왜 제안되었나?
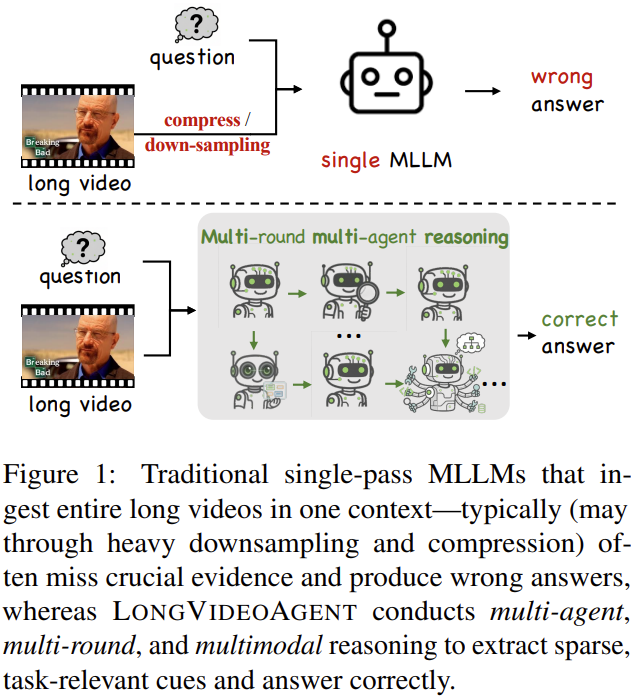
Crucially, most prior systems are non-agentic models: they process a static, pre-encoded or down-sampled video.
기존의 연구들은 미리 설계된(pre-encoded) 아키텍쳐로 분석을 수행하였다. 이러한 기존 연구의 한계는 프로세스의 진행단계가 비가역적(irreversible)이라는 점이다. 예를 들어 기존 연구는 대부분 Long video에 대한 추론을 위해 시각정보인 비디오를 압축하여 모델에 입력한다. 이때 압축에 과정의 정보 손실이 주어진 문제 해결에 필수적이더라도 돌이킬 수 없다. 반면 agentic 아키텍쳐는 프로세스의 진행과정에서 적절하게 진행되기 때문에 위와 같은 한계를 다룰 수 있다.
논문의 주 기여점
(i) master LLM과 grounding/vision specialists LLM이 협업하는 multi-agent 구조를 제시
(ii) 간결하고 단계별 접근이 가능한 강화학습 방안 제시
(iii) episode-level의 long video datasets(LongTVAQ/LongTVAQ+)를 제시
방법론
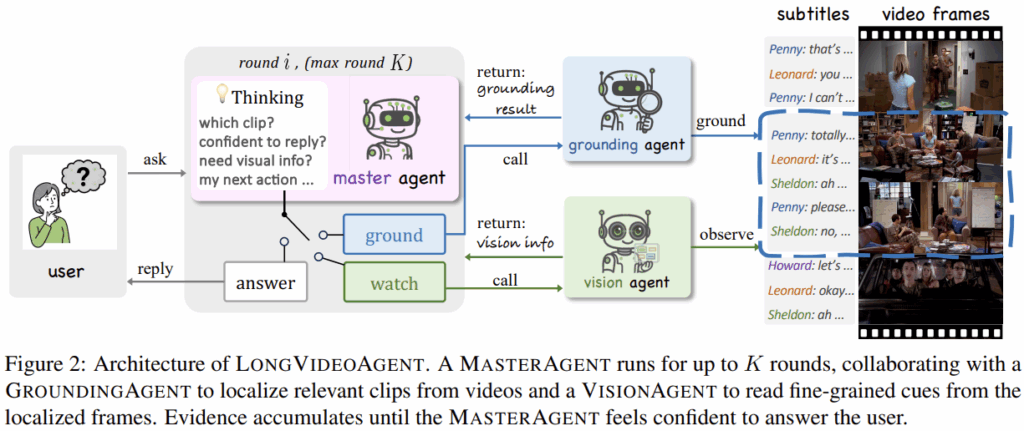
저자들은 Long-video QA를 multi-agent reasoning 문제로 해석하였다. 위의 Figure 2는 저자들이 제시한 프레임워크의 도식이다. 그림과 같이 시스템은 최대 k번 반복적으로 진행된다. open-source LLMs을 master agent로 하며, tool인 ground agent와 vision agent를 필요에 따라 호출한다. 또한 저자들은 master agent를 위한 강화학습 방법을 제시하였다. 프레임워크와 학습 방법에 대한 자세한 설명은 아래와 같다.
1) Multi-agent System Framework


제안한 프레임워크에서 master agent는 table1의 system prompt를 따르고, 진행되는 프로세스인 multi-turn policy는 Algorithm 1으로 정리할 수 있다. Algorithm의 Require에 명시되었듯이 사용되는 전문가 에이전트는 grounding agent와 vision agent이다. master agent는 알고리즘 1의 while 문(line3-line28)을 수행한다. master agent의 지시에 따라 K번 이하의 턴이 진행되는데, 매 턴마다 시각정보를 습득하는 <watch>/사건의 위치를 찾는 <request_grounding>/정답을 생성하고 반복 턴을 종료하는 <answer> 중 하나가 수행된다. 또한 매 턴에서 수행한 결과는 다음 턴을 위한 master agents의 입력에 함께 사용된다.
위의 프로세스가 진행될 때, 각 전문가 에이전트(grounding/vision agent)의 세부사항은 아래와 같다.
- Grounding agent: 질의와 subtitle이 주어지면 temporal segment에 해당하는 clip tag를 출력함.
- Vision agent: grounding agent가 제공한 clip tag와 관찰이 필요한 정보에 대한 주문(instruction)이 주어지면 관찰을 수행하고 관찰 결과는 다음 선택을 위한 master agent의 입력에 포함됨.
2) Reinforcement Learning for LONGVIDEOAGENT
제안하는 프레임워크에서 학습의 대상은 master agent이다. master agent는 open-source LLMs으로 구성되었으며, 호출되는 전문가 에이전트(grounding/vision agent)는 학습하지 않은(frozen) 채로 master agent만을 GRPO 기법으로 학습한다.
- 종료 조건: 프레임워크의 종료조건은 <answer> … </answer> 가 출력되거나, 최종 횟수인 K에 도달했을 때 이다.
- 실행 방법: Algorithm 1과 동일하게 K이하의 t번 반복이 허용되며, 종료되기 이전 t의 반복 결과는 다음 policy 예측을 위해 ot에 포함된다.
- 보상 설계: 보상은 2가지 평가 조건으로 설계되었다. 먼저 format reward는 <visual_query> … </visual_query>와 같이 미리 설계된 action tag가 포함되도록 올바른 형태를 유지한경우 1(긍정 보상), 그 외의 경우는 0(보상 없음)으로 설계되었다. 다음으로 Answer correctness reward는 agent가 생성한 정답이 옳으면 1, 그렇지 않으면 0(오답, 미응답, multi-turn 횟수 초과)을 받게 된다.
Experiments
Setting
저자들은 60-90초의 클립들로 구성된 TVQA와 TVQA+의 일부를 샘플링하여 LongTVQA, LongTVQA+를 설계했다. TVQA는 6개의 TV 프로그램을 통해 수집된 데이터로 subtitle과 moment annotation을 제공하며 TVQA+는 이를 가공하여 frame-level boxes까지 제공한다. 저자들은 클립을 에피소드 수준(시간 단위)로 병합하고, visual stream, subtitles, 관련 질문을 병합해 긴 영상을 위한 데이터셋인 LongTVQA를 제시하고 실험에 사용하였다. 또한 실험의 베이스라인으로는 (open-sorce)DeepSeek-R1, Qwen2.5-3B/7B, (closed-source)Grok, GPT5-mini, GPT-4o, Gemini 2.5 pro를 활용했다. 또한 프레임워크 구현을 위해서는 기본적으로 Grok-4-fast-reasoning을 grounding agent, GPT-4o를 vision agent로 사용하였다. 이때 최대 반복 횟수는 K=5이다. 한편 master agent는 open source 모델을 사용했으며 Qwen2.5-3B/7B에 대해 리포팅되었다.
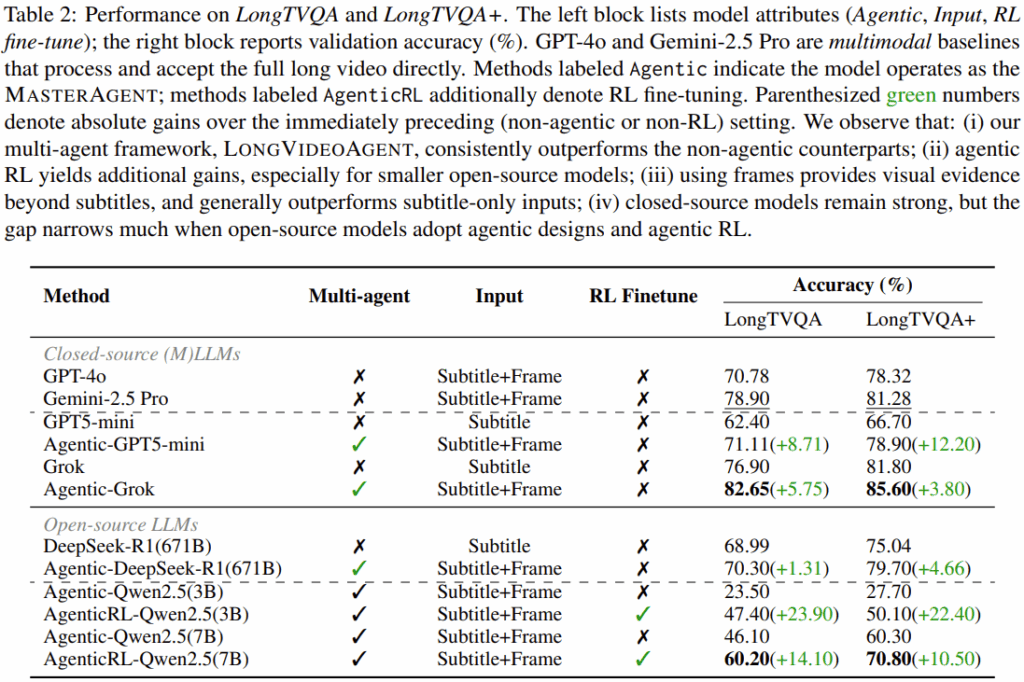
에이전틱 알고리즘을 접목한 메인 실험 결과는 Table2와 같다. open-souce인 qwen에서 강화학습을 적용하였을 때 일관적으로 개선되었음을 확인할 수 있으며, Qwen 7B의 강화학습 적용모델은 GPT5-mini에 상응하는 성능을 달성했음을 알 수 있다. Table3와 Table5는 제안한 프레임워크(Longvideoagent)의 동작 예시이다.

마무리
본 논문은 Longvideoagent라는 long video를 위한 multi-agent 프레임워크와 학습 방법 및 벤치마크를 제시했다. open/close-source를 포함한 다양한 LLMs을 master agent로 하고, 제안한 아키텍쳐와 학습방법을 적용한 성능을 Table2를 통해 보였다. 실험결과 TVQA, TVQA+ 조각난 데이터셋을 에피소드 단위로 병합해 긴 영상으로 가공한 LongTVQA/LongTVQA+ 데이터셋에 대해 제안한 구조들이 모두 유의미 했음을 확인할 수 있었다. 제시한 벤치마크 외에 다른 Long video QA를 성능비교에 활용하지 않은 점과 다른 agentic 방법론과 비교된 성능을 제시하지 않은 점에 아쉬움이 있으며, 논문에서는 modality 확장, 더 세부적인 grounding 지원, (아마도 master agent 를 넘어선 )더 광범위한 RL 학습이 차후 과제라고 밝혔다.
안녕하세요, 유진님. 좋은 리뷰 감사합니다.
리뷰를 보면서 Video Agent에 대해서 강화학습 기반으로 구성을 했다는 점이 인상적이었습니다.
제가 이해하고 있는 바로는 강화학습이 많은 시도를 통해서 학습이 이루어진다고 알고 있습니다. 이런 점에서 LongVideoAgent의 경우 매 episode마다 외부 API 기반의 에이전트를 반복적으로 호출한다는 점에서, 학습 비용이 상당할 것으로 예상됩니다. 이러한 방식이 실제로 얼마나 많은 계산 자원과 비용을 요구하는지, 혹은 이를 완화하기 위한 전략이 존재하는지에 대한 논의가 궁금합니다.
좋은 리뷰 감사드립니다.📽️
안녕하세요 기현님 리뷰 읽어주셔서 감사합니다.
우선 공개된 연산량을 말씀드리겠습니다 LongvideoAgent는 master agent만을 학습했으며
– Qwen2.5-7B의 경우 4대의 H800 GPU에서 12시간
– Qwen2.5-3B의 경우 4대의 H800 GPU에서 6시간
학습을 진행했습니다. SFT이 아닌 강화학습만을 진행하였고 모든 에이전트를 학습하지 않음으로서 기존 방법대비 학습 범위를 제한한 비교적 단순한 학습 설정이라고 주장하였습니다. 다만 추가적인 연산 경량화 전략은 사용하지 않고 표준적으로 사용되는 GRPO기반 강화학습을 사용했다고 하네요..
유진님 좋은 리뷰 감사합니다.
저자들이 Long-Video QA를 multi-agent reasoning 문제로 해석했다고 언급해주셨는데, 이러한 해석은 저자들이 처음으로 제안한 아이디어인지가 궁금합니다.
또한, master/grounding/vision agent가 존재하고, master는 전체 프로세스를 컨트롤하는 것으로 이해하였는데, 이러한 방식이 새로운 것 같습니다. 제가 이해한 바로는, grounding agent는 해당하는 clip을 찾고, vision agent는 해당 clip에 대한 내용을 master agent에 다음 선택을 위한 입력으로 제공하는 것으로 보이는데, 그런데 정확히 vision agent는 무엇을 하는 지 궁금합니다. 답변을 생성하는 것 일까요? 그렇다면 이렇게 전달된 답변을 보고, 더 추론이 필요할지, 답변이 적절한지에 대한 종합적 판단을 master agent가 내리는 것으로 이해하면 될까요?
안녕하세요 승현님 읽어주셔서 감사합니다.
먼저 말씀하신 아이디어는 저자들이 완전히 처음 제안한 것은 아닌것 같습니다. 비슷한 류로 해석한 연구를 종종 확인했습니다.
다음으로 vision agent의 역할은 논문의 표현을 빌려오자면 grounding agent가 찾아낸 세그먼트를 관찰하는 것입니다. 정확히는 vison agent한테 master agent가 주어주는 프롬프트를 기반으로 객체, 속성, 동작, OCR과 같은 장면의 정보를 텍스트 형태로 관찰해 전달합니다. 예시로 리뷰 하단의 Table3, Table5을 보시면 이해가 쉬울 것입니다.
감사합니다.