Video Large Language Models(Video-LMMs)는 시공간 토큰(spatiotemporal tokens)을 활용해서 강력한 비디오 이해 능력을 가지게 되었지만 토큰 개수가 많아질수록 연산량이 2차적으로 증가한다는 문제점을 가지고 있었습니다. 이에 저자들은 시간, 공간적으로 redunduncy를 갖는 토큰을 합치는(merge) training-free token merging 방법론인 STTM을 소개합니다.
Introduction
LLM에 video understanding 능력을 결합한 Video LLM은 본질적인 연산량 문제를 겪고 있는데, 시공간 정보가 담긴 수많은 시각 토큰을 처리하기 어렵기 때문입니다. 특히 LLM의 context length는 한정되어 있기 때문에, 비디오의 duration이 길어질수록 증가하는 토큰 수에 대응하기 위해서는 redundunt한 토큰을 합치는 token merging이 필수적입니다. token merging에는 크게 두 가지 방법이 소개되는데, 쿼리 기반으로 토큰을 압축하는 query-aware와, 쿼리 상관없이 전체 비디오 토큰을 대상으로 토큰을 압축하는 query-agnostic이 있습니다. 저자들은 latency를 기준으로 query-agnostic한 방법론을 선택합니다.
긴 지연시간은 video-LLMs을 실제 서비스로 배포하는 데 있어 여전히 핵심적인 bottleneck으로 남아 있습니다. 질문 답변 전, video context 전체를 처리하여 key-value 상태(KV state)를 미리 채워놓아야 하기 때문인데, 실제로 Gemini같은 LLM은 키밸류 상태를 캐싱해서 연산을 다시 하는 것을 방지하고, 같은 비디오에 관한 멀티 턴 대화를 효율적으로 지원합니다. 하지만 현존 training-free 토큰 압축 방법론들은 query-aware strategies, 즉 쿼리와 관련된 토큰들만 압축시키려고 하기 때문에 쿼리를 입력할 때마다 KV state를 계산하고 output을 산출해서 멀티 턴 대화에 취약합니다. 따라서 멀티 턴 대화를 지원하기 위해서는, 쿼리가 아니라 전체 비디오 토큰에 대하여 KV state를 딱 한 번 계산하고 캐싱하는 query-agnostic 토큰 압축이 필수적입니다. 이에 저자들은 비디오 시공간적인 구조를 살려 redundunt한 토큰들을 압축하는 STTM(spatio-temporal token merging)을 제안합니다. 자세한 메커니즘은 Methods에서 다뤄보도록 하겠습니다.
Prerequisite
제 기준으로 알고 있어야 도움이 되는 지식들이 몇 가지 있어서.. related work와 엮어서 정리해보았습니다. 비디오 데이터는 본질적으로 시공간적 중복성(spatiotemporal redunduncy)이 매우 높습니다. 이를 위해 저자들은 비디오 압축(video compression) 기술에서 두 가지 모티브를 차용하여 token reduction 방법론을 설계했습니다. 첫 번째는 공간적 압축을 위한 QuadTree 분할입니다. 기존 비디오 코덱이 화면 영역의 복잡도에 따라 블록의 해상도를 다르게 할당하는 것에 착안하여, STTM에서는 단순 배경은 큰 해상도의 토큰 하나로 묶고, fine한 객체 영역은 작은 토큰들로 남겨두는 multi-granular(여러 해상도의 토큰들으로 표현)한 spatial merging 방식을 도입했습니다.
두 번째 모티브는 시간적 압축에 차용한 Skip Mode입니다. 이전 프레임과 아예 똑같다면, 데이터 저장 없이 “이전 꺼 그대로 써”라는 신호만 보내는 코덱의 원리를 사용해서, STTM에서는 이전 프레임과 공간적으로 겹치면서 정보까지 유사한 토큰들은 시간적으로 앞선 대표 토큰 하나에 과감히 흡수시키는 merge 전략을 설계했습니다.
Quadtree

기존 video compression에서는, Quadtree라는 자료구조를 사용해서 복잡한 영역(머리카락, 텍스트 등)은 잘게 쪼개고, 단순한 영역(하늘, 벽)은 크게 쪼갭니다. 정사각형을 4개의 작은 정사각형은 재귀적으로 분할하는 방식으로 자세한 분할법은 아래와 같습니다.
- 전체 이미지/큰 블록 하나를 하나의 노드로 보고, 2×2의 자식 노드 4개로 쪼갠다
- 부모 노드 ↔ 각 자식 노드 비교 : 현재 블록 내의 픽셀 값들의 유사도 계산
- 분산이나 MSE 활용
- STTM에서는 토큰 간 코사인 유사도로 대체
- Branch 결정
- 분산이 threshold보다 낮으면, 더 이상 나누지 않고 leaf node로 확정(no split). 이 큰 블록은 하나의 대표값이나 적은 비트로 압축됨
- 분산 높으면 최소 크기에 도달할 때까지 split 계속
RoPE(Rotary Position Embedding)
기존의 일반적인 Sinusoidal PE가 단순히 고정된 사인/코사인 값을 토큰 벡터에 더해서 절대적인 위치를 알려준다면, RoPE는 토큰 벡터 자체를 위치 인덱스에 비례해 일정 각도만큼 ‘회전’시킴으로써 토큰 간의 상대적인 거리(Relative position)를 훨씬 자연스럽게 모델링하는 기법입니다.
Methods
STTM은 시간, 공간 축을 모두 고려해서 비디오 토큰을 합쳐 다양한 해상도의(multi-granular) 비디오 토큰을 생성하는 방법론으로, training-free이며 해당 모듈을 LLM의 중간 단계 layer에 플러그인 형태로 쉽게 끼워 넣을 수 있습니다. transformer의 초기 레이어 하나에 삽입되어 single pass로 수행되며, query-agnostic한 방법이기 때문에 KV cache 재사용 측면에서 강점이 있다고 합니다.
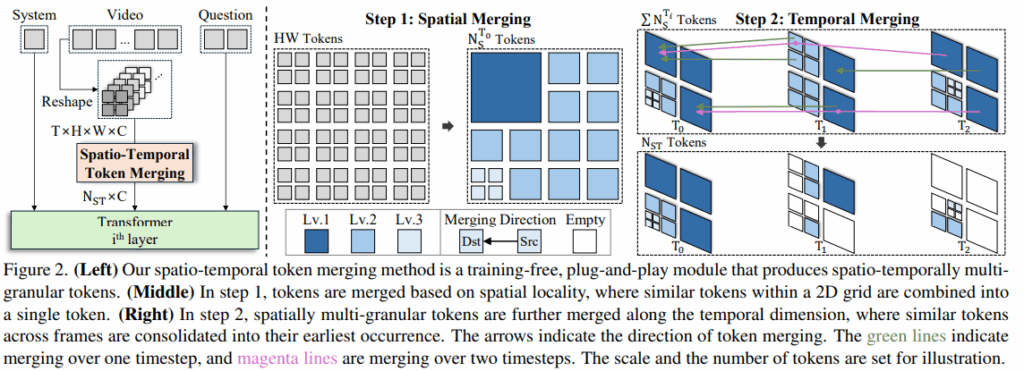
STTM 모듈은 LLM의 초반부 i번째 layer로 이어지기 전 단계에 적용됩니다. LLM 내부에서 동작하기 때문에, 토큰들은 현재 1D sequence의 형태입니다. 먼저 이 1D sequence를 reshape해서 T \times H \times W \times C 크기로 변환합니다. 쉽게 말하면 ‘feature map의 sequence’처럼 변환한다고 보시면 되겠습니다. STTM의 최종 목표는 이를 더 작은 크기의 N_{ST} \times C (N_{ST} \ll T \times H \times W) 차원으로 변환하는 것입니다.
Spatial Token Merging
다음 단계는 공간적 토큰 병합(Spatial Token Merging)입니다. 이는 2D 공간의 지역성(Spatial locality)을 활용하여, 각 프레임 내에서 비슷한 토큰들을 묶어주는 단계입니다. 결과적으로 정보 변화가 적은 배경은 큼직한 토큰(Coarse-grained) 하나로 압축되고, 객체의 경계처럼 정보 변화가 큰 영역은 작은 토큰(Fine-grained)으로 남아 디테일을 보존하게 됩니다. (Fig 3 참조) 이 과정은 Quadtree 자료구조를 통해 이루어집니다.
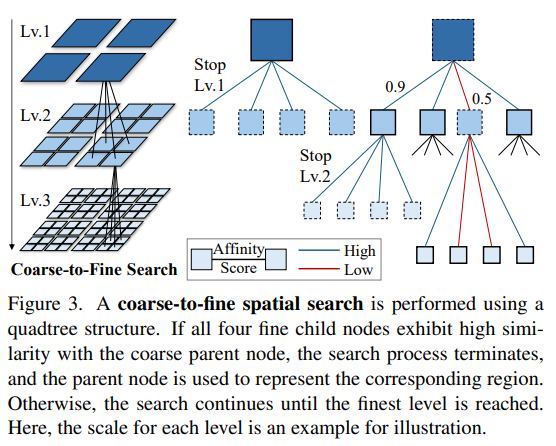
먼저 Bottom-up으로 쿼드트리를 세팅합니다. 초기 프레임 피처맵(예: 24×24 토큰)을 가장 세밀한 끝단인 리프 노드(Leaf node)로 둡니다. 그리고 2×2 단위로 토큰을 average pooling하며 부모 노드를 만들면서 위로 쌓아나갑니다. 전체 프레임 기준 2×2크기의 root node(Lv.1)이 될 때까지 트리의 특징값들을 미리 계산해 둡니다.
이후 Top-down으로 병합 단계(coarse-to-fine search) 단계가 이어집니다. 최상단인 Lv.1부터 시작하여, 각 부모 노드와 그 아래 4개의 자식 노드(Lv.2) 간의 코사인 유사도를 구합니다. 만약 4개의 자식 노드가 모두 부모 노드와의 유사도가 임계값(tau_S)보다 높다면, 해당 영역은 단순한 배경으로 판단하여 **하나의 부모 노드로 병합(Merge)**합니다. 반대로 자식 노드 중 하나라도 유사도가 \tau_S보다 낮다면, 복잡한 영역으로 판단하여 병합을 포기하고, 그 아래 레벨의 자식 노드들로 내려가 다시 유사도 비교 과정을 반복합니다. 이 탐색은 반복적으로 진행되며 최초에 설정한 24×24 낱개 토큰 단위(Leaf node)에 도달할 때까지 진행됩니다. 마지막으로, 실제 quadtree search는 각 트리 레벨에서의 탐색은 병렬 연산으로 구현되었기 때문에 실제 running time은 linear하게 유지됩니다.
Temporal Token Merging
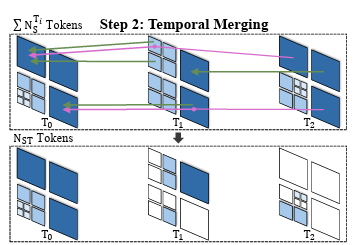
다음 단계는 Temporal Token Merging으로, 프레임 간의 중복을 제거하여 비디오 토큰을 꾹꾹 눌러담는 과정입니다. 이로 인해 움직이 없는 배경이나 정지해 있는 객체들이 주요 타켓이 됩니다.
이 과정은 연속된 두 프레임을 나란히 두고 시작합니다. 공간적으로 동일한 위치에 있는 토큰들 간의 코사인 유사도를 계산하는데, 이때 앞선 spatial merging으로 인해 프레임마다 토큰의 크기가 제각각이더라도 시공간적으로 겹치는 영역이 있다면 모두 비교 대상이 됩니다. 예를 들어, T_0과 T_1을 놓고 봤을 때, T_0 좌상단의 커다란 배경 토큰 하나가 T_1 프레임 좌상단의 작게 쪼개진 4개의 토큰과 겹친다면, 이들 각각의 유사도를 모두 평가하는 방식입니다.
유사도가 사전에 설정한 임계값(\tau_T)을 넘으면 시간적 변화가 없다고 판단하여 병합을 진행합니다. STTM은 이를 방향 그래프로 모델링하여, 미래 토큰이 과거 토큰을 향하도록 연결합니다. 이 그래프를 전체 프레임 시퀀스로 확장해서 공통 루트 노드를 찾고, 방향 그래프로 연결된 ‘중복된’ 정보는 가장 처음 등장했던 이 공통 루트 노드에 모두 흡수시킵니다(by average pooling).
T_1,T_2 좌상단 토큰의 예시처럼, 현재 프레임(T_2)의 토큰이 과거의 4개 자식 노드와 겹치면서 모두 임계값을 넘는 경우 어디로 병합해야할지 모호해지는 케이스가 생길 수 있습니다. STTM은 이때 연산의 정확도보다는 GPU 병렬 처리 효율성을 위해 무조건 ‘좌상단’ 토큰으로 병합하는 heuristic을 적용했습니다. 이를 통해 temporal merging 역시 전체 비디오 기준 O(THW)라는 선형적인 연산 복잡도만을 가지며 모델의 실행 속도에 거의 영향을 주지 않게 됩니다. 이렇게 Spatio-temporal merging을 완료하면, 시공간적 중복성은 줄인 압축된 토큰들만 남게 되며, 시각화 결과는 다음과 같습니다.

Token Reordering After Merging
이제 병합된 토큰들은 다시 1D Sequence로 변환하여 LLM의 다음 transformer layer로 전달해주어야 합니다. 그래서 linearization을 거치게 됩니다. STTM은 두 가지 기준을 두고 토큰을 정렬하는데,
- 시간적으로 앞선 프레임(과거 프레임)을 우선적으로 배치한다.
- 프레임 내에서는, 각 토큰이 위치한 좌상단 토큰부터 Z자 형태로 스캔하며 순서를 매긴다.
이렇게 flatten만 하게 되면 토큰들이 원래 가지고 있던 위치 정보가 섞이기 때문에, 최신 LLM이 사용하는 RoPE(Rotary Positional Embedding)을 사용해서 위치 정보를 인코딩합니다. 저자들은 RoPE 적용을 위해 세 가지 전략을 제안합니다.
- Merged RoPE : 병합된 여러 토큰들이 가지고 있던 원래의 위치 값들을 하나로 평균 내어 사용
- Survived RoPE : 병합 과정에서 살아남은 토큰의 원래 위치 값을 그대로 유지
- Reassigned RoPE: 새롭게 정렬된 순서에 맞춰 위치 ID를 1부터 새로 부여하는 방식

위 table은 각 전략을 적용했을 때에 대해, token merging 전후의 결과를 상대값을 나타낸 표입니다. Reassigned RoPE가 성능이 가장 높은 것으로 보아 토큰 병합과정에서 여러 위치 정보가 누락되기 때문에, 깔끔하게 새로 위치 저옵를 부여하는 것이 더 안정적임을 시사합니다.
Experiments
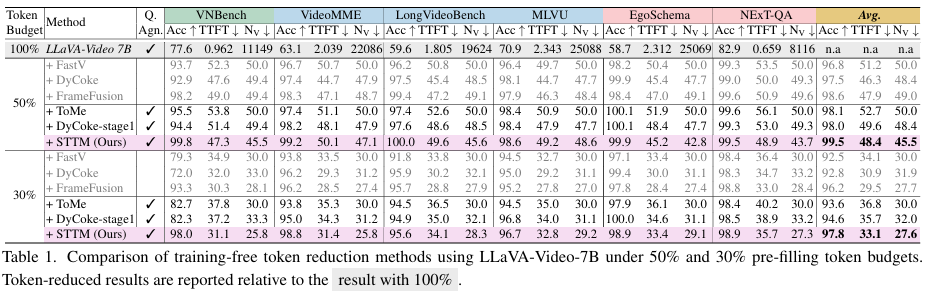
위 실험 결과는 LLaVA-Video-7B 모델에 STTM 모듈을 적용한 메인 실험 결과로, 모델에 token merging을 적용한 전후의 결과를 상댓값으로 나타낸 table입니다. 표 읽으실 때의 참고사항을 아래와 같습니다. (Token Budget은 기존보다 얼마나 토큰 개수를 사용했지를 나타내는데, spatial/temporal threshold를 바꿔가며 조절 가능)
Datasets
- Short form : Egoschema, NExT-QA
- Long : VideoMME, LongVideoBench, MLVU
- Needle in a haystack(중요 프레임 찾기 문제): VNBench
Eval Metrics
- acc on MCQs
- TTFT (Time To First Token): latency 확인, “추론 속도”
- N_v : Num of Visual Tokens
- R. (Relative Values) : 원본 대비 몇 % 수준인가
전체적으로, 토큰을 절반, 또는 30%만 남겨도 정확도 하락이 단 0.5% 언저리에 불과한 모습을 보입니다. 특히 디테일이 중요한 Needle in a Haystack 테스크를 다루는 VNBench에서도 성능 하락 폭이 적기 때문에, STTM이 시공간적 디테일도 잘 보존한다는 것을 보여줍니다. 결론적으로 STTM은 연산 속도(TTFT) 면에서는 다른 경량화 기법들만큼 충분히 빠르면서도, 시공간 디테일을 파괴하지 않아 성능 하락을 0~2%대로 막아내는 엄청난 가성비를 자랑합니다.
Conclusion
이 논문은 Video LLM 분야에서 training-free로 multi-granualr한 비디오 토큰 병합을 시도한 최초의 연구라는 점에서 contribution을 가집니다. 6개의 video QA 벤치마크에서 검증되었으며, 특히 fine-grained한 디테일 잡기가 중요한 VNBench에서 토큰 수 감소로 인한 성능 하락을 최소화하여 효율적인 방법론임을 증명했습니다. 또한 query-agnostic한 구조이기 때문에 KV cache를 그대로 재사용할 수 있어 연산 효율성을 극대화했습니다.
하지만 한계점 역시 존재합니다. STTM이 시공간적 잉여 정보를 성공적으로 줄여주긴 하지만, token budget을 맞추기 위해 spatial / temporal threshold(\tau_S, \tau_T)를 수동으로 조작해야 한다는 heuristic이 존재합니다. 따라서 저자들은 future work로 주어진 budget에 맞춰 모델이 스스로 최적의 병합 기준을 찾아내는 Adaptive Threshold Selection 기법 탐구를 제안하며 마무리합니다.
논문을 읽으며 VLM, 비디오 압축 기술 등 많은 선수 지식들을 알게 되어 유의미했던 시간이었습니다. 토큰 개수를 줄인다는 것은 그만큼 널널해진 context length에 더 많은 정보를 꾹꾹 눌러담을 수 있다는 의미이기 때문에 고정된 token budget 기준 long video에서의 성능이 드라마틱하게 향상되어야하지 않나 싶지만 관련 실험이 없었다는 점이 살짝 아쉬운 점으로 남는 것 같습니다.
안녕하세요 재윤님 리뷰 잘 읽었습니다. 읽다가 혼자 궁금한 점이 생겨 댓글 남겨두겠습니다.
Quadtree 분할에서 부모-자식 토큰 간 cosine similarity가 threshold보다 높으면 merge한다고 한 것 같은데요. 그러다ㅗ면 이 similarity는 LLM 내부 feature space에서 계산되는 것이라 semantic 정보가 강하게 반영될 것 같습니다.
그렇다면 실제로 배경이 아니라 semantic이 비슷한 객체 영역도 merge되는 경우는 없었는지 궁금합니다. 예를 들어 사람 얼굴과 다른 사람 얼굴처럼 의미적으로 유사하지만 spatially 중요한 영역이 합쳐질 가능성은 없었을까요?
1. 안녕하세요 주영님, 좋은 질문 감사합니다.
공간축의 merging threshold는 논문/코드에서 0.85, 0.9 등 꽤 높게 설정하여 사실상 질감이 거의 똑같은 배경 수준만 merge시키도록 설계되었습니다. 다만 그렇기 때문에 배경이 아니어도 의미적으로 굉장히 유사하다면 공간적으로 중요한 영역이 합쳐질 가능성도 존재하며, 이는 heuristic한 설계의 단점이라고 생각합니다.
안녕하세요 재윤님 좋은 리뷰감사합니다.
spatial token merging에서 공간축으로 병합을 할때 Coarse-grained과 Fine-grained으로 나누어서 병합을 하는데, 이에 대한 Ablation 결과도 있을까요? 그리고 기존 논문들에서는 Fine-grained한 병합 방식을 어떻게 구현했는지도 궁금합니다.
감사합니다.
안녕하세요 의철님, 좋은 질문 감사합니다.
spatial merging의 경우 coarse-grained와 fine-grained로 나누어서 병합을 한다기보다, coarse-to-fine search를 통해 배경은 큼직한, 디테일은 세세한 토큰으로 표현한다고 보시는 게 더 정확합니다. 관련 ablation으로는, root node 초기화를 2×2 / 4×4로 진행한 실험이 있습니다. 4×4 size로 루트를 초기화했을 때 성능이 더 좋았는데, 저자들은 2×2 초기화했을 때 하위 디테일이 더 뭉개지기 때문에 적당히 촘촘한 크기에서 시작하는 것이 성능 방어에 도움이 된다고 분석했습니다.
안녕하세요 재윤님 좋은 리뷰 감사합니다.
RoPE를 간단하게 그냥 알고만 있었지 적어주신 내용 기반으로 궁금한 점이 생겨 positional embedding 관련해서도 엄청 많이 연구가 되어오고 있었네요.
저자가 제안한 방법론 자체도 영상 압축 관점에서도 잘 이어지는 것 같아서 매력적인 contribution 처럼 보입니다.
재윤님이 마지막에 언급하신 주어진 token budget 내에서 성능이 올랐어야 하지 않나 싶은 부분을 좀 더 구체적으로 설명해주실 수 있나요? ( EX, 총 token budget 대비 Image token budget이 이정도 줄었으면 추가적으로 어떤 정보로 채울 수 있을지?)
감사합니다.
안녕하세요 인택님, 좋은 질문 감사합니다.
conclusion에서 언급했던 부분에 대한 추가 설명 드리겠습니다. merging으로 줄어든 토큰으로도 성능 방어가 된다면, 남는 context length에 추가 정보를 부여할 수 있다는 의미입니다. 그래서 이 남는 공간에 기존에 context length가 부족하여 처리가 어려웠던 (굉장히)long video에 STTM을 적용하면 기존 대비 상당한 성능 향상을 보여야 하지 않나라는 생각이 들었습니다. 또는 조금 다른 관점일 수 있지만, 남는 공간 만큼 frame sampling을 더 dense하게 샘플링하면 더 많은 정보를 입력하기 떄문에 추론 능력이 올라갈 것이라고 생각했다. 결국 잉여 토큰을 덜어낸 자리를 다른 정보로 채웠을 때의 실험 부재가 아쉬웠다는 의미였습니다.
안녕하세요 재윤님 좋은 리뷰 감사합니다.
궁금한점이 있습니다.
제가 이해한바로 RoPE는 각도 기반의 pos emb여서 거리에 따른 attention이 달라져,
일종의 inductive bias를 가지는 방법론으로 알고 있습니다.
그런데 Reassigned RoPE을 적용하게 되면, 원래라면 근처가 아니였을 token들에 대해
inductive bias를 가지게 될 것 같은데, 성능이 제일 좋은 이유가 잘 이해가 되지 않습니다.
Reassigned RoPE가 성능이 제일 좋은 이유에 대해 좀 더 설명이 가능할까요?
안녕하세요 정우님, 좋은 질문 감사합니다. Survived RoPE의 경우 병합된 토큰들로 인해 위치 인덱스에 불연속적인 공백이 발생하는데, 이 부분은 LLM의 attention 연산에 혼란을 야기합니다(merged RoPE도 비슷한 느낌) . 따라서 원래의 거리감을 잃더라도, 시간적으로 재정렬된 reassigned RoPE가 LLM의 상대적 위치를 안정화했기 때문이라고 분석했습니다.
안녕하세요 재윤님 좋은 리뷰 감사합니다.
Reassigned RoPE를 적용한 결과 성능이 제일 좋았다는 부분에서 원래 위치 정보를 최대한 보존하는 것이 좋을 줄 알았는데 오히려 새롭게 위치를 재할당하는 것이 더 좋은게 의외였던거 같은데 그러면 token merging 이후에는 원래의 구조보다 압축된 sequence 자체가 더 중요하다고 봐도 되는지 궁금합니다!
감사합니다.
안녕하세요 우현님, 좋은 질문 감사합니다.
위의 정우님 질문과 같은 맥락인 것으로 보이는데, 어차피 redundunt한 토큰은 시간적으로 앞선 root에 흡수되기 때문에 남는 토큰만 LLM이 잘 처리할 수 있게 연속적인 위치 정보를 새로 부여하는 것이 더 좋더라! 라고 이해하시면 될 것 같습니다. 감사합니다.