안녕하세요, 오늘 리뷰할 논문은 AAAI 2026 Oral 논문인 SM3Det 입니다. LVU 논문 작업 이후 다시 저희 팀 기업 과제 팔로우업과 창의학기제를 겸해서 SAR Object Detection 관련 논문을 읽고 있는 중인데, 좋은 아이디어를 가지고 주장을 전개해나간 것 같습니다. 리뷰 시작하겠습니다!
Introduction
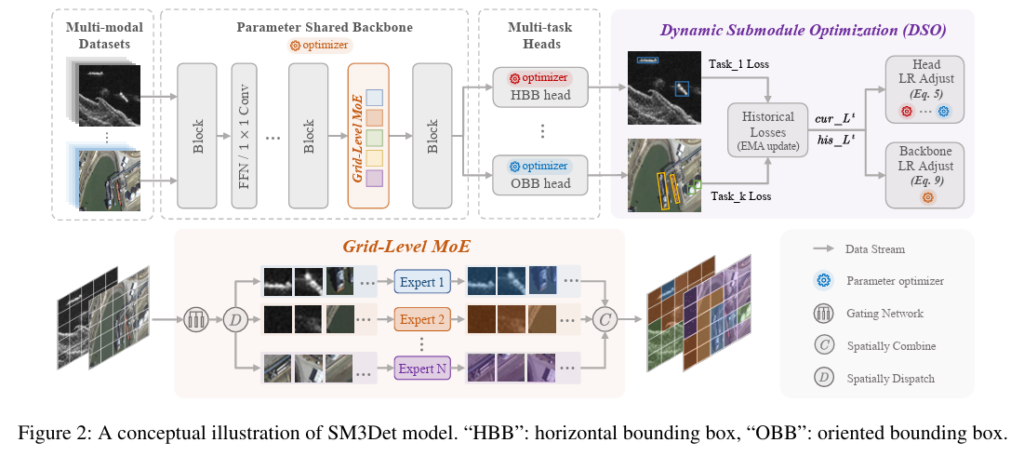
기존의 객체 탐지 모델들은 주로 단일 모달리티 데이터셋만을 다루며, HBB(Horizontal Bounding Box)나 OBB(Oriented Bounding Box)와 같이 미리 정의된 단일 형태의 탐지 과제만 수행하는 한계가 있었습니다. 이러한 획일화된 방식은 여러 모달리티 사이에 분명히 존재하는 ‘공통 지식(Shared Knowledge)’을 간과하게 만듭니다. 특히 최근 무인기(UAV)나 위성들은 다양한 센서를 탑재하고 있어, 동일한 영역을 촬영한 다채로운 모달리티의 이미지를 동시에 처리하는 능력이 어느 때보다 중요해졌습니다. 공간적으로 정렬된(Spatially aligned) 다중 소스 이미지를 다루는 기존 연구들도 존재하지만, 이 역시 단일 형태의 탐지 과제로 제한된다는 단점이 있습니다. 결과적으로 공간적 정렬에 얽매이지 않고 모든 모달리티를 아우르며, 다중 형태(Multiple format)의 객체 탐지가 가능한 진정한 의미의 통합 모델의 필요성이 대두되었습니다. 이러한 필요성에 따라 저자들은 입력 모달리티나 사전 정의된 task format에 구애받지 않고 객체를 탐지하는 새로운 태스크인 M2Det(Multi-modal Datasets and Multi-Task Object Detection)을 제안합니다.
Natural 이미지와 Painting 이미지 데이터셋을 묶어서 학습하는 것은 두 데이터가 광학 이미지 베이스라는 점에서 크게 문제가 되지 않았고, 성능 또한 향상이 있었습니다. 하지만 Remote Sensing 멀티모달 데이터셋의 경우 데이터셋을 통합하는 과정에서 두 가지 병목을 겪게 됩니다.
- Representation Constraints : RGB, SAR, IR 등 모달리티마다 고유한 패턴과 데이터 분포가 완전히 다릅니다. 따라서 기존처럼 단일 파라미터 세트(Dense Model)만으로 이 모든 특성을 억지로 담아내려다 보면 모델의 수용력이 부족해집니다
- Optimization Inconsistencies : 모달리티나 태스크마다 모델이 겪는 학습 ‘난이도’가 제각각입니다. 논문에서 예로 든 HBB와 OBB를 보면, 우리가 일반적으로 아는 HBB에 비해 OBB(회전 바운딩 박스)는 객체가 뉘어져 있는 미세한 회전 각도(Angle)까지 추가로 아주 정밀하게 맞춰야 하므로 체감 난이도가 훨씬 높고 손실(Loss)이 떨어지는 속도도 느립니다. 이로 인해 네트워크 내부 요소들의 최적화 속도와 방향이 서로 엇갈리게 되고, 결국 특정 태스크의 손실을 줄이려다 다른 태스크의 성능이 떨어지는 등 목표 간의 충돌이 발생합니다
저자들은 이러한 문제를 해결하기 위해 SAR(SARDet-100k), RGB(DOTA), 적외선(DroneVehicle) 데이터를 하나로 묶은 종합적인 벤치마크를 구축하고, 통합 모델인 SM3Det를 제안합니다. 이 모델의 해결 전략은 구조적 측면과 최적화 측면 두 가지로 나뉩니다.
- Grid-level Sparse MoE
백본 네트워크에 Plug-and-play 방식의 Sparse MoE(Mixture of Experts) 아키텍처를 도입했습니다. 이미지가 들어오면 통째로 특정 전문가에게 보내버리는 기존의 Image-level routing과 달리, 피처맵을 그리드(Grid) 단위로 잘게 쪼개어 각 영역(패치)에 가장 적합한 전문가를 동적으로 할당(Adaptive routing)합니다. 이를 통해 모달리티 간의 공통 지식과 고유한 표현을 엉킴 없이 모두 효과적으로 포착해 냅니다. - DSO (Dynamic Submodule Optimization)
모델 최적화의 일관성과 동기화를 맞추기 위해 DSO 메커니즘을 적용했습니다. 기존처럼 단순히 손실 함수의 가중치를 조절하거나 gradient를 변형하는 방식은 특정 부품을 정밀하게 통제하기 어렵고 계산 효율도 떨어졌습니다. 반면 DSO는 backbone과 task head 등 네트워크 각 구성 요소의 학습률(Learning Rate, LR)을 맞춤형 policy에 따라 동적으로 조절합니다. 특정 task만 비정상적으로 빠르게 학습되거나 뒤처지지 않도록 수렴 속도의 균형을 맞추고, 네트워크 전체가 일관된 방향으로 업데이트되도록 아주 세밀하게 제어하는 역할을 수행합니다.
Methods
Grid-Level MoE
기존의 멀티 데이터셋 객체 탐지는 같은 파라미터를 공유하는 Dense model을 적용하여 모달리티 간의 공통 지식을 사용했으며, 데이터셋이 결국 attribute 등만 다른 광학 이미지 기반이었기 때문에 실제로 효과가 있었습니다. 하지만 RGB, SAR, IR 등의 멀티모달 이미지는 shape이나 scale처럼 ‘공통 지식’인 부분도 존재하지만, 모달리티 간의 근본적인 차이로 인해 위와 같은 밀집 모델을 적용할 경우 피처 공간이 혼잡해지는 문제가 발생합니다. 따라서 모달리티 간의 공통 지식에 더해 각 모달리티별 고유한 표현(distinct representation)을 학습하기 위해 저자들은 Sparse MoE 아키텍처를 제안했습니다.
저자들은 이 MoE Experts들을 FFN(Feed-Forward Network) 안에 통합했습니다. 기존 현대 CNN에서는 특징 간의 상호작용이나 차원 축소 및 확장을 위해 1×1 conv을 사용했는데, 저자들이 제안한 Sparse experts는 바로 이 레이어를 강화하기 위해 도입되었습니다. 또한, 기존 Transformer 기반 detector가 전체 이미지를 하나의 전문가에게만 보냈던 것과 달리, Sparse MoE는 local grid마다 가장 알맞은 전문가가 처리하도록 설계되었습니다. 정확한 동작 과정은 다음과 같습니다.
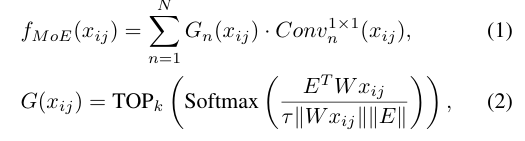
먼저 feature map을 그리드 레벨로 자른 뒤, local feature인 x(편의상 ‘패치’라고 칭하겠습니다)를 가지고 수식과 같은 과정을 전개합니다. 우선 게이팅(gating) 함수 G를 통해 관련도가 높은 전문가를 top-k로 선별합니다. 이때 패치 x와 가중치 W를 곱해준 뒤, 전문가별 ‘표현 임베딩’을 의미하는 E와 비교하여 코사인 유사도를 계산합니다. 참고로 여기서 Experts는 병렬로 선언된 N개의 1×1 conv layer를 의미합니다. 이후Softmax를 통해 유사도가 전문가별 확률 분포로 반환되며, 이 중에서 상위 k개의 전문가만 선별합니다. 선택된 전문가로 1×1 합성곱 연산을 진행하고, softmax 확률값을 가중치로 사용하여 가중합을 구하는 과정을 뽑힌 k개의 전문가 모두에 대해 수행합니다. expert 초기화의 경우, 사전 학습된 1×1 합성곱 가중치를 N개의 전문가에 모두 동일하게 복제하여 초기화합니다.
Dynamic Submodule Optimization(DSO)
Multi-task 객체 탐지에서 마주하는 난관 중 하나는 모달리티와 task마다 학습 난이도가 다르다는 것입니다. 이러한 차이는 동기화되지 않은 최적화 속도와 일관적이지 않은 최적화 방향을 유발하며, 결국 서로 다른 손실 함수(loss function) 간의 objective가 충돌하는 현상을 초래합니다. 저자들은 이 문제를 해결하기 위해 DSO 메커니즘을 제안했습니다.
DSO는 각 task head에서 계산된 손실(loss) 값을 지표(indicator)로 사용하여 task submodule별 학습률(learning rate, LR)을 동적으로 조정합니다. 이를 위해 두 가지 Policy를 제안했습니다.
- 1. 독립적인 가중치를 갖는 태스크 헤드는 각 태스크별 수렴 속도가 균형을 이루도록 개별적으로 학습률을 조절하여 특정 태스크에만 과적합되거나 뒤처지는 것을 방지합니다.
- 2. 공유 가중치인 백본(backbone)의 경우 파라미터 업데이트 방향이 서로 충돌하지 않고 일관성을 유지하도록 학습률을 통제합니다.
우선 학습 손실(training loss)을 다음과 같이 정의합니다.
- {cur\_L}_{i}^{t} : i번째 반복(iteration)에서 task t의 현재 손실 값
- {his\_L}_{i}^{t} : 태스크 t의 과거 손실 누적 지수 이동 평균(EMA, Exponential Moving Average)
다음으로는 태스크 헤드별 학습률 조정과 백본의 학습률 조정 계산을 나누어 진행합니다.
1. Task head Submodule’s LR adjustment
먼저 태스크별로 w_i^t = {his\_L}_{i}^{t} / {cur\_L}_{i}^{t} 라는 수렴 속도의 역을 계산합니다. 이후 재가중치 요소(reweighting factor)를 다음과 같이 정의합니다.
온도(temperature) \theta가 적용된 소프트맥스(softmax) 계산 후 전체 태스크 개수 T를 곱하여 재가중치 요소인 \lambda_i^t를 만듭니다. 결과적으로 cur_L 값이 크면 수렴이 더 빠르다는 것을 의미하며, 이에 따라 w_i^t가 작아지고 최종적으로 \lambda_i^t가 작게 도출되어 과도하게 빠른 수렴 속도를 제어하게 됩니다.
2. Backbone Submodule’s LR adjustment
백본은 모든 태스크(task)가 파라미터를 공유하기 때문에, 전체적인 일관성을 잘 고려하기 위해 일관성 점수(Consistency Score, C)를 구하며, 이는 다음의 과정을 통해 계산합니다.

- his_L와 cur_L를 각각 softmax 함수에 통과시킵니다. → P(L) = \text{Softmax}(L)
- KL divergence, D_{KL}을 사용하여 현재의 손실(loss) 분포와 과거의 손실 분포가 얼마나 달라졌는지를 측정합니다. 이후 1에서 이 값을 빼서 C를 정의합니다. 이때 C는 (-\infty, 1]의 범위를 갖게 되는데, 1에 가깝다면 현재의 손실 비율이 과거의 비율과 비슷하다는 의미이므로 현재의 학습이 안정적이라는 것을 나타냅니다. 이때는 학습률(LR)을 높여서 빠른 수렴을 유도해야 합니다. 반대로 C가 작다면 학습이 불안정하다는 의미이므로 학습률을 낮추어 조심스럽게 업데이트해야 합니다.
따라서 공유 가중치 백본(shared weight backbone)을 동적으로 재가중치(reweighting)하기 위해 이 식을 사용합니다.

- sigmoid 함수에 2를 곱하여 최종 가중치가 (0, 2) 범위가 되도록 설정합니다.
- b : 기준점 역할을 하는 하이퍼파라미터로, 만약 C = b라면 가중치가 1이 되어 원래의 학습률이 그대로 유지됩니다.
- \tau (온도, temperature) : 값의 민감도를 조절합니다.
Experiments

M2Det task의 학습 및 평가를 위해 SARDet-100K(SAR 이미지), DOTA-v1.0(광학 이미지), DroneVehicle(적외선 이미지)의 세 데이터셋을 합쳐 SOI-Det라는 새 벤치마크 데이터셋을 만들고 사용했으며, 백본으로는 디폴트로 ConvNext-T를 사용했습니다. 베이스라인인 3 model은 각 데이터셋에 모델을 따로 학습시킨 결과입니다.
주목할 점은, simple joint training(공통 백본과 개별 태스크 헤드를 적용하고 무작위 샘플링으로 학습시키는 방식)에서 큰 폭의 성능 하락이 있었는데, 이는 멀티 모달리티를 다루는 본 task가 얼마나 힘든 과제인지 방증합니다. 반면 SM3Det는mAP를 1.97 끌어올렸으며, 특히 DSO만 적용한 lightweight version에서도 다른 SOTA 모델들을 앞서는 모습을 보였습니다. 여러 모달리티와 task(HBB,OBB, …)가 존재하는 상황에서 consistent한 학습을 위해 LR을 잘 조절해주는 게 중요함을 증명해낸 결과라고 볼 수 있을 것 같습니다.

experts의 수와 top k의 구성에 대한 ablation인데, 보신 바와 같이 N=8, top-k=2 조합이 가장 성능이 좋았습니다. N,k 값을 늘릴 수록 모델의 표현력이 풍부해진다고 예상해볼 수 있지만, 그만큼 연산량이 늘어나기 때문에 성능 향상과 연산 효율성 사이 trade-off를 고려해서 위의 세팅이 최적이었다고 합니다. 또한 experts는 grid-level로 적용했을 때 압도적인 성능을 보여줌으로써, 더 세밀한 단위로 처리하는 것이 object localization에 도움이 되었다라고 설명합니다.
DSO의 파라미터 tau, b에 대한 하이퍼파라미터 튜닝 실험 결과입니다. 인상적인 부분은 bias의 경우 값을 다르게 설정하더라도 성능 차가 미미했으며, task head policy(non-shared)와 backbone policy(shared)을 각각 켜고 껐을 때의 실험을 통해서 두 가지 policy가 모두 적용되었을 때 제대로된 성능이 나온다는 것을 보여주었습니다
Conclusion
이 논문은 원격 탐사 환경에서 멀티모달 데이터셋과 멀티 task 객체 탐지를 수행하는 M2Det task를 정의하고 이에 대해 Grid-level MoE와 DSO를 통합한 모델인 SM3Det를 성공적으로 제시했습니다. 저자들은 비록 multi-spectrum 이미지를 추가로 실험에 포함시키지 못하긴 했지만, 다른 모달리티로의 확장 가능성을 내세우며 다양한 컴퓨터 비전 응용 분야에 적용될 수 있음을 주장합니다.
안녕하세요, 재윤님. 좋은 리뷰 감사합니다.
Grid-level로 MoE를 적용한 방식이 특히 인상 깊었습니다.
한 가지 궁금한 점은, 기존에도 이미지 분석이나 객체 탐지 분야에서 MoE가 활용된 사례가 있었는지입니다.
만약 있다면, 본 논문의 방식과 어떤 차이가 있는지도 간단히 설명해주시면 감사하겠습니다.
안녕하세요 기현님, 좋은 질문 감사합니다.
기존 멀티 데이터셋 객체 탐지 task에서의 MoE 방식은 image-level routing, 전체 이미지를 통째로 특정 expert에게 전달해서 처리합니다. 이러한 방식은 광학 이미지 기반의 자연 이미지, 그림 이미지 등의 병합 데이터셋에서는 꽤 효과적으로 동작했으나 M2Det task의 detection의 경우엔 성격이 아예 다른 SAR, RGB, IR 등의 멀티모달 이미지를 사용하기 때문에 모달리티 간 공동의 지식과 모달리티 특유의 패턴을 모두 포착하기 위해 grid-level sparse MoE를 적용했습니다.
안녕하세요 재윤님 좋은 리뷰 감사합니다.
Expert 초기화할 때에 사전 학습된 1×1 합성곱 가중치를 N개의 전문가에 모두 동일하게 복제하여 초기화한다고 언급해주셨는데, 그렇다면 학습 초기에 모든 expert가 동일한 출력을 가지게되어 gating 함수의 라우팅이 무의미해지는건 아닌지 궁금합니다. expert를 나누는 과정에서 어떤 메커니즘이 사용되서 잘 학습될 수 있는지 궁금합니다.
grid-level 라우팅에서 grid의 크기는 어떻게 결정되는지 궁금합니다. 너무 작으면 local context가 부족해지고, 너무 크면 grid-level로 나누는 의미가 없어질 것 같은데 이에 대한 분석이나 ablation이 있는지 궁금합니다.
감사합니다.
안녕하세요 성준님, 좋은 질문 감사합니다.
1) 말씀주신대로 첫 번째 미니배치가 들어올 때는 모든 expert 가중치가 동일하기 때문에 사실상 랜덤 선택으로 top k experts를 선택합니다. 이때 들어오는 이미지에 따라서 각 expert 가중치가 업데이트되는데, 예를 들어서 첫 입력 이미지가 자동차 RGB 이미지라면 선택된 expert에 자동차의 특징이 담기고, 다음 이미지가 SAR 이미지라면 SAR의 노이즈 피처가 담기는 식으로 ‘분업화’가 이뤄지게 됩니다. 결국 학습이 진행될 수록 각 expert는 특정 feature에 전문화됩니다.
(2) 질문 주셔서 생각해보니, ‘패치’ 같은 개념이 아니라 ‘픽셀’의 개념이 더 가까울 것 같습니다. Grid-level MoE모듈은 ConvNext 백본의 중간 레이어에 플러그인해서 사용하는데, 이때 픽셀 하나에 receptive field만큼의 정보가 담기게 됩니다. 그렇기 때문에 grid는 feature map의 한 픽셀을 나타내고, expert(1×1 conv)를 적용해서 처리하게 됩니다.