안녕하세요 이번에 리뷰할 논문은 아카이브에 올라온지 2달된 LoGoPlanner Localization Grounded Navigation Policy with Metric-aware Visual Geometry라는 논문 입니다.
지금까지는 image goal, language prompt 기반의 navigation 논문들을 찾아보면서 읽었는데 이번에는 Goal pose conditioned navigation논문을 한번 찾아서 읽어보고자했고 리뷰로 들고 오게 되었습니다. 바로 리뷰 시작하도록 하겠습니다.
Introduction
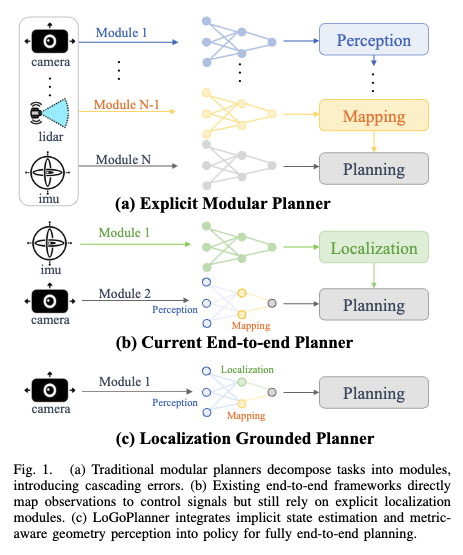
먼저 해당 방법론이 등장한 배경에 대해서 설명을 드리도록 하겠습니다.
전통적인 내비게이션 파이프라인은 보통 모듈형 구조로써 perception, Localization, mapping, planning으로 분해하는 구조로 구성됩니다. 이런 각각 모듈로 분해해서 내비게이션을 수행하는 방식 같은 경우에는 실패 원인에 대한 분석이 상대적으로 쉽고 각 구성요소를 개별적으로 최적화 할 수 있게 해주지만 크나큰 단점으로는 모듈 하나가 잘못되면 전체 시스템 latency가 누적되고 모듈간 연쇄적인 에러가 발생하는 문제가 존재합니다. 특히나 이런 문제는 legged robbots을 실제 환경에서 동작시켰을 때 발생한다고 하는데, legged robot의 뚝딱뚝딱한 움직임으로 인해 생기는 진동이 카메라나 IMU와 같은 센서에 영향을 주게 되면서 오도메트리와 매핑 정확도를 떨어뜨리게 되고 이는 하위 단계에서 수행하는 Planning을 불안정하게 만든다고 합니다.
그래서 최근에 End-to-end 학습 기반 방법들은 전통적인 모듈화된 내비게이션 방식이 아니라 시각 관측으로부터 바로 planning 혹은 Control으로 연결하는 간결한 파이프라인이 많이 생겨났다고 합니다. 근데 이런 대부분은 방식은 perception, mapping, planning 모듈을 하나의 간결한 파이프라인으로 대체할 뿐이지 사실상 localization(self-state updates) 관점에서 여전히 SLAM이나 Visual Odometry 와 같은 외부 localization 모듈에 의존한다고 합니다. 그렇기 때문에 해당 방식들은 localization을 하기 위해서 카메라와 로봇 차체 간의 정확한 Extrinsic 파라미터를 필요로하게돠고 이는 로봇에 부착된 센서들의 위치에 민감하게 된다라는 문제가 생기게 됩니다.
그래서 저자들은 위와 같은 문제를 해결하고자 즉, explicit localization에 대한 의존성을 극복하고자 긴 시간 시퀀스를 입력으로 동작하는 implicit state estimation이 가능하도록 하는 내비게이션 프레임워크 LoGoPlanner를 제안하게 됩니다. 자세한 내용은 메서드 파트에서 다루도록 하겠습니다.
Methods
일단 저자가 풀고자 하는 내비게이션 task는 RGB-D 관측만을 사용한 Point conditioned Goal Navigation 입니다. 즉 Goal pose와 RGB-D 입력이 들어왔을 때 에이전트는 추가적인 모듈에 의존하지 않고 충돌을 피하면서 start pose에서부터 지정된 Goal Pose 목표점까지 이동해야하는 것입니다. 에이전트는 과거 여러 프레임을 토대로 현재 프레임 기준으로 어디 지점을 가야하는지를 지속적으로 추정하는 동시에 안전하게 도착점까지 도착하기 위해서는 주변 환경 또한 인지하면서 내비게이션을 수행하게 됩니다.
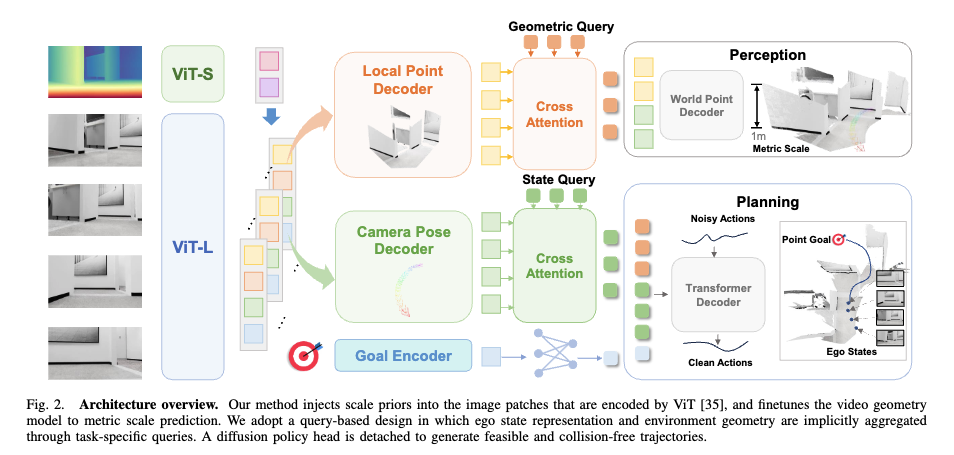
위 그림처럼 LoGoPlanner는 metric-aware perception, implicit localization, 그리고 planning 을 공동으로 학습하는 통합형 end-to-end 내비게이션 프레임워크입니다.
Metric-aware Visual Geometry Learning
먼저 인코더 같은 경우에는 사전학습된 VGGT 인코더를 사용합니다. 근데 VGGT와 같은 video geometric 모델 같은 경우에는 이미지 시퀀스로부터 dense한 3D 장면을 복원할 수 있긴하지만 복원된 3D 장면은 상대적인 스케일정보이기 때문에 실제 메트릭한 스케일을 요구하는 내비게이션에 적용하는데 있어서 한계가 있습니다. 그래서 저자들은 이러한 한계를 해결하고자 metric depth map으로부터 얻은 스케일 정보를 바탕을 백본을 파인튜닝해서 미터 스케일 장면 재구성이 가능하도록 합니다.
길이 N짜리의 RGB 이미지 시퀀스 I_{1:N}가 입력으로 들어오면 사전학습된 VGGT 인코더를 통해 각 이미지를 패치 단위로 분할해서 semantic token(t^I_i \in \mathbb{R}^{K \times C_I})을 생성하고 그 다음 동일한 인코더의 경량 버전을 가지고 depth map을 geometric token(t^D_i \in \mathbb{R}^{K \times C_D})으로 인코딩하게 됩니다. 이 토큰들을 패치 레벨에서 fusion하게 되고 어텐션 메커니즘과 RoPE를 통합한 트랜스포머 디코더 모듈을 추가로 사용함으로써 미터 스케일 감각이 들어간 프레임별 피쳐를 생성하게 됩니다. 수식은 아래와 같습니다.
t^{\text{metric}}_i = \text{Attention}{\text{(RoPE}}\big((t^I_i,\; t^D_i),\; \text{pos}\big))위에서 \text{pos} \in \mathbb{R}^{K \times 2} 는 이미지 패치들의 공간적 위치 좌표로 \text{RoPE}(\cdot,\text{pos}) 는 \text{pos} 에 들어 있는 2차원 좌표를 이용해 토큰에 position-dependent rotations 을 적용함으로써, 프레임 내부 어텐션 메커니즘이 패치 토큰들 사이의 공간적 위치 관계를 더 잘 포착하도록 강화한다고합니다. 결과적으로 t^{\text{metric}}_i 는 시점 i에서 metric-scale awareness가 반영된 fused feature embedding을 의미한다고 보시면 좋을 것 같습니다.
그리고 추가적으로 해당 LogoPlanner 프레임워크는 포인트 클라우드도 예측을 하게 되는데 이 예측 정확도를 높이고자 저자들은 학습과정동안 추가적인 감독신호를 제공하는 auxiliary tasks를 도입하게 됩니다.
구체적으로 앞서 얻은 프레임별 피쳐들 F={t^{\text{metric}}_1,\ldots,t^{\text{metric}}_N} 을 두개의 task-specific heads로 나눠서 처리하게 됩니다.
각각 두개의 헤드는 local point head, camera pose head입니다.
Local point prediction
각 프레임 i에 대해서 로컬 포인트 헤드 \phi_p는 metric aware 토큰 t^{\text{metric}}_i을 바탕으로 latent feature [latex]h^p_i를 뽑아내게 되고 latent feature h^p_i을 디코딩해서 카메라 좌표계 기준의 로컬 3D 포인트를 예측하게 됩니다. 수식은 아래와 같습니다.
h^p_i = \phi_p(t^{\text{metric}}_i), \quad \hat{\mathbf{P}}^{\,\text{local}}_i = f_p(h^p_i)여기서
\hat{\mathbf{P}}^{\,\text{local}}_i = {\hat{\mathbf{p}}^{\,\text{local}}_{i,j}}_{j=1}^{M}는 프레임 i에 대해서 예측된 로컬 포인트 j들의 집합을 의미하는데, 이 예측값은 이미지의 각 픽셀 (u,v)에 대해 핀홀 카메라 모델로 구한 카메라 좌표계 기준의 로컬 포인트를 GT로 학습이 이루어지게 됩니다.
카메라 내부 파라미터와 주어진 Depth 정보를 통해서 아래수식처럼 카메라 좌표계 기준 로컬 포인트 GT를 뽑아냅니다.
여기서 왜 depth 카메라가 있는데 굳이 depth를 그대로 역투영해서 포인트클라우드를 안만들고 모델이 local 3D point를 예측하게 하는지에 대한 의문점이 드실 수 있습니다. 이에 대해서 저자는 이 sparse한 depth를 그대로 쓰면 노이즈 정보가 그대로 3D로 표현되는 문제가 있는데 모델이 로컬 3D 포인트를 학습 기반으로 복원, 정제해서 예측하면 더 안정적인 3D를 만들 수 있고,
그 예측 과정에서 만들어진 latent feature h_i^p가 이후 월드 좌표계로 쌓을 때(뒷단에 world point prediction) 도움이 되는 implicit한 geometry feature로써 활용될 수 있기 때문이라고 합니다.
Camera pose prediction
카메라 포즈 헤드\phi_c도 마찬가지로 t^{\text{metric}}_i을 가지고 h^c_i를 뽑아내게 되고 이를 디코딩해서 예측된 Camera-to-World 변환을 출력하게 됩니다.
h^c_i = \phi_c(t^{\text{metric}}_i), \quad \hat{\mathbf{T}}_{c,i} = f_c(h^c_i)여기서 월드 좌표계라고 하면 마지막 타임스텝에서의 차체 프레임을 기준으로 정의되는 자표계라고 보시면 좋을 것 같습니다. 즉 가장 첫 시작 지점이 아닌 현재 위치한 곳 기준의 차체 기준 좌표계를 여기서는 월드 좌표계로 정의를 합니다. \hat{\mathbf{T}}_{c,i} 프레임 i의 카메라 좌표를 마지막 차체 프레임(현재 기준)으로 옮기는 변환이라고 보시면 될 것 같고, 결국 매 타임 스텝마다 마지막 프레임의 차체 좌표를 기준으로 카메라 프레임의 궤적이 예측된다고 보시면좋을 것 같습니다.
World Point Prediction
예측된 로컬 포인트나 예측된 카메라 포즈를 그대로 인코딩해서 사용하기 보다는 앞서 각각 구했던 latent feature h^p_i, h^c_i 를 활용하여 월드 포인트를 뽑아내게 됩니다. 각 프레임 i 에 대해서 로컬 포인트 특징 h^p_i와 포즈 특징 h^c_i를 concat한 다음에 그런 다음 얻은 프레임별 fused features을 컨텍스트 융합 모듈 A를 통해 패치들 전체에 걸쳐 합치게 됩니다.
h^w_i = A\left([h^p_i,\, h^c_i]\right)
위처럼 각 정보가 합쳐진 특징 h^w_i은 포인트 클라우드 디코더 \psi를 통과하고 나온 \hat{\mathbf{P}}^{\,\text{world}}_i은 마지막 프레임의 차체 좌표계에서 표현되는 metric scale로 재구성된 장면 포인트 클라우드를 의미합니다. 즉 여러 프레임에서 얻은 로컬 3D point + 카메라 포즈 정보를 이용해서 planning에서 바로 쓸 수 있는 현재기준(마지막 프레임)의 메트릭 스케일의 포인트 클라우드를 생성하게 되는 것입니다. 수식은 아래와 같습니다.
마지막 비선형 수식은 좌표의 큰 범위를 안정적으로 회귀하기 위한 출력 스케일링이라고 보시면 됩니다. 좌표를 그대로 regression하지 않고, 로그/지수 계열로 리파라미터라이즈해서 학습을 안정화한다는 아이디어 자체는 3D point regression에서 흔하게 쓰이는 방식이라고 합니다.
Localization Grounded Navigation Policy
앞서 설명드렸던 카메라 포즈 추정과 마찬가지로 h^c_i로 부터 차체 포즈와 상대 목표 위치(goal)예측을 수행합니다.
초기에 주어진 목표는 전역 목표점인데 planning은 현재 i프레임 기준의 상대 목표점으로 수행하기 때문에 현재 i프레임(차체 기준)에서의 상대 목표 \mathbf{\hat{g}_i}를 예측하게끔합니다.
근데 위에서 차체포즈 \mathbf{\hat{T}}_{b,i}는 논문에서 (x_i, y_i, \theta_i) 로 정의하면서 시작점에 대한 현재위치를 의미한다고 합니다. 재구성 포인트 클라우드, 카메라 포즈는 마지막 프레임 기준으로 예측했다면 차체 포즈 예측은 에피소드 시작점에 대한 절대 위치로 예측한다고 합니다.
그리고 저자들은 goal transformation 이나 궤적 최적화를 위해서 앞서 설명드린 예측된 포즈 정보들이나 3D 포인트클라우드를 네트워크에 명시적으로 바로 입력 않고 UniAD라는 방법론을 참고해서 서로 다른 모듈들을 태스크 특화 쿼리를 통해 집계하는 쿼리 기반 설계를 활용합니다. 어떤 좌표 정보(포즈/포인트)를 쓰지 않고도 플래닝에 필요한 정보를 가져오게 하기 위해서 쿼리가 피쳐들에서 정보를 뽑아오게 만드는 식으로 동작하게 됩니다.
state 쿼리 Q_s가 pose-specific tokens/feature(여기서는 h^c)에서 상태 정보를 뽑아오게 됩니다.
Q_S = \text{CrossAttn}(Q_s,\, h^c)geometry 쿼리 Q_g같은 경우는 (3D 포인트 관련) geometry feature(논문 표기상 h^p)에서 환경 기하 정보를 뽑아오게됩니다.
Q_G = \text{CrossAttn}(Q_g,\, h^p)여기서 핵심은 CrossAttn이 aggregation 하는 역할을 한다는 건데 여기서 저자가 강조하는 점은 좌표(포즈/포인트)를 downstream에 직접 전달하는 대신 학습된 feature에서 필요한 정보만 요약해서Q_S, Q_G로 뽑아낸다라는 점입니다.
이렇게 생성된 Q_S, Q_G 그리고 goal encoder를 타고 나온 골 임베딩concat된 후에 이후 트랜스포머 디코더의 입력으로 들어가게되고 계획 컨텍스트 쿼리(planning context query) Q_P를 생성하게 됩니다. 위처럼 명시적인 포즈/포인트들이 아니라 암묵적인 state,geometry 특징들은 planning을 위한 조건 신호로 활용되게 되는데 이러한 전략은 상위 모듈의 예측 값을 하위 태스크에 직접 적용할 떄 발생할 수 있는 cascadinf error를 피할 수 있도록한다고 합니다. 그리고 마지막으로 내비게이션 궤적 planning을 위해서 저자들은 diffusion 정책 헤드를 넣어서 아래와 같은 액션 청크
{a_t=(\Delta x_t, \Delta y_t, \Delta \theta_t)}_{t=1}^{T}
를 생성하게 됩니다.
가우시안 노이즈로부터 샘플링한 a_K에서 시작해서 모델은 노이즈가 섞인 액션 시퀀스로부터 노이즈를 예측하고, K 번의 반복적인 디노이징 단계를 수행해 노이즈 수준이 점점 줄어드는 중간 액션들의 연속을 생성하도록하고 자세한 수식은 아래와 같습니다.
여기서 a_k는 단계 k 에서의 노이즈 액션이고, \epsilon_\theta는 계획 컨텍스트 쿼리 Q_P를 바탕으로 노이즈를 예측하는 네트워크라고 보시면 됩니다.
Experiments
저자들은 다양한 로봇 embodiments에 대해서 위와 같은 방식이 잘 동작하도록 하기 위해서 임의의 카메라 높이와 다양한 피치 각도 하에서 학습데이터를 구성하여 학습함으로써 시스템이 다양한 카메라 설정 전반에 걸쳐 일반화 할 수 있도록 했다고 합니다. 근데 데이터 셋은 시뮬레이션 데이터셋만 활용한 것 같습니다. 데이터 셋은 20만개가 넘는 궤적과 약 1천만 장의 렌더링 이미지로 구성되었다고 합니다.
먼저 해당 logoplanner 같은 경우는 2단계로 학습을 진행합니다. 1단계에서 video geometry 모델의 디코더와 태스크 특화 헤드를 먼저 파인튜을 진행합니다. 이 과정에서 depth 기반 scale prior를 주입하게 되고 metric scale의 장면 포인트 클라우드와 카메라 포즈 정보를 GT로 제공합니다. 그리고 2 단계에서는 diffusion head를 태스크 특화 헤드와 함계 joint 학습이 이루어지면서 백본의 디코더는 freeze한채로 학습을 진행한다고 합니다.
먼저 저자들은 시뮬레이션 환경과 실제 환경 모두에서 서로 다른 학습 기반 플래너들의 성능을 평가합니다. 테스트 환경은 학습 과정에서 한번도 보지 못한 unseen 환경으로 구성하였고 로봇은 지속적으로 자신의 상태를 추정하고 충돌 없는 궤적을 planning하면서 지정된 목표 지점으로 잘 이동하는 것을 목표로 합니다.
플래닝 성능은 Success Rate(SR)와 Success weighted by Path Length(SPL) 지표로 측정되는데 SR 같은 경우는 전체 에피소드 시도중 성공으로 판정된 비율이라고 볼 수 있습니다. 여기서 성공의 판정 기준은 실험 프로토콜에 따라 조금 다를 수 있겠지만 보통은 목표 지점 근처 거리 임계값 이내 도달하거나 혹은 stop 같은 종료 액션을 올바르게 수행한다던지 등등 있는것 같은데 여기서는 자세한 언급은 없습니다. SPL 같은 경우는 성공 여부에 더해서 최단 경로 대비 실제 이동 경로가 얼마나 효율적인지를 함께 반영한 점수라고 보시면 좋을 것 같습니다. 즉 시작지점 부터 목표 지점까지 최단경로길이대비(장애물 고려한) 실제 에이전트가 이동한 경로 길이를 평가하는 지표다라고 이해하시면 좋을 것 같습니다.
시뮬레이션 환경 실험

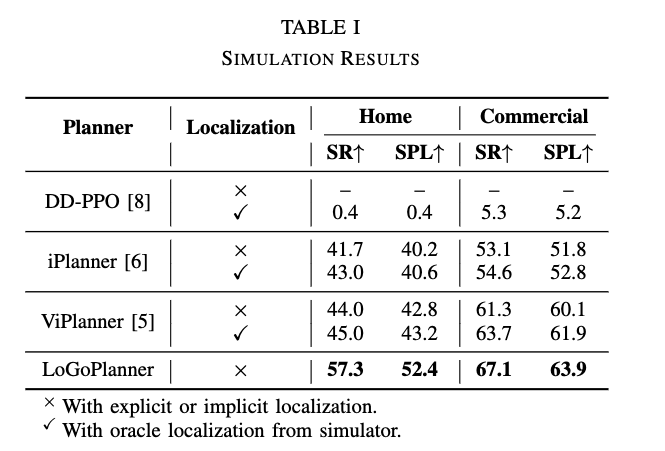
먼저 시뮬레이션 실험입니다. 현실적인 환경을 모사하기 위해서 InternScenes 데이터셋에서 40개의 장면을 선택하고 그 중 Home, Commercial 환경 각각 20개씩 평가를 진행합니다. 각각예시는 Fig3을 참고하시면 좋을 것 같습니다. 각 장면에서 점유되지 않은 공간 내에서 start-goal 쌍(거리는 4-10m)을 100개로 무작위로 샘플링하 평가를 진행하였다고 합니다. Localization에서 체크 표시는 플래너가 시뮬레이터가 제공하는 포즈를 사용했는지 여부를 나타낸다라고 보시면 됩니다.
이때 iPlanner와 ViPlanner의 경우 외부 localization 모듈(ORB-SLAM3)를 사용하는 반면 LoGoPlanner는 외부 localization 모듈을 사용하지 않고 implicit state estimation을 수행하여 동작합니다. 결과적으로 외부 localization 모듈을 활용하지 않고 implict state 정보와 다중 프레임 기반 geometric reconstruction을 함께 통합함으로써 더 좋은 성능을 보입니다. 또 Localization GT를 사용한 베이스라인 결과들과 비교했을 때에도 더 좋은 성능을 보입니다.
그리고 강화학습 기반 플래너인 DD-PPO 같은 방법은 보통 막대한
실제 환경 실험

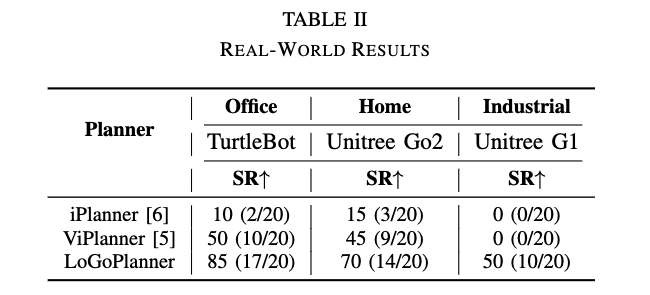
실제 환경에서 LoGoPlanner의 플랫폼 간, 장면 간, 시점 간 일반화 성능을 평가하기 위해서 저자들은 다양한 환경 구성 하에서 서로 다른 3개의 로봇 플랫폼에서 실험 평가를 진행합니다. 사무실 환경에서는 터틀봇으로 그리고 복잡한 가정집(?) 환경에서는 로봇개로 그리고 산업 현장(?)에 대해서는 2족 로봇으로 테스트 했다고 하고 총 20개 궤적에서 평가를 진행합니다.
먼저 iPlanner같은 경우는 전반적으로 장애물 회피를 잘 못한다고 합니다. 그에 반해 ViPlanner 같은 경우는 좀더 나은 성능을 보이긴 하는데 ViPlanner같은 경우는 단일 프레임 기반의 내비게이션을 수행하기 때문에 좀더 복잡한 환경 unitree G1이면서 산업환경인 경우네느 성능이 좋지 않은 모습을 보입니다.
저자들이 제안한 LoGoPlanner는 VO나 SLAM을 필요로 하지 않고 바로 실제 환경에 바로 적용이 가능합니다. 사족 보행 플랫폼에서 발생하는 카메라 흔들림에도 불구하고 LogoPlanner는 self-localization을 잘 수행하면서 충돌 없는 궤적을 생성하는 모습을 보인다고 합니다. 또 포인트 클라우드를 implicit 중간 표현으로 활용함으로써 sim-to-real 갭을 추가로 줄이면서 장면 구조와 카메라 시점이 다양한 상황에서도 기존 베이스라인 보다 좋은 일반화 성능, 직접 적용 가능성을 보여줍니다.
Ablation Study
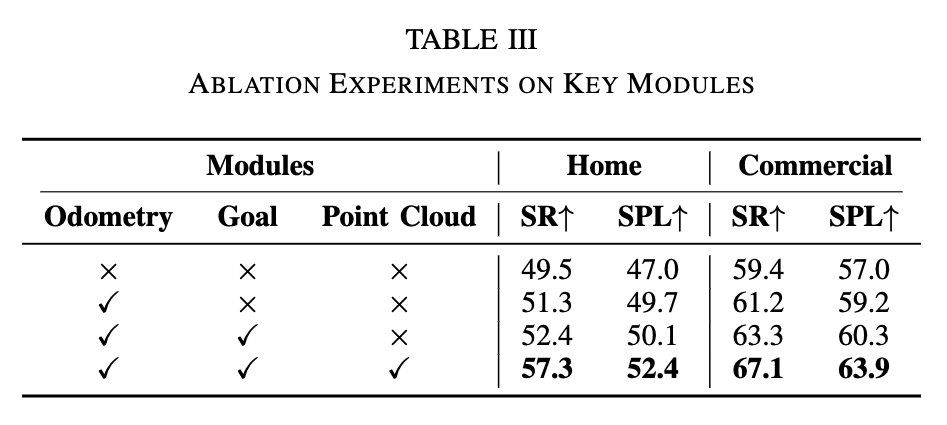
모델이 self-state estimation and metric-aware perception을 잘 하도록 하기 위해 저자들은 1단계 학습에서 3가지 auxiliary task 를 도입합니다.
먼저 Odometry 같은 경우는 앞서 메서드 파트에서 설명드린 부분에서 pose-feature h_i^c로부터 차체 포즈를 예측하는 헤드가 있었는데 시작점 기준 차체 포즈를 GT로써 차체포즈 예측 헤드를 학습시키는 보조 태스크라고 보시면 좋을 것 같고
Goal 같은 경우도 마찬가지로 pose-feature h_i^c로부터 현재 프레임 i에서의 상대 goal pose를 예측하는 과제를 의미합니다.
그리고 Point Cloud 같은 경우는 논문에서 설명이 자세하게 나와있지는 않지만 로컬 포인트 예측, 카메라 포즈 예측, 월드 포인트 클라우드 예측 이 3가지를 합쳐서 말하는 것 같습니다.
구체적으로 Local point head \phi_p 각 프레임에서 카메라 좌표계 로컬 3D 포인트를 예축하는 과제 Camera pose head \phi_c 각 프레임의 camera-to-world 변환(카메라 포즈)을 예측하는 과제 그리고 이 둘의 중간 feature h^p_i, h^c_i 를 합쳐서 world point(=장면 point cloud) 를 복원하는 보조 태스크를 의미한다고 보시면 좋을 것 같습니다.
아무 보조 태스크도 사용하지 않고 end-to-end supervision만으로 학습된 모델은 기본적인 path-planning 능력은 보이긴 하는데 중간 feature 표현 학습하는데 있어서 명시적인 가이던스가 없기 때문에 self-state 추정이 부정확해지는 문제가 생긴다고 합니다. Odometry와 Goal supervision을 추가하면 self-state 추정이 개선되면서 궤적 생성또한 안정적인 모습을 보인다고 합니다. 여기서 point Cloud supervisio 까지 추가하하면 모델이 2D semantic 정보를 넘어서 장애물의 3D 공간적 관계를 포착할 수 잇게돼서 궤적 생성하는데 있어서 장애물 회피성능 또한 크게 향상되는 모습을 보인다고 합니다.
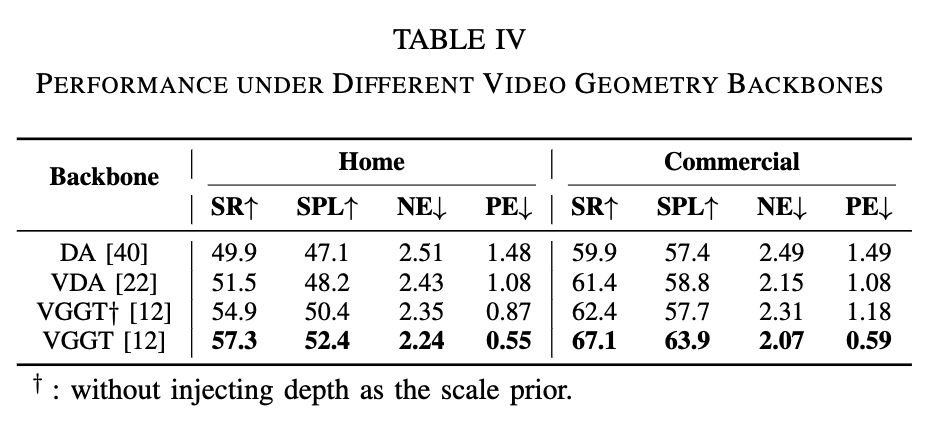
그리고 마지막으로 geometric 백본에 대한 ablation 실험입니다. 먼저 단일 프레임만을 처리하는 geometric 백본인 depth anythong 부터 다중 프레임 처리 백본인 Video depth anything 그리고 metric scale이 없는 VGGT(오리지날), 그리고 VGGT에 메트릭 스케일을 주입한 버전(ours)를 가지고 평가를 합니다. 이 실험 과정에서는 앞서 언급한 모든 보조 태스크를 그대로 유지합니다.
먼저 포즈 추정과 플래닝 정확도를 평가하기 위해 Navigation Error(NE), Planning Error(PE)를 정의하여 평가하였다고 합니다. 각각에 대해서 설명드리면 NE는 로봇이 최종적으로 멈춘 위치와 목표 지점 사이의 유클리드 거리를 나타낸 것이고 PE같은 경우는 Planning한 tradjectory의 끝점과 실제 목표 지점사이의 거리를 나타낸다고 보시면 됩니다.
먼저 먼저 depth anything 기반의 백본들 같은 경우는 프레임 단위의 어떤 깊이 정보를 제공하긴해서 장애물 회피에는 도움을 준다고는 하지만 성공률은 낮은 모습을 보입니다.
또 기존 reconstruction 기반 사전학습 모델 VGGT는 depth prior가 없기 때문에 스케일 불일치 문제로 인해 성능이 낮은 모습을 보이고 여기에 scale prior를 주입하는 설계를 도입한 LoGoPlanner 백본은 다른 방법보다 더 높은 플래닝 성공률, 정확도를 보이는 결과를 확인 할 수 있습니다.
따라서 저자들은 실제 환경에 적용하기 위해서는 여전히 metric scale의 supervision이 필요하다고 합니다.

그리고 위 Fig5는 논문에 첨부되어있는데 아무런 언급이 없었지만 들고왔습니다. 아마 world point prediction을 상황에 맞게 시각화한 결과이지 않을까 싶습니다.
Conclusion
해당 논문의 방법론의 규모에 비해서 상세하게 설명된 내용이 많이 없어서 이해하기 힘들었던 논문이었던 것 같습니다. 기존에 읽어왔던 논문들이랑은 완전 분위기가 달라서 이해하기 힘들었을 수 도 있는 것 같습니다. 그리고 비교한 방법론이 iPlanner, ViPlanner 두개라 평가 결과만을 가지고 잘 동작한다고 봐도 좋은건가라는 생각이 들었는데 그래도 해당 데모 영상에 르키위가 동작하는 영상에서 르키위가 꽤나 잘 작동하는 모습을 보고 잘 작동할거라는 희망을 가지면서 꾸역꾸역 읽어내려갔던 것 같습니다.
그리고 비교한 방법론이 하나의 프레임워크 내에서 self state 추정, 3D Point Cloud 예측, feature level에서의 query-base 설계가 되었다는 점에서 실제 배포과정에서 각 보조 태스크 헤드를 뗀다고 해도 추론시간이 꽤나 걸릴거 같다는 생각이 들긴합니다. 물론 보인 데모 영상은 서버사이드에서 동작시켰다고 합니다. 그리고 해당 방법론같은 경우는 사용 가능한 내비게이션 장면수가 제한적이라 실제환경에서의 재구성 성능은 아직 좋지 않다고 합니다. 그래서 현재 저자들은 metric scale의 real world 데이터 셋을 가지고 학습을 진행하고 있다고 합니다. 이상으로 리뷰 마치도록 하겠습니다.
안녕하세요 우현님 좋은 리뷰 감사합니다.
해당 방법론에서 Metric scale을 재구성하기위해 fine tuning을 해서 실제 메트릭에 맞추는걸로 이해를 했는데요 실험표들의 성능을 보았을때 metric이 실제 metric과 얼만큼 차이가나는지에 대한 리포팅이 없어서 혹시나 저자들이 metric scale에 대한 실험은 따로 언급한게 없을까요 ?
안녕하세요 우진님 좋은 댓글 감사합니다.
일단 Metric scale에 대한 실험은 따로 없었습니다. 우진님꼐서 말씀주신 대로 뭔가 저도 해당 결과가 있으면 좋지 않았을까 싶지만 사실상 world point cloud를 예측하는거 자체가 중간 피쳐표현을 강화하기 위한 기존 auxiliary tasks로써 존재하기 때문에 저자는 실제 inference 내비게이션 관점에서 플래닝 결과만으로 Metric 영향을 평가하지 않았나 싶습니다. 감사합니다.
우현님 좋은 리뷰 감사합니다.
해당 방법론은 Local Point로 3D 포인트를 복원하는 과정에서 생성된 geometry feature, Camer-to-World 변환 관계를 추정하고 World Point를 예측하는 과정에서 구한 state 쿼리, goal encoder를 타고 나온 골 임베딩을 사용하여 planning을 수행하는 것으로 이해하였습니다. 제가 세미나에서 이해하기로 goal은 2D라고 하셨던 것 같은데, 이 3가지 정보가 너무 다른 도메인의 정보들인데, 이를 단순히 concate하는 방식으로 이용하여도 충분할 지 궁금합니다. 저자들은 이에 대한 다른 언급이 없었을까요?
안녕하세요 승현님 좋은 댓글 감사합니다.
다만 논문을 보면 저자들이 이 세 정보를 raw feature를 그대로 붙이는 방식으로 concat했다기 보다는, 먼저 task-specific query와 cross-attention으로 각각을 planning에 유리한 implicit representation으로 추출한 후에 그 결과를 goal embedding과 함께 결합하는 구조로 보시면 좋을 것 같습니다. 그래서 저자들의 의도는 도메인이 다른 이 3가지 정보를 그냥 concat한다기보다는 concat 하기 이전에 planning context로 정렬된 latent feature들로 변환한 뒤 concat한다는 쪽으로 이해해주시면 좋을 것 같습니다.
감사합니다.