안녕하세요 이번에 리뷰할 논문은 internrobotics의 NavDP: Learning Sim-to-Real Navigation Diffusion Policy with Privileged Information Guidance 라는 논문입니다. 해당 논문은 시뮬레이션 데이터만으로 학습했음에도 불구하고 실제 로봇에 바로 올려서 zero-shot으로 동작할 수 있는 navigation policy를 다룬 연구다라고 보시면 좋을 것 같습니다. 바로 리뷰 시작하도록 하겠습니다.
Introduction
기존에 visual navigation 쪽에서는 GNM, ViNT, NoMaD처럼 learning-based navigation 모델들이 많이 나와 있었고, 또 반대로 iPlanner, ViPlanner, EgoPlanner처럼 planning 기반 접근들도 꾸준히 제안되고 있었습니다. 그런데 실제 open-world 환경으로 가면 여전히 해결이 잘 안 되는 부분이 있는데 바로 복잡한 환경에서의 안전한 경로 선택, 다양한 embodiment에 대한 genralization 그리고 real-world 데이터를 대규모로 모으기 어렵다는 점이라고 합니다. 기존 modular navigation stack은 perception, mapping, planning, control이 분리되어 있기 때문에 설계나 디버깅 관점에서는 유리할 수 있지만 실제로는 latency와 누적 오차가 생기고 하이퍼파라미터 튜닝 부담이 크다는 문제가 있습니다. 그리고 learning-based 방식은 좀 더 end-to-end하게 가져갈 수는 있지만 결국 좋은 real-world robot trajectory data가 많이 필요하다는 한계가 있습니다. 특히나 로봇 데이터를 실제로 모으는 건 시간이 너무 오래 걸리고환경 다양성을 확보하는 것도 쉽지 않기 때문에 저자들은 scalable한 simulation을 최대한으로 활용하자라고 주장을 합니다.
저자들은 imitation learning은 positive demonstration을 잘 따라가게 만들 수는 있지만 어떤 행동이 위험한지에 대한 negative supervision이 부족하다고 합니다. 반대로 reinforcement learning은 행동의 결과를 reward로 학습할 수 있지만 data efficiency가 낮다는 문제가 있다고 합니다. 그래서 저자들은 여기서 단순히 simulation으로 behavior cloning/RL만 하겠다는 것이 아니라 diffusion policy의 표현력과 imitation learning의 효율성, 그리고 RL의 critic 개념을 묶어서 trajectory를 생성하는 actor와 trajectory를 평가하는 critic을 동시에 학습하는 구조를 제안하였고 이게 NavDP의 핵심 아이디어라고 보시면 될 것 같습니다.
그리고 추가적으로 이 논문은 simulation 안에서만 얻을 수 있는 privileged information을 활용하는데, trajectory generation 쪽은 simulation 안의 global-optimal planner로 supervision을 받고 critic 쪽은 ESDF(Euclidean Signed Distance Field)를 기반으로 trajectory의 안전성을 더 세밀하게 학습하는식으로 합니다. 단순히 잘 간 trajectory만 따라하는 것이 아니라 이 trajectory가 왜 더 안전한지까지 배우도록 설계한 것이다라고 이해하면 좋을 것 같습니다. 그리고 저자들은 내비게이션 데이터 엔진(학습용 navigation 데이터를 자동으로 대량 생산해주는 전체 파이프라인)을 통해서 3000개 이상의 scene에서 100만 m 이상 규모의 navigation 데이터셋을 구축합니다.
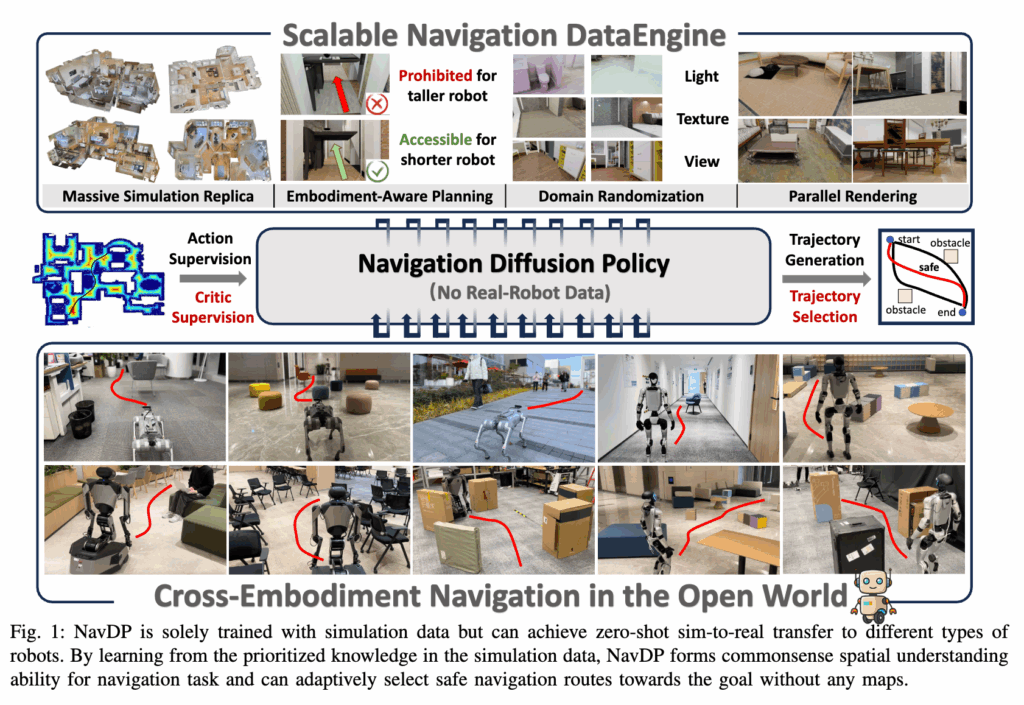
Figure 1이 사실상 해당 논문을 다 설명하는 그림인 것 같은데 위쪽은 scalable navigation data engine, 가운데는 privileged supervision을 받는 NavDP, 아래쪽은 서로 다른 실제 로봇들에서의 cross-embodiment navigation 결과를 보여줍니다. 특히 No Real-Robot Data라고 명시해놓고도 실제 로봇에서 동작하는 그림을 보여주는데 저자들이 어필하고자 하는건 simulation-only 학습으로도 real-world도 충분히 좋은 수행능력을 보여준다는 것 같습니다. 그리고 여기서 그냥 local planner를 end-to-end로 대체한 것이 아니라 안전한 경로를 고를 줄 아는 navigation policy를 만들려 했다는 점에서 기존 NoMaD류와도 결이 조금 다른 것 같습니다.(NoMaD는 단순히 경로를 생성해내는 것 뿐인데 NavDP는 만들어진 여러 경로 중에서 뭔가 더 안전한지 평가해서 고르는 것까지 가능)
Method
이 논문의 전체 방법론은 크게 세 부분인 거 같은데 첫 번째는 scalable simulation data engine,두 번째눈 RGB-D 기반의 NavDP architecture, 세 번째는trajectory generation과 critic-based selection을 함께 학습하는 one-stage training이라고 보시면 좋을 것 같습니다.
Scalable Navigation Data Engine
먼저 이 논문은 모델만 제안한 것이 아니라 학습에 필요한 navigation 데이터를 시뮬레이터에서 대량으로 생성하는 파이프라인까지 같이 설계도합니다. 로봇은 기본적으로 two-wheel differential drive를 가진 원통형 body로 가정했다고 합니다. 그리고 서로 다른 embodiment를 흉내 내기 위해 로봇 높이 h_b를 0.25m에서 1.25m 사이로 랜덤하게 바꾸고, 카메라 pitch와 FOV도 같이 랜덤화합니다. cross-embodiment generalization을 위해서 이렇게 세팅했다고 보시면 좋을 것 같습니다.
그 다음 trajectory를 어떻게 만드는지 설명드리면 먼저 scene mesh를 voxel map으로 바꾸고 주행가능 영역에 대한 ESDF를 추정 합니다. 그리고 navigable area와 obstacle area를 정의하고 start와 goal을 무작위로 샘플링하고 A* 알고리즘을 통해서 계획 경로를 생성하고 각 waypoint를 주변 obstacle로부터 더 멀어지도록 greedy search를 통해 refine한 다음 cubic spline interpolation으로 부드럽게 만든다고 합니다. 뭔가 복잡한데 단순히 shortest path가 아니라 충돌 위험을 줄인 좀더 스무스한 expert trajectory를 만들기 위해 노력했다라고 보시면 좋을 것 같습니다.
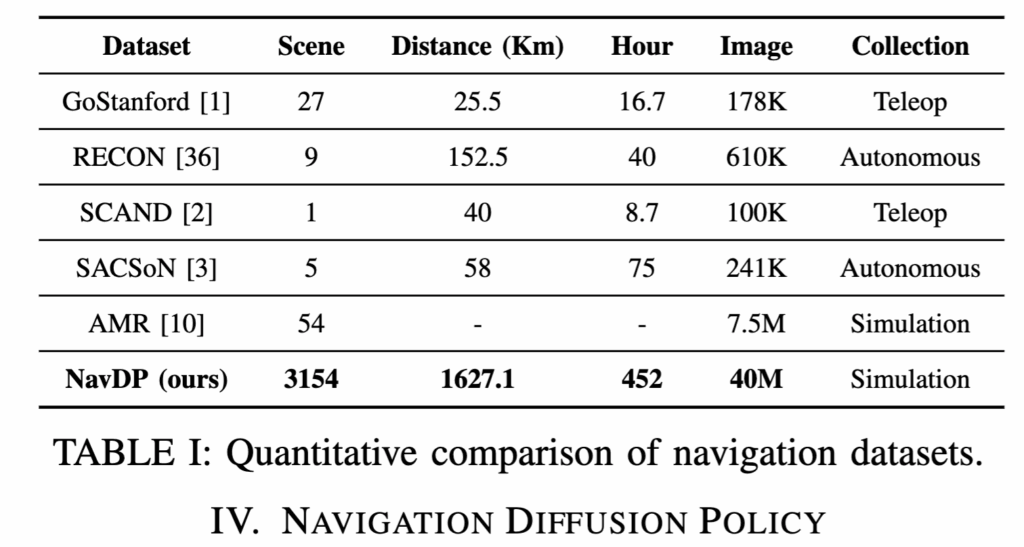
그리고 나서 BlenderProc를 사용해 trajectory를 따라가며 photorealistic RGB와 depth를 렌더링하고 light, view, texture randomization까지 적용합니다. 사용한 scene source도 3D-Front, HSSD, HM3D, Replica, Gibson, Matterport3D 등 3000개가 넘는 scene을 사용했고 scene당 100개의 start-goal pair를 샘플링했다고 합니다. 최종적으로는 200K가 넘는 trajectory랑 1M meter 이상의 주행 거리, 40M 이미지 규모의 데이터셋을 만들었고 기존 navigation dataset과 비교했을 때 scene diversity와 scale이 훨씬 크다는 점을 아래 표에서 강조합니다.
Navigation Diffusion Policy
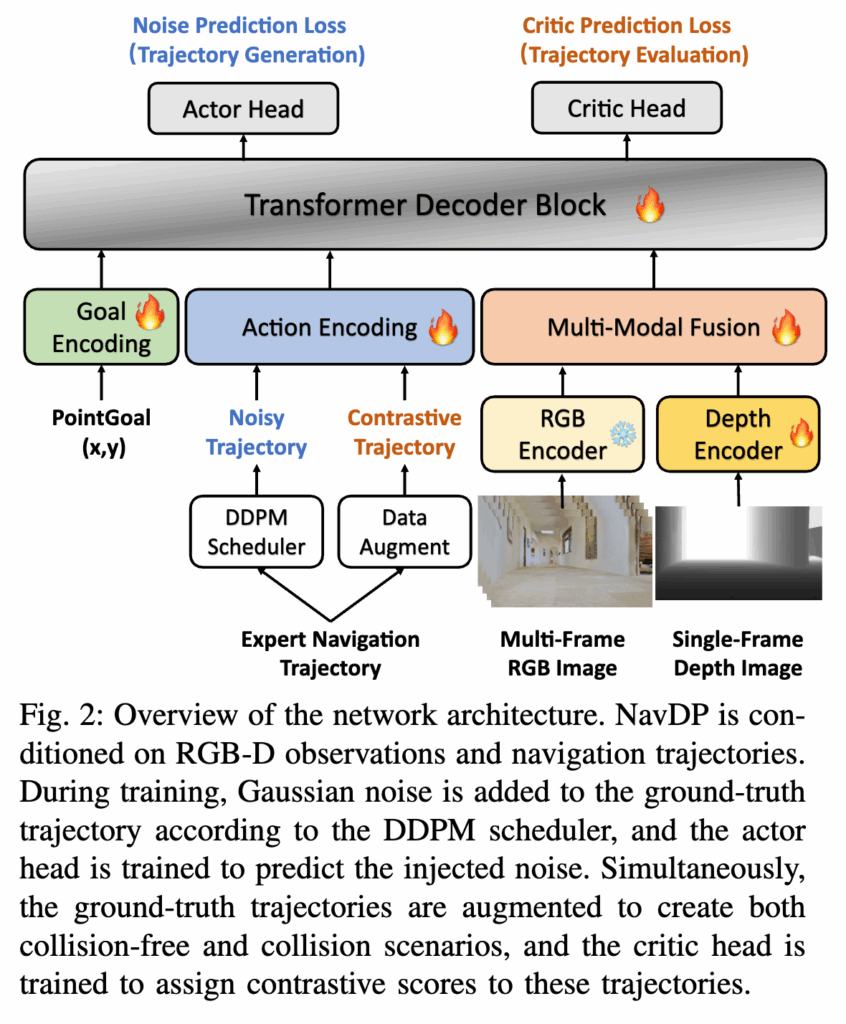
이제 NavDP 구조에 대해서 설명드리도록 하겠습니다. NavDP는 크게 보면 multi-modal encoder와 unified policy transformer로 구성됩니다. 입력은 RGB-D observation과 goal이고 여기서 RGB는 한 장이 아니라 과거를 포함한 multi-frame RGB N장을 사용하고 depth는 single-frame만 사용한다고합니다.(한장만 사용하는 이유는 잘 모르겠습니다.) RGB branch는 pretrained된 DepthAnything encoder를 사용하고 depth branch는 scratch로 학습한 ViT encoder를 사용했다고합니다. RGB와 depth를 따로 토큰화한 뒤, lightweight transformer decoder를 통해 이를 compact token으로 fuse하고 goal은 PointGoal 방식의 상대 좌표 (x_g, y_g)이고 no-goal task에서는 zero embedding으로 들어간다고 합니다.
RGB는 semantic 정보와 temporal consistency를 주고 depth는 실제 물리적 거리와 scale 정보를 주는식으로 설계를 했다라고 보시면 좋을 것 같고 저자들은 sim-to-real gap을 줄이기 위해 depth는 0.1m에서 5m 범위만 사용한다고 합니다. 아무래도 depth는 현실에서 노이즈가 심할 수 있으니 너무 먼 거리까지 사용하지 않은 것 같습니다.
Fig 2를 보면 아래쪽에서 RGB encoder와 depth encoder가 observation을 처리하고, noisy trajectory 혹은 contrastive trajectory가 action encoding을 거쳐 transformer decoder block으로 들어갑니다. 그리고 위에서 actor head와 critic head가 각각 noise prediction loss와 critic prediction loss를 받는 식으로 학습이 진행된다고 보시면 됩니다.
Unified Policy Transformer
NavDP는 trajectory generation과 trajectory evaluation을 하나의 transformer decoder 위에 같이 처리하고 rajectory generation에서는 noisy trajectory가 query가 되고, RGB-D fused token과 diffusion timestep token이 key/value가 되게 됩니다. 여기서 actor head는 주입된 noise를 얼마나 잘 예측하느냐를 디diffusion 기반으로 학습되고 그리고 여기서 trajectory evaluation에서는 arbitrary trajectory가 query로 critic head는 그 trajectory의 safety score를 예측합니다. 동일한 transformer decoder를 공유하기는 하지만 입력 query와 attention mask가 서로 다르게 됩니다.
추론 시에는 actor가 여러 개의 candidate trajectory를 만들고 critic이 그 후보들에 점수를 매겨서 최종 trajectory를 고릅니다. 그냥 diffusion model 하나로 최종 trajectory를 바로 출력하는 게 아니라 여러 경로를 생성한 다음 더 안전한 것을 고르는 식으로 NoMaD보다 좀더 안정적으로 action을 만드는 느낌입니다.
Loss
Actor Loss
trajectory generation은 diffusion policy 방식이기 때문에 정답 trajectory 자체를 바로 회귀하는 것이 아니라 trajectory에 더해진 noise를 예측하도록 학습합니다. 논문에서는 no-goal task와 point-goal task 각각에 대해 actor loss를 정의합니다.
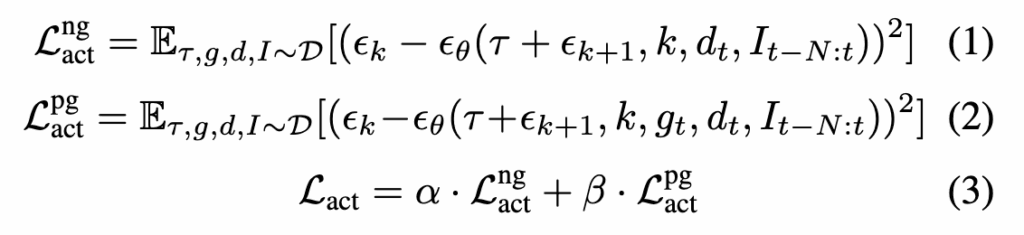
식(1)은 no-goal task에 대한 actor loss이고
여기서 \tau는 noise가 없는 expert trajectory이고 \epsilon_k는 DDPM scheduler로부터 샘플링한 noise라고합니다. noisy trajectory \tau + \epsilon_{k+1}가 들어왔을 때 네트워크 \epsilon_\theta가 실제 주입된 noise를 복원하도록 학습하는 형태라고 합니다.
식 (2)는 point-goal task에 대한 actor loss이고 식 (1)과 차이는 goal embedding g_t가 추가된다는 점입니다. no-goal task는 말 그대로 목표 없이 exploration하는 상황인거고 point-goal task는 목표 좌표가 주어진 navigation의 상황이라고 보시면 좋을 것 같습니다.
Critic Value
논문이 NoMaD와 달리 안정적인 궤적을 선택할 수 있는 이유가 되는 부분인거 같은데 이 Critic lable은 단순히 충돌, 비충돌 이진 라벨이 아니라 trajectory 상 waypoint들의 ESDP값을 통해서 더 복잡하게 정의됩니다.
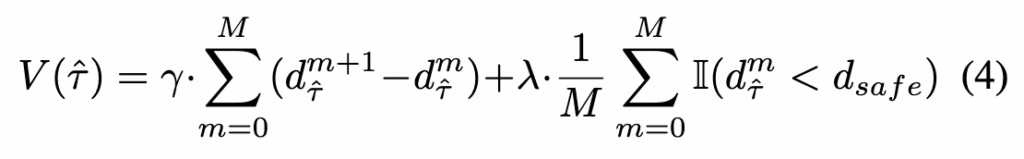
여기서 \hat{\tau}는 augmentation된 trajectory이고 d^m_{\hat{\tau}}는 그trajectory의 m번째 waypoint에서의 ESDF 값이라고 보시면 되고, 첫 번째 항은 trajectory를 따라가면서 obstacle로부터의 거리가 어떻게 변하는지를 보는 항이고, 두 번째 항은 safe distance 이하로 가까워지는 waypoint가 얼마나 많은지를 보는 penalty 항으로 이해하시면 좋을 것 같습니다. 즉 critic은 단순히 목적지로 가는가만 보는 게 아니라 waypoint 전체를 따라가며 얼마나 안전한 trajectory인지를 점수화하는 친구라고 보시면 좋을 것 같습니다.
Critic Loss
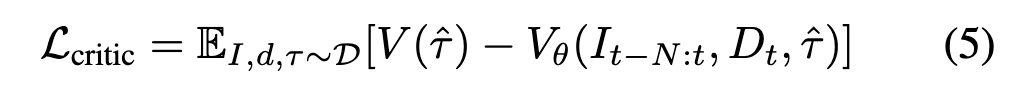
네트워크가 예측한 critic score V_\theta가 ESDF 기반 label critic value V(\hat{\tau})를 잘 맞추도록 학습이 되게끔합니다. 최종적으로는 이 Critice Loss랑 Actor Loss 두 Loss의 합으로 one-stage joint로 학습이 이루어지게 됩니다.
아래는 Training Detail 입니다.
Experiments
저자들은 저자들이 설정한 다섯 가지 질문에 대한 평가를 합니다.

실험은 simulation과 real-world 모두에서 진행했고 simulation은 IsaacSim 기반이고 point-goal task에는 20개 realistic scene, no-goal task에는 10개 cluttered scene을 사용했다고 합니다. 각각 2,000 episode와 1,000 episode로 평가를 했다고 하며 real-world는 Turtlebot4, Unitree Go2, Unitree G1을 사용했고 point-goal과 no-goal 각각 여러 indoor scenario에서 테스트했다고합니다. 평가는 point-goal에서는 SR과 SPL, no-goal에서는 collision 전까지 버틴 시간과 exploration area를 사용하여 평가합니다.
Point-goal navigation
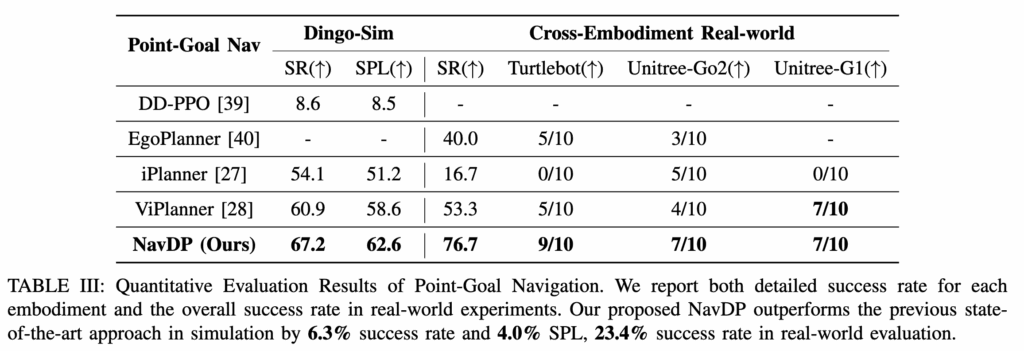
먼저 Table III를 보면 point-goal navigation에서 NavDP는 simulation의 Dingo 환경에서 ViPlanner(이전 SOTA)보다 높고 real-world cross-embodiment에서도 좋은 SR을 보입니다. 특히 iPlanner랑 비교했을 때실제 embodiment가 바뀌는 상황에서 NavDP가 더 안정적으로 일반화된다고 볼 수 있다고 저자들은 어필합니다.
그리고 저자가 위에 대해서 분석한 내용을 자세히 정리하자면 성능차이의 원인을 3가지로 설명합니다. 첫째는 temporal consistency라고 합니다.(과거 몇개 프레임) iPlanner와 ViPlanner는 single-frame input 기반이라 현재 프레임만 보고 경로를 바꾸기 쉬운데 그러면 카메라는 장애물을 지나갔어도 로봇 몸체는 아직 통과하지 못한 상황에서 path가 급격히 바뀌어 충돌할 수 있다고 합니다. 둘째는 depth noise에 대한 robustness라고 하는데 planning 기반 방식은 noisy depth나 부정확한 local map에 민감하다고 합니다. 그리고 마지막으로 세번째는 불규칙한 geometry나 hole이 있는 장애물에서 depth-centric planning이 잘못된 해석을 할 수 있는데 NavDP는 critic-based trajectory selection 덕분에 좀 더 안전한 경로를 고를 수 있었다고 설명합니다.
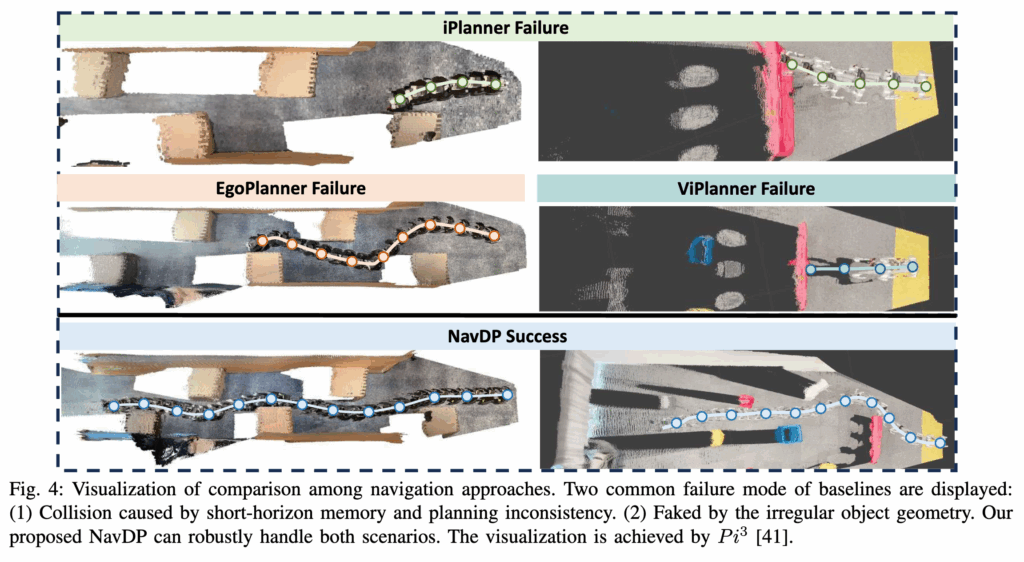
위는 앞서 저자들이 분석한 베이스라인 방법론들의 실페 케이스와 자신들의 성공케이스를 적나라하게 비교하는 정성적인 결과입니다.
No-goal exploration
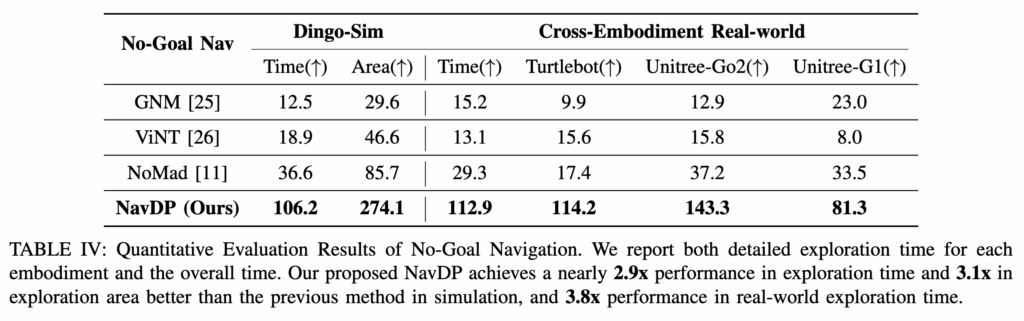
위를 보면 goal conditioned보다 no-goal navigation에서는 차이가 더 크게 나타나는 것을 확인할 수 있습니다. simulation, real-world에서 NoMaD보다 압도적인 성능을 보입니다. 단순히 목표점까지 가는 것보다 오랫동안 안전하게 돌아다니는 능력에서 NavDP가 훨씬 더 좋은 성능을 보이지 않았나 싶습니다. no-goal task에서는 목표를 향해서 스트레이로 가는 능력보다 계속 안전한 path를 선택하는 능력이 더 중요한데 NavDP는 diffusion으로 multiple candidate를 만들고 critic으로 걸러내기 때문에 이런 exploration setting에서 더 좋은 성능을 보인 것 같습니다.
Real-world trajectory visualization

논문은 Unitree Go2, G1, Galaxea R1에 NavDP를 실제로 올려서 top-2 trajectory와 critic value를 시각화한 결과도 보여줍니다. Figure 5를 보면 빨간 trajectory일수록 critic value가 높고 더 안전한 경로, 파란 trajectory일수록 위험한 경로라는 것을 나타내는데 observation view, pedestrian interference, varying light, motion blur 같은 요소로 training data와 다른 상황에서도 100m 이상 인간 개입 없이 navigation했다고 설명합니다. 장애물이나 코너를 잘 피해서 경로를 선택한다는 점에서 critic이 실제로 trajectory selection에 쓰이고 있다라는 것을 정성적으로 보여주는 것 같습니다.
Ablation study
먼저 Table V는 RGB-D fusion, multi-frame RGB, critic selection, augmentation, no-goal auxiliary task에 대한 어블레이션 테이블입니다. 그런데 depth를 빼면 success가 크게 떨어지고, RGB를 빼도 성능이 꽤 감소합니다. single-frame RGB-D로 바꾸면 성능이 소폭 감소하는데 이건 temporal context가 중요하다는 것을 보여줍니다. 특히 critic-based selection을 제거하면 success가 눈에 띄게 떨어지는 것을 확인할 수 있습니다. depth 제거 시 success가 10.3%, RGB 제거 시 5.1%, multi-frame 제거 시 2.8% 하락하고, critic selection 제거 시 simulation success가 7.8% 감소하는 결과를 보이고 또 no-goal auxiliary task를 같이 학습하면 point-goal 성능이 향상되는 모습을 보입니다.
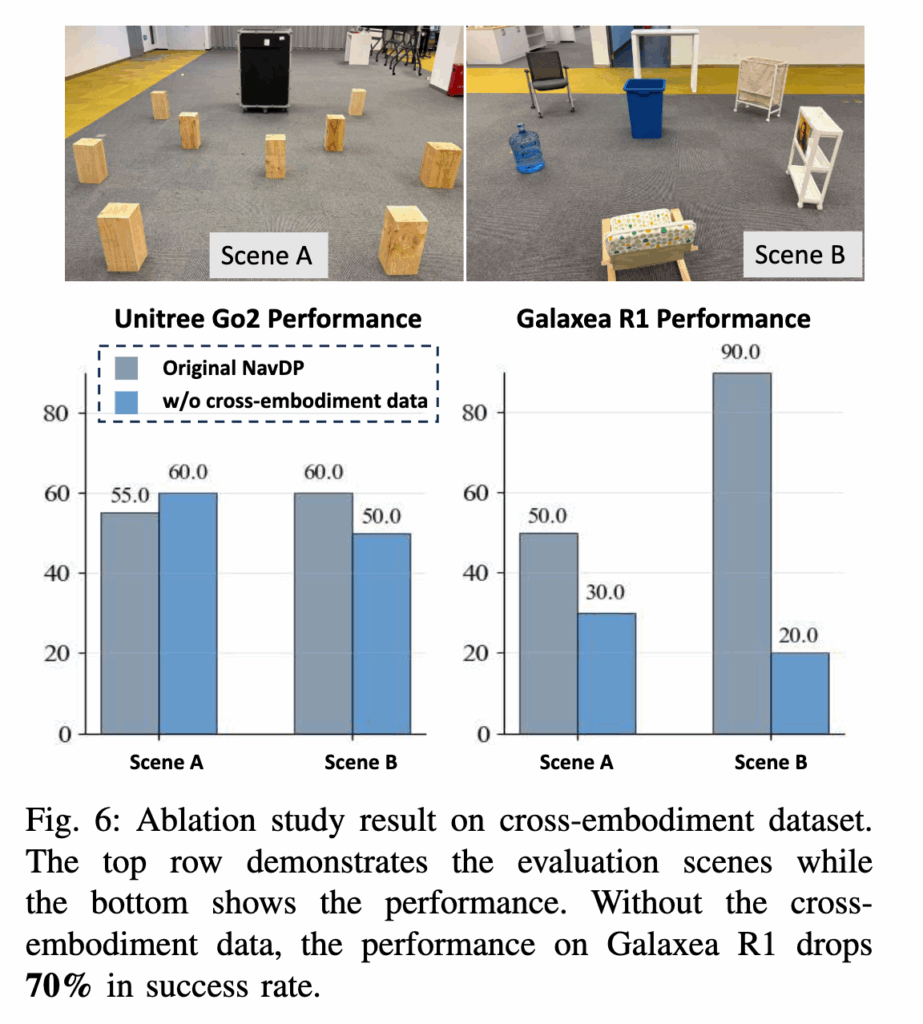
그리고 Figure 6은 cross-embodiment data의 중요성( 랜덤으로 로봇 높낮이 설정한다는 부분). 낮은 height의 robot data만으로 학습한 모델은 Unitree Go2에서는 어느 정도 버티지만, 더 큰 Galaxea R1에서는 테이블 아래를 지나가면 안 되는 상황을 제대로 이해하지 못해서 success rate가 90%에서 20%로 크게 떨어지는 결과를 보입니다. 결국 cross-embodiment generalization은 단순히 inference 때 잘 되기를 바라는 것이 아니라 data generation 단계에서 embodiment-aware randomization이 들어가야한다라는 것을 보여줍니다.
Conclusion
정리하면 저자들은 simulation privileged information을 어떻게 policy 학습에 잘 녹여낼 것인지 그리고 trajectory generation과 evaluation을 어떻게 하나의 end-to-end policy 안에 묶을 것인지를 고민하면서 NavDP라는 프레임 워크를 설계를 했고 global planner가 trajectory generation supervision을 주고 ESDF가 critic supervision을 주는식으로 학습이 되면서 actor는 여러 경로를 만들고 critic은 그중 더 안전한 경로를 고르는 이런 구조 덕분에 NavDP는 simulation-only 학습임에도 실제 로봇에서 zero-shot으로 잘 일반화되는 결과를 보이는 것 같습니다.
보통 navigation policy는 최종 output trajectory만 보고 좋다 나쁘다를 이야기하기 쉬운데 여기서는 ESDF를 통해 trajectory 자체의 공간적 안전성을 직접 supervision으로 넣는다는 점이 결국 이 critic이 이 경로는 벽에 너무 가까워 이 경로는 점점 더 위험해진다 라는 같은 감각을 simulation에서만 얻을 수 있는 privileged information으로 모델이 배우게끔 한 설정이 좋은 것 같습니다. 실제 환경에서는 이런 완전한 ESDF를 얻기 어려운데 simulation에서는 가능하다는 점을 잘 활용했다는 생각이 듭니다. 이만 리뷰 마치도록 하겠습니다.
안녕하세요 우현님 리뷰 잘 읽었습니다
내용 중 ESDF를 각 지점에서 가장 가까운 장애물까지의 거리를 수치화한 지도로 이해했는데 제가 파악한 게 맞을까요?
만약 맞다면, ESDF는 보통 정적인 맵을 전제로 생성되지않나요>? 어떻게 보행자 같은 동적 장애물 상황에서도 Critic이 안전한 경로를 선택할 수 있었는지 궁금합니다. 데이터 생성 단계에서 동적 객체까지 반영된 별도의 처리가 있었나요?
감사합니당
안녕하세요 우현님 리뷰 감사합니다.
Simulation을 통한 scale-up이 진행된 연구가 있을 것 같았는데, 내비게이션 쪽에서도 역시 진행이 됐었구나 하면서 읽게 됐습니다. 몇가지 질문이 있는데요,
Q1. 시뮬레이션 환경은 indoor 위주로 구성되어있을 것 같고, depth 정보도 outdoor에서는 시뮬레이션과 현실 센서 간 오차가 있을 것 같은데, outdoor에서도 sim2real이 잘 될 수 있는 이유에 대한 분석이 있나요?
Q2. Depth를 보조적인 도구로 사용하는 것 같고, 그래서 한 장만 쓰는게 아닌가 싶은데, RGB에서 DepthAnything 인코더를 사용한 이유에 대한 언급이나 다른 백본과 ablation 있나요?
Q2-1. DA 인코더가 history의 geometry를 이해하면서 어떻게 진행했는지를 좀 더 알 수 있는걸까요..? 오히려 depth에 힘을 빼면서 DA 인코더로 sim2real gap을 줄인건가.. 싶어서 여쭤봅니다.
Q3. 시뮬레이션 환경의 텍스쳐에 대한 visual gap 영향은 없나요?