction으로, 학습된 predictor에 최소한의 변형을 가하고 그 차이를 비교하는 일종의 근사적 causal inference를 통해 시각 정보를 끄집어냅니다. 셋째, compositional prompting으로, 단순한 prompt들을 조합해서 점점 더 복잡한 query를 구성합니다.
이 세 가지를 합치면 ZWM은 일종의 data-driven world model이 됩니다. 여기서 world model이라고 부르는 이유는, 이 시스템이 “proxy action(가짜 행동)이 장면에 미치는 영향”을 예측할 수 있기 때문입니다. 이 부분은 뒤에서 다시 자세히 설명됩니다.
2. The ZWM framework
ZWM 프레임워크는 위에서 언급한 세 가지 설계 원리로 구성됩니다. 이 섹션에서는 각 원리가 구체적으로 어떻게 동작하는지를 설명합니다.
2.1 Sparse temporally-factored prediction
ZWM에서 실제로 학습되는 핵심 구성요소는 sparse temporally-factored masked multi-frame visual predictor이고, 논문에서는 이를 \Psi라고 표기합니다. 개념 자체는 긴 video에도 적용 가능하지만, 논문에서는 이해를 돕기 위해 두 프레임만 쓰는 setting으로 설명합니다.
쉽게 설명하자면 이렇습니다. 짧은 시간 간격을 두고 찍힌 두 RGB 프레임 f_1과 f_2가 있다고 할 때, \Psi는 f_1 전체와 f_2의 아주 일부 patch만 보고 f_2 전체를 예측하는 함수입니다. 즉 입력은 (f_1, f^{masked}_2) 형태이고, 여기서 f^{masked}_2는 f_2에 mask를 씌워서 일부 patch만 남긴 것입니다. 출력은 f_2 전체의 추정치 \hat{f}_2가 됩니다. 학습은 ground-truth 프레임 쌍에 대해 예측값과 실제값의 L2 loss를 최소화하는 방식으로 진행됩니다.
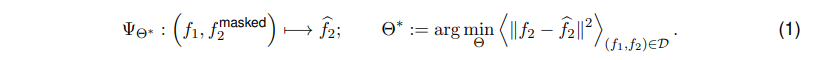
여기서 학습의 두 가지 중요한 포인트가 있습니다. 첫째, mask가 매우 sparse하다는 점입니다. f_2의 patch 중 10% 이하만 모델에 공개됩니다. 둘째, mask가 매번 무작위로 선택되기 때문에 모델이 프레임의 의미적 내용을 미리 알 필요가 없습니다. 이 구조는 일종의 masked autoencoder인데, 일반적인 MAE와 다른 점은 mask가 temporally biased 되어 있다는 것입니다. 즉 한 프레임(f_1)은 거의 다 보여주고, 다른 프레임(f_2)은 거의 다 가립니다.
여기서 중요한 점은, 이 단순해 보이는 제약이 모델에게 매우 구조적인 representation을 학습하도록 강제한다는 것입니다. f_2를 잘 복원하려면 모델은 어쩔 수 없이 다음 두 가지를 해야 합니다. 하나는 f_1의 빽빽한 patch들로부터 물체의 appearance를 추론하는 것입니다(왜냐하면 f_2에서 공개된 patch는 너무 적어서 appearance를 알기 어렵기 때문입니다). 다른 하나는 f_2에서 sparse하게 공개된 patch들로부터 물체와 카메라의 motion 변화를 추론하는 것입니다. 결과적으로 \Psi는 appearance와 motion을 암묵적으로 분리(factorize)하게 되고, 저차원의 motion 정보를 압축적이면서도 자연스럽게 해석 가능한 visual token 집합으로 만들게 됩니다. 이 부분이 ZWM의 zero-shot 능력이 가능해지는 핵심 토대라고 볼 수 있습니다.
2.2 Zero-shot extraction via approximate causal inference
ZWM의 두 번째 핵심 아이디어는, 위에서 학습된 압축적이지만 해석 가능한 motion token들을 “zero-shot prompt”로 조작해서, predictor가 암묵적으로 알고 있는 지식을 명시적으로 끄집어내는 것입니다.
이 과정의 핵심 메커니즘은 세 단계로 정리됩니다. 1. ground-truth 입력에 최소한의 perturbation(변형)을 가합니다. 2. 원래 입력에 대한 \Psi의 출력과, 변형된 입력에 대한 출력을 비교합니다. 3. 그 차이를 aggregate(집계)해서 원하는 양을 뽑아냅니다.
예를 들어 물체를 segment하고 싶다면, perturb 함수는 물체 위의 작은 patch 하나를 옮겨서 “가상의 motion”을 만듭니다. 그러면 predictor \Psi는 이 가상의 motion을 그 물체의 나머지 부분으로 전파시키지만, 장면의 다른 부분으로는 전파시키지 않습니다. compare 함수는 변형된 경우와 원래 경우 사이의 optical flow를 계산하고, aggregate 함수는 그 flow에 threshold를 적용해서 어떤 픽셀이 그 물체에 속하는지를 결정합니다. 논문에서는 이 perturb, compare, aggregate 함수를 다르게 고르는 것만으로 매우 다양한 visual concept을 zero-shot으로 추출할 수 있다고 말합니다.
논문에서는 이 방식을 일종의 approximate causal inference라고 설명합니다. causal inference는 “어떤 원인에 최소한의 변화를 주었을 때 결과가 어떻게 바뀌는가”를 묻는 과정인데, ZWM에서 \Psi는 세계의 dynamics에 대한 학습된 구조 방정식 역할을 합니다. 그래서 \Psi에 최소한의 perturbation을 주면 세계의 causal 구조 일부가 드러나게 됩니다. 예를 들어 object segmentation에서 motion perturbation을 주는 것은 “같은 물체에 속한다”는 latent cause 때문에 픽셀들이 함께 움직인다는 causal 구조를 드러내는 것이라고 볼 수 있습니다.
2.3 Compositional prompting
세 번째 원리는 단순한 prompt들을 조합해서 점점 더 복잡한 query를 만드는 것입니다. ZWM은 RGB 픽셀 자체보다 motion이나 object 같은 더 추상적인 시각 구조를 점진적으로 추출하고 통합합니다.
구체적으로는 1. RGB로부터 optical flow를 추정하고, 2. binocular(양안) view에 optical flow를 계산해서 relative depth를 구하고, 3. 가상의 motion을 시뮬레이션한 뒤 optical flow를 계산해서 물체를 segment하고, 4. 이렇게 얻은 flow와 segment를 intuitive physics에 활용합니다. 결과적으로 이 composition은 visual intermediate들의 computational graph를 만들어 가는 셈입니다. 즉 단순한 능력 위에 복잡한 능력을 쌓아 올리는 방식으로 이해하면 됩니다.
2.4 Model implementation
predictor \Psi는 neural network로 구현되고, SGD로 학습됩니다. backbone은 Vision Transformer(ViT)이고, 170M(170M 파라미터)과 1B(10억 파라미터) 두 가지 크기로 실험했습니다.
조금 더 구체적으로 보면, 입력 프레임은 256×256 픽셀로 resize된 뒤 8×8 픽셀 patch로 나뉘어서 한 프레임당 32×32 = 1024개의 patch token이 됩니다. 첫 프레임 f_1은 1024개 token 전부가 사용되고, 두 번째 프레임 f_2는 10%의 patch(약 102개)만 공개되며 나머지는 학습 가능한 공유 mask token으로 대체됩니다. 두 프레임 모두 positional embedding(학습되는 형태, sinusoidal이 아님)을 더한 뒤 concat해서 transformer에 들어갑니다.
학습 데이터는 실제 video에서 뽑은 RGB 프레임 쌍이고, 두 프레임 사이의 시간 간격은 150ms~450ms 사이에서 uniform하게 샘플링됩니다. 모델은 200,000 step, batch size 512로 학습되는데, 이는 약 950 video hour, 즉 하루 약 10시간 깨어 있다고 가정하면 대략 95일치의 경험에 해당한다고 합니다. optimizer는 AdamW(peak learning rate 3e-4, weight decay 1e-1)를 쓰고, data augmentation은 전혀 적용하지 않은 채 raw RGB 프레임 쌍에 직접 학습시킵니다.
여기서 한 가지 신기한 점은, 이 asymmetric masking(완전히 보이는 f_1, 90% 가려진 f_2)이 ZWM 개념의 핵심 설계라는 것입니다. 이게 정말 필요한지를 확인하기 위해 저자는 symmetric masking 변형(두 프레임 모두 45%-45%, 또는 90%-90% mask)도 학습시켜 봤는데, 이 부분은 ablation에서 다시 다룹니다.
3. Results
ZWM performs diverse visual-cognitive tasks zero-shot
이 섹션에서는 ZWM이 얼마나 다양한 visual-cognitive task를 zero-shot으로 잘 수행하는지를 검증합니다. 평가하는 task는 낮은 수준부터 높은 수준까지, optical flow, relative depth estimation, object segmentation, intuitive physical reasoning 네 가지입니다.
데이터 효율성과 robustness를 보기 위해 ZWM을 세 가지 서로 다른 visual diet로 학습시켰습니다. BabyView(868시간, 어린 아이들의 egocentric video, 이것으로 학습한 모델을 BabyZWM이라고 부름), Kinetics-400(약 670시간, BabyView보다 작지만 훨씬 다양한 인터넷 video), Big Video Dataset(BVD)(약 7000시간, 컴퓨터비전 데이터셋 + 인터넷 video로 다양성과 규모의 상한선에 해당).
비교 대상(baseline)은 크게 두 종류입니다. 하나는 representation-based 모델로, pretraining으로 general-purpose feature를 학습한 뒤 downstream task에 finetuning이나 가벼운 head로 전이하는 방식입니다. 여기에는 ImageNet supervised로 학습된 ResNet-50, self-supervised static image 모델인 DINOv3, self-supervised video 모델인 V-JEPA2가 포함됩니다(DINOv3와 V-JEPA2는 BabyView로 학습한 버전도 함께 비교). 이 모델들은 native하게 zero-shot이 아니기 때문에, 저자는 cosine similarity 기반의 간단한 zero-shot probe를 설계해서 비교했습니다. 다른 하나는 task-specific baseline으로, 각 benchmark를 위해 직접 학습된 supervised 모델들입니다(예: flow, depth, segmentation 전용 supervised network). 이건 “사람 수준의 능력은 통합된 world model이 아니라 각각 특화된 시스템들로 달성된다”는 대안 가설을 구체화한 것이라고 볼 수 있습니다.
여기서 중요한 점은, 사람을 직접 비교할 만한 benchmark가 부족하고 사람은 이런 일상적인 시각 task에서 거의 ceiling 성능을 보일 것이기 때문에, 저자는 supervised SOTA 시스템을 강력한 proxy baseline으로 삼았다는 것입니다. 따라서 이들을 능가한다면 BabyZWM의 zero-shot data efficiency를 강하게 입증하는 셈입니다.
3.1 Optical flow
Optical flow는 TAP-Vid 계열 benchmark로 평가했습니다. TAP-Vid-DAVIS는 사람이 annotation한 ground-truth가 있는 challenging한 실제 video이고, TAP-Vid-Kubric은 시뮬레이터로 생성된 synthetic video로 ground-truth flow가 정확히 알려져 있습니다. 평가 지표는 pixel-threshold accuracy(예측이 ground-truth로부터 일정 픽셀 반경 안에 들어오는 비율)와 occlusion 검출 정확도입니다.

Figure 2를 보면 (A)는 optical flow를 추출하는 방법을, (B)는 flow 예측을 track 형태로 보여준 것을, (C)는 flow benchmark 결과를, (D)~(F)는 relative depth 방법과 결과를 보여줍니다. 결과를 정리하자면, BabyZWM은 TAP-Vid-DAVIS에서 label-supervised 모델인 CoTracker3, DPFlow, SeaRAFT와 경쟁력 있는 수준의 성능을 보였고, occlusion 검출에서도 supervised baseline과 비슷한 수준을 달성했습니다. TAP-Vid-Kubric에서는 강하긴 하지만 synthetic 데이터로 학습한 supervised 모델보다는 약간 낮았습니다. 그리고 BabyZWM은 representation-based 모델인 DINOv3와 V-JEPA2를 능가했습니다. 쉽게 말하면, 라벨도 없이 아이의 일상 video만으로 학습했는데도 flow 전용으로 supervised 학습한 모델과 비슷한 수준까지 올라왔다는 것이 핵심입니다.
3.2 Relative depth estimation
Depth는 UniQA-3D benchmark로 평가했는데, 이 benchmark는 두 점을 주고 어느 쪽이 더 멀리 있는지를 판단하게 합니다. ZWM에서 depth는 stereo 이미지 사이의 optical flow를 계산해서 zero-shot으로 추출됩니다. 결과적으로 ZWM과 BabyZWM 모두 90% 이상의 정확도를 보였습니다. 이 성능은 대형 vision-language 모델(Gemini-1.5, GPT-4-Turbo, GPT-4o)을 능가하고, supervised monocular 모델(MiDaS-CNN)이나 self-supervised monocular 모델(MonoDepth2)과 비슷한 수준이며, supervised binocular 모델에만 약간 뒤처졌습니다.
3.3 Object discovery (segmentation)
Object segmentation은 SpelkeBench로 평가했습니다. 이 benchmark는 class를 따지지 않고(class-agnostic) 물체를 “구별되고 경계가 있는 개체”로 정의합니다.
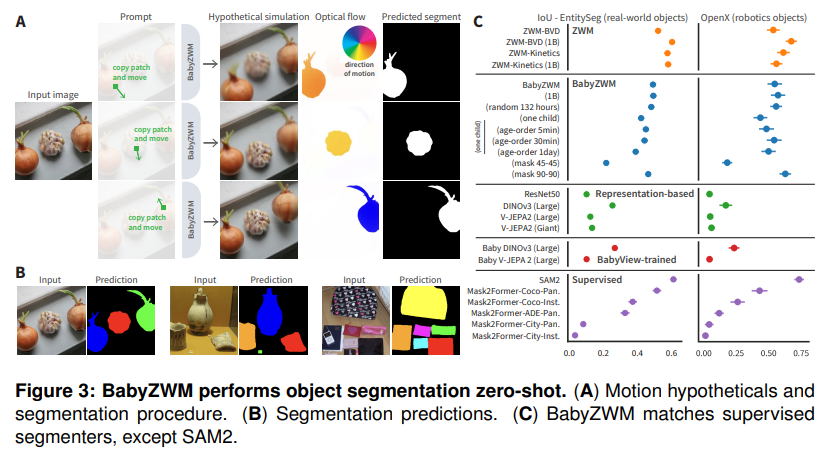
Figure 3을 보면 (A)는 motion hypothetical(가상 motion)을 이용한 segmentation 절차를, (B)는 실제 segmentation 예측 결과를, (C)는 benchmark 결과를 보여줍니다. (A)를 보면 입력 이미지에서 물체 위 patch를 복사해 옮기고, predictor가 그 가상 motion을 물체 전체로 전파시킨 뒤, optical flow를 계산해서 물체 영역을 잡아내는 흐름이 잘 드러납니다. 결과적으로 BabyZWM은 대규모 COCO 데이터로 학습된 supervised Mask2Former 계열과 견줄 만한 성능을 보였고, 다만 대규모 사람 annotation을 활용하는 SAM2보다는 약간 낮았습니다.
3.4 Intuitive physical understanding
마지막으로 저자는 intuitive physics를 평가하기 위해 새로운 short-timescale physical reasoning benchmark를 직접 만들었습니다. 이 benchmark는 손(hand)과 1~2개의 물체 사이의 상호작용을 다루며, 다섯 가지 추론 카테고리를 테스트합니다: object cohesion(물체의 한 부분을 움직이면 전체가 함께 움직임), support – top(받침을 치우면 위 물체가 떨어짐), support – bottom(아래 물체를 움직이면 위 물체도 함께 움직임), force transfer(한 물체를 다른 물체로 밀면 두 번째 물체가 움직임), force separation(떨어져 있는 물체를 움직여도 다른 물체는 영향받지 않음). 정확도는 모델의 예측이 ground-truth target 프레임에 더 가까운지, 아니면 context 프레임에 더 가까운지를 MSE와 LPIPS perceptual similarity로 비교해서 정의합니다.

Figure 4를 보면 (A)는 다섯 가지 physics 카테고리 benchmark의 구성을, (B)는 interpretability 분석 결과를, (C)는 카테고리별 정확도를 보여줍니다. 결과적으로 ZWM, BabyZWM, V-JEPA2는 모든 카테고리에서 거의 100% 성능에 도달했지만 Baby V-JEPA2는 그렇지 못했습니다.
특히 흥미로운 부분은 (B)의 interpretability 분석입니다. 저자가 BabyZWM에 interpretability 기법을 적용해 보니, 물체의 motion을 예측할 때 손(즉 causal agent, 원인이 되는 주체)을 일관되게 따라가는 attention head들이 발견되었습니다. 이 부분은 모델이 “무엇이 motion의 원인인가”를 어느 정도 내부적으로 포착하고 있다는 신호로 볼 수 있습니다. Appendix의 추가 분석을 보면, 더 깊은 transformer layer일수록 query patch의 attention이 background나 random patch보다 hand patch에 불균형하게 많이 할당되는 경향이 나타납니다. 다만 저자는 attention weight가 모델 내부 계산의 간접적인 지표일 뿐이라서, 이 head들이 정말 causal한 역할을 하는지는 추가 연구가 필요하다고 조심스럽게 말하고 있습니다.
ZWM achieves data efficiency and continual learning
올바른 visual-cognitive 학습 이론이라면, 사람이 실제로 경험하는 datastream으로도 효과적으로 학습할 수 있어야 합니다. 이 섹션은 ZWM이 정말 데이터 효율적인지를 점점 더 엄격한 조건으로 검증합니다.
먼저, BabyZWM은 Kinetics-400이나 BVD처럼 훨씬 다양한 데이터로 학습한 동일 architecture와 비교했을 때 성능 대부분을 유지했습니다. 즉 데이터 다양성이 훨씬 적은데도 성능 저하가 크지 않다는 것인데, 이는 ZWM architecture 자체가 데이터 효율적임을 보여준다고 볼 수 있습니다.
더 엄격한 테스트를 위해 저자는 Single-Child BabyView라는, BabyView 중 단 한 명의 아이(생후 9~30개월)에게서 녹화된 132시간 분량만 추린 subset으로 ZWM을 학습시켰습니다. 이건 한 아이의 매우 제한된 시각 다양성만으로 일반화 가능한 능력을 학습할 수 있는지를 보는, 한층 더 stringent한 테스트입니다. 추가로 34명 아이에게서 무작위로 132시간을 뽑은 subset도 학습시켰는데, 이렇게 하면 “다양성”의 기여와 “총 노출 시간”의 기여를 분리해서 볼 수 있습니다. 결과적으로 Single-Child BabyZWM은 대부분의 task에서 BabyZWM과 비슷한 성능을 보였습니다.
또한 저자는 Single-Child BabyZWM을, 영상 클립을 아이의 나이 순서대로 정렬한 데이터에 대해 single-epoch(한 번만 통과)로 학습시킨 버전도 만들었습니다. 이건 developmental robustness와 continual/life-long learning을 테스트하기 위한 것입니다. 여기서 5분, 30분, 1일 단위의 temporal window 안에서 클립을 섞는(shuffle) curriculum을 여러 개 만들었는데, 이건 경험이 consolidation(공고화)되는 정도를 대략적으로 흉내 낸 것입니다(예: 한 에피소드 안에서의 mixing vs. 수면 같은 재배열). 결과적으로 age-ordered Single-Child BabyZWM 모델들도 모든 task에서 Single-Child BabyZWM과 비슷한 성능을 보였습니다. 한마디로 정리하자면, 데이터를 어떻게 정렬해서 한 번씩만 보여줘도 ZWM은 능력을 잘 학습한다는 것입니다.
마지막으로 masking 관련 ablation이 나옵니다. “Standard” BabyZWM은 asymmetric masking(완전히 보이는 f_1, 90% 가려진 f_2)을 쓰는데, 이는 motion dynamics 학습을 명시적으로 우선시하는 설계입니다. 이 temporally-factored mask 구조가 ZWM 개념의 핵심이기 때문에, 저자는 더 단순한 대안인 symmetric masking 변형(45%-45%, 90%-90%)을 평가했습니다. 그 결과 두 symmetric 변형 모두 성능이 상당히 나빴습니다. 이 부분은 결국 motion 정보를 강조하는 것이 data efficiency와 zero-shot 추상화에 중요하다는 것을 보여주는 장치라고 볼 수 있습니다. 즉 “masking을 했다”는 사실 자체가 아니라 “temporally biased된 masking”이 핵심이라는 것입니다.
BabyZWM’s developmental curves broadly parallel children’s learning
이 섹션에서는 BabyZWM의 학습 checkpoint별 성능 변화, 즉 developmental trajectory를 분석해서, 서로 다른 visual-cognitive 능력이 언제 emerge하는지를 살펴봅니다.
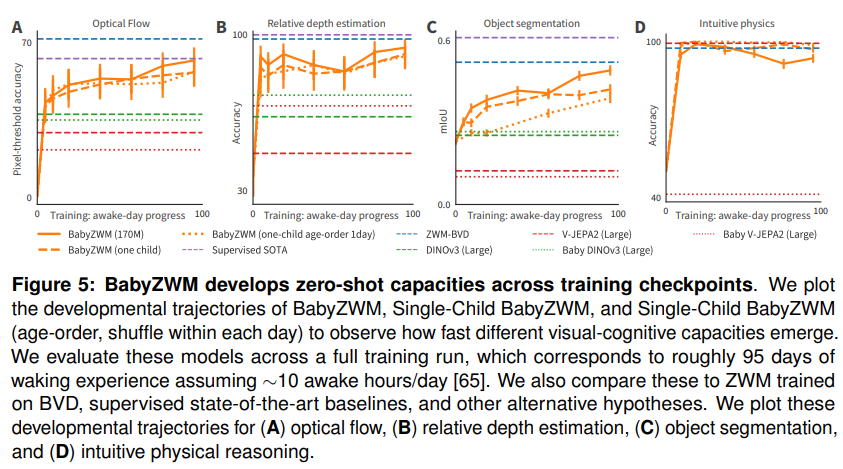
Figure 5를 보면 BabyZWM, Single-Child BabyZWM, age-order Single-Child BabyZWM의 developmental trajectory가 네 가지 task별로 그려져 있습니다. x축은 학습 진행도(약 95일치 깨어 있는 경험에 해당)이고, supervised SOTA나 다른 대안 모델들의 성능선도 함께 표시되어 있어서 어디까지 도달하는지를 비교할 수 있습니다.
결과를 정리하면 다음과 같습니다. (A) optical flow 정확도는 학습 초반에 올라간 뒤 plateau에 도달하는데, 이는 아이들의 single-/multi-object tracking 발달과 비슷한 패턴입니다. (B) relative depth 능력은 학습 데이터가 쌓이면서 가파르게 올라간 뒤 높게 유지되는데, 이는 초기 stereopsis(양안시) 발달과 비슷합니다. (C) object segmentation 능력은 학습 내내 꾸준히 개선되는데, 이는 영아기 동안 물체 인식/segmentation이 점진적으로 좋아진다는 발달 연구 결과와 일치합니다. (D) intuitive physics 능력도 학습이 진행되면서 향상되는데, 이는 영아가 cohesion·continuity·solidity 같은 거친 기대에서 시작해 점차 정밀한 support 추론이나 force transfer 민감도로 발전하는 과정을 닮았습니다.
다만 저자는 이런 trajectory 비교를 조심스럽게 해석해야 한다고 명확히 밝힙니다. 이 곡선들은 benchmark별 task 난이도, 평가 지표, ceiling effect 같은 설계 차이를 어느 정도 반영하기 때문에, 능력 발달의 순서를 깔끔하게 보여주는 것이라고 단정하기는 어렵다는 것입니다. 그래서 한 가지 takeaway는, 사람과 기계의 초기 시각 능력을 더 체계적이고 비교 가능하게 benchmarking할 필요가 있다는 점이라고 볼 수 있습니다.
ZWM representations align with neural responses
행동(behavior) 측면에서 사람과 비슷한 특징을 보였다면, 다음 질문은 “내부 representation도 뇌와 비슷한가”입니다. 사람의 시각 시스템은 hierarchical하게 조직되어 있어서 망막 입력을 점점 더 복잡한 representation으로 변환하고, 이 구조는 어린 시절 동안 발달합니다.
저자는 모델의 내부 representation과 뇌 반응의 유사성을 neural predictivity로 측정합니다. 쉽게 말하면, 모델 feature에서 신경 반응으로 가는 cross-validated linear probe(ridge regression)를 fit한 뒤, noise-corrected correlation을 보고하는 방식입니다. 평가에는 두 가지 상호 보완적인 데이터셋을 씁니다. NSD(Natural Scenes Dataset)는 사람의 fMRI 데이터로 large-scale representational geometry를 포착하고, TVSD(THINGS Ventral Stream Spiking Dataset)는 마카크 원숭이의 단일 뉴런 electrophysiology로 fine-grained한 뉴런 tuning과 timing을 보여줍니다.
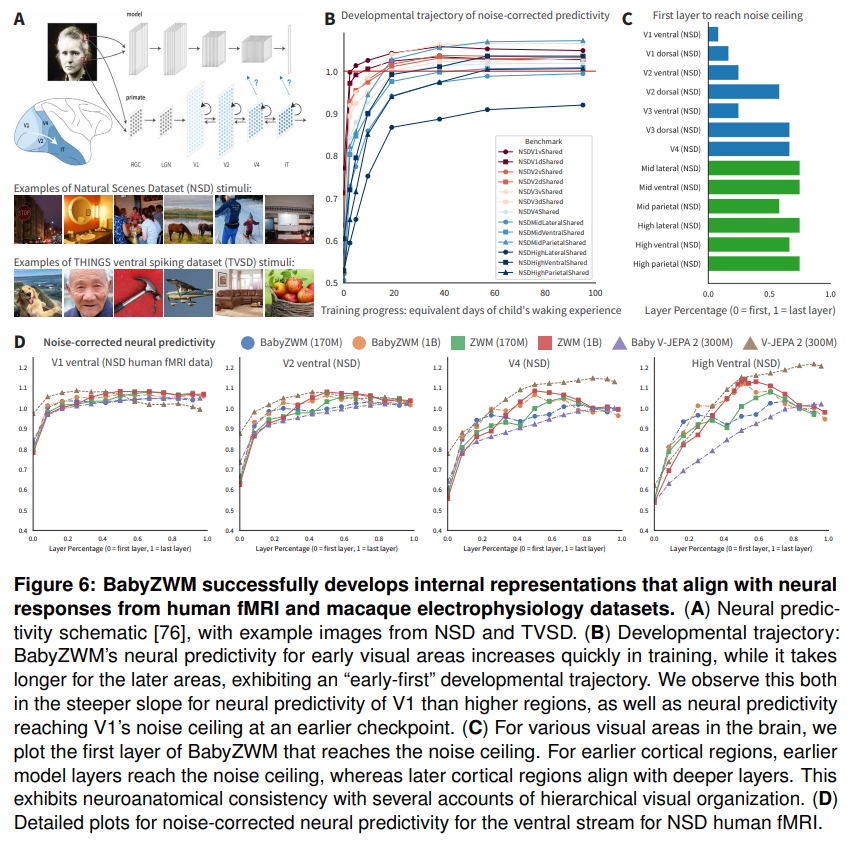
Figure 6을 보면 (A)는 neural predictivity를 측정하는 방식과 자극 이미지 예시를, (B)는 학습에 따른 neural predictivity의 발달 궤적을, (C)는 각 visual area별로 noise ceiling에 처음 도달하는 모델 layer를, (D)는 ventral stream에 대한 상세한 neural predictivity를 보여줍니다.
결과를 정리하면, BabyZWM의 neural alignment는 hierarchical한 시각 발달과 일관된 모습을 보입니다. 초기 visual cortex(예: V1)에 대한 neural predictivity는 상대적으로 이른 학습 checkpoint에서 noise ceiling에 가까워지는 반면, 더 높은 영역들은 더 천천히 좋아집니다. 저자는 이를 “early-first” developmental trajectory라고 부릅니다. 또한 layer-area 대응이 hierarchical하게 정렬되어 있습니다. 즉 초기 cortical region은 모델의 초기 layer가, 후기 cortical region은 모델의 깊은 layer가 가장 잘 예측합니다. 이는 모델 layer와 cortical region 사이의 일종의 “mechanistic mapping”을 지지하는 결과라고 볼 수 있습니다. Appendix의 추가 분석을 보면, 이 hierarchical한 layer-area 대응은 NSD뿐 아니라 단일 뉴런 해상도의 TVSD에서도 동일하게 확인되어, 이 representational hierarchy가 fMRI 측정 scale 때문에 생긴 artifact가 아니라는 것을 보여줍니다.
결과적으로, 하나의 self-supervised world model이 서로 다른 종(species)과 측정 scale에 걸쳐 공유되는 representational 구조를 포착하고, 발달 dynamics와 hierarchical 조직이라는 사람과 비슷한 특징을 모두 재현했다고 볼 수 있습니다.
4. Discussion
논문에서 주장하는 contribution을 다시 정리하면 다음과 같습니다. 현대의 visual learning 알고리즘은 사람에 비해 매우 데이터 비효율적이고, 특히 아이가 실제로 경험하는 datastream으로 학습하면 성능 격차가 큽니다. ZWM은 이 격차를 메우는 새로운 접근으로, “representation learning + task-specific readout”이라는 지배적 패러다임에서 “통합된 zero-shot world model”로의 전환을 의미합니다. representation learning에서는 downstream task마다 별도의 라벨 readout이 필요해서 수행 가능한 task 범위가 제한되고 sparse한 라벨에 overfitting하기 쉬운데, ZWM은 challenging한 실제 장면, synthetic 시뮬레이션, 심지어 상하 반전된 이미지에 대해서까지 zero-shot out-of-distribution 일반화를 달성합니다.
AI 관점에서도 의미가 있습니다. 현재의 self-supervised 비전 모델은 풍부한 representation을 학습하지만 여전히 task별 라벨 readout이라는 비싸고 깨지기 쉬운 의존성에 갇혀 있습니다. ZWM은 단 하나의 학습된 predictor가 universal interface를 통해 optical flow, depth, segmentation, physical reasoning을 zero-shot으로 내놓으면서 이 병목을 제거합니다. 이는 NLP에서 LLM이 task별 fine-tuned 모델을 대체한 패러다임 전환과 비슷하지만, ZWM은 비전에서 이를 훨씬 적은 데이터로 달성했다는 점이 다릅니다. 이 부분은 large-scale 라벨 데이터를 구하기 어려운 robotics, medical imaging, embodied AI 같은 분야에 직접적인 의미가 있다고 볼 수 있습니다.
저자는 ZWM을 인지·학습에서 intermediate structure(중간 구조)의 역할에 관한 두 극단 사이의 자연스러운 hybrid로 설명합니다. 한쪽 극단은 Sutton의 “Bitter Lesson”이 대표하는 순수 학습 입장(복잡한 hand-built inductive bias는 불필요하다)이고, 다른 쪽 극단은 인지과학에서 나온 입장(사람의 학습은 세계에 대한 강한 prior를 내장하고 있다)입니다. ZWM의 세 가지 원리는 이 두 아이디어를 모두 끌어와서, 최소한으로만 bias된 학습 네트워크 안에서 어떻게 명시적 구조를 만들어낼 수 있는지를 보여줍니다. 구체적으로 ZWM은 architecture, learning algorithm, task-specific readout program 같은 작은 구조적 prior는 innate일 수 있지만, representational content와 network parameter는 경험으로부터 학습된다는 일종의 “hybrid innateness 가설”을 구현한 것이라고 볼 수 있습니다.
마지막으로 “왜 이것이 world model인가”에 대한 설명이 흥미롭습니다. 언뜻 보면 \Psi의 입력은 그냥 데이터일 뿐이고, world model이라면 있어야 할 action이 보이지 않습니다. 하지만 ZWM은 “data-driven world model”로, 구하기 비싼 진짜 action 데이터를 cheap한 데이터 연산(예: pixel patch 조작)으로 대리(proxy)합니다. flow나 segment를 계산하기 위해 만드는 “tracer”나 “motion”이 바로 그 가짜 action입니다. ZWM은 데이터 patch를 진짜 action 데이터처럼 다루고, raw 데이터로 학습한 덕분에 세계가 어떻게 동작하는지를 충분히 학습해서 이런 hypothetical을 능숙하게 수행할 수 있게 됩니다.
5. Limitations
논문에서 명시한 limitation은 다음과 같습니다. 첫째, ZWM은 아주 어린 아이가 학습하는 physically-grounded한 양들에 초점을 맞췄기 때문에, 이름이 붙은 언어적 카테고리 같은 semantic 개념이 어떻게 발달하는지는 다루지 못합니다. 저자는 향후 ZWM이 학습한 world model을 아이가 경험하는 풍부한 언어·청각 데이터와 통합하길 기대한다고 합니다. 둘째, 상세한 발달 행동·신경 비교 데이터가 부족하다는 경험적 한계가 있습니다. 이런 데이터셋은 만들기가 매우 어렵습니다. 셋째, \Psi가 deterministic regression 모델이기 때문에 mode collapse에 취약하고, 미래가 불확실한 상황에서는 blurry한 예측을 내놓습니다. 이 설계는 longer-horizon 예측이나 control 연구를 제한하므로, multi-frame 학습, 더 풍부한 temporal memory, long-horizon task로의 확장이 중요한 다음 단계라고 저자는 말합니다.
향후 연구 방향으로 저자가 특히 흥미롭게 보는 것은, zero-shot으로 추출한 task extraction(flow, depth, segment 등)을 다시 predictor \Psi 안으로 통합해서 \Psi가 이런 중간 양들을 조건으로 받고 예측까지 할 수 있게 만드는 것입니다. 이렇게 하면 매번 추출된 새로운 intermediate가 predictor를 풍부하게 만드는 학습 target이 되는 일종의 bootstrapping cycle이 생기고, 점점 더 효율적인 학습과 더 정교한 intermediate 발견으로 이어질 수 있다고 합니다.
결과적으로 해당 논문은 단순히 성능이 좋은 World Model을 하나 제시했다기보다는, 어린아이가 실제로 보는 1인칭 시각 경험만으로도 어떻게 물체, 움직임, 깊이, 물리적 상호작용 같은 것들을 이해하게 되는지에 대한 하나의 계산적 가설을 제시한 논문이라고 볼 수 있을 것 같습니다.
기존에 제가 봤던 Cosmos 같은 World Model들은 대규모 데이터를 어떻게 잘 모으고, 토큰화하고, 압축해서 학습시킬 것인지에 초점이 맞춰져 있어서 사실 일반적인 연구 환경에서는 쉽게 접근하기 어렵다는 느낌이 있었는데, 이 논문에서는 BabyView처럼 아이가 실제로 보는 제한된 영상 데이터만으로도 꽤 다양한 visual-cognitive task를 zero-shot으로 수행할 수 있다는 점이 흥미로웠습니다. 특히 f_1 전체와 일부만 보이는 f_2를 통해 다음 프레임을 예측하도록 학습시키면서 appearance와 motion을 분리하도록 유도하고, 이후 perturb-compare-aggregate 방식으로 optical flow, depth, segmentation, intuitive physics 같은 능력을 별도의 task-specific 학습 없이 뽑아낸다는 점이 핵심으로 보입니다. 물론 해당 논문이 바로 로봇 제어나 edge device에서의 실시간 World Model을 보여준 것은 아니지만, 진짜 action 데이터 대신 patch perturbation이나 tracer 같은 proxy action을 사용해서 장면의 변화와 물리적 구조를 추론한다는 점은 embodied AI나 로봇용 World Model에도 충분히 이어질 수 있을 것 같아 보였습니다. 결국 이 논문은 더 큰 데이터와 더 큰 모델만을 사용하는 방향이 아니라, 적절한 구조와 self-supervised prediction 방식을 잘 설계하면 훨씬 적은 경험으로도 세계에 대한 유용한 표현을 만들 수 있다는 점을 보여준 논문이라서 해당 분야에 대한 발전 가능성이 높아 보였습니다.

긴 리뷰 읽어주셔서 감사합니다~~ありがとうございます!
안녕하세요 기현님 좋은 리뷰 감사합니다.
내용이 많이 어렵고 복잡한 것 같습니다.. 허허 제가 이해를 잘 못한거 같은데 ZWM에서 말하는 제로샷이 단순히 다운스트림 태스크에 지도학습 기반 task-specific head를 붙이지 않는다는 의미인지 아니면 태스크 정의 자체도 거의 주어지지 않는다는 의미인지가 궁금했습니다. 결국 perturb-compare-aggregate 방식은 사람이 태스크별로 설계한 규칙처럼 보이는데 이 부분까지 포함해서 완전한 zero-shot이라고 하는건지 헷갈립니다. 감사합니다.
안녕하세요, 우현님. 좋은 질문 감사합니다.
제가 이해한 ZWM의 zero-shot은 태스크 정의가 아예 주어지지 않는다는 의미보다는, downstream task마다 지도학습 기반 head를 따로 붙이거나 라벨 데이터로 추가 학습하지 않는다는 의미에 더 가까운 것 같습니다.
말씀하신 것처럼 perturb-compare-aggregate 과정은 사람이 태스크별로 설계한 query 방식에 가깝다고 볼 수 있습니다. 그래서 완전히 task-agnostic한 zero-shot이라기보다는, 학습된 world predictor를 추가 학습 없이 사람이 설계한 perturb와 query로 활용하는 방식이라고 생각했습니다.
즉 “태스크별 학습이 없다”는 점에서는 zero-shot이지만, task에 대한 규칙이나 추출 방식까지 전혀 주어지지 않는 완전한 zero-shot은 아닌 것 같습니다.
답글 감사합니다.