오늘 소개드린 논문은 LLM의 evalutation에 대한 분석과 분석 방법을 다룬 논문입니다. 일반적인 벤치마크는 정확도를 기준으로 평가합니다. 하지만 이는 LLM이 실제로 그 정보에 대한 지식이 없는지(empty shelves) 혹은 지식을 갖고있으나 추론 과정 중에 오류가 있었는지(lost key) 구분 할 수 없습니다. 본 논문은 이러한 평가방식에 문제를 지적하며 새로운 벤치마크와 평가 방법을 제시합니다.
1) LLM의 성능을 correct or incorrect로 구분하지 말라고? 그렇다면 어떻게 평가할 건데?
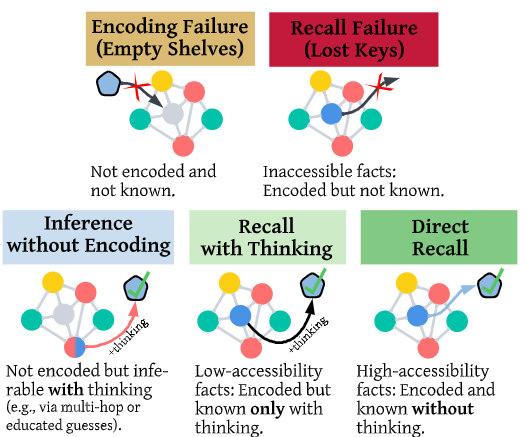
논문에서는 새로운 LLM의 평가방식을 제시했습니다. 위가 논문에서 제시하는 LLM의 상태의 분류입니다. 먼저 encoding failure(노랑)은 LLM에 지식이 없어서 틀린 경우입니다. 이는 재학습을 통해 해결할 수 있습니다. 다음은 recall failure(빨강)입니다. 이는 지식은 존재하나 추론 과정중에 이를 이끌어내지 못한것으로, CoT와 같은 추론 테크닉으로 해결할수 있는 오류입니다. 다음으로 inference without encoding(하늘)은 답변에 관련한 지식이 존재하지 않으나 주변 지식과 추론 중 thinking 과정을 통해 답변할 수 있는 경우입니다. Recall with thinking(연두)은 알고있는 지식이지만 thinking 과 같은 추론 과정을 거처야지만 답변할 수 있는 경우, 마지막으로 Direct Recall이 thinking 없이도 정답을 맞출 수 있는 highly accessable 지식을 의미합니다.
2) 재정의한 답변타입을 평가하는 방법
논문에서는 위와같이 correct/incorrect라는 결과론적 평가를 더 세부적으로 나누고자 하였습니다. 이 과정에서 제시된 평가방식(profiling method)을 소개하겠습니다. 먼저 논문에서는 fact는 옳고 그름을 판단할 수 있는 명제 중에서 순서가 있는 것으로 정의했습니다. 일반적으로 평가를 위한 fact 라는 요소는 QA 질문에서는 하나의 질의쌍으로 구성됩니다. 반면 본 논문에서는 fact라는 것을 정의하고 이에 대한 다수의 질문쌍으로 fact를 LLM이 알고있는지 여부를 평가하게 되는 것 입니다.

위와 같이 평가에서 새로운 기본 단위로서 fact를 정의했습니다. 그렇다면 이 fact를 어떻게 평가에서 활용할까요? 평가를 위해서는 fact를 활용하여 질의를 생성합니다. 예를 들어 “세종대학교는 광진구에 위치한다” 라는 fact를 통해 “세종대학교는 어디에 위치하는가?”와 같은 질의를 생성할 수 있습니다. 이렇게 생성된 질의를 기반으로 LLM의 답변 품질을 수치화하는 산출식은 아래와 같습니다. 질의(q)당 n개의 답변을 생성하여 옳다고 판단되는 답변 개수를 c_q, 틀리다고 판단되는 답변의 개수를 i_q로 하며 전체 답변 중 옳은 답의 비율을 의미합니다.
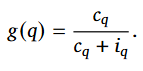
정리하면 fact를 활용해 질의를 생성하고, 각 질의에 대해 n번의 반복수행으로 답변의 일관성(일관적인 성공이 가능한가)을 기반으로 평가를 하는 방식입니다. 그렇다면 기존 accuracy 기반 평가와 다른 점은 무엇일까요? 본 논문은 앞서 언급된것처럼 추론 실패의 원인을 2가지ㅡ지식은 갖고 있으나 활용의 실패를 의미하는 lost key, 지식 자체가 부족한 encoding failureㅡ로 구분하고자 합니다. 이에 따라 논문은 두가지 상호보완적 평가기준 encoding, knowledge(recall)을 주장합니다.
encoding: #특정 fact에 대해서 encoding을 성공했는지 여부를 측정하는 평가기준
직관적으로 학습에 사용한 상태를 재생산 할 수 있으면 이는 모델에 충분히 encoded 되었다, 즉 이미 알고있다 라고 평가된다. 이러한 기존 관념을 활용하여 논문에서는 학습에 사용되었던 추론 형태를 따라하는(mimic) 방식의 평가셋(E_f)을 구성하고 이를 기반으로 예측의 품질을 평가했다.
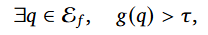
평가셋은 두가지 테스크로 구성했는데, LLM pre-training 방식을 그대로 따라한 추론 방법과 통상적으로 질의응답에 최적화된 post-training 모델에 대해 적절히 평가하기 위한 문맥 질문 방식으로 구성된 테스크이다. 예시를 통해 이해하면 쉬운데, 아래와 같다.
- Fact: 세종대학교는 서울특별시에 위치한 사립 대학이다. 세종대학교는 광진구에 있다
- task1 입력: 세종대학교는 서울특별시에 위치한 사립 대학이다. 세종대학교는
- task2 입력: 세종대학교는 서울특별시에 위치한 사립 대학이다. 세종대학교는 어느 구에 있습니까?
위처럼 pre-training을 모사한 task1과 post-train을 모사한 task2를 합한 평가셋 E에 대한 추론을 수행하고, 각 질의에 대한 성공률(수식1)이 기준치 𝜏(0.5)를 넘을경우 해당 fact에 대한 encoding이 되었다고 판된하는 것이다.
knowledge: #특정 fact에 대해서 LLM이 실제로 지식을 갖고있는지 여부를 측정하는 평가기준
다음으로 LLM이 어떠한 fact를 알고있다는것은 직관적으로 해당 LLM이 해당 정보에 관한 질의에 적절한 응답을 했을때 이다. 따라서, encoding과 명확하게 구분되어야 하는 것은 encoding은 fact의 재생산 가능도에 대해 집중했다면 knowledge는 질의의 방향에 대해 관계없이 (즉, 학습에 사용한 form이 무너지더라도) 예측에 성공해야하는 것이다. 따라서 위와 다른점은 평가셋의 구성이며 평가 방식은 동일하다.
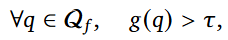
knowledge 평가를 위한 평가셋은 fact 당 4가지 질의(정방향 질의 2/역방향 질의 2)로 구성된다. 앞서 fact는 순서가 있는 명제라고 정의했는데, 이때 명제는 subject->object 순서로 서술 된다. 위의 순서를 활용해서 subject를 포함한 질의로 object를 유추하는 질의를 정방향 질의, object를 포함한 질의로 subject를 유추하는 질의를 역방향 질의로 정의한다. 예시는 아래와 같다.
- fact: 오아시스는 boardwalk club에서 첫 공연을 했다. : {subject}는 {object}에서 동작했다
- direct question: 어디서 오아시스가 첫 공연을 했습니까? : 답이 object
- reverse question: 누가 boardwalk club에서 첫 공연을 했습니까? : 답이 subject
Wikiprofile benchmark
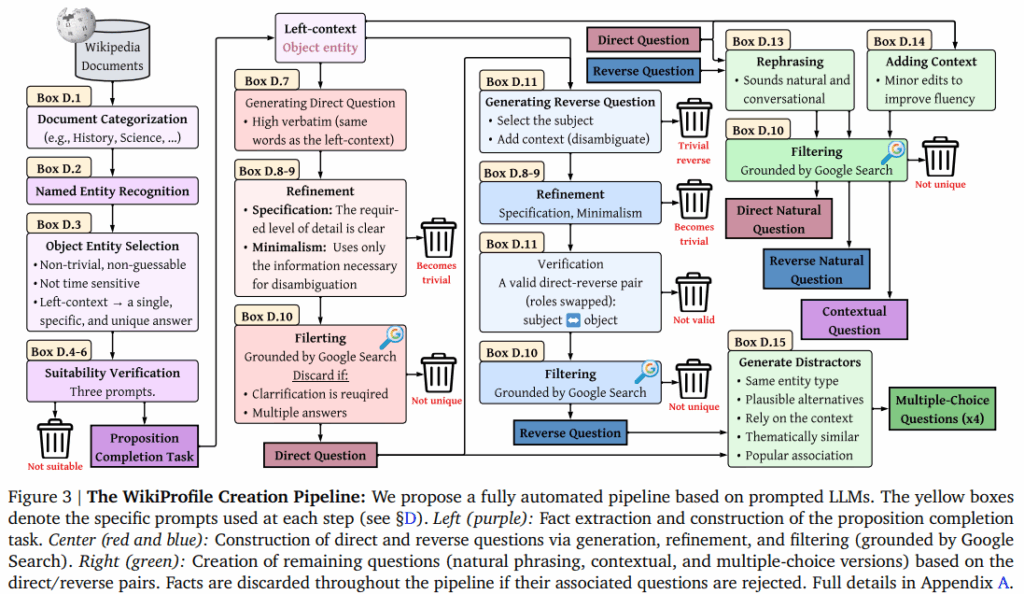
논문은 제시한 평가를 위해 위키피디아에서 크롤링한 wikiprofile이라는 데이터셋을 제시했고 위는 샘플링 방법에 대한 파이프라인입니다. 10,000 개의 위키피디아 페이지를 크롤링했으며 페이지당 3개의 명제를 선택했습니다. 선택된 명제들은 Figure 5의 15단계 필터링을 통해 정제되었으며, 자세한 필터링 방법은 부록에 10페이지에 걸처 설명되어있기에 차후 내용을 추가할 예정입니다.
분석 방법
논문에서는 model의 종류를 타지 않는 근본적인 분석을 진행하기 위해 5족의 총 13개의 LLM에 대한 분석을 수행하였습니다. 모델의 종류는 다음과 같습니다: Gemini-3 (Pro and Flash variants); Gemini-2.5 (Pro and Flash variants); GPT-5.2, GPT-5, GPT-5-mini; GPT-4.1, GPT-4.1-mini; Gemma3 (1B, 4B, 12B, 27B). 이때, 각 모델에서 문제(q)당 응답생성을 8번 반복(n=8)하였습니다.
생성한 답변에 대한 평가는 LLM 기반 모델을 활용했는데, wikiprfile의 fact 2,150개에 대해 각 fact당 10개의 질문, 이를 8회씩 반복했기 때문에 모두 사람이 평가하는것에 어려움이 있기 때문입니다. Gemini-2.5-pro with thinking 모델을 통해 답변의 생성 결과를 correct/incorrect로 평가하도록 했습니다.
분석 결과
해당 부분이 본 논문의 핵심이라고 할 수 있는 분석 결과입니다. 분석결과는 LLM 에러에 실제로 지식 부족이 아닌 추론과정의 오류인 recall 병목이 있음을 발견해내고, 그 원인을 밝히는것에 관합니다. 순차적으로 소개드리겠습니다.
1. Recall bottleneck ( 정말로 몰라서 틀리는게 아닌가요?)
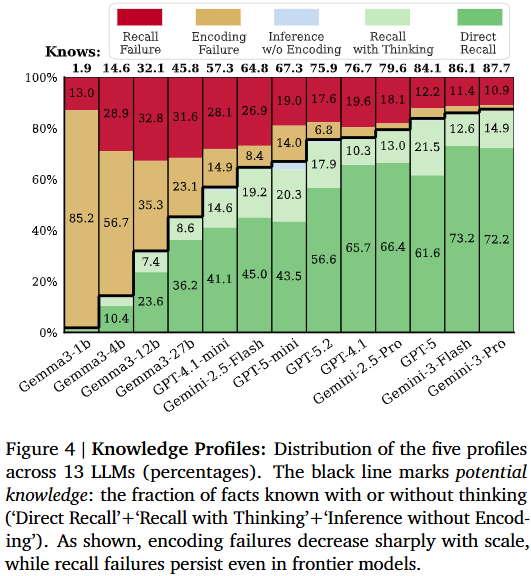
가장 먼저 논문은 제안한 벤치마크의 profiling 기법을 통해 13개의 LLM의 에러 형식을 분석했습니다. 그 결과 최신 모델인 GPT-5나 Gemini-3-pro의 결과에서 정보가 없음을 의미하는 Encoding Failure 에러는 거의 수렴할 정도로 줄어들었습니다. 그러나 추론 과정에서 발생하는 recall failure는 여전히 개선의 여지가 남아있음을 확인할 수 있습니다. 특히 Gemma3 모델의 성능으로 보면 1B에서 27B까지 모델이 커질때 Encoding Failure는 85.2%에서 23.1%까지 감소했지만 recall failure는 증가했음을 확인할 수 있습니다. 이처럼 두 에러는 구분되는 특성을 갖으며 모델 스케일이 증가함에 따라 모델의 모든 퍼포먼스가 개선되지는 않음을 알 수 있습니다.
2. Why recall fails (그렇다면 왜 Recall은 개선되지 않나요? 실패의 이유는?)
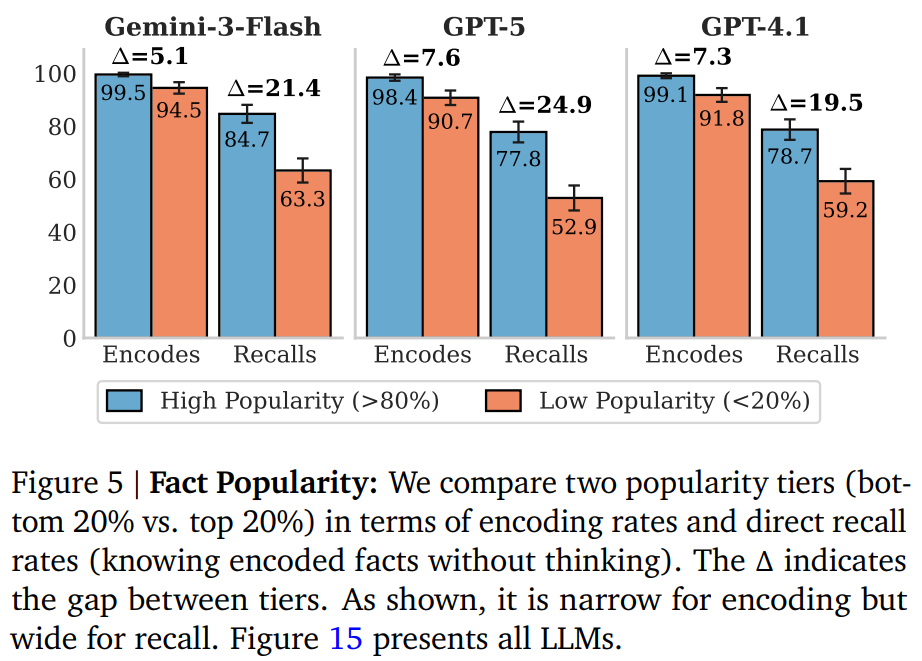
위 실험에서 우리는 단순히 모델 스케일 증가로 개선되지 않는 Recall fails을 확인했습니다. 이러한 에러의 발생 이유를 저자들은 fact의 존재 분포와 질의의 방향으로 분석했습니다. 먼저 wikipedia pages에서 인기도가 높은 페이지와 낮은 페이지들에 대해 분석한 결과는 Figure15 입니다. 이때 인기도는 페이지 뷰 기준으로 산출되었는데, 높은 페이지는 인용이 많아 확률적으로 등장빈도가 높으므로 등장빈도가 높은 정보를 의미하고, 인기도가 낮은 페이지는 등장 빈도가 낮은 정보를 의미합니다. 실험 결과 결과 인기도가 낮은 페이지(주황) recall이 실패할수는 있으나 encoding이 안됬음을 의미하는것이 아님을 알 수 있습니다. 즉 빈도수가 낮게 등장한 정보도 모델이 알고는 있으나 활용하지 못했을 가능성이 있다는 것입니다.
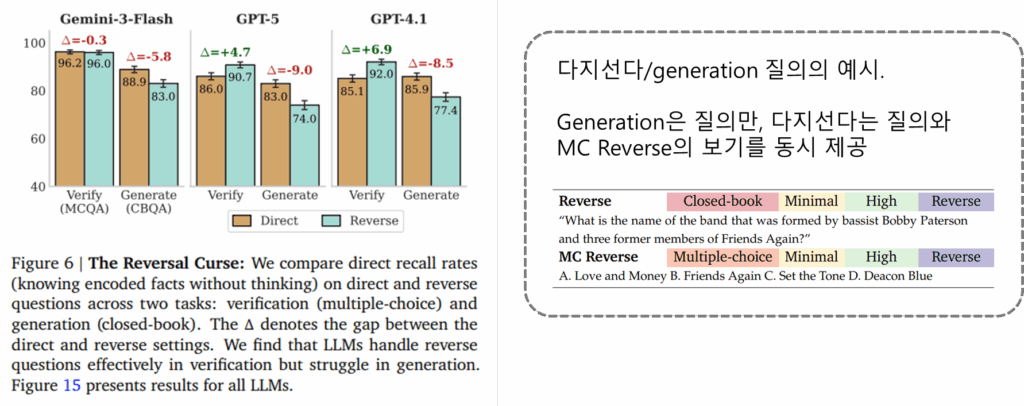
recall fails에 대한 두번째 분석은 질의의 방향입니다. 기존 몇몇 연구에서는 LLM이 정보를 활용할 때 방향성이 관여함을 확인했습니다. 즉 A는 B이다는 예측하더라도 B는 A이다의 예측은 실패하는 현상이 있었다는 것입니다. 이를 분석하기 위해 위에서 설계한 reverse question(역방향 질의)와 direct question(정방향 질의)의 성능을 비교했습니다. 또한, 동일 질문에 대해 다지선다로 구성한 MCQA(multiple-choice question ansering)와 정답을 직접 생성하는 Generate(closed-book question ansering, CBQA) 성능을 비교하였습니다. 실험 결과인 Figure6에서 확인할 수 있듯이 CBQA 과제에서는 정방향 질의 대비 역방향 질의 성능 하락이 컸으나 MCQA은 일부 모델에서는 오히려 성능 개선도 있었습니다. 실제로 LLM이 정보활용에 방향성이 있다면 과제의 형태에 상관없이 역방향 질의에서 정방향 질의 대비 성능 하락이 있어야하는데 그렇지 않았습니다. 즉, LLM에서 자주 보이는 방향성 문제(reversal curse) 역시 양방향적 정보는 저장이 되이었으나 기억하지 못하는 recall fail과 연관된 현상으로 해석할 수 있습니다.
3. Thinking as a recovery mechanism ( Thinking은 얼마나 도움이 되는가? )
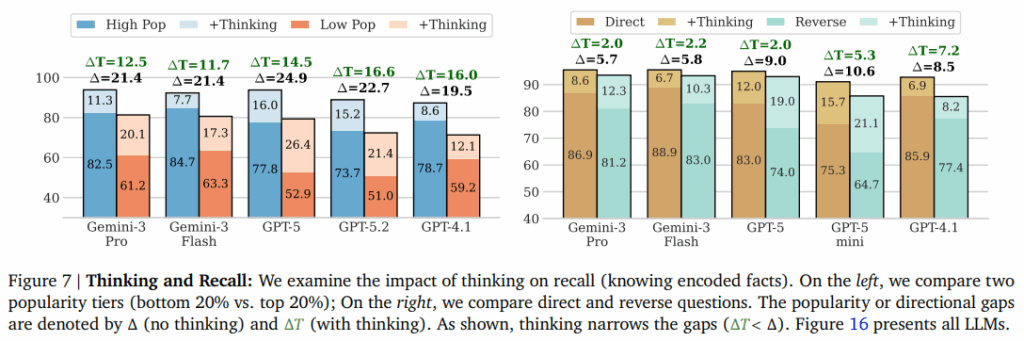
encoding된 지식을 잘 활용하는 기법인 Thinking을 적용할때 recall fails을 어느정도 개선할 수 있는지에 대한 결과는 Figure 7와 같습니다. 실험결과 thinking을 적용하면 인기도가 높은 페이지(Common facts)와 적은 페이지(Rare facts) 모두에서 성능개선이 있음을 확인할 수 있습니다. 특히, recall 성능이 낮았던 rare facts(figure7 좌)나 역방향 질의(figure7 우)에서 Thinking 적용을 통한 성능개선이 비교적 컸으며 결과적으로 우위에 있던 범주와의 성능 차이를 줄였음을 확인할 수 있습니다. 이를통해 Thinking은 recall fail 개선에 어느정도 유의미함을 확인할 수 있습니다.
정리하면 LLM은 정보를 내제하고 있지만 접근하지 못하여 QA등의 과제를 실패하는 경우가 있습니다. 이는 추상적으로 표현하면 약하게 연결되거나 저장된 정보로 Thinking과 같이 다른 각도에서 정보에 접근하는 기법으로 일부 개선할 수 있습니다. 저자들은 이러한 현상에 대해 인간의 인지현상과 비슷한 점이 있으며, 인간과 LLM의 유사한 인지 과정을 갖는것은 아니지만 정보 저장(encoded)과 회상(recall) 하는 시스템의 일반적인 특징일 수 있다고 분석하였습니다.
리뷰를 마치며 느낀점은 아래와 같습니다. 먼저 몰라서 틀린것과 추론에서 실패한 것에 대한 구분이 유의미한가 라는 고민이 있었습니다. 그러나 Figure4의 결과를 보면 명확히 두 에러의 요인이 구분되고 있음은 알 수있네요. 둘의 차이점에 대한 제가 이해한 직관적인 예시는 다음과 같습니다. 명제 A와 명제 B에 대해 모두 틀린 예측을 하더라도 명제 A는 틀릴 확률이 0.2, 명제 B는 틀릴 확률이 0.5로 다르며 개선을 위해 명제 B는 재학습이 필요하지만 명제 A는 재학습이 필요없거나 재학습하더라도 해결할 수 없을수도 있다는 것이지요. 그러나 실제로 특정 테스크의 성능을 개선하는데 있어서 명제 A와 명제 B에 대한 에러 타입을 고려하는것이 좋은지에 대해서는 잘 모르겠습니다. 이상으로 리뷰를 마치겠습니다.
리뷰 잘 읽었습니다. 궁금한 점이 있어서 댓글 남겨두겠습니다!
Encoding failure vs recall failure를 실제로 어떻게 구분할까요? 둘 다 “틀린 답”으로 관측되는데, profiling 방식에서 어떤 패턴이 나오면 이게 recall이구나 라고 판단하는건가요??
안녕하세요 주영님 읽어주셔서 감사합니다.
판단 과정은 단순합니다 encoding failure의 경우 학습 데이터와 동일한 포멧에 대해 예측을 실패한 정도를 의미하며 recall failure의 경우 역방향 질의가 포함된 질의에 대해 예측을 과반수 이상 실패할 경우를 의미합니다.
즉 하나의 fact에 대해 모델이 encoding fail혹은 recall fail을 만들어내는지 검토하기위해 많은 질의가 필요합니다. 그 결과 즉, 통계를 기반으로 실패의 케이스(encoding fail, recall fail)를 구분합니다.
감사합니다
안녕하세요 유진님 리뷰 감사합니다.
CBQA에서는 역방향 질의에서 성능이 크게 하락하고 MCQA에서는 일부 모델은 오히려 성능 개선이 되었고, 이게 recall fail와 연관된 현상으로 설명해주셨는데, 그렇다면 CBQA에서 성능이 떨어진 이유가 아무 단서 없이 빈 상태에서 정답 토큰을 직접 생성해야 하기 때문에 recall fail이 발생한 것이라고 이해하면 될까요??
감사합니다.