안녕하세요 제가 이번에 리뷰할 논문은 UrbanNAV라는 논문입니다. 저번에 CityWalker라는 논문을 리뷰하고 세미나를 했던 적이 있는데 UrbanNav 저자들은 이 Citywalker 논문을 베이스로 잡아서 기존 Citywalker에서 저자들이 느꼈던 문제들을 조금 해결하면서 추가적으로 language instruction 까지 도입해서 language goal conditioned navigation 연구를 진행한 논문이라고 보시면 좋을 것 같습니다. 바로 리뷰 시작하도록 하겠습니다.
Introduction
사실 해당 인트로 부분은 language를 도입했다라는 점을 제외하고는 citywalker의 인트로와 비슷합니다. 그래도 해당 논문기준으로 다시 설명을 드리도록 하겠습니다. 먼저 기존 navigation 연구를 보면 크게 두 갈래가 있는데 하나는 GNM, ViNT, NoMaD처럼 주행 데이터를 바탕으로 정책을 직접 학습하는 learning-based 계열이고, 다른 하나는 SLAM, mapping, planning을 조합하는 보다 modular한 navigation stack 계열입니다. 전자는 end-to-end하게 행동을 만들 수 있다는 장점이 있지만 대규모 real robot trajectory가 필요하고 후자는 설계가 명확하지만 실제 open-world 환경에서는 구성 요소 간 오차 누적, 복잡한 튜닝, latency 문제가 따라오게됩니다. 특히 풀고자 하는 문제를 좁혀서 복잡한 도시 환경으로 가면 문제는 더 어려워지는데 실내와 달리 도시 장면은 상황도 다양하고pedestrian interaction도 많고, instruction같은 경우도 공원 분수 옆 건물로 가라, 유리 건물 왼쪽 교차로 표지판으로 가라 처럼 landmark 중심의 모호한 자연어인 경우가 많기 때문이라고 합니다.
이 논문이 기존 같은 문제를 풀고자 했던 CityWalekr를 직접적으로 겨냥하여 말하지는 않았지만 저자들은 두개의 질문을 던집니다.
먼저 첫번째는 웹에서 수집한 사람 walking video를 로봇 navigation 학습에 그대로 써도 되는지 그리고 두번째는 그런 비정형 비디오로부터 어떻게 instruction-action supervision을 자동으로 만들 것인지 입니다.
그래서 위 질문에 대한 저자들의 답은 그대로 쓰면 안 되고 robot-compatible filtering이 반드시 필요하고 trajectory와 landmark, instruction을 자동으로 연결해주는 annotation pipeline이 필요하다고 주장합니다. 결국 해덩 논문은 단순히 웹 비디오 많이 끌어 모아서 학습했다가 아니라 로봇에 맞는 데이터만 걸러내고 그 위에 instruction grounding을 얹는 데이터 가공 파이프라인을 설계하고자 합니다.
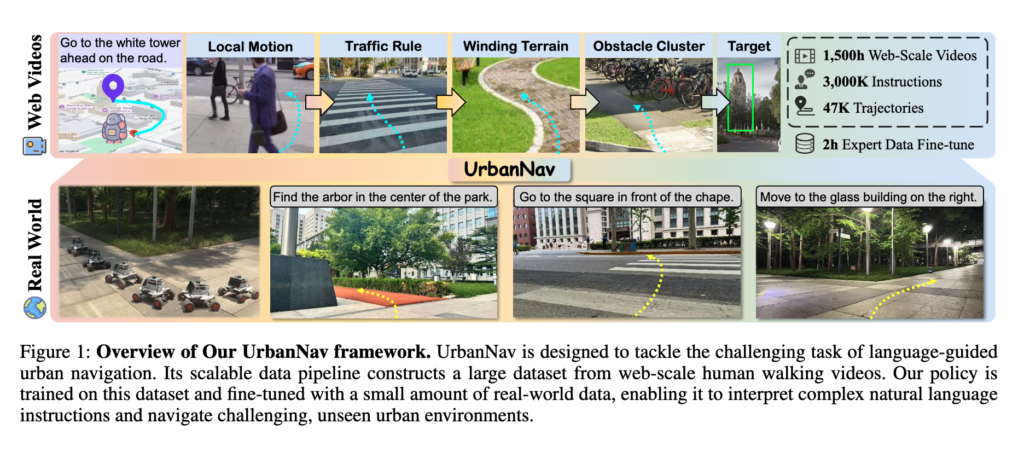
위 Figure 1을 보면 1,500시간 규모의 web-scale videos, 47K trajectories, 3M instructions를 바탕으로 policy를 사전학습하고, 이후 실제 데이터 2시간 정도만으로 fine-tune하는 전체 프레임워크를 보여주는데 여기서 결국 CityWalekr나 이 UrbanNav저자들 두 논문에서 어필하고 싶은 것은 도심 navigation을 위한 다양한 지식정보들은 결국 고비용의 Expert data보다는 web-scale human trajectory에서 쉽게 얻을 수 있다라는 것 같습니다.
Method
이 논문의 방법론은 크게 두 부분으로 나눠 볼 수 있습니다. 첫 번째는 in-the-wild human walking video로부터 잘 정제해서 로봇 내비게이션을 위한 고가치 데이터 셋을 선별하고 여기에 인스트럭션까지 추가해서 만드는 과정 긜고 두 번째는 그 데이터로 language-conditioned policy를 를 학습하는 policy architecture입니다. 전자가 좀더 해당 논문의 핵심인 것 같습니다.
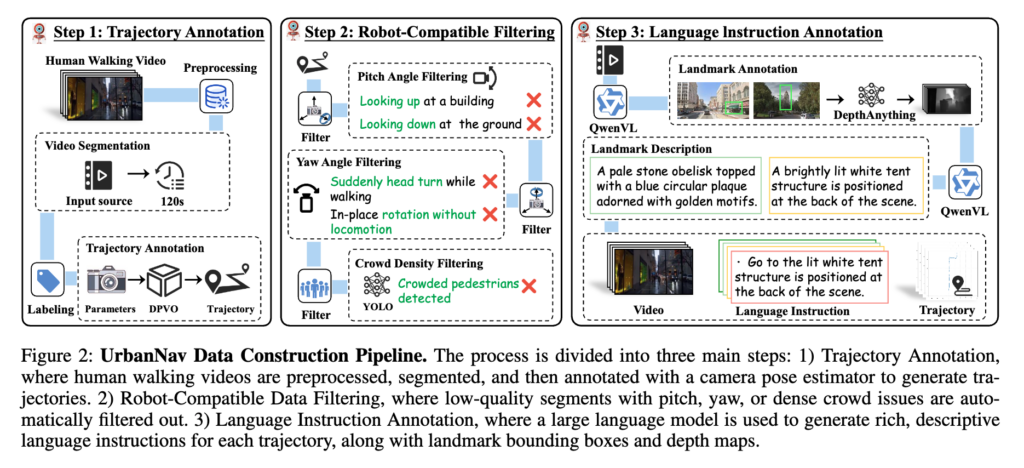
사실 위 그림이 첫번쨰 과정을 하나로 설명하는 그림이라고 보시면 될것 같습니다. 자세한 내용은 이어서 설명드리도록 하겠습니다.
유튜브 Video Labeling Pipeline
저자들은 YouTube에서 2,000시간이 넘는 egocentric human walking video를 수집합니다. CityWalker가 사용한 유튜브 비디오랑 동일합니다. 이 비디오는 도시 거리, 주거 지역, 공원 길 등 다양한 urban scene을 포함하고 있고 그리고 날씨, 조명, 장애물도 다양하게 다양한 시나리오들이 들어있습니다. 로봇 내비게이션 분야에서 이런 사람의 1인칭 walking video가 로봇의 egocentric motion과 어느 정도 유사하기 때문에 해당 데이터를 계속해서 활용해보고자 하는 것 같습니다. 물론 완전히 같지는 않지만 실제 teleoperation dataset보다 훨씬 scale이 크고 다양한 환경을 담고 있고 또 상대적으로 얻기 쉽기도 하기 때문인점도 있는 것 같습니다.
그 다음으로는 각 프레임 별로 포즈 정보를 annotation 해줘야합니다. 그래서 CityWalker가 사용한 방식 그대로 각 비디오를 2분짜리 clip으로 자르고 DPVO를 이용해 각 프레임의 camera pose를 추정해서 egocentric trajectory label을 만듭니다. 마찬가지로 저자들은 visual odometry는 긴 horizon에서 drift가 생길 수 있지만 이 논문은 policy가 과거 8 step 정도의 짧은 context만 이용해 미래 행동을 예측하기 때문에 로컬한 supervision으로는 충분히 쓸 수 있다고 설명합니다.
Robot에 적합한 Data로 Filtering
실제로 저도 기존 CityWalker를 재현하는 과정에서 유튜브 영상이나, 유튜브 영상을 가지고 수도라벨링을 뽑아냈을 때 정말 노이즈가 많다라는 것을 느꼈었고 그 중 하나는 특히 사람이 카메라를 들고 직진을 하면서 카메라 회전도 동시에 하기 때문에 기존 로봇 내비게이션(몸체와 카메라 고정)과의 이동과 카메라 시점 변환 정렬이 안맞는다는 점이었습니다. 실제로 해당 영상을 가지고 VO 알고르짐을 통해 포즈를 뽑아내면 엄청 이상하게 뽑힙니다. 해당 부분에 대해서 저자들도 똑같이 지적을 합니다. 사람 walking video는 로봇과 다르게 고개를 위아래로 크게 흔들 수 있고 또 옆을 쳐다보거나 제자리 회전을 할 수도 있고 또 엄청 북적거리는 보행자 틈 사이을 비집고 지나가는 행동도 자주 나타납니다. 그런데 이런 영상은 로봇 정책을 학습시키기엔 부적절 한데 왜냐하면 로봇 카메라는 보통 forward-facing fixed-view(로봇의 직진 방향과 카메라의 시점 동일)이고 이를 기반으로 한 navigation policy는 시점과 이동 방향의 일관성을 전제로 학습이 이뤄집니다 그래서 사람의 머리 움직임까지 들어간 데이터를 그대로 넣으면 정책이 보는 방향과 실제 가는 방향의 관계를 헷갈리게 학습할 가능성이 크다고 저자들은 주장합니다.
그래서 저자들은 세 가지 필터를 둡니다. 첫번째는 pitch variation이 15도 이상이면 제거해서 위아래 고개 움직임이 큰 시퀀스를 버리고 두번째로는 로봇의 이동 방향과 카메라 뷰 방향의 각도가 60도 이상이면 제거해서 갑작스러운 카메라 헤드 움직임 그리고 꽃게 움직임 그리고 카메라 들고 한바퀴 빙글 도는 행위 와 같은 클립을 걸러냅니다. 그리고 마지막으로 YOLOv10을 이용해 보행자를 탐지해서 보행자 밀집도를 계산하고 한 프레임에 5명 이상이 여러 번 등장하는 씬은 제거합니다. 결과적으로 대략 1566시간 규모로 줄여서 최종 훈련용 데이터를 만듭니다.
Language Instruction Annotation
그 다음은 trajectory에 language를 붙이게 되는데. 저자들은 먼저 trajectory 주변에 있는 landmark를 골라야 한다고 말합니다. 해당 landmark는 도달 가능해야 하고 시각적으로도 구분 가능해야 하고 또 동적인 객체가 아니어야 한다고 합니다. 예를 들어 buildings, sculptures, signboards, traffic lights는 괜찮지만 pedestrians나 vehicles는 제외한다고 합니다. 이후 Qwen2.5-VL-72B를 이용해 landmark를 detection하고 bounding box와 landmark name을 얻은 뒤 다시 VLM을 활용해 자연스러운 navigation instruction을 생성했다고 합니다. 결국 한 trajectory 안에 여러 landmark 후보가 생기고, 각각에 대해 도로 중앙 분리대 앞 노란 표지판으로 가라 같은 language instruction이 자동 생성된다고 합니다. 근데 여기 부분이 해당 과정애 대해서 깊게 다루지 않고 있어서 가장 많은 의문점이 들었던 파트입니다. 여기서 detection은 어떻게 했는지랑 자연스로운 navigation instruction을 생성할 때 비디오 클립단위를 넣었는지 등등이 잘 설명이 되어있지 않았습니다. 결국 ~~로 가라 라는 자연어를 생성하기 위해서는 실제 해당 영상이 그 길로 가야 올바른 GT가 생성될 수 있는건데 프레임 하나만 보고 ~~로 가라라는 자연어를 생성하면 실제 그 클립이 그대로 갔는지는 알 수 없는데 이걸 어떻게 처리했는가 궁금하네요. detection은 뭔가 Qwen2.5-VL-72B만을 사용해서 BBOX추출도 다 한것 같은데, 여기서 생기는 노이즈 결과(모호한 주석, 잘못된 라벨링, BBOX)는 저자들이 수작업으로 직접 제거 했다고 합니다. 프레임수로 따지면 엄청 많을 텐데 어떻게 수작업으로 제거했는지는 따로 언급은 없었습니다. 돌아와서 최종적으로는 trajectory당 평균 65개의 landmark, 평균 17 단어 길이의 description이 생성했다고 합니다.
Policy Architecture
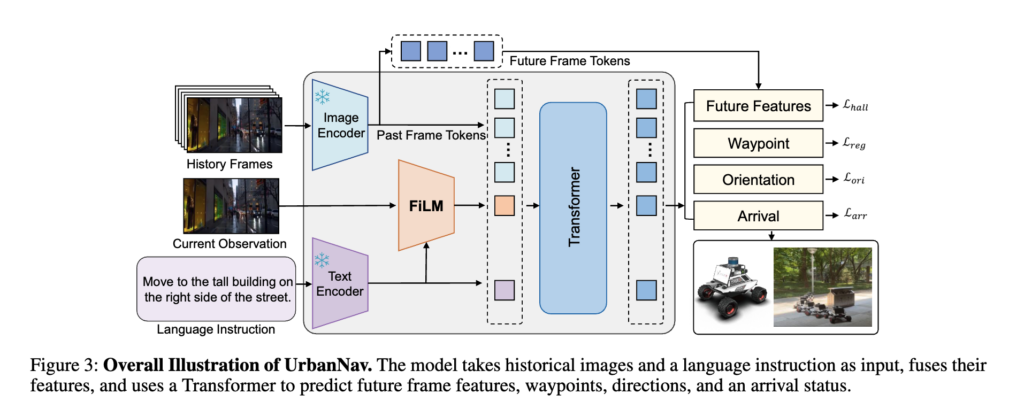
policy 구조는 기존 CityWalker와 goal 입력 모달리티만 달라졌다만 제외하면 거의 똑같습니다. 일단 모델 입력은 language instruction, 현재 observation, 그리고 과거 k개의 visual observation입니다. 여기서 k=8입니다. language는 CLIP 텍스트인코더로으로 인코딩하고 visual frame은 DINOv2로 인코딩합니다. 이 두 encoder는 frozen 상태로 두고 현재 observation은 FiLM을 이용해 language-conditioned에 맞게 끔 인코딩 되고 생성된 토큰들은 historical visual token과 함께 Transformer encoder에 들어가게 됩니다. 그 결과로 future trajectory에 해당하는 waypoint, orientation, arrival status, 그리고 future frame feature을 예측하게 됩니다. Future Features는 citywalker의 Hallucination feature랑 똑같이 설계했다고 보시면 좋을 것 같습니다.
Loss
loss는 총 네 가지입니다. waypoint regression loss, orientation loss, arrival prediction loss, feature hallucination loss입니다. waypoint loss는 예측한 waypoints에서 predicted position(x,y)과 GT position의 L2 차이를 의미하고, orientation loss는 predicted direction과 GT direction의 각도 차이를 cosine similarity 기반으로 계산하는 항입니다. 그리고 arrival loss는 goal에 도달했는지 여부를 BCE로 손실항을 구성하고 마지막으로 hallucination loss는 미래 observation feature의 L1 차이를 나타내는 항이라고 보시면 좋을 것 같습니다.
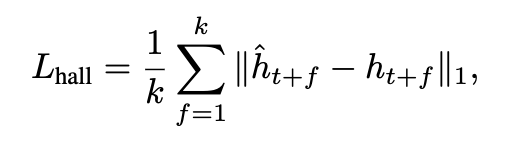
최종 항은 아래 처럼 구성됩니다.
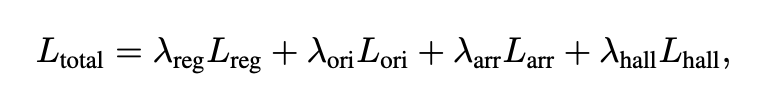
Experiments
먼저 베이스라인은 NoMaD + CLIP, ViNT + CLIP, LeLaN으로 설정합니다. 여기서 NoMaD와 ViNT는 원래 language input을 직접 받는 구조가 아니기 때문에, 저자들은 CLIP으로 text feature를 뽑아 visual feature와 fusion하는 방식으로 비교했다고 설명합니다. 그리고 LeLaN은 원래 Language를 골로 입력받아 indoor object-goal navigation 계열인데 출력이 waypoints가 아니라 선/각 속도 값이라 이부분만 따로 헤드를 설계해서 future waypoint regression 형태로 출력하도록 하여 비교했다고 합니다. baseline 비교는 완전히 원논문 그대로는 아니고 language-guided urban waypoint prediction task에 맞게 약간 변형한 버전들이라고 합니다. 아마도 기존 이미지 인코더를 그대로 썼을 것 같기 때문에 따로 텍스트와의 정렬을 맞춰서 엄밀하게 실험을 진행하지는 않았을 것 같습니다.
평가는 offline 테스트 셋과 real-world에서 평가를 수행하고 offline에서는 AOE, MAOE로 방향 오차를 보고, ADE, MADE로 위치 및 경로 차이를 비교합니다. AOE는 각도 차이, ADE는 거리 차이를 의미하고 여기에 M이 붙은 친구들은 약간 좀더 보수적으로 평가하는 친구들 이라고 보시면 좋을 것 같습니다.(예측한 waypoint에서 가장 오차가 큰 친구들의 평균)
Offline Benchmark
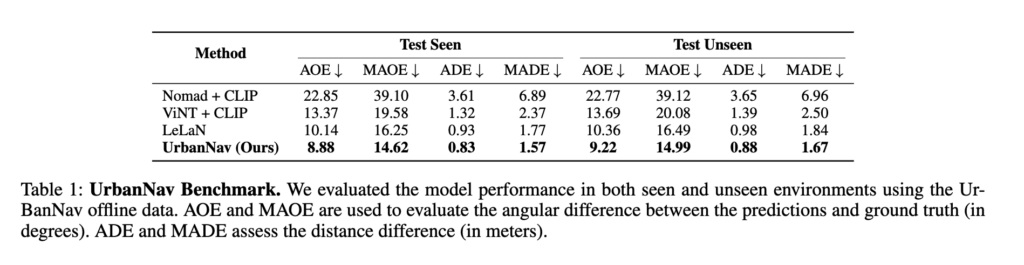
Table 1을 보면 UrbanNav는 seen/unseen 모두에서 가장 좋은 성능을 보입니다. seen이랑 unseen 격차가 크그렇게 크지는 않은데 이부분에 대해서 저자들은 모델이 단순히 훈련 환경의 landmark를 암기했다기보다 어느 정도 instruction-grounded motion prior를 일반화해서 배웠다고 합니다. 물론 이건 offline trajectory error 관점의 이야기이고 실제 real world deployment에서는 다를 수 있다고 생각합니다.
Real-World Deployment
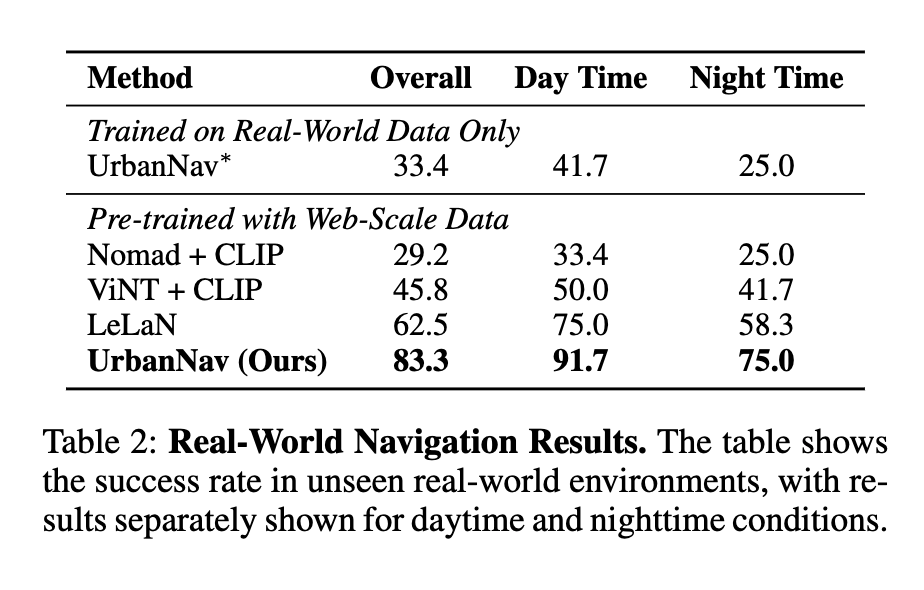
여기서 real-world data only로 학습한 UrbanNav가 overall 33.4% 밖에 안나오는데 저자들은 이부분에 대해서 이 모델의 성능은 단순히 architecture가 좋아서가 아니라 web-scale pretraining이 real-world deployment에서의 이점을 보여준다라고 주장합니다.
Robustness in Challenging Scenarios
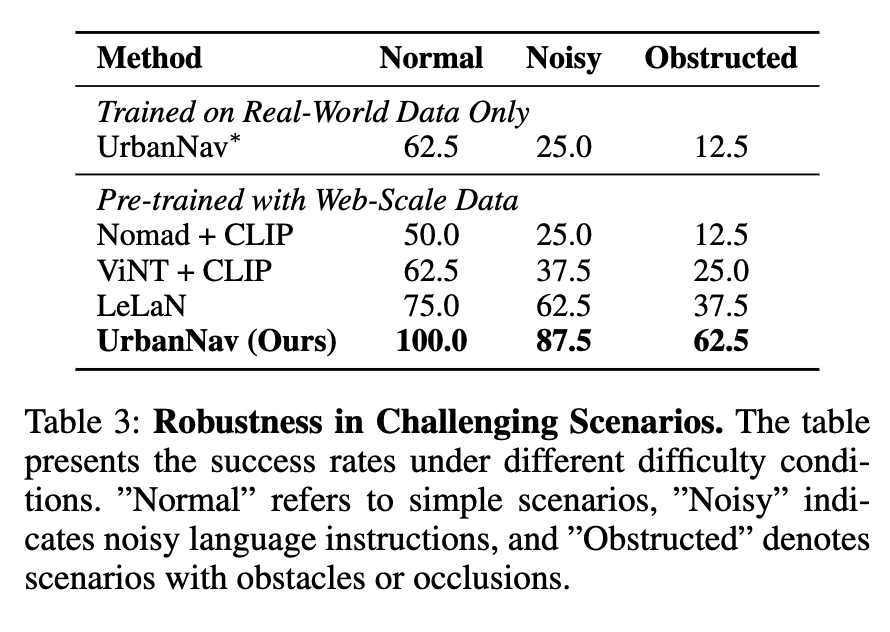
Table 3은 normal, noisy, obstructed 세 가지 시나리오로 robustness를 나눠 평가합니다. UrbanNav는 baseline 대비 모두 가장 높은결과를 보입니다. 저자들은 이것도 마찬가지로 web-scale 데이터에 다양한 expression과 landmark description이 들어갔기 때문이라고 주장합니다.
obstructed scenario에서는 UrbanNav도 성능이 많이 떨어지는결과를 보이는데, 여기선 저자도 이를 인정하면서,자기 방법은 local navigation에 더 가깝고 처음부터 목표가 안 보이는 경우 long-horizon exploration까지 강하게 하도록 설계된 것은 아니라고 주장합니다.
Qualitative Results
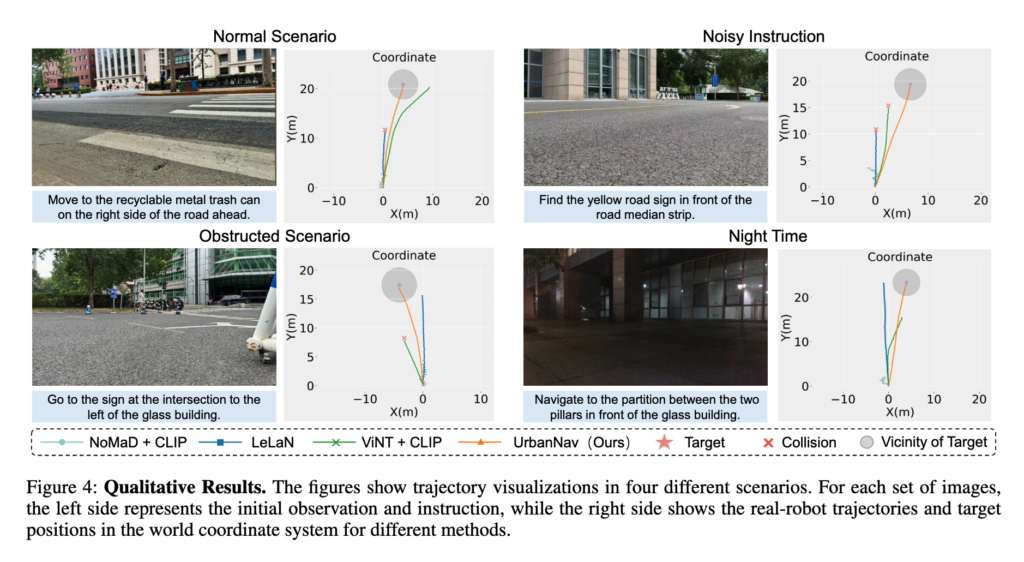
Figure 4는 정성적으로 normal, noisy instruction, obstructed, night time 네 가지 상황에서의 결과를 보여줍니당. UrbanNav는 목표 근처로 비교적 안정적으로 도달하는 반면, baseline들은 instruction을 잘못 해석하거나 collision을 일으키는 경우가 잦았다고 합니다.
Ablation Study
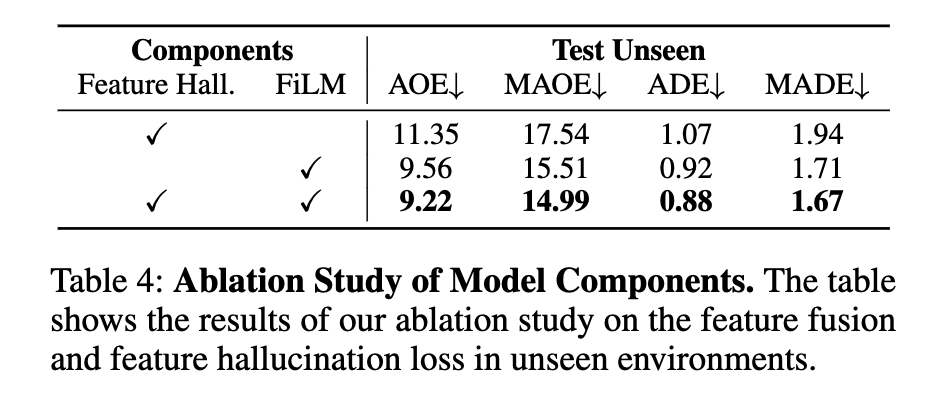
Table 4는 FiLM feature fusion, feature hallucination loss에 대한 ablation 결과 입니다. 둘 다 없는 경우보다 각각 추가될수록 unseen 성능이 좋아지고, 둘 다 함께 있을 때 가장 좋은 결과를 보입니다.
여기서 hallucination loss 부분에 대해서는 CItywalker는 이런 auxiliary future prediction이 zero-shot inference에 꼭 도움이 되지 않는다는 지적하는 부분이 있었고 실제로도 해당 논문에서 성능이 떨어지는 실험결과를 제시했는데, 이 논문은 오히려 이 hallucination loss가 이득이 있다고 말하고 실험결과도 실제로 그렇게 나왔다고 주장합니다. 저자들은 그 이유를 clean하고 robot-compatible한 data 덕분이라고 설명합니다. 즉 로봇에 적합한 데이터 정제 과정이 있었기 때문이라고 합니다. 데이터에 안좋은 품질의 데이터들이 많이 존재하면 future feature prediction은 오히려 잘못된 미래 예측을 하게끔 학습이 이뤄질 수 있는데 여기선 filtering으로 view-motion consistency를 맞춘 덕분에 미래 장면 예측이 더 유의미한 학습 신호가 되었을 가능성이 크다고 합니다.
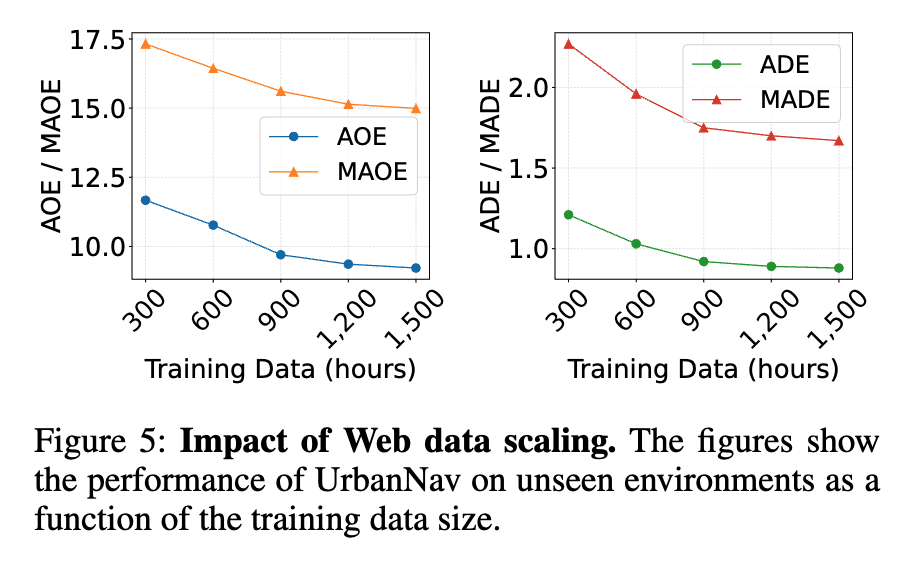
Figure 5는 훈련 데이터 양을 300시간에서 1,500시간까지 늘려가며 unseen 성능을 본 결과입니다. 결과적으로 데이터 양이 많아질 수 록 성능이 좋아지는 결과를 보입니다.
Conclusion
논문을 읽으면서 들었던 생각은 뭔가 저자의 언급이랑은 다른 엉뚱한(?) reference가 달려있는거랑 그리고 모델 input 관련해서 갑자기 나중에는 로봇의 위치정보가 입력으로 들어간다는 등 서두랑 실험파트에서 말하는 저자의 주장이 일치하지 않는것 등등이 많아서 살짝 아쉬운 부분이 많았습니다. 그리고 가장 아쉬운건 저자들의 프레임워크, 그리고 사전학습 데이터 등등 다 Citywalker를 기반으로 하고 있는데 정작 citywalker와의 성능비교는 리포팅 하지 않았다는 점이 좀 아쉬웠습니다. 그리고 CityWalker도 그렇고 이 UrbanNav는 planning 관점 혹은 로봇 관점에서 안정적인 action 시퀀스를 뱉기 위해서 고려한 설계에 대한 내용이 들어있다기보다 기존에 주어진 웹스케일의 방대한 비디오 데이터셋을 어떻게 비전 알고리즘을 통해 잘 가공해서 이러한 내비게이션 태스크에도 잘 동작할 수 있음을 보여주는 논문인 것 같습니다. 그리고 둘다 확실히 오프라인 테스트 데이터 셋을 구축하고 정량적 평가설계도 엄밀하게 하는 모습도 보입니다. 다만 real robot 환경에서의 평가도 하긴 하지만 약간 디테일한 결과나 실험 세팅을 제시해주지 않습니다. 근데 citywalker를 제외하고 읽었던 논문들이 대부분 로보틱스 관련 학회였는데 해당 논문들은 로봇 내비게이션 관점에서 설계한 아키텍쳐의 성능을 비교하는 부분에 있어서 citywalker,urbanNav랑 다르게 디테일한 정량적인 평가는 제시하지 않지만 real 환경이라던가 시뮬레이션에서의 평가 결과를 여러 로봇 플랫폼이나 다양한 시나리오를 설계해서 평가해서 제시합니다. 물론 여기서도 막 엄청 디테일한 결과나 실험세팅을 어떻게 했는지 엄청 자세히 제시하지는 않지만 일단은 real 환경에서 다양한 시나리오에 대해 실제 로봇에 탑쟈했을 때 원하는 목표점 까지 안전하게 간다라는 것은 확실하게 보여주는 것 같습니다. 오프라인 테스트 데이터셋 같은걸로 그 순간 궤적 하나 하나에 대한 정량적 평가를 잘 하지 않는 것 같습니다. 로봇 관점에서는 안전하게 최종 목적지 까지 도착하는게 중요하고 여러번 움직임으로써 최종 목적지에 잘 도달할 수 있는지를 목적으로 설계된 연구이다 보니 여기서 수행한 이 로컬한 움직임의 그 순간만의 평가는 사실 의미 없는 평가일 수 도 있을 것 같습니다.(왜냐면 기존 방법론은 해당 순간의 오차는 다음 단계에서 보완되도록 움직이게끔 설계되어있고 실제로 제시된 수치차이는 거의 너무 작기 때문에 그래서 실제로 제 개인적인 생각으로는 여기서 제시한 정량적 결과랑 real robot에 배치했을 때의 결과는 다를 수 있다고 생각합니다.) 이만 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요 우현님 리뷰 감사합니다.
논문의 내용과는 조금 다른 질문일수도 있으나, navigation 쪽은 indoor와 outdoor를 나누어서 연구하는 것 같은데, 혹시 가장 큰 이유가 있을까요? 요구되는 근본적인 능력은 비슷할거라고 생각하는데, urban 세팅에서의 연구는 어떤 특징이 있는지 궁금합니다. 또 세미나에서도 city에서 navigation하는 연구를 다뤄주신 것 같은데, 우현님의 개인적인 연구 방향과 연관이 있는 것인지 궁금합니다.