Introduction
Foundation model(e.g. CLIP)의 등장 이후의 model은 엄청난 성능과 일반화 능력을 가지게 되었습니다. 하지만 개인 수준에서 foundation model처럼 대용량의 데이터셋으로 학습시키는건 불가능에 가깝습니다. 그렇기에 결국 foundation model을 어떻게 task에 맞게 잘 tuning 시키는지가 중요해졌습니다.
이 논문은 CLIP을 위주로 진행합니다. 그렇기에 일단 CLIP이 어떤 feature에 집중하는지 시각화해보았습니다.

Fig. 2를 보면, CLIP은 channel마다 다른 semantic 부분에 집중한다는 것을 볼 수 있습니다. 가장 첫번째 사진을 보면, 특정 채널은 귀, 얼굴, 외곽 등등 다른 의미적 부분에 Grad-CAM이 몰려있습니다.
위 시각화 결과에서 인사이트를 얻어 논문은 Masked Channel Modeling을 제안합니다. feature embedding의 특정 channel들을 masking하고 이를 reconstruction하는 과정에서 encoder는 열심히 가려진 semantic 정보를 유추해야고, 이를 통해 전반적 semantic 이해도가 오르기에 성능 또한 오른다고 주장하고 있습니다.
그래서 Masked Channel Modeling(이하 MCM)의 장점은
1. Foundation model(CLIP)을 low training cost로 scale up하여, 다양한 task에 zero-shot로 사용 가능
2. Foundation model(CLIP)의 일반화 성능을 올린다.
Related Work
이 논문은 당연하듯 Masked Image Modeling(이하 MIM)에서 영감을 받았습니다. MIM은 아래 그림과 같이 진행됩니다.

Encoder 통과 전, random patch embedding을 제거하고 encoder를 통과 시킵니다(연산 효율적). 통과한 feature embedding에 mask token을 붙여, decoder를 통해 reconstruction하는 방법론입니다.
이를 통해, encoder는 masked된 부분을 살아남은 token을 보고 유추해야하므로 semantic한 정보에 대한 이해가 올라갑니다. 최종적으로 encoder의 성능을 강화시켜 다른 downstream task에 사용하기 위해 사용하는 방법입니다.
Method
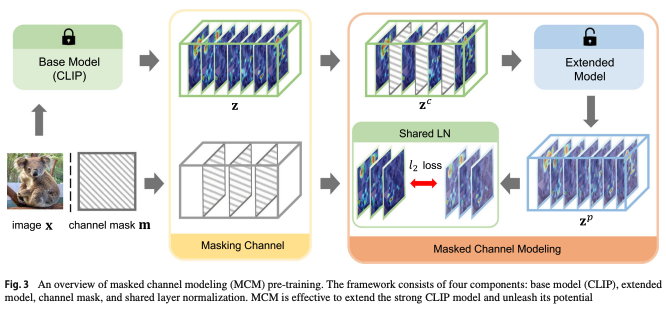
Extracing Visual Features
먼저 완전히 Freezed된 CLIP을 이용해, 이미지를 patch(feature) embedding으로 변환합니다.
x \in \mathbb{R}^{H \times W \times 3}의 image가
N = HW / P^{2}[/latex], visual feature z \in \mathbb{R}^{(N+1) \times C}로 변환되는 일반적인 과정입니다 (+1은 CLS token)
Masking Channel
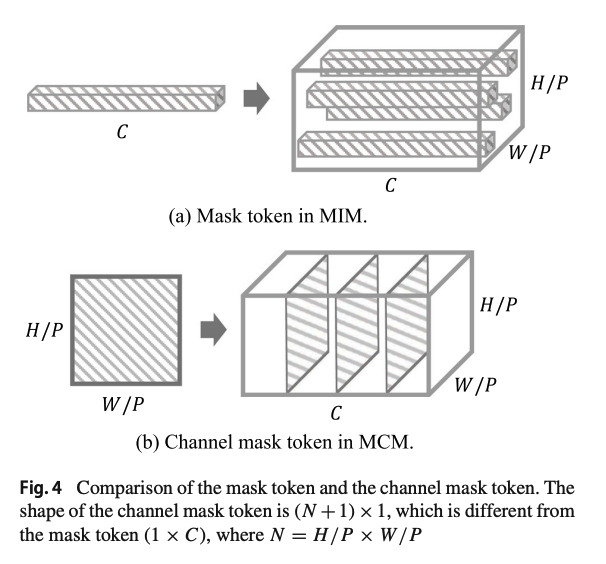
이제 MCM을 위해, patch embedding의 channel을 masking(50%)해줍니다.
(N+1) x C의 patch embedding의 C차원을 masking한 후에
learnable mask token인 (N+1) x 1로 채워넣습니다. 그리고 CLS token이 masked된 token에 대한 정보를 implicit하게 가지고 있기 때문에 CLS token도 제거합니다.
Masked Channel Modeling
그리고 저자는 이제 masked channel 복원 모델을 위한 extended model를 설계합니다. 이 extended model은 decoder와는 다릅니다. decoder는 학습이 끝나면 버려지지만, extended model은 끝까지 남아서 모델을 extend합니다.
저자는 이 extended model이 corrupted(masked)된 visual feature map을 받아서, channel간의 reasoning을 통해 원래의 channel 관계를 복원하는 역할이라고합니다.
그리고 이 extended model은 depth(layer)가 깊어질 수록 성능이 증가하는데, maximum extendable depth는 encoder의 수용력(inherent capability)에 따라 다르다고 합니다. 예를 들어, CLIP-ViT-L은 CLIP-ViT-B보다 더 복잡한 channel correlation을 담고 있기에, 더 깊은 extended model을 통해 복구해야 성능이 좋습니다.
Shared LayerNorm. MCM pre-training을 더 안정되게 학습하기 위해서, image feature z와 predicted image feature z^{p}를 normalize하는데 같은 encoder의 LayerNorm을 사용합니다.
즉, z는 원래 encoder를 통과한 값이므로 encoder의 마지막 LayerNorm을 당연히 통과하는데 반해, z^{p}는 extended model의 output이므로 자체의 LayerNorm을 통과해야하는데 이걸 encoder의 LayerNorm으로 바꿔주었습니다. 이를 통해 z^{p}에 latent representation space에 implicit constraint를 걸어주었다고 저자는 얘기합니다.
그리고 두 결과를 L2 loss를 이용하여 loss를 정의합니다.
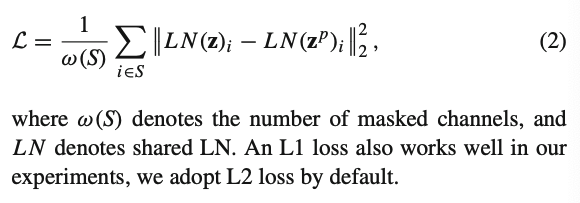
Experiment
학습은 ImageNet-1k를 이용해서 이루어졌습니다. 그리고 masking은 50%의 channel을 random하게 하였습니다.
Zero-shot Learning
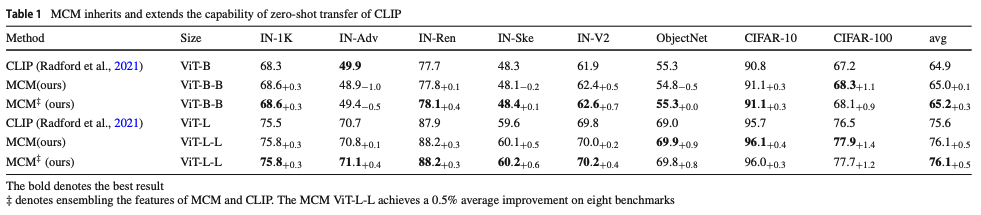
MCM은 CLIP의 zero-shot 성능을 그대로 유지했습니다. Masked Auto Encoding(Masked Image Modeling)은 최종적으로 pixel을 reconstruction하기 때문에, image-text space로 align시키지 않습니다.
Table1.을 보면, MCM을 적용한 방법이 기존 CLIP 대비 모든 dataset에서 성능이 소폭 상승했고, CLIP과 ensembling한 feature에서는 좀 더 큰 폭으로 상승했습니다.
저자는 성능이 오른 이유를 Masked Ianguage Modeling(이하 MLM)과 같이 설명합니다. MLM은 문장이 있을 때, 단어를 지움으로써 semantic한 정보를 가린 후, 다시 복원하게 하여 단어 사이에 semantic correlation을 강화하도록 합니다. MCM도 마찬가지로 Channel 사이의 semantic correlation을 학습하였기에 zero-shot 성능이 올랐다~라고 얘기를 합니다.
End-to-End Fine-Tuning
MCM pre-training method는 CLIP을 적은 training cost로도 효과적으로 성능을 높일 수 있다고 합니다. 이를 증명하기 위해 image classification task에서 다양한 다른 모델들과 비교 실험을 해보았습니다.
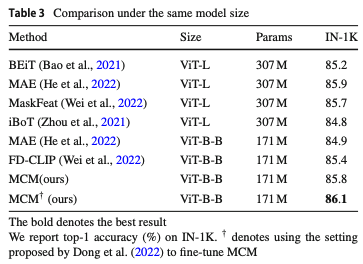
보면 MCM 방법론이 같은 ViT-B-B 방법론들의 성능을 이겼을 뿐더러, ViT-L를 사용한 방법론들 보다 더 성능이 좋은 것을 확인할 수 있습니다.
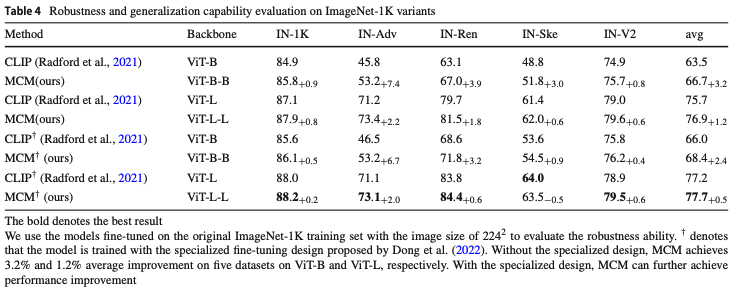
그리고 Table 4에서는 IN-1k의 변종 데이터셋 (Rendition, Adversarial, Skethch, …)에서도 일관되게 CLIP보다 좋은 성능을 보인다는 점에서 일반화 성능 역시 좋다는 것을 보이고 있습니다.
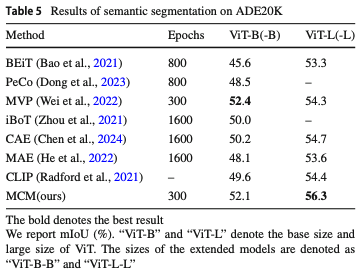
또한 image classification이 아닌 Semantic Segmentation에서도 비슷한 양상을 보입니다. ViT-B-B에서 다른 방법론들과 유사하거나 높은 성능을 보이고, ViT-L에서는 압도적인 성능 향상을 보입니다.
이를 통해, MCM이 여러 Downstream task의 일반적 성능을 높인다는 사실을 실험을 통해보였습니다.
Ablation Study
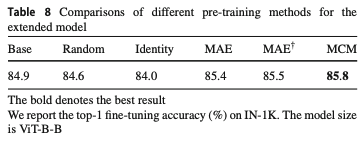
Table 8.는 Extended Model을 다양한 retraining 방식에 따른 성능 비교 입니다.
Base는 extend model이 없는 결과입니다.
Random은 extend model을 random initialize한 결과고,
identity는 masking이 없이 학습을 한 것 입니다.
그리고 MAE랑 MAE cross는 각각 pixel 복원과 feature 복원입니다.
위 방법론들과 비교해도 MCM이 제일 좋다는 걸 보였습니다.
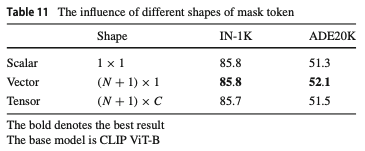
mask token(mask에 채워넣는 learnable 값)을 어떻게 설정하는지에 대한 ablation입니다
모든 channel을 하나의 값으로 채우는 Scalar와
patch마다 다른 값으로 채우는 Vector
그리고 channel과 patch마다 다른 값으로 채우는 tensor중에
Vector가 성능이 제일 좋았습니다.
Tensor같은 channel-wise mask token은 feature channel의 관계를 학습을 통해 어느정도 담을 것이기에 MCM의 effectiveness를 감소시킨다고 주장합니다.
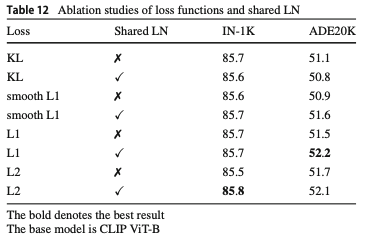
loss fn과 Shared LN에 따른 ablation입니다.
loss로는 KL, smooth L1, L1, L2를 실험해주었습니다.
성능적으로 L2가 가장 좋은 결과를 보였습니다.
그리고 shared LN을 썼을 때, L1/L2 계열에서는 약간의 향상이 있었지만, KL에서는 약간의 드랍이 있었습니다.
KL divergence는 대칭적이지 않은 두 분포 사이를 측정하려고 하기에, 분포를 같은 latent로 끌고 오려는 shared LN이랑 잘 맞지 않은 것 같다고 얘기합니다.
Visualization
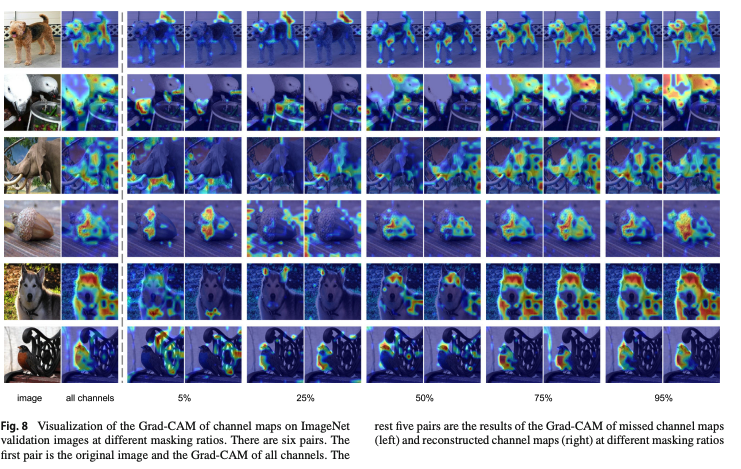
마지막으로 masking ratio에 따른 Grad-CAM 시각화를 보여줍니다.
masking ratio에 따라 MCM이 어떤 정보를 복원하고 있는지를 보여줍니다.
masking ratio가 낮을 때는 맨 위 강아지 사진을 보면, 꼬리와 같은 지엽적 정보에 집중하지만, ratio가 50%쯤 오면 다리들에 집중하는 것처럼 더 의미적인 정보에 집중하기 시작합니다. 그리고 ratio가 95까지 가면 강아지 전체를 복원하기 시작합니다.
요약해보면, channel을 아무리 많이 가려도 가려지지 않은 채널 속에 여전히 강아지의 꼬리 모양, 질감 같은 fragmentray semantics가 남아있기 때문에 extended model과 MCM을 통해 semantic한 정보를 다시 예측할 수 있음을 보여줍니다.
안녕하세요 정우님 좋은 글 감사합니다.
내려갔을때 설명해주신 내용을 이번 리뷰로 다뤄주셨네요.
궁금한점이 있는데
“identity는 masking이 없이 학습을 한 것 입니다. 그리고 MAE랑 MAE cross는 각각 pixel 복원과 feature 복원입니다. 위 방법론들과 비교해도 MCM이 제일 좋다는 걸 보였습니다.”
해당 부분에 대해서 몇가지 질문이 있습니다.
1. identitiy 가 masking 없이 학습한거라면 기존 성능과 오차가 매우 적어야한다고 생각했는데 떨어지는 경향성이 생기는 이유가 있나요?
2. MAE, MAE cross에 대해서 pixel과 feature 복원이라고 하셨는데, 저자의 방식이 feature 복원 아닌가요? 헷갈려서 질문드립니다. 그리고 pixel 복원이라면 channel값들까지 복원 후 다시 RGB의 실제 값으로 복원한다고 생각이 드는데 그러면 해당 과정에서 추가적으로 적용되어야 하는게 있나요?
감사합니다.
안녕하세요 인택님 좋은 질문 감사합니다.
1. identity가 masking 없이 원본을 그대로 보여줬기 때문에 저자는 “serious information leakage”가 일어나서 성능이 하락했다고 얘기를 합니다. CLIP의 잘 학습된 가중치가, 추가된 layer에서 무의미하게(목적성 없이) 섞였기에 성능이 하락했다고 생각합니다.
2. 맞습니다. 이 논문은 feature level의 복원입니다. 그러나 이 논문의 기저가 되는 MAE(Masked Image Modeling)은 pixel level reconstruction이 base입니다.
왜냐하면, 이 논문은 freezed CLIP의 결과를 GT 삼지만, MAE는 encoder 전체를 학습시키기 때문에 GT가 계속 바뀌어서 학습이 제대로 이루어지지 않습니다.
그렇기에 이 논문은 freezed CLIP이라는 명확한 GT가 있으니 MAE도 feature reconstruction으로 학습시켜보았고, MAE cross가 살짝(아주 살짝) 좋은것을 보였습니다.
그리고 pixel level reconstruction을 하려면 feature를 복구한다음 결국 마지막에 linear projection으로 다시 pixel 차원으로 펴주는 과정이 추가됩니다.
감사합니다.