안녕하세요 손우진입니다.
이번에 제가 리뷰할 논문은 thermal 카메라를 VLA 모델에 통합해서 온도 기반 로봇 시스템을 만드는 논문입니다. 평소 thermal을 6D pose estimation 쪽에서 활용하는 연구를 하다 보니 thermal이 perception 단계에서 어떻게 쓰일 수 있는지에 주로 관심이 있었는데요. 이 논문은 manipulation입니다, 그리고 더 나아가 “warm water 가져와줘” 같은 자연어 명령을 thermal 정보까지 활용해서 직접 행동으로 옮기는 부분을 다루고 있어 흥미롭게 읽었습니다. 지난 번에 리뷰한 TherA 논문이 “RGB로부터 TIR을 만들어내는” 쪽이었다면, 이번 ThermoAct는 “TIR을 입력으로 받아서 로봇 행동을 만들어내는” 쪽이라 비교해서 읽으시면 thermal modality가 어디까지 확장되고 있는지 감이 잡히실 것 같습니다. 재밌게 읽어주세요~
Introduction
VLA 연구들이 처음에는 대부분 RGB 카메라 이미지를 주요 입력으로 사용해 왔습니다. 하지만 RGB만으로는 real환경에서의 다양한 작업을 수행하기 어렵다고 지적합니다. 사람이 컵을 집을 때 단순히 “보이는지”뿐 아니라 그 컵이 뜨거운지, 무거운지, 미끄러운지 같은 물리적 속성을 함께 고려하듯이, 로봇도 더 다양한 sensory modality를 통합해야 하는 추세로 넘어갔습니다. 이런 흐름에서 최근에는 depth, force, tactile, audio 같은 추가 modality를 VLA에 붙이는 연구들이 등장하고 있습니다.
그런데 저자들은 이 중에서 ‘온도’ 라는 물리적 속성이 거의 다뤄지지 않았다는 점에 주목합니다. 예를 들어 “가장 차가운 콜라를 집어줘”라는 명령은 비전 기반 모델로는 풀 수 없습니다. 캔이 시각적으로 다 비슷하게 생겼기 때문이죠. 또한 안전 시나리오로 가면 더 명확해지는데, thermal 카메라를 달면 이런 상황 인지가 가능해진다는 것이 저자들의 motivation입니다.
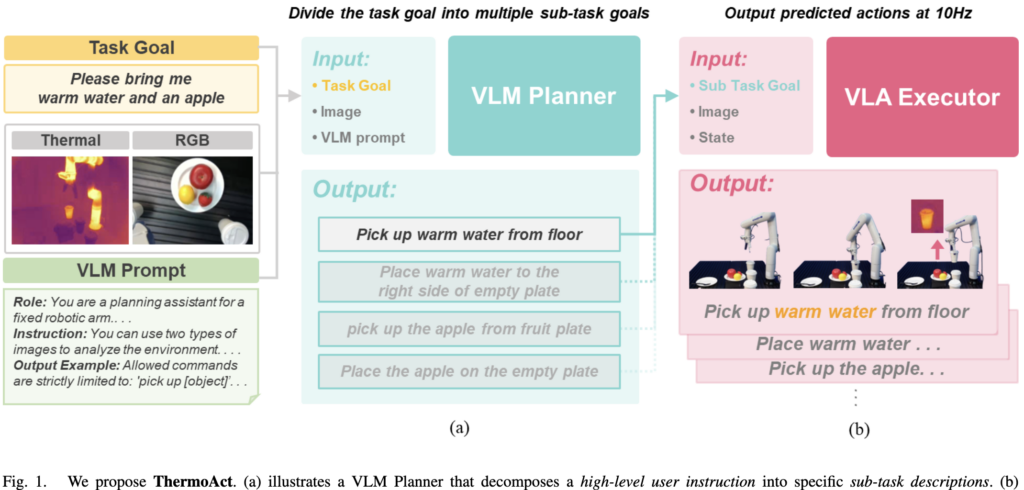
Fig. 1을 보시면 ThermoAct의 전체 구조가 나와있는데요. “warm water랑 사과 가져다줘” 같은 high-level instruction이 들어오면, RGB와 thermal 이미지를 함께 본 VLM Planner가 이걸 “pick up warm water from floor → place warm water → pick up apple → place apple” 같은 sub-task 시퀀스로 분해해줍니다. 그러면 VLA Executor가 각 sub-task를 받아서 실제 로봇 control을 수행하는 구조입니다.
저자들이 hierarchical 구조의 도입 설명을 thermal과 같이 large-scale pre-training dataset이 거의 없는 modality는, end-to-end로 “warm water 가져와줘”라는 추상적 명령을 한번에 학습시키기가 매우 어렵다는 점에서 구성했다고 합니다. 사실 thermal 뿐 아니라 long-horizon task 자체가 VLA의 약점이기도 하고요. 그래서 저자들은 large-scale로 pre-trained 된 VLM에게 맡기고, VLA는 “pick up warm water”처럼 단순화된 sub-task만 학습하면 되도록 나눠줍니다. 이를 통해 적은 양의 thermal demonstration(task당 50 episode)만으로도 안정적인 학습이 가능하다는 것을 보여주는 것이 이 논문의 주된 주장입니다.
저자들은 raw thermal data를 VLA에 넣기 위해 20~35°C 범위로 linear normalize한 뒤 INFERNO colormap으로 mapping해서 3채널 RGB로 변환합니다. 이 부분은 pre-trained vision encoder를 그대로 활용하기 위한 선택입니다. 하지만 사실 thermal 카메라의 가장 큰 장점 중 하나는 영하부터 수백 도까지 넓은 온도 범위를 한 장의 이미지 안에 담을 수 있다는 점인데요. 이를 20~35°C라는 좁은 구간으로 잘라버리면 그 범위 바깥의 온도 정보는 전부 같은 값으로 뭉개져 버립니다. 예를 들어 task 5의 hair straightener는 실제로 작동 중일 때 100°C를 훌쩍 넘기지만, 35°C에서 saturate되기 때문에 60°C든 150°C든 모델 입장에서는 똑같이 “가장 밝은 노란색”으로만 보이게 됩니다. 즉 thermal 카메라를 달았지만 “뜨겁다 vs 차갑다” 정도의 이진 정보만 활용하는 셈인데, 이 부분은 뒤에서 결과를 보면서 다시 한번 짚어볼 예정입니다.
저자들의 Contribution은 다음과 같이 정리됩니다.
Thermal modality의 VLA 통합을 제안했습니다. 기존 VLA 연구가 RGB, depth, force, tactile에 집중해온 것과 달리, thermal 카메라를 VLA의 입력으로 직접 사용해 온도 기반 의사결정이 가능함을 실험적으로 보였습니다.
Hierarchical 구조를 통한 data-efficient 학습을 구현했습니다. high-level reasoning을 VLM Planner가 담당하고, low-level control은 VLA Executor(π0 기반)가 담당하는 분리 구조를 통해, 대규모 thermal dataset 없이 task당 50 episode 수준의 적은 데이터만으로도 학습이 가능함을 보였습니다.
real-world action. Kinova Gen3 Lite 7-DoF 매니퓰레이터 위에서 일상 시나리오(warm water/cold Coke 전달, 적절한 컵 매칭) 3개와 안전 시나리오(과열 배터리 픽업, hair straightener 끄기) 2개로 구성된 총 5개 task에서 평가했으며, RGB-RGB baseline 대비 thermal-aware sub-task에서 평균 약 40% 성능 향상을 보였습니다.
Method
방법론에 대해 설명드리겠습니다. ThermoAct는 크게 두 개의 모듈로 구성된 hierarchical 구조를 가지고 있습니다. (a) 사용자 명령과 환경 정보를 받아 high-level reasoning을 수행하는 VLM Planner, 그리고 (b) Planner가 분해한 sub-task를 입력받아 실제 로봇 control을 수행하는 VLA Executor입니다. 핵심 아이디어는 단순합니다. thermal 같이 large-scale dataset이 없는 modality에 대해 end-to-end로 복잡한 추론과 행동을 모두 학습시키는 건 비효율적이니, 추상적 reasoning은 이미 충분히 학습된 VLM에게 맡기고 VLA는 단순화된 sub-task만 책임지게 하자는 것입니다. 그러면 각 모듈을 차례대로 살펴보겠습니다.
VLM Planner
VLM Planner는 ThermoAct 구조의 가장 상위에 위치한 모듈로 사용자가 입력한 자연어 명령을 VLA가 실행 가능한 형태의 sub-task 시퀀스로 분해해주는 역할을 합니다. 저자들은 별도의 fine-tuning 없이 Gemini 2.0 Flash를 그대로 활용했습니다.
입력으로는 세 가지가 들어갑니다. 첫 번째는 사용자가 던지는 Task (예를들면 “warm water랑 사과 가져다줘”), 두 번째는 현재 환경을 보여주는 wrist RGB 이미지와 thermal 이미지(둘 다 256×256×3), 세 번째는 reasoning을 가이드하는 prompt입니다. 이 prompt는 모델의 역할 정의, 환경 설명 지시, 출력 형식, 그리고 출력 예시로 구조화되어 있습니다. 출력 형식을 미리 정해두는 이유는, VLM이 자유롭게 출력하면 매번 다른 형식의 plan이 나와서 VLA가 받기 어렵기 때문입니다. 저자들은 출력 가능한 command를 “pick up [object]”, “place [object] to [location]” 같은 정해진 template으로 제한했습니다.

Fig. 2(a)를 보시면 VLM Planner의 동작 예시가 나와있는데요, VLM이 이해도가 좋은것이 Planner가 thermal image를 직접 보고 환경을 분석한 뒤 plan을 만든다는 점입니다. 예를 들어 task 2 “give me a cold Coke” 시나리오에서, Planner는 thermal image를 보고 “콜라가 차갑다”고 판단하면 바로 콜라를 집어오는 plan을 만들고, 콜라가 상온이라고 판단하면 “ice maker에서 얼음 컵을 가져오는” plan을 추가로 생성합니다. 즉 thermal 정보가 단순히 VLA의 perception 입력으로만 쓰이는 게 아니라, plan 자체의 분기 조건으로 작동한다는 것이 ThermoAct 구조의 특징입니다.
Thermal Data Processing
먼저 raw 온도값을 20~35°C 범위로 linear normalize합니다. 이 구간을 벗어나는 값은 모두 0 또는 1로 clip되고, 그 사이는 선형으로 [0, 1] 범위에 매핑됩니다. 두 번째로 [0, 1]의 float 값을 0~255의 8-bit grayscale 변환합니다. 세 번째로 이 grayscale을 INFERNO colormap을 통해 3채널로 변환합니다 이렇게 변환된 256×192×3 이미지가 wrist RGB 이미지와 함께 VLA의 입력으로 들어가게 됩니다. 저자들은 이 colormap 변환이 thermal contrast를 visual contrast로 바꿔주기 때문에 VLA가 attention을 주기 쉽다고 주장합니다. 도입부에서 얘기하였듯이 정보 손실을 불러오지만, 한편으로 50 episode라는 적은 demonstration으로 학습 가능한 형태를 만들었다는 점에서는 실용적인 trade-off였다고 볼 수 있을 것 같습니다. 다만 normalization 범위가 20~35°C로 고정되어 있다 보니, 실내 온도가 다른 환경이나 더 넓은 온도 분포를 가지는 시나리오에서는 그때그때 범위를 다시 맞춰줘야 한다는 한계가 있어 보입니다.
VLA Executor
VLA Executor는 ThermoAct의 low-level controller로, Planner가 만든 sub-task를 받아 실제 joint command를 만들어내는 역할을 합니다. 모델은 π0를 baseline으로 하고, LoRA fine-tuning을 통해 task별로 효율적으로 학습됩니다.
각 control cycle에서 VLA는 4가지 입력을 받습니다. 시점 t에서의 observation은 다음과 같이 정의됩니다.
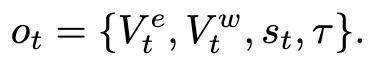
여기서 Vte는 외부 카메라(thermal) 입력, Vtw는 wrist 카메라(RGB) 입력, st는 6개 joint angle + gripper state로 구성된 robot state vector, τ는 VLM Planner가 만든 자연어 sub-task description입니다.
출력은 각 timestep에서 8차원 action vector로 생성됩니다.
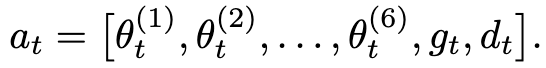
앞 6개는 target joint angle, gt는 gripper control value, 마지막 dt는 sub-task 완료를 알리는 done flag입니다. 이 done flag는 VLA가 자율적으로 “이 sub-task 끝났음”을 판단해서 다음 sub-task로 넘어가는 trigger를 직접 만들어내는 방식입니다. 외부에서 정해진 시간이나 success classifier로 transition을 결정하는 게 아니라 모델 내부에서 boundary를 학습한다는 점이 특이합니다. 다만 이게 어떻게 학습되는지에 대한 디테일은 논문에서 충분히 설명하지 않습니다. 데이터 수집 단계에서 demonstrator가 수동으로 done flag를 표시했다는 정도만 언급되어 있어서, sub-task 사이 경계가 모호한 long-horizon task에서 어떻게 안정적으로 동작하는지는 좀 더 확인이 필요해 보입니다.
저자들은 학습 효율을 위해 전체 weight를 학습시키지 않고 LoRA만 학습시키는 방식을 사용하였습니다.
Experiments
실험 설명드리도록 하겠습니다. 저자들은 총 3가지 실험을 설계했습니다. (1) 데이터 양에 학습 효율성, (2) RGB-RGB vs RGB-Thermal 모달리티 비교, (3) hierarchical 구조와 flat VLA의 비교입니다. 모든 실험은 Kinova Gen3 Lite 위에서 진행되었고, 각 sub-task당 N=10 trial로 평가되었습니다. 다만 실험표 구성이 의구심이 드는 실험들이여서 갸우뚱 하긴했습니다
Task 구성
5개의 task가 있고 크게 두 그룹으로 나뉩니다.
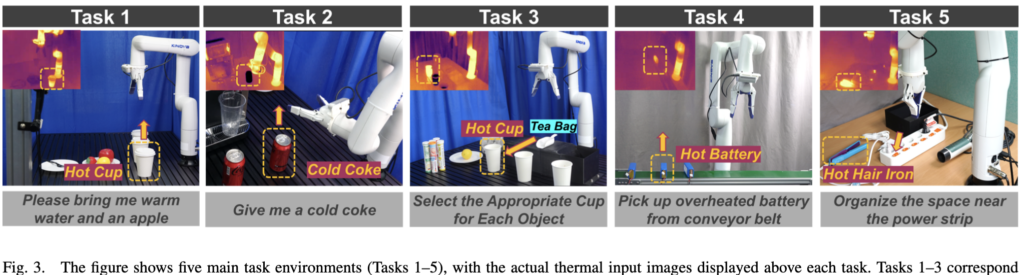
일상 시나리오(Task 1-3) 는 사용자 의도를 이해하는 데 thermal이 쓰이는 케이스입니다. 따뜻한 물 건네기, 차가운 콜라 주기(없으면 ice maker로 얼음컵 제공), 객체 속성에 맞는 컵 매칭(티백→따뜻한 물, 레몬→콜라)으로 구성되어 있습니다.
안전 시나리오(Task 4-5) 는 위험 상황 인지에 thermal이 쓰이는 케이스로, 컨베이어 벨트 위 과열 배터리 픽업과 켜져 있는 hair straightener 끄기입니다.
Experiment 1: 학습 데이터 양 분석
저자들은 30, 50, 70 episode로 학습시켜 데이터 양에 따른 성능 변화를 관찰했습니다. 평가 대상은 두 가지 setup으로 나뉘는데요, RGB-RGB는 thermal 정보가 필요 없는 일반 sub-task인 “pick apple from various fruits” 단일 결과만 평가했고, RGB-T는 동일한 “pick apple” sub-task와 thermal 정보가 필요한 두 sub-task(“pick the warmest cup”, “turn off the active hair straightener”)를 합쳐 총 3가지 sub-task의 평균 성공률로 평가했습니다. 즉 RGB-RGB는 일반 task 단일 결과이고, RGB-T는 thermal task 2개와 일반 task 1개를 평균낸 값이라 두 column이 같은 평가 대상을 공유하지는 않고 데이터 양 측면에서만 평가를 한것 같습니다.
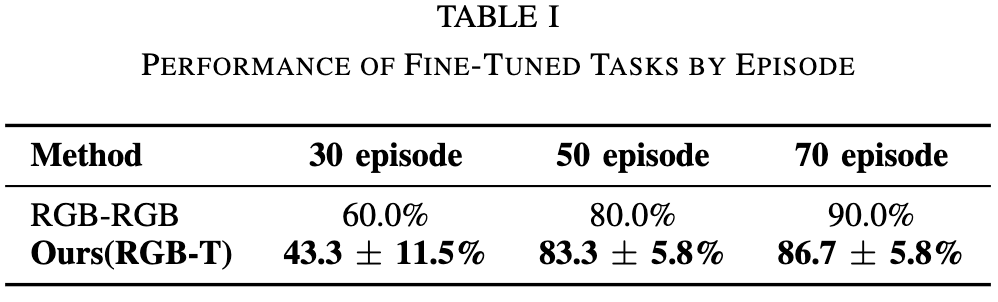
Table I의 RGB-T 평균은 30 episode 43.3%, 50 episode 83.3%, 70 episode 86.7%로 50 episode 부근에서 수렴된다고 얘기를 합니다. 다만 이 결과는 의문점이 드는것이. 우선, RGB-RGB와 RGB-T의 평가 대상이 비대칭이라 두 column을 직접 대조하기는 어렵고, RGB-T의 ±5.8% 표준편차도 sub-task 간 성능 격차에서 나온 분산일 가능성이라는 생각도 큽니다. 50 → 70 episode의 변화가 이 표준편차 범위 안에 들어간다는 점에서, 50에서 수렴된다는 결론을 내릴 수 있는지? 의문입니다
Experiment 2: RGB-RGB vs RGB-T (메인 결과)
이 실험이 사실상 논문의 핵심입니다. 50 episode 동일 조건에서 두 modality 구성을 5개 task 전체에 걸쳐 비교합니다.
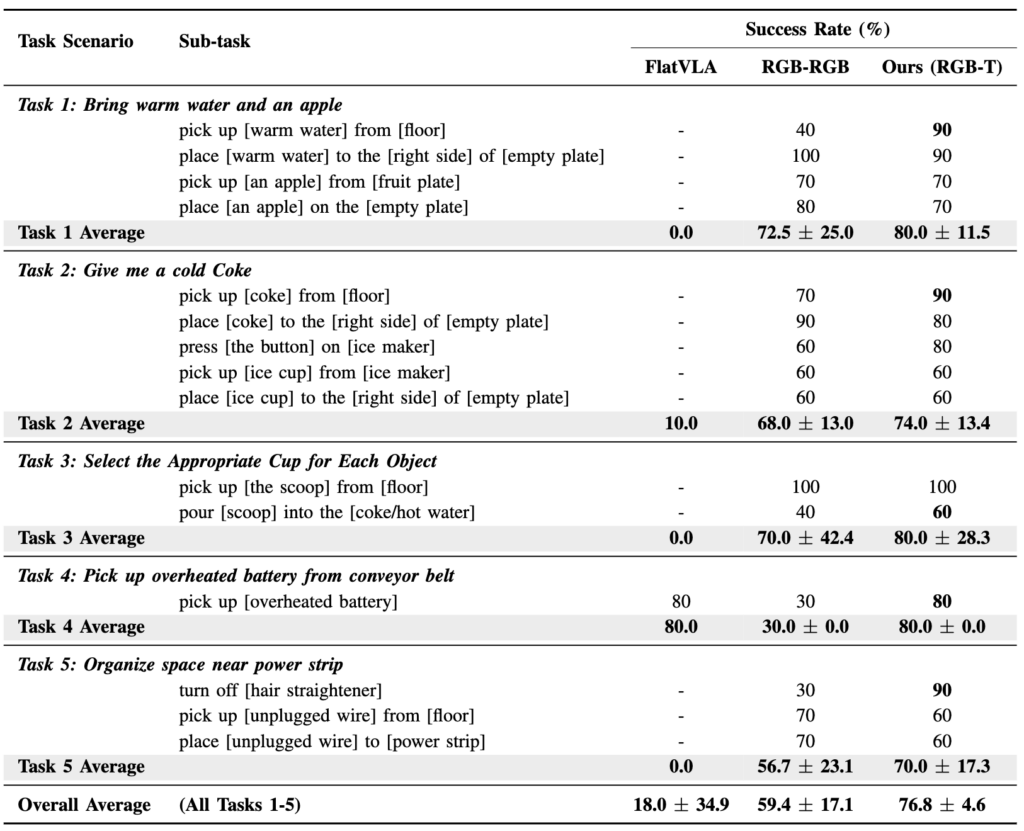
전체 평균은 RGB-RGB 59.4%, RGB-T 76.8%로 약 17%p 향상되었고, thermal-relevant sub-task만 보면 42% → 82%로 약 40%p 차이를 보입니다(Fig. 5).
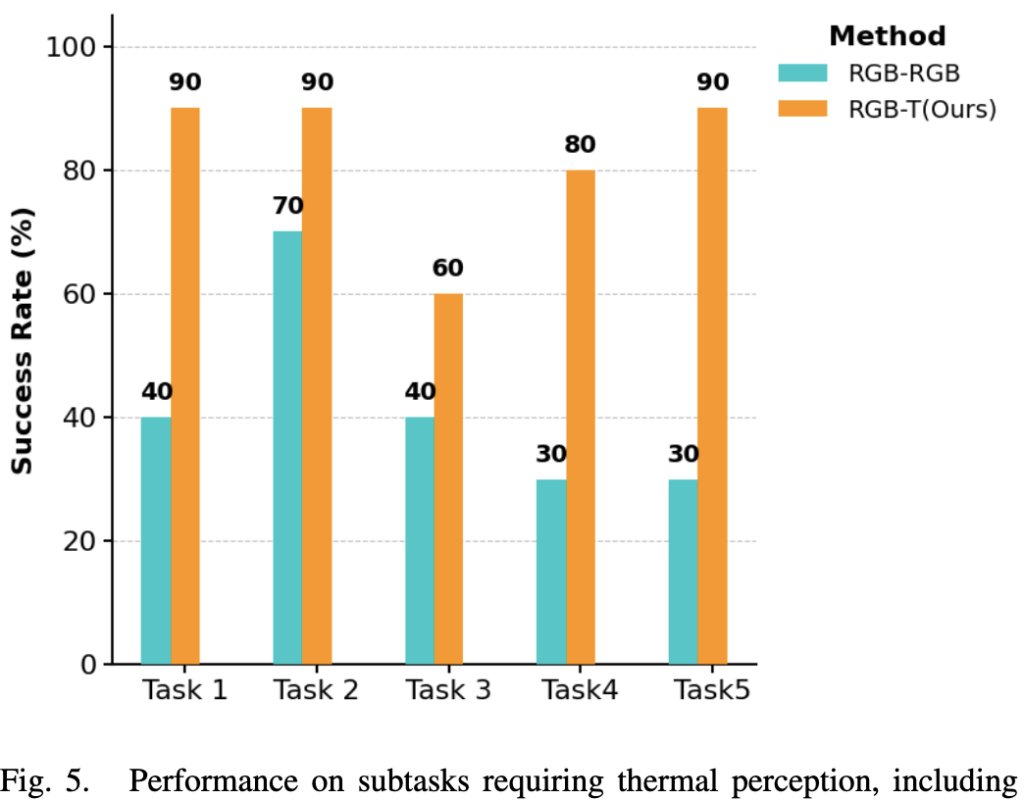
저자들은 이를 근거로 “thermal 입력이 thermal task 성능을 결정적으로 높이면서 일반 task 성능은 유지한다”고 주장합니다. 다만 아쉬운점은 표준편차가 너무 크다는 생각이듭니다. RGB-RGB의 Task 3은 42.4%로 표준편차가 거의 평균급인데. 10번 평가에서 저렇게 나온것 같습니다. 제가 VLA 논문들을 많이 읽어보지않아서 그런건지 10개 정도로 평가하기에는 부족하다고 생각이드는데 10번 task가 받아드려지는 것인지 궁금하긴합니다.
Experiment 3: Hierarchical vs Flat VLA
마지막은 hierarchical 구조(VLM Planner + VLA)와 end-to-end flat VLA의 비교입니다. 결과는 Table II의 FlatVLA 열에 있는데, Flat VLA는 단일 sub-task인 Task 4를 제외한 4개 task에서 0~10%의 성공률을 보입니다. 전체 평균은 18.0%로 hierarchical 방법(76.8%)과 큰 격차입니다.
저자들은 thermal같이 pre-training이 부족한 modality에서 long-horizon task를 end-to-end로 학습시키기 어렵고, hierarchical 구조가 데이터 부족 환경에서 효과이라는 것입니다. Task 2에서 VLM Planner가 thermal image를 보고 콜라가 따뜻하다고 판단하면 자동으로 ice cup을 가져오는 adaptive plan을 생성한다는 점입니다. 이건 hierarchical 구조가 thermal-aware reasoning에 기반한 plan 분기까지 가능하게 한다는 점을 보여주는 것이 의미있었던 것 같습니다.
감사합니다
안녕하세요 우진님 리뷰 감사합니다.
온도가 다뤄지지 않은 것을 노리고 효과적인 방법으로 thermal 정보의 필요성을 잘 어필한 연구인 것 같습니다. 다만 20~35도 안에서만 정규화하고 나머지는 clipping 처리한게 좀 많이 아쉬운 것 같은데요,, 너무 강조를 시켜주는 것이지 않나 싶습니다. Gemini를 그대로 쓰면서 High level planning만 하려고 해서 그런 것 같은데.. 해당 관점에서 좀 더 thermal 영상의 이해를 키우는 쪽으로, 혹은 thermal 정보를 좀 더 low level로 융합하는 연구의 가능성에 대해 우진님의 생각이 궁금합니다.
관심가져주셔서 감사합니다,
20~35도 구간만 정규화하고 나머지를 clipping한 건 thermal을 좀 인위적으로 강조한 면이 있어 저도 아쉽게 느꼈습니다. 다만 저 역시 당장은 low level 융합보다는 high level 쪽에서 접근해보고 싶은 마음이라, thermal 이해 자체를 그렇게 막 크게 키우는 방향은 그다음 단계 과제로 두려 합니다.
감사합니다
안녕하세요. 우진님 리뷰 감사합니다.
생각해보니 “뜨거운 물 가져와줘”라는 명령은 일상에서 충분히 할 법한 명령인데 rgb로는 부족한 것을 thermal로 풀어낸것이 흥미로운 논문이었습니다. 다만 일상에서뿐만 아니라 안전 시나리오까지 고려하기 위해서는 더 variation이 넓은 온도 범위를 다뤄야 할거 같은데 단순히 정규화하는 것이 아쉬운 부분이었습니다. task가 5개로 구성되어있는데, 주로 “pick up [object]”, “place [object] to [location]”와 같이 한정된 template를 사용한 것으로 이해했는데요. 궁금한 점이 온도를 다룰 수 있게 되면 저라면 가장 많이 발생할 법한 명령어가 A, B, C가 있을 때 이 것들 중에서 미지근한 음료, 조금 차가운 음료, 많이 차가운 음료가 있을 때 가장 차가운 음료를 달라고 하는 것처럼 비교를 명령할 것 같은데요. 우진님께서는 이러한 명령어가 들어왔을 때 충분히 해당 모델이 대응하고 subtask로 분류할 수 있을 거라 생각되시는지, 힘들다면 왜 그런지 생각을 여쭙고 싶습니다.
감사합니다.
리뷰에 관심가져주셔서 감사합니다.
좋은 관점이라고 생각합니다. 말씀하신 비교형 명령은 결국 planning 단에서 풀어야 할 문제 같은데, ‘미지근하다’, ‘차갑다’ 같은 표현 자체가 절대 온도값이라기보다 후보 객체들 사이의 상대적인 개념이니, 절대 임계치로 정규화하기보다는 후보들 간 온도를 비교·랭킹해서 subtask로 내려주는 방식이면 충분히 대응할 수 있을 것 같습니다. 좋은 인사이트 감사합니다!