안녕하세요. 이번에 들고온 논문은 한달전에 아카이브에 올라온 Less Is More: Scalable Visual Navigation from Limited Data라는 논문입니다. 간단하게 컨셉만 말씀드리고 넘어가면 무작정 많은 cross-embodiment 데이터를 섞는 방향보다는 타겟 로봇에 맞는 geometry-aware supervision을 어떻게 잘 추가할 것인가를 연구한 논문이라고 보시면 좋을 것 같습니다. 저자들은 이 정책을 LIMO라고 부르고 single RGB observation과 SE(2) goal을 받아서 local goal-conditioned waypoint trajectory를 예측하도록 설계합니다. 보통은 더 큰 백본, 더 큰 데이터, 더 다양한 embodiment 쪽으로 많이 가는데 이 논문은 오히려 expert data는 적어도 괜찮고 대신 그것을 planner-generated supervision으로 얼마나 잘 증폭시키는지가 중요하다고 이야기합니다. 논문 제목이 Less Is More인 이유도 이것때문인거 같습니다. 그럼 바로 리뷰 시작하도록 하겠습니다.
Introduction
기존에 리뷰했던 내비게이션 논문들과는 다르게 좀더 예전에는 전통적으로 geometric pipeline이 중심으로 내비게이션을 수행하도록 하는 연구를 했다고 합니다. 맵을 만들고, traversability를 추정하고, 그 위에서 planner가 path를 만들고, controller가 그것을 따라가는 식입니다. 이런 접근은 collision avoidance 관점에서는 유리하기는 하지만 저자들은 실제 open-world에서는 geometry만으로는 부족한 부분이 있다고 합니다. 예를 들어 덤불나 좀 큰 잔디는 실제로는 통과 가능한 친구들인데 기존 geometric한 접근은 무시하고 통과해도 되는 것들을 rigid obstacle처럼 볼 수 있고 반대로 물웅동이처럼 geometry만 봐서는 괜찮아 보이지만 실제로는 지나가기엔 위험할 수 있습니다. 단순히 가로 막혀있는지 아닌지가 아니라, 어떤 경로가 로봇 입장에서 더 자연스럽고 안전한지 이런 semantic한 정보를 이해하는데 한계가 있다고 저자들은 주장합니다.
그래서 최근에는 RGB image로부터 바로 navigation behavior를 배우는 imitation learning 기반 visual navigation 방법론이 많이 제안이 되었는데 ViNT, NoMaD, FlowNav 같은 계열이 대표적이라고 볼 수 있고 이런 방법들은 다양한 embodiment 데이터를 섞어서 foundation navigation model 쪽으로 스케일을 키우는 식으로 연구가 되었습니다. 근데 자율주행 데이터처럼 쉽고 수많은 데이터를 모을 수 있는 분야와는 다르게 일반적인 mobile robot navigation에서는 고품질의 expert demonstration을 그렇ㅎ게 많이 모으기가 어렵다고 합니다. visual navigation의 성능은 모델 크기만이 아니라 어떤 데이터가 들어가는지도 중요한데 mobile robt navigation에서는 그 데이터가 희소하고 비쌉니다.
위와 같은 관점에서 저자들은 현재의 visual navigation 모델이 직면할 수 있는 다섯 가지 한계를 제시합니다.
- 내비게이션 성능이 비용이 많이 드는 실제 환경의 expert demonstration 데이터에 의존한다는 점
- 기존 데이터셋에서 행동 다양성이 제한적이어서 내비게이션이 단순하고 보수적인 움직임으로 편향된다는 점
- 모델이 기하학적 장애물 회피를 전적으로 시연 데이터만으로 학습해야 한다는 점
- 서로 다른 embodiment의 데이터를 함께 학습한 현재 모델들은 특정 embodiment에 바람직한 행동을 선택하지 못한다는 점
- 그리고 학습이 종종 도달 가능한 목표(feasible goals)에만 집중된다는 점
결국 저자은 기존 Imitation learning 프레임워크를 기반으로 하면서도 embodiment에 맞는 semantic한 이해와 강인한 내비게이션 행동을 할 수 있도록 내비게이션 정책을 어떻게 효율적으로 학습할 수 있을까? 라는 질문을 던지고 이를 위해 저자들은 LIMO를 제안합니다.
LIMO는 single RGB image와 robot-centric SE(2) goal을 입력으로 받아 waypoints를 예측하는 policy인데 학습 데이터는 두 종류를 섞습니다. 하나는 human teleoperation(GrandTour dataset)에서 추출한 teleop dataset이고 다른 하나는 해당 데이터 셋에서 random goal sampling과 planner-generated path를 통해서 추가로 만든 geometric dataset입니다. 여기서 사람 demonstration은 semantic preference(잔디지만 지나갈 수 있음)를 전달하고 planner를 기반으로 추가로 만든 geometric dataset은 scalable한 geometric supervision을 주는 구조라고 이해하시면 좋을 것 같습니다.
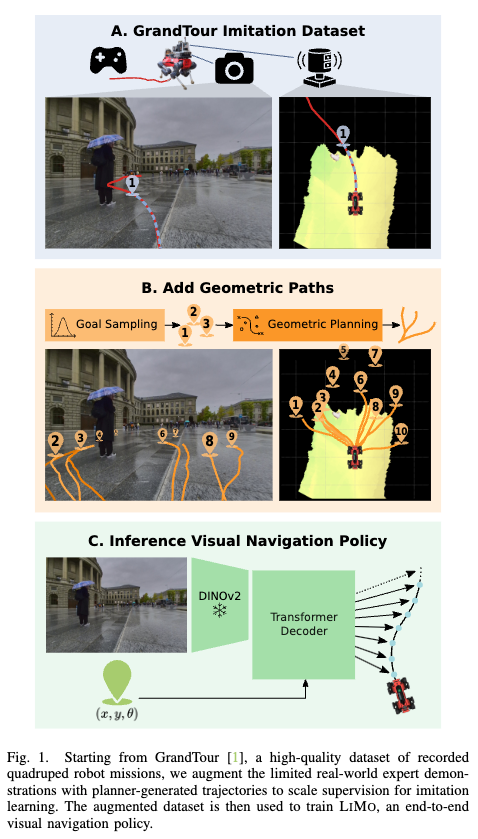
Figure 1이 논문 전체를 압축 요약한 그림인 것 같습니다. 위쪽은 GrandTour라는 실제 4족보행 robot을 인간이teleop 하면서 수집한 dataset이고 가운데는 이 데이터 셋에서 기존 플래너를 가지고 random goal sampling과 geometric planning을 추가해 geometric한 이해를 학습 할 수 있는 supervision을 늘리는 단계이고 아래는 이렇게 만든 데이터로 DINOv2 기반 visual navigation policy를 학습하는 과정이라고 보시면 좋을 것 같습니다. GrandTour dataset에서 시작해서 geometric path를 따로 생성해서 추가하고 최종적으로 visual navigation policy를 학습하는게 전체 파이프라인이라고 보시면 좋을 것 같습니다.
Method
이 논문의 방법론을 크게 2단계로 나누면 첫 번째는 MPPI 기반 geometric planner를 이용해 추가 trajectory를 생성하는 data curation 두 번째는 single RGB와 goal pose를 입력으로 받는 LIMO policy architecture를 기반으로 teleop data와 geometric data를 합쳐서 imitation learning으로 학습하는 전체 파이프라인인 것 같습니다.
Data curation
먼저 geometric supervision을 만들기 위해 저자들은 MPPI planner를 사용했다고 합니다. MPPI는 gradient-free optimization 방식으로 command velocity sequence를 샘플링하고 cost가 낮은 trajectory 쪽으로 분포를 업데이트하는 planner라고 합니다. MPPI는 현재 로봇의 pose 정보, goal pose, 그리고 기하학적인 정보(elevation map)를 바탕으로 내부에 있는 동역학 모델을 거쳐서 최종적으로 action sequence랑 이걸로 얻어지는 planned path를 내뱉는 친구라고 이해하시면 좋을 것 같습니다. 좀더 자세하게 설명드리면 주어진 elevation map(높이 맵)으로부터 CNN 기반 traversability map(주행 가능한지 나타내는 맵)을 만들고, 로봇 footprint가 지나가는 grid cell들의 cost를 합산하는 방식으로 goal 까지 최적의 경로를 구하는 알고리즘이라고 이해하시면 좋을 것 같습니다. (MPPI planner는 정확한 elevation mapping으로부터 얻은 privileged information을 활용하기 때문에 기하학적으로 실행 가능한 경로를 안정적으로 생성한다고함)자세한 내용은 Aggressive driving with model predictive path integral control이라는 논문을 참고하시면 좋을 것 같습니다.
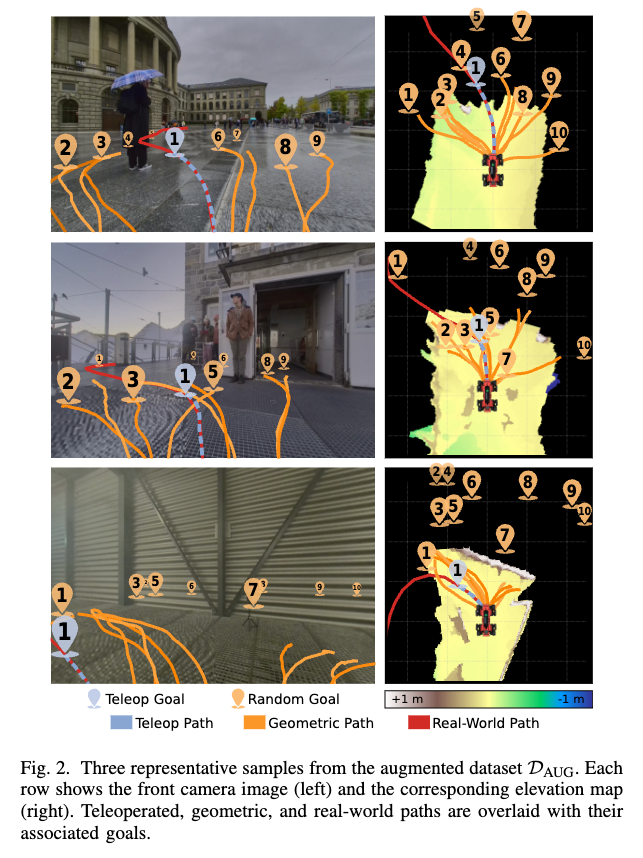
이제 데이터셋을 어떻게 만드는지를 보면 먼저 D_{TEL}은 기존 teleoperation trajectory에서 추출한 길이가 고정되어있는 샘플들로 구성합니다. 이 데이터는 semantic preference와 실제 그 4족보행 로봇의 움직임 특성을 정책이 학습하습할 수 있게끔하 친구라고 볼 수 있습니다. 사람이 직접 조작했기 때문에 이런 장면에서는 이렇게 가는 것이 자연스럽다라는 것을 담고 있는 데이터라고 이해하시면 됩니다. 그리고 D_{GEO}는 훨씬 scale이 큰데, 각 camera frame마다 robot-centric 좌표계에서 랜덤 goal을 여러 개 샘플링(K개 샘플링 K개의 geometric path가 생기는 것)하고, 여기에 대해 MPPI planner가 path를 생성하는식으로 데이터 규모를 늘립니다. 그리고 저자들은 여기서 샘플링된 goal이 꼭 feasible할 필요가 없다는 점을 강조하는데 figure2의 제일 마지막 부분을 보시면 infeasible한 goal이어도 planner는 goal 쪽으로 진전할 수 있는 다른 경로를 만들어 내거나 장애물에 일단 안부딪힐 수 있는 안전한 행동을 만들어낸다고 합니다.
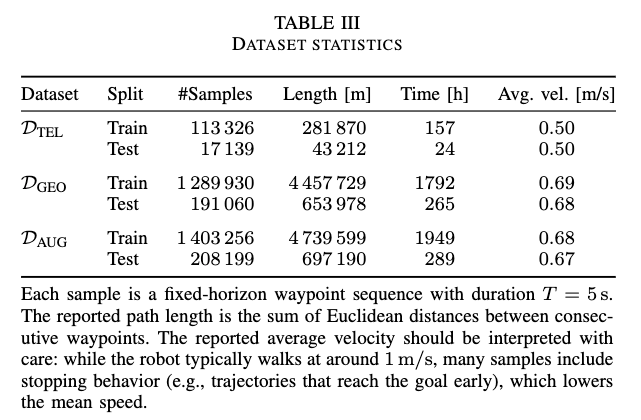
논문에서 사용한 데이터 셋인 GrandTour human expert data는 실제로는 6시간 규모인데, planner-generated geometric supervision을 붙이면서 D_{GEO}는 1792시간 최종 D_{AUG}는 1949시간 수준까지 규모를 늘렸고 샘플 수도 140만 개 이상으로 늘린 것을 볼 수 있습니다.
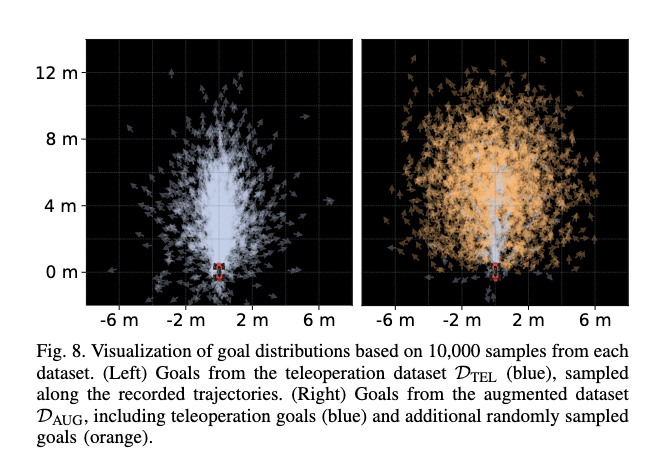
그리고 goal 분포도 D_{GEO}은 원래 teleop trajectory를 따라가는 goal 위주라 상대적으로 경로가 편향된 반면 D_{AUG}는 random goal sampling이 포함되면서 훨씬 더 넓고 diverse한 goal distribution을 갖게 된다고 합니다.
Policy Architecture
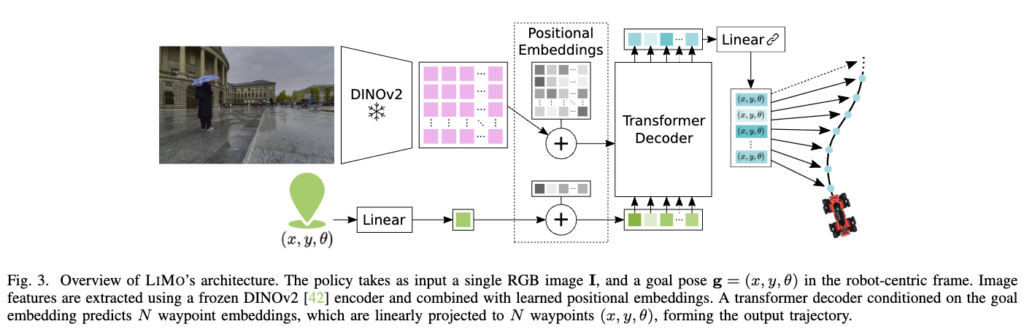
이제 LIMO architecture를 보면 입력은 single RGB image와 robot-centric goal pose g = [x, y, θ] 로 들어가게 됩니다. 여기선 기존 방법론들과는 다르게 temporal 한 정보를 사용하지 않고 single RGB 이미지만을 사용했는지는 따로 언급하지는 않았습니다. 다만 future work에서 추후에 temporal한 정보를 사용하면 더 좋은 결과를 보일 수 있다고는 언급합니다. 여기서 image는 frozen DINOv2 encoder를 통해 patch embedding으로 만들고 goal pose는 같은 embedding dimension으로 projection된 뒤 N개의 waypoint query로 복제 시킵니다. 이후 positional embedding이 추가된 waypoint query가 transformer decoder로 들어가고, image feature가 key/value 역할을 하게되고 최종적으로 N개의 waypoint embedding이 나옵니다. 이것들을 linear layer로 projection해서 최종 SE(2) trajectory를 예측하는 구조로 설계되다고 보시면 좋을 것 같습니다그리고 모델은 waypoint는 50개를 예측하고 horizon은 5초라고 보시면 좋을 것 같습니다.(5초동안의 경로를 50개의 waypoint로 예측하는 것으로 보시면 좋을 것 같습니다.
Experiments
저자들은 평가를 위한 4가지 질문을 던집니다.
(Q1) 다양한 geometric demonstration이 실제로 내비게이션 성능 향상에 효과적인가?
(Q2) LIMO는 보지 못한 새로운 환경에도 일반화할 수 있는가?
(Q3) 제안한 방법은 embodiment-specific한 내비게이션을 가능하게 하는가?
(Q4) LIMO는 실제 로봇에 배치되었을 때도 동작하는가?
실험도 마찬가지로 GrandTour dataset에서 따로 빼둔 테스트 셋에서 평가합니다. GrandTour를 앞서 빈약하게 언급했는데 여기서 좀더 자세하게 설명하면 해당데이터셋은 ANYmal D(로봇개)가 스위스의 49개 site에서 다양한 weather와 lighting condition 아래 수집한 6시간짜리 deployment 데이터입니다. metric은 geodesic distance 기반 success와 SPL을 사용합니다. goal에 1m 이내 도달했고 collision이 없으면 success로 하고 SPL은 goal-reaching 뿐 아니라 path efficiency(멀쩡한 길 냅두고 돌아가진 않았는지)까지 함께 보는 지표라고 보시면 좋을 것 같습니다.

Fig. 4에서 저자들은 LIMO가 예측한 경로를 이미지 상에 그린건데 (a, b, e, f, g, i, j, k) 좌측 9개를 보면LIMO는 문이 열려 있는 위치를 식별하고 바퀴로봇은 못하고 로봇개만이 할 수 있는 계단을 올라가거나 내려갈 경로를 계획(embodiment-specific navigation이 가능함(Q3))하면서 거친 자연 환경에서도 주행할 수 있는 경로를 보입니다.
세 번째 열의 비교 (c, g, k)에서는 D_{AUG}로 학습된 정책은 D_{TEL}만으로 학습된 baseline보다 훨씬 더 geometry-aware하고 장애물 회피 능력이 뛰어난 경로를 생성함을 보여주는 모습을 보이고 결국 geometric demonstration을 포함했을 때의 이점을 보여준다고 저자들은 주장합니다(Q1). 그리고 이 모델은 held-out mission(학습에는 쓰지 않고, 평가할 때만 따로 남겨둔 mission)들에서도 안정적인 trajectory를 계획하는 모습을 보이는데 마찬가지로 저자들은 보지 못한 새로운 환경에 대한 일반화 능력(Q2)을 보여주는 결과라고 합니다.
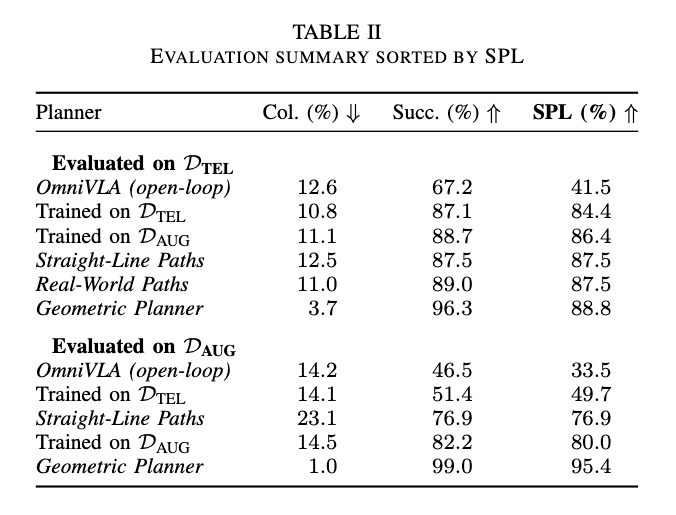
먼저 D_{TEL} 분포에서 평가할 때는 Trained on D_{AUG}이랑 Trained on D_{TEL}의 차이가 크지는 않은 결과를 보입니다. 오히려 Straight-Line Paths(로봇에서 goal까지 직선으로 향하는 경로)가 더 좋은 성능을 보이는 것을 확인할 수 있는데, 결국 이것의 의미는 D_{TEL} split 자체는 대부분 goal이 거의 straight ahead에 있고 obstacle도 상대적으로 적어서 어려운 문제는 아니기 때문에 보이는 결과라고 합니다. 그래서 이런 분포에서는 geometric augmentation의 이득이 크게 안 보인다고 합니다.
근데 D_{AUG} split에서는 Trained on D_{TEL}과 Trained on D_{AUG}가 거의 30%정도의 차이를 보입니다. 이 결과는 결국 다양하고 장애물이 많은상황의 goal distribution에서는 teleop demonstration만으로는 부족하고, planner-generated geometric data가 엄청 중요하다는 것을 보여준다라고 저자들은 주장합니다. 또 OmniVLA의 부진에 대해서는 원래 closed-loop replanning을 전제로 학습되었다는 점이랑wheel-dominated cross-embodiment data에 강하게 편향되어 있다는 점을 고려했을 때 이런걸 고려한 평가 프로토콜을 설계한게 아니니깐 공정한 비교는 아닐 수 있다라고는 언급합니다.
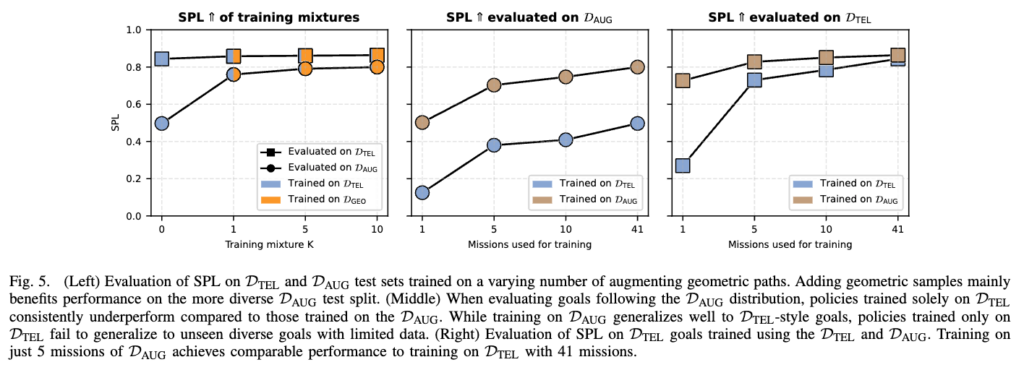
Figure 5에서 왼쪽 그래프는 frame당 추가 geometric path 수 K를 늘렸을 때의 SPL 변화를 보여주는 그래프입니다. geometric sample을 넣는 효과는 D_{TEL}보다 D_{AUG} evaluation에서 더 크게 나타나는 모습을 보이는데 단순한 goal 분포에서는 큰 차이가 안 나지만 다양한 goal과 복잡한 scene으로 갈수록 geomteric planner supervision가 중요하다라는 것을 보여주는 것 같습니다.
가운데와 오른쪽 그래프를 보면 D_{AUG}로 학습한 정책은 D_{TEL} goal에서도 좋은 성능을 보이는데 반대로 D_{TEL}만으로 학습한 정책은 D_{AUG} goal distribution에서는 안좋은 성능을 보이는 것을 확인할 수 있습니다. 그리고 또 D_{AUG} 5개 mission으로 학습한 모델이 D_{TEL} 41개 mission으로 학습한 모델과 비슷한 D_{TEL} 성능을 보입니다.
Real-Robot Deployment
저자들은 LIMO를 ANYmal D에 올려서 unseen location에서 closed-loop로 실행하고, Jetson Orin onboard에서 6 Hz로 동작시켰다고 합니다. 또 저자들은 정적 장애물뿐 아니라 동적 장애물, 좁은 복도 이동 3가지 경우에 대해서 정량적 평가를 진행합니다.


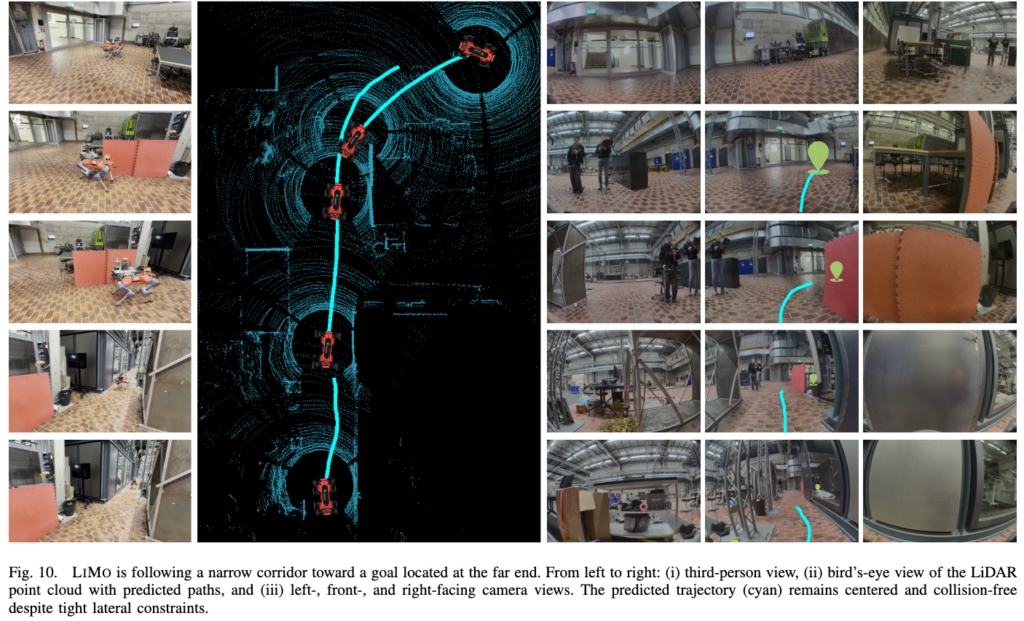
정적 장애물 환경에서 잘 동작하는 모습을 보이고 동적 장애물 실험에서는 사람이 큰 매트를 들고 로봇의 원래 path를 막아버리는데, LIMO가 6 Hz로 계속 replanning하면서 다른 경로를 찾는 모습을 보였다고 합니다. 그리고 그림의 우측에 보여지는 이미지가 3개인데 저자들은 실제 robot deployment에서는 front camera만 쓰면 collision이 발생해서, left/right side camera를 추가한 multi-camera variant를 사용했다고 합니다. 이유는 간단합니다. single front view만 사용하면 obstacle이 forward field of view 밖으로 벗어난 순간 policy가 그걸 잘 인지하지 못한다고 합니다. 심지어 해당 모델은 단일 프레임 이미지만 사용하기 때문에 더욱 보이지 않는 장애물에 취약할 수 있습니다.
Conclusion
저자들은 몇가지 중요한 한계를 언급하는데 일단 저자들이 생성한 geometric supervision 자체가 elevation map과 traversability estimation에 의존하기 때문에 planner label이 cliff edge 같은 edge case에서는 잘못된 label이 들어갈 수 있는 문제가 있다고 합니다. 그리고 LIMO는 single RGB frame 기반이라 temporal memory가 없어서 occlusion이나 longer-horizon reasoning에서 취약한 모습을 보이고, 그리고 supervision scale은 키울 수 있어도 visual diversity는 결국 원본 dataset scene에 묶여있다는 점을 언급합니다. 최근에는 데이터를 많이 섞고 embodiment도 많이 섞는 것이 일반화 측면에서 유리하다라고 하는데 해당 논문은 오히려 그렇게 되면 예를 들어 사족 보행로봇이 원래 할 수 있는 계단오르기 같은 것들이 바퀴 기반 데이터에 묻히게 된다는 문제점을 말하는데 어떤게 정답인지는 잘 모르겠습니다. 그래도 이 논문을 읽기 전까지는 무조건 다양하고 많은 데이터 셋이 유리하다라고 생각했었는데 해당 논문을 읽고나니깐 local planning은 생각보다 robot specific한 문제일 수 있어서 무조건 embodiment-agnostic한 foundation model이 답은 아닐 수도 있겠다는 생각이 들었습니다. 이만 리뷰 마치도록 하겠습니다.
리뷰 잘 읽었습니다. 리뷰해주신 논문은 새로운 navigation architecture라기보다는, 좋은 geometric supervision을 cheap하게 만들고, 그것을 semantic teleop data와 잘 섞는 방식에 더 가까운 것처럼 이해했습니다. 몇 가지 궁금한 점이 있어 남겨두겠습니다.
1. MPPI planner가 elevation map과 traversability map을 기반으로 경로를 생성한다고 하셨는데, 이 traversability map은 실제 로봇에서 미리 계산된 맵을 사용하는 건가요? 아니면 비디오 데이터에서 추정된 정보를 사용하는 건가요?
2. LIMO가 single RGB frame만을 입력으로 사용한다고 하셨는데, 혹시 논문에서 다른 프레임 정보를 사용하지 않는 이유나 장점에 대해 추가로 설명한 부분이 있었는지도 궁금합니다.