안녕하세요 손우진입니다.
오늘 리뷰할 논문은 단일 RGB 기반의 6D 객체 포즈 refinement와Tracking에 관한 논문인 “GoTrack: Generic 6DoF Object Pose Refinement and Tracking” 입니다.
이전 리뷰들에서 다루었던 FoundPose나 GenFlow처럼 학습 단계에서 보지 못한 새로운 객체(Unseen Object)의 포즈를 추정하는 흐름을 이어가면서도, 이를 비디오 트래킹 환경으로 확장할 때 발생하는 불안정성을 해결한 논문입니다. 그럼 바로 시작하겠습니다!
introduction
일반적으로 AR이나 로보틱스에서도 그렇게 실제 환경에서 단일 이미지에서의 포즈 추정뿐만 아니라, 연속된 비디오 프레임에서 객체의 포즈를 실시간으로 추적하는 Tracking 기술또한 필수적입니다.
최근 6D 포즈 분야에서는 객체의 3D CAD 모델을 렌더링하고 실제 이미지와 비교하여 포즈를 보정하는 Render-and-compare 기반의 Refinement 방식이 높은 정확도를 보여주고 있지만 저자들은 이러한 기존의 Refinement 모델들을 비디오 추적에 그대로 적용할 때 발생하는 문제점을 지적합니다.
기존 방식들은 렌더링된 3D 템플릿과 현재 프레임 사이의 Model-to-frame에만 의존하게됩니다. 하지만 이 방식은 합성 이미지와 실제 이미지 간의 도메인 차이를 극복해야 하므로 꽤나 무거운 네트워크를 사용하거나 연산이 오래걸리는 한계가 있습니다. 게다가 매 프레임마다 새롭게 매칭을 수행하다 보니 이전 프레임에서 얻은 픽셀 단위의 정보가 버려지게 되고 이러한 비효율적인 방식이 tracking 결과에 Jitter나 포즈가 틀어지는 것을 발생시킵니다.
저자들은 이 문제를 해결하기 위해 SLAM 시스템의 구조를 이용하였다고 합니다. SLAM에서는 시간이 지남에 따라 누적되는 오차를 보정하기 위해 전역적인 Model-to-frame 등록을 사용하고 카메라가 이동할 때 효율적이고 부드러운 움직임 추정을 위해 Frame-to-frame 등록을 함께 사용한다고 합니다(저도 SLAM에 대한 개념은 적어서..그러려니 하고 넘어갔습니다). GoTrack은 이 두 가지 등록 방식을 모두 Optical Flow 기반으로 구현하여 6D 객체 추적에 통합한 프레임워크입니다.

논문의 Figure 1은 이렇게 구축된 프레임워크가 실제 환경에서 얼마나 강력하게 동작하는지를 보여줍니다. 손으로 물체를 쥐고 조작하는 등 심한 Occlusion이나 움직임이 발생하는 까다로운 조건 속에서도, 특정 객체에 대한 사전 학습 없이6DoF 포즈를 추적해 내고 있습니다. 매 프레임 무거운 매칭을 하는 대신, 가벼운 Frame-to-frame Flow를 통해 화면에 살아남은 픽셀들의 흐름을 매끄럽게 따라가는 전략이 가려짐 상황에서 높은 강인함을 보여주었습니다.
저자들이 논문을 통해 입증한 핵심 Contribution을 객관적으로 정리하면 다음과 같습니다.
- 기존 방법들보다 단순하면서도 큰 포즈 편차를 교정할 수 있고, 별도의 scoring 네트워크 없이도 신뢰할 수 있는 포즈 신뢰도 점수를 산출하며, 6DoF 객체 포즈 추정 및 추적 벤치마크 모두에서 SOTA( RGB-only ) 결과를 달성하는 Flow 기반 6DoF 포즈 Refiner를 제안했습니다.
- 템플릿 검색을 통해 coarse 포즈를 빠르게 생성하고, 이를 Flow 기반 Refiner로 최적화하는 seamless 6DoF 포즈 추정 파이프라인을 제안했습니다. 두 단계 모두 DINOv2에 의존하므로 구현이 매우 용이합니다.
- Refiner를 Frame-to-frame Optical flow 추정으로 확장하여 추적 효율성을 높이고, jitter을 줄이며, 가려짐(occlusion)에 대한 강건성을 향상시킨 견고한 6DoF 포즈 추적 파이프라인을 제안했습니다.
Method
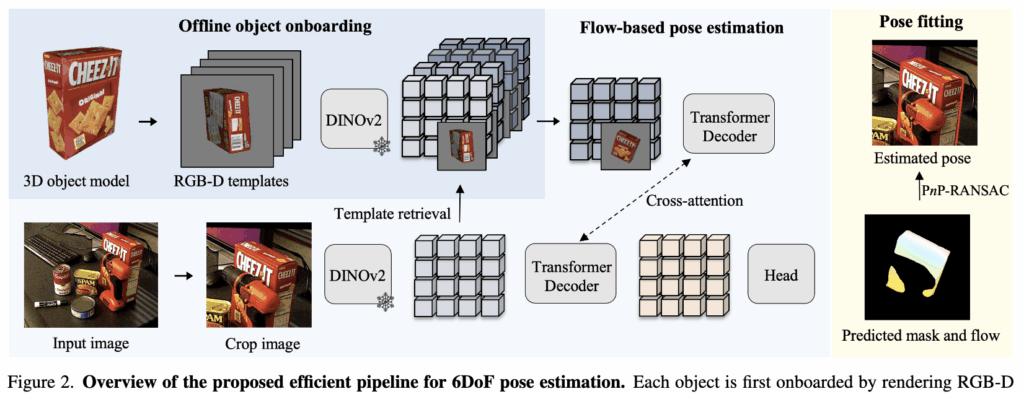
Method 파트에 대해 설명드리겠습니다. 위 그림은 제안하는 프레임워크의 Overview입니다. 논문의 방법론은 크게 세 가지 파트로 구성되어 있습니다. 첫 번째는 템플릿과 입력 이미지 사이의 매칭을 수행하는 Flow-based object pose refinement, 두 번째는 특징 추출을 공유하여 효율성을 높인 Efficient object pose estimation pipeline, 마지막으로 이를 비디오 연속 프레임으로 확장한 Extension to object pose tracking 입니다.
Flow-based object pose refinement
GoTrack의 Flow 기반 Refinement 모듈은 렌더링된 RGB-D 템플릿과 입력 이미지를 정렬하는 역할을 합니다. 네트워크 구조를 살펴보면, 먼저 Freeze된 DINOv2 백본을 통해 두 이미지의 특징을 추출하고 Transformer 디코더에 통과시킵니다. 이를 통해 템플릿 픽셀이 입력 이미지에서 어디로 이동했는지를 나타내는 Optical flow와, 해당 픽셀이 가려지지 않고 실제로 보이는지를 나타내는Visibility mask를 예측합니다. 예측된 마스크 영역에 템플릿의 Depth 정보를 결합하면 2D-3D 대응점이 매칭되게됩니다.
이후 대응점들에 EPnP-RANSAC 통해 해를 찾고, 최종적으로 채택된 Inlier들을 모아 Levenberg-Marquardt 알고리즘으로 6D 포즈를 fit하게 맞춥니다. 이 과정에서 Scoring 네트워크를 거치지 않고, PnP 최적화 과정에서 도출된 전체 대응점 가중치 대비 최종 Inlier 가중치의 비율을 계산하여 포즈 신뢰도 점수를 산출했다고 합니다. 기존에는 포즈 후보들의 스코어링을 매겨서 최종적인 포즈를 구했는데 저자들은 lnlier의 비율을 통해 네트워크를 태우는 것 보다 효율적인 방법을 제안했습니다.
마지막으로 이 네트워크는 Decoder와 head를 학습시켰는데 가시성에 대한 Binary Cross Entropy 오차와 Flow에 대한 L1 오차를 결합한 Loss를 통해 학습이 이루어집니다. 가려진 객체같은 경우에는 가려진 영역의 Flow 예측 오차는 무시하고 실제 화면에서 관찰 가능한 픽셀들에 대해서만 L1 오차를 계산하도록 제한하였습니다. 이는 네트워크가 노이즈를 학습하지 않고, 유효한 Flow에만 집중하여 학습되도록 설계했다고 합니다.
Efficient Object Pose Estimation Pipeline
앞서 설명한 Flow 기반 보정 모듈은 객체의 초기 포즈를 추정하는 단계와 합쳐져 단일 이미지 포즈 파이프라인을 구축합니다. 이를 위해 우선 Offline onboarding 과정이 필요합니다. 대상 객체의 3D CAD 모델을 다양한 시점에서 렌더링하여 템플릿 이미지들을 생성하고, DINOv2 백본을 통해 템플릿들의 Feature를 미리 추출하여 데이터베이스를 구축해 둡니다.
기존의 파이프라인들은 초기 포즈를 찾기 위해 입력 이미지를 추가적인 네트워크에 통과시켰고, 이후 Refinement를 위해 객체를 새롭게 렌더링한 뒤 또 다른 네트워크에 이미지를 다시 통과시켜야 하는 추가적인 연산이 있었습니다. 하지만 GoTrack은 파운데이션 모델인 DINOv2를 전체 파이프라인의 공통 백본으로 사용합니다. 즉, 새로운 카메라 입력 이미지가 들어오면 DINOv2 백본을 단 한 번만 통과시켜 특징 맵을 추출합니다. 그리고 이 추출된 단일 feature 맵을 오프라인으로 구축해 둔 템플릿 데이터베이스와 비교하여 가장 유사한 템플릿의 시점을 초기 포즈로 사용합니다. 이후 추가적인 특징 추출이나 실시간 렌더링 과정 없이, 입력 이미지의 피처와 검색된 템플릿의 피처를 그대로 재사용하여 Refinement 디코더로 넘겨줍니다.
결과적으로 초기 포즈를 찾는 검색 과정과 이를 refinement를 하는 과정에서 연산의 효율을 얻었습니다. 런타임에서의 백본 연산을 1회로 줄이면서도 실시간 렌더링을 제거한 것 입니다.
Extension to object pose tracking
마지막으로 이 논문의 핵심 비디오 Tracking 확장은 introduction에서 언급한 SLAM의 프레임 간 일관성을 파이프라인에 적용하여 연산 속도를 높이고 노이즈처럼 포즈가 튀는 현상을 해결합니다. 단일 이미지 기반의 Refinement 모듈을 비디오에 그대로 적용하면 이전 프레임의 포즈를 단순히 다음 프레임의 초기값으로만 넘겨주게 되어, 매 프레임마다 픽셀 매칭 정보가 완전히 초기화되는 비효율적인 문제가 발생하게 됩니다. 아무래도 계속 추론하고 추론하다보니 비효율적인 것은 맞습니다.
저자들은 이를 해결하기 위해 이전 프레임과 현재 프레임 사이에 연산량이 적은 기존의 범용 Optical Flow 모델인 RAFT를 사용하여 2D 픽셀 이동을 추정합니다. 그리고 이전 프레임의 Model-to-frame 매칭에서 살아남았던 2D-3D Inlier 대응점들의 2D 좌표를, 앞서 구한 프레임 간 Flow 흐름에 따라 현재 프레임의 위치로 매끄럽게 이동시킵니다. 이렇게 위치가 갱신된 새로운 2D 좌표와 기존의 3D 좌표를 바탕으로 다시 EPnP 알고리즘을 돌려 현재 프레임의 6D 포즈를 구하게 됩니다.
여기서 연산량을 줄여주는 핵심은 객관적인 조건부 Trigger 방식에 있습니다. 만약 프레임 간 Flow로 구한 포즈의 Inlier 비율이 0.8 이상이라면 추적이 유지되고 있다고 판단하여, 렌더링이나 DINOv2 백본 연산 없이 이 포즈를 최종 채택하고 바로 다음 프레임으로 넘어갑니다. 반면 객체가 너무 빠르게 움직이거나 심한 Occlusion이 발생하여 프레임 간 추적을 놓치게 되고 Inlier 비율이 0.8 미만으로 떨어질 때만, Model-to-frame 보정 네트워크를 다시 구한다고 합니다. 그리하여 템플릿으로부터 새로운 2D-3D 대응점을 다시 추출해 냅니다.
결과적으로 영상이 재생되는 대부분의 시간 동안에는 가벼운 RAFT 모델만 구동되며, 추적이 불안정해질 때만 40ms짜리 무거운 보정 네트워크가 개입하게 됩니다. 이를 통해 연산량을 줄이면서도 흔들림 없이 비디오 tracking을 유지할 수 있다고 합니다.
Experiments
저자들이 제안한 프레임워크를 검증하기위해서 논문은 크게 단일 이미지에서의 6DoF 포즈 Refinement 벤치마크와 비디오 환경에서의 Tracking 벤치마크 두 가지 실험 결과를 제시합니다.
가장 먼저 핵심 벤치마크인 BOP 데이터셋의 7개 데이터셋을 대상으로 단일 이미지 기반 보정 성능을 평가했습니다.
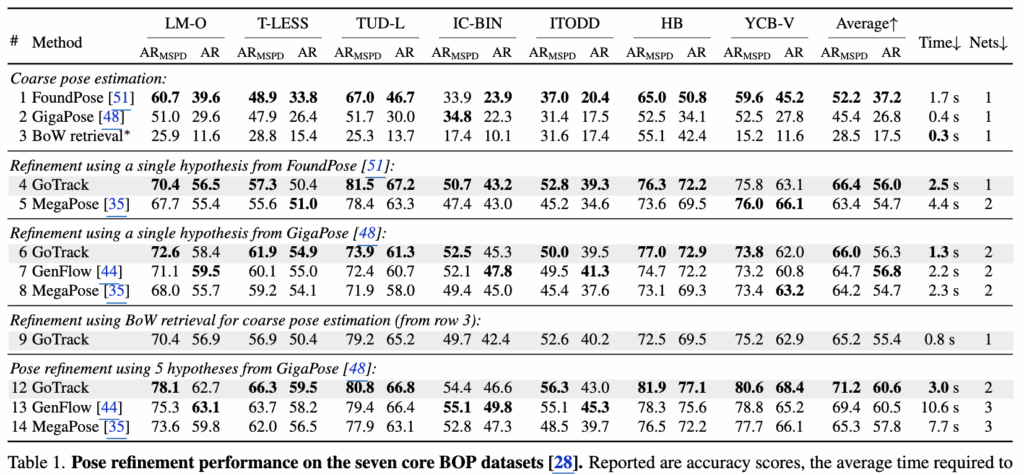
위 Table 1에 나타난 정량적 지표를 보면, 초기 포즈로 FoundPose를 사용했을 때(초기포즈 추출 부분은 Foundposef랑 동일합니다) GoTrack은 기존 SOTA 모델인 MegaPose와 비교하여 평균 AR 지표를 향상시켰습니다. 또한 GigaPose를 초기 포즈로 설정한 환경에서도 최신 모델인 GenFlow와 비슷한 성능을 기록했습니다 refinement가 빠르고 효율적인 측면에서 어필을 합니다. 기존 모델들이 여러 초기 포즈를 평가하기 위해 Scoring 네트워크를 별도로 사용했던 반면, GoTrack은 앞서 Method에서 설명한 직관적인 Inlier 비율만으로 더 높은 정확도를 달성했습니다. 제안된 파이프라인이 가벼우면서도 성능 면에서 활용할 방법인것 같습니다.
다음으로 비디오 환경에서의 연속적인 추적 성능과 연산 효율성을 YCB-V 데이터셋을 통해 검증했습니다.
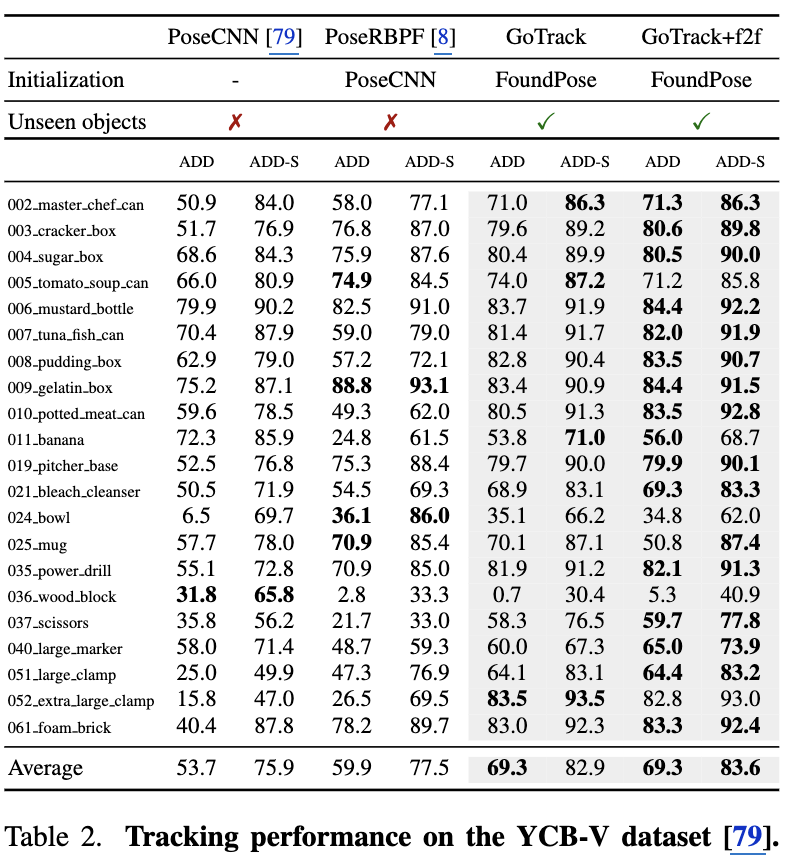
Table 2의 결과를 보면, 특정 객체들에 대해 사전 학습을 진행했던 PoseCNN이나 PoseRBPF 같은 기존의 추적 모델들보다, 학습 단계에서 타겟 객체를 전혀 보지 못한Unseen object 타겟인 GoTrack이 ADD-S AUC 지표에서 더 높은 점수를 기록했습니다. 단일 모달리티만으로도 가려짐이나 복잡한 객체 추적이 잘 되는 것을 볼 수 있습니다. 저자들은 이 결과를 통해, 타겟 객체를 직접 학습에 사용한(Seen) 기존 모델들과 비교하더라도 자신들의 Unseen 모델이 대등하거나 오히려 이를 뛰어넘는 성능을 달성할 수 있음을 어필합니다.
하지만 이 부분의 평가 기준에는 아쉬운 점이 존재하긴 합니다. Object-specific 학습 방식은 새로운 객체에 범용적으로 적용할 수는 없지만, Inference 단계에서 무거운 템플릿 검색이나 피처 매칭 과정 없이 곧바로 포즈를 Regression하므로 속도와 연산 효율성 측면에서 훨씬 가볍고 빠르다는 점이 있습니다. 음 한마디로 지향하는 기준이 전혀 다른 두 방식을 단순 포즈 정확도 지표만으로 비교한 것은, 객관적인 성능 평가 측면에서 물음표입니다 그리고 posecnn같은 경우 2017년에 나온 모델이기도 하구요.
하지만 비디오 환경에서 프레임 간 Optical Flow를 활용한 2D-3D 대응점 추적 방식은 큰 연산 없이도 부드러운 추적을 가능케 한 접근 같습니다. 아무래도 사전 지식 없는 새로운 객체를 즉각적으로 추적해야 하는 로봇같은 환경에선 GoTrack같은 tracking 방법이 더 효율적이지 않을까 싶습니다.
감사합니다
우진님 좋은 리뷰 감사합니다.
Tracking에 대한 설명 중, 이전프레임의 Model-to-frame 매칭에서 살아남은 2D-3D inlier 대응점을 이동시킨다고 하셨는데, 해당 과정은 빠르게 이루어지는 지 궁금합니다.
또한, introduction에서 Frame-to-frame 등록을 이용한다고 하셨는데, 방법론 설명에는 따로 없는 것 같습니다. 혹시 어떤게 이에 해당하는 지 알 수 있을까요?
안녕하세요 우진님 좋은 리뷰 감사합니다.
결국 이 방법도 초기 포즈를 찾는 템플릿 검색이 어느 정도 맞아야 refinement와 tracking이 안정적으로 이어질 것 같은데, 처음 검색이 틀어진 경우 보정 단계가 그 오차를 어디까지 복구할 수 있는지 궁금합니다. unseen object에 강하다고 해도 실제로는 초기 템플릿 검색 성능에 많이 의존하게 되는 구조인건지가 궁금합니다. 감사합니다.